
課件獲取:關註公眾號“數棧研習社”,後臺私信 “ChengYing” 獲得直播課件 視頻回放:點擊這裡 ChengYing開源項目地址:github 丨 gitee 喜歡我們的項目給我們點個__ STAR!STAR!!STAR!!!(重要的事情說三遍)__ 技術交流釘釘 qun:30537511 本 ...
課件獲取:關註公眾號“數棧研習社”,後臺私信 “ChengYing” 獲得直播課件
視頻回放:點擊這裡
ChengYing開源項目地址:github 丨 gitee 喜歡我們的項目給我們點個__ STAR!STAR!!STAR!!!(重要的事情說三遍)__
技術交流釘釘 qun:30537511
本期我們帶大家回顧一下海洋同學的直播分享《ChengYing部署Hadoop集群實戰》
一、Hadoop集群部署準備
在部署集群前,我們需要做一些部署準備,首先我們需要按照下載Hadoop產品包:
● Mysql
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Mysql_5.7.38_centos7_x86_64.tar
● Zookeeper
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Zookeeper_3.7.0_centos7_x86_64.tar
● Hadoop
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hadoop_2.8.5_centos7_x86_64.tar
● Hive
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hive_2.3.8_centos7_x86_64.tar
● Spark
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Spark_2.1.3-6_centos7_x86_64.tar
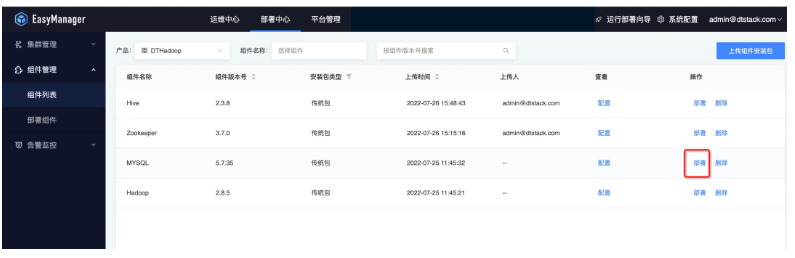
接著我們可以將下載好的產品包直接通過ChengYing界面上傳,具體路徑是:部署中心—組件管理—組件列表—上傳組件安裝包:
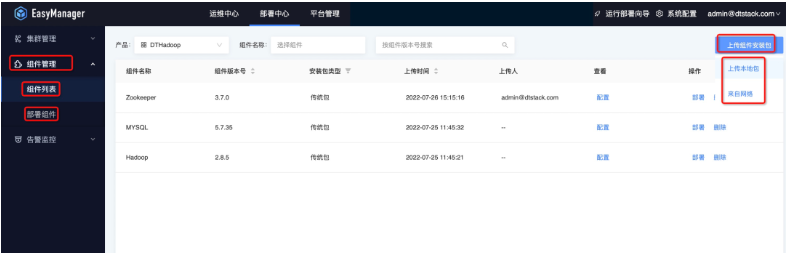
可以通過兩種模式上傳產品包:
本地上傳方式
產品包在先下載到本機電腦存儲中,點擊本地上傳,選在產品包上傳。
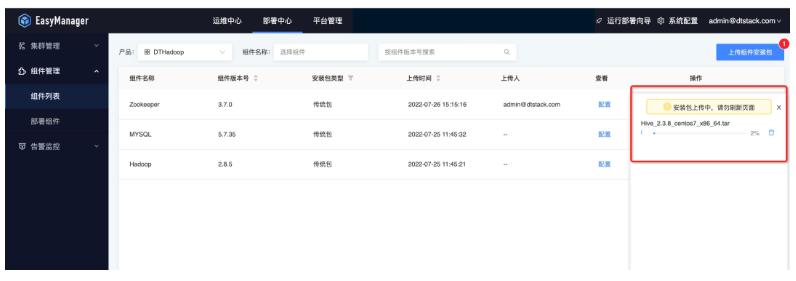
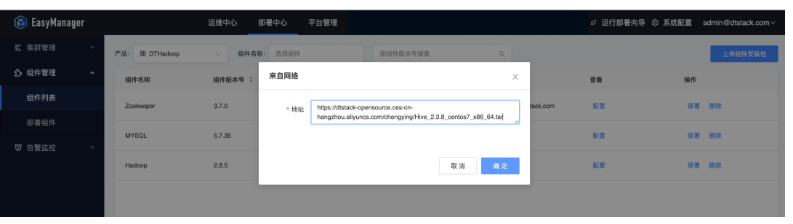
網路上傳模式
直接填寫產品包網路地址上傳(ChengYing的網路需要和產品包網路互通)。
Hadoop集群部署流程
做完準備後,我們可以開始進入集群部署,Hadoop集群部署流程包括以下步驟:

集群部署順序說明
-
首先需要部署Mysql和zookeeper,因為Hadoop需要依賴zookeeper,Hive元數據存儲使用的是Mysql;
-
其次需要部署Hadoop,Hive
-
最後部署Spark,因Spark依賴hivemetastore
PS:部署順序是不可逆的
Hadoop集群部署角色分佈
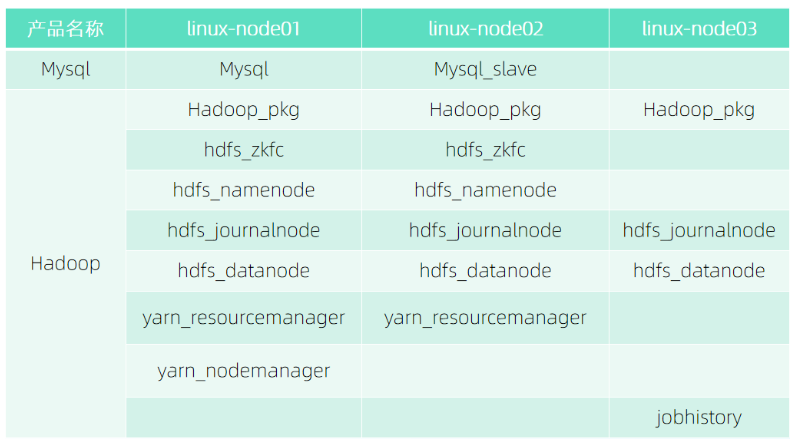
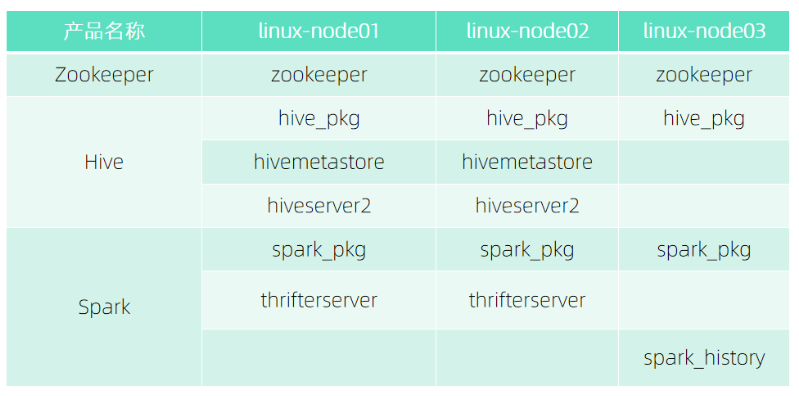
產品包標準部署流程

-
選擇需要部署的產品包,點擊部署按鈕,然後選擇對應需要部署的集群,預設集群為dtstack,集群名稱可配置;
-
下一步選擇需要部署的服務,預設產品包下的服務都會部署,可以根據實際需求部署,在此階段可以對服務的配置文件進行修改,例如:修改Mysql連接超時時間等;
-
最後點擊部署,等待部署完成。
Mysql服務部署流程演示
接下來我們以Mysql服務部署流程來為大家實際演示下整體流程:
● 第一步:選擇集群
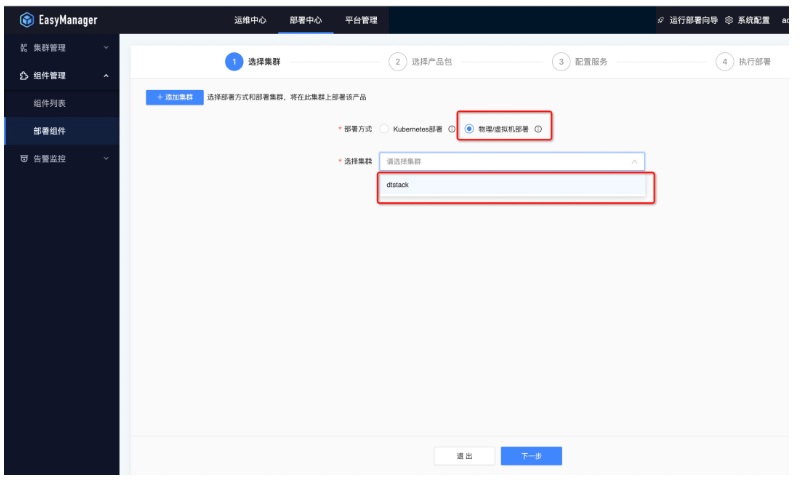
● 第二步:選擇產品包
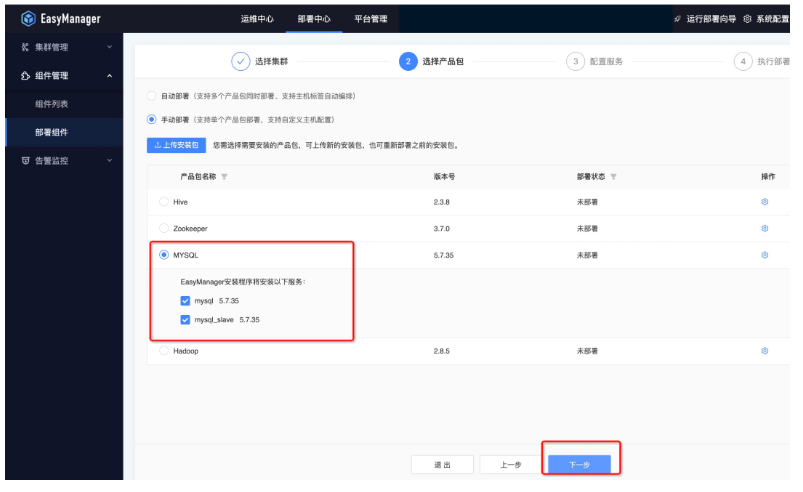
● 第三步:選擇部署節點

● 第四步:部署進度查看
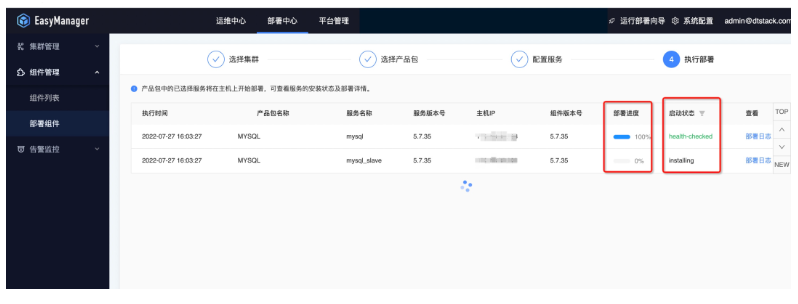
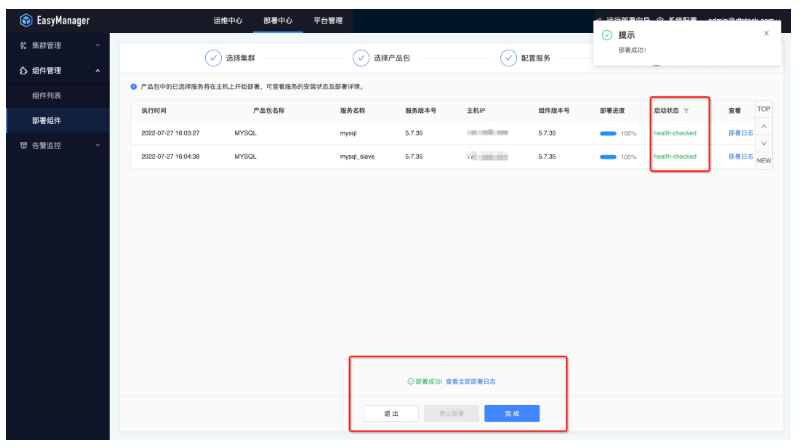
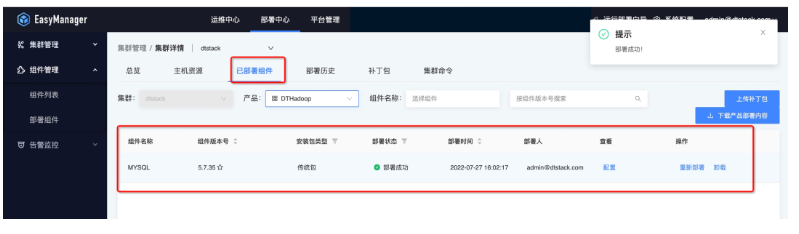
● 第五步:部署後狀態查看
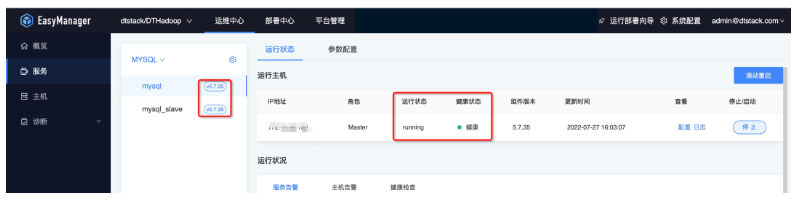
Hadoop集群使用與運維
集群部署完畢後,若有需求可以進行配置變更操作。
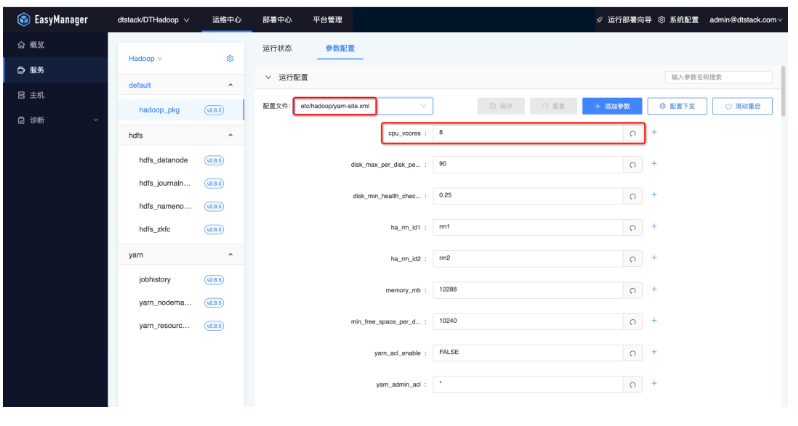
● 配置修改
例如:如果需要操作修改yarn的配置文件,可以先選擇yarn-site.xml文件,可以在搜索框搜索需要修改的配置文件key,如cpu_vcores。
● 配置保存
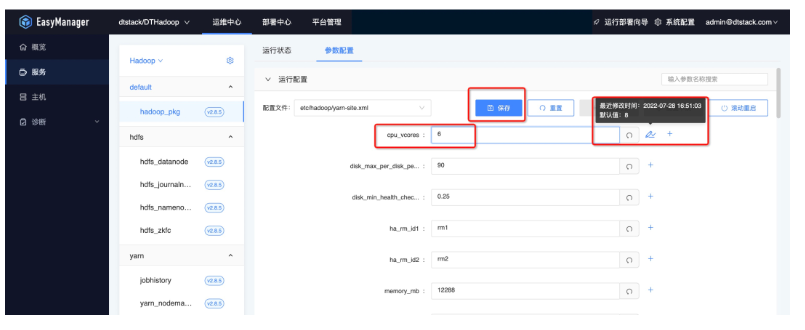
● 配置下發

Taier對接Hadoop操作流程
ChengYing除了可自動部署運維外,還可以對接Taier部署Hadoop集群,Taier 是一個大數據分散式可視化的DAG任務調度系統,旨在降低ETL開發成本、提高大數據平臺穩定性,大數據開發人員可以在 Taier 直接進行業務邏輯的開發,而不用關心任務錯綜複雜的依賴關係與底層的大數據平臺的架構實現,將工作的重心更多地聚焦在業務之中。
利用ChengYing部署管理Taier服務,可以做到實時監控Taier的服務狀態,隨時界面修改Taier配置等。Taier對接Hadoop集群的操作流程如下:

-
首先需要在Taier控制台選擇多集群配置,新增一個集群;
-
然後配置sftp、資源調度組件、存儲組件和計算組件;
-
配置完成後需要保存並且測試連通性。
註意事項:
在對接過程中,sftp主機需要和Taier網路相通,並且sftp配置主機的路徑需要存在,如果不存在,需要手動創建。
Taier的部署網路需要與Hadoop網路相通,如果運行任務,需要在Taier所在節點加入Hadoop集群的Host配置;編譯/etc/hosts文件,增加IP Hostname。
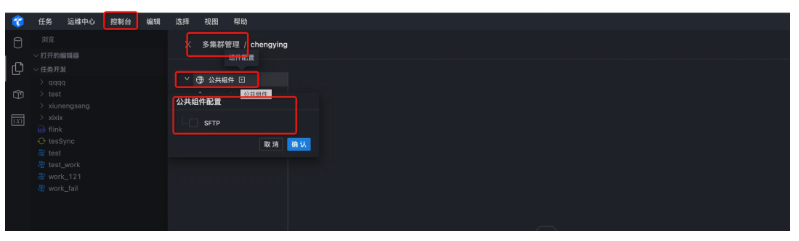
● 第一步:配置公共組件
首先進入Taier登陸界面,點擊控制台,新增集群,然後進入多集群管理界面,配置公共組件,選擇SFTP,進入SFTP配置界面。
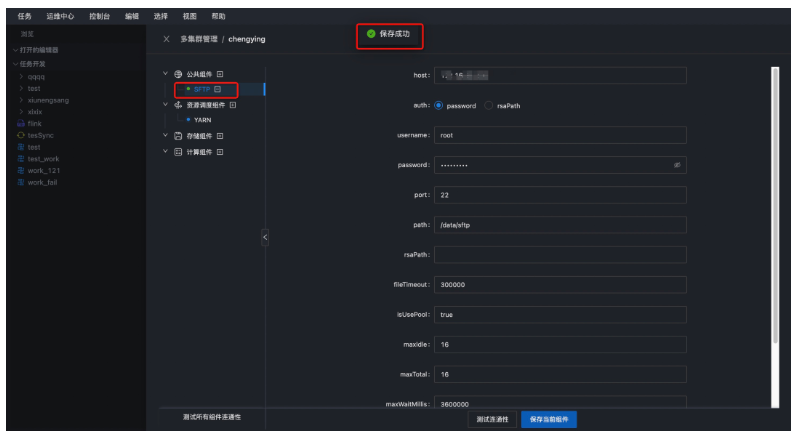
● 第二步:配置SFTP
然後配置SFTP的host,認證方式,預設採用用戶名密碼方式,輸入用戶名和密碼,並且輸入path路徑,此路徑需要在主機上存在,如果不存在,需要手動創建一個SFTP路徑.
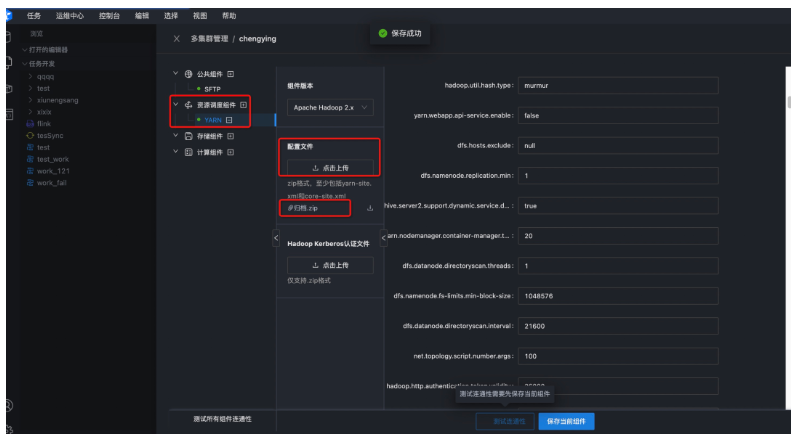
● 第三步:資源調度組件配置
需要到部署Hadoop伺服器到/opt/dtstack/Hive/hive_pkg/conf目錄下獲取hive-site.xml文件,下載到本地;
到/opt/dtstack/Hadoop/Hadoop_pkg/etc/Hadoop目錄下獲取hdfs-site.xml、core-site.xml、yarn-site.xml文件,下載到本地;
這四個文件壓縮成一個zip包,上傳這個壓縮包。
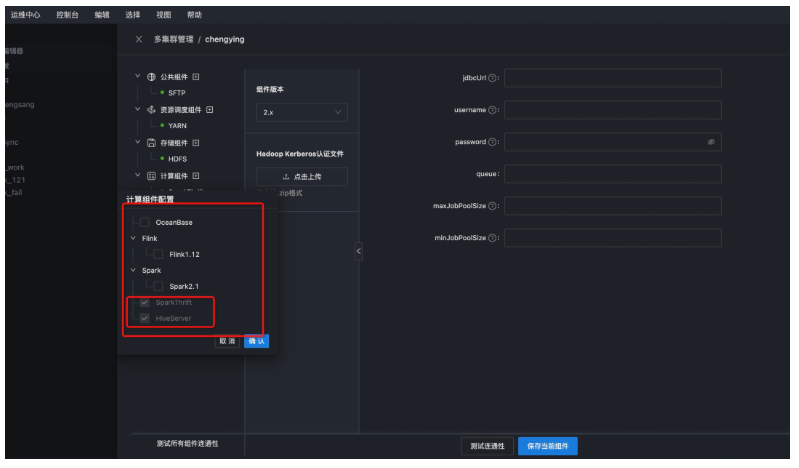
● 第四步:計算組件配置
選擇計算組件模塊,選擇需要對接的計算引擎Hive和Spark,選擇Hive和Spark的版本,填寫對應的jdbc(jdbc:hive://ip:port/)連接串,然後點擊保存,測試連通性。
註意:jdbcurl中ip分別為Hive組件的hiveserver2和Spark中的thrifterserver所在節點ip。
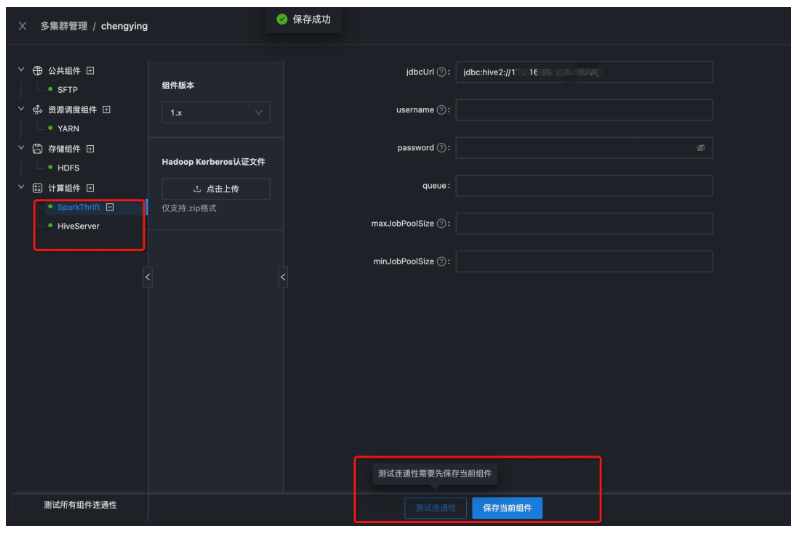
● 第五步:配置Hive和Spark
以下是配置完成Hive和Spark組件後,測試連通性的狀態。
註意:本地演示環境Hadoop未開啟安全,Hive和Spark只需要配置jdbcurl即可。
Hadoop集群近期規劃
最後和大家聊聊Hadoop集群近期規劃,近期主要有三大規劃:
● 產品包製作
製作ChengYing部署產品包的流程及實踐。
● ChunJun&Taier產品包
製作可以用ChengYing部署的Taier和chunjun的產品包
● Hadoop運維
通過ChengYing運維大數據集群;
通過ChengYing一鍵開啟Hadoop集群安全。
袋鼠雲開源框架釘釘技術交流qun(30537511),歡迎對大數據開源項目有興趣的同學加入交流最新技術信息,開源項目庫地址:https://github.com/DTStack


