MySQL刪除數據的方式 以MySQL 5.7為例,資料庫刪除數據的方式一共有以下三種: delete truncate drop 以上三種方式都可以刪除數據,但是使用場景是不同的。 對於整個表進行刪除的執行速度來說: drop > truncate >> delete MySQL刪除數據的方式-d ...
MySQL刪除數據的方式
以MySQL 5.7為例,資料庫刪除數據的方式一共有以下三種:
- delete
- truncate
- drop
以上三種方式都可以刪除數據,但是使用場景是不同的。
對於整個表進行刪除的執行速度來說:
drop > truncate >> delete
MySQL刪除數據的方式-delete
delete是屬於資料庫的DML操作語言,一般是根據條件逐行進行刪除。
使用delete刪除數據時,資料庫只能刪除數據不能刪除表的結構,並且會觸發資料庫的事務機制。
delete執行時,會先將所刪除數據緩存到rollback segment中,事務commit之後生效;
在InnoDB中,使用delete其實並不會真正的把數據刪除,是一種邏輯刪,資料庫底層實際上只是給刪除的數據做了一個已刪除的標記,因此,刪除數據後的表占空間大小和刪除前是一樣的.
MySQL刪除數據的方式-drop
drop屬於資料庫DDL定義語言,同 truncate ,執行後立即生效,無法找回。
drop table table_name立刻釋放磁碟空間 ,drop 語句將刪除表的結構、被依賴的約束(constraint)、觸發器(trigger)、索引(index); 依賴於該表的存儲過程/函數將保留,但是變為 invalid 狀態。
刪除數據的方式-TianMu 引擎的支持情況
目前StoneDB的TianMu引擎是支持 truncate 語句 和 drop 語句的,但是delete語句目前還不支持。
TianMu引擎需要不需要delete?
TianMu引擎設計的初衷
TianMu是一個列式存儲引擎,列式存儲的出現主要是為了方便快捷查詢和高效存儲大量同類型的數據而設計的,主要使用場景就是OLAP場景。下麵是OLAP場景的部分關鍵特征:
①絕大多數是讀請求
②數據以相當大的批次(> 1000行)更新,而不是單行更新;或者根本沒有更新。
③已添加到資料庫的數據不能修改。
④對於讀取,從資料庫中提取相當多的行,但只提取列的一小部分。
⑤列中的數據相對較小:數字和短字元串(例如,每個URL 60個位元組)
⑥處理單個查詢時需要高吞吐量(每台伺服器每秒可達數十億行)
⑦事務不是必須的
⑧對數據一致性要求低
目前行業現狀
| 支持列存儲的資料庫類型 | 是否支持delete | 備註 |
|---|---|---|
| MariaDB ColumnStore | 支持 | |
| SQL Server | 支持 | |
| Oracle In-Memory Column Store | 支持 | |
| DB2 BLU Acceleration | 支持 | |
| MySQL HeatWave | 不支持 | 主要作為輔助引擎,支持DML同步 |
| TiFlash | 不支持 | 主要作為輔助引擎,支持DML同步 |
| PolarDBIn-Memory Column Index | 支持 | |
| openGauss | 支持 | |
| ClickHouse | 支持 | 非標準的DELETE操作 |
OLAP場景下 對於數據的delete的操作可以說沒有或者頻率很小,同時列式存儲對比行式存儲來說並不擅長數據的增刪改,如果是為了極致的查詢性能,完全可以捨棄 DML 操作。但是為了功能的完整性,提升產品的競爭力,目前我們也放開了 insert 和 單表的 update 的功能,delete功能暫時還不支持,未來我們將對改功能進行支持。
主流列式資料庫的delete方案
本節主要講以下三種列式存儲資料庫的delete方案:
•openGauss
•ClickHouse
•PolarDB
openGauss 列存儲引擎的方案
底層存儲結構
openGauss底層存儲結構與stonedb類似 ,存儲基本單位是CU(Compression Unit,壓縮單元),即表中一列的一部分數據組成的壓縮數據塊。行存引擎中是以行作為單位來管理,而當使用列存儲時,整個表整體被按照不同列劃分為若幹個CU。

CU文件本身結構,則如下圖所示。
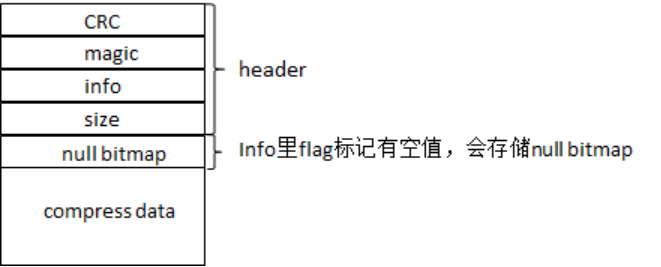
每個CU對應一個CU Desc的記錄,在CU desc里記錄了整個CU的事務時間戳信息、CU的大小、存儲位置、magic校驗碼、min/max等信息。

每張列存表還配有一張Delta表,Delta表自身為行存儲表。當有少量的數據插入到一張列存表時,數據會被暫時放入Delta表,等到到達閾值或滿足一定條件或操作時再行整合為CU文件。Delta表可以避免單點數據操作帶來的很重的CU操作與開銷。
刪除策略
- 列存儲的CU中數據的刪除,實際上是標記刪除。刪除操作,相當於是更新了CUDesc表中CU對應CUDesc記錄的delete bitmap(刪除點陣圖)結構,標記列中某行對應數據已被刪除,而CU文件數據不會被更改。這樣可以避免刪除操作帶來的IO放大以及解壓、壓縮的高額CPU開銷。這樣的設計,也可以使得對於同一個CU的select(查詢)和delete(刪除)互不阻塞,提升併發能力。列存儲CU中數據更新,則是遵循append-only(僅允許追加)原則的,即CU文件僅會向後進行延展擴充,亦或是啟用新的CU文件,而不是在對應行在CU中的位置就地更新。
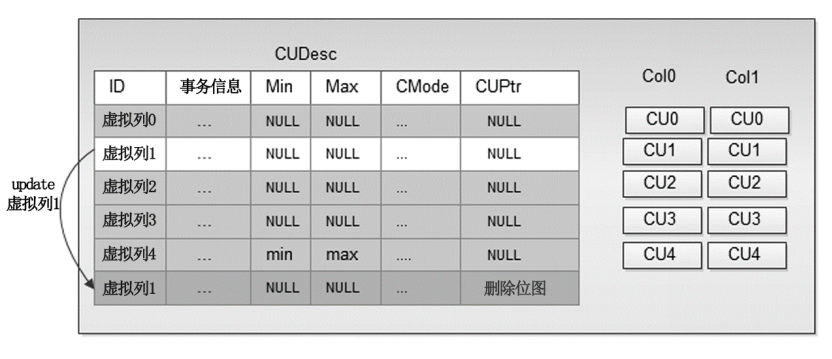
失效空間的清理
- 由於CU以及CUDesc的元數據管理模式,原有系統中的Vacuum機制實際上並不會非常有效的清除CU中已經失效的存儲空間,因為Lazy Vacuum(清理數據時,只是標識無用行的狀態可以錄入新數據,不會影響對錶數據的操作)僅能在CUDesc級別進行操作,在多數場景下無法對CU文件本身進行清理。列存儲內部如果要對列存數據表進行清理,需要執行Vacuum Full(除了清理無用行,還會合併數據塊,整個過程會鎖定表)操作。
ClickHouse delete 方案
特點:缺少高頻率,低延遲的修改或刪除已存在數據的能力。僅能用於批量刪除或修改數據。
數據有序存儲
ClickHouse支持在建表時,指定將數據按照某些列進行sort by。排序後,保證了相同sort key的數據在磁碟上連續存儲,且有序擺放。在進行等值、範圍查詢時,where條件命中的數據都緊密存儲在一個或若幹個連續的Block中,而不是分散的存儲在任意多個Block, 大幅減少需要IO的block數量。另外,連續IO也能夠充分利用操作系統page cache的預取能力,減少page fault。
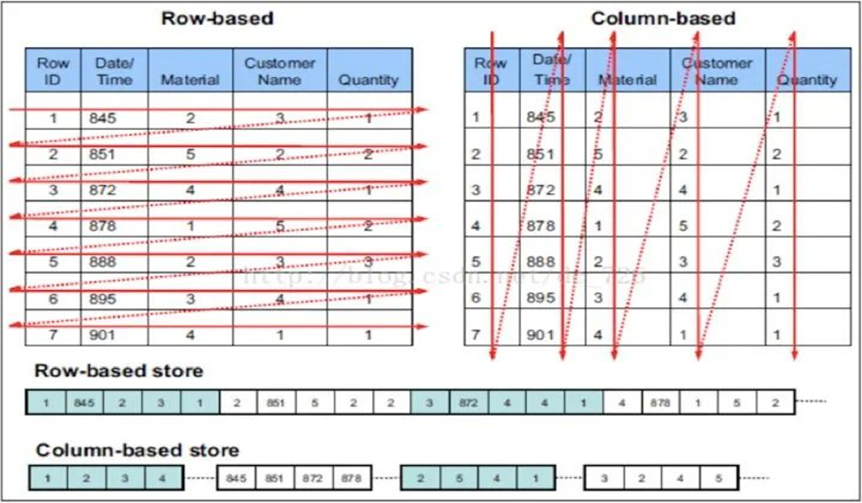
delete 策略
ClickHouse是個分析型資料庫。
OLAP場景下,數據一般是不變的,因此ClickHouse對update、delete的支持是比較弱的,實際上並不支持標準的update、delete操作。
ClickHouse通過alter方式實現更新、刪除,它把update、delete操作叫做mutation(突變)。
標準SQL的更新、刪除操作是同步的,即客戶端要等服務端返回執行結果(通常是int值);
而ClickHouse的update、delete是通過非同步方式實現的,當執行update語句時,服務端立即返回,但是實際上此時數據還沒變,而是排隊等著。
Mutation具體過程
首先,使用where條件找到需要修改的分區;然後,重建每個分區,用新的分區替換舊的,分區一旦被替換,就不可回退;對於單獨一個分區,是原子性的;但對於整個mutation,如果涉及多個分區,則不是原子性的。
PolarDB In-Memory Column Index
特點:PolarDB將列存實現為InnoDB的二級索引
在PolarDB中所有Primary Index和Secondary Index都實現為一個B+Tree。列索引在定義上是一個Index,但其實是一個虛擬的索引,用於捕獲對該索引覆蓋列的增刪改操作。
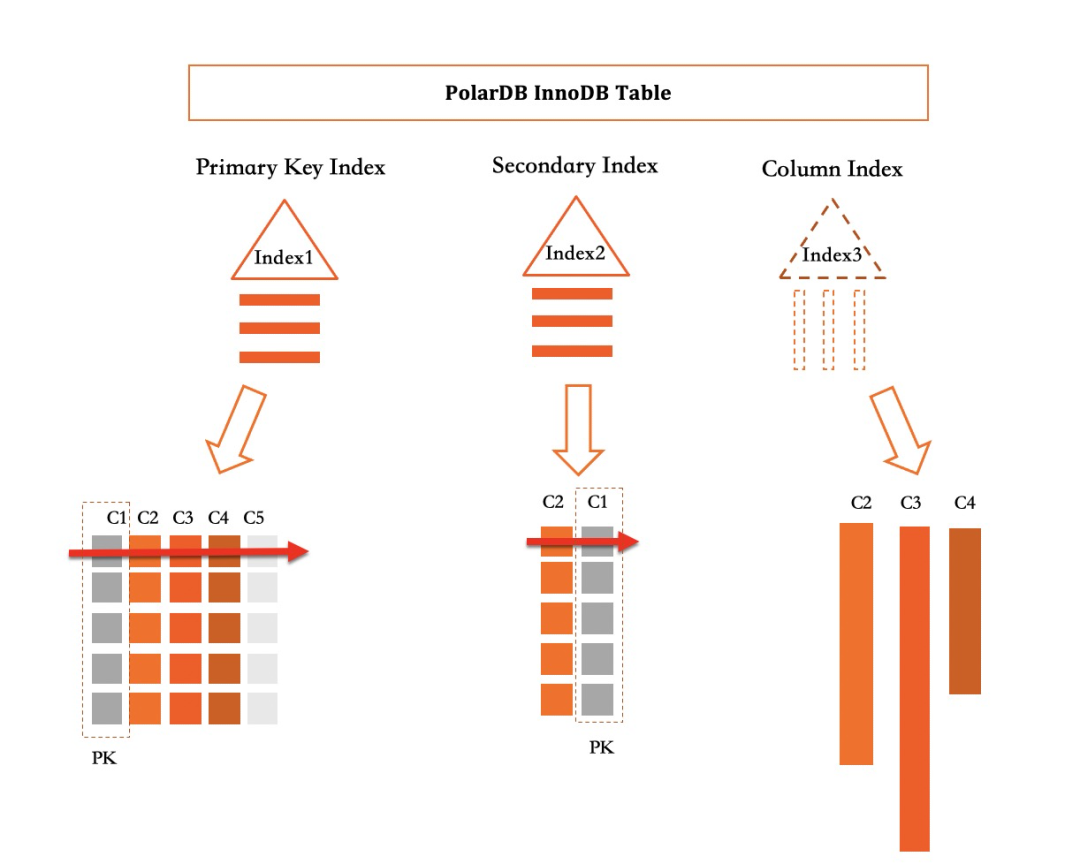
如上圖所示,在PolarDB中所有Primary Index和Secondary Index都實現為一個B+Tree。而列索引在定義上是一個Index,但其實是一個虛擬的索引,用於捕獲對該索引覆蓋列的增刪改操作。
對於上面的表其主表(Primary Index)包含(C1,C2,C3,C4,C5) 5列數據, Seconary Index索引包含(C2,C1) 兩列數據, 在普通二級索引中,C2與C1編碼成一行保存在B+tree中。而其中的列存索引包含(C2,C3,C4)三列數據. 在實際物理存儲時,會對三列進行拆分獨立存儲,每一列都會按寫入順序轉成列存格式。
列存實現為二級索引的另一個好處是執行器的工程實現非常簡單,在MySQL中已經存在覆蓋索引的概念,即一個查詢所需要的列都在一個二級索引中存儲,則可以直接利用這個二級索引中的數據滿足查詢需求,使用二級索引相對於使用Primary Index可以極大減少讀取的數據量進而提升查詢性能。當一個查詢所需要的列都被列索引覆蓋時,藉助列存的加速作用,可以數十倍甚至數百倍的提升查詢性能。
實現為InnoDB二級索引方案的優點:
1.查詢執行器的工程實現非常簡單
2.可以復用InnoDB的事務處理框架
3.可以復用InnoDB的數據編碼格式
4.DDL語句操作非常靈活
5.可以復用InnoDB的Redo事務日誌模塊
6.二級索引與主表有一樣的生命周期,方便管理
列存數據組織
對ColumnIndex中每一列,其存儲都使用了無序且追加寫的格式,結合標記刪除及後臺非同步compaction實現空間回收。其具體實現上有如下幾個關鍵點:
列索引中記錄按RowGroup進行組織,每個RowGroup中不同的列會各自打包形成DataPack。
每個RowGroup都採用追加寫,分屬每個列的DataPack也是採用追加寫模式。對於一個列索引,只有個Active RowGroup負責接受新的寫入。當該RowGroup寫滿之後即凍結,其包含的所有Datapack會轉為壓縮格保存到磁碟上,同時記錄每個數據塊的統計信息便於過濾。
列存RowGroup中每新寫入一行都會分配一個RowID用作定位,屬於一行的所有列都可以用該RowID計算定位,同時系統維護PK到RowID的映射索引,以支持後續的刪除和修改操作。
刪除操作只需要設置一個刪除標記位。
更新操作採用標記刪除的方式來支持,對於更新操作,首先根據RowID計算出其原始位置並設置刪除標記,然後在ActiveRowGroup中寫入新的數據版本。
當一個RowGroup中的無效記錄超過一定閾值,則會觸發後臺非同步compaction操作,其作用一方面是回收空間,另一方面可以讓有效數據存儲更加緊湊,提升分析型查詢單的效率。
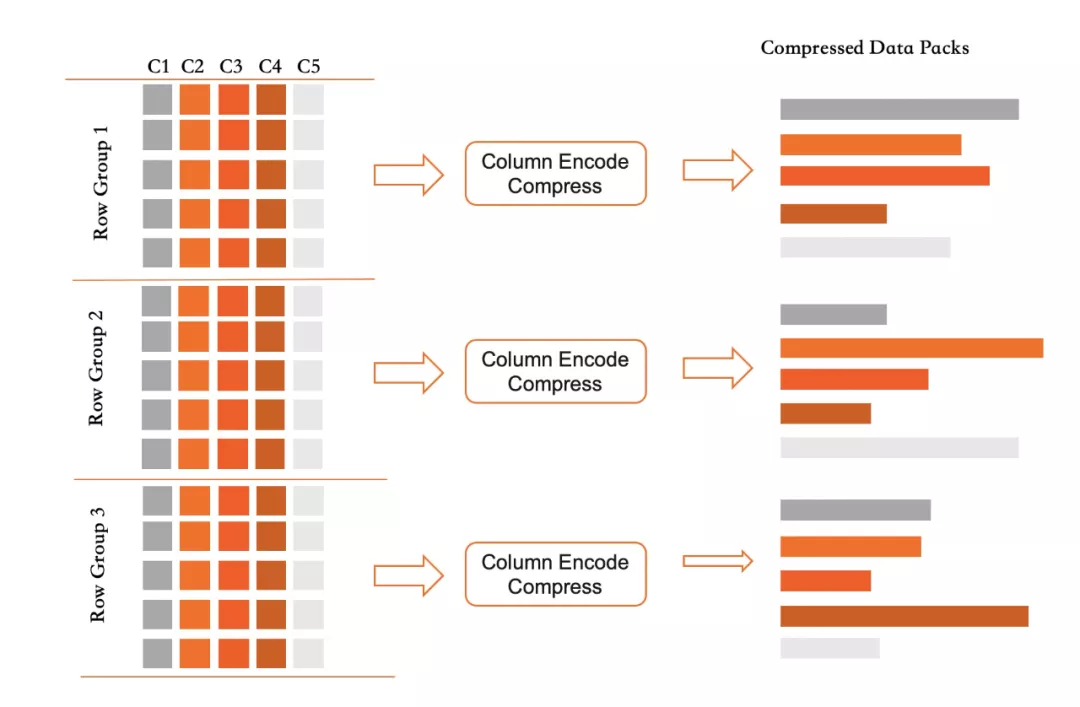
delete 策略
刪除操作只需要設置一個刪除標記位。
更新操作採用標記刪除的方式來支持,對於更新操作,首先根據RowID計算出其原始位置並設置刪除標記,然後在ActiveRowGroup中寫入新的數據版本。
當一個RowGroup中的無效記錄超過一定閾值,則會觸發後臺非同步compaction操作,其作用一方面是回收空間,另一方面可以讓有效數據存儲更加緊湊,提升分析型查詢的效率。
各列式存儲的delete方案彙總
| 支持列存儲的資料庫類型 | 存儲結構 | Delete策略 |
|---|---|---|
| MariaDB ColumnStore | 固定大小的數據塊+元數據 | 標記刪除 |
| SQL Server | 列存儲索引+行組+列段 | 標記刪除 |
| PolarDB In-Memory Column Index | 列存儲索引+RowGroup+DataPack+元數據 | 標記刪除 |
| openGauss | 元數據+數據包 | 標記刪除 |
| ClickHouse | 有序存儲+分區數據包 | 新建分區替換 |
TianMu引擎 delete 功能規劃
GitHub issue 鏈接:
https://github.com/stoneatom/stonedb/issues/343
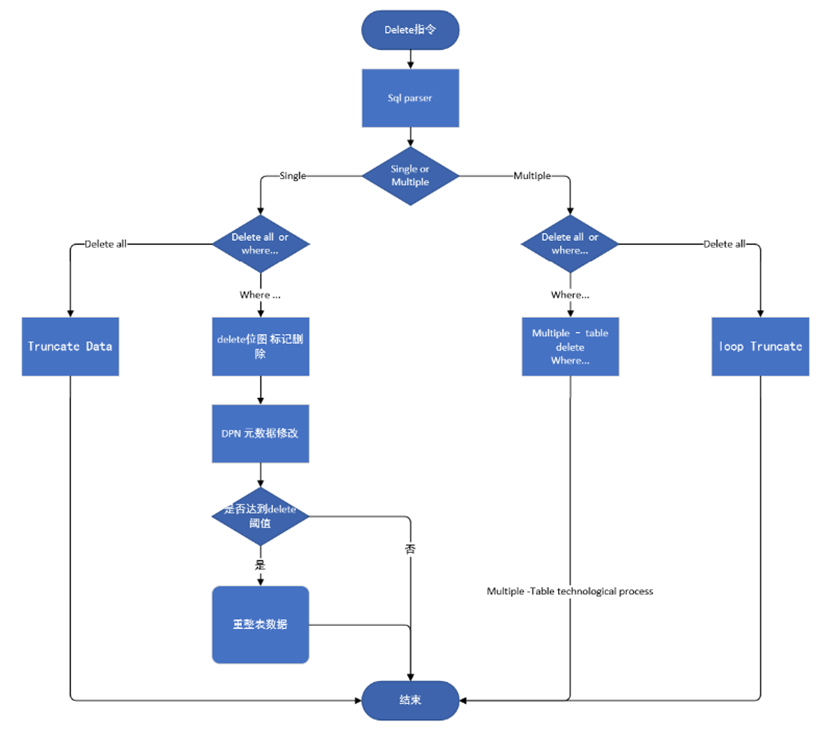
TianMu引擎 delete 功能實現流程圖