
StoneDB 的整體架構分為三層,分別是應用層、服務層和存儲引擎層。應用層主要負責客戶端的連接管理和許可權驗證;服務層提供了 SQL 介面、查詢緩存、解析器、優化器、執行器等組件;Tianmu 引擎所在的存儲引擎層是 StoneDB 的核心,數據的組織和壓縮、以及基於知識網格的查詢優化均是在 Tia ...
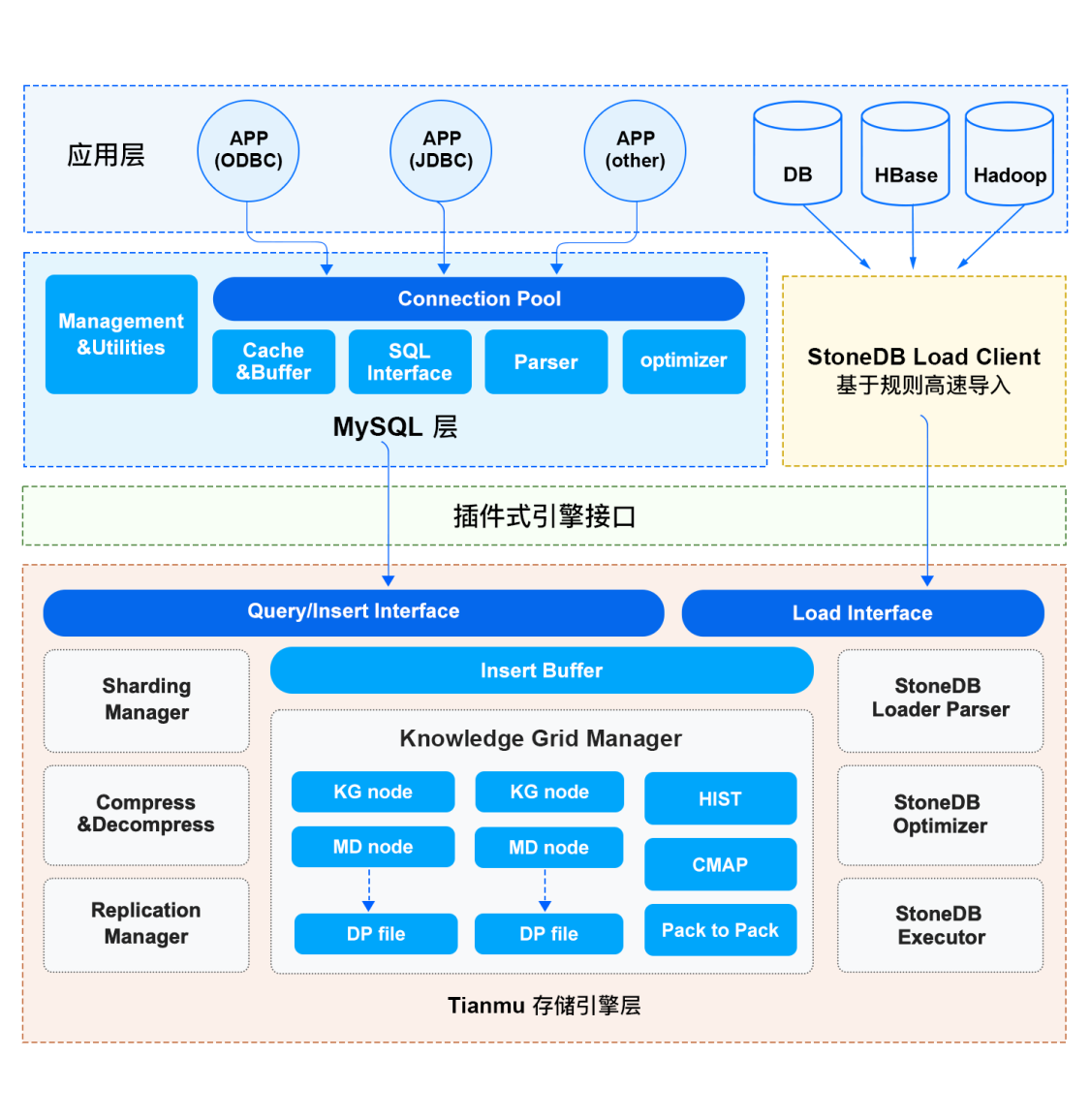
StoneDB 的整體架構分為三層,分別是應用層、服務層和存儲引擎層。應用層主要負責客戶端的連接管理和許可權驗證;服務層提供了 SQL 介面、查詢緩存、解析器、優化器、執行器等組件;Tianmu 引擎所在的存儲引擎層是 StoneDB 的核心,數據的組織和壓縮、以及基於知識網格的查詢優化均是在 Tianmu 引擎實現。下麵為大家詳細介紹 StoneDB 整體架構中的主要特性。
列式存儲
StoneDB 創建的表在磁碟上是以列模式進行存儲的,由於關係型資料庫中每一列的數據類型都相同,所以這種連續的空間存儲與行式存儲相比,更加能夠實現數據的高壓縮比。在讀取數據方面,如果只想查詢一個欄位的結果,在行式存儲中,引擎層向服務層返回的是一整行的數據,需要消耗更多的網路帶寬和 IO。而列式存儲只需要返回一個欄位,極大減少了網路帶寬和 IO 的消耗。另外,列式存儲無需再為列創建索引和維護索引。
| id | name | age |
|---|---|---|
| 1 | Jack | 37 |
| 2 | Rose | 18 |
| 3 | Jason | 26 |

數據壓縮
上面提到同一數據類型的列存儲在一起,能夠實現數據的高壓縮比。StoneDB 會根據不同的數據類型選擇不同的壓縮演算法,目前支持的壓縮演算法主要有 PPM、LZ4、B2、Delta 等。數據被壓縮後,數據量變得更小,在讀取數據時,對網路帶寬和磁碟 IO 的壓力也就越小。由於列式存儲相比行式存儲有十倍甚至更高的壓縮比,StoneDB 可以節省大量的存儲空間,降低存儲成本。
知識網格管理
當表的數據量達到千萬、億級,在做統計分析類查詢時,使用 MySQL 的 InnoDB 存儲引擎或其它關係型資料庫的行式存儲引擎可能需要幾分鐘到幾十分鐘才能得到結果集。這是因為基於成本的優化器需要根據表或者索引的統計信息生成執行計劃,然後再去讀取數據,中間過程會發生 IO,如果統計信息不准,生成了一個錯誤的執行計劃,那麼可能會發生更多的 IO。而 StoneDB 的 Tianmu 引擎在相同的數據量下,比 MySQL 的 InnoDB 存儲引擎或或其它關係型資料庫的行式存儲引擎要快數十倍。Tianmu 引擎除了列式存儲、數據壓縮特性外,還有知識網格技術。在瞭解知識網格前,需要瞭解以下幾個基本概念。
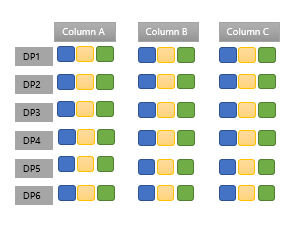
Data Pack
數據包用於存放實際數據,是最底層的數據存儲單元,每列按照65536行切分成一個數據包。每個數據包比列更小,具有更高的壓縮比,而每個數據包又比每行更大,具有更好的查詢性能。數據包是知識網格的解壓縮單元。
粗糙集是一門數學學科,用來研究不完整的數據,不精確的知識表達、學習、歸納等的一套理論。在 StoneDB 中,粗糙集用於對數據包的劃分,根據 SQL 的查詢條件的數據在數據包中的確認範圍,數據包分為以下幾類:
1)不相關的數據包:表示不滿足查詢條件的數據包,這類數據包直接被忽略。
2)相關的數據包:表示滿足查詢條件的數據包,如果要查詢相關的數據包裡面的具體數據,需要對數據包進行解壓縮,如果根據數據包的元數據節點就能得到數據,那麼就不需要解壓縮數據包。
3)可疑的數據包:表示數據包中的數據部分滿足查詢條件,需要進一步解壓縮數據包才能得到滿足條件的數據。
Data Pack Node
數據包節點也稱為元數據節點,記錄了每個數據包中列的最大值、最小值、平均值、總和、總記錄數、null值的數量、壓縮方式、占用的位元組數。每一個元數據節點對應一個數據包。
Knowledge Node
元數據節點的上一層是知識節點,除了記錄數據包之間或者列之間關係的元數據集合,比如數據包的最小值與最大值範圍、列之間的關聯關係外,還記錄了數據特征以及更深度的統計信息。大部分的知識節點數據是裝載數據的時候產生的,另外一部分是查詢的時候產生的。
知識節點的3種基本類型:
1)Histogram
數據類型為整型、日期型、浮點型的列的統計值以直方圖的形式存在。將一個數據包的最小值到最大值之間分為1024段,每段占用一個 bit,如果數據包中的實際值處於段中的範圍,則標記為1,否則標記為0。Histogam 在數據被載入時自動創建。
如下的例子中,說明數據包中有值落在0100和102301102400兩個區間。
| 0‒100 | 101‒200 | 201‒300 | ... | 102301‒102400 |
|---|---|---|---|---|
| 1 | 0 | 0 | ... | 1 |
如果想要執行以下 SQL:
select * from table where id>199 and id<299;
通過直方圖可知,這個查詢沒有在這個數據包命中,即當前數據包不滿足查詢條件,這個數據包直接被丟棄。
2)Character Map
數據類型為字元串的列的字元映射表。統計當前數據包內 1~64 長度中 ASCII 字元是否存在。如果存在,則標記為1,否則標記為0。字元檢索時,按照字元順序依次對比字元標識值即可知道該數據包是否包含匹配數據。Character Map 在數據被載入時自動創建。
如下的例子中,說明 A 在字元串的第1個和第64個位置。
| Char/Char pos | 1 | 2 | ... | 64 |
|---|---|---|---|---|
| A | 1 | 0 | ... | 1 |
| B | 0 | 1 | ... | 0 |
| C | 1 | 1 | ... | 1 |
| ... | ... | ... | ... | ... |
3)Pack to Pack
包對包關係表示不同表的兩個列之間的等值映射表,並以二進位矩陣的形式進行存儲,如果符合表關聯條件,則標記為1,否則標記為0。包對包關係能幫助在表關聯查詢的時候快速判斷出符合查詢條件的數據包,從而提升表關聯查詢的效率。表關聯查詢時,Pack to Pack 被自動創建。
如下的例子中,表關聯的查詢條件是"A.C=B.D",在 A.C1 這個數據包中,只有 B.D2 和 B.D5 這兩個數據包中有符合表關聯條件的值。
| B.D1 | B.D2 | B.D3 | B.D4 | B.D5 | |
|---|---|---|---|---|---|
| A.C1 | 0 | 1 | 0 | 0 | 1 |
| A.C2 | 1 | 1 | 0 | 0 | 0 |
| A.C3 | 1 | 1 | 0 | 1 | 1 |
Knowledge Grid
知識網格由元數據節點和知識節點組成,在做統計分析類查詢時,StoneDB 根據知識網格技術過濾掉不相關的數據包,如果只剩下相關數據包,那麼只需要讀取元數據就能返回查詢結果。這樣就消除瞭解壓縮數據包的過程和降低 IO 消耗,提高了查詢響應時間和網路利用率。
接下來,我們通過一個例子來理解一個查詢語句在存儲引擎層使用知識網格技術的查詢優化過程。
有如下的查詢語句和數據包節點的數據值分佈範圍。
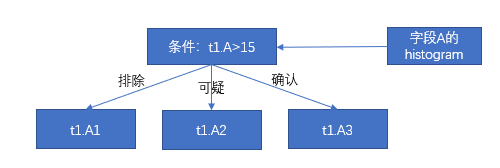
select min(t2.D) from t1,t2 where t1.B=t2.C and t1.A>15;
| Min. | Max. | |
|---|---|---|
| t1.A1 | 1 | 9 |
| t1.A2 | 10 | 30 |
| t1.A3 | 40 | 100 |
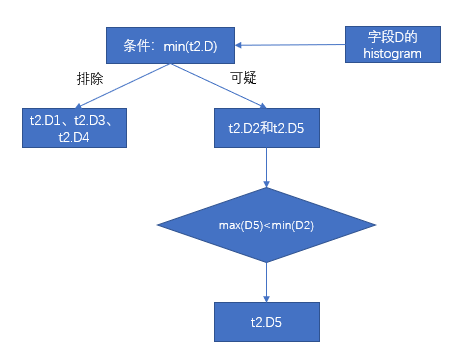
- 根據列 A 的 DPN 可知,t1.A1 屬於不相關的數據包,t1.A2 屬於可疑的數據包,t1.A3 屬於相關的數據包,這一步就過濾掉數據包 t1.A1。
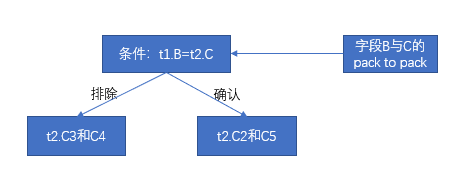
| t2.C1 | t2.C2 | t2.C3 | t2.C4 | t2.C5 | |
|---|---|---|---|---|---|
| t1.B1 | 1 | 1 | 1 | 0 | 1 |
| t1.B2 | 0 | 1 | 0 | 0 | 0 |
| t1.B3 | 1 | 1 | 0 | 0 | 1 |
- 第一步已經過濾掉數據包 t1.A1,這一步就不需要對 t1.B1 和 t2.C1 做關聯對比,根據包對包關係的映射表可知,這一步過濾掉數據包 t2.C3 和 t2.C4。那麼滿足關聯條件的數據包有 t2.C2 和 t2.C5。
| Min. | Max. | |
|---|---|---|
| t2.D1 | 0 | 500 |
| t2.D2 | 101 | 440 |
| t2.D3 | 300 | 6879 |
| t2.D4 | 1 | 432 |
| t2.D5 | 3 | 100 |
- 第一步和第二步已經過濾掉 D1、D3、D4,那麼只剩下 D2 和D5,根據列 D 的 DPN 可知,D5 的最大值100小於 D2 的最小值101,這一步過濾掉數據包 D2。最後只剩下數據包 D5,根據元數據得到 D5 的最小值3。
高性能導入
StoneDB 提供獨立的數據導入客戶端,支持不同的數據源環境,支持多語言架構。數據在導入前,首先會進行預處理,如數據壓縮和知識節點的構建。數據經過預處理後,進入存儲引擎無需再次執行解析、數據驗證以及事務處理等操作。
於StoneDB的任何問題,都可以加我V咨詢:StoneDB_2022 。

