
在電腦發展的早期,一直都是集中式計算,計算能力依賴大型電腦。隨著互聯網的發展,繁重的業務需要巨大的計算能力才能完成,而集中式計算無法滿足要求,大型電腦的價格也非常昂貴。分散式計算將任務分解成更小的部分,分配給多台電腦處理,這樣可以節約整體計算時間,大大提高計算效率。互聯網大型網站往往面臨高並... ...
1.分散式系統的發展
在電腦發展的早期,一直都是集中式計算,計算能力依賴大型電腦。隨著互聯網的發展,繁重的業務需要巨大的計算能力才能完成,而集中式計算無法滿足要求,大型電腦的價格也非常昂貴。分散式計算將任務分解成更小的部分,分配給多台電腦處理,這樣可以節約整體計算時間,大大提高計算效率。
互聯網大型網站往往面臨高併發訪問、海量數據處理等問題,必須保證系統高可用、易伸縮等等。分散式架構採用多台機器協同工作,動態伸縮容量,使用冗餘節點來消除單點故障,提高系統可用性。
2.分散式系統的挑戰
軟體開發沒有銀彈,任何系統結構都有利有弊,分散式系統的挑戰有三點:
- 1)網路資源受限:節點間採用網路通信,而網路存在帶寬限制和延時,任何一個節點都無法做到瞬間響應和高吞吐量。
- 2)節點管理成本:分散式系統節點可能膨脹到成千上萬個,運維節點的成本非常高。
- 3)缺乏全局時鐘:網路上電腦時鐘同步的準確性受到極大的限制,沒有一致的全局時間。電腦在空間隨意分佈,很難定義不同機器上事件先後發生順序。
3.分散式系統基本理論
3.1 CAP定理
分散式系統的三個特性Consistency(一致性)、Availability(可用性)、Partition tolerance(分區容錯性),最多只能同時滿足其中兩個,三者不可兼得。
- Consistency (一致性):數據更新後,所有節點在同一時間的數據完全一致。客戶端併發訪問時,返回的數據是一致的。服務端儘快將數據複製到整個系統,以保證數據最終一致。
- Availability (可用性):系統能夠一直為用戶服務,不出現操作失敗或者超時等情況。在單位時間內的可用性常用N個9來衡量,比如99.999%的可用性。
- Partition Tolerance (分區容錯性):分散式系統內部由許多節點構成,外界看上去是一個整體。節點或網路分區遇到故障的時候,仍然能夠對外提供滿足一致性或可用性的服務。系統中少量機器宕掉,剩下的機器還能夠正常運轉,用戶沒有任何感知。
大型互聯網應用的集群節點非常多,發生節點或者網路故障是常態。系統必須要滿足分區容錯性,最終只能在C和A之間取捨。
傳統行業項目有所不同,以金融系統為例,涉及到金錢的操作,必須要滿足數據一致性。出現網路故障寧可停止服務,也要保證C,最終只能在A和P之間取捨。
3.2 PACELC理論
CAP理論並不能很好的指導現實的系統架構。比如Availability (可用性),如果介面長時間才返回結果,固然可用,但是業務上不能接受。大部分情況下,系統分區都是平穩運行的,系統設計要權衡延遲與數據一致性的問題。為了保證數據一致性,讀寫的延遲必然升高。
在分區錯誤的情況下,在C和A中取捨,縮寫為 PAC。分區正確的情況下,取 Latency(延遲)與 Consistency(一致性),縮寫為LC。PACELC 中的 E 代表 Else,連起來就是PACELC。
很多存儲軟體實現了 PACELC 的策略,用戶根據不同業務場景使用不同的配置。以MySQL主從複製為例,提供了三種模式:
- 非同步模式:主庫執行完客戶端提交的事務,立即將結果返給客戶端,不關心從庫是否已經接收並處理。由於數據同步的延時,客戶端在從庫上可能讀不到最新數據。這種模式對MySQL是性能最佳的,但是用戶需要權衡,業務能否忍受這種延時。
- 全同步複製:主庫執行完客戶端提交的事務,所有的從庫都執行了該事務才返回結果。這樣保證強一致性,但是響應時間變長了。
- 半同步複製:主庫在執行完客戶端提交的事務後,等待至少一個從庫接收到並寫到 relay log 中,才返回給客戶端。這樣做延遲小了很多,相比於非同步複製,數據更加不容易丟失。
3.3 BASE模型
BASE模型全稱是Basically Available(基本可用)、Soft-state(軟狀態/柔性事務)、Eventually Consistent(最終一致性)。絕大部分分散式系統,實現分區容忍性是基本要求,因此要平衡一致性和可用性。BASE強調犧牲高一致性,獲得可用性。允許數據在一段時間內不一致,只要保證最終一致就可以了。
3.4 一致性演算法
分散式系統中的數據一致性問題,是系統設計中最關鍵、最有難度的領域,業界提出了很多成熟的一致性共識演算法。
- Paxios演算法
1998年,萊斯利·蘭伯特(Leslie Lamport)在《The Part-Time Parliament》論文中首次公開Paxos協議。他使用希臘的小島Paxos作為比喻,描述了Paxos小島中通過決議的流程。2001年,Lamport重新發表了朴實的演算法描述版本《Paxos Made Simple》。
- Raft演算法
由於Paxos演算法太難以理解和實現,斯坦福大學的 Diego Ongaro 和 John Ousterhout 提出了更容易理解的 Raft 演算法。相比傳統的 Paxos 演算法,Raft 將大量的計算問題分解成簡單的相對獨立的子問題,並且和 Multi-Paxos 有同樣的性能,
有興趣的朋友,可以看看Raft演算法的動畫演示。
- ZAB協議
ZAB協議全稱 Zookeeper Atomic Broadcast(Zookeeper 原子廣播協議)。分散式協調服務ZooKeeper設計了支持崩潰恢復的一致性協議。基於該協議,ZooKeeper 實現了一種主從模式的系統架構來保持集群中各個副本之間的數據一致性。從設計上看,ZAB 協議和 Raft 很相似。
4.分散式架構組件
4.1 主要組件
- 服務註冊與發現:Spring Cloud Eureka、Apache Nacos、Apache Zookeeper、ETCD
- 服務調用:Spring Cloud Feign、Apache Dubbo、Motan、gRPC
- 微服務網關:Spring Cloud Zuul、Spring Cloud Gateway、Apache ShenYu、Kong
- 微服務熔斷降級:Spring Cloud Hytrix、Alibaba Sentinel
- 負載均衡器:Spring Cloud Ribbon、Spring Cloud LoadBalancer
- 分散式監控:Spring Boot Admin、美團 CAT、Zabbix、Prometheus + Grafana + Alertmanager、Open-Falcon
- 配置管理:Spring Cloud Config、Alibaba Nacos、百度Disconf、攜程Apollo
- 消息隊列:RocketMQ、Kafka、RabbitMQ
- 任務調度:Apache Dolphinscheduler、Apache ElasticJob、XXL-JOB
- 分散式事務:Alibaba Seata
- 調用鏈跟蹤:Spring Cloud Sleuth + ZipKin、Apache Skywalking
- 日誌採集:Flume + Kafka + HDFS、Elasticsearch + Logstash + kafka + Kiabana
- 分庫分表:Apache ShardingSphere、MyCat 、美團DBProxy
- 分散式鎖:Redisson + Redis
- 許可權控制:Spring Security、Shiro + JWT
- 文件系統:Fastdfs、Minio、HDFS
- 反向代理:Nginx
4.2 輔助工具
- Java應用診斷:Alibaba Arthas
4.3 常用架構
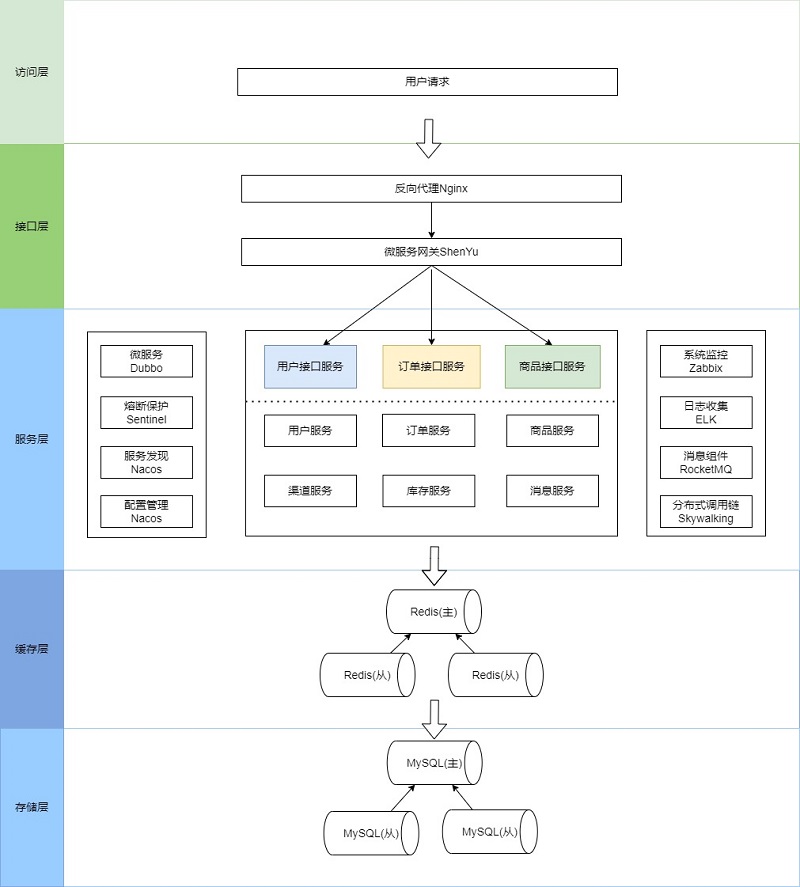
5.常用資料庫
5.1 資料庫的發展
資料庫是一個悠久歷史的行業,從誕生到現在也有接近五十年的歷史了。資料庫一直在技術、業務以及應用場景等方面不停地演進和發展。上世紀九十年代,針對個人辦公、個人娛樂以及企業信息化的場景,基於X86伺服器誕生了像MySQL、MS SQL Server這些著名的關係型資料庫。
NoSQL資料庫是由於互聯網業務的誕生而產生的。2006年,谷歌引入了BigTable,後續出現了HBase、Cassandra、MongoDB和Redis,這些資料庫都是由不同的底層數據組織形式去解決不同的問題。在2010年前後,谷歌又引入了以Spanner為代表的新產品,出現了F1、SequoiaDB、TiDB等NewSQL資料庫,使用SQL解決應用性問題,也保留了NoSQL的可擴展性問題。
NoSQL資料庫是為瞭解決傳統關係型資料庫的弊端,它有四個特點:
- 易擴展:NoSQL數據共同的特點是去掉關係資料庫的關係型特性,數據之間無關係,這樣就非常容易擴展,在架構的層面上帶來了可擴展的能力。
- 高性能:NoSQL資料庫都具有非常高的讀寫性能,尤其在大數據量下同樣表現優秀。由於數據之間的無關係性,資料庫的結構簡單。
- 高可用:NoSQL在不太影響性能的情況,就可以方便地實現高可用的架構。比如Cassandra、HBase模型,通過複製模型也能實現高可用。
- 數據模型靈活:NoSQL無須事先為要存儲的數據建立欄位,隨時可以存儲自定義的數據格式。而在關係資料庫里,增刪欄位是一件非常麻煩的事情。
5.2 OLTP和OLAP
從業務場景來看,數據處理可以分為OLTP和OLAP。這兩種場景採用何種資料庫,取決於開發人員的技術水平和經驗。通常來說,OLTP採用強一致性的關係型資料庫,OLAP採用NoSQL或者列式資料庫。
- OLTP(on-line transaction processing)
OLTP為聯機事務處理,主要用來記錄業務事件的發生。當行為產生後,系統記錄事件是誰在什麼時候什麼地方做了什麼事,在資料庫中進行數據的增刪改查,要求高實時性、強穩定性、數據一致性。
- OLAP(On-Line Analytical Processing)
OLAP為聯機分析處理,側重大數據量查詢。當業務發展到一定程度,要利用離線數據做分析,為決策提供支持。
5.3 常用NoSQL資料庫
- MongoDB
MongoDB是一個面向文檔的資料庫,以JSON格式存儲數據。它主要用於網站的數據存儲、內容管理與緩存應用。MongoDB支持全文檢索,查詢方式非常豐富,在數據處理與聚合等方面具有很強的靈活性,同時具備極高的擴展性和可用性。
- Cassandra
Cassandra是一套開源分散式資料庫系統。最初由Facebook開發,用於儲存收件箱等簡單格式數據,集Google BigTable的數據模型與Amazon Dynamo的完全分散式的架構於一身。由於Cassandra良好的可擴展性,被Digg、Twitter等知名Web 2.0網站所採納,成為了一種流行的分散式結構化數據存儲方案。
- CouchDB
CouchDB是一個面向文檔的資料庫,以JSON格式存儲數據。CouchDB可以用於存儲網站的數據與內容,以及提供緩存等。支持通過JavaScript在CouchDB上運行MapReduce查詢。CouchDB還提供了一個非常方便的基於Web的管理控制台。
- Redis
Redis是一個記憶體中的鍵值資料庫。Redis具備存儲和操作高級數據類型的能力。這些數據類型是大多數開發人員熟悉的基本數據結構(列表、映射、集合)。Redis的讀寫數據的效率極高,遠遠超過常規資料庫,常常用於大型項目的緩存層。
- HBase
HBase 是一個面向列式存儲的分散式資料庫,其設計思想來源於 Google 的 BigTable 論文。HBase 底層存儲基於 HDFS 實現,集群的管理基於 ZooKeeper 實現。HBase 良好的分散式架構設計為海量數據的快速存儲、隨機訪問提供了可能,基於數據副本機制和分區機制可以輕鬆實現線上擴容、縮容和數據容災,是大數據領域中 Key-Value 數據結構存儲最常用的資料庫方案。
- Elasticsearch
Elasticsearch 是一個分散式、高擴展、高實時的搜索與數據分析引擎。它提供了一個多用戶能力的全文搜索引擎,基於RESTful web介面。Elasticsearch是用Java語言開發的,並作為Apache許可條款下的開放源碼發佈,是一種流行的企業級搜索引擎。
- ClickHouse
ClickHouse 是俄羅斯的Yandex(類似百度)開源的列式存儲資料庫,主要用於線上分析處理查詢,能夠使用SQL查詢實時生成分析數據報告。使用場景與Elasticsearch類似,甚至有更高的性能。
5.4 常用關係型資料庫
- Oracle
Oracle是全球最大的信息管理軟體及服務供應商,總部位於美國加州Redwoodshore。Oracle資料庫產品為財富排行榜上的前1000家公司採用,是最知名、使用最廣泛的企業資料庫。
- DB2
DB2是IBM公司開發的關係資料庫管理系統,主要用於大型應用系統,具有較好的可伸縮性 。DB2是IBM推出的第二個關係型資料庫,所以稱為DB2。它提供了高層次的數據利用性、完整性、安全性、並行性、可恢復性,以及小規模到大規模應用程式的執行能力,具有與平臺無關的基本功能和SQL命令運行環境。可以同時在不同操作系統使用,包括Linux、UNIX 和 Windows。
- Microsoft SQL Sever
Microsoft SQL Server 是一個全面的資料庫平臺,使用集成的商業智能 (BI)工具提供了企業級的數據管理。Microsoft SQL Server資料庫引擎為關係型數據和結構化數據提供了更安全可靠的存儲功能,使您可以構建和管理用於業務的高可用和高性能的數據應用程式。
- MySQL
MySQL是使用最廣泛的開源關係型資料庫,由瑞典MySQL AB公司開發,現在已被 Oracle收購。MySQL與常用的主流資料庫Oracle、SQL Server相比,特點就是免費,並且在任何平臺上都能使用,占用的資源較小,受個人用戶以及中小企業青睞。對於大型項目來說,MySQL的承載能力和安全性就略遜於Oracle資料庫。
- MariaDB
MariaDB資料庫管理系統是MySQL的一個分支,主要由開源社區在維護,採用GPL授權許可。MariaDB的目的是完全相容MySQL,包括API和命令行,使之能輕鬆成為MySQL的代替品。在存儲引擎方面,使用XtraDB來代替MySQL的InnoDB。MariaDB名稱來自創始人Michael Widenius的女兒Maria的名字。
- PostgreSQL
PostgreSQL 是一個強大的開源對象關係資料庫系統,它使用並擴展了SQL語言,並結合了許多安全存儲和擴展最複雜數據工作負載的功能。PostgreSQL的起源可以追溯到 1986 年作為加州大學伯克利分校POSTGRES項目的一部分。PostgreSQL的架構、可靠性、數據完整性、功能集、可擴展性得到充分的驗證,開源社區也非常活躍。它是最接近工業標準SQL92的查詢語言,至少實現了SQL:2011標準中要求的179項主要功能中的160項(註:目前沒有哪個資料庫管理系統能完全實現SQL:2011標準中的所有主要功能)。
- TiDB
TiDB是PingCAP公司自主設計、研發的開源分散式關係型資料庫,是一款同時支持線上事務處理與線上分析處理 (Hybrid Transactional and Analytical Processing,HTAP)的融合型分散式資料庫產品,具備水平擴容或者縮容、金融級高可用、實時 HTAP、雲原生的分散式資料庫、相容 MySQL 5.7 協議和MySQL生態等重要特性,為用戶提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解決方案。TiDB適合高可用、強一致要求較高、數據規模較大等各種應用場景。
- TBase
TiDB是騰訊在Postgres-XC基礎上開發的資料庫。Postgres-XC(eXtensible Cluster)是一個提供寫可擴展、同步、對稱的和透明的PostgreSQL群集解決方案的開源項目。相較於Postgres-XC,TBase的穩定性得到了較大提高,通過在內核中引入GROUP概念,提出了雙Key分佈策略,有效地解決了數據傾斜的問題。它根據數據的時間戳,將數據分為冷數據和熱數據,分別存儲於不同的存儲設備中,有效地解決了存儲成本的問題。
- OceanBase
OceanBase是由螞蟻集團自主研發的企業級分散式關係資料庫,始創於2010年。OceanBase在TPC-C和TPC-H測試上都刷新了世界紀錄的國產原生分散式資料庫。OceanBase具有數據強一致、高可用、高性能、線上擴展、高度相容SQL標準和主流關係資料庫、低成本等特點。
- SequoiaDB
SequoiaDB巨杉資料庫是一款金融級分散式關係型資料庫,主要面對高併發聯機交易型場景提供高性能、可靠穩定以及無限水平擴展的資料庫服務。用戶可以在 SequoiaDB 巨杉資料庫中創建多種類型的資料庫實例,以滿足上層不同應用程式各自的需求。SequoiaDB 巨杉資料庫支持 MySQL、MariaDB、PostgreSQL 和 SparkSQL四種關係型資料庫實例、JSON文檔類資料庫實例、以及 S3對象存儲的非結構化數據實例。
6.參考
https://www.yisu.com/zixun/323416.html
https://blog.csdn.net/qq_16933229/article/details/109729522
https://www.jianshu.com/p/794ba6b42dcc
https://www.cnblogs.com/lidabo/p/15822815.html
https://blog.csdn.net/qq_31960623/article/details/116308332
https://www.cnblogs.com/lidabo/p/15822815.html
https://blog.csdn.net/qq_43413788/article/details/119171555
https://blog.csdn.net/yuhaiyang_1/article/details/80862914
https://blog.csdn.net/TJtulong/article/details/106510970
https://blog.51cto.com/u_14637492/5260036
公 眾 號:編碼磚家
獨立博客:codingbrick.com
出處:https://www.cnblogs.com/xiaoyangjia/
本文版權歸作者所有,任何人或團體、機構全部轉載或者部分轉載、摘錄,請在文章明顯位置註明作者和原文鏈接。

