
有讀者可能會一臉懵逼? 啥是索引潛水? 你給起的名字的嗎?有沒有索引蛙泳? 這個名字還真不是我起的,今天要講的知識點就叫索引潛水(Index dive)。 先要從一件怪事說起: ...
有讀者可能會一臉懵逼?
啥是索引潛水?
你給起的名字的嗎?有沒有索引蛙泳?

這個名字還真不是我起的,今天要講的知識點就叫索引潛水(Index dive)。
先要從一件怪事說起:
我先造點數據復現一下問題,創建一張用戶表:
CREATE TABLE `user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主鍵ID',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT 0 COMMENT '年齡',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
通過一批用戶年齡,查詢該年齡的用戶信息,並查看一下SQL執行計劃:
explain select * from user
where age in (1,2,3,4,5,6,7,8,9);

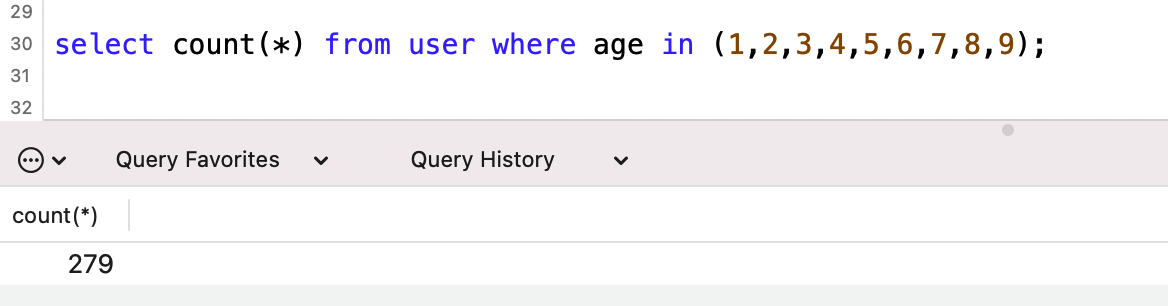
where條件中有9個參數,重點關註一下執行計劃中的預估掃描行數為279行。
到這裡沒什麼問題,預估的非常準,實際就是279行。
但是,問題來了,當我們在where條件中,再加一個參數,變成了10個參數,預估掃描行數本應該增加,結果卻大大減少了。
explain select * from user
where age in (1,2,3,4,5,6,7,8,9,10);

一下子減少到了30行,可是實際行數是多少呢?
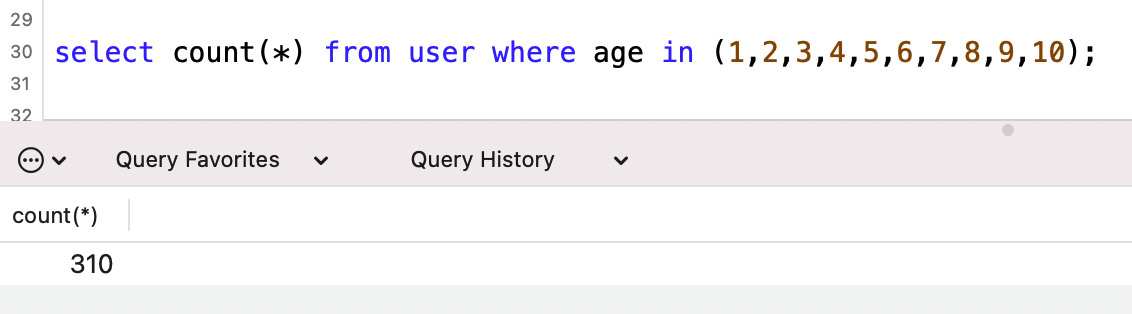
實際是310行,預估掃描行數是30行,真是錯到姥姥家了。
MySQL咋回事啊,到底還能不能預估?
不能預估的話,換其他人!

大家肯定也是滿臉疑惑,直到我去官網上看到了一個詞語,索引潛水(Index dive)。
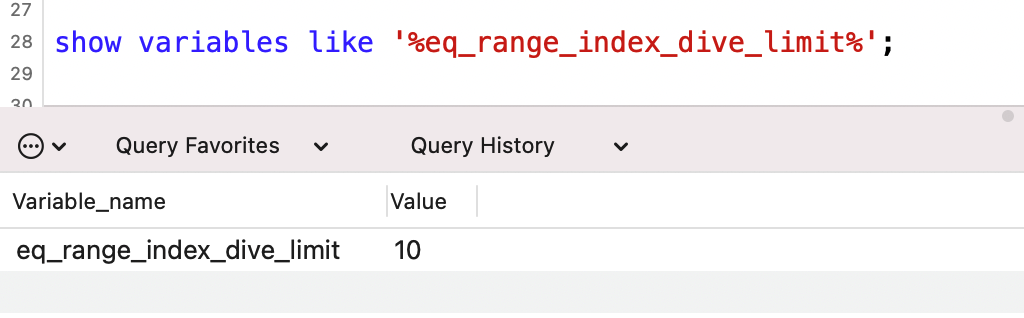
跟這個詞語相關的,還有一個配置參數 eq_range_index_dive_limit。
MySQL5.7.3之前的版本,這個值預設是10,之後的版本,這個值預設是200。
可以使用命令查看一下這個值的大小:
show variables like '%eq_range_index_dive_limit%';
當然,我們也可以手動修改這個值的大小:
set eq_range_index_dive_limit=200;
這個 eq_range_index_dive_limit 配置的作用就是:
當where語句in條件中參數個數小於這個值的時候,MySQL就採用索引潛水(Index dive)的方式預估掃描行數,非常準確。
當where語句in條件中參數個數大於等於這個值的時候,MySQL就採用另一種方式索引統計(Index statistics)預估掃描行數,誤差較大。
MySQL為什麼要這麼做呢?
都用索引潛水(Index dive)的方式預估掃描行數,不好嗎?
其實這是基於成本的考慮,索引潛水估算成本較高,適合小數據量。索引統計估算成本較低,適合大數據量。
一般情況下,我們的where語句的in條件的參數不會太多,適合使用索引潛水預估掃描行數。
建議還在使用MySQL5.7.3之前版本的同學們,手動修改一下索引潛水的配置參數,改成合適的數值。
如果你們項目中in條件最多有500個參數,就把配置參數改成501。
這樣MySQL預估掃描行數更準確,可以選擇更合適的索引。

快去檢查一下你們的線上配置吧!
文章持續更新,可以微信搜一搜「 一燈架構 」第一時間閱讀更多技術乾貨。


