
前言 嗨嘍~大家好呀,這裡是魔王吶 ! 開發環境以及模塊的使用: python 3.6 pycharm requests >>> pip install requests os 內置模塊 不需要安裝的 整體流程: 代碼 import requests # 第三方模塊 pip install requ ...
前言
嗨嘍~大家好呀,這裡是魔王吶 !

開發環境以及模塊的使用:
-
python 3.6
-
pycharm
-
requests >>> pip install requests
-
os 內置模塊 不需要安裝的
整體流程:
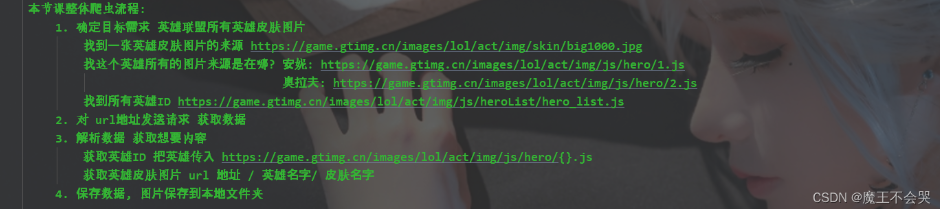
代碼
import requests # 第三方模塊 pip install requests
import pprint # 格式化輸出的模塊 在列印json的數據的時候,可以更加方便 查看數據信息
import os # 內置模塊 不需要安裝 自帶的
import re # 內置模塊 不需要安裝

數據集、源碼、解答加Q君羊:926207505 點擊藍字加入【python學習裙】

def change_title(title): mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]') new_title = re.sub(mode, '_', title) return new_title def save(title, name, img_url): # 我想要把每個英雄皮膚圖片,單獨保存在一個文件裡面 filename = f'img\\{title}\\' # 自動創建文件夾 # 如果沒有這個文件夾 / 沒有這個路徑 那麼就創建這個文件夾 if not os.path.exists(filename): os.mkdir(filename) # 獲取圖片內容,是要獲取它一個二進位數據內容 # 文本數據 response.text json數據 response.json() 二進位數據 response.content img_content = requests.get(url=img_url, headers=headers).content with open(filename + name + '.jpg', mode='wb') as f: f.write(img_content) print(name) response = requests.get(url=url, headers=headers) # pprint.pprint(response.json()) # 解析數據 獲取 英雄ID # json數據提取數據 和 字典類似 根據關鍵字提取值 通俗的講 根據冒號左邊的內容 提取冒號右邊的內容 hero_list = response.json()['hero'] # 返回的數據內容 是列表形式 # 通過遍歷/for 迴圈 提取它每一個英雄ID lis = [] for index in hero_list: hero_id = index['heroId'] lis.append(hero_id) # 字元串 格式化方法 # 對英雄的皮膚數據 url地址 發送請求 獲取英雄皮膚圖片數據 lis = lis[27:]

# pprint.pprint(response_1.json()) # 解析數據 獲取英雄皮膚url地址/英雄名字/皮膚名字 skins = response_1.json()['skins'] for index_1 in skins: # 皮膚圖片地址 img_url = index_1['mainImg'] # 英雄名字 title = index_1['heroTitle'] # 皮膚名字 name = index_1['name'] new_name = change_title(name) new_title = change_title(title) if img_url: save(new_title, new_name, img_url) else: chroma_img = index_1['chromaImg'] save(new_title, new_name, chroma_img)
效果











尾語
要成功,先發瘋,下定決心往前沖!
學習是需要長期堅持的,一步一個腳印地走向未來!
未來的你一定會感謝今天學習的你。
—— 心靈雞湯
本文章到這裡就結束啦~感興趣的小伙伴可以複製代碼去試試哦


