
2 併發容器線程安全應對之道 引言 在前面,我們學習了hashmap 大家都知道HashMap不是線程安全(put、刪除、修改、遞增、擴容都無鎖)的 所以在處理併發的時候會出現問題 接下來我們看下J.U.C包裡面提供的一個線程安全並且高效Map(ConcurrentHashMap) 看一下,他到底是 ...
2 併發容器線程安全應對之道
引言
在前面,我們學習了hashmap
大家都知道HashMap不是線程安全(put、刪除、修改、遞增、擴容都無鎖)的
所以在處理併發的時候會出現問題
接下來我們看下J.U.C包裡面提供的一個線程安全並且高效Map(ConcurrentHashMap)
看一下,他到底是如何實現線程併發安全的
2.1 併發容器總體概述
目標:學習ConcurrentHashMap基本概念和認識它的數據結構
ConcurrentHashMap概念:
ConcurrentHashMap是J.U.C包裡面提供的一個線程安全的HashMap, 在併發編程中使用的頻率(Spring)比較高。
數據結構如下
數組+鏈表+紅黑樹+鎖(synchronized+cas)
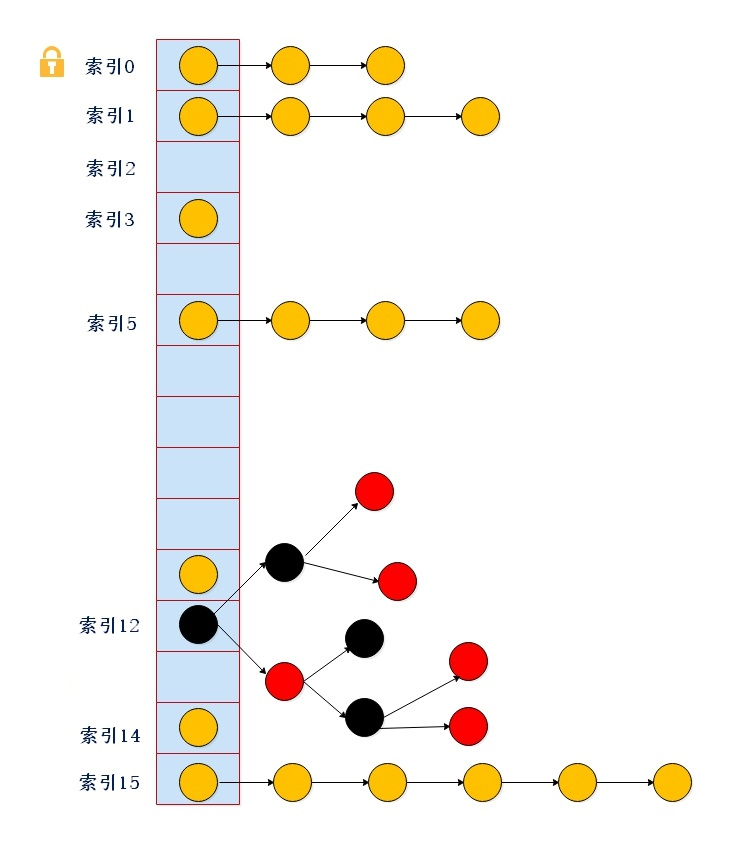
總結:
1、數據結構和hashmap一模一樣,唯一的區別就是concurrenthashmap在put、刪除、修改、遞增、擴容和數據遷移的時候都加鎖了(syn or cas)
2、加鎖只是鎖住一個元素,區別於HashTable(整個表,idea可以查看源碼來驗證)
2.2 併發容器數據結構與繼承
目標:
簡單認識下ConcurrentHashMap繼承關係
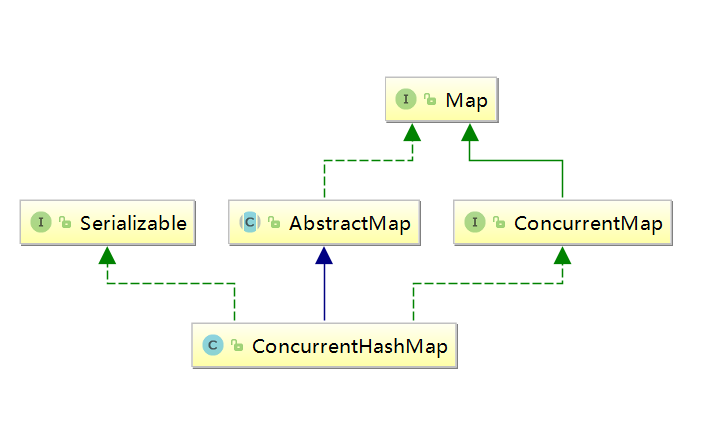
總結
ConcurrentHashMap:實現Serializable表示支持序列化
繼承AbstractMap(實現map介面),實現了一些基本操作
實現ConcurrentMap介面,封裝了map的基本操作
2.3 併發容器源碼深度剖析
測試代碼
見put部分
2.3.1 併發容器成員變數
目標:認識下ConcurrentHashMap成員變數,先有個印象,方便後續源碼分析
private static final int MAXIMUM_CAPACITY = 1 << 30; //table最大容量:2^30=1073741824
private static final int DEFAULT_CAPACITY = 16; //預設容量,必須是2的冪數
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; ////數組的建議最大值
private static final int DEFAULT_CONCURRENCY_LEVEL = 16; //併發級別,1.8前的版本分段鎖遺留下來的,為相容以前的版本
static final int TREEIFY_THRESHOLD = 8;// 鏈表轉紅黑樹閥值
static final int UNTREEIFY_THRESHOLD = 6;// 樹轉鏈表閥值
static final int MIN_TREEIFY_CAPACITY = 64;// 轉化為紅黑樹的表的最小容量
private static final int MIN_TRANSFER_STRIDE = 16;// 每次進行轉移的最小值
//咦?threshold 呢???
2.3.2 併發容器構造器
目標:
先認識下ConcurrentHashMap的5個構造器,看下在構造中(第一步)做了哪些事情
1、ConcurrentHashMap()型構造函數
public ConcurrentHashMap() {
}
總結:該構造函數用於創建一個帶有預設初始容量 (16)、負載因數 (0.75) 的空映射
2、ConcurrentHashMap(int)型構造函數
private static final int MAXIMUM_CAPACITY = 1 << 30
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0) // 初始容量小於0,拋出異常
throw new IllegalArgumentException();
//到達最大容量的一半以上後,直接取最大容量!
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
// 初始化,sizeCtl是什麼鬼??看上去是容量……
this.sizeCtl = cap;
}
總結:該構造函數用於創建一個帶有指定初始容量的map
3、ConcurrentHashMap(Map<? extends K, ? extends V>)型構造函數
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
// 將集合m的元素全部放入
putAll(m);
}
總結:該構造函數用於構造一個與給定映射具有相同映射關係的新映射。
4、ConcurrentHashMap(int, float)型構造函數
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
總結:該構造函數用於創建一個帶有指定初始容量、載入因數 新的空映射。
5、ConcurrentHashMap(int, float, int)型構造函數
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) // 合法性判斷
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap; // 好像是容量?沒那麼簡單,待會往下看
}
總結:該構造函數用於創建一個帶有指定初始容量、載入因數和併發級別的新的空映射
擴展:和HashMap完全一樣?錯!我們來看一個實例
1)代碼實例
package com.cmap;
import org.openjdk.jol.info.ClassLayout;
import java.util.HashMap;
import java.util.concurrent.ConcurrentHashMap;
public class CMapInit {
public static void main(String[] args) {
HashMap m = new HashMap(15,0.5f);
ConcurrentHashMap cm = new ConcurrentHashMap(15, 0.5f);
//debug here
System.out.println("before put");
m.put(1,1);
cm.put(1,1);
//and here
System.out.println("after put");
System.out.println(ClassLayout.parseInstance(cm).toPrintable());
}
}
2)調試,put之前
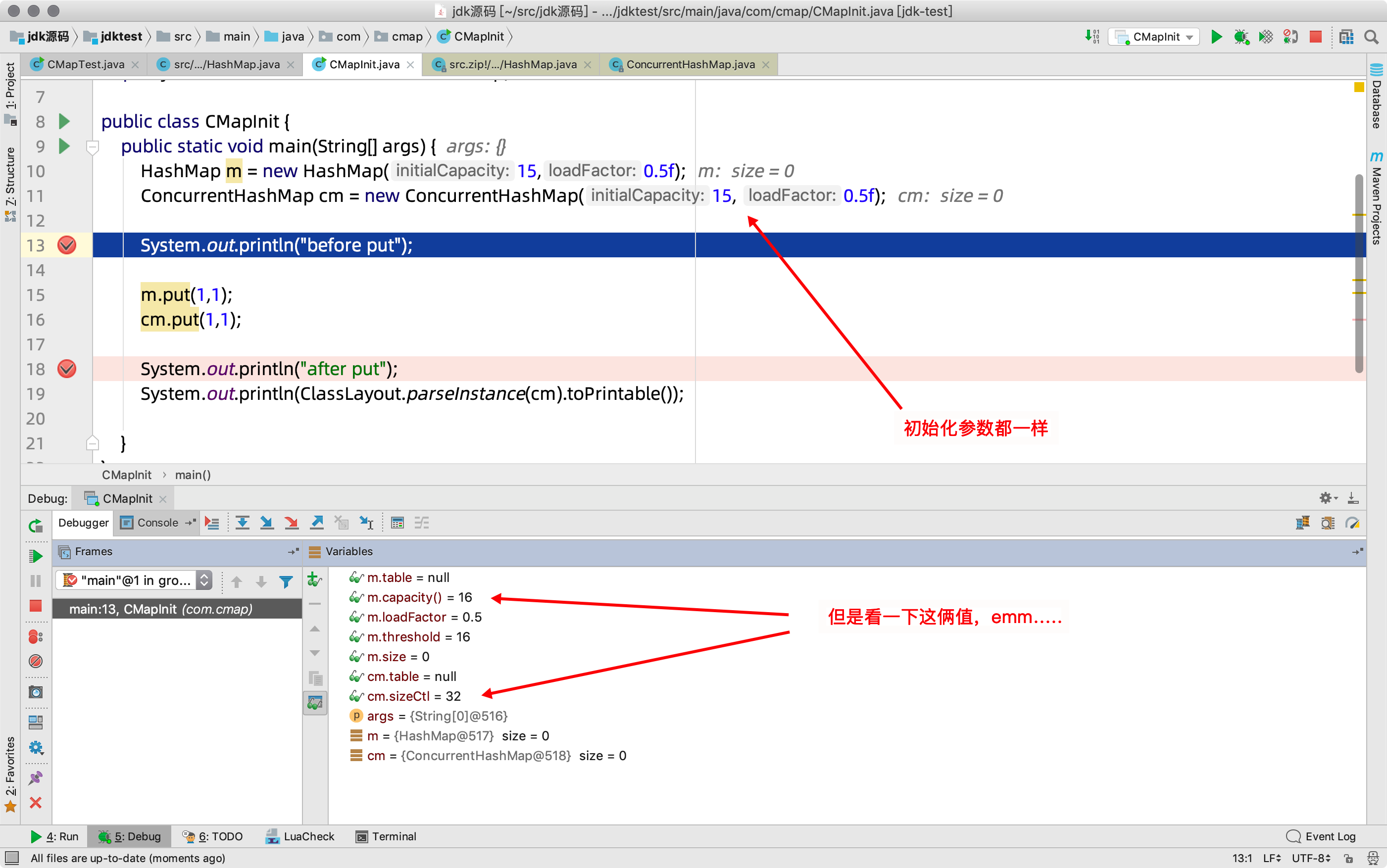
3)繼續,debug到第二步試試,put之後
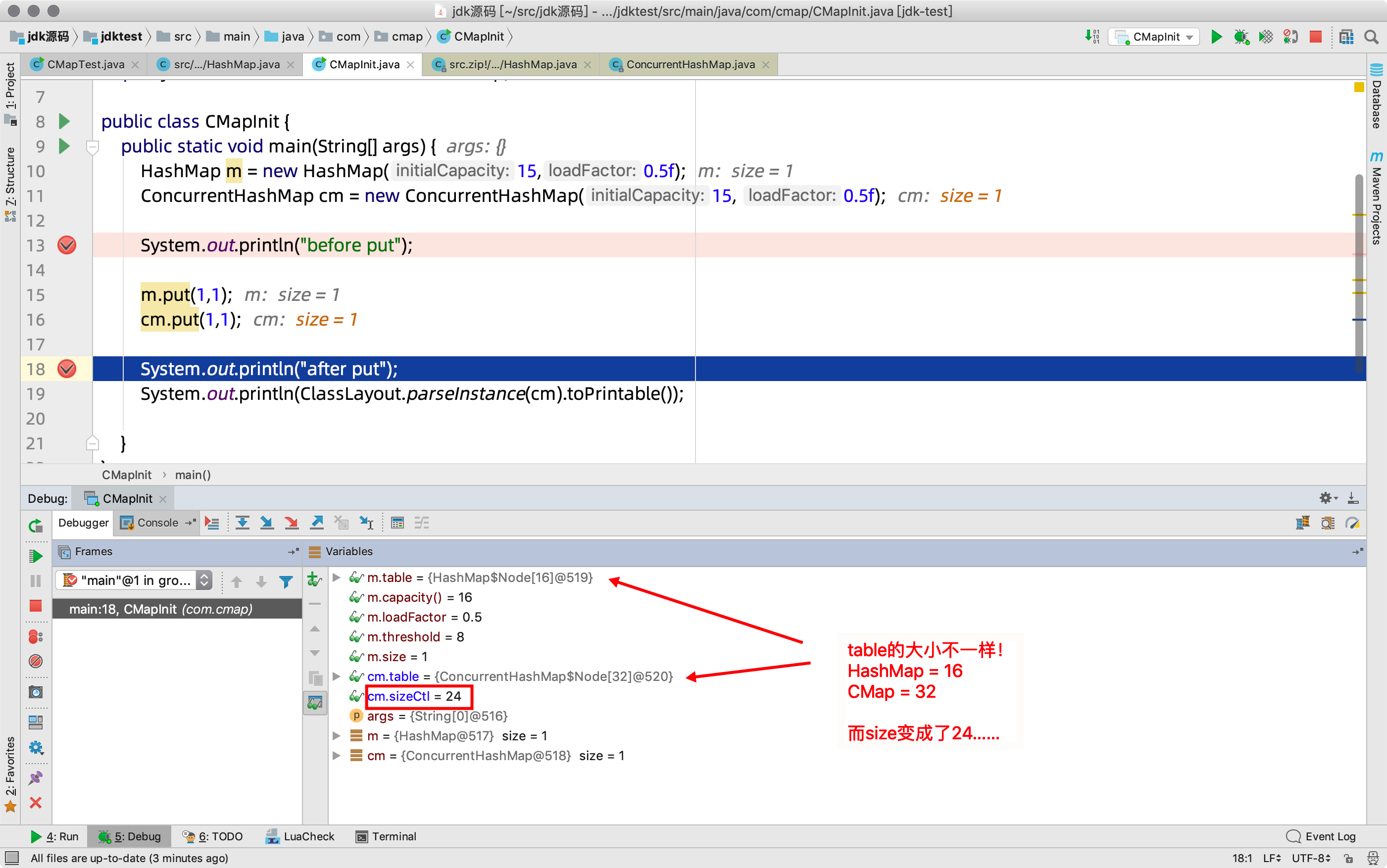
- 容量並不是我們之前認為的16,而是32
- 而sizeCtl,我們理解,應該類比於hashMap中的threshold,它應該等於 32*0.5=16才對
- 可是最終為24
這是什麼神操作???
4)原理剖析
先說結論:方法調用的都是tableSizeFor,只不過,Cmap所計算的參數不一樣,註意回顧上面的構造函數
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
//initial = 15, size = 31
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
//所以tableSizeFor做滿1運算前,並不是15本身,而是size,也就是31
//運算後,cap=32 , 不是16
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
那麼它啥時候變成24的呢?
//開始之初,table為null,在put時,會觸發table的初始化,也就是以下方法
//從put方法的入口可以追蹤到,我們猜想它肯定在這裡,初始化table的時候
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//sc = 原來的sizeCtl也就是 32
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
//n = sc = 32 , 預設就是default=16了
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
//創建node數組,長度為n,也就是32
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
//創建完複製給table,初始化完成,也就是我們看到的32長度的數組
table = tab = nt;
// n >>> 2 ,相當於n除以4是8, 32-8=24
//實際效果相當於,n* 3/4 , 也就是 n*0.75 , 你指定的0.5在初始化時對它沒什麼用!
sc = n - (n >>> 2);
}
} finally {
//在finally中將它賦給了sizeCtl,也就是我們最終看到的24
sizeCtl = sc;
}
break;
}
}
return tab;
}
那麼sizeCtl起不到threshold的作用,它是幹嘛的呢?
其實它的作用遠遠比hashmap中的thredhold大的多,看看官方的說法:
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
翻譯過來就是這樣子:(官方就這麼規定的,記住它!)
- 用來控制table的初始化和擴容操作
- 預設為0,int類型的,廢話
- -1 代表table正在初始化
- -N 表示有N-1個線程正在進行擴容操作
其餘情況:
- 如果table未初始化,表示table需要初始化的大小。
- 如果table初始化完成,表示table的容量,預設是table大小的0.75倍
而修改它的方法也比較多,initTable只是其中的一個:
-
initTable()
-
addCount()
-
tryPresize()
-
transfer()
-
helpTransfer()
2.3.3 put方法
目標:1、ConcurrentHashMap增加的邏輯是什麼
2、ConcurrentHashMap是如何保證線程安全的
基礎回顧:關於compareAndSwapInt(CAS)
一定要理解CAS的原理,Cmap的精髓就在於cas和sync保障了線程安全,下文的源碼分析馬上要用到它
(畫圖展示兩個線程的cas交互操作)
(U.compareAndSwapInt(this, SIZECTL, sc, -1))
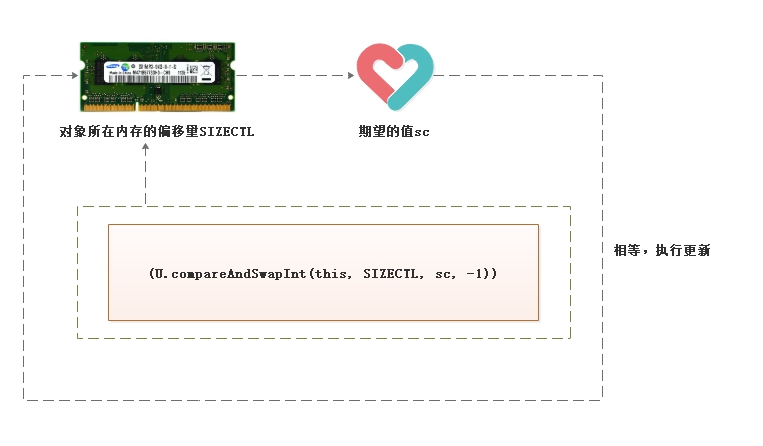
解釋:
-
此方法是Java的native方法,並不由Java語言實現。
-
方法的作用是,讀取傳入對象this在記憶體中偏移量為SIZECTL位置的值與期望值sc作比較。
-
相等就把-1值賦值給SIZECTL位置的值。方法返回true。
-
不相等,就取消賦值,方法返回false。
-
一般配合迴圈重試操作,被for或while所包裹
1)測試代碼
package com.cmap;
import java.util.ArrayList;
import java.util.ConcurrentModificationException;
import java.util.HashMap;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
public class CMapTest {
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
public static void main(String[] args) {
ConcurrentHashMap<Integer, Integer> m = new ConcurrentHashMap<Integer, Integer>();
for (int i = 0; i < 64; i++) {
if (i == 0) {
m.put(i, i);//正常新增(演示)
} else if (i == 11) {
//容量預設16,臨界值=12, 那麼i=11正好是第12個值,引發擴容
m.put(i, i);//擴容(演示)
} else if (i == 10) {
m.put(27, 27);
m.put(43, 43);
} else if (i == 9) {
} else if(i==23){
m.put(i,i); // 23, 第二次擴容
}else {
m.put(i, i);//正常新增
}
}
m.get(8);
System.out.println(m);
}
//哈希衝突
static void testHashCode() {
System.out.println((16 - 1) & spread(new Integer(27).hashCode()));
System.out.println((16 - 1) & spread(new Integer(43).hashCode()));
System.out.println((16 - 1) & spread(new Integer(11).hashCode()));
}
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
}
2)增加過程
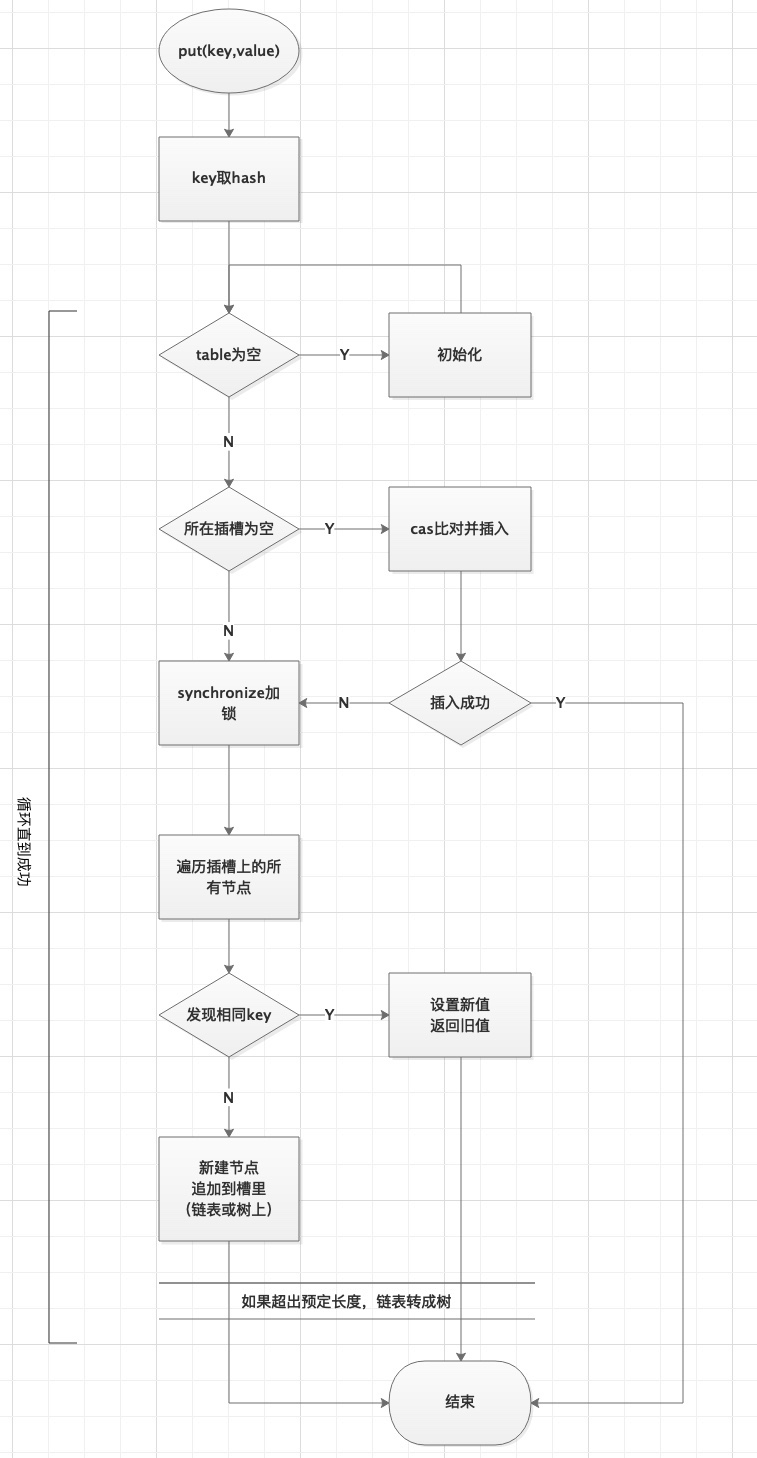
//提示:該方法岔路比較多,要廣度優先閱讀,先看外圍大路,再細分裡面的子方法
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());//key取hash擾動
int binCount = 0;
for (Node<K,V>[] tab = table;;) {//迴圈直到成功
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();//表為空的話,初始化表,下麵會詳細介紹【預留1】
//定址,找到頭結點f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//cas在這裡!!!
//插槽為空,cas插入元素
//比較是否為null,如果null才會設置並break,否則到else
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; //插入成功,break終止即可,如果不成功,會進入下一輪for
}
//helpTransfer() 擴容。下小節詳細講,一個個來……【預留2】
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//synchronized 在這裡!!!
//插槽不為空,說明被別的線程put搶占了槽
//那就加鎖,鎖的是當前插槽上的頭節點f(類似分段鎖)
synchronized (f) {
if (tabAt(tab, i) == f) { //這步的目的是再次確認,鏈表頭元素沒有被其他線程動過
if (fh >= 0) { // 正常節點的hash值
binCount = 1; //統計節點個數
//沿著當前插槽的Node鏈往後找
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果找到相同key,說明之前put過
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent) //abset參數來決定要不要覆蓋,預設是覆蓋
e.val = value;
break;
}
Node<K,V> pred = e;
//否則,新key,新Node插入到最後
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
//如果是紅黑樹,說明已經轉化過,按樹的規則放入Node
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
//如果節點數達到臨界值,鏈表轉成樹
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount); //計數,如果超了,調transfer擴容
return null;
}
//compareAndSetObject,比較並插入,典型CAS操作
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
3)初始化表方法
多線程下initTable的交互流程:
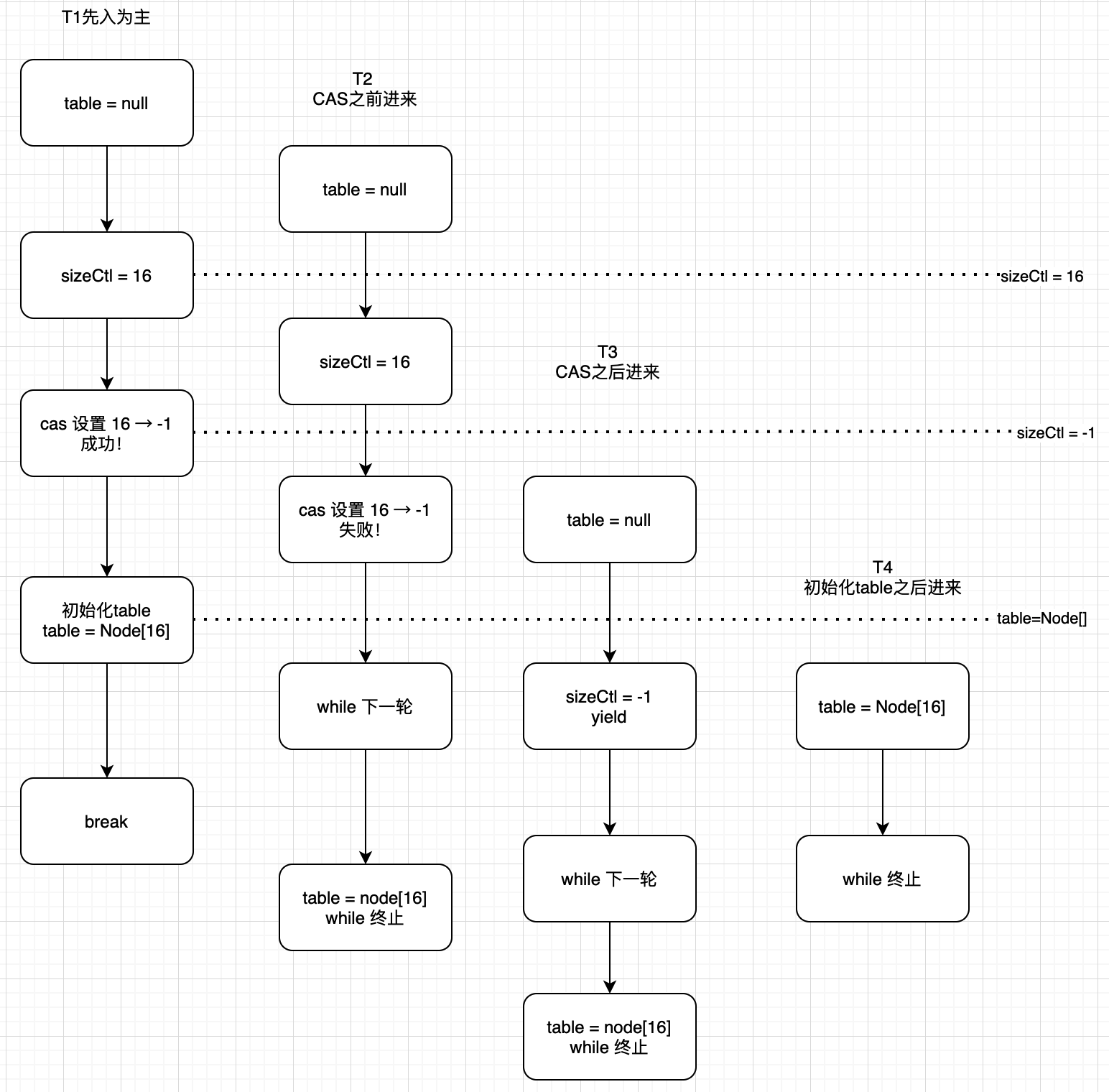
源碼:
/**
* 註意點:先以單線程看業務流程,再類比多個線程操作下的併發是如何處理的?
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) { //自旋
//第1個線程這個if不成立,會進入下麵,設置為-1
//第2個線程來的時候if成立,註意理解多線程在跑。
if ((sc = sizeCtl) < 0) //註意回顧上面的值,小於0表示正在初始化,或擴容
Thread.yield();//有線程在操作,將當前線程yield讓出時間片。喚醒後進入下一輪while
//CAS操作來設置SIZECTL為-1,如果設置成功,表示當前線程獲得初始化的資格
//傳入對象 & 記憶體地址 & 期望值 & 將修改的值
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
//再次確認一下,table是null,還沒初始化
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//預設容量16
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; //初始化table
//給table賦值,註意這個table是volatile的,會被其他線程及時看到!
//一旦其他線程看到不是null,走while迴圈發現table不等於空就return了
table = tab = nt;
sc = n - (n >>> 2); //計算下次擴容的閾值,容量的0.75
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
總結:
-
判斷順序為先看 table=null 再看 sizeCtl = -1
-
T1來得早,按部就班進行
-
T2 - T4 在不同時間點進入,行動不一樣,有的是被cas擋住,有的被table非null擋住
2.3.4 擴容
目標:1、圖解+斷點分析查看ConcurrentHashMap是如何擴容的
2、圖解+斷點分析查看ConcurrentHashMap是如何遷移數據的
測試代碼
package com.cmap;
import java.util.ArrayList;
import java.util.ConcurrentModificationException;
import java.util.HashMap;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
public class CMapTest {
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
public static void main(String[] args) {
ConcurrentHashMap<Integer, Integer> m = new ConcurrentHashMap<Integer, Integer>();
for (int i = 0; i < 64; i++) {
if (i == 0) {
m.put(i, i);//正常新增(演示)
} else if (i == 11) {
m.put(i, i);//擴容 1
} else if (i == 10) {
m.put(27, 27);
m.put(43, 43);
} else if (i == 9) {
} else if(i==23){
m.put(i,i); // 23, 第二次擴容(演示點,debug打在這裡再進去)
}else {
m.put(i, i);//正常新增
}
}
System.out.println(m);
}
}
入口:
/*
在上面, putVal方法的最後, 進 addCount(),再跳到最後,發現:
會走到 transfer() 方法,這是真正的擴容操作
同時,Cmap還帶有它的特色,也就是 多線程協助擴容,helpTransfer
最後調的也是transfer方法
*/
final V putVal(K key, V value, boolean onlyIfAbsent) {
// ……
addCount(1L, binCount);
}
private final void addCount(long x, int check) {
// ...
// 擴容操作的核心在這裡
transfer(tab, null);
}
/**
* Helps transfer if a resize is in progress. 如果正在擴容,上去幫忙
* tab = 舊數組, f=頭結點,如果正在擴容,它是一個ForwardNode類型
*/
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {//一堆條件判斷,不去管它
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
//其他線程進來,多了這一步: cas將 sizeCtl + 1, (表示增加了一個線程幫助其擴容)
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
// 找到了,核心在這裡!這個內部藏著擴容的具體操作
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
核心源碼【重點】
CMap是如何多線程協助遷移數據的???
/**
* Moves and/or copies the nodes in each bin to new table. See
* above for explanation.
*/
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// 將 length / 8 然後除以 CPU核心數。如果得到的結果小於 16,那麼就使用 16。
// 如果桶較少的話,預設一個 CPU(一個線程)處理 16 個桶
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // 最小16
if (nextTab == null) { // 新的 table 尚未初始化
try {
// 擴容 2 倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
// 賦值給新table
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
// 更新成員變數
nextTable = nextTab;
// transferIndex表示沒遷移的桶里最大索引的值,這個會被多個線程瓜分走越來越小。
// 一開始這個值是舊tab的尾部:也就是 n
// 瓜分時,從大索引往後分,也就是順序是 : 15 14 13 12 ....0
transferIndex = n; // tag_0
}
// 新 tab 的 length
int nextn = nextTab.length;
// 創建一個 fwd 節點,用於標記。
// 註意,它裡面的hash屬性是固定的MOVED,還記得 putVal里的helpTransfer前的判斷嗎?
// 當別的線程put的時候,正好發現這個槽位中是 fwd 類型的節點,也調helperTransfer參與進來。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true; //臨時變數,表示要不要移動槽
boolean finishing = false; //臨時變數,表示當前槽有沒有遷移完
for (int i = 0, bound = 0;;) { //每次for遍歷一個桶來遷移,也就是舊table里的一個元素
Node<K,V> f; int fh;
while (advance) { //這裡的while是配合tag_3的cas做自旋,只有它可能會觸發多次迴圈,其他倆都是1次跳出
//while比較亂:可以打斷點進來調試查看每次的經過
// 第一次for的時候進 tag_3 確定bound和i,也就是給當前線程分配了 bound ~ i 之間的桶
// 以後每次--i,只要不大於bound,都進 tag_1,也就是啥都不幹
// 最後一次,等於bound的時候,說明分配給當前線程的桶被它for完了,退出
int nextIndex, nextBound;
if (--i >= bound || finishing) // tag_1
//如果i比bound還大,或者當前i下的鏈表沒移動完,--i推動一格
advance = false;
else if ((nextIndex = transferIndex) <= 0) { // tag_2 ,註意!這個賦值操作第一次也要發生
//如果transferIndex <=0 說明已遷移完成,沒有桶需要處理了,退出
i = -1;
advance = false;
}
else if (U.compareAndSwapInt // tag_3
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
// 第一次for的時候會走進這裡,確定當前線程負責的桶的範圍,同時cas更新transferIndex
// 也就是,多個線程第一次都會訪問到這裡,通過cas來分一部分桶,cas防止併發下重覆分配
// 註意,來這裡之前,經過了tag_2的賦值:
// 所以這裡在cas前 nextIndex = transferIndex = 16
// cas後, transferIndex = nextBound = (nextIndex - stride) = 0
// 註意,這裡不一定是0,只不過舊長度16被一個線程全拿走了,剩下了0個
// 也就是說,transfer是本次分配後,還剩下的桶里最大的索引,別的線程還會繼續分
bound = nextBound;// 最小下標0(舊數組)
i = nextIndex - 1;//最大下標15(舊數組)
advance = false;
}
} // end while
// 判斷i的範圍,不在可移動插槽的索引範圍內,說明全部遷移完了!
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// 如果完成了擴容
if (finishing) {
nextTable = null;// 釋放
table = nextTab;// 更新 table
sizeCtl = (n << 1) - (n >>> 1); // 更新閾值
return;// 結束方法。
}
// 如果沒完成,嘗試使用cas減少sizeCtl,也就是擴容的線程數,同時更新標記 finishing為true
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;//
i = n;
}
}
//下麵才是真正遷移數據的操作!!!
else if ((f = tabAt(tab, i)) == null)
// 獲取老 tab i 下標位置的變數,如果是 null,就使用 fwd 占位。
// cas成功,advance為true,下次for里while會做--i移動一個下標
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)// 如果不是 null 且 hash 值是 MOVED。
advance = true; // 說明別的線程已經處理過了,移動一個下標
else {
// 到這裡,說明這個位置有實際值了,且不是占位符,那就需要我們遷數據了。
// 對這個節點上鎖。防止別的線程 putVal 的時候向鏈表插入數據
synchronized (f) {
// 判斷 i 下標處的桶節點是否和 f 相同 ,確保沒有被別的線程動過
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;// 定義 low, height 高位桶,低位桶
// 如果 f 的 hash 值大於 0 屬於常規hash,開始拆分高低鏈表
// 參考靜態變數:MOVED -1、TREEBIN -2、RESERVED -3、HASH_BITS > 0
if (fh >= 0) {
// 和老長度進行與運算,由於 Map 的長度都是 2 的次方(16就是10000 這類的數字)
// 那麼取與 n 只有 2 種結果,一種是 0,一種是n
// 如果是結果是0 ,拆分後,Doug Lea 將其放在低位鏈表,反之放在高位鏈表
// 這裡和HashMap的演算法一樣!
int runBit = fh & n; //算算頭結點是高位還是低位
Node<K,V> lastRun = f;
// 遍歷這個桶,註意,這地方有個討巧的操作!
// 和HashMap不同這裡不是一上來就移動,而是先打標記
// 往下看 ↓ (可以藉助下麵的圖來同步說明)
//
for (Node<K,V> p = f.next; p != null; p = p.next) {
// 沿著鏈往下走,挨個取與
int b = p.hash & n;
// 如果和上次迴圈的值相等,那不動(當然第一次的話就是和頭節點比較)
if (b != runBit) {
//如果不相等的話,就切換值
runBit = b; // 0遍。
lastRun = p; // 這個 lastRun 保證後面的節點與自己的取於值相同,避免後面沒
}
}
//思考一下,經過上一輪遍歷完,發生了什麼?
// runBit 要麼是0 要麼是1 ,
// lastRun 指向了最後一次切換的那個節點,它後面再沒發生或切換
// 也就意味著,lastRun後面所有的節點和它都具備相同的runBit值
// 想想,可以做什麼???
// 對!在lastRun處直接切斷!帶著後面的尾巴,直接當做拆分後的高位,或者低位鏈表
// 這樣就不需要和hashMap一樣挨個斷開指針,再挨個接一遍到新鏈,一鍋端就行了
if (runBit == 0) {// 如果最後的 runBit 是 0 ,直接當低位鏈表
ln = lastRun;
hn = null;
}
else {
hn = lastRun; // 如果最後的 runBit 是 1, 直接當高位鏈表
ln = null;
}
// 那麼lastRun前面剩下的那些呢?
// 再遍歷一遍就是了,註意,是從頭結點f遍歷到lastRun,後面的不需要操心了
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0) // 如果與運算結果是 0,那麼放低位鏈表,註意是頭插
ln = new Node<K,V>(ph, pk, pv, ln); // 參數里的ln是next,頭插!
else // 1 則放高位
hn = new Node<K,V>(ph, pk, pv, hn);
} // 為什麼這裡不怕多線程時的頭插法出問題?(因為在sync里!)
// 這裡往下就類似 hashMap
// 設置低位鏈表放在新鏈表的 i
setTabAt(nextTab, i, ln);
// 設置高位鏈表,在原有長度上加 n
setTabAt(nextTab, i + n, hn);
// 將舊的鏈表設置成占位符,表示遷移完了!
setTabAt(tab, i, fwd);
// 繼續向後推進
advance = true;
}
// 如果是紅黑樹同樣的路子,設置高低位node
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
// 遍歷
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
// 和鏈表相同的判斷,與運算 == 0 的放在低位
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
} // 不是 0 的放在高位
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 如果樹的節點數小於等於 6,那麼轉成鏈表,反之,創建一個新的樹
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// 低位樹
setTabAt(nextTab, i, ln);
// 高位樹
setTabAt(nextTab, i + n, hn);
// 舊的設置成占位符
setTabAt(tab, i, fwd);
// 繼續向後推進
advance = true;
}
}
}
}
}
}
總結
1、關於多線程協同
原來:128,擴容後256
難道使用單線程去完成所有數據的遷移工作?
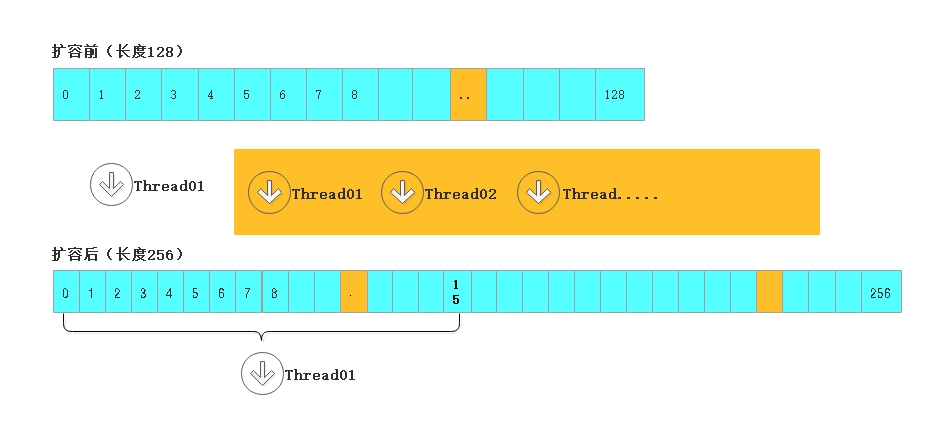
既然使用多線程進行遷移,如果保證數據不能亂?
將數組分段(桶),每個線程負責至少16個桶(stride),8個線程就可以並行工作了
至於誰分哪些桶,從高索引到低索引,通過cas一起減transferIndex的值來實現,避免重覆切分
切一段,低索引叫bound,高索引叫i,遍歷遷移就是了
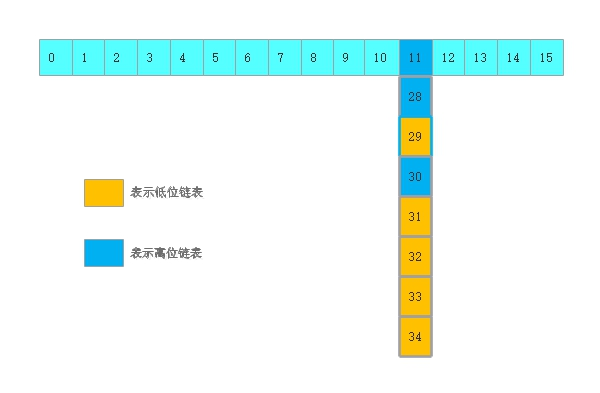
2、關於數據遷移(一個討巧的小操作)
tips:
第一次,從11往後遍歷,最後 runBit=0, lastRun指向31節點
從31處切斷,後面的一窩端直接當低位鏈表,不需要再挨個動他們
第二次,再遍歷11 - 30 , 根據情況頭插到高位和低位新鏈表上
3、線程安全性
1、多個線程通過cas操作防止重覆操作。
2、節點引用的地方使用volatile保持了線程修改時對其他線程及時可見
3、遷移的時候對插槽加sync鎖,保障安全性
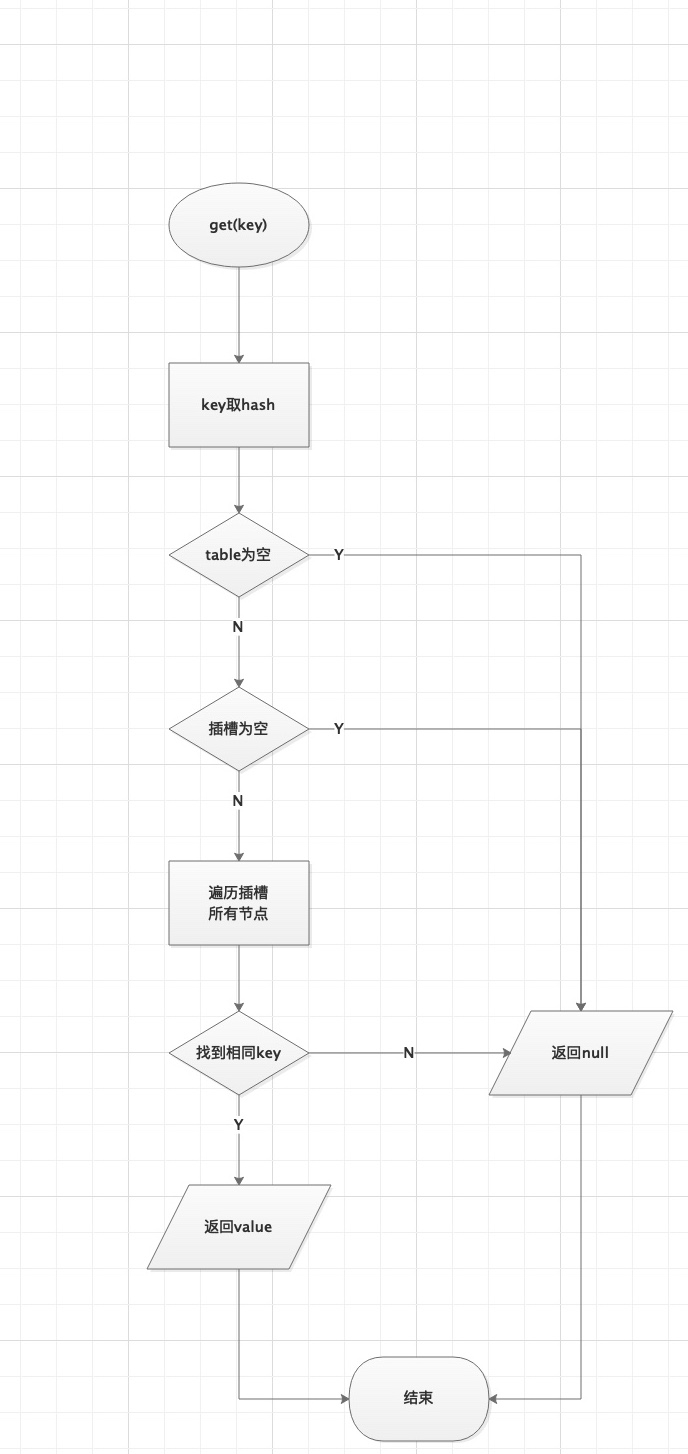
2.3.5 get方法
目標:1、ConcurrentHashMap查詢是否加鎖,如何保證線程安全
2、在查詢的時候遇到擴容怎麼辦
ConcurrentHashMap查詢流程圖如下
tips
多線程下,所謂get的不安全因素,就是最怕讀到臟數據
get的時候取到了數據,其實其他線程已經把它改掉了,就是所謂的可見性問題。
get方法源碼如下
//get操作無鎖
//因為Node的val和next是用volatile修飾的
//多線程環境下線程A修改結點的val或者新增節點的時候是對線程B可見的
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//key取hash
int h = spread(key.hashCode());
//1.判斷table是不是空的,2.當前桶上是不是空的
//如果為空,返回null
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//找到對應hash槽的第一個node,如果key相等,返回value
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
//hash值為負值表示正在擴容,這個時候查的是ForwardingNode的find方法來定位到nextTable新表中
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) { //既不是首節點也不是ForwardingNode,那就往下遍歷
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
//遍歷完還沒找到,返回null
return null;
}
思考:
get沒有加鎖,在進行查詢的時候是如何保證讀取不到臟數據呢?
猜想一下?
是在內部類Node類的val上加了volatile?
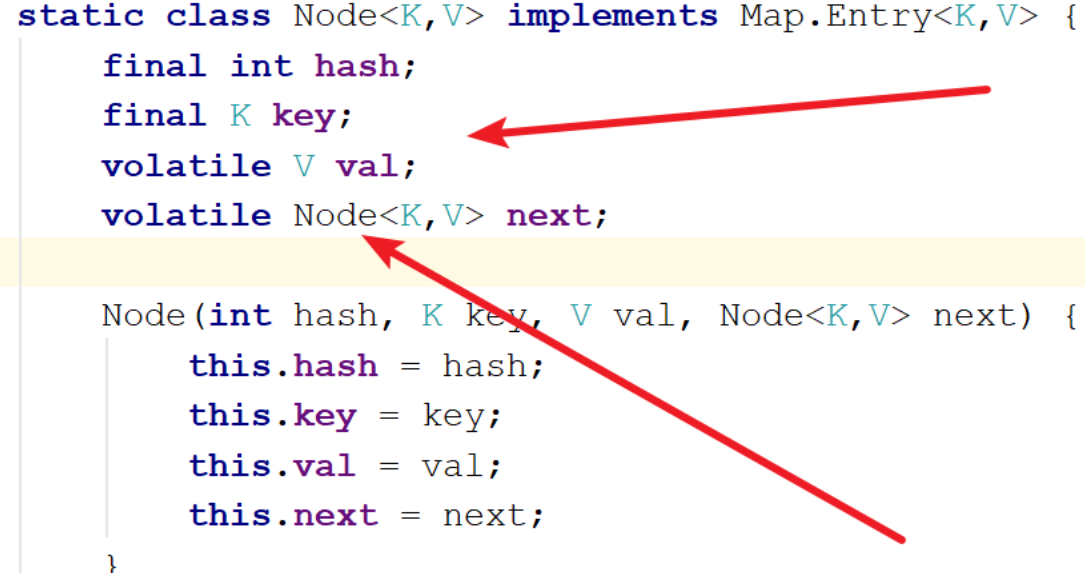
2、是在成員變數數組table上加了volatile?

結論:get通過Node內部類volatile關鍵字來保證可見性、有序性
總結
- 計算hash值,定位到該table索引位置,如果是首節點符合就返回
- 如果遇到擴容的時候,會調用標誌正在擴容節點ForwardingNode的find方法,查找該節點,匹配就返回
- 以上都不符合的話,就往下遍歷節點,匹配就返回,否則最後就返回null
- get不加鎖,是因為Node的成員val和指針next是用volatile修飾的
- 在1.8中ConcurrentHashMap的get操作全程不需要加鎖,這也是它比其他併發集合比如hashtable安全效率高的原因之一
擴展:
remove的操作與put一樣。只是put是加到鏈表上,而remove是在鏈表上移除。
題外話
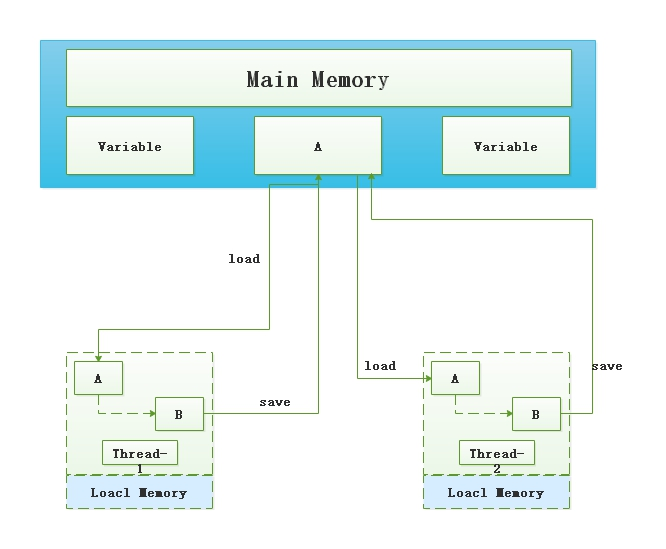
Cmap里用到了大量的CAS
CAS(Compare and Swap), 比較並交換,它是一個樂觀鎖
比較的什麼?替換的什麼?
比較當前工作記憶體的值和主記憶體的值,如相同則修改,否則繼續比較;直到記憶體和工作記憶體中的值一致為止
解釋
這是因為我們執行第一個的時候,期望值(主存)和原本值是滿足的,因此修改成功,
第二次後,主記憶體的值已經修改成了B,不滿足期望值,因此返回了false,本次寫入失敗
cas有什麼缺點?如何解決
缺點一
缺點:
最大缺點就是ABA問題
ABA:如果一個值原來是A,變成了B,又變成了A,那麼使用CAS進行檢查時會發現它的值沒有發生變化,但是實際上卻變化了
解決方案:
1、使用版本號。在變數前面追加上版本號,每次變數更新的時候把版本號加一,那麼A-B-A 就會變成1A-2B-3A
2、從Java1.5開始JDK的atomic包里提供了一個類AtomicStampedReference來解決ABA問題
這個類的compareAndSet方法作用是首先檢查當前引用是否等於預期引用,並且當前標誌是否等於預期標誌,如果全部相等,則更新
缺點二
不停自旋(迴圈)會給CPU帶來更大的開銷
本文由傳智教育博學谷 - 狂野架構師教研團隊發佈
如果本文對您有幫助,歡迎關註和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力
轉載請註明出處!


