
眾所周知MySQL聯合索引遵循最左首碼匹配原則,在少數情況下也會不遵循(有興趣,可以翻一下上篇文章)。 創建聯合索引的時候,建議優先把區分度高的欄位放在第一列。 至於怎麼統計區分度,可以按照下麵這種方式。 ...
眾所周知MySQL聯合索引遵循最左首碼匹配原則,在少數情況下也會不遵循(有興趣,可以翻一下上篇文章)。
創建聯合索引的時候,建議優先把區分度高的欄位放在第一列。
至於怎麼統計區分度,可以按照下麵這種方式。
創建一張測試表,用來測試:
CREATE TABLE `test` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`a` int NOT NULL,
`b` int NOT NULL,
`c` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='測試表';
統計每個欄位的區分度:
select
count(distinct a)/count(*),
count(distinct b)/count(*),
count(distinct c)/count(*)
from test;
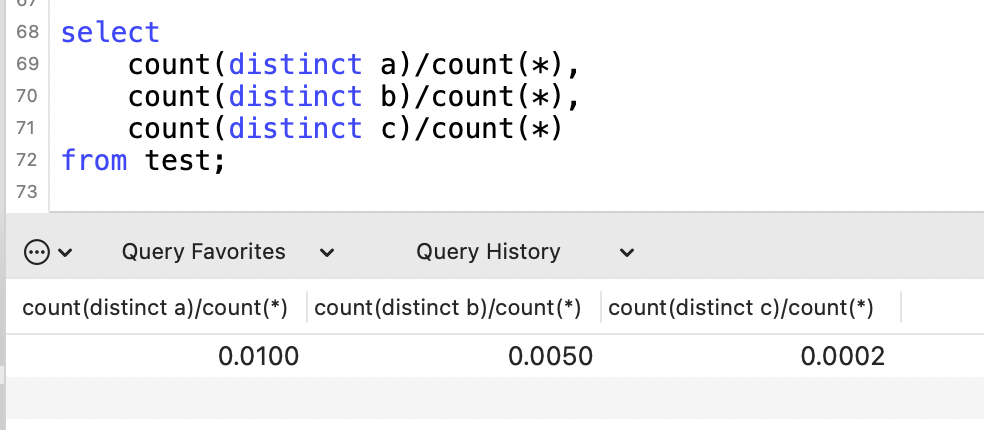
值越大,區分度越高,優先放在第一列。
很多人不知道聯合索引在B+樹中是怎麼存儲的?我簡單畫一下。
比如在(a,b)欄位上面創建聯合索引,存儲結構類似下麵這樣:

葉子節點存儲全部數據,用順序指針相連,數據都是先按a欄位排序,a欄位的值相等時再按b欄位排序。
a欄位的值是全局有序的,分別有1,1,1,2,2,2。
b欄位的值是全局無序的,分別有1,3,5,1,3,5,只有在a欄位的值相等時才呈現出局部有序。
所以在進行SQL查詢的時候,如果where條件中沒有a欄位,只有b欄位,是無法用到索引的,像下麵這樣:
select * from test where b=1;
像有些文章上面說的,在(a,b)兩個欄位上創建聯合索引,就會創建兩個索引,分別是(a)和(a,b),這其實是一種不恰當的表述,雖然結果是對的。
下麵做幾道聯合索引的經典面試題,試一下大家掌握的怎麼樣?
第一題:
下麵這條SQL,該怎麼創建聯合索引?
SELECT * FROM test WHERE a = 1 and b = 1 and c = 1;
你以為的答案是(a,b,c),其實答案是6個,abc三個的排列組合,(a,b,c)、(a,c,b)、(b,a,c)、(b,c,a)、(c,a,b)、(c,b,a)。
MySQL優化器為了適應索引,會調整條件的順序。
再給面試官補充一句,區分度高的欄位放在最前面,大大加分。
第二題:
下麵這條SQL,該怎麼創建聯合索引?
SELECT * FROM test WHERE a = 1 and b > 1 and c = 1;
考察的知識點是: 聯合索引遇到範圍匹配會停止,不會再匹配後面的索引欄位。
所以答案應該是:(a,c,b)和 (c,a,b)。
當創建(a,c,b)和 (c,a,b)索引的時候,查詢會用到3個欄位的索引,效率更高。
怎麼判斷是用到了3個欄位的索引,而不是只用到前兩個欄位的索引呢?
有個非常簡單的方法,看執行計劃的索引長度。

由於int類型的欄位占4個位元組,3個欄位長度剛好是12個位元組。
第三題:
下麵這條SQL,該怎麼創建聯合索引?
SELECT * FROM test WHERE a in (1,2,3) and b > 1;
答案是(a,b)。in條件查詢會被轉換成等值查詢,可以驗證一下:

可以看到用到了兩個欄位的索引。
所以我們在平時做開發,儘量想辦法把範圍查詢轉換成in條件查詢,效率更高。
> 文章持續更新,可以微信搜一搜「 一燈架構 」第一時間閱讀更多技術乾貨。


