
[數據結構-線性表1.1] 數組(.NET源碼學習) 數組,一種數據類型(在絕大數語言中不是基本數據類型)且為引用類型,在記憶體中以連續的記憶體單元進行分配,所以其大小在創建對象後為定值,不可更改。 一.記憶體分配 對於兩種不同數據類型而言,其記憶體分配方式是不同的。值類型直接在棧(C#中稱為堆棧Stack ...
[數據結構-線性表1.1] 數組(.NET源碼學習)
數組,一種數據類型(在絕大數語言中不是基本數據類型)且為引用類型,在記憶體中以連續的記憶體單元進行分配,所以其大小在創建對象後為定值,不可更改。
一.記憶體分配
對於兩種不同數據類型而言,其記憶體分配方式是不同的。值類型直接在棧(C#中稱為堆棧Stack)上分配,將其儲存的內容直接存放到棧中;引用類型則是將指向實例對象的地址存在棧中,對該地址進行解析後獲得一個在堆(此處,C#中稱為托管堆)中的位置,這個位置儲存著真正的內容。

對於int類型,其大小為32位,即4個位元組,所以整型數組中的每個元素占4個位元組。但整個數組在記憶體中所占位元組大小並不是“Length * 4”,因為在位數組分配的記憶體開頭會被同步索引塊、類型對象指針和數組長度所占據。
一般地:對於32位程式,上述三者分別占用4個位元組;64位程式則分別占用8個位元組。

在記憶體分配表中可以看到:(32位程式)
第一行表示同步索引塊;第二行表示類型對象指針;第三行表示當前數組所分配的長度;第四行目前本人不知道其具體含義,歡迎大佬留言;之後便是存儲的每個元素,每個元素占4個位元組。
【註:上述詳細內容請查找CLR相關資料】
據此,可以推斷出:我們顯示看到的長度指的是可儲存元素的數量,而數組的整體大小則需要額外加上16位元組(32位)/ 32位元組(64位)。
二.訪問與迭代
(一)數組的訪問與遍歷
對於數組的訪問,一般採用索引的方式訪問每一個元素。本人看來,索引讀取的內容是記憶體地址。數組之所以可以用索引來訪問,是因為其在記憶體中是連續的,就像C/C++中用指針訪問數組,指針加一即表示下一個元素。此外,由於數組滿足通過索引訪問,索引由整形數字表示,所以理論上,數組最大長度為整型最大值(int.MaxValue = 2^31 – 1 = 2147483647),但由於實際記憶體的原因,一般地,一維最好不要超過10^7,二維最好不要超過10^5 * 10^5。
(二)長度索引模式與迭代器模式
長度索引模式要求被訪問對象具有可確定的長度且支持索引運算符[],如數組和集合(List等);而某些數據結構在運行時長度未知,某些不支持索引訪問,如Stack<T>、Queue<T> 和 Dictionary<TKey and TValue>等。
對於迭代器模式,其實現方式基於IEnumerator<T>介面,也就是說能夠使用foreach進行訪問的對象/類型,必須可以創建/返回該介面的對象。
【註:C#不要求必須實現IEnumerable/IEnumerable<T>才能使用foreach迭代數據類型,只要求包含GetEnumerator(可返回類型為IEnumerator<T>的對象)的公共定義即可】

IEnumerator<T>介面對應的類型是一個集合訪問器,即可迭代對象,其內部包含一個屬性Current,用於返回當前處理的元素;兩個方法(bool)MoveNext,從一個元素移到下一個元素,同時檢測是否已枚舉完所有項;Reset,通常會拋出 NotImplementedException,是在無法實現請求的方法或操作時引發的異常。
就數組而言對於上述兩種模式的效率差異不是很大。平均地,除第一次外,索引訪問要快於迭代器訪問。

(三)IEnumerable<T>與IEnumerator<T>
對於IEnumerator<T>而言,在多重迴圈、多線程以及共用狀態下,如果兩個foreach彼此交錯且訪問的是同一個集合,那就會出現一個枚舉器被多條語句使用的情況。集合必須始終有當前元素的狀態指示符,以便在調用MoveNext時,可以確定下一個元素。在這種情況下,交錯的一個迴圈可能會影響另一個迴圈。
所以,集合類不直接支持IEnumerator<T>和IEnumerator介面。而是直接支持另一種介面IEnumerable<T>。該介面的作用是返回一個類型為IEnumerator<T>的對象。這樣不同的迭代語句有著自己的迭代器,不會相互爭搶。
三.C#中的數組
(一)維度數組
當然,官方應該沒有這樣的稱法,只是稱一維、二維數組等。
對於一維數組,其在記憶體中就是簡單的以連續的方式進行存儲。理論上,其最大長度為2147483647,但實測後其最大長度為2147483591(實測平臺:.NET 6 32位控制台程式)。
對於二維或更高維的數組,其在記憶體中的存儲方式並不是我們所想象的一個矩陣或一個立方,記憶體只由一個個獨立的存儲單元組成,並不能表示出具有相關性的幾何區域。

在記憶體分配表中可以看到:(32位程式)
一維數組占用前16位元組,存儲數組本體信息;而二維數組占用32位元組存儲本體信息。之後的數據存儲方式與一維數組一致,每個元素占4個位元組。由此可以推斷出多維數組的存儲方式依舊是按連續記憶體的方式進行存儲。
#一維數組和多維數組的下標轉換#
(1)多維 => 一維(扁平化處理)
int[,,,,…,] arr = new int[a, b, c, d,…,k];
arr[x, y, z, w,…,n] => idx = x * (b * c * d * …) + y * (c * d * …) + z * (d * …) + … + n
(2)一維 => 多維(以二維為例)
int[,] arr = new int[a, b];
p[x] = arr[u, v] 其中u = x / b v = x % b
(二)交錯數組
以數組為元素的數組,叫做交錯數組,即該數組內部元素為數組,每個數組的大小可以不同。


以上時兩種基本初始化方式。在初始化交錯數組時,第一個索引運算符表示長度,第二個索引運算符表示維度,如一維[],二維[,]等。
元素的訪問與之前提到的方法類似,通過單個索引運算符訪問

第一個索引運算符表示arr中的對象,第二個索引運算符表示對應對象中的元素。
四.有關數組的常用API(源碼學習)
【註:本節提到的源碼及內容均在.NET 5的基礎上論述】
(一)排序Array.Sort()
通過反編譯發現,該方法存在的16個重載最後都會調用Line 2125的方法。
【以下內容為源碼分析】
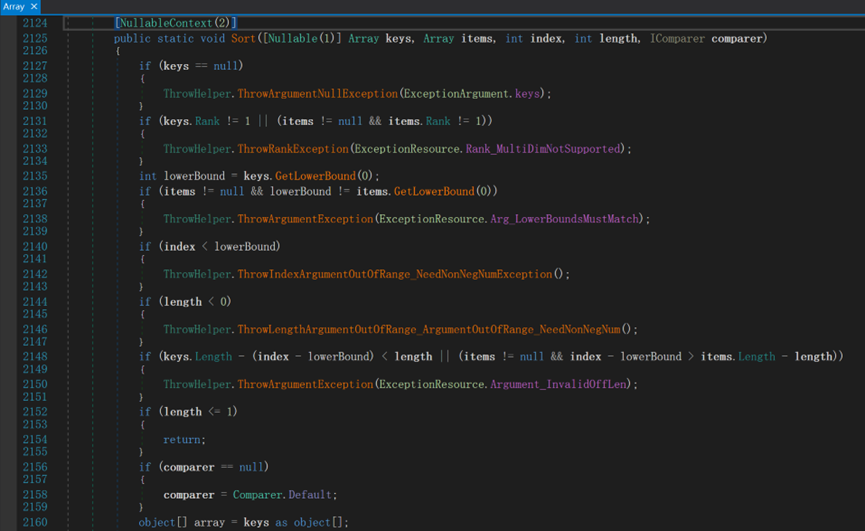
- Line 2125:
(1) Nullable<T> 表示可被分配為null的值類型,[Nullable(type)]表示被修飾的數據結構可以存儲type類型的元素,沒有值則存儲null;
(2) keys 表示目標數組,即待排序的數組;
(3) items 表示另一個數組(預設為null),其內部的每一個元素與keys中每個關鍵字對應;常用於兩個數組的關聯排序,預設將keys中的元素按索引順序和items中的元素一一對應,在排序時以keys中的元素為比較對象進行排序,在對keys中的元素進行位置移動時會連帶對應items中的元素一起移動,類似於鍵值對。
(4) index:排序起始索引(預設為0);
(5) length:排序長度(預設為arr.Length);
(6) compare:比較器對象(預設為升序)。
- Line 2131:Array.Rank 該屬性獲取數組的秩,即維度。
- Line 2135:Array.GetLowerBound(Int32) 該方法獲取數組下限索引,其中的整數代表“行索引”。
- Line 2136:keys的起始索引必須和items的起始索引一致。
- Line 2148:
(1) keys.Length - (index - lowerBound) < length 表示 從index開始的要排序的元素長度 小於 標稱長度length,即要排序的元素長度不夠;
(2) items != null && index – lowerBound > items.Length – length 表示 index之前的不參與排序元素長度 已經超過 items的長度,使得keys中要排序的部分沒有可對應的items元素。
- Line 2158:預設比較器對象為升序

- Line 2160~2169:
(1) as 關鍵字判斷並進行轉換。若無法轉換且不發生錯誤,則返回null;否則返迴轉換後得到對象;
(2) Line 2161:array != null 表示該數組成功轉換為object類型;
(3) Line 2164:表示items為空 或 items成功轉換;
【註:(4)(5)為本人結合資料推斷得出,有待證實】
(4) as成功轉換的前提是,當需要轉化對象的類型屬於轉換目標類型 或者 屬於轉換目標類型的派生類型時,轉換操作才能成功,而且並不產生新的對象。而數組類型在System.Array中,並不屬於System.Object,所以自帶的數組類型無法利用as轉換為object類型。
因此,可推斷:所有基本數據類型均不能以上述方式成功轉換,因為基本數據類型屬於System.ValueType;而自定義的對象數據類型可以成功轉換,因為自定義類型屬於Sytem.Object。
(5) 如果全都轉換成功,則需要利用對象的排序方式進行排序,不能使用基本數據類型的方式進行排序。(體現在Line 2166與Line 2215)。
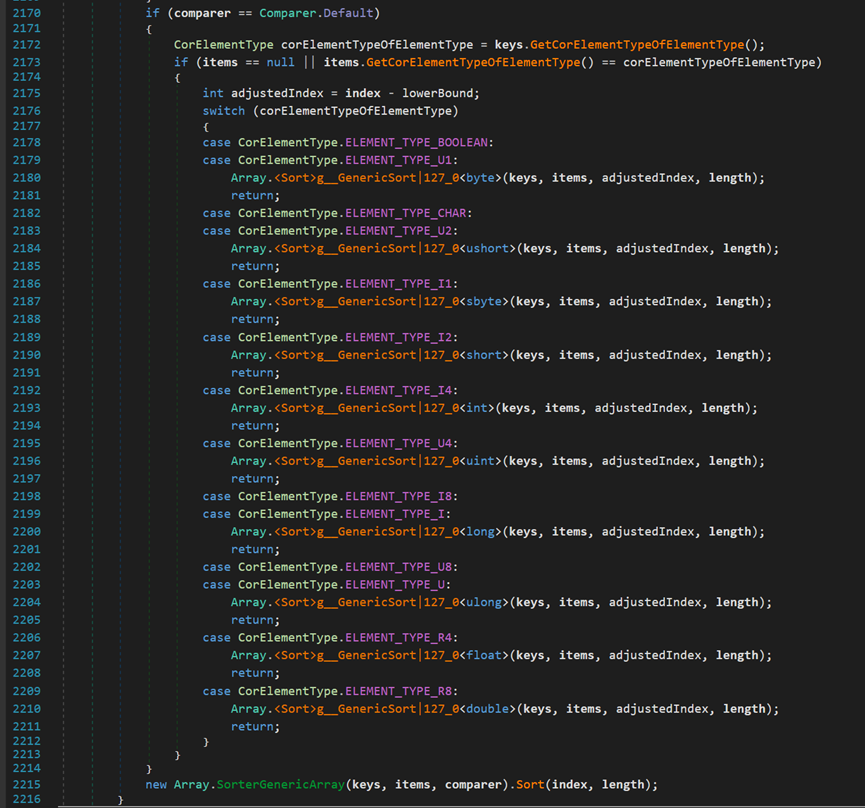
- Line 2172:CorElementType指定公共語言運行時Type、類型修飾符或有關元數據類型簽名中的類型的信息,即指明類型。(詳細內容見:CorElementType 枚舉 - .NET Framework | Microsoft Docs)。keys.GetCorElementTypeOfElementType()表示返回keys對應的類型。
- Line 2173:要麼不進行關聯排序(items == null),要麼進行關聯排序(必須保證二者類型相同)。
- Line 2176~2211:根據不同類型選取 不同類型<T> 的方法。

之後將keys轉換為Span列表,Span類型可以表示任意記憶體的相鄰區域,以此達到部分排序的目的;Span中的Sort方法位於MemoryExtensions類中。
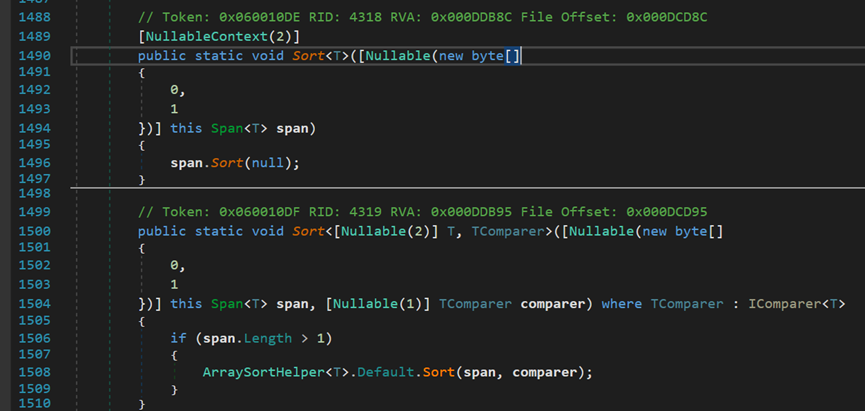
- Line 1506:當列表長度大於1時,調用ArraySortHelper<T>中Default對象的Sort方法。
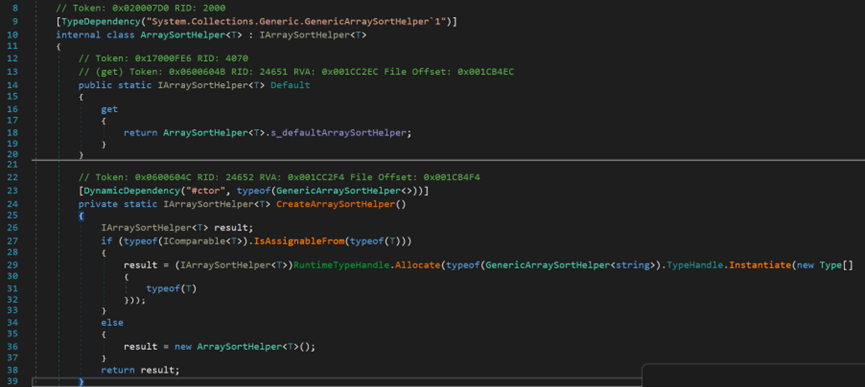
- Line 10:ArraySortHelper<T>派生自介面IArraySortHelper<T>。
- Line 18:進入到Line 24。
- Line 27:創建ArraySortHelper對象;
(1) 內部的Default對象會根據是否實現了介面IComparable<T>來創建不同的 ArraySortHelper;
(2) Type.IsAssignbleFrom(Type c)方法判讀指定類型c的實例是否能分配給當前類型Type的變數;即判斷c是否為Type類型或其派生類型。
- Line 29:預設情況下,使用預設比較器對象(升序)滿足該行條件,使用GenericArraySortHelper中的Sort方法。
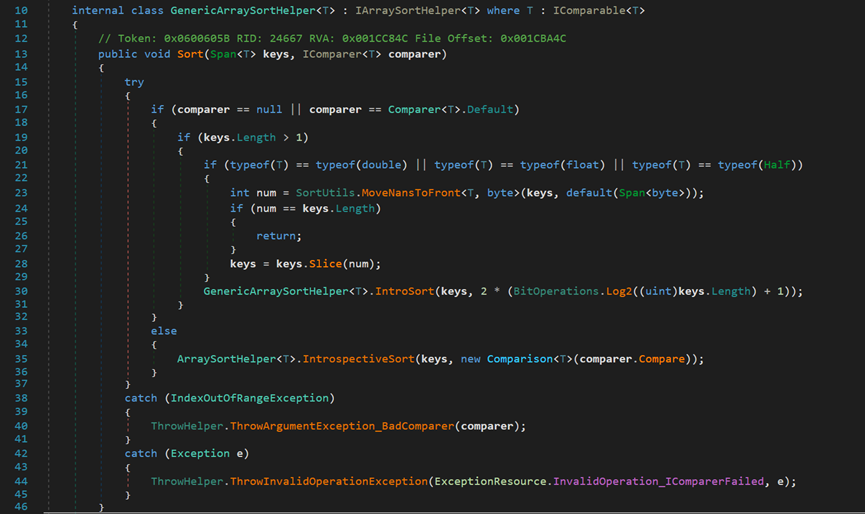
- Line 16、Line 35:無論是否滿足Line 17處的條件,最終都會首先進入IntroSort方法。
- Line 30:2 * (BitOperations.Log2((uint)keys.Length) + 1) 計算若使用堆排序後,可建成的堆的深度。
【至此,數組開始正式進入排序階段】
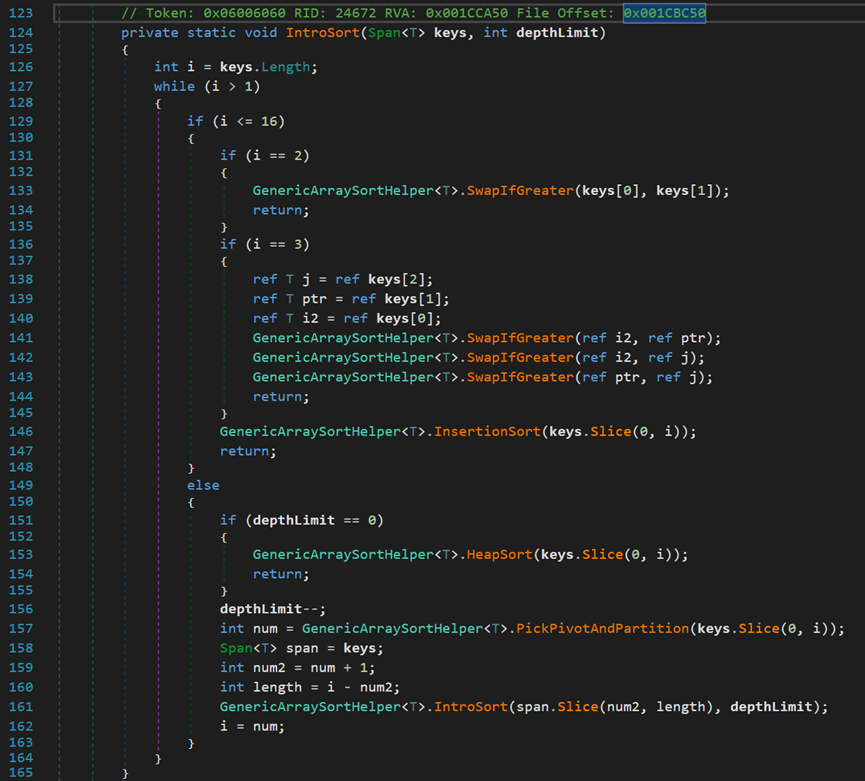
- Line 129:註意到,當Length小於等於16時,選用InsertionSort插入排序;反之使用HeapSort堆排序。這是一種優化思想,根據大量實驗表明:數據量小於等於16時插排效率更高。
- Line 151:遞歸操作,每次 depthLimit 都會減1, 當深度為0排序還沒有完成的時候,就會直接使用堆排序(HeapSort)
(插排、堆排代碼如下):
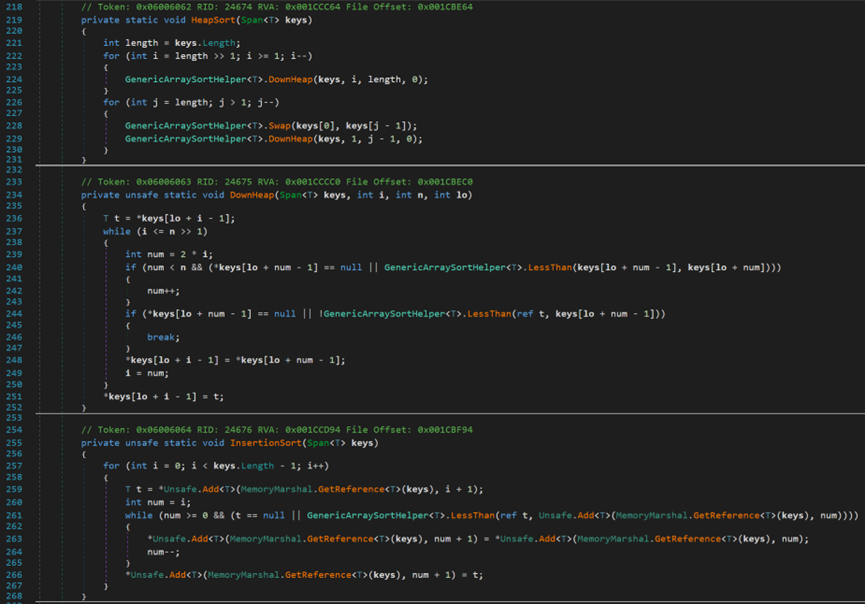
其中的DownHeap是建立頂堆的過程,預設為小頂堆。
- Line 133:SwapIfGreater(T t, T t)該方法用於交換兩個元素,使其滿足升序。
- Line 157:註意到此處的快速排序,其內部使用了尾遞歸的快速排序以及三數取中法。
小結 一
1. .NET對數組進行排序時,有較長的“前搖”,需要判斷、轉換等相關操作;
2. .NET中對數組的排序方法不是單一的,而是綜合許多排序方法,在不同條件下選擇不同的方法,以達到最優的解法。
(二)克隆Array.Clone()


- Line 24:Object.MemberwiseClone方法,創建當前 Object 的淺表副本;
一個集合的淺度拷貝意味著只拷貝集合中的元素,不管他們是引用類型或者是值類型,不拷貝引用所指的對象。即,新集合中的引用和原始集合中的引用所指的對象是同一個對象。與此形成對比的是深度拷貝,不僅拷貝集合中的元素,而且還拷貝元素直接或者間接引用的所有東西。即,新集合中的引用和原始集合中的引用所指的對象是不同的。

【註:下方內容為本人結合資料推斷得出,有待證實】
- Line 26:以被克隆對象為基礎,分配一個新的未初始化的對象。
- Line 27:返回一個指向目標對象的指針(從該指針處開始寫入數據)。
- Line 28、29:分別獲取被克隆對象與目標對象的數據。
- Line 30:以指針形式訪問ConatinsCGPointers

將傳入的對象的Flags屬性與2^24做且運算 和 (uint)0無符號整數0進行比較。之後按照不同的情況進行數據填充,完成後返回類型為object的對象。
(三)複製Array.Copy()
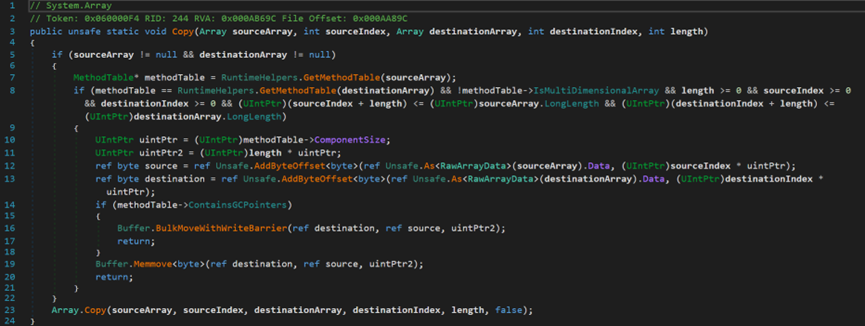
- Line 3:sourceArray源數組(被覆制的數組),sourceIndex複製起點,destinationArray目標數組,destinationIndex粘貼起點,length複製長度。
- Line 7:獲取源數組的數據類型。
- Line 8:進行相關判斷,是否滿足複製粘貼條件;包括:源數組類型與目標數組類型應一致、源數組不應為多維數組、複製長度和複製起點大於等於0、複製起點索引值 + 複製長度小於等於目標數組最大長度、粘貼起點索引值 + 複製長度小於等於目標數組最大長度。
接下來的過程與Clone方法基本一致。
- Line 23:註意到最後一個參數false,表示條件不滿足無法複製。
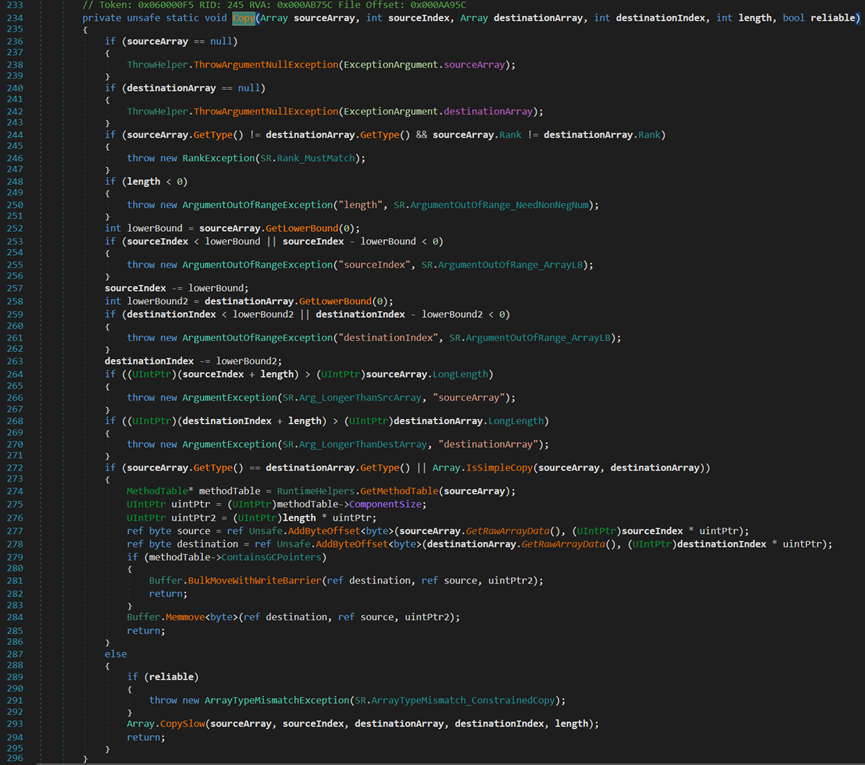
該部分主要功能是拋出異常,因為在實際使用中,無法調用到包含bool reliable參數的這個方法。

(四)複製Array.CopyTo()

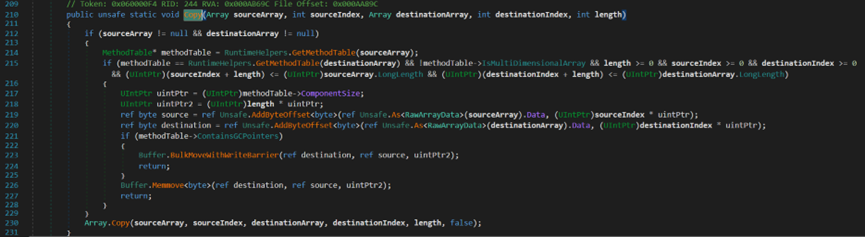
- Line 3:Array array為目標數組。
可以發現,其原理和Copy方法、Clone方法基本一致。
小結 二
1. 三種方法均可以將一個數組的內容,放到另一個數組上。
2. Clone方法具有返回值,為Object類型,在克隆後直接賦值給目標數組,因此不需要目標數組實例化。
2. Copy與CopyTo方法沒有返回值,是通過直接在目標數組上填充,以完成複製,因此目標數組必須實例化且目標數組必須和源數組類型一致。
4. Copy為靜態方法,可通過Array類名直接調用;Clone與CopyTo方法為非靜態方法,故需要實例化的一個數組來調用。
5. Clone方法使淺層拷貝,Copy與CopyTo是深層拷貝。



總結
1. 本文從源碼的角度,對數組、數組遍歷以及常見方法進行了分析與論述。更多關於數組的內容可參閱(.NET API 瀏覽器 | Microsoft Docs)。
2. 對於記憶體分配,數組屬於引用類型,其值儲存在堆中,但引用的對象儲存在棧中(是一個記憶體地址),通過該引用對象找到並訪問堆中的值。
3. 對於迭代器訪問,所以可使用迭代器訪問的數據類型均必須可以創建或返回一個IEnumerator<T>的對象,供迭代器使用。
4. 對於Array.Sort()方法,其內部不是單一的排序方式,而是在不同情況下使用不同的的排序方式,以達到最佳效率。
5. 對於三種複製方法,Clone為淺層拷貝,拷貝後,新數組與源數組引用地址相同;Copy與CopyTo為深層拷貝,拷貝後,新數組與源數組引用地址不同,是一個完全新的對象。
【感謝您可以抽出時間閱讀到這裡,因個人水平有限,可能存在錯誤,望各位大佬指正,留下寶貴意見,謝謝!】
TRANSLATE with


