
資料庫CPU使用率100%報警頻繁起來。第一個想到的就是慢Sql,我們對未合理運用索引的表加入索引後,問題依然沒有得到解決,深入排查時,發現在 order by id asc limit n時,即使where條件已經包含了覆蓋索引,優化器還是選擇了錯誤的索引導致。 ...
1 前言
近期隨著數據量的增長,資料庫CPU使用率100%報警頻繁起來。第一個想到的就是慢Sql,我們對未合理運用索引的表加入索引後,問題依然沒有得到解決,深入排查時,發現在 order by id asc limit n時,即使where條件已經包含了覆蓋索引,優化器還是選擇了錯誤的索引導致。通過查詢大量資料,問題得到瞭解決。這裡將解決問題的思路以及排查過程分享出來,如果有錯誤歡迎指正。
2 正文
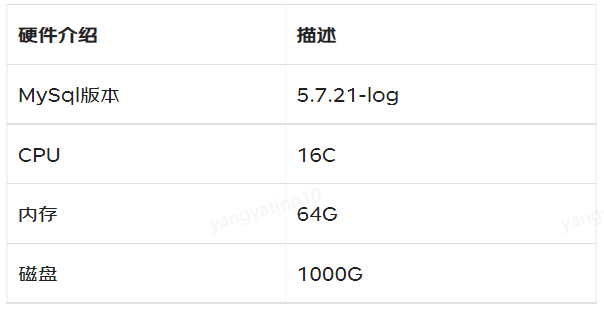
2.1 環境介紹
2.2 發現問題
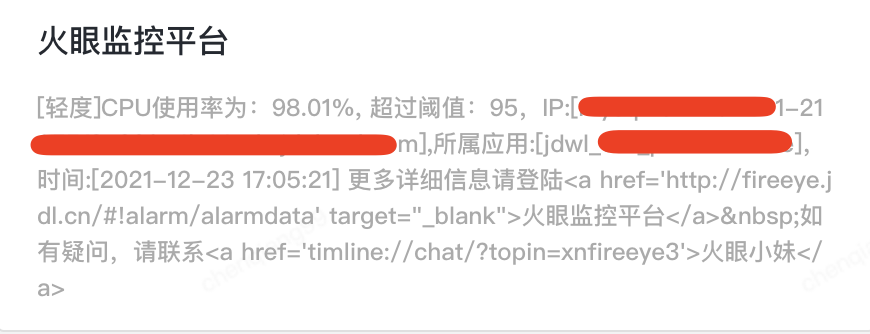
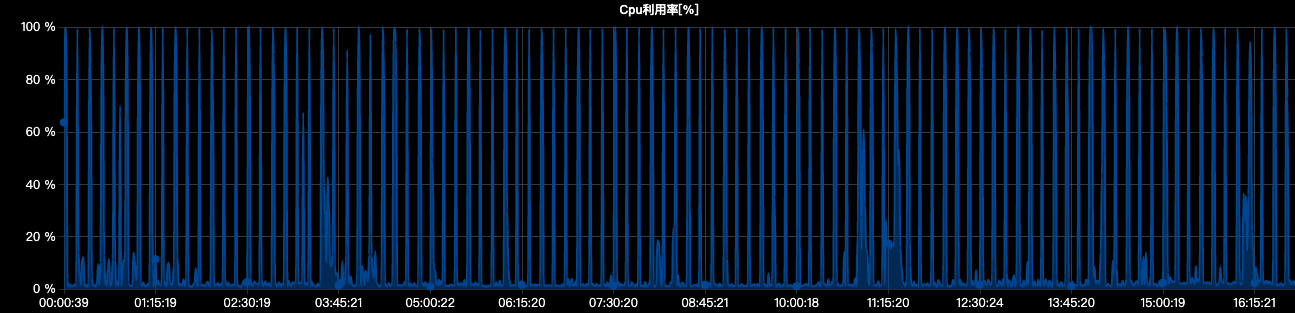
22日開始,收到以下圖1報警變得頻繁起來,由於資料庫中會有大數據推數動作,資料庫CPU偶爾報警並沒有引起對該問題的重視,直到通過圖2對整日監控數據分析時,才發現問題的嚴重性,從0點開始,資料庫CPU頻繁被打滿。
2.3 排查問題
發現問題後,開始排查慢Sql,發現很多查詢未添加合適的索引,經過一輪修複後,問題依然沒有得到解決,在深入排查時發現了一個奇怪現象,SQL代碼如下(表名已經替換),比較簡單的一個單表查詢語句。
SELECT * FROM test WHERE is_delete = 0 AND business_day = '2021-12-20' AND full_ps_code LIKE 'xxx%' AND id > 2100 ORDER BY id LIMIT 500;
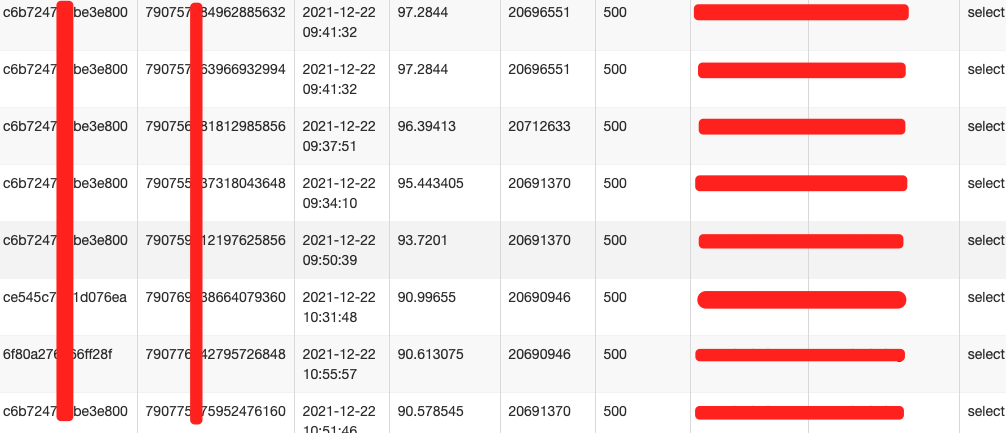
看似比較簡單的查詢,但執行時長平均在90s以上,並且調用頻次較高。如圖3所示。
開始檢查表信息,可以看到表數據量在2100w左右。

排查索引情況,主鍵為id,並且有business_day與full_ps_code的聯合索引。
PRIMARY KEY (`id`) USING BTREE, KEY `idx_business_day_full_ps_code` (`business_day`,`full_ps_code`) ==========以下索引可以忽略======== KEY `idx_erp_month_businessday` (`erp`,`month`,`business_day`), KEY `idx_business_day_erp` (`business_day`,`erp`), KEY `idx_erp_month_ps_plan_id` (`erp`,`month`,`ps_performance_plan_id`), ......
通過Explain查看執行計劃時發現,possible_keys中包含上面的聯合索引,而Key卻選擇了Primary主鍵索引,掃描行數Rows為1700w,幾乎等於全表掃描。

2.4 解決問題
第一次,我們分析是,由於Where條件中包含了ID,查詢分析器認為主鍵索引掃描行數會少,同時根據主鍵排序,使用主鍵索引會更加合理,我們試著添加以下索引,想要讓查詢分析器命中我們新加的索引。
ADD INDEX `idx_test`(`business_day`, `full_ps_code`, `id`) USING BTREE;
再次通過Explain語句進行分析,發現執行計劃完全沒變,還是走的主鍵索引。
explain SELECT * FROM test WHERE is_delete = 0 AND business_day = '2021-12-20' AND full_ps_code LIKE 'xxx%' AND id > 2100 ORDER BY id LIMIT 500;

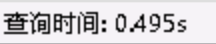
第二次,我們通過強制指定索引方式 force index (idx_test)方式,再次分析執行情況,得到圖7的結果,同樣的查詢條件同樣的結果,查詢時長由90s->0.49s左右。問題得到解決

第三次,我們懷疑是where條件中有ID導致直接走的主鍵索引,where條件中去掉id,Sql調整如下,然後進行分析。依然沒有命中索引,掃描rows變成111342,查詢時間96s
SELECT * FROM test WHERE is_delete = 0 AND business_day = '2021-12-20' AND full_ps_code LIKE 'xxx%' ORDER BY id LIMIT 500


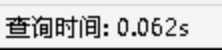
第四次,我們把order by去掉,SQL調整如下,然後進行分析。命中了idx_business_day_full_ps_code之前建立的聯合索引。掃描行數變成154900,查詢時長變為0.062s,但是發現結果與預想的不一致,發生了亂序
SELECT * FROM test WHERE is_delete = 0 AND business_day = '2021-12-20' AND full_ps_code LIKE 'xxx%' AND id > 2100 LIMIT 500;

第五次,經過前幾次的分析可以確定,order by 導致查詢分析器選擇了主鍵索引,我們在Order by中增加排序欄位,將Sql調整如下,同樣可以命中我們之前的聯合索引,查詢時長為0.034s,由於先按照主鍵排序,結果是一致的。相比第四種方法多了一份filesort,問題得解決。
SELECT * FROM test WHERE is_delete = 0 AND business_day = '2021-12-20' AND full_ps_code LIKE 'xxx%' AND id > 2100 ORDER BY id,full_ps_code LIMIT 500;


第六次,我們考慮是不是Limit導致的問題,我們將Limit 500 調整到 1000,Sql調整如下,奇跡發生了,命中了聯合索引,查詢時長為0.316s,結果一致,只不過多返回來500條數據。問題得到瞭解決。經過多次實驗Limit 大於695時就會命中聯合索引,查詢條件下的數據量是79963,696/79963大概占比是0.0087,猜測當獲取數據比超過0.0087時,會選擇聯合索引,未找到源代碼驗證此結論。
SELECT * FROM test WHERE is_delete = 0 AND business_day = '2021-12-20' AND full_ps_code LIKE 'xxx%' AND id > 2100 ORDER BY id LIMIT 1000;


經過我們的驗證,其中第2、5、6三種方法都可以解決性能問題。為了不影響線上,我們立即修改代碼,並選擇了force index 的方式,上線觀察一段時間後,資料庫CPU恢復正常,問題得到瞭解決。
3 事後分析
上線後問題得到瞭解決,同時也留給我了很多疑問。
- 為什麼明明where條件中包含了聯合索引,卻未能命中,反而選擇了性能較慢的主鍵索引?
- 為什麼在order by中增加了一個索引其他欄位,就可以命中聯合索引了呢?
- 為什麼我僅僅是將limit限制條件由原來的500調大後,也能命中聯合索引呢?
這一切的答案都來自MySQL的查詢優化器。
3.1 查詢優化器
查詢優化器是專門負責優化查詢語句的優化器模塊,通過計算分析收集的各種系統統計信息,為查詢給出最優的執行計劃——最優的數據檢索方式。
優化器決定如何執行查詢的方式是基於一種稱為基於代價的優化的方法。5.7在代價類型上分為IO、CPU、Memory。記憶體的代價收集了,但是並沒有參與最終的代價計算。Mysql中引入了兩個系統表,mysql.server_cost和mysql.engine_cost,server_cost對應CPU的代價,engine_cost代表IO的代價。
server_cost(CPU代價)
- row_evaluate_cost (default 0.2) 計算符合條件的行的代價,行數越多,此項代價越大
- memory_temptable_create_cost (default 2.0) 記憶體臨時表的創建代價
- memory_temptable_row_cost (default 0.2) 記憶體臨時表的行代價
- key_compare_cost (default 0.1) 鍵比較的代價,例如排序
- disk_temptable_create_cost (default 40.0) 內部myisam或innodb臨時表的創建代價
- disk_temptable_row_cost (default 1.0) 內部myisam或innodb臨時表的行代價
由上可以看出創建臨時表的代價是很高的,尤其是內部的myisam或innodb臨時表。
engine_cost(IO代價)
- io_block_read_cost (default 1.0) 從磁碟讀數據的代價,對innodb來說,表示從磁碟讀一個page的代價
- memory_block_read_cost (default 1.0) 從記憶體讀數據的代價,對innodb來說,表示從buffer pool讀一個page的代價
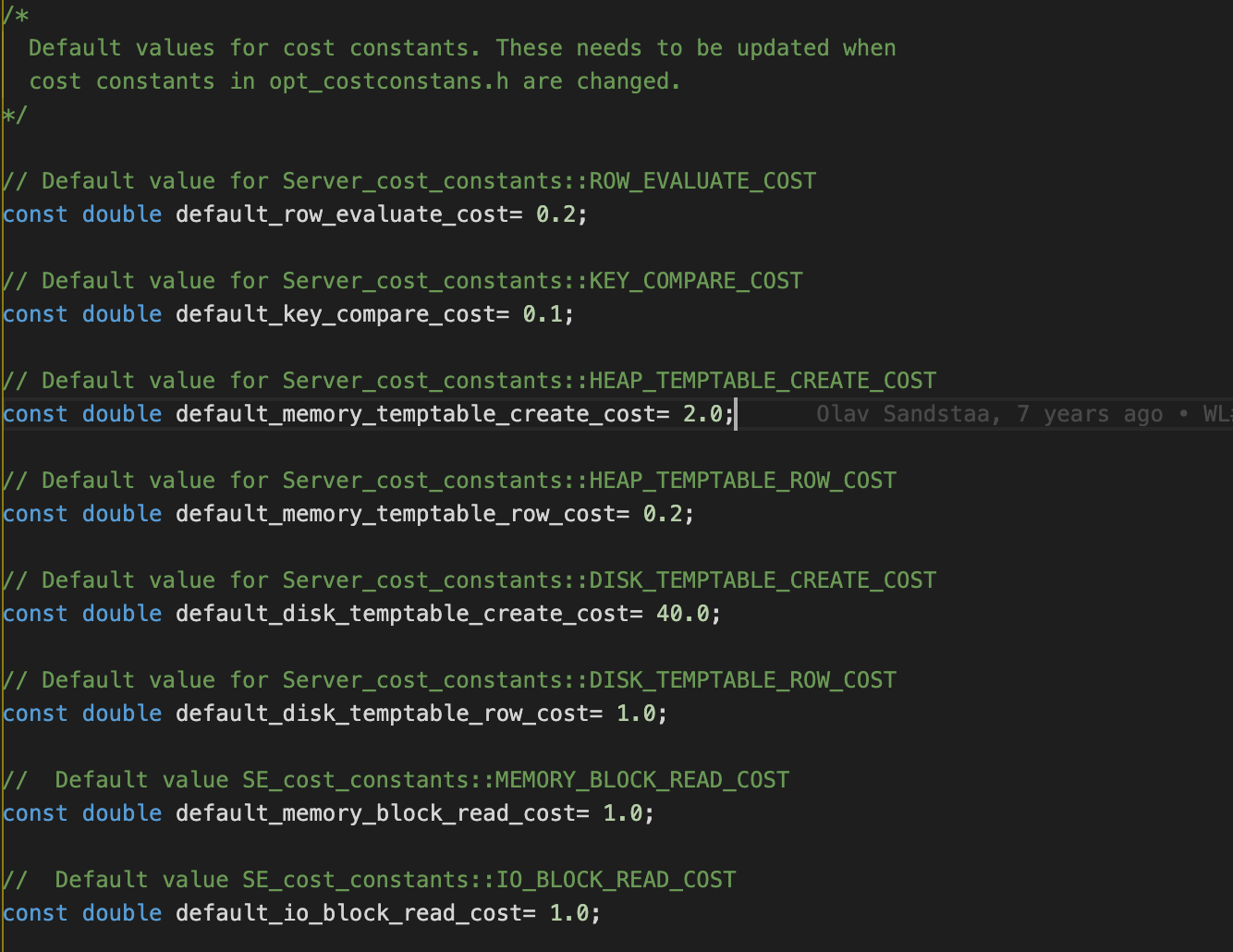
這些信息都可以在資料庫中配置,當資料庫中未配置時,從MySql源代碼(5.7)中可以看到以上預設值情況
3.2 代價配置
--修改io_block_read_cost值為2 UPDATE mysql.engine_cost SET cost_value = 2.0 WHERE cost_name = 'io_block_read_cost'; --FLUSH OPTIMIZER_COSTS 生效,只對新連接有效,老連接無效。 FLUSH OPTIMIZER_COSTS;
3.3 代價計算
代價是如何算出來的呢,通過讀MySql的源代碼,可以找到最終的答案
3.3.1 全表掃描(table_scan_cost)
以下代碼摘自MySql Server(5.7分支),全表掃描時,IO與CPU的代價計算方式。
double scan_time= cost_model->row_evaluate_cost(static_cast<double>(records)) + 1; // row_evaluate_cost 核心代碼 // rows * m_server_cost_constants->row_evaluate_cost() // 數據行數 * 0.2 (row_evaluate_cost預設值) + 1 = CPU代價 Cost_estimate cost_est= head->file->table_scan_cost(); //table_scan_cost 核心代碼 //const double io_cost // = scan_time() * table->cost_model()->page_read_cost(1.0) // 這部分代價為IO部分 //page_read_cost 核心代碼 // //const double in_mem= m_table->file->table_in_memory_estimate(); // // table_in_memory_estimate 核心邏輯 //如果表的統計信息中提供了信息,使用統計信息,如果沒有則使用啟髮式估值計算 //pages=1.0 // //const double pages_in_mem= pages * in_mem; //const double pages_on_disk= pages - pages_in_mem; // // //計算出兩部分IO的代價之和 //const double cost= buffer_block_read_cost(pages_in_mem) + // io_block_read_cost(pages_on_disk); // // //buffer_block_read_cost 核心代碼 // pages_in_mem比例 * 1.0 (memory_block_read_cost的預設值) // blocks * m_se_cost_constants->memory_block_read_cost() // // //io_block_read_cost 核心代碼 //pages_on_disk * 1.0 (io_block_read_cost的預設值) //blocks * m_se_cost_constants->io_block_read_cost(); //返回IO與CPU代價 //這裡增加了個繫數調整,原因未知 cost_est.add_io(1.1); cost_est.add_cpu(scan_time);
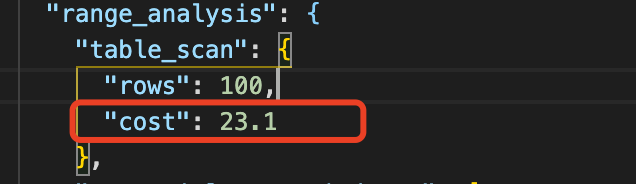
根據源代碼分析,當表中包含100行數據時,全表掃描的成本為23.1,計算邏輯如下
//CPU代價 = 總數據行數 * 0.2 (row_evaluate_cost預設值) + 1 cpu_cost = 100 * 0.2 + 1 等於 21 io_cost = 1.1 + 1.0 等於 2.1 //總成本 = cpu_cost + io_cost = 21 + 2.1 = 23.1
驗證結果如下圖
3.3.2 索引掃描(index_scan_cost)
以下代碼摘自MySql Server(5.7分支),當出現索引掃描時,是如何進行計算的,核心代碼如下
//核心代碼解析 *cost= index_scan_cost(keyno, static_cast<double>(n_ranges), static_cast<double>(total_rows)); cost->add_cpu(cost_model->row_evaluate_cost( static_cast<double>(total_rows)) + 0.01)
io代價計算核心代碼
//核心代碼 const double io_cost= index_only_read_time(index, rows) * table->cost_model()->page_read_cost_index(index, 1.0); // index_only_read_time(index, rows) // 估算index占page個數 //page_read_cost_index(index, 1.0) //根據buffer pool大小和索引大小來估算page in memory和in disk的比例,計算讀一個page的代價
cpu代價計算核心代碼
add_cpu(cost_model->row_evaluate_cost( static_cast<double>(total_rows)) + 0.01); //total_rows 等於索引過濾後的總行數 //row_evaluate_cost 與全表掃描的邏輯類似, //區別在與一個是table_in_memory_estimate一個是index_in_memory_estimate
3.3.3 其他方式
計算代價的方式有很多,其他方式請參考 MySql原代碼。https://github.com/mysql/mysql-server.git
3.4 深度解析
通過查看optimizer_trace,可以瞭解查詢優化器是如何選擇的索引。
set optimizer_trace="enabled=on"; --如果不設置大小,可能導致json輸出不全 set OPTIMIZER_TRACE_MAX_MEM_SIZE=1000000; SELECT * FROM test WHERE is_delete = 0 AND business_day = '2021-12-20' AND full_ps_code LIKE 'xxx%' AND id > 0 ORDER BY id LIMIT 500; select * FROM information_schema.optimizer_trace; set optimizer_trace="enabled=off";
通過分析rows_estimation節點,可以看到通過全表掃描(table_scan)的話的代價是 8.29e6,同時也可以看到該查詢可以選擇到主鍵索引與聯合索引,如下圖。
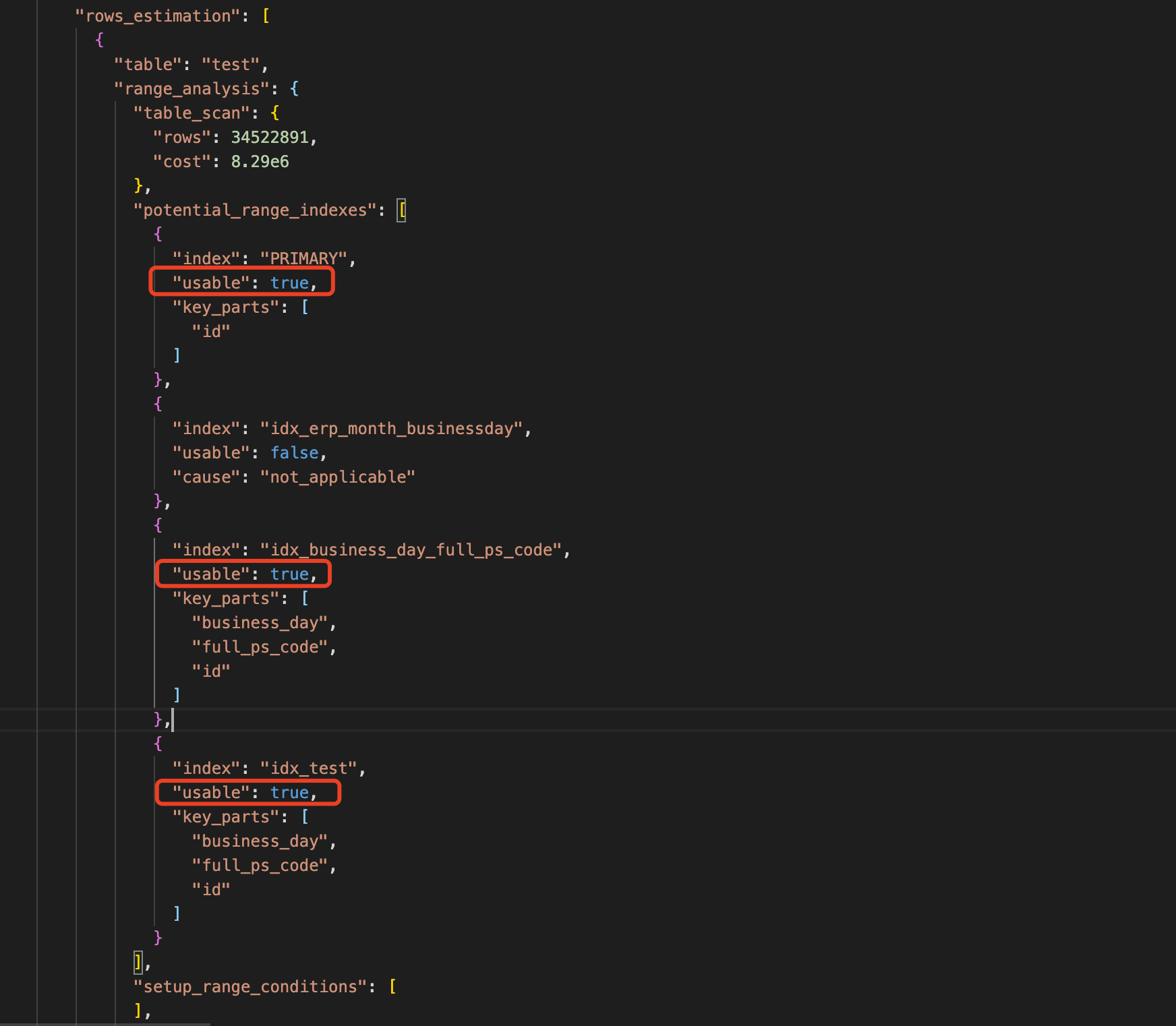
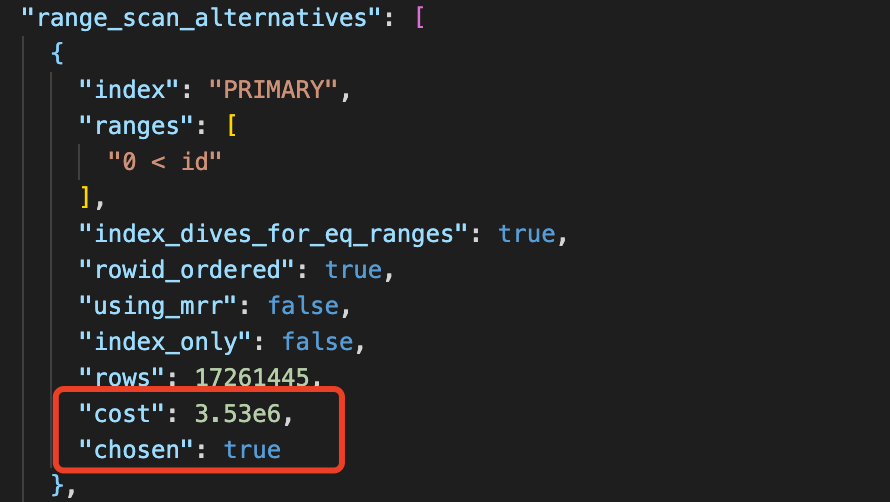
上圖中全表掃描的代價是8.29e6,我們轉換成普通計數法為 8290000,如果使用主鍵索引成本是 3530000,聯合索引 185881,最小的應該是185881聯合索引,也可以看到第一步通過成本分析確實選擇了我們的聯合索引。
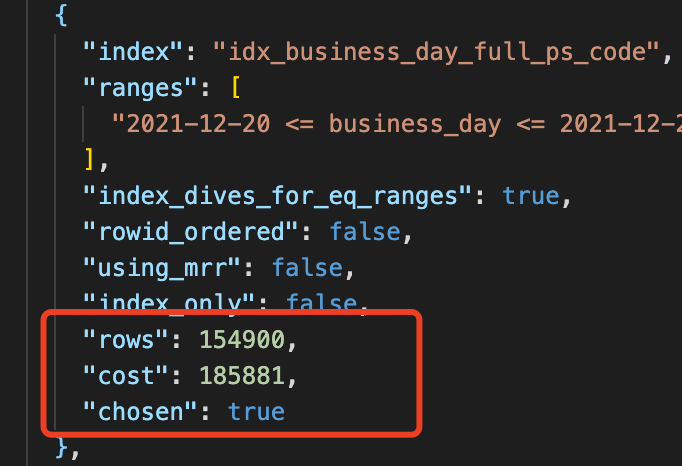
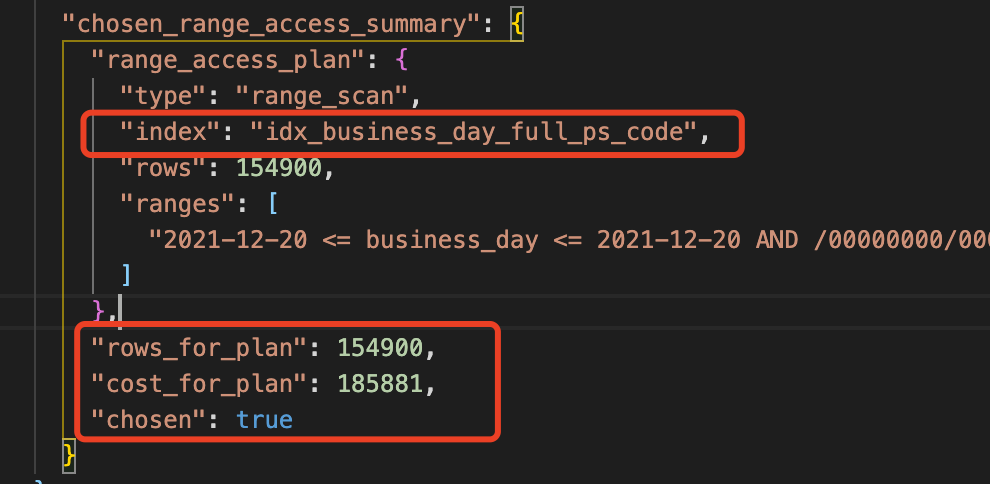
但是為什麼還是選擇了主鍵索引呢?
通過往下看,在reconsidering_access_paths_for_index_ordering節點下, 發現由於Order by 導致重新選擇了索引,在下圖中可以看到主鍵索引可用(usable=true),我們的聯合索引為not_applicable (不適用),意味著排序只能使用主鍵索引。
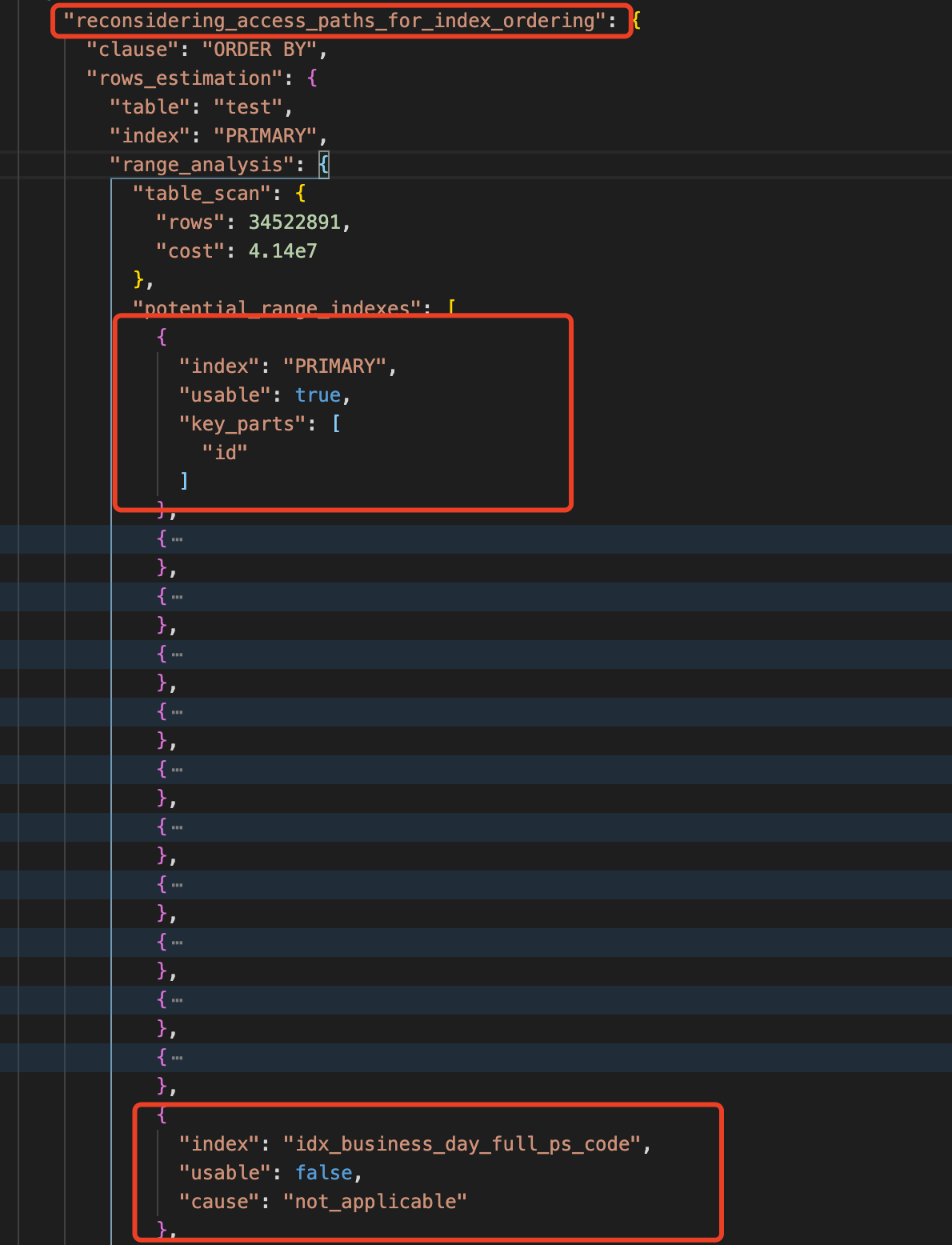
接下來通過index_order_summary可以看出,執行計劃最終被調整,由原來的聯合索引改成了主鍵索引,就是說這個選擇無視了之前的基於索引成本的選擇。
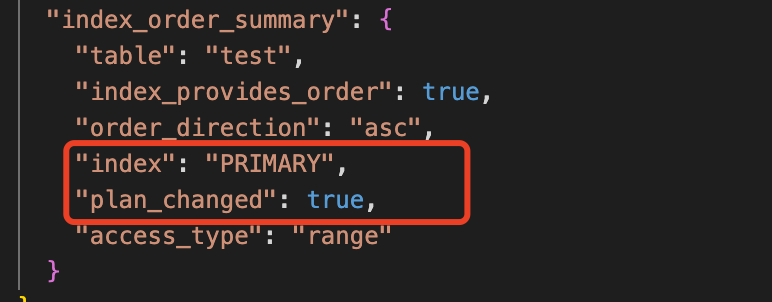
為什麼會有這樣的一個選項呢,主要原因如下:
The short explanation is that the optimizer thinks — or should I say hopes — that scanning the whole table (which is already sorted by the id field) will find the limited rows quick enough, and that this will avoid a sort operation. So by trying to avoid a sort, the optimizer ends-up losing time scanning the table.
從這段解釋可以看出主要原因是由於我們使用了order by id asc這種基於 id 的排序寫法,優化器認為排序是個昂貴的操作,所以為了避免排序,並且它認為 limit n 的 n 如果很小的話即使使用全表掃描也能很快執行完,所以它選擇了全表掃描,也就避免了 id 的排序。
5 總結
查詢優化器會基於代價來選擇最優的執行計劃,但由於order by id limit n的存在,MySql可能會重新選擇一個錯誤的索引,忽略原有的基於代價選擇出來的索引,轉而選擇全表掃描的主鍵索引。這個問題在國內外有大量的用戶反饋,BUG地址 https://bugs.mysql.com/bug.php?id=97001 。官方稱在5.7.33以後版本可以關閉prefer_ordering_index 來解決。如下圖所示。

另外在我們日常慢Sql調優時,可以通過以下兩種方式,瞭解更多查詢優化器選擇過程。
--第一種 explain format=json sql語句 ------------------------------------------------------------------------- --第二種 optimizer_trace方式 set optimizer_trace="enabled=on"; --如果不設置大小,可能導致json輸出不全 set OPTIMIZER_TRACE_MAX_MEM_SIZE=1000000; SQL語句 select * FROM information_schema.optimizer_trace; set optimizer_trace="enabled=off";
當你也出現了本篇文章碰到的問題時,可以採用以下的方法來解決
- 使用force index,強制指定索引。
- order by中增加一個聯合索引的key。
- 擴大limit 返回的範圍(不推薦,隨著數據量的增大,可能還會走回主鍵索引)
- order by (id+0) asc 欺騙查詢優化器,讓其選擇聯合索引。
- MySQL 5.7.33版本以上,可以關閉prefer_ordering_index解決。
作者:陳強

