
我的Go併發之旅。本節介紹併發的基礎知識,上下文、原語、競爭條件、原子性、記憶體訪問同步、死鎖、併發與並行、併發哲學。 ...
註:本文所有函數名為中文名,並不符合代碼規範,僅供讀者理解參考。
上下文
上下文(Context)代表了程式(也可以是進程,操作系統,機器)運行時的環境和狀態,聯繫程式整個生命周期與資源調用,是程式可以訪問到的所有資源的總和,資源可以是一個變數,也可以是一個對象的引用。
上下文切換
所謂的上下文切換(context switch),指的是發生進程調度(進程切換)時,內核(kernel)要把當前進程的狀態和數據保存起來以備以後使用,同時把之前保存的進程的相關狀態調出來,這樣新調度出來的進程才能運行。
原語
原語,一般是指由若幹條指令組成的程式段,用來實現某個特定功能,在執行過程中不可被中斷。
電腦是一門人造科學,因此真正意義上的“原語”(Primitive)是不存在的。操作系統層面上的“原語”(比如 write 之類的系統調用)對程式員來講的確是不可分割的最小單位,但是這些系統調用本身還是用好幾句彙編語句組成的(對於 Linux 來說是 C 語言)。可能有人要說到了機器代碼這一級就不能再分了,但事實上一條機器指令也是由好幾個組合邏輯信號構成的。同樣的道理,控制信號也不過是無數電子在器件內部漂移的結果。
因此定義“原語”的前提是觀察者所處的位置(上下文)。一旦規定了觀察者的位置和觀察的角度,比如就在操作系統的這層上,read,write,wait這些個系統調用自然就是最“原始”的辭彙,這也是為什麼“原語”會在操作系統中頻繁出現的緣故。
上下文也可以被定義為一個操作被認為是原子性的界限。
競爭條件
兩個或多個操作必須按正確的順序執行,而程式並未保證這個順序,就會發生競爭條件。
大多數情況下,競爭條件會出現在數據競爭中,一個併發操作嘗試讀取一個變數,而在某個不確定的時間,另一個併發操作視圖寫入同一個變數。因為開發人員總是用順序性的思維來思考問題,他們總假設某行代碼會先於另一行代碼執行。
func 競爭條件() {
var data int
go func() {
data++
}()
if data == 0 {
fmt.Println("Value", data)
}
}
在這段代碼中會出現三種可能性,可以根據 go程(goroutine)、if判斷、列印輸出執行的順序判斷。
- if、列印、go程 => Value 0
- if、go程、列印 => Value 1
- go程、if => 跳過列印,無輸出
僅僅幾行代碼就給程式帶來了巨大的不確定性。
有時,某些程式員會寫出一種看似解決了問題的“方案”,就是添加 time.Sleep,但是這種方案並不可靠!通過顯式休眠的方式只是在概率上增加了邏輯的正確性,但不會真正變成邏輯上的正確。休眠時間也會影響程式的運行效果!
原子性
某些東西被認為是原子的,或者具有原子性的時候,這意味著在它運行的環境中,它是不可分割或不可中斷的。在你所定義的上下文中,原子的東西將被完整的運行,在這種情況下不會同時發生任何事情。
在考慮原子性時,經常第一件需要做的事就是定義上下文或範圍,然後再考慮這些操作是否是原子性的。
當一個東西是原子的,說明它在併發環境中是安全的。而大多數語句不是原子的,更不用說函數、方法和程式了,所以為了構建邏輯正確的程式,需要我們做記憶體訪問同步,使用一系列操作來強制保持原子性。
記憶體訪問同步
臨界區:程式中需要獨占訪問共用資源的部分。(可以理解成讀寫共用資源的代碼段)
正如前面的例子,保護程式臨界區的一個方法是在臨界區之間記憶體訪問做同步。具體做法是添加一個互斥鎖。
func 競爭條件_互斥鎖() {
var lock sync.Mutex
var data int
go func() {
lock.Lock()
data++
lock.Unlock()
}()
lock.Lock()
if data == 0 {
fmt.Println("Value", data)
} else {
fmt.Println("Value", data)
}
lock.Unlock()
}
如果你發現你的代碼中有臨界區,那就添加互斥鎖,保證各個臨界區對共用資源(data)的獨占訪問權,從而對記憶體的訪問進行了同步。但這僅僅解決了數據競爭,沒有解決競爭條件 !這種方式同步對記憶體的訪問有性能上的問題。
死鎖
所有併發進程彼此等待。
活鎖
正在主動執行併發操作的程式,但無法向前推進程式狀態。
饑餓
在任何情況下,併發進程都無法獲得執行工作所需的所有資源
通常意味著有一個或多個貪婪的併發進程,不公平地阻止(貪婪地搶占鎖,以完成整個工作迴圈(通常是不必要地擴大其持有共用鎖上的臨界區))一個或多個併發進程以儘可能有效地完成工作。
饑餓也可能產生於 CPU、記憶體、文件句柄、資料庫連接,任何必須共用的資源都是有可能產生饑餓的原因。
找到同步訪問記憶體的平衡點
同步訪問記憶體代價是昂貴的,所以將鎖擴展到臨界區外是有利的,但是會產生前面的饑餓問題。
需要在粗粒度和細粒度同步之間找到一個平衡點。
一般經驗是將記憶體訪問同步限制在關鍵部分,不擴展到臨界區外;直到同步成為性能問題,再擴展範圍。
給併發函數註釋
- 誰負責併發,是調用者負責,還是函數自己負責。
- 如何利用併發原語解決這個問題的。比如遞歸調用。
- 誰負責同步,調用者負責記憶體訪問同步還是結構體內部處理。
函數可以採用純函數式方法,儘可能消除同步的問題。
函數最好返回一個只讀的channel,而不是傳入參數的指針,這樣更具有明確性。
併發與並行
併發屬於代碼,並行屬於一個運行中的程式的屬性。
並行的"同時"是同一時刻可以多個進程在運行(處於running),併發的"同時"是經過上下文快速切換,使得看上去多個進程同時都在運行的現象,是一種OS欺騙用戶的現象。
實際上,當程式中寫下多進程或多線程代碼時,這意味著的是併發而不是並行。併發是因為多進程/多線程都是需要去完成的任務,不並行是因為並行與否由操作系統的調度器決定,可能會讓多個進程/線程被調度到同一個CPU核心上。只不過調度演算法會儘量讓不同進程/線程使用不同的CPU核心,所以在實際使用中幾乎總是會並行,但卻不能以100%的角度去保證會並行。也就是說,並行與否程式員無法控制,只能讓操作系統決定。
CSP
通信順序進程。一個進程的輸出應該直接流向另一個進程的輸入。
Go魅力
一般編程語言會把它們的抽象鏈結束在系統線程和記憶體訪問同步的層級。
但是Go語言採取了不同的路線,使用goroutine和channel代替這些概念。goroutine把我們從必須按照並行的思考方式中解放出來,作為替代,他允許我們按照更為自然的等級對問題進行建模。Go語言的運行時自動地將goroutine映射到系統的線程上,併為我們管理它們之間的調度(智能分配OS線程)。
Go併發哲學
不要通過共用記憶體進行通信,通過通信來共用記憶體。在面對不同場景時,選擇不同的方式。
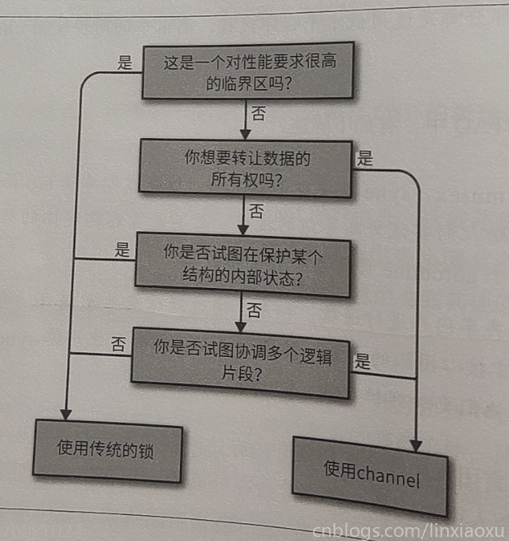
數據所有權:併發程式安全就是保證同時只有一個併發上下文擁有數據的所有權,通過channel可以把數據傳遞給其他go程,解耦生產者和消費者。
追求簡潔,儘量使用channel,並且認為goroutine的使用是沒有成本的。
參考書籍
-
《Go語言併發之道》Katherine CoxBuday
-
《Go語言核心編程》李文塔
-
《Go語言高級編程》柴樹彬、曹春輝


