MatrixOne從入門到實踐——物聯網平臺架構升級 公司介紹 西安天能軟體科技有限責任公司,成立於2018年,公司自成立起集中力量精心打造物聯網平臺,擁有集自主研發、終端生產、銷售、服務一體的物聯網平臺及服務團隊,已為國內外300多家物聯網企業、千萬級物聯網設備提供合作支持。 公司在物聯網領域擁有 ...
MatrixOne從入門到實踐——物聯網平臺架構升級
公司介紹
西安天能軟體科技有限責任公司,成立於2018年,公司自成立起集中力量精心打造物聯網平臺,擁有集自主研發、終端生產、銷售、服務一體的物聯網平臺及服務團隊,已為國內外300多家物聯網企業、千萬級物聯網設備提供合作支持。
公司在物聯網領域擁有多項設備接入、遠程管理及大數據分析等研發技術專利,用行業領先的物聯網服務經驗為企業註入了全新的生產力。
智能家居上雲:針對消費級設備智能化特點,Skyable為空凈新風、凈水機、廚衛電器、白色大家電、可穿戴設備、血糖儀、體脂秤、智能鎖等消費級智能產品提供設備連接、數據分析、設備管理、智能售後、APP開發、用戶畫像分析等服務,方便廠商快速實現產品智能化。
工業物聯網:通過工業IOT平臺建設,將海量工業設備通過智能工業網關接入IOT平臺,對海量工業設備運行數據及狀態進行集中實時上報、分析、監測、跟蹤,靈活設置設備參數,達到設備故障提前預知,並提前主動對設備進行狀態調整或檢修,減少設備故障造成的財產損失也減少強迫停機的次數,提升設備的使用壽命。
行業背景
物聯網作為一個提出 20 多年的概念,在技術上已經獲得了各項突破性進展,包括感知技術促進智能設備獲取數據,通信技術負責傳輸數據,大數據技術使企業開始嚮往海量數據存儲與處理的能力,以及近年引起廣泛討論的 AIoT,讓人們對人工智慧在物聯網的應用充滿期待。
以客戶為中心——這一理念的正確性在不同商業領域得到驗證,尤其在產業鏈複雜、市場分散化、碎片化的物聯網行業,企業更應該關註目標客戶的痛點與需求,選擇合適的路徑進行商業化運作。但物聯網前端客戶的需求一向是多樣化的,在很多細節上都會有不同,如果企業做服務時每次都為客戶的定製化需求大費周章做開發,實際很容易拖累整個公司業務的高效運行。
平臺介紹
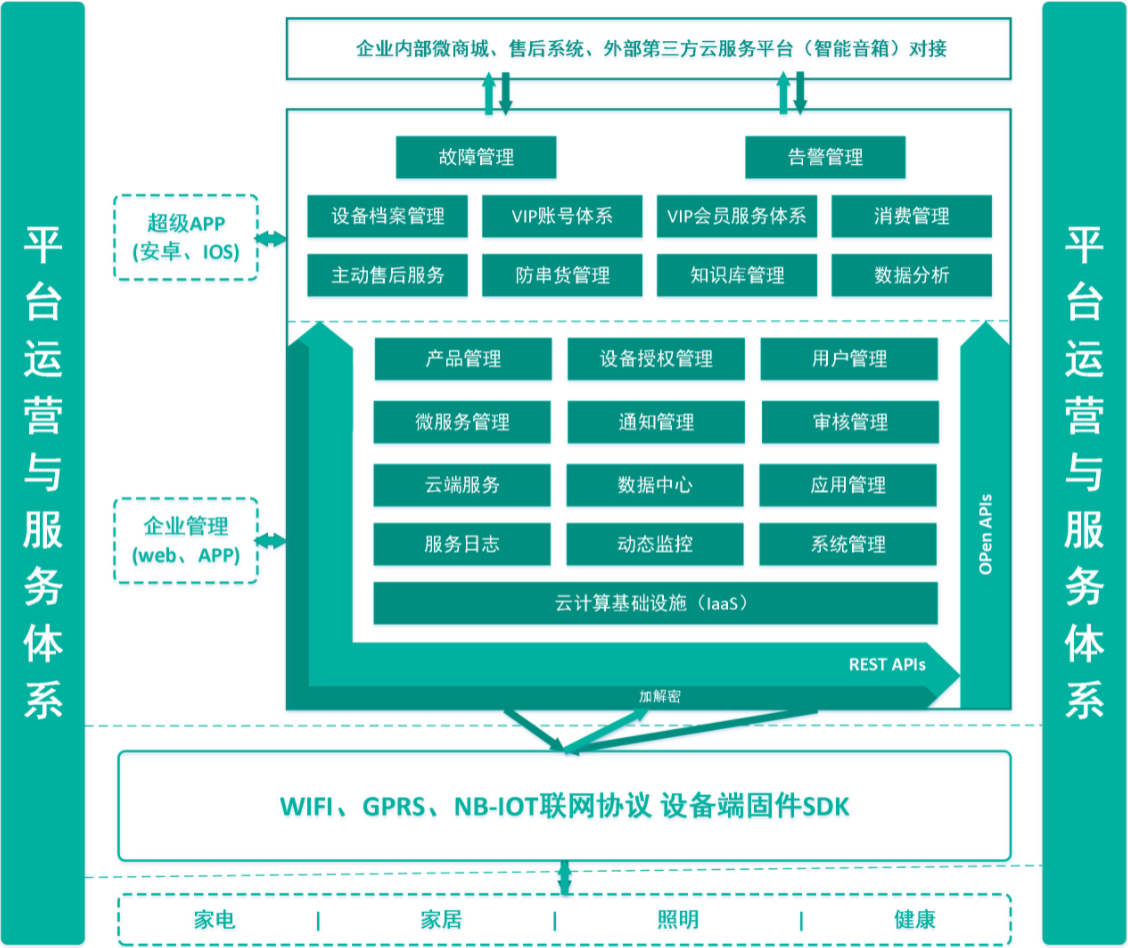
Skyable IOT平臺
支持海量設備接入,平臺提供安全穩定的設備通信通道,靈活相容MQTT、CoAP、TCP、UDP、REST/HTTP等多種物聯網常用傳輸協議,完成千萬量級設備的連接管理、數據計算和存儲等高併發處理。
平臺提供適用於APP、Web、雲服務開發的API和SDK,通過分散式集群調度系統自動優化計算資源的使用,客戶只需關註業務邏輯,即可快速實現高性能、高可用、穩定可靠的應用。
平臺提供豐富的通用功能組件庫,減少“重覆造輪子”的工作,客戶可以快速組合出適用於自己業務場景的應用。
物聯網設備攻擊日益頻繁的今天,平臺構建了覆蓋設備端、雲端、客戶端完備的安全體系,為客戶的設備和數據安全性提供了有力支撐。
平臺(公有雲)目前已部署了包括中國、東南亞、歐洲、北美等多地域的服務集群,遍佈全球核心商業價值圈,幫助客戶更好的拓展國際化業務。
業務背景
平臺對於設備基礎數據、狀態數據以及少量的應用數據會存放在Mysql中。對於大量的歷史數據平臺會將數據寫入MongoDB資料庫中進行存儲。另外會通過數據採集模塊非同步的將數據寫入MongoDB中提供給分析平臺做後續的分析處理。針對日誌數據,會通過自定義日誌解析模塊寫入Elasticsearch中進行搜索查詢。
平臺現狀
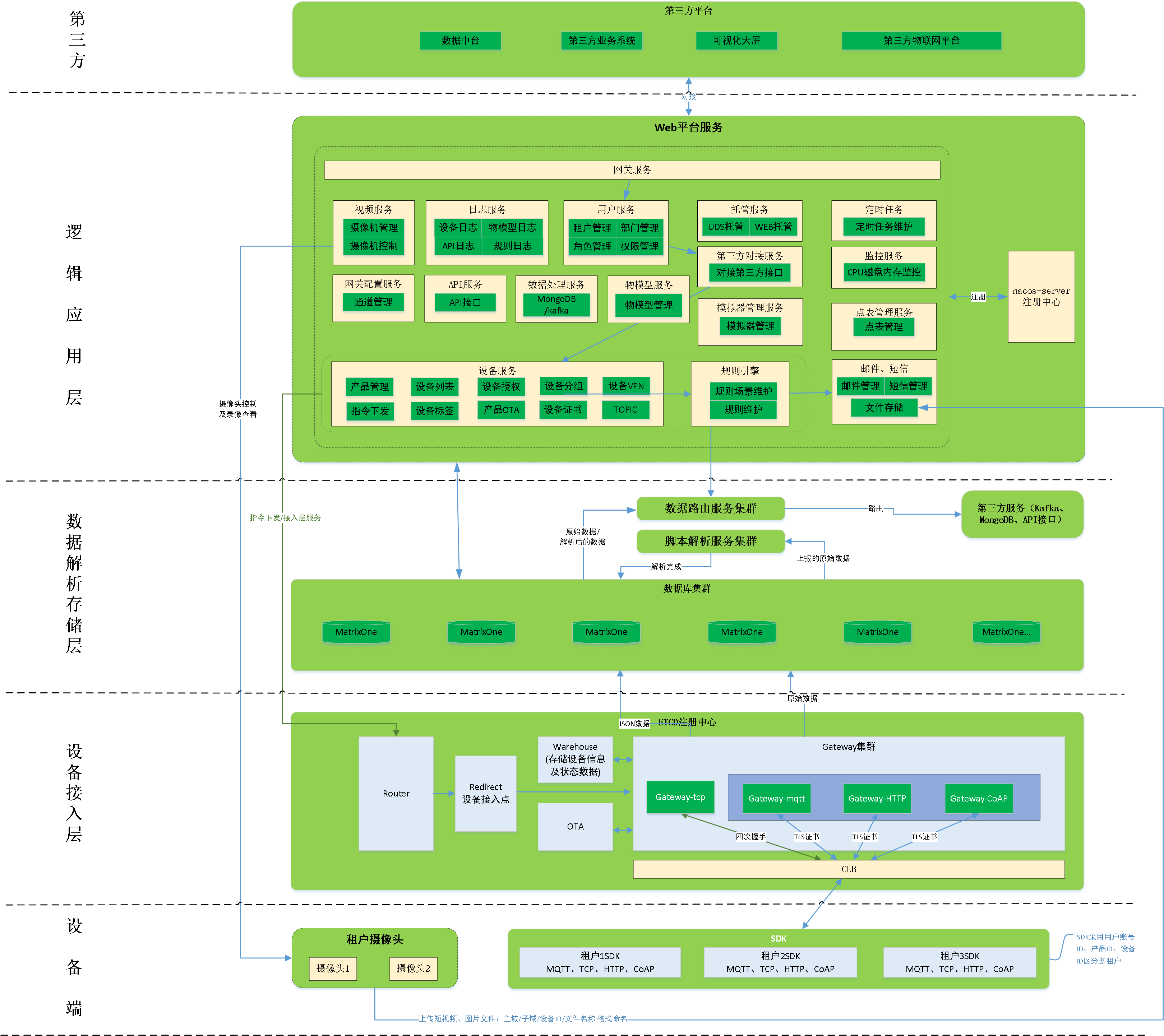
目前平臺主要分了以下幾個層面:
-
租戶設備
租戶設備包括邊緣網關和直連設備。邊緣網關子設備如PLC設備、工業電腦、工業伺服器等設備,將數據上報網關與平臺交互。直連設備可直接上報數據與平臺進行交互。
-
接入層
設備接入層包括邊緣網關及平臺接入集群,邊緣網關通過平臺提供的設備端SDK,將數據上報的平臺接入集群,支持MQTT、HTTP、CoAP等傳輸協議。SDK按照平臺的通訊協議標準,在設備的數據協議的基礎上進行了二次封裝,包括平臺驗證等。
-
解析層
用戶自定義腳本解析是由用戶創建解析規則腳本,上傳到平臺針對上報數據進行解析,解析後的數據推送到第三方業務平臺。
-
存儲層
存儲層負責平臺基礎數據存儲和設備業務數據存儲,平臺基礎數據包括產品基礎數據、屬性數據、設備基礎數據、企業基礎數據、用戶基礎數據、許可權基礎數據等,基礎數據採用MySQL資料庫存儲。設備業務數據存儲分為實時數據、歷史數據和平臺日誌,實時數據和歷史數據採用MongoDB資料庫,平臺日誌採用ES資料庫。
-
應用層
應用層負責展示、控制,包括產品管理、設備管理、計量管理、企業管理、雲端組件、雲端服務等。
在核心的計算存儲層,我們原有的架構引入的多種資料庫來解決不同的業務場景,如:
- mysql
- Redis
- MongoDB
- kafka集群
- elasticsearch集群

目前存在以下痛點:
-
數據冗餘度高
多個組件之間數據都有多副本,數據冗餘成本高
-
架構複雜,多個組件之間的數據耦合性高
組件與組件之間存在數據的反覆流向,架構複雜,耦合性較高
-
運維成本高,私有雲部署成本高
部分客戶部署環境不會允許太高的資源消耗,目前架構部署比較吃硬體成本
-
ap性能不足
基於MongoDB的ap,在數據量大了之後,ap性能不佳
因此,我們想尋找一個能解決HTAP,並還能解決部分流式計算場景的資料庫來承擔我們平臺的核心存儲計算功能,簡化我們的平臺架構,提高硬體資源的利用率。減少我們的開發和硬體成本。
通過調研對比業內幾家HTAP的產品,我們最終選擇了一家新興的資料庫產品:MatrixOne。由於該產品目前出於打磨階段,我們也是現在小部分業務場景進行了部分業務替代,進行方案平臺的逐步升級。
選擇MatrixOne的主要原因有以下幾點:
-
優異的雲原生系統架構
在IOT場景,有許多邊緣雲的場景,需要資料庫能夠面對複雜多變的存儲介質和數據協議,MatrixOne天生雲原生的架構,支持TP、AP雙模式,能夠更好的應對這一業務場景。
-
GO開源的源代碼
團隊中有很多GO語言開發者,基於MatrixOne開源的源代碼,我們能更好的利用MatrixOne的特性
-
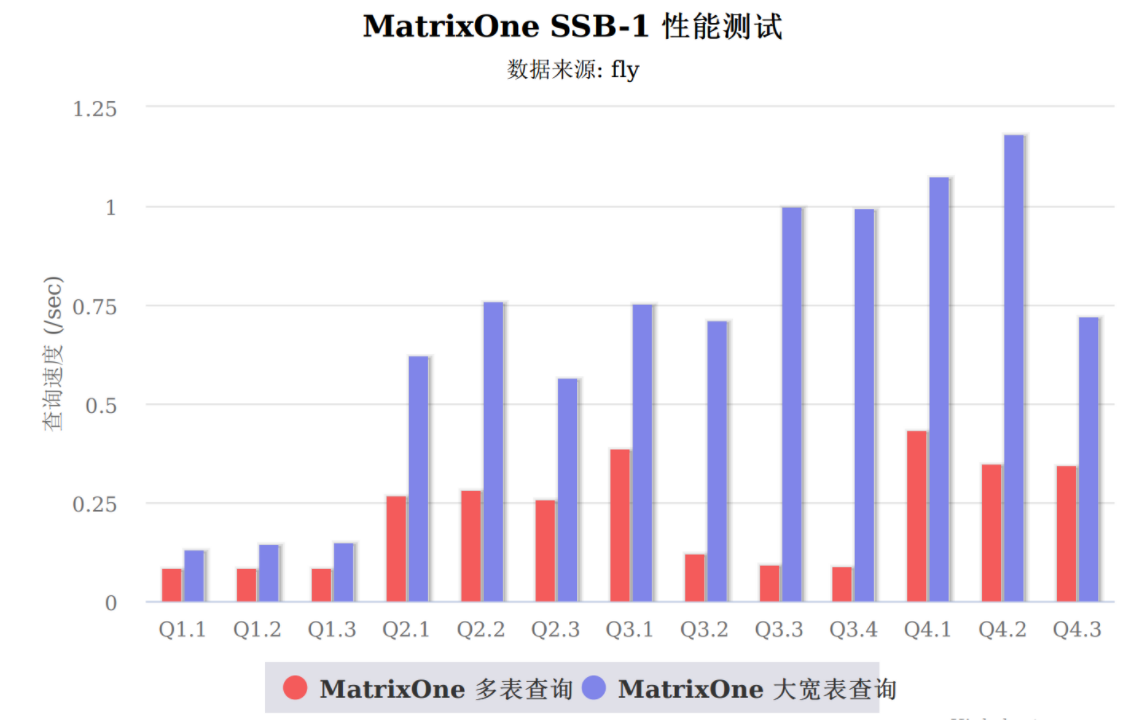
出色的AP性能
我們內部在對比了tpch的性能測試後,由於業務場景需要,我們之前使用的是MongoDB作為我們的AP場景,MySQL做為TP場景,由於設備量逐漸增大,上報數據量大,MongoDB和MySQL已無法滿足AP、TP場景的性能要求,而MatrixOne即支持了TP,AP的性能表現還十分的優異,且AP業務可以和TP共用同一套框架。

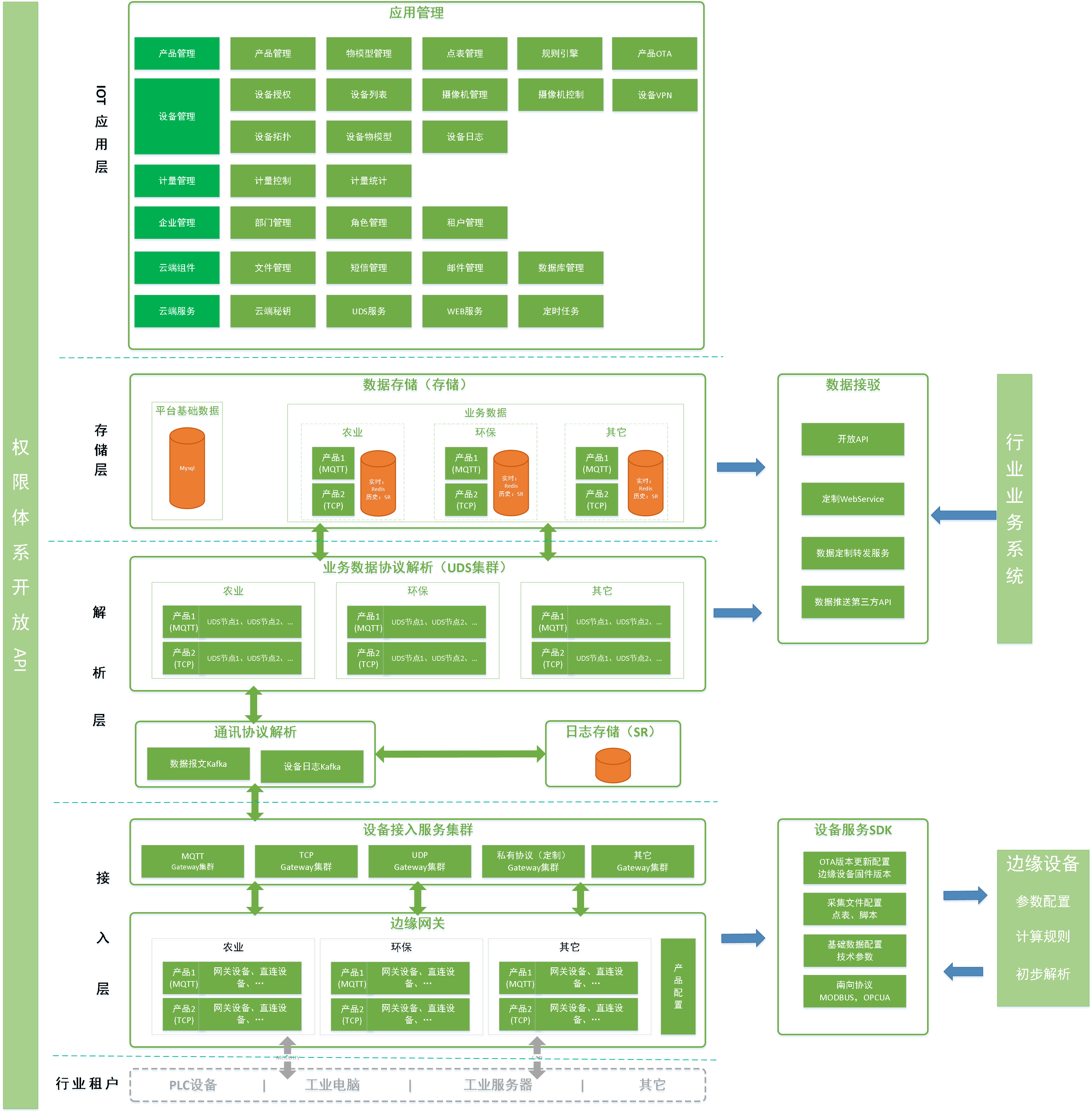
平臺改造
目前初步改造主要是統一TP和AP的場景,即將原來的MySQL和MongoDB更換為MatrixOne。而在原有的日誌解析的ES集群,期望MatrixOne在具備流式計算的功能之後,將整個數據解析層統一為MatrixOne,進而整個核心數據存儲計算基本全由MatrixOne對外提供服務。
下圖為我們平臺改造後的部分架構調整:

業務提升
-
成本優化
我們在測試環境充分測試後,逐步使用新的平臺架構,替換了部分客戶的私有雲物聯網平臺。最明顯的提升在於硬體資源得到了充分的利用。部分物聯網客戶平臺數據量並不是很大(數十億的數據總量),因而原有的架構 在ap場景會存在部分的資源浪費。在使用新的架構之後,我們相比較之前的架構,可以使用原來AP場景下MongoDB空閑時的硬體資源,來解決所有的場景問題,原有的架構需要大概5台低配 (16C + 32G ) + 3台高配 (64C + 128G)的伺服器資源,改造後,我們只需要3台高配的硬體資源即可,節省了大概5台的硬體資源成本。並且減少了系統之間的複雜度和數據的重覆冗餘,業務開發人員也只需要針對同一個核心資料庫進行業務編碼。
-
查詢優化
針對大數據量的場景下,相比較原有的MongoDB查詢速度,部分複雜查詢分鐘級別甚至更久的查詢速度,MatrixOne能夠優化至秒級別的響應,同時在測試環境下,我們對數十億級別的關聯查詢,MatrixOne相比較MongoDB表現的更加優異。
總結
在初步嘗鮮了MatrixOne之後,目前MatrixOne還存在一些問題,但是得益於優異的架構設計,和社區快速的反饋,我相信未來MatrixOne產品會越來越好,同時目前基於我們平臺,對於MatrixOne急需支持的有以下幾點:
-
流式計算的支持
要統一我們整個數據存儲計算,還需要目前將整個流式計算鏈路解放出來,目前我們還是使用Kafka + MongoDB的解決方案,這一塊的資源消耗較為嚴重,希望MatrixOne 可以先行提供流式數據接入的內嵌插件,替換我們目前的解決方案,完全去掉MongoDB。同時更希望,MatrixOne能夠集成完整的流式計算,不依賴於中間件,去掉Kafka集群和zk集群,進一步減少系統的複雜度。
-
分散式的支持
目前0.5.1的版本還不支持完全的分散式,0.6的版本會支持,我們希望來驗證一些更大數據集的業務場景。
-
機器學習的支持
目前我們分析平臺的機器學習還需要集成傳統的spark 框架,希望MatrixOne未來能夠支持機器學習的框架,並且能夠快速發佈訂閱機器學習的模型。
-
更豐富的數據類型導入支持
目前我們數據從統一gateway出口的數據為json,進入MatrixOne還需要人為進行一次解析,我們希望MatrixOne能夠支持更加豐富的數據接入模式,來應對物聯網場景複雜的數據源。
-
豐富的公有雲平臺支持
目前我們有眾多的大客戶使用的是公有雲服務體系,我們希望MatrixOne能夠上線更多的公有雲市場,避免我們目前部署還需要使用裸金屬伺服器,同時享受雲的優異特性。
未來展望
期望未來MatrixOne能夠讓我們平臺進化為如下架構:
HSTAP一體
- 設備端出來的原始二進位數據能夠直接通過各種協議,統一入口,進入到MatrixOne的流式引擎中
- 超大數據規模場景下優異的HSTAP性能,滿足大數據量下的實時寫入,更新,查詢的場景,優化緩存場景。。
- 能夠直接通過MatrixOne內部的多表延遲物化視圖、UDF等特性,通過SQL線上解析原始數據,並且落地到TP表或者AP表
- 所有的業務系統 由MatrixOne提供統一服務出口,提供業務服務
- MatrixOne內置機器學習框架,可以在平臺上集成多種不同語言的模型,進行機器學習SQL化開發