
摘要:《Index Checkpoints for Instant Recovery in In-Memory Database Systems》是由華為雲資料庫創新Lab一作發表在資料庫領域頂級會議VLDB'2022的學術論文。 本文分享自華為雲社區《VLDB'22 HiEngine極致RTO論文 ...
摘要:《Index Checkpoints for Instant Recovery in In-Memory Database Systems》是由華為雲資料庫創新Lab一作發表在資料庫領域頂級會議VLDB'2022的學術論文。
本文分享自華為雲社區《VLDB'22 HiEngine極致RTO論文解讀》,作者:雲資料庫創新Lab 。
1. HiEngine簡介
HiEngine是華為雲自研的一款面向雲原生環境的OLTP型資料庫, HiEngine在標準TPC-C事務模型下, 端到端單節點(華為2488H V5機型)性能可以達到663w+的tpmC, 多節點擴展性線性度超過0.8。 其核心架構關鍵詞如下:
- 計算,記憶體,存儲三層分離式雲原生架構
- 華為雲原生的分散式記憶體資料庫
- 同時包含分離式記憶體池和分離式存儲池
具體HiEngine詳細的技術架構和性能表現,可以參考我們團隊發表在SIGMOD2022 [1]的論文工作。
2. HiEngine對日誌恢復的優化
此外, HiEngine還擁有極致的RTO恢復性能,在100GB數據集下,可以達到10s級別的恢復時間。 本文將詳細闡述HiEngine在追求極致RTO過程中提出的若幹技術。
2.1 記憶體資料庫的經典恢復流程
回溯學術界現有的工作, 我們可以把記憶體資料庫的恢復大體劃分為幾大步驟:
- STEP1: 載入最近一次成功執行的元組檢查點數據;
- STEP2: 回放檢查點到故障點期間的日誌數據;
- STEP3: 掃描元組數據,重建記憶體索引結構;
我們團隊充分結合HiEngine架構的特點和學術界State of the art的一些工作, 提出了結合HiEngine Indirection array結構特點的dataless checkpoint和indexed logging恢復技術。 因此需要首先介紹一下什麼是HiEngine的Indirection array。
2.2 Indirection Array
與大多數工業/學術系統一般, HiEngine內部採用多版本的方式維護Tuple元組數據, 並且Tuple並沒有按頁面進行組織,而是按照版本鏈的方式組織。 每個邏輯元組用一個全局唯一的RowID標識, 所有的RowID以一個全局的數組進行組織, 該數組我們姑且稱作Indirection Array。 並且, HiEngine索引中每個葉子節點存儲的是RowID而不是具體的tuple address。
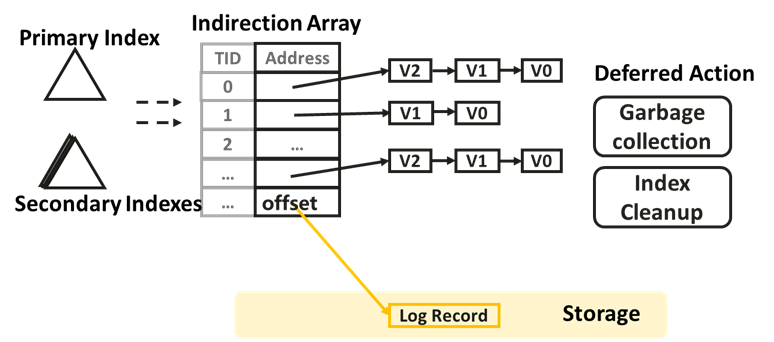
Indirection Array的設計有如下幾點好處:
- 更新操作不用修改索引;
- 非唯一索引可以通過添加RoWID尾碼轉換為唯一索引;
- 記憶體元組和日誌記錄統一編址, Indirection Array中存放的address既可以是記憶體元祖的頭指針地址, 也可以是record對應的log record的offset地址;
- Indexed-Logging;
- Dataless Checkpoint;
下一章節我們將對Indexed logging和Dataless checkpoint展開描述。
2.3 Indexed-logging
HiEngine繼承了"the log is the database"日誌即資料庫的概念, 具體來說Indirection Array中存放的地址既可以是記憶體的tuple,也可以是一個對應在記憶體中的log offset。 (我們使用uint64的最高一個bit標識是記憶體地址還是磁碟偏移。 因為對於64bit的操作系統的指針高12bit都為0)。
另一方面, 多版本系統在恢復後, 只需要恢復最新版本的數據即可, 因為舊版本的數據在系統重啟後對事務不再可見。 因此, 在系統一旦故障時, HiEngine只需要並行掃描日誌流, 把對應的log record的offset偏移設置到Indirection array的對應位置即可。 註意這一過程中還可以對多個日誌流採用並行掃描和並行設置log offset的方式加速。
一旦系統恢復時,把最新版本的log offset設置到對應的Indirection Array的TID位置後。 HiEngine系統即可開始工作, 對於首次訪問到某一TID時, 系統會載入offset位置的record, 線上生成一個新版本的tuple數據。 我們稱作為bringOnline Lazily。
並且在系統運行期間, HiEngine可以識別冷Tuple數據, 對Tuple數據進行凍結並轉存成log record, 同時修改對應RoWID的address為log record的offset
2.4 Dataless checkpoint
檢查點執行的頻率決定了需要恢復的日誌量的上限, 因此為了追求儘可能快的恢復時間, 檢查點執行的頻度必須得高。 這就對檢查點演算法本身提出了更高的性能需求:(1) 單次檢查點執行時間必須要快; (2) 檢查點不能導致前端事務性能明顯的抖動;
因為記憶體元組支持多版本的優勢, 可以極其容易獲取事務一致性的快照數據, 常規的檢查點演算法是獲取該快照數據並對快照存檔。 但常規的方式必然導致需要存檔的快照數據量大, 進而導致checkpoint時間較長。
而HiEngine的做法不甚相同, (1) HiEngine在事務預提交階段, 把存檔日誌的offset反向回填到對應tuple數據的header中存放。 (2) 因此在Checkpoint獲取事務一致性快照後, 並不是把快照中的tuple數據存檔, 而是把對應tuple header中的offset進行持久化, 並且以一個序列化的Indirection Array存檔。
總結: HiEngine這種將快照對應的log offset存檔的checkpoint方法叫做DataLess Checkpoint, 其相比於對快照進行存檔的方式, 需要序列化存檔的數據量少, 對前端事務影響的時間也更短, 恢復時載入檢查點的時間也更短。
2.5 階段性優化與遺留瓶頸
Indexed Logging和Dataless checkpoint只是解決了章節2.1提到的STEP1和STEP2的性能瓶頸, 這也是當下很多學術工作關註的優化重心。 我們通過實驗對比, 在百GB規模的TPCC數據集下, 沒採用Indexed logging和Dataless checkpoint技術的恢復時間在310s左右, 採用了Indexed logging和Dataless checkpoint技術後,可以把恢復時間減少到50+ s。
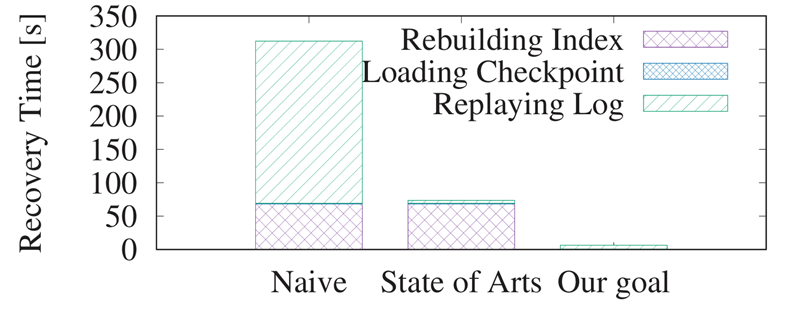
但是50+ s離HiEngine期望的目標仍有距離, 因此我們的工作重心需要聚焦到如何優化STEP3中索引重建的時間, 進一步追求極致的RTO時間目標。
3. HiEngine對索引恢復的優化
3.1 索引檢查點的必要性
首先, 需要指出的是元組數據可以通過載入檢查點並回放日誌的方式得以恢復, 但索引數據則需要重建的方式才能得以恢復。
必要性: 主要原因在於索引並沒有檢查點, 如果索引也存在索引檢查點數據, 索引數據的恢復也可以載入索引檢查點數據, 然後通過重做insert和delete的log record恢復checkpoint之後的index索引項。
因此巨集觀朴素的想法是通過索引檢查點對HiEngine索引重建的耗時問題進行優化。 但是:
(1) 索引本身並不支持多版本, 因此無法無阻塞的獲取事務一致性的快照數據。 換句話說, 索引檢查點必然是模糊Fuzzy類型的檢查點。
(2) 而HiEngine的日誌只有redo沒有undo, 如何保證恢復出來的數據沒有臟數據,並且不丟失索引項。 總之, 如何保證數據的正確性。
(3) 並且由於索引不支持快照隔離, 如何無阻塞的獲取索引檢查點也是一項重要的性能問題。VLDB這篇論文針對正確性和性能兩個維度展開討論HiEngine的索引檢查點。
3.2 索引檢查點的正確性
我們通過一個示例展示, HiEngine如何保證檢查點數據的正確性。
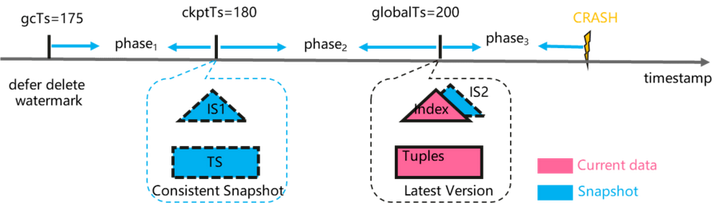
如圖所示, 我們假設存在一個理想化的演算法能夠獲取快照隔離級別並且事務一致性的索引檢查點數據, 對應的元組檢查點和快照檢查點分別標識為TS和IS1。 此種情況數據元祖檢查點和索引檢查點獲取的都是時間戳在180時刻的事務一致性的快照數據, 恢復後很容易保證數據的正確性。
但是現實的情況是索引只能"嘗試"捕獲當前觸發檢查點時刻的數據, 此時在索引中必然存在尚未提交事務的索引項, 因此捕獲到的檢查點數據必然是非事務一致的, 或者說是模糊的(Fuzzy checkpoint)。 我們用IS2標識。
對比IS1和IS2可以發現, IS2相比於IS1差異的索引項是來自於phase2階段的操作。 前文已經說過, 因為Indirection array的設計, update操作不會修改索引, 因此我們需要針對insert和delete操作提出數據正確性保證的措施:
(1) 插入操作: 對於在phase2階段的插入操作, 一旦系統恢復時載入檢查點後, 我們應該能識別出phase2節點插入的臟數據。 因為tuple數據是可以保證事務一致性和數據正確性的。 在系統訪問index時,我們需要對index和對應tuple不匹配的索引認定為"臟數據", 並觸發補償性刪除動作, 同時給客戶端返回不存在該索引項。
(2) 刪除操作: 對於在phase2階段刪除的索引項, 因為恢復時只回放檢查點之後日誌, 該索引項必將在恢復後丟失lost了。 因此我們應該需要阻止phase2階段的index刪除動作的執行。 剛好, HiEngine和很多MVCC系統一樣, delete當做是交給GC模塊延後執行的。 我們只需要確保gc的watermark在檢查點觸發時滯後於checkpoint時間戳即可。也就是說 gc timestamp = min{minStartTs-1, minEndTs-1}。 詳細可以翻閱論文。
3.3 索引檢查點的性能目標
上一章節, 我們通過"恢復後識別並刪除臟索引數據"和"阻止滯後gc"的方式能夠保證的正確性, 但如何保證索引檢查點的性能仍是一個問題。
朴素的想法是停掉前端事務並複製索引數據, 但這肯定會導致很長時間的阻塞。 因此, 我們首先給出一個優化的索引檢查點演算法應該滿足一下4個條件:(1) Wait Free processing; (2) Efficient index operations; (3) Fast and frequent checkpoints; (4) Load friendly checkpoint file format。 具體對性能需求的描述, 可以查閱我們的論文。 並且, 我們提出了三種Index checkpoint的演算法。
3.4 ChainIndex
ChainIndex通過多顆物理索引樹維護一個邏輯索引, 其按照每次checkpoint產生一個新的索引樹的方式產生一顆新的索引樹, 索引樹組織成一個鏈表的形式, 鏈表頭的索引作為寫入索引, 維護一個檢查點周期內的增量索引樹。 非鏈表頭的索引樹都作為只讀結構存儲。 並且ChainIndex會在後臺合併若幹個delta樹。
檢查點過程: 在每次檢查點執行觸發時, HiEngine首先凍結鏈表頭的索引樹, 與此同時原子性產生一個新的索引結構用於接受新啟動事務的索引修改操作。 對於尚未結束的索引操作仍然寫入到凍結的索引樹, 待所有尚未提交的索引操作結束後, 我們採用後序遍歷的方式產生一個mmap友好的checkpoint文件。
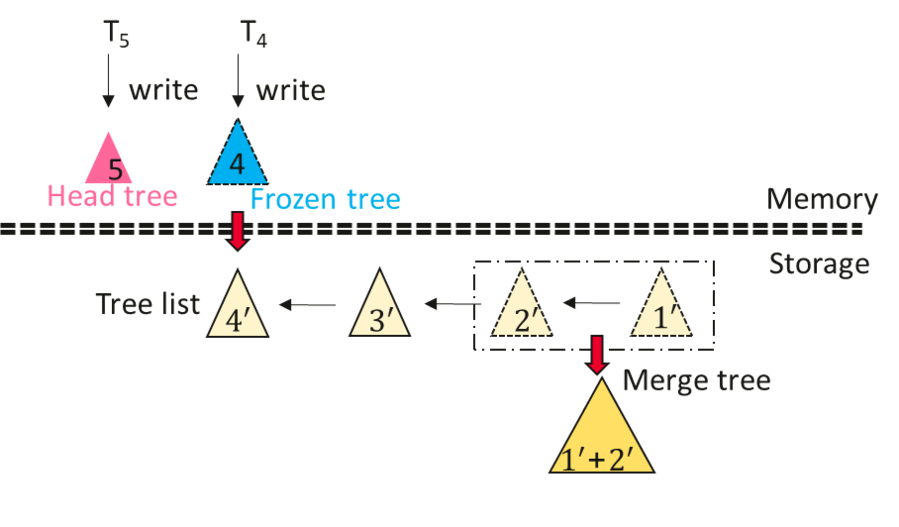
恢復過程: 每次恢復時HiEngine只需通過mmap的方式載入checkpoint文件; 然後, 回放日誌恢復checkpoint之後的索引項。
總結: ChainIndex總體架構啟發來自於LSM, 對寫操作友好, 但(1)存在嚴重的讀放大問題。 (2) 並且ChainIndex只支持增量檢查點,不支持全量檢查點。
3.5 MirrorIndex
MirrorIndex在ChainIndex的基礎上, 通過引入一個額外的full tree或者說是mirror tree, 從而解決ChainIndex的讀放大缺點。 其在每一次insert或delete時, 同時對headTree和mirror tree進行修改, 可以確保headtree包含一個檢查點周期的增量數據, mirror tree包含全量數據。 因此, 讀操作直接訪問mirror index即可。
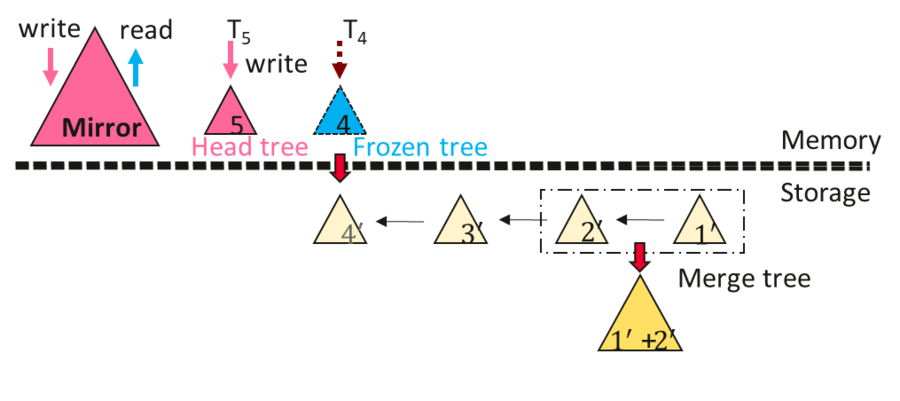
MirrorIndex的checkpoint流程和ChainIndex一樣。 但恢復流程有很大不同。 其恢復流程如下
- mmap映射增量檢查點文件到記憶體中
- 回放日誌恢復headTree的數據
- 步驟2完成後, 系統便可以接受服務了,但此時性能表現和ChainIndex類似, 有嚴重的讀放大問題。 與此同時, HiEngine觸發後臺rebuild mirror index的過程, 待mirrorIndex重建完成後, 讀放大問題消失
總結: MirrorIndex相比ChainIndex消除了讀放大的問題, 但卻(1)存在一定的讀放大。 (2)並且MirrorIndex需要引入額外的樹結構, 記憶體占用很多。 (3) MirrorIndex只支持增量檢查點。(4)恢復後,有一個短暫的性能"爬坡"階段。
3.6 Indirection Array CoW
ChainIndex和MirrorIndex總體思想都是採用delta數據的思想,維護增量檢查點。 另一大類的策略是採用Copy On Write的思想, 針對樹結構的CoW演算法是Path Copying, 其修改拷貝節點時會導致父節點的指針發生修改, 從而導致級聯修改。 這會導致性能下降很多, 並且路徑拷貝會導致索引併發的lock free演算法需要適配, 工作量大。
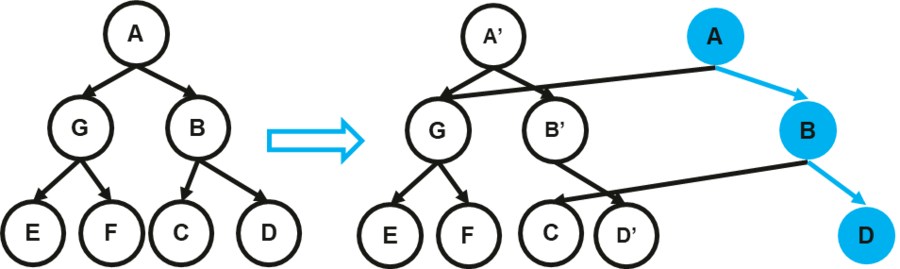
因此我們放棄了Path Copying的策略, 通過引入Indirection array的方式引入"邏輯索引節點"的概念, 從而消除級聯拷貝的問題。 IACoW對每個index node分配一個唯一的node ID, 並且parent node的child pointer存放的不在是記憶體指針地址, 而是修改為子節點的node id, 此時修改拷貝節點時不需要修改父節點指針。
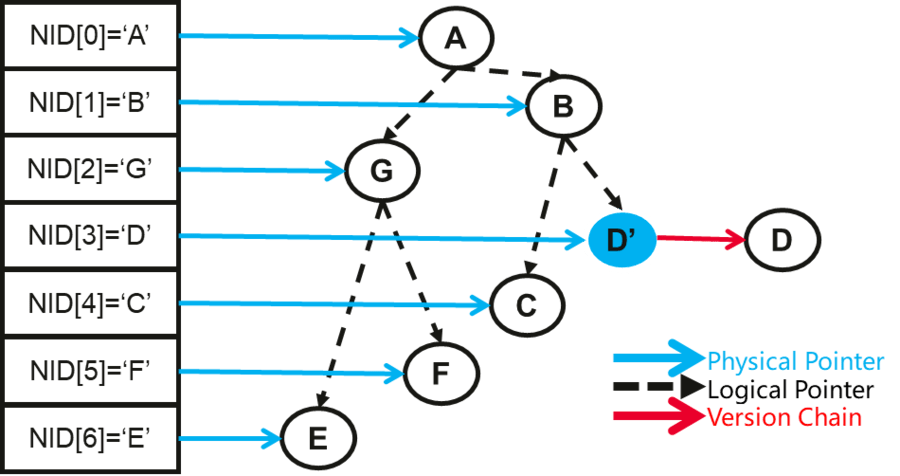
另外我們引入checkpoint epoch number來識別index node的新舊版本。 具體來說, 每次checkpoint全局epoch自動加一, 不同checkpoint周期因為copy on write產生的新版本用不同epoch number標識。 checkpoint執行流程中, 我們通過掃描Indirection array, 並根據epoch number可以捕獲增量和全量兩種類型的檢查點數據。 恢復時, 通過mmap的方式即可恢復checkpoint數據。 具體的node版本管理, node的gc以及checkpoint數據組織形式等細節問題,可以查閱論文。
總結: IACoW同時支持增量和全量檢查點, 並且IACoW引入的額外記憶體並不多。 但是IACoW會因為pointer chasing導致少許讀放大。
4. HiEngine恢復性能評估
實驗過程中, 我們首先評估checkpoint對性能抖動的影響, 結果展示MirrorIndex和IACoW在checkpoint期間性能影響並不大, 但ChainIndex由於讀放大問題性能抖動嚴重。

同時我們測試了在相同配置下, 不同演算法的恢復時間。 結果顯示在異常下點時, IACoW可以保證在10s的時間內完成恢復。
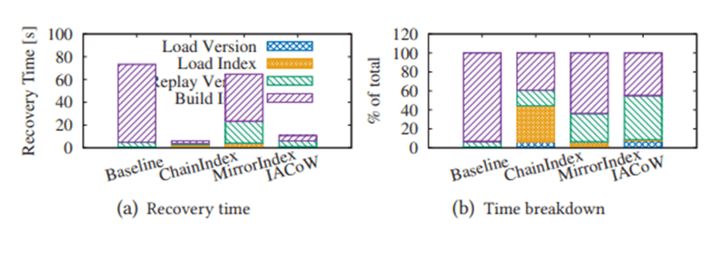
在正常下電時, IACoW可以保證在2s的時間內完成恢復。
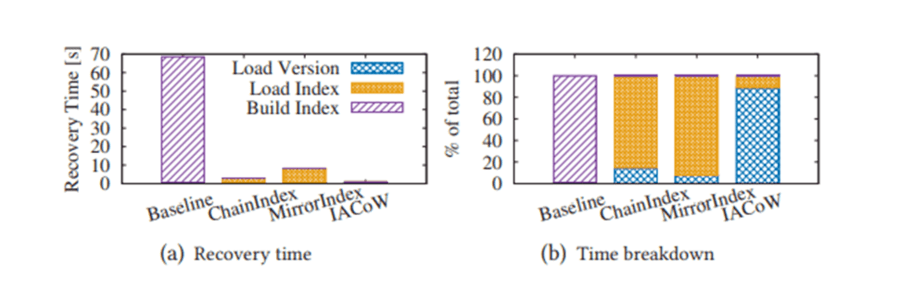
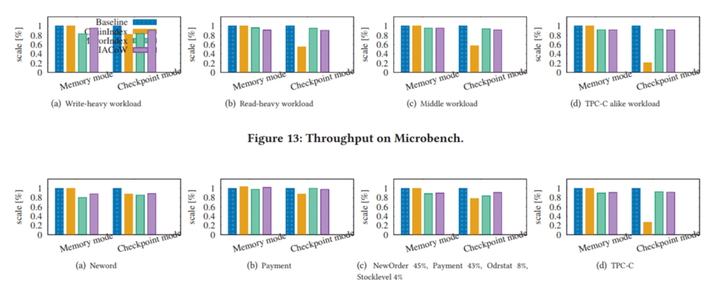
並且我們在TPC-C和microbench負載下, 實驗反應MirrorIndex和IACoW對端到端性能的影響在10%以內, 但卻可以換取10s級別的RTO保障。
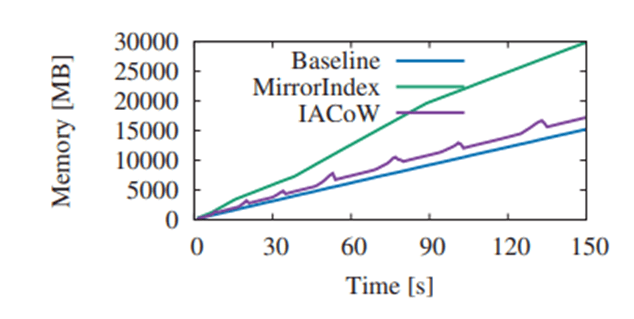
我們在控制相同事務性能的前提下, 測試各自的索引記憶體空間開銷。 實驗表明, IACoW的額外記憶體開銷很小, 但MirrorIndex需要x2的記憶體開銷。
我們總結對比各種方案的優缺點如下:

5. 總結
論文首先發現記憶體資料庫的索引重建是一個性能瓶頸點, 並得到了評委們的一致認可, 摘錄VLDB Reviewers對論文的選題評價。
The authors observed that, in today’s systems, the performance bottleneck in recovery is in restoring indexes. This is a cute observation which I consider important to the system community.
Overall, it is an important contribution to point out index restoration as the new performance bottleneck - I wasn’t aware of this before.
As the techniques have been improved with database recovering, this work claims that index rebuilding becomes a bottleneck of in-memory database recovering. This observation is very interesting, and it motivates the need of fast index recovering (instead of fast index reconstruction).
針對索引重建的瓶頸點, 本文探討了索引正確性的保證,並提出了3個索引檢查點演算法。 最終在端到端的HiEngine系統中,對比評估了各自的優缺點。 實驗結果表明, IACoW演算法在100GB規模下可以達到10s級的恢復時間, 對於有極致RTO需求的場景, 可以引入該演算法提速恢復。
參考文獻:
[1] Yunus Ma, Siphrey Xie, Henry Zhong, Leon Lee, and King Lv. 2022. HiEngine: How to Architect a Cloud-Native Memory-Optimized Database Engine. In Proceedings of the 2022 International Conference on Management of Data (SIGMOD '22). Association for Computing Machinery, New York, NY, USA, 2177–2190. https://doi.org/10.1145/3514221.3526043
展現領先科研實力,華為雲資料庫創新LAB三篇論文入選國際資料庫頂級會議VLDB'2022
華為雲資料庫創新lab官網:https://www.huaweicloud.com/lab/clouddb/home.html
We Are Hiring:https://www.huaweicloud.com/lab/clouddb/career.html ,簡歷發送郵箱:[email protected]
華為雲資料庫創新Lab 時序資料庫openGemini正式開源,開源地址:https://github.com/openGemini,誠邀開源領域專家加入!


