
1、導入模塊 import requests import csv from concurrent.futures import ThreadPoolExecutor 2、先獲取第一個頁面的內容 分析得到該頁面的數據是從getPriceData.html頁面獲取,並保存在csv文件中 得到url地址 ...
1、導入模塊
import requests
import csv
from concurrent.futures import ThreadPoolExecutor
2、先獲取第一個頁面的內容
分析得到該頁面的數據是從getPriceData.html頁面獲取,並保存在csv文件中
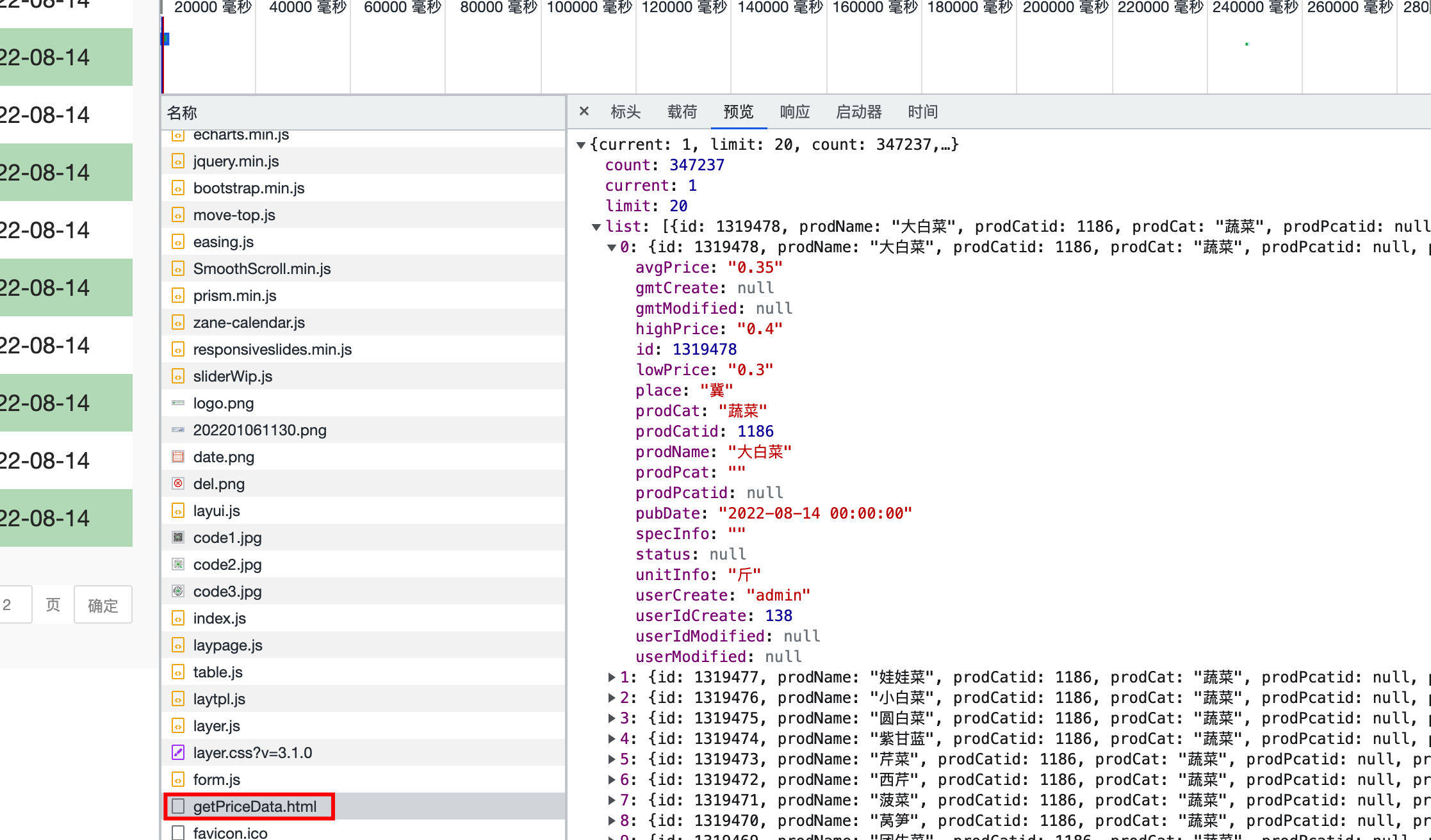
得到url地址後,提取第一個頁面內容
def download(url, num):
resp = requests.post(url).json()
for i in resp['list']:
temp = [i['prodName'], i['lowPrice'], i['highPrice'], i['avgPrice'], i['place'], i['unitInfo'], i['pubDate']]
csvwrite.writerow(temp)
if __name__ == "__main__":
url = 'http://www.xinfadi.com.cn/getPriceData.html'
download(url)
print('success')
** 此為第一個頁面信息提取:**
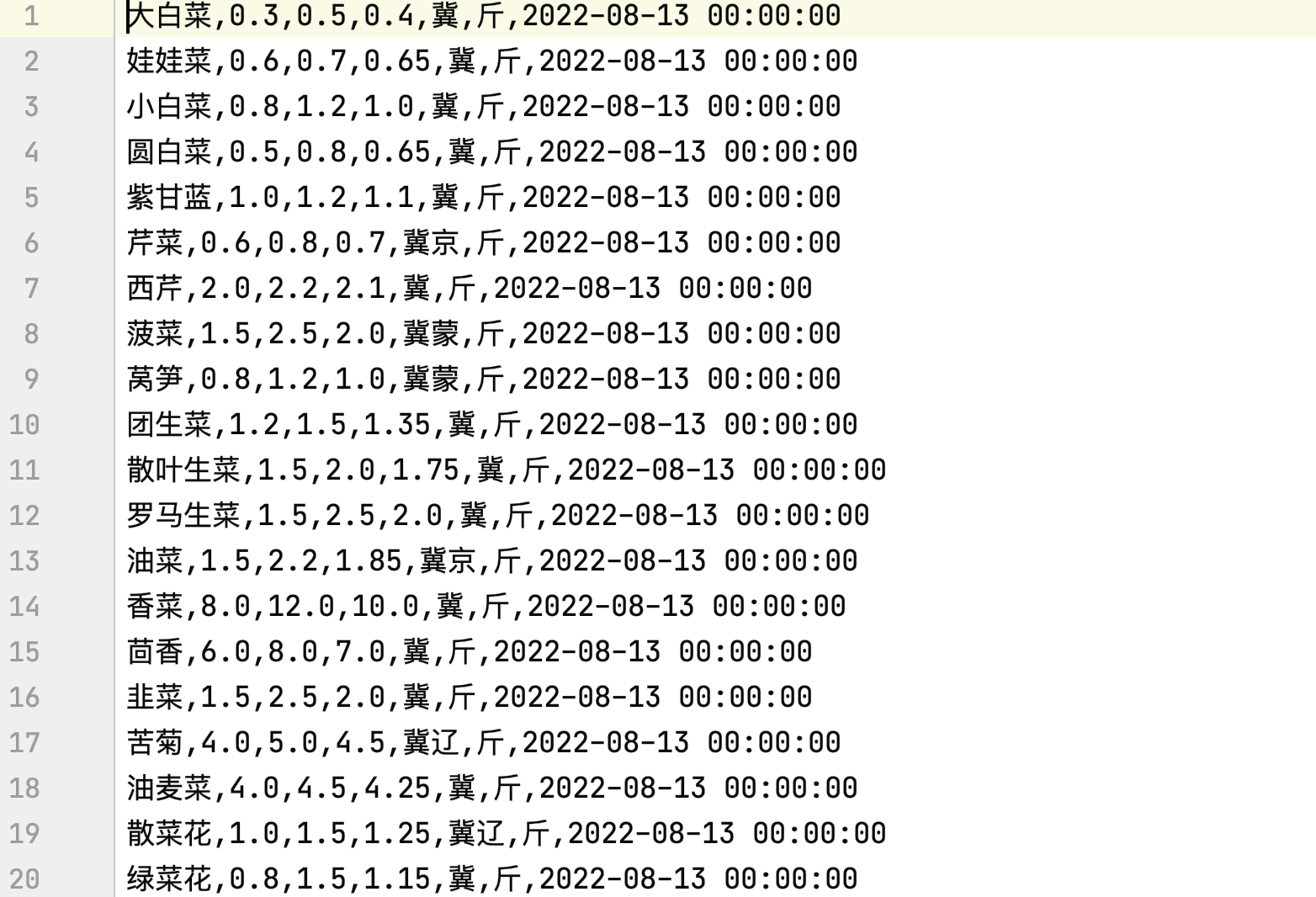
3、獲取更多的信息
分析頁面數據顯示規律,請求地址時頁面攜帶頁碼和需要顯示數據的條數,一共17362頁,每頁20條數據
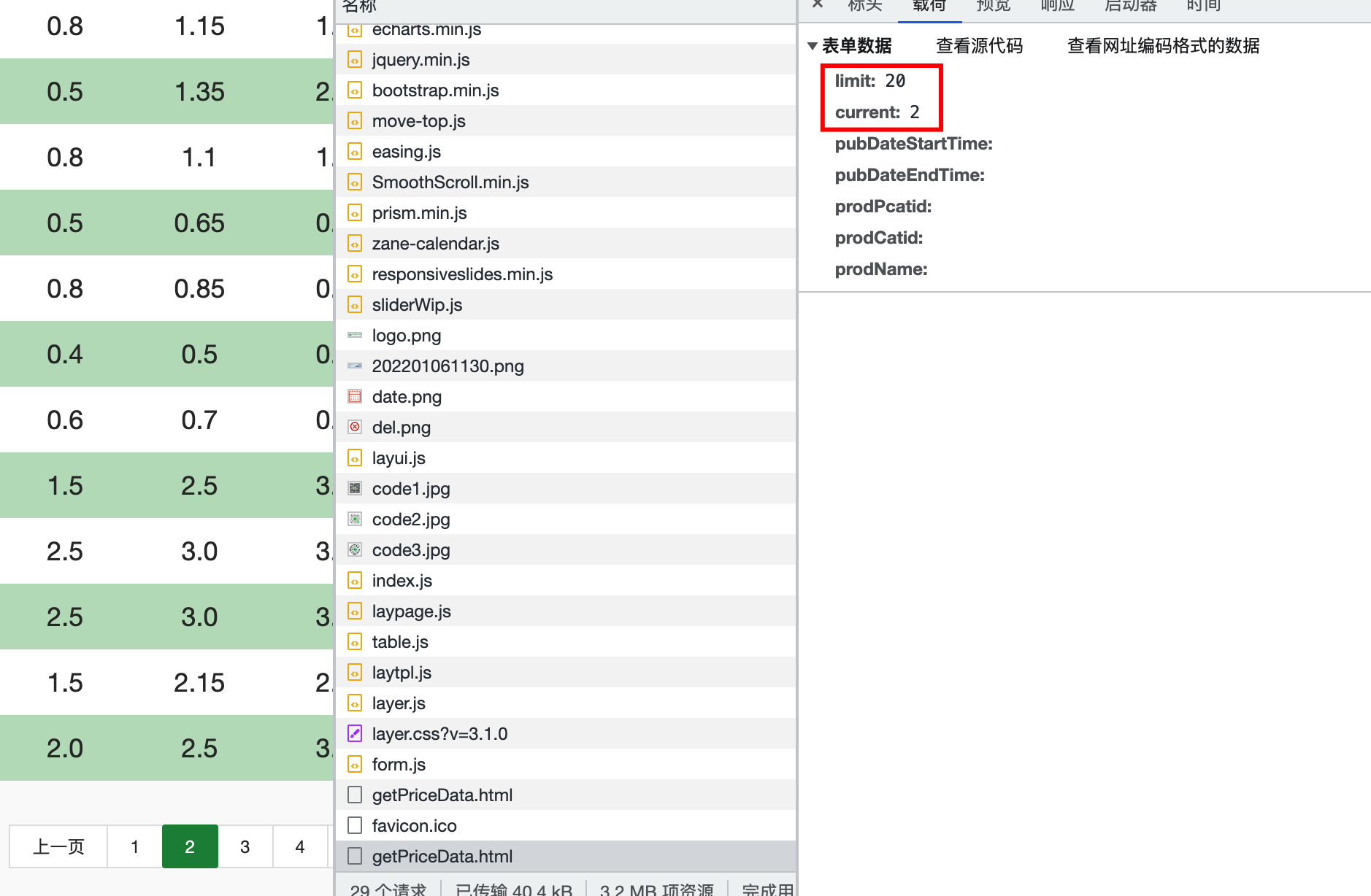
設置100個線程提取17362頁數據,同時每次請求時傳入頁碼
def download(url, num):
data = {
"limit": 20,
"current": num
}
resp = requests.post(url, data=data).json()
for i in resp['list']:
temp = [i['prodName'], i['lowPrice'], i['highPrice'], i['avgPrice'], i['place'], i['unitInfo'], i['pubDate']]
csvwrite.writerow(temp)
print(f'{num}頁提取完成')
if __name__ == "__main__":
url = 'http://www.xinfadi.com.cn/getPriceData.html'
# 設置100個線程
with ThreadPoolExecutor(100) as t:
for i in range(1, 17363):
t.submit(download(url, i))
print('success')
4、完整代碼
4、完整代碼
# 1、提取單頁面
import requests
import csv
from concurrent.futures import ThreadPoolExecutor
f = open("data.csv", mode="w", encoding="utf-8")
csvwrite = csv.writer(f)
def download(url, num):
data = {
"limit": 20,
"current": num
}
resp = requests.post(url, data=data).json()
for i in resp['list']:
temp = [i['prodName'], i['lowPrice'], i['highPrice'], i['avgPrice'], i['place'], i['unitInfo'], i['pubDate']]
csvwrite.writerow(temp)
print(f'{num}頁提取完成')
if __name__ == "__main__":
url = 'http://www.xinfadi.com.cn/getPriceData.html'
# 設置100個線程
with ThreadPoolExecutor(100) as t:
for i in range(1, 17363):
t.submit(download(url, i))
print('success')
以下為第1頁~第199頁數據:



