
首先nosql可以被理解為not only sql 泛指非關係型資料庫,也就是說不僅僅是sql,所以它既包含了sql的一些東西,但是又和sql不同,併在其的基礎上改變或者說擴展了一些東西。 提到nosql,首先我們就要分析一下關係型資料庫的行式存儲和非關係型資料庫的列式存儲區別在哪? 行式存儲我們都 ...
首先nosql可以被理解為not only sql 泛指非關係型資料庫,也就是說不僅僅是sql,所以它既包含了sql的一些東西,但是又和sql不同,併在其的基礎上改變或者說擴展了一些東西。
提到nosql,首先我們就要分析一下關係型資料庫的行式存儲和非關係型資料庫的列式存儲區別在哪?
行式存儲我們都很熟悉,不論是mysql數據表還是我們熟悉的excel表,這些表裡每一行都是完整的一條數據,它們彼此關聯,彼此有關係。
以核酸檢測的數據為例:
行式存儲
一般核酸檢測需要以下幾個欄位:姓名、身份證號、檢測機構、檢測時間、結果、價格
比如是這樣的:
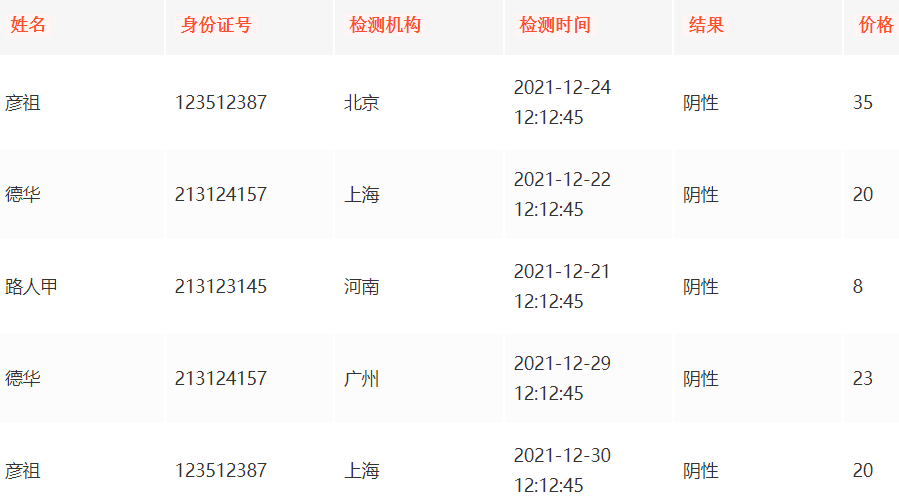

行存儲優點分析
- 在這樣的物理結構下,因為是連續空間,所以插入一條數據只需要追加到當前數據之後即可,很方便
- 對於按記錄查詢也很方便,例如:我們要查詢彥祖的所有核酸記錄,頁面應用的話應該是通過彥祖的身份證號
- 對應的sql如下:
select * from 核酸記錄表 where 身份證號='彥祖的身份證號'
- 這個sql的執行流程比較清晰
1.先從索引查詢出來彥祖的記錄存儲的物理地址
2.在通過物理地址去表的物理存儲中查詢對應地址中的數據
- 這樣就可以快速得到彥祖的核酸記錄
行存儲缺點分析
- 這時候,業務方提了一個需求,他要統計彥祖做核酸總共花了多少錢
- 對於這個需求,sql實現也很簡單,通過對
價格列sum就可以實現,sql如下:
select sum(價格) from 核酸記錄表 where 身份證號='彥祖的身份證號'
- 這個sql的執行流程也比較清晰
1.先從索引查詢出來彥祖的記錄存儲的物理地址
2.在通過物理地址去表的物理存儲中查詢對應地址中的數據
3.拿到所有數據時候,再通過對於價格列sum聚合得到結果
- 分析下,因為行存儲使用的是連續空間,即使需求裡面只需要
select sum(價格),但是讀取物理存儲時候,還是讀取出來了所有的欄位
行存儲優缺點總結
- 通過上面的分析,總結一下行存儲的優缺點
優點:
1.連續空間對於插入/更新很方便
2.對於記錄查詢很方便
缺點
1.會查詢出來很多不需要的列
列式存儲
- 在列存儲中,對於同樣的核酸記錄表,存儲的物理結構如下:

- 在列式存儲中,會把每一列存儲到一起,如
姓名列,是把所有記錄中的姓名這列的值使用連續空間存放到一起 - 而對於各個列之間,是沒有必要使用連續空間存放到一起的,所以很多列式資料庫都使用了分散式存儲的方式,存儲各個列
- 下麵我們來分析下列存儲的
數據壓縮和查詢執行流程
列存儲的數據壓縮
- 很多列式資料庫都是通過
字典表的方式進行數據壓縮 - 因為是把每一列存放到一起的,所以很容易通過對於每一列進行去重,來構建一個字典表,例如:
- 對於
姓名列,這列的所有數據如下:
彥祖|德華|路人甲|德華|彥祖
-
對這列值去重以後,構建一張
姓名列字典表,構建演算法忽略,就使用自增id的方式,如下:id姓名列1 彥祖 2 德華 3 路人甲 -
這樣構建字典表,對於列存儲的物理存儲結構,就可以執行存儲字典表中的id,而不用存儲具體的值,有了字典表以後
姓名列存儲如下:
1|2|3|2|1
- 同樣對於
價格列,這列的所有數據如下:
35|20|8|23|20
-
對這列值去重以後,構建一張
價格列字典表,構建演算法忽略,就使用自增id的方式,如下:id價格列1 35 2 20 3 8 4 23 -
有了字典表以後
價格列存儲如下:
1|2|3|4|2
- 這樣通過一些數據壓縮演算法等,可以對數據存儲進行壓縮
列存儲的查詢執行過程
- 有字典表以後,我們來看下,列存儲一般是如何進行查詢的
- 業務需求查詢
彥祖,20塊錢做的核酸記錄:
select * from 核酸記錄表 where 姓名=彥祖 and 價格=20
- 對於該sql,執行過程如下:
1.對於where 姓名=彥祖
首先查詢姓名字典表,查詢到彥祖的id=1
id |
姓名列 |
|---|---|
| 1 | 彥祖 |
| 2 | 德華 |
| 3 | 路人甲 |
2.通過查詢到彥祖的id,對於性名列進行對比,構建一個bitmap,把匹配的要的列的索引位設置為1,否則為0
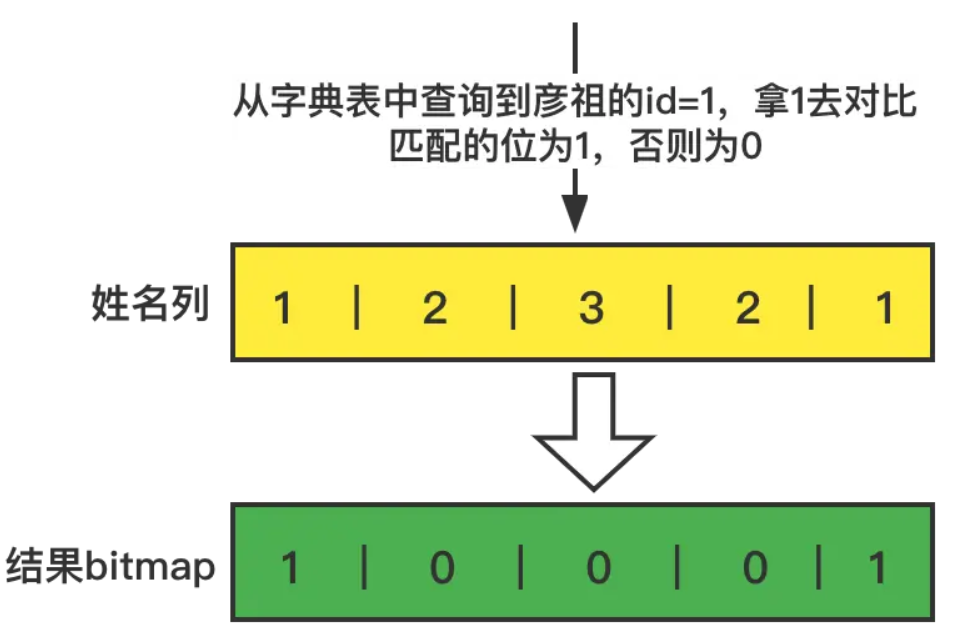
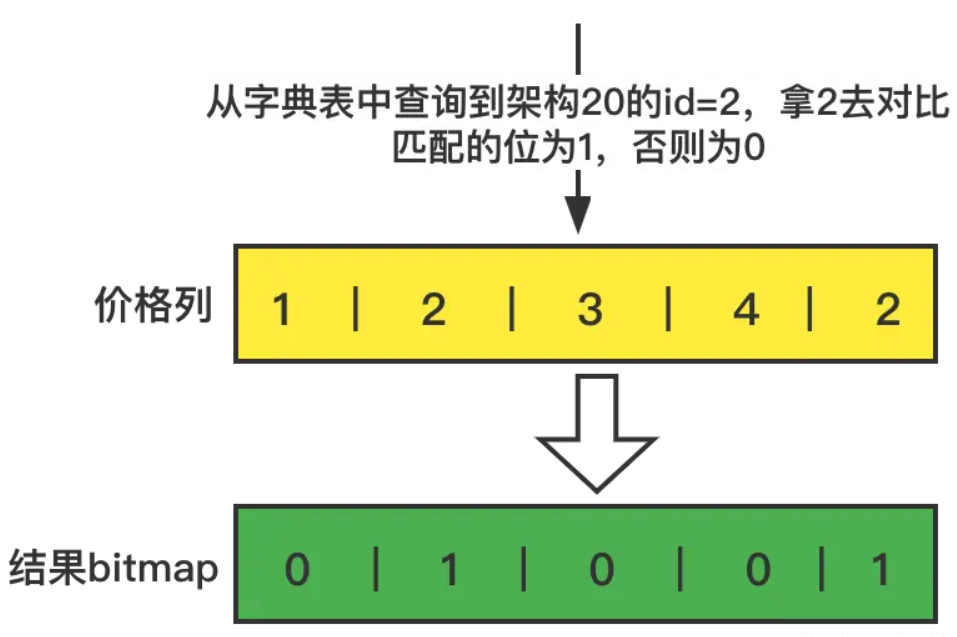
3.對於where 價格=20 和上面一樣的操作,先查詢價格欄位表,20 的id=2
id |
價格列 |
|---|---|
| 1 | 35 |
| 2 | 20 |
| 3 | 8 |
| 4 | 23 |
4.通過查詢到價格20的id,對於價格列進行對比,構建一個bitmap,把匹配的要的列的索引位設置為1,否則為0
5.對於兩個where條件的結果bitmap做與運算,bitmap中,位為1的索引就是要查詢數據的所有列的索引,如該例子中,兩個結果bitmap與運算後的結果是00001,所以所有列的第5個值,拼接起來就是我們要查詢的數據。
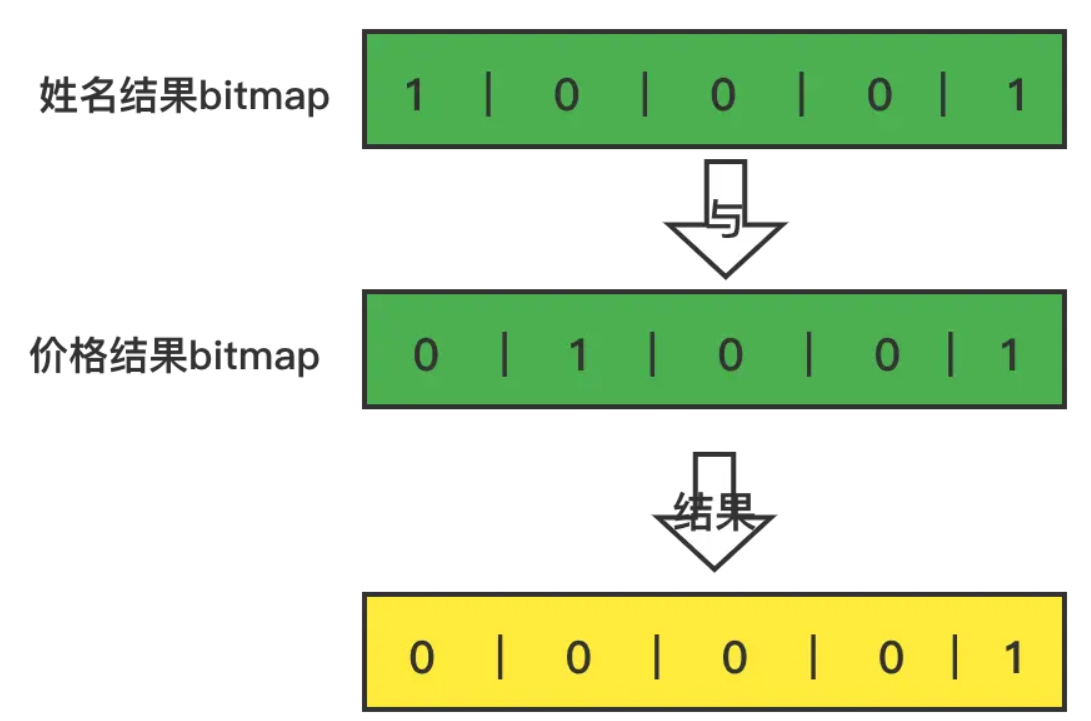
6.所以我們把所有列的第五個值拿出來組裝後就是我們需要的數據
列存儲優點分析
- 上面講了列存儲的
數據壓縮,在數據壓縮上列存儲有一定的優勢 - 每一列都可以天然做索引,不需要額外的數據結構來對各個列構建索引,所以不用在意每一列的數據類型,都可以做索引
- 對於統計彥祖做核酸總共花了多少錢這種需求
select sum(價格) from 核酸記錄表 where 身份證號='彥祖的身份證號'
- 因為列是
分開存儲的,按照上面講的查詢流程,其實最後我們得到的結果bitmap,拿到位=1的索引後,我們不需要查詢所有的列,只需要拿著索引去價格列中獲取相應位置的值,然後在進行sum聚合
列存儲缺點分析
- 因為各個列是分開存儲的,所以在插入、更新時,需要對於
每一個列進行操作,沒有行存儲連續空間那麼方便 - 還是看上面說的查詢過程,每次查詢過後,都需要對查詢到的需要的列進行一個數據組裝
列存儲優缺點總結
- 通過上面的分析,總結一下列存儲的優缺點
優點:
1.數據壓縮比較有優勢
2.任何列都可以做索引
3.查詢時只有涉及到的列會被讀取
缺點
1.每次查詢時,都需要對查詢到的列進行數據重新組裝
2.插入/更新操作比較困難
參考自:https://juejin.cn/post/7056820168239874062
好看請贊,養成習慣 :) 本文來自博客園,作者:靠譜楊, 轉載請註明原文鏈接:https://www.cnblogs.com/rainbow-1/p/16573903.html


