
摘要:本文重點介紹單個SQL語句持續執行慢的場景。 本文分享自華為雲社區《GaussDB(DWS) SQL性能問題案例集》,作者:黎明的風。 本文重點介紹單個SQL語句持續執行慢的場景。我們可以對執行慢的SQL進行單獨分析,SELECT、INSERT、UPDATE等語句都可以使用explain ve ...
摘要:本文重點介紹單個SQL語句持續執行慢的場景。
本文分享自華為雲社區《GaussDB(DWS) SQL性能問題案例集》,作者:黎明的風。
本文重點介紹單個SQL語句持續執行慢的場景。我們可以對執行慢的SQL進行單獨分析,SELECT、INSERT、UPDATE等語句都可以使用explain verbose + SQL語句輸出查詢計劃來進行分析,這樣只輸出查詢計劃,語句不會被實際的執行。
如果查詢計劃只出現__REMOTE_FQS_QUERY__或__REMOTE_LIGHT_QUERY__,看不到具體的計劃,可以先執行set enable_fast_query_shipping to off; 然後再重新列印執行計劃。
經常遇到的問題有以下幾個:
【案例1】語句中包含不下推的函數
檢查查詢計劃中是否包含_REMOTE_TABLE_QUERY_關鍵字, 如果有則表示語句沒有下推,數據需要從DN上收取到CN上,然後語句在CN上執行。語句不下推原因,要從CN的日誌中查找,搜索的關鍵字為:SQL can’t be shipped,以下為函數造成的不下推例子:
LOG: SQL can't be shipped, reason: Function Fun1() can not be shipped
此外如果出現以下幾種不下推的關鍵字:__REMOTE_GROUP_QUERY__、__REMOTE_LIMIT_QUERY__、
__REMOTE_SORT_QUERY__。這種需要檢查enable_stream_operator參數是否處於關閉狀態,一般來說打開STREAM開關後,語句就可以下推執行了。
如果出現以下兩種關鍵字,表示語句可以下推執行:
__REMOTE_FQS_QUERY__:表明語句走了Fast Query Shipping(FQS),SQL語句會下發到DN上執行,並且各DN之間沒有數據交互,常見的場景有過濾條件為等值查詢(where id = 1),或者關聯的列是表的分佈列的查詢(where t1.id = t2.id)。
__REMOTE_LIGHT_QUERY__:表明語句走了Light Proxy(CN輕量化),將語句下發給了單個DN去處理,常見的場景過濾條件是分佈列的等值查詢(where id = 1),或者向一個DN插入數據的INSERT語句。
【案例2】表上有索引但沒有走索引掃描,進行了全表掃描
從查詢計劃中可以看到Seq Scan或CStore Scan這樣的關鍵字,如下所示:
對於行存表:-> Seq Scan on t1
對於列存表:-> CStore Scan on col_t1
出現這種問題通常有以下幾種情況:
沒有對所查詢的表收集統計信息
如果表的實際行數很大,而估算行數很小,查詢時可能會走全表順序掃描,造成執行速度慢。此時通過analyze表更新統計信息,讓優化器選擇最佳的查詢計劃,一般就可以解決執行慢的問題。
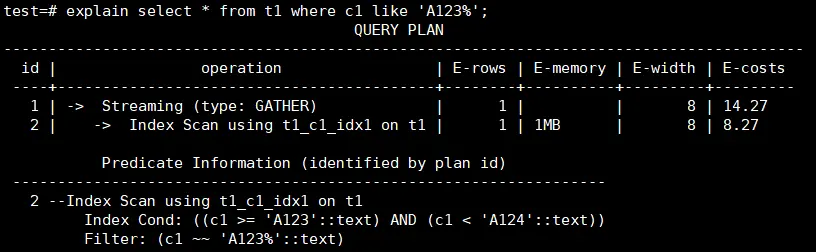
【案例3】模糊匹配沒有走索引
後模糊匹配查詢可以通過建立一個BTREE索引來實現,需要根據數據類型設置索引的operator,對於text,varchar和char分別設置和text_pattern_ops,varchar_pattern_ops和bpchar_pattern_ops。
例如c1列的類型為text,創建索引時增加text_pattern_ops。
CREATE INDEX ON t1 (c1 text_pattern_ops);
創建索引後,可以看到語句執行時會使用到前面創建的索引,執行速度會變快。
【案例4】創建索引時所指定列的順序問題
多列複合索引的組織結構與單列欄位索引結構類似,按索引內表達式指定的順序編排。當創建多列複合索引時,選擇什麼樣的列的順序,對查詢性能會帶來一定的影響。
例如按照c_date,c1和c2列的順序建立檢索,如果符合c_date條件的數據很多,通過這個索引掃描的數據就很會很多,造成執行時間長。

新建多列複合索引,將查詢條件里的等值條件的列放到索引列的前面,先使用等值進行過濾,需要掃描的數據變少,查詢變快。

【案例5】分區表沒有分區剪枝進行了全表掃描
問題背景:XSYX局點使用MERGE INTO語句將每天的數據入庫到表裡,目標表為分區表,業務上線運行一段時間後發現MERGE INTO速度逐漸變慢。
原因分析:MERGE INTO語句的源表和目標表都是分區表,當前僅對源表增加了時間的過濾條件,可以進行分區剪枝。目標表由於沒有指定時間過濾條件,進行的是全表掃描,隨著每日的入庫業務運行,目標表的數據量越來越大,造成執行速度越來越慢。
解決方案:由於源表的數據在MERGE INTO時會導入到目標表的對應分區里,可以對目標表增加時間的過濾條件進行分區剪枝。
業務修改前的查詢計劃:
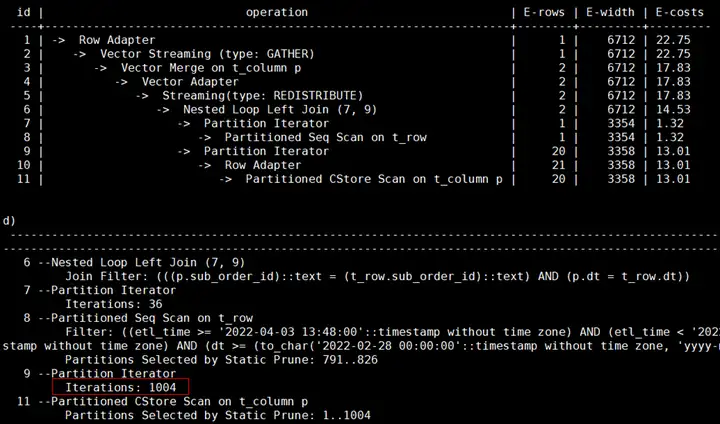
對目標表增加了時間過濾條件後的計劃顯示可以走分區剪枝:

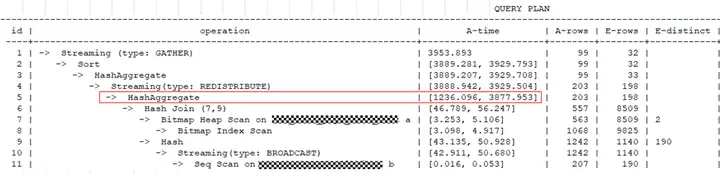
【案例6】表數據在DN節點上有存儲傾斜
從查詢計劃中的A-time可以看到最長和最短的執行時間相差很大,說明在不同DN上掃描數據的時間不同。

在查詢計劃的DN信息中,通過rows可以看出在datanode1上掃描的數據量明顯多於datanode2,說明有存儲傾斜,這種情況建議對錶進行合理的設計,選擇合適的分佈列,將數據均勻分佈到所有的DN上。

【案例7】自定義函數引起執行慢
問題現象:查詢語句比較簡單,兩個表做關聯後輸出了其中一列的值,在輸出前增加了一個自定義函數對數據進行了處理。
原因分析:自定義函數里邏輯相對複雜,包含了對錶的查詢及數據計算邏輯,造成執行變慢。
解決方案;業務上對自定義函數進行性能優化。
【案例8】查詢視圖執行時間長
問題現象:某YD局點從C80版本遷移數據到8.1.1版本後,查詢PG_STAT_USER_TABLES視圖的時間由幾分鐘變成半個小時都不出結果。
原因分析:8.1.1版本中的PG_STAT_USER_TABLES視圖在獲取插入、更新、刪除的行數的欄位數值時,每一條記錄都涉及到CN和DN的交互,在數據量和集群規模大的情況下耗時較多。
解決方案:建議根據應用的實際需要,將視圖定義中不需要的函數註釋掉以提升查詢效率。
【案例9】關閉indexscan和bitmapscan後可以使用並行提升性能
問題現象: 查詢計劃中顯示走了Index Scan,通過索引查詢出的數據量比較大,速度慢。
原因分析:由於使用索引掃描時無法使用並行查詢,當索引訪問的數據量大時執行速度較慢。
解決方案:將enable_indexscan和enable_bitmapscan參數關閉,設置query_dop後走並行查詢。

