
蒼穹之邊,浩瀚之摯,眰恦之美; 悟心悟性,善始善終,惟善惟道! —— 朝槿《朝槿兮年說》 寫在開頭 提起Java領域中的鎖,是否有種“道不盡紅塵奢戀,訴不完人間恩怨“的”感同身受“之感?細數那些個“玩意兒”,你對Java的熱情是否還如初戀般“人生若只如初見”? Java中對於鎖的實現真可謂是“百花齊 ...
蒼穹之邊,浩瀚之摯,眰恦之美; 悟心悟性,善始善終,惟善惟道! —— 朝槿《朝槿兮年說》

寫在開頭

提起Java領域中的鎖,是否有種“道不盡紅塵奢戀,訴不完人間恩怨“的”感同身受“之感?細數那些個“玩意兒”,你對Java的熱情是否還如初戀般“人生若只如初見”?
Java中對於鎖的實現真可謂是“百花齊放”,按照編程友好程度來說,美其名曰是Java提供了種類豐富的鎖,每種鎖因其特性的不同,在適當的場景下能夠展現出非常高的效率。
但是,從理解的難度上來講,其類型錯中複雜,主要原因是Java是按照是否含有某一特性來定義鎖的實現,如果不能正確理解其含義,瞭解其特性的話,往往都會深陷其中,難可自拔。
查詢過很多技術資料與相關書籍,對其介紹真可謂是“模棱兩可”,生怕我們搞懂了似的,但是這也是我們無法繞過去的一個“坎坎”,除非有其他的選擇。
作為一名Java Developer來說,正確瞭解和掌握這些鎖的機制和原理,需要我們帶著一些實際問題,通過特性將鎖進行分組歸類,才能真正意義上理解和掌握。
比如,在Java領域中,針對於不同場景提供的鎖,都用於解決什麼問題?其實現方式是什麼?各自又有什麼特點,對應的應用有哪些?
帶著這些問題,今天我們就一起來盤一盤,Java領域中的鎖機制,盤點一下相關知識點,以及不同的鎖的適用場景,幫助我們更快捷的理解和掌握這項必備技術奧義。
關健術語

本文用到的一些關鍵詞語以及常用術語,主要如下:
- 線程調度(Thread Scheduling ):系統分配處理器使用權的過程,主要調度方式有兩種,分別是協同式線程調度(Cooperative Threads-Scheduling)和搶占式線程調度(Preemptive Threads-Scheduling)。
- 線程切換(Thread Switch ):主要是指在併發過程中,多線程之間會對上下文進行切換資源,並交叉執行的一種併發機制。
- 指令重排(Command Reorder ): 指編譯器或處理器為了優化性能而採取的一種手段,在不存在數據依賴性情況下(如寫後讀,讀後寫,寫後寫),調整代碼執行順序。
- 記憶體屏障(Memory Barrier): 也稱記憶體柵欄,記憶體柵障,屏障指令等, 是一類同步屏障指令,是CPU或編譯器在對記憶體隨機訪問的操作中的一個同步點,使得此點之前的所有讀寫操作都執行後才可以開始執行此點之後的操作。
基本概述
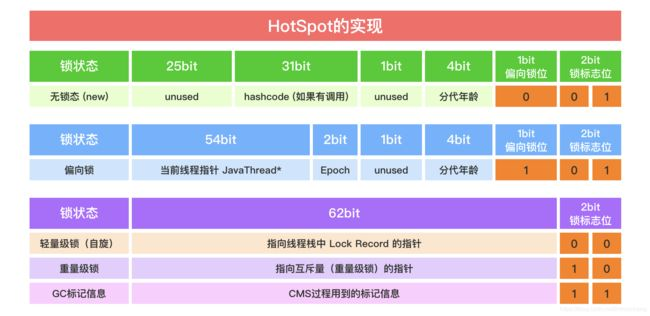
縱觀Java領域中“五花八門”的鎖,我們可以依據Java記憶體模型的工作機制,來具體分析一下對應問題的提出和表現,這也不失為打開Java領域中鎖機制的“敲門磚”。
從本質上講,鎖是一種協調多個進程 或者多個線程對某一個資源的訪問的控制機制。
一.電腦運行模型
電腦運行模型主要是描述電腦系統體繫結構的基本模型,一般主要是指CPU處理器結構。
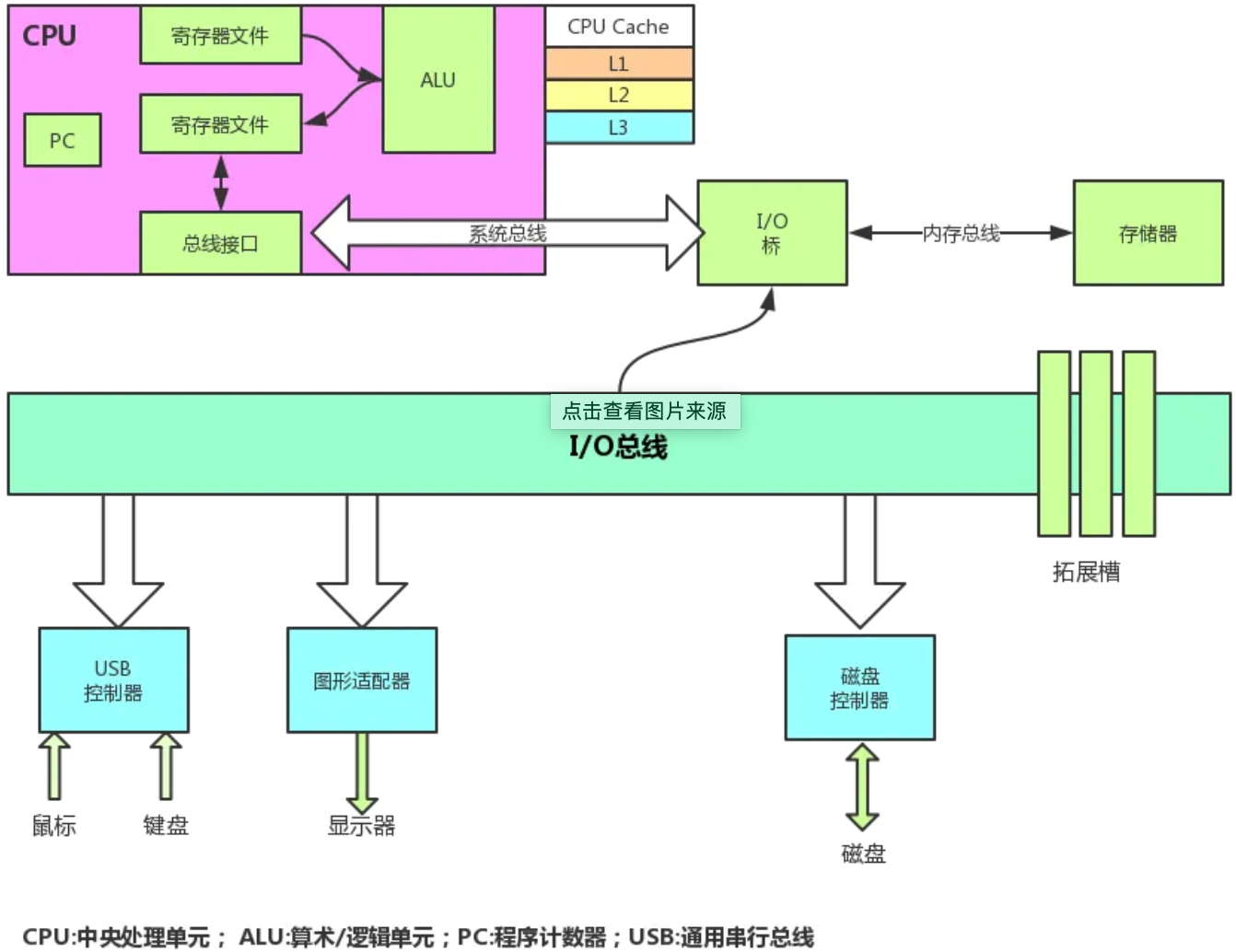
在電腦體繫結構中,中央處理器(CPU,Central Processing Unit)是一塊超大規模的集成電路,是一臺電腦的運算核心(Core)和控制核心( Control Unit)。它的功能主要是解釋電腦指令以及處理電腦軟體中的數據。
一個計算能夠運行起來,主要是依靠CPU來負責執行我們的輸入指令的,通常情況下,我們都把這些指令統稱為程式。
一般CPU決定著程式的運行速度,可以看出CPU對程式的執行有很重要的作用,但是一個電腦程式的運行快慢並不是完全由CPU決定,除了CPU還有記憶體、快閃記憶體等。
由此可見,一個CPU主要由控制單元,算術邏輯單元和寄存器單元等3個部分組成。其中:
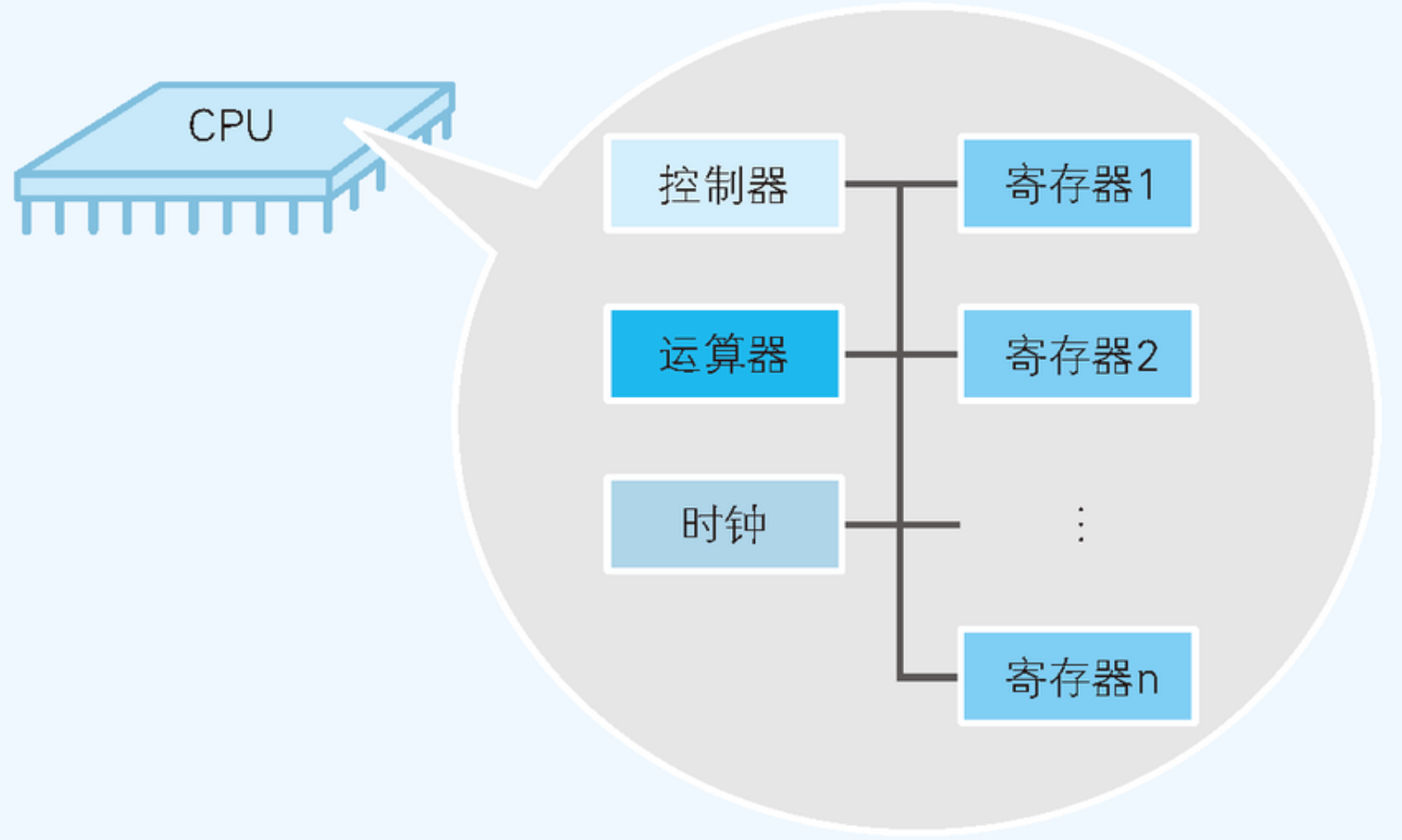
- 控制單元( Control Unit): 屬於CPU的控制指揮中心,主要負責指揮CPU工作,通過向算術邏輯單元和寄存器單元來發送控制指令達到控制效果。
- 算術邏輯單元(Arithmetic Logic Unit, ALU): 主要負責執行運算,一般是指算術運算和邏輯運算,主要是依據控制單元發送過來的指令進行處理。
- 寄存器單元(Register Unit): 主要用於存儲臨時數據,保存著等待處理和已經處理的數據。
一般來說,寄存器單元是為了減少CPU對記憶體的訪問次數,提升數據讀取性能而提出的,CPU中的寄存器單元主要分為通用寄存器和專用寄存器兩個種,其中:
- 通用寄存器:主要用於臨時存放CPU正在使用的數據。
- 專用寄存器:主要用於臨時存放類似指令寄存器和程式計數器等CPU中專有用途的數據。其中:
- 指令寄存器:用於存儲正在執行的指令
- 程式計數器: 保存等待執行的指令地址
簡單來說,CPU與主存儲器主要是通過匯流排來進行通信,CPU通過控制單元來操作主存中的數據。而CPU與其他設備的通信都是由控制來實現。
綜上所述,我們便可以得到一個電腦記憶體模型的大致雛形,接下來,我們便來一起盤點解析是電腦記憶體模型的基本奧義。
二.電腦記憶體模型
電腦記憶體模型一般是指計算系統底層與編程語言之間的約束規範,主要是描述電腦程式與共用存儲器訪問的行為特征表現。
根據介紹電腦運行模型來看,電腦記憶體模型可以幫助以及指導我們理解Java記憶體模型,主要在如下的兩個方面:
- 首先,系統底層希望能夠對程式進行更多的優化策略,一般主要是針對處理器和編譯器,從而提高運行性能。
- 其次,為編程語言帶來了更多的可編程性問題,主要是複雜的記憶體模型會有更多的約束,從而增加了程式設計的編程難度。
由此可見,記憶體模型用於定義處理器間的各層緩存與共用記憶體的同步機制,以及線程與記憶體之間交互的規則。
在操作系統層面,記憶體主要可以分為物理記憶體與虛擬記憶體的概念,其中:
- 物理記憶體(Physical Memory): 通常指通過安裝記憶體條而獲得的臨時儲存空間。主要作用是在電腦運行時為操作系統和各種程式提供臨時儲存。常見的物理記憶體規格有256M、512M、1G、2G等。
- 虛擬記憶體(Virtual Memory):電腦系統記憶體管理的一種技術。它使得應用程式認為它擁有連續可用的記憶體(一個連續完整的地址空間),它通常是被分隔成多個物理記憶體碎片,還有部分暫時存儲在外部磁碟存儲器上,在需要時進行數據交換。
一般情況下,當物理記憶體不足時,可以用虛擬記憶體代替, 在虛擬記憶體出現之前,程式定址用的都是物理地址。
從常見的存儲介質來看,主要有:寄存器(Register),高速緩存(Cache),隨機存取存儲器(RAM),只讀存儲器(ROM)等4種,按照讀取快慢的順序是:Register>Cache>RAM>ROM。其中:
- 寄存器(Register): CPU處理器的一部分,主要分為通用寄存器和專用寄存器。
- 高速緩存(Cache):用於減少 CPU 處理器訪問記憶體所需平均時間的部件,一般是指L1/L2/L3層高級緩存。
- 隨機存取存儲器(Random Access Memory,RAM):與CPU直接交換數據的內部存儲器,它可以隨時讀寫,而且速度很快,通常作為操作系統或其他正在運行中的程式的臨時數據存儲媒介。
- 只讀存儲器(Read-Only Memory,ROM):所存儲的數據通常都是裝入主機之前就寫好的,在工作的時候只能讀取而不能像隨機存儲器那樣隨便寫入。
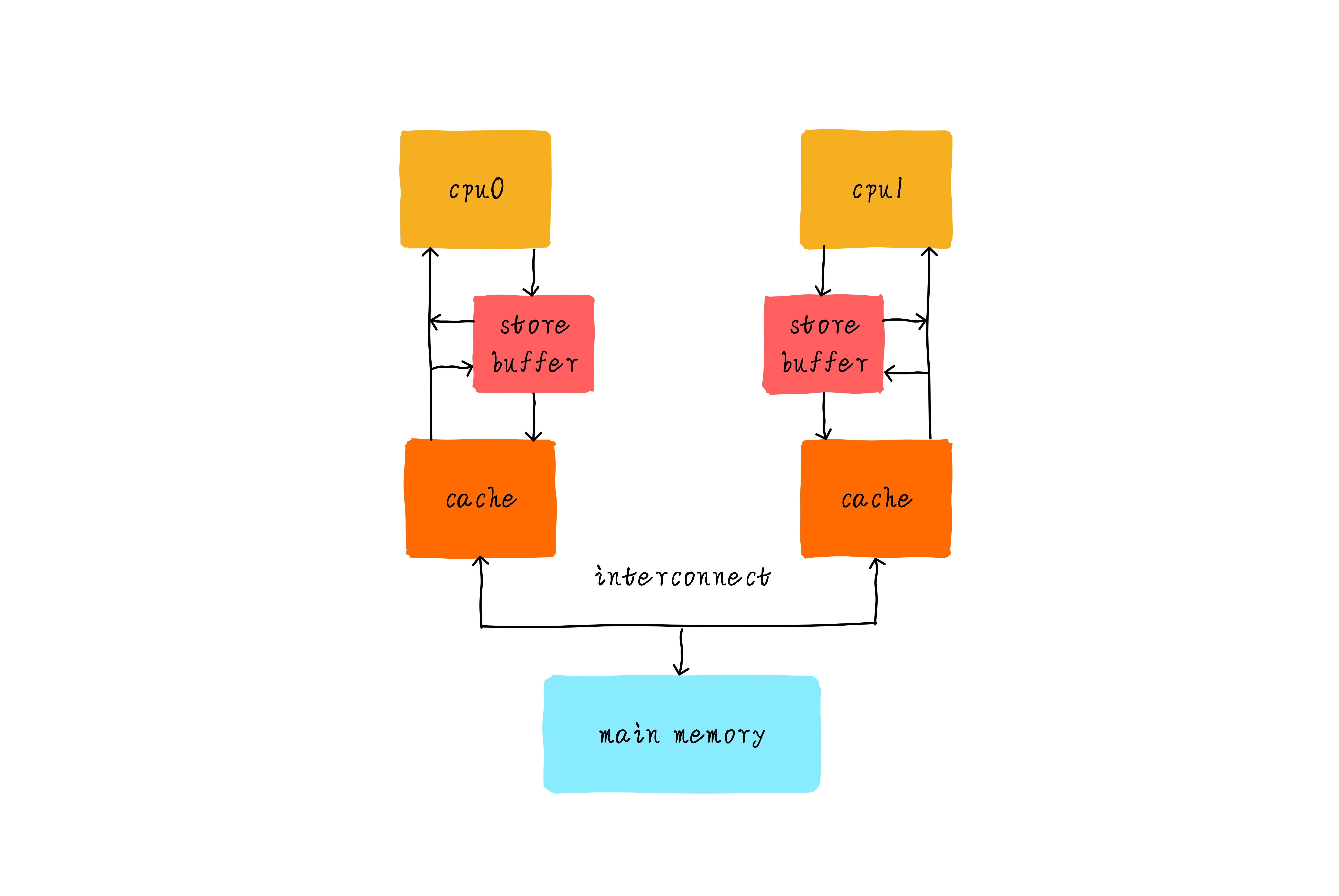
由於CPU的運算速度比主存(物理記憶體)的存取速度快很多,為了提高處理速度,現代CPU不直接和主存進行通信,而是在CPU和主存之間設計了多層的Cache(高速緩存),越靠近CPU的高速緩存越快,容
量也越小。
按照數據讀取順序和與CPU內核結合的緊密程度來看,大多數採用多層緩存策略,最經典的就三層高速緩存架構。
也就是我們常說的,CPU高速緩存有L1和L2高速緩存(即一級高速緩存和二級緩存高速),部分高端CPU還具有L3高速緩存(即三級高速緩存):
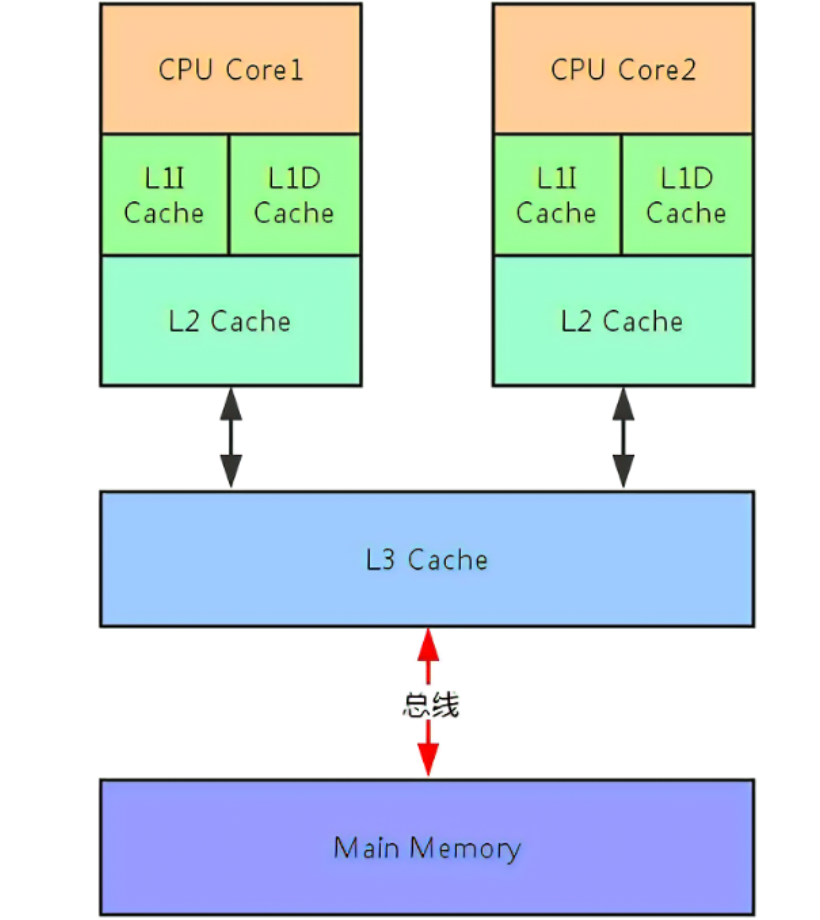
CPU內核讀取數據時,先從L1高速緩存中讀取,如果沒有命中,再到L2、L3高速緩存中讀取,假如這些高速緩存都沒有命中,它就會到主存中讀取所需要的數據。
每一級高速緩存中所存儲的數據都是下一級高速緩存的一部分,越靠近CPU的高速緩存讀取越快,容量也越小。
當然,系統還擁有一塊主存(即主記憶體),由系統中的所有CPU共用。擁有L3高速緩存的CPU,CPU存取數據的命中率可達95%,也就是說只有不到5%的數據需要從主存中去存取。
因此,高速緩存大大縮小了高速CPU內核與低速主存之間的速度差距,基本體現在如下:
- L1高速緩存:最接近CPU,容量最小、存取速度最快,每個核上都有一個L1高速緩存。
- L2高速緩存:容量更大、速度低些,在一般情況下,每個內核上都有一個獨立的L2高速緩存。
- L3高速緩存:最接近主存,容量最大、速度最低,由在同一個CPU晶元板上的不同CPU內核共用。
總結來說,CPU通過高速緩存進行數據讀取有以下優勢:
- 寫緩衝區可以保證指令流水線持續運行,可以避免由於CPU停頓下來等待向記憶體寫入數據而產生的延遲。
- 通過以批處理的方式刷新寫緩衝區,以及合併寫緩衝區中對同一記憶體地址的多次寫,減少對記憶體匯流排的占用。
綜上所述,一般來說,對於單線程程式,編譯器和處理器的優化可以對編程開發足夠透明,對其優化的效果不會影響結果的準確性。
而在多線程程式來說,為了提升性能優化的同時又達到兼顧執行結果的準確性,需要一定程度上記憶體模型規範。
由於經常會採用多層緩存策略,這就導致了一個比較經典的併發編程三大問題之一的共用變數的可見性問題,除了可見性問題之外,當然還有原子性問題和有序性問題。
由此來看,在電腦記憶體模型中,主要可以提出主存和工作記憶體的概念,其中:
- 主存:一般指的物理記憶體,主要是指RAM隨機存取存儲器和ROM只讀存儲器等
- 工作記憶體:一般指寄存器,還有以及我們說的三層高速緩存策略中的L1/L2/L3層高級緩存Cache等
在Java領域中,為瞭解決這一系列問題,特此提出了Java記憶體模型,接下來,我們就來一看看Java記憶體模型的工作機制。
三.Java記憶體模型
Java記憶體模型主要是為瞭解決併發編程的可見性問題,原子性問題和有序性問題等三大問題,具有跨平臺性。
JMM最初由JSR-133(Java Memory Model and ThreadSpecification)文檔描述,JMM定義了一組規則或規範,該規範定義了一個線程對共用變數寫入時,如何確保對另一個線程是可見的。
Java記憶體模型(Java Memory Model JMM)指的是Java HotSpot(TM) VM 虛擬機定義的一種統一的記憶體模型,將底層硬體以及操作系統的記憶體訪問差異進行封裝,使得Java程式在不同硬體以及操作系統上執行都能達到相同的併發效果。
Java記憶體模型對於記憶體的描述主要體現在三個方面:
- 首先,描述程式各個變數之間關係,主要包括實例域,靜態域,數據元素等。
- 其次,描述了在電腦系統中將變數存儲到記憶體以及從記憶體中獲取變數的底層細節,主要包括針對某個線程對於共用變數的進行操作時,如何通知其他線程(涉及線程間如何通信)
- 最後,描述了多個線程對於主存中的共用資源的安全訪問問題。
一般來說,Java記憶體模型在對記憶體的描述上,我們可以依據是編譯時分配還是運行時分配,是靜態分配還是動態分配,是堆上分配還是棧上分配等角度來進行對比分析。
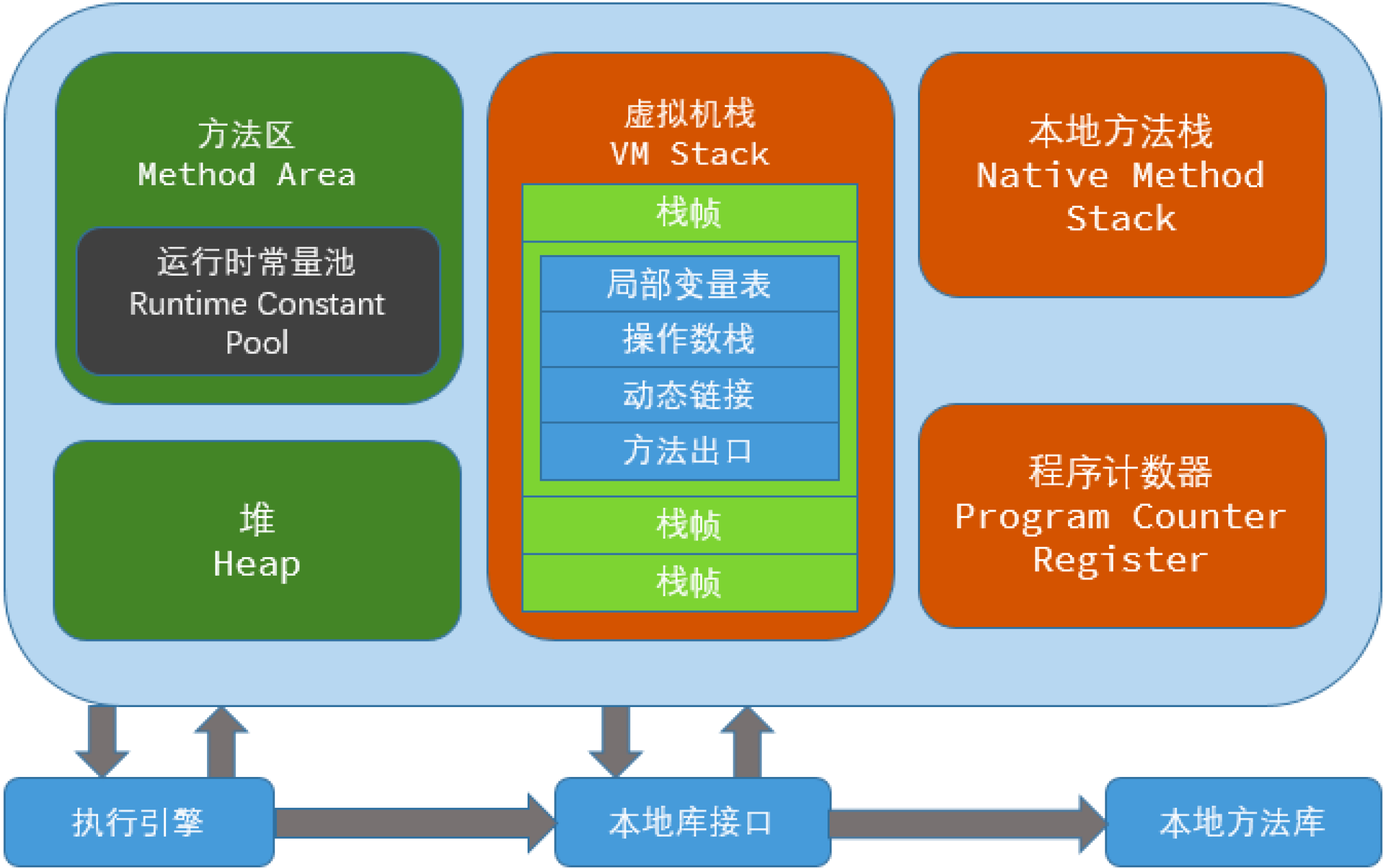
從Java HotSpot(TM) VM 虛擬機的整體結構上來看,記憶體區域可以分為線程私有區,線程共用區,直接記憶體等內容,其中:
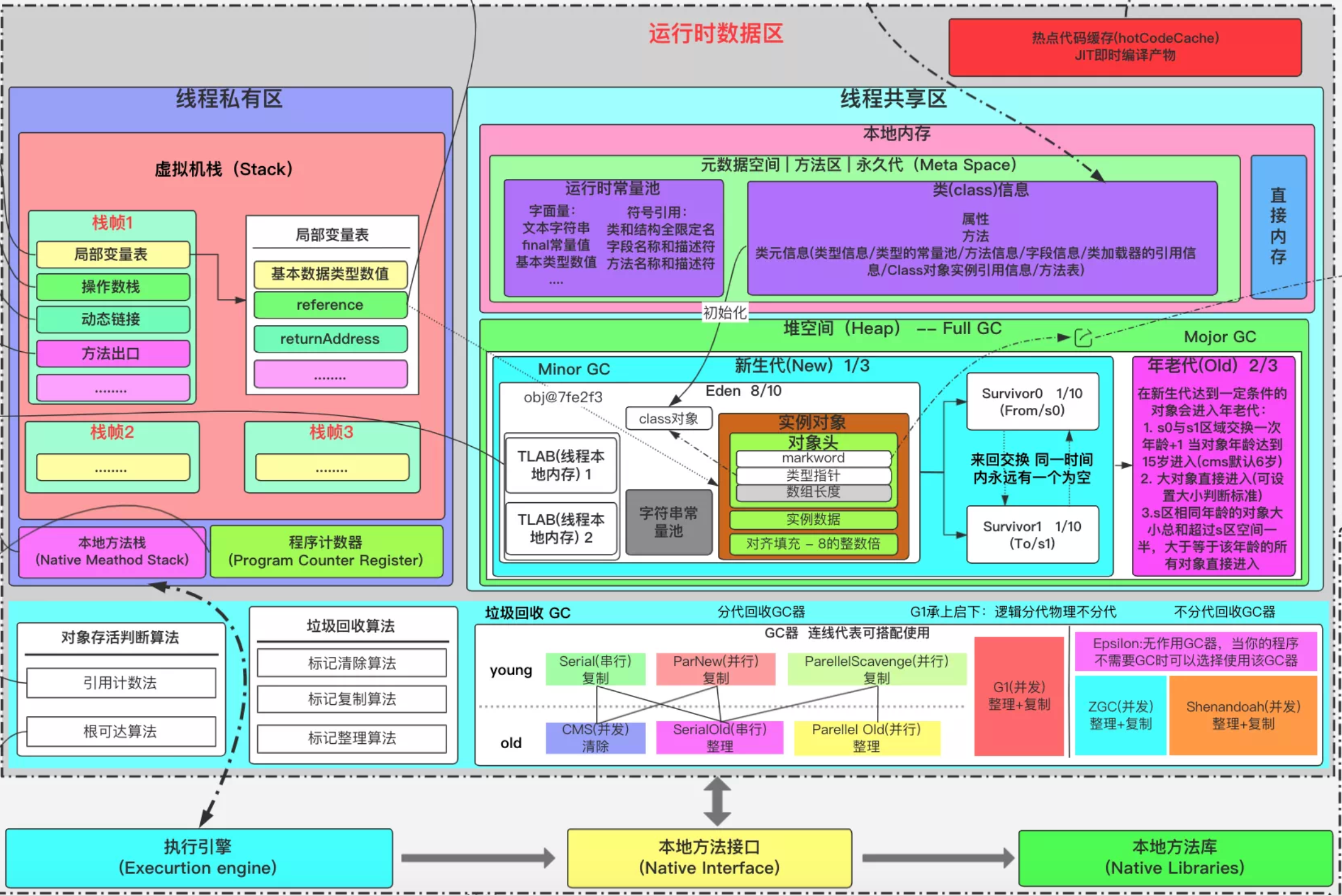
- 線程私有區(Thread Local):主要包括程式計數器、虛擬機棧、本地方法區,其中線程私有數據區域生命周期與線程相同, 依賴用戶線程的啟動/結束 而 創建/銷毀。
- 線程共用區(Thread Shared):主要包括JAVA 堆、方法區,其中,線程共用區域隨虛擬機的啟動/關閉而創建/銷毀。
- 直接記憶體(Driect Memory):不會受Java HotSpot(TM) VM 虛擬機中的GC影響,並不是JVM運行時數據區的成員。
根據線程私有區中包含的數據(程式計數器、虛擬機棧、本地方法區)來具體分析看,其中:
- 程式計數器(Program Counter Register ):一塊較小的記憶體空間, 是當前線程所執行的位元組碼的行號指示器,每條線程都要有一個獨立的程式計數器,而且是唯一一個在虛擬機中沒有規定任何OutOfMemoryError情況的區域。
- 虛擬機棧(VM Stack):是描述Java方法執行的記憶體模型,在方法執行的同時都會創建一個棧幀用於存儲局部變數表、操作數棧、動態鏈接、方法出口等信息。
- 本地方法區(Native Method Stack):和Java Stack作用類似, 區別是虛擬機棧為執行Java方法服務, 而本地方法棧則為Native方法服務。
根據線程共用區中包含的數據(JAVA 堆、方法區)來具體分析看,其中:
- JAVA 堆(Heap):是被線程共用的一塊記憶體區域,創建的對象和數組都保存在Java堆記憶體中,也是垃圾收集器進行垃圾收集的最重要的記憶體區域。
- 方法區(Method Area):是指Java HotSpot(TM) VM 虛擬機把GC分代收集擴展至方法區,Java HotSpot(TM) VM 的垃圾收集器就可以像管理Java堆一樣管理這部分記憶體, 而不必為方法區開發專門的記憶體管理器,其中這裡需要註意的是:
- 在JDK1.8之前,使用永久代(Permanent Generation), 用於存儲被JVM載入的類信息、常量、靜態變數、即時編譯器編譯後的代碼等數據. , 即使用Java堆的永久代來實現方法區, 主要是因為永久帶的記憶體回收的主要目標是針對常量池的回收和類型的卸載, 其收益一般很小。
- 在JDK1.8之後,永久代已經被移除,被一個稱為“元數據區(Metadata Area)”的區域所取代。元空間(Metadata Space)的本質和永久代類似,最大的區別在於:元空間並不在虛擬機中,而是使用本地記憶體。預設情況下,元空間的大小僅受本地記憶體限制。類的元數據放入 Native Memory, 字元串池和類的靜態變數放入Java堆中,這樣可以載入多少類的元數據由系統的實際可用空間來控制。
這裡對線程共用區和程私有區其細節,就暫時不做展開,但是我們可以簡單地看出,對於Java領域中的記憶體分配,這兩者之間已經幫助我們做了具體區分。
在繼續後續問題探索之前,我們一起來思考一個問題:按照線性思維來看,一個Java程式從程式編寫到編譯,編譯到運行,運行到執行等過程來說,究竟是先入堆還是先入棧呢 ?
這個問題,其實我在看Java HotSpot(TM) VM 虛擬機相關知識的時候,一直有這樣的個疑慮,但是其實這樣的表述是不准確的,這需要結合編譯原理相關的知識來具體分析。
按照編譯原理的觀點,從Java記憶體分配策略來看,程式運行時的記憶體分配有三種策略,其中:
- 靜態存儲分配:靜態存儲分配要求在編譯時能知道所有變數的存儲要求,指在編譯時,就能確定每個數據在運行時的存儲空間,因而在編譯時就可以給他們分配固定的記憶體空間。這種分配策略要求程式代碼中不允許有可變數據結構的存在,也不允許有嵌套或者遞歸的結構出現,因為它們都會導致編譯程式無法計算準確的存儲空間需求。
- 棧式存儲分配:棧式存儲分配要求在過程的入口處必須知道所有的存儲要求,也可稱為動態存儲分配,是由一個類似於堆棧的運行棧來實現的。和靜態存儲分配相反,在棧式存儲方案中,程式對數據區的需求在編譯時是完全未知的,只有到運行的時候才能夠知道,也就是規定在運行中進入一個程式模塊時,必須知道該程式模塊所需的數據區大小才能夠為其分配記憶體。棧式存儲分配按照先進後出的原則進行分配。
- 堆式存儲分配:堆式存儲分配則專門負責在編譯時或運行時模塊入口處都無法確定存儲要求的數據結構的記憶體分配,比如可變長度串和對象實例。堆由大片的可利用塊或空閑塊組成,堆中的記憶體可以按照任意順序分配和釋放。
也就是說,在Java領域中,一個Java程式從程式編寫到編譯,編譯到運行,運行到執行等過程來說,單純考慮是先入堆還是入棧的問題,在這裡得到了答案。
從整體上來看,Java記憶體模型主要考慮的事情基本與主存,線程本地記憶體,共用變數,變數副本,線程等概念息息相關,其中:
- 從主存與線程本地記憶體的關係來看 : 主存主要保存Java程式中的共用變數,其中主存不保存局部變數和方法參數列表;而線程本地記憶體主要保存Java程式中的共用變數的變數副本。
- 從線程與線程本地記憶體的關係來看:每個線程都會維護一個自己專屬的本地記憶體,不同線程之間互相不可直接通信,其線程之間的通信就會涉及共用變數可見性的問題。
在Java記憶體模型中,一般來說主要提供volatile,synchronized,final以及鎖等4種方式來保證變數的可見性問題,其中:
- 通過volatile關鍵詞實現: 利用volatile修飾聲明時,變數一旦有更改都會被立即同步到主存中,當線程需要使用這個變數時,需要從主存中刷新到工作記憶體中。
- 通過synchronized關鍵詞實現:利用synchronized修飾聲明時,當一個線程釋放一個鎖,強制刷新工作記憶體中的變數到主存中,當另外一個線程需要使用此鎖時,會強制重新載入變數值。
- 通過final關鍵詞實現:利用final修飾聲明時,變數一旦初始化完成,Java中的線程都可以看到這個變數。
- 通過JDK中鎖實現:當一個線程釋放一個鎖,強制刷新工作記憶體中的變數到主存中,當另外一個線程需要使用此鎖時,會強制重新載入變數值。
實際上,相比之下,Java記憶體模型還引入了一個工作記憶體的概念來幫助我們提升性能,而且JMM提供了合理的禁用緩存以及禁止重排序的方法,所以其核心的價值在於解決可見性和有序性。
其中,需要特別註意的是,其主存和工作記憶體的區別:
- 主存: 可以在電腦記憶體模型說是物理記憶體,對應到Java記憶體模型來講,是Java HotSpot(TM) VM 虛擬機中虛擬記憶體的一部分。
- 工作記憶體:在電腦記憶體模型內是指CPU緩存,一般是指寄存器,還有以及我們說的三層高速緩存策略中的L1/L2/L3層高級緩存;對應到Java記憶體模型來講,主要是三層高速緩存Cache和寄存器。
綜上所述,我們對Java記憶體模型的探討算是水到渠成了,但是Java記憶體模型也提出了一些規範,接下來,我們就來看看Happen-Before 關係原則。
四.Java一致性模型指導原則
Java一致性模型指導原則是指制定一些規範來將複雜的物理電腦的系統底層封裝到JVM中,從而向上提供一種統一的記憶體模型語義規則,一般是指Happens-Before規則。
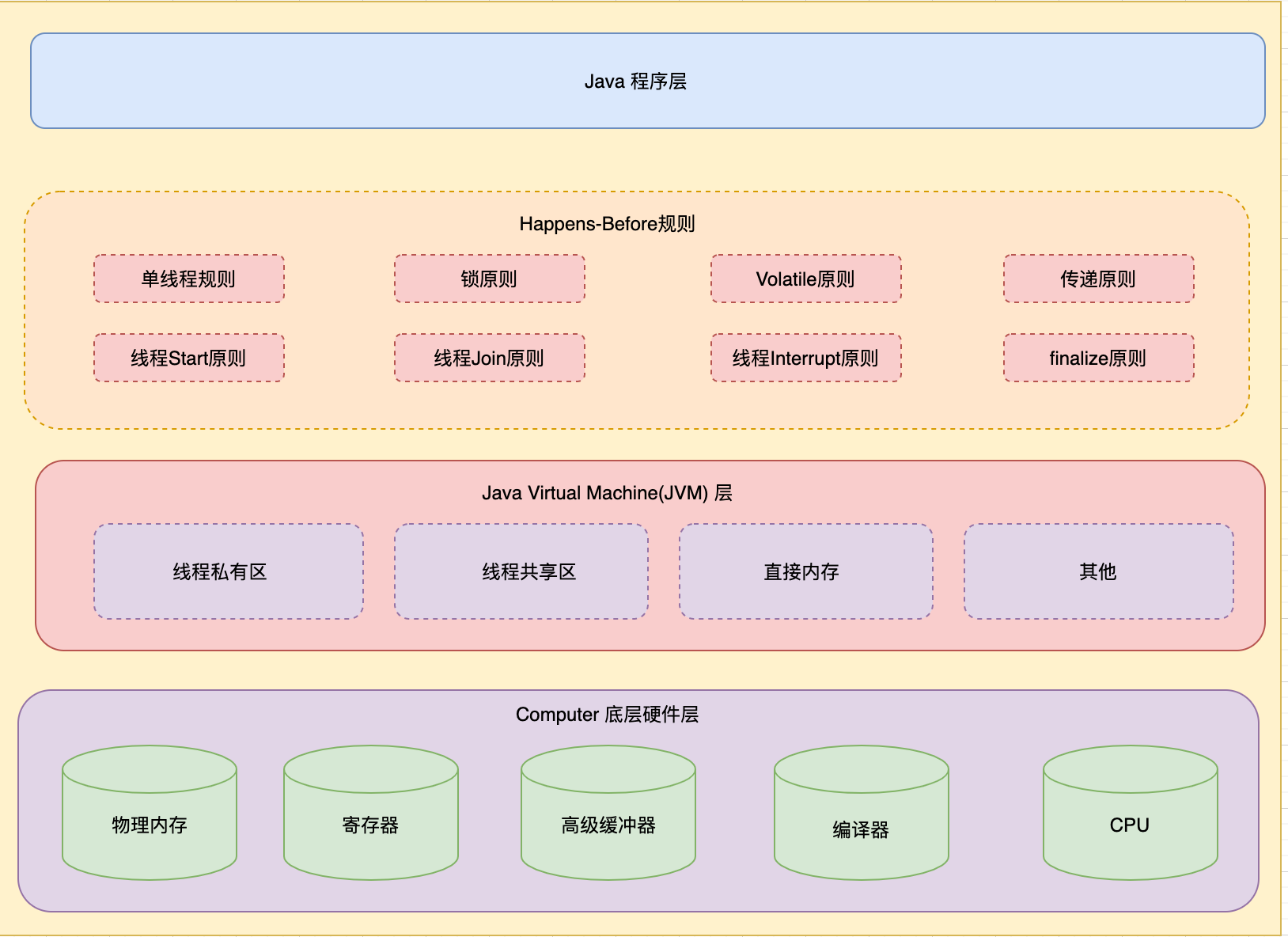
Happen-Before 關係原則,是 Java 記憶體模型中保證多線程操作可見性的機制,也是對早期語言規範中含糊的可見性概念的一個精確定義,其行為依賴於處理器本身的記憶體一致性模型。
Happen-Before 關係原則主要規定了Java記憶體在多線程操作下的順序性,一般是指先發生操作的執行結果對後續發生的操作可見,因此稱其為Java一致性模型指導原則。
由於Happen-Before 關係原則是向上提供一種統一的記憶體模型語義規則,它規範了Java HotSpot(TM) VM 虛擬機的實現,也能為上層Java Developer描述多線程併發的可見性問題。
在Java領域中,Happen-Before 關係原則主要有8種,具體如下:
- 單線程原則:線程內執行的每個操作,都保證 happen-before 後面的操作,這就保證了基本的程式順序規則,這是開發者在書寫程式時的基本約定。
- 鎖原則:對於一個鎖的解鎖操作,保證 happen-before 加鎖操作。
- volatile原則:對於 volatile 變數,對它的寫操作,保證 happen-before 在隨後對該變數的讀取操作。
- 線程Start原則:類似線程內部操作的完成,保證 happen-before 其他 Thread.start() 的線程操作原則。
- 線程Join原則:類似線程內部操作的完成,保證 happen-before 其他 Thread.join() 的線程操作原則。
- 線程Interrupt原則:類似線程內部操作的完成,保證 happen-before 其他 Thread.interrupt() 的線程操作原則。
- finalize原則: 對象構建完成,保證 happen-before 於 finalizer 的開始動作。
- 傳遞原則: Happen-Before 關係是存在著傳遞性的,如果滿足 A happen-before B 和 B happen-before C,那麼 A happen-before C 也成立。
對於Happen-Before 關係原則來說,而不是簡單地線性思維的前後順序問題,是因為它不僅僅是對執行時間的保證,也包括對記憶體讀、寫操作順序的保證。僅僅是時鐘順序上的先後,並不能保證線程交互的可見性。
在Java HotSpot(TM) VM 虛擬機內部的運行時數據區,但是真正程式執行,實際是要跑在具體的處理器內核上。簡單來說,把本地變數等數據從記憶體載入到緩存、寄存器,然後運算結束寫回主記憶體。
總的來說,JMM 內部的實現通常是依賴於記憶體屏障,通過禁止某些重排序的方式,提供記憶體可見性保證,也就是實現了各種 happen-before 規則。與此同時,更多複雜度在於,需要儘量確保各種編譯器、各種體繫結構的處理器,都能夠提供一致的行為。
五.Java指令重排
Java指令重排是指在執行程式時為了提高性能,編譯器和處理器常常會對指令做重排序的一種防護措施機制。
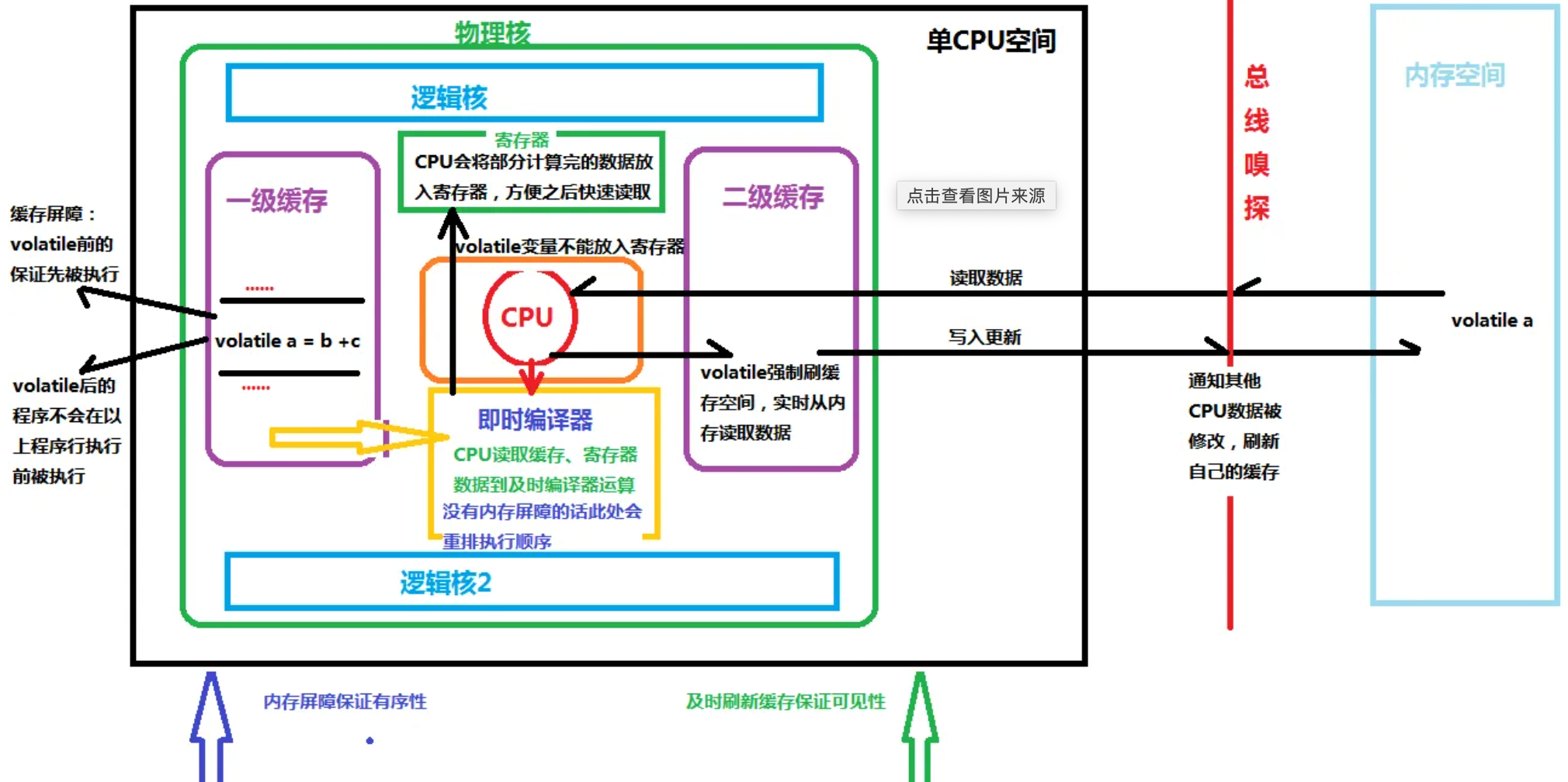
我們在實際開發工作中編寫代碼時候,是按照一定的代碼的思維和習慣去編排和組織代碼的,但是實際上,編譯器和CPU執行的順序可能會代碼順序產生不一致的情況。
畢竟,編譯器和CPU會對我們編寫的程式代碼自身做一定程度上的優化再去執行,以此來提高執行效率,因此提出了指令重排的機制。
一般來說,我們在程式中編寫的每一個行代碼其實就是程式指令,按照線性思維方式來看,這些指令按道理是一行行代碼存在的順序去執行的,只有上一行代碼執行完畢,下一行代碼才會被執行,這就說明代碼的執行有一定的順序。
但是這樣的順序,對於程式的執行時間上來看是有一定的耗時的,為了加快代碼的執行效率,一般會引入一種流水線技術的方式來解決這個問題,就像Jenkins 流水線部署機制的編寫那樣。
但是流水線技術的本質上,是把每一個指令拆成若幹個部分,在同一個CPU的時間內使其可以執行多個指令的不同部分,從而達到提升執行效率的目的,主要體現在:
- 獲取指令階段: 主要使用指令通道和指令寄存器,一般是在CPU處理器主導
- 編譯指令階段:主要使用指令編譯器,一般是在編譯器主導
- 執行指令階段:主要使用執行單元和數據通道,相對來說像是從記憶體在主導
一般來說,指令從排會涉及到CPU,編譯器,以及記憶體等,因此指令重排序的類型大致可以分為 編譯器指令重排,CPU指令重排,記憶體指令重排,其中:
- 編譯器指令重排:編譯器在不改變單線程程式語義的前提下,可以重新安排語句的執行順序
- CPU指令重排:現代處理器採用了指令級並行技術(Instruction-Level Parallelism, ILP)來將多條指令重疊執行。如果不存在數據依賴性,處理器可以改變語句對應機器指令的執行順序。
- 記憶體指令重排:由於處理器使用緩存和讀/寫緩衝區,其載入和存儲操作看上去類似亂序執行的情況。
在Java領域中,指令重排的原則是不能影響程式在單線程下的執行的準確性,但是在多線程的情況下,可能會導致程式執行出現錯誤的情況,主要是依據Happen-Before 關係原則來組織部重排序,其核心就是使用記憶體屏障來實現,通過記憶體屏障可以堆記憶體進行順序約束,而且作用於線程。
由於Java有不同的編譯器和運行時環境,對應起來看,Java指令重排主要發生在編譯階段和運行階段,而編譯階段對應的是編譯器,運行階段對應著CPU,其中:
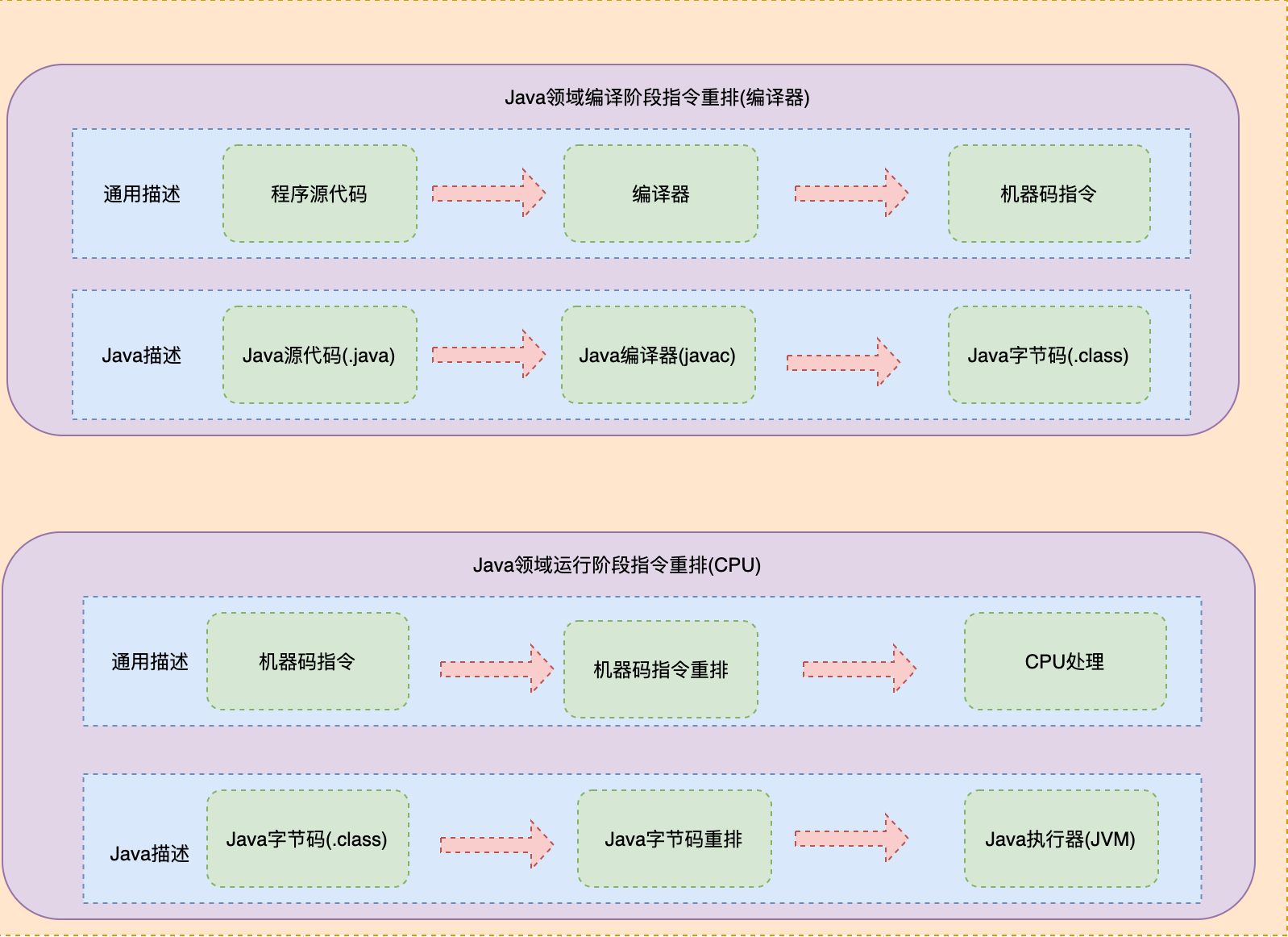
- 編譯階段指令重排:
- 1⃣️ 通用描述:源代碼->機器碼的指令重排: 源代碼經過編譯器變成機器碼,而機器碼可能被重排
- 2⃣️ Java描述:Java源文件->Java位元組碼的指令重排: Java源文件被javac編譯後變成Java位元組碼,其位元組碼可能被重排
- 運行階段指令重排:
- 1⃣️ 通用描述:機器碼->CPU處理器的指令重排:機器碼經過CPU處理時,可能會被CPU重排才執行
- 2⃣️ Java描述:Java位元組碼->Java執行器的指令重排: Java位元組碼被Java執行器執行時,可能會被CPU重排才執行
既然設置記憶體屏障,可以確保多CPU的高速緩存中的數據與記憶體保持一致性, 不能確保記憶體與CPU緩存數據一致性的指令也不能重排,記憶體屏障正是通過阻止屏障兩邊的指令重排序來避免編譯器和硬體的不正確優化而提出的一種解決辦法。
但是記憶體屏障的是需要考慮CPU的架構方式,不同硬體實現記憶體屏障的方式不同,一般以常見Intel CPU來看,主要有:
- 1⃣️ lfence屏障: 是一種Load Barrier 讀屏障。
- 2⃣️ sfence屏障: 是一種Store Barrier 寫屏障 。
- 3⃣️ mfence屏障:是一種全能型的屏障,具備ifence和sfence的能力 。
- 4⃣️ Lock首碼,Lock不是一種記憶體屏障,但是它能完成類似記憶體屏障的功能。Lock會對CPU匯流排和高速緩存加鎖,可以理解為CPU指令級的一種鎖。
在Java領域中,Java記憶體模型屏蔽了這種底層硬體平臺的差異,由JVM來為不同的平臺生成相應的機器碼。
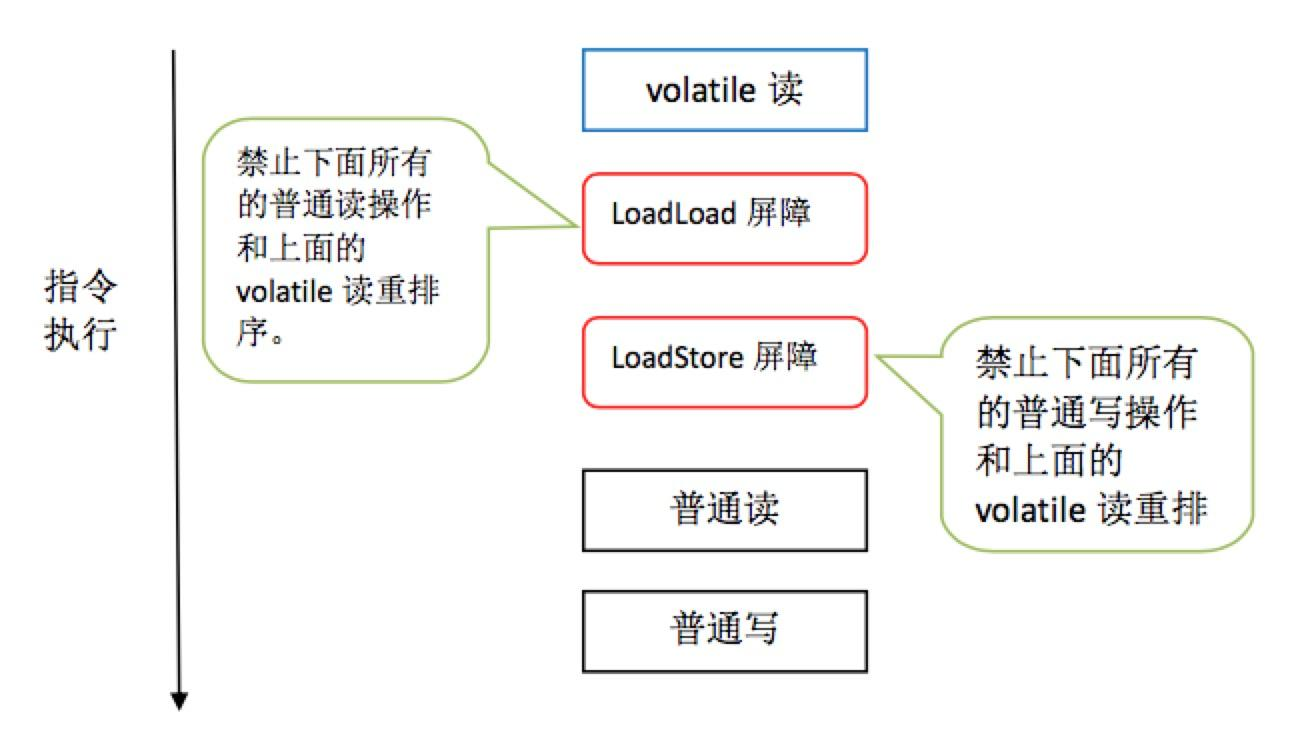
從廣義上的概念定義看,Java中的記憶體屏障一般主要有Load和Store兩類:
- 1⃣️ 對Load Barrier來說,在讀指令前插入讀屏障,可以讓高速緩存中的數據失效,重新從主記憶體載入數據
- 2⃣️ 對Store Barrier來說,在寫指令之後插入寫屏障,能讓寫入緩存的最新數據寫回到主記憶體
從具體的使用方式來看,Java中的記憶體屏障主要有以下幾種方式:
- 1⃣️ 通過 synchronized關鍵字包住的代碼區域:當線程進入到該區域讀取變數信息時,保證讀到的是最新的值。
- a. 在同步區內對變數的寫入操作,在離開同步區時就將當前線程內的數據刷新到記憶體中。
- b. 對數據的讀取也不能從緩存讀取,只能從記憶體中讀取,保證了數據的讀有效性.這也是會插入StoreStore屏障的緣故。 - 2⃣️ 通過volatile關鍵字修飾變數:當對變數的寫操作,會插入StoreLoad屏障。
- 3⃣️ 其他的設置方式,一般需要通過Unsafe這個類來執行,主要是:
- a. Unsafe.putOrderedObject():類似這樣的方法,會插入StoreStore記憶體屏障
- b. Unsafe.putVolatiObject() 類似這樣的方法,會插入StoreLoad屏障
綜上所述,一般來說volatile關健字能保證可見性和防止指令重排序,也是我們最常見提到的方式。
六.Java併發編程的三宗罪
Java併發編程的三宗罪主要是指原子性問題、可見性問題和有序性問題等三大問題。
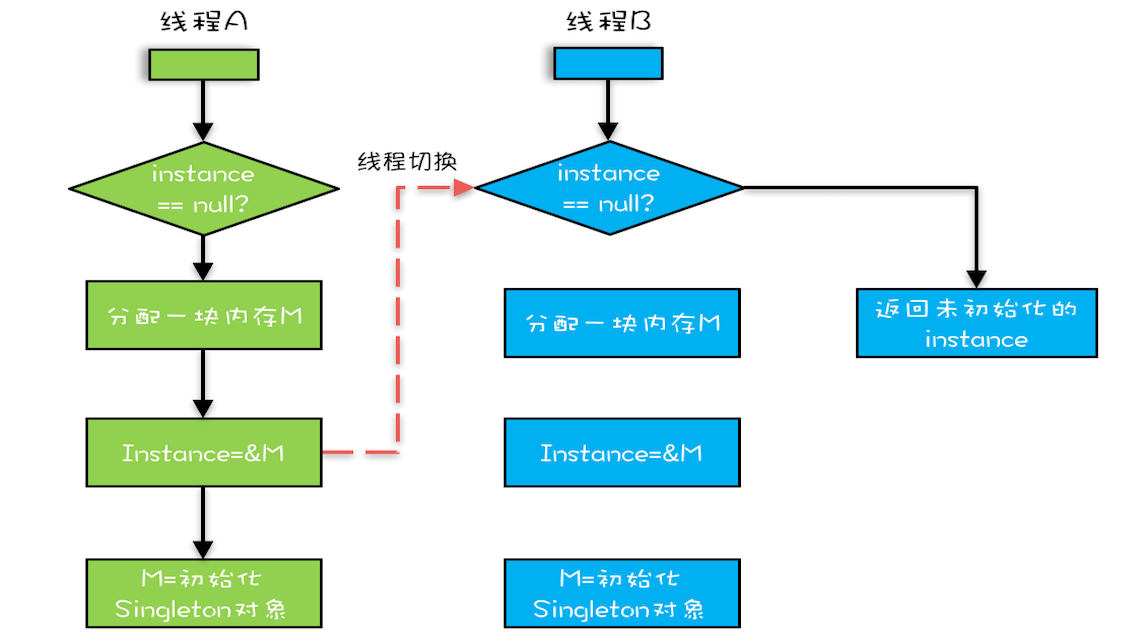
在介紹Java記憶體模型時,我們都說其核心的價值在於解決可見性和有序性,以及還有原子性等,那麼對其總結來說,就是Java併發編程的三宗罪,其中:
- 原子性問題:就是“不可中斷的一個或一系列操作”,是指不會被線程調度機制打斷的操作。這種操作一旦開始,就一直運行到結束,中間不會有任何線程的切換。
- 可見性問題:一個線程對共用變數的修改,另一個線程能夠立刻可見,我們稱該共用變數具備記憶體可見性。
- 有序性問題:指程式按照代碼的先後順序執行。如果程式執行的順序與代碼的先後順序不同,並導致了錯誤的結果,即發生了有序性問題。
但是,這裡我們需要知道,Java記憶體模型是如何解決這些問題的?主要體現如下幾個方面:
- 解決原子性問題:Java記憶體模型通過read、load、assign、use、store、write來保證原子性操作,此外還有lock和unlock,直接對應著synchronized關鍵字的monitorenter和monitorexit位元組碼指令。
- 解決可見性問題:Java保證可見性通過volatile、final以及synchronized,鎖來實現。
- 解決有序性問題:由於處理器和編譯器的重排序導致的有序性問題,Java主要可以通過volatile、synchronized來保證。
一定意義上來講,一般在Java併發編程中,其實加鎖可以解決一部分問題,除此之外,我們還需要考慮線程饑餓問題,數據競爭問題,競爭條件問題以及死鎖問題,通過綜合分析才能得到意想不到的結果。
綜上所述,我們在理解Java領域中的鎖時,可以以此作為一個考量標準之一,來幫助和方便我們更快理解和掌握併發編程技術。
七.Java線程饑餓問題
Java線程饑餓問題是指長期無法獲取共用資源或搶占CPU資源而導致線程無法執行的現象。
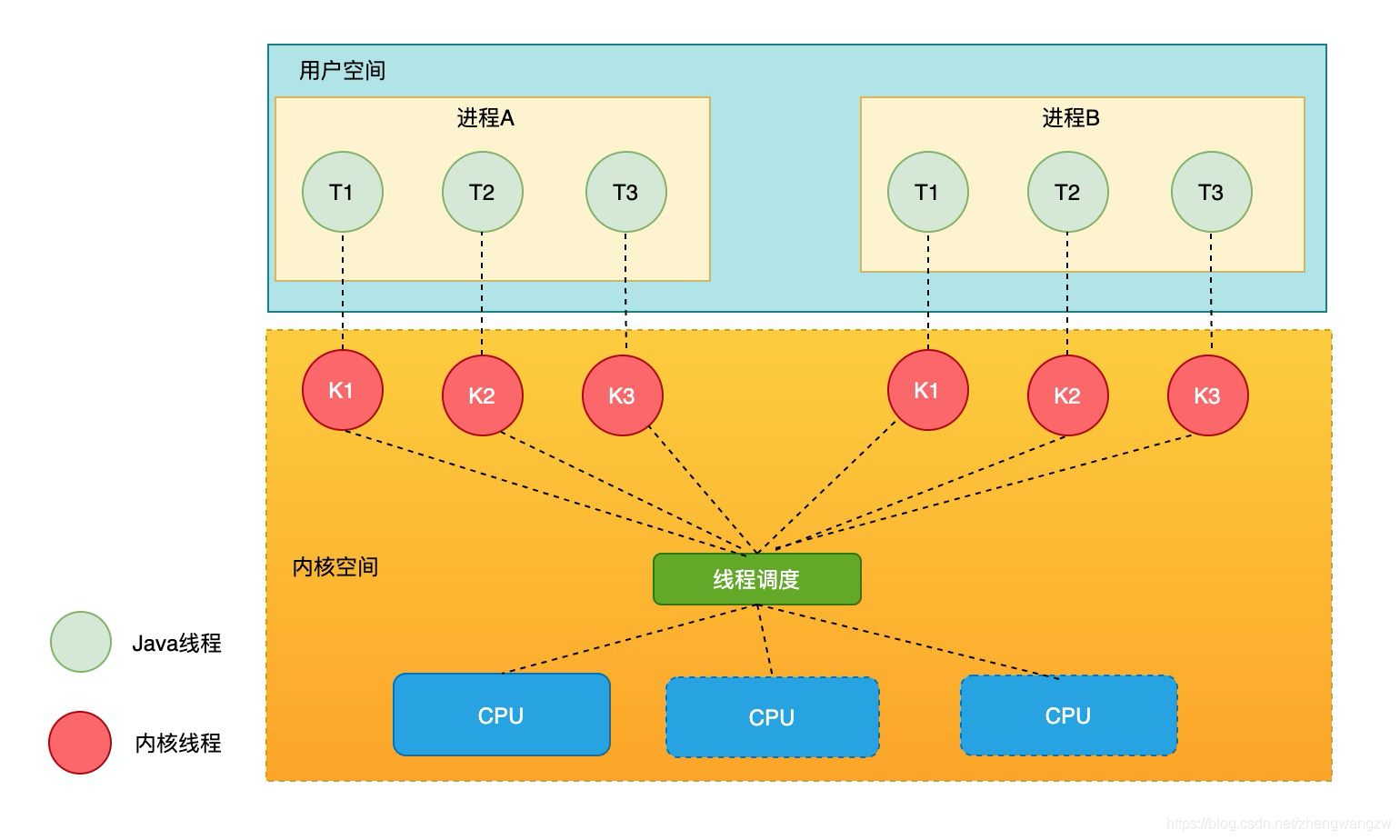
在Java併發編程的過程中,特別是開啟線程數過多,會遇到某些線程貪婪地把CPU資源占滿,導致某些線程分配不到CPU而沒有辦法執行。
在Java領域中,對於線程饑餓問題,可以從以下幾個方面來看:
- 互斥鎖synchronized饑餓問題:在使用synchronized對資源進行加鎖時,不斷有大量的線程去競爭獲取鎖,那麼就可能會引發線程饑餓問題,主要是synchronized只是加鎖,沒有要求公平性導致的。
- 線程優先順序饑餓問題:Java中每個線程都有自己的優先順序,一般情況下使用預設優先順序,但是由於線程優先順序不同,也會引起線程饑餓問題。
- 線程自旋饑餓問題: 主要是在Java併發操作中,會使用自旋鎖,由於鎖的核心的自旋操作,會導致大量線程自旋,也會引起線程饑餓問題。
- 等待喚醒饑餓問題: 主要是因為JVM中wait和notify實現不同,比方說Java HotSpot(TM) VM 虛擬機是一種先入先出結構,也會引起線程饑餓問題。
針對上述的饑餓問題,為瞭解決它,JDK內部實現一些具備公平性質的鎖,可以直接使用。所以,解決線程饑餓問題,一般是引入隊列,也就是排隊處理,最典型的有ReentrantLock。
綜上所述,這不就是為我們掌握和理解Java中的鎖機制時,需要考慮Java線程饑餓問題。
八.Java數據競爭問題
Java數據競爭問題是指至少存在兩個線程去讀寫某個共用記憶體,其中至少一個線程對其共用記憶體進行寫操作。
對於數據競爭問題,最簡單的理解就是,多個線程在同時對於共用記憶體的進行寫操作時,在寫的過程中,其他的線程讀到數據是記憶體數據中非正確預期的。
產生數據競爭的原因,一個CPU在任意時刻只能執行一條指令,但是對其某個記憶體中的寫操作可能會用到若幹條件機器指令,從而導致在寫的過程中還沒完全修改完記憶體,其他線程去讀取數據,從而導致結果不可預知。從而引發數據競爭問題,這個情況有點像MySQL數據中併發事務引起的臟讀情況。
在Java領域中,解決數據競爭問題的方式一般是把共用記憶體的更新操作進行原子化,同時也保證記憶體的可見性。
針對上述的饑餓問題,為瞭解決它,JDK內部實現一系列的原子類,比如AtomicReference類等,但是主要可以採用CAS+自旋鎖的方式來實現。
綜上所述,這不就是為我們掌握和理解Java中的鎖機制時,需要考慮Java數據競爭問題。
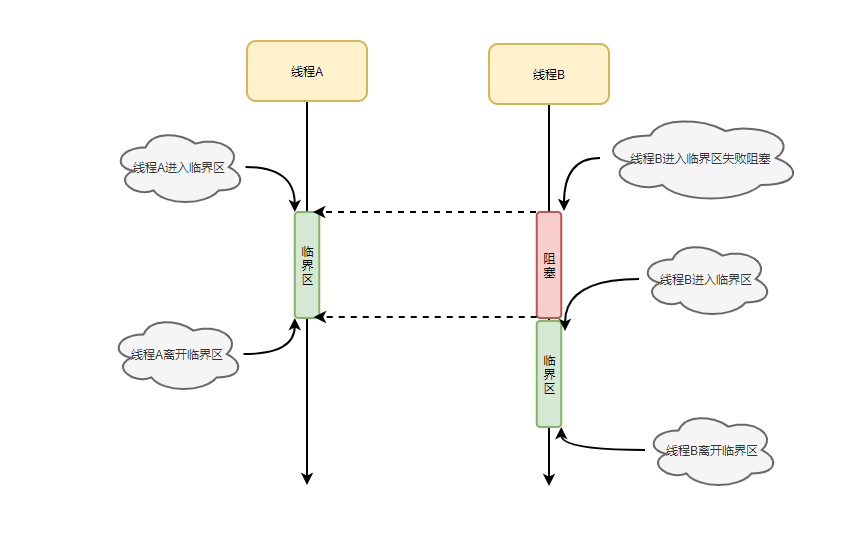
九.Java競爭條件問題
Java競爭條件問題是指代碼在執行臨界區產生競爭條件,主要是因為多個線程不同的執行順序以及線程併發的交叉執行導致執行結果與預期不一致的情況。
對於競爭條件問題,其中臨界區是一塊代碼區域,其實說白了就是我們自己寫的邏輯代碼,由於沒有考慮位,從而引發的多個線程不同的執行順序以及線程併發的交叉執行導致執行結果與預期不一致的情況。
產生競爭條件問題的主要原因,一般主要有線程執行順序的不確定性和併發機制導致上下文切換等兩個原因導致競爭條件問題,其中:
- 線程執行順序的不確定性:這個線程調度的工作方式有關,現在大部分電腦的操作系統都是搶占方式的調度方式,所有的任務調度由操作系統來完全控制,線程的執行順序不一定是按照編碼順序的,主要有操作系統調度演算法決定。
- 併發機制導致上下文切換:在併發的多線程的程式中,多個線程會導致進行上下文的資源切換,並且交叉執行,從而併發機制自身也會引起競爭條件問題。
在Java領域中,解決競爭條件問題的方式一般是把臨界區進行原子化,保證臨界區的源自性,保證了臨界區捏只有一個線程,從而避免競爭產生。
針對上述的饑餓問題,為瞭解決它,JDK內部實現一系列的原子類或者說直接使用synchronized來聲明,均可實現。
綜上所述,這不就是為我們掌握和理解Java中的鎖機制時,需要考慮Java競爭條件問題。
十.Java死鎖問題
Java死鎖問題主要是指一種有兩個或者兩個以上的線程或者進程構成一個無限互相等待的環形狀態的情況,不是一種鎖概念,而是一種線程狀態的表徵描述。
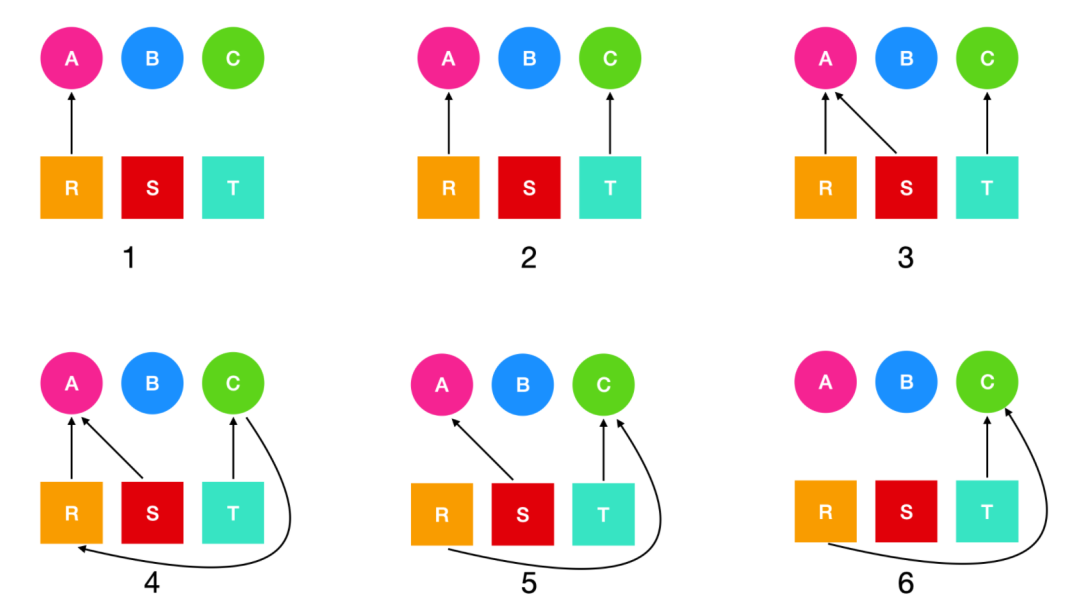
一般為了保證線程安全問題,我們都會想著給會使用加鎖機制來確保線程安全,但如果過度地使用加鎖,則可能導致鎖順序死鎖(Lock-Ordering Deadlock)。
或者有的場景我們使用線程池和信號量等來限制資源的使用,但這些被限制的行為可能會導致資源死鎖(Resource DeadLock)。
Java死鎖問題的主要體現在以下幾個方面:
- 1⃣️ Java應用程式不具備MySQL資料庫伺服器的本地事務,無法檢測一組事務中是否有死鎖的發生。
- 2⃣️ 在Java程式中,如果過度地使用加鎖,輕則導致程式響應時間變長,系統吞吐量變小,重則導致應用中的某一個功能直接失去響應能力無法提供服務。
當然,死鎖問題的產生也必須具備以及同時滿足以下幾個條件:
- 互斥條件:資源具有排他性,當資源被一個線程占用時,別的線程不能使用,只能等待。
- 阻塞不釋放條件: 某個線程或者線程請求某個資源而進入阻塞狀態,不會釋放已經獲取的資源。
- 占有並等待條件: 某個線程或者線程應該至少占有一個資源,等待獲取另外一個資源,該資源被其他線程或者線程霸占。
- 非搶占條件: 不可搶占,資源請求者不能強制從資源占有者手中搶奪資源,資源只能由占有者主動釋放。
- 環形條件: 迴圈等待,多個線程存在環路的鎖依賴關係而永遠等待下去。
對於死鎖問題,一般都是需要編程開發人員人為去干預和防止的,只是需要一些措施區規範處理,主要可以分為事前預防和事後處理等2種方式,其中:
- 事前預防: 一般是保證鎖的順序化,資源合併處理,以及避免嵌套鎖等。
- 事後處理: 一般是對鎖設置超時機制,在死鎖發生時搶占鎖資源,以及撤銷線程機制等。
除了有死鎖的問題,當然還有活鎖問題,主要是因為某些邏輯導致一直在做無用功,使得線程無法正確執行的情況。
應用分析
在Java領域中,我們可以將鎖大致分為基於Java語法層面(關鍵詞)實現的鎖和基於JDK層面實現的鎖。

單純從Java對其實現的方式上來看,我們大體上可以將其分為基於Java語法層面(關鍵詞)實現的鎖和基於JDK層面實現的鎖。其中:
- 基於Java語法層面(關鍵詞)實現的鎖,主要是根據Java語義來實現,最典型的應用就是synchronized。
- 基於JDK層面實現的鎖,主要是根據統一的AQS基礎同步器來實現,最典型的有ReentrantLock。
需要特別註意的是,在Java領域中,基於JDK層面的鎖通過CAS操作解決了併發編程中的原子性問題,而基於Java語法層面實現的鎖解決了併發編程中的原子性問題和可見性問題。
單純從Java對其實現的方式上來看,我們大體上可以將其分為基於Java語法層面(關鍵詞)實現的鎖和基於JDK層面實現的鎖。其中:
- 基於Java語法層面(關鍵詞)實現的鎖,主要是根據Java語義來實現,最典型的應用就是synchronized。
- 基於JDK層面實現的鎖,主要是根據統一的AQS基礎同步器來實現,最典型的有ReentrantLock。
需要特別註意的是,在Java領域中,基於JDK層面的鎖通過CAS操作解決了併發編程中的原子性問題,而基於Java語法層面實現的鎖解決了併發編程中的原子性問題和可見性問題。
而從具體到對應的Java線程資源來說,我們按照是否含有某一特性來定義鎖,主要可以從如下幾個方面來看:
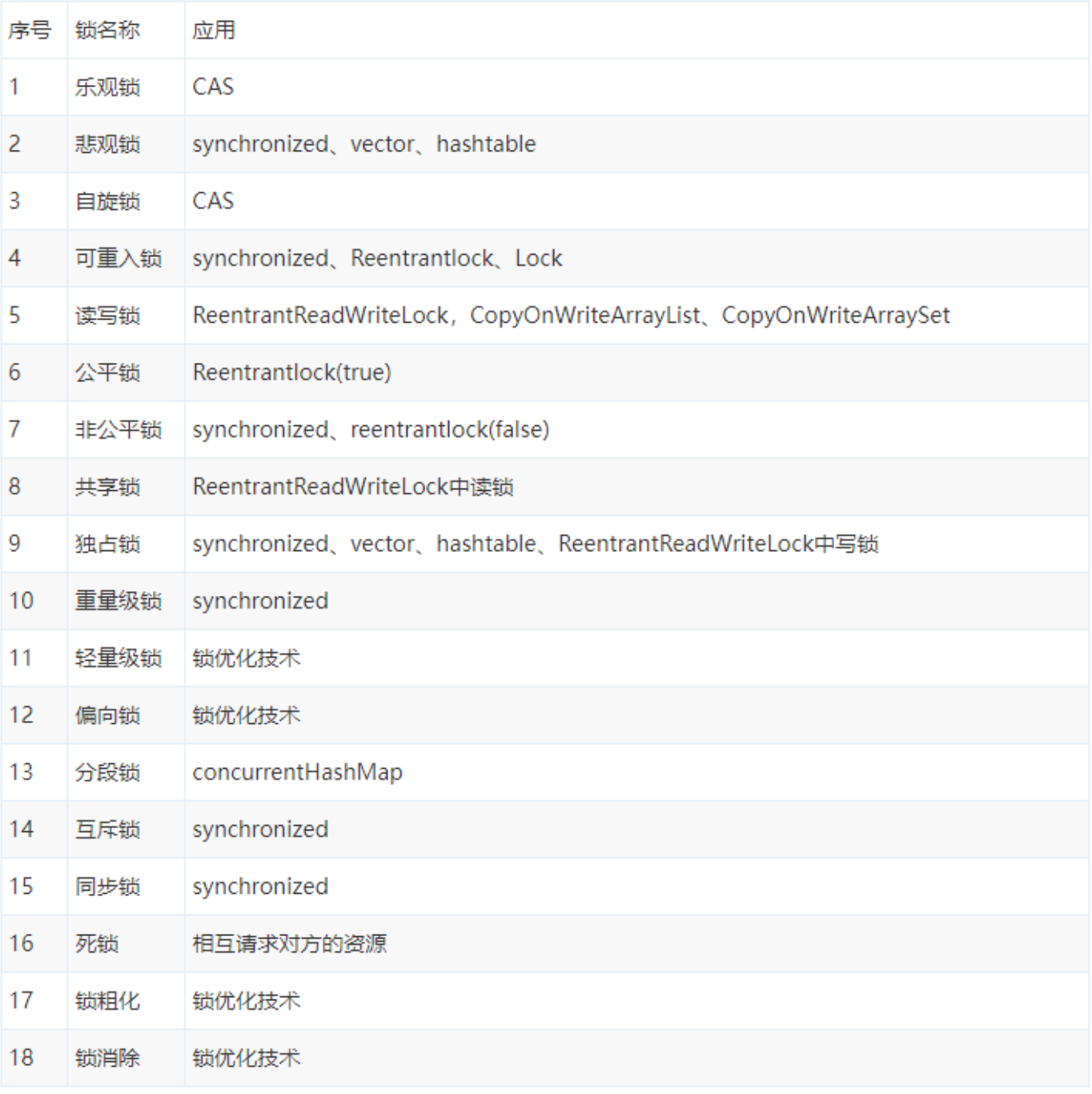
- 從加鎖對象角度方面上來看,線程要不要鎖住同步資源 ? 如果是需要加鎖,鎖住同步資源的情況下,一般稱其為悲觀鎖;否則,如果是不需要加鎖,且不用鎖住同步資源的情況就屬於為樂觀鎖。
- 從獲取鎖的處理方式上來看,假設鎖住同步資源,其對該線程是否進入睡眠狀態或者阻塞狀態?如果會進入睡眠狀態或者阻塞狀態,一般稱其為互斥鎖,否則,不會進入睡眠狀態或者阻塞狀態屬於一種非阻塞鎖,即就是自旋鎖。
- 從鎖的變化狀態方面來看,多個線程在競爭資源的流程細節上是否有差別?
- 1⃣️ 對於不會鎖住資源,多個線程只有一個線程能修改資源成功,其他線程會依據實際情況進行重試,即就是不存在競爭的情況,一般屬於無鎖。
- 2⃣️ 對於同一個線程執行同步資源會自動獲取鎖資源,一般屬於偏向鎖。
- 3⃣️ 對於多線程競爭同步資源時,沒有獲取到鎖資源的線程會自旋等待鎖釋放,一般屬於輕量級鎖。
- 4⃣️ 對於多線程競爭同步資源時,沒有獲取到鎖資源的線程會阻塞等待喚醒,一般屬於重量級鎖。
- 從鎖競爭時公平性上來看,多個線程在競爭資源時是否需要排隊等待?如果是需要排隊等待的情況,一般屬於公平鎖;否則,先插隊,然後再嘗試排隊的情況屬於非公平鎖。
- 從獲取鎖的操作頻率次數來看,一個線程中的多個流程是否可以獲取同一把鎖?如果是可以多次進行加鎖操作的情況,一般屬於可重入鎖,否則,可以多次進行加鎖操作的情況屬於非可重入鎖。
- 從獲取鎖的占有方式上來看,多個線程能不能共用一把鎖?如果是可以共用鎖資源的情況,一般屬於共用鎖;否則,獨占鎖資源的情況屬於排他鎖。
針對於上述描述的各種情況,這裡就不做展開和贅述,看到這裡只需要在腦中形成一個概念就行,後續會有專門的內容來對其進行分析和探討。
寫在最後

在上述的內容中,一般常規的概念中,我們很難會依據上述這些問題去認識和看待Java中的鎖機制,主要是在學習和查閱資料的時,大多數的論調都是零散和細分的,很難在我們的腦海中形成知識體系。
從本質上講,我們對鎖應該有一個認識,其主要是一種協調多個進程 或者多個線程對某一個資源的訪問的控制機制,是併發編程中最關鍵的一環。
接下來,對於上述內容做一個簡單的總結:
- 1⃣️ 電腦運行模型主要是描述電腦系統體繫結構的基本模型,一般主要是指CPU處理器結構。
- 2⃣️ 電腦記憶體模型一般是指計算系統底層與編程語言之間的約束規範,主要是描述電腦程式與共用存儲器訪問的行為特征表現。
- 3⃣️ Java記憶體模型主要是為瞭解決併發編程的可見性問題,原子性問題和有序性問題等三大問題,具有跨平臺性。
- 4⃣️ Java一致性模型指導原則是指制定一些規範來將複雜的物理電腦的系統底層封裝到JVM中,從而向上提供一種統一的記憶體模型語義規則,一般是指Happens-Before規則。
- 5⃣️ Java指令重排是指在執行程式時為了提高性能,編譯器和處理器常常會對指令做重排序的一種防護措施機制。
- 6⃣️ Java併發編程的三宗罪主要是指原子性問題、可見性問題和有序性問題等三大問題。
- 7⃣️ Java線程饑餓問題是指長期無法獲取共用資源或搶占CPU資源而導致線程無法執行的現象。
- 8⃣️ Java數據競爭問題是指至少存在兩個線程去讀寫某個共用記憶體,其中至少一個線程對其共用記憶體進行寫操作。
- 9⃣️ Java競爭條件問題是指代碼在執行臨界區產生競爭條件,主要是因為多個線程不同的執行順序以及線程併發的交叉執行導致執行結果與預期不一致的情況。
-


