
電腦的演進就是一部在挖坑和填坑之間反覆橫跳的發展史。對這一點的理解會隨著本文的後續講述逐漸加深。比如高速緩存Cache很好地解決了CPU與記憶體的速度矛盾,但是也為電腦系統帶來了更高的複雜度 ...
故事還得從一個矛盾說起。
摩爾定律告訴我們:大約每18個月會將晶元的性能提高一倍。晶元的這種飛速發展直接導致了晶元的指令執行速度與記憶體讀取速度之間的巨大鴻溝。
舉個例子,CPU在1納秒之內可以執行幾十條指令,但是從記憶體中讀取一條數據就需要花費幾十納秒。這種數量級的差異便是電腦中的一個主要矛盾:
CPU日益增長的對數據快速讀取的需要和I/O設備讀取速度不平衡不充分的發展之間的矛盾
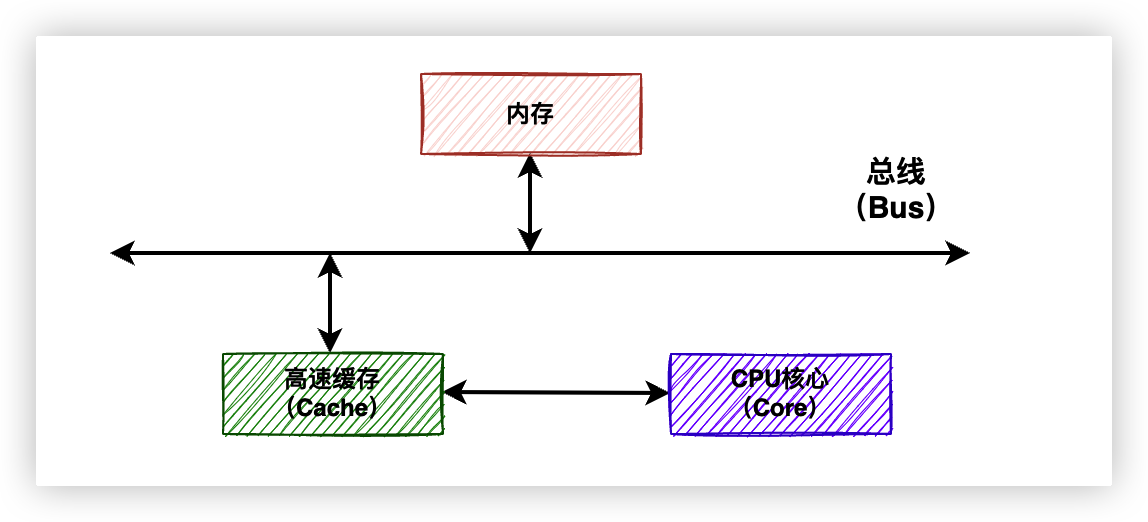
而CPU運行所需要的指令和數據都存儲在低速的記憶體中,人們無法容忍讓CPU這樣寶貴的高速設備進行漫長的等待。
電腦科學領域的任何問題都可以通過增加一個中間層來解決。所以需要一個比記憶體更快的存取設備做緩衝,儘量做到和CPU一樣快,這樣就不需要每次都從低速的記憶體中獲取數據了。
於是引入了高速緩存。
1. 高速緩存
我們已經知道為什麼需要高速緩存了。那麼什麼是高速緩存?它為什麼就比記憶體快?既然這麼快,為什麼不直接當成記憶體用?
別急,我一點點解釋。
1.1. 什麼是高速緩存Cache
我們最熟悉的記憶體是一種動態隨機訪問存儲器(Dynamic RAM,DRAM),存儲器中每個存儲單元由配對出現的晶體管和電容器構成,每隔一段時間,固定要對DRAM刷新充電一次,否則內部的數據就會消失。
而高速緩存是一種靜態隨機訪問存儲器(Static RAM,SRAM),不需要刷新電路就能保存它內部存儲的數據,這就是靜態的含義,因此SRAM的存儲性能非常高!工作速度在納秒級別,勉強能跟得上CPU的運算速度。
但是SRAM的缺點就是集成度低,相同容量的記憶體可以設計成較小的體積,但是SRAM卻需要更大的體積;而且,SRAM這玩意兒巨貴!這就是不能直接把它當記憶體用的原因。
越靠近CPU核心地帶的設備越需要強悍的性能,可是容量如果太小又幫不上太大的忙。如果一個中間層(一層高速緩存)不能高效解決問題,那就多來幾個中間層。目前CPU的解決思路一般是以量取勝,比如同時設置L1、L2、L3三級緩存。
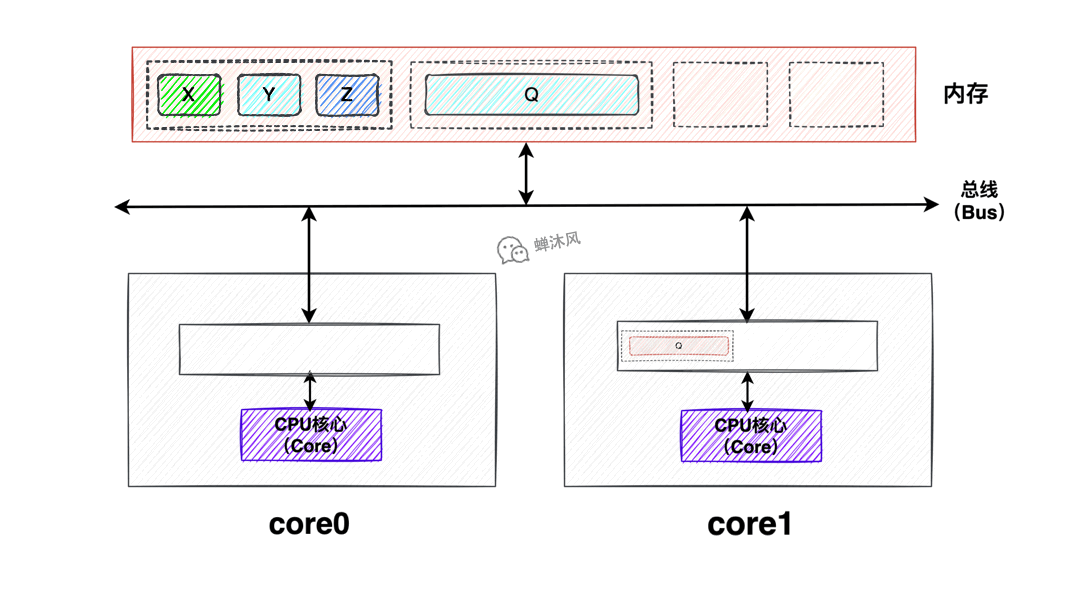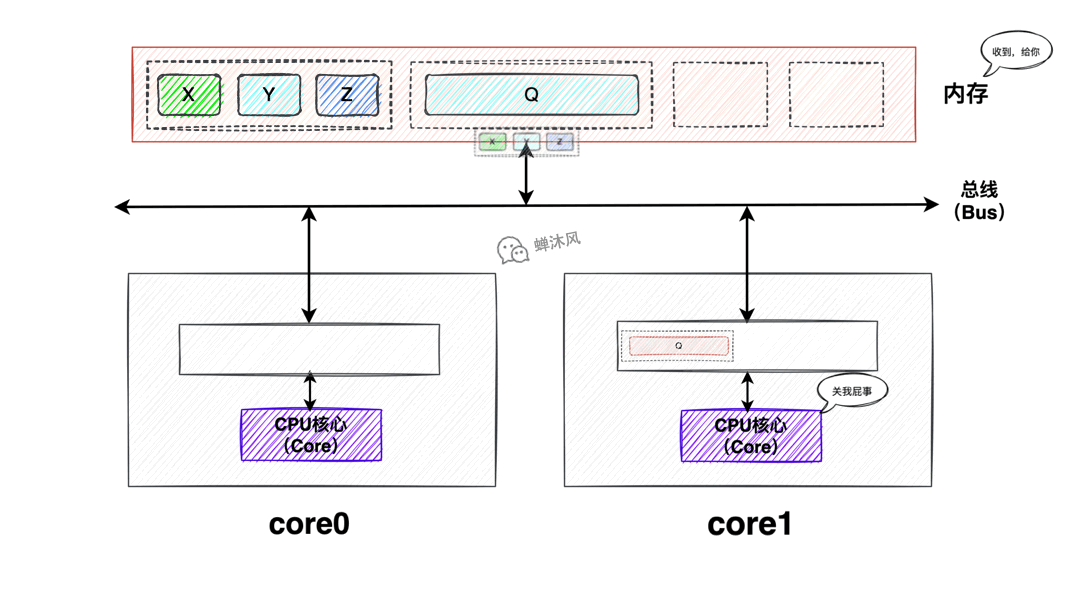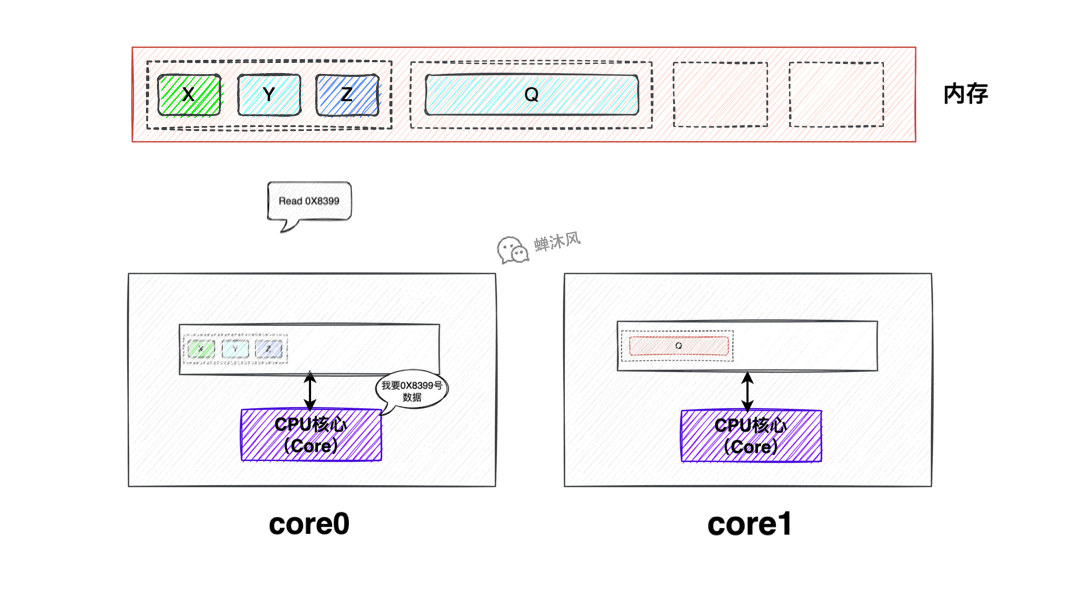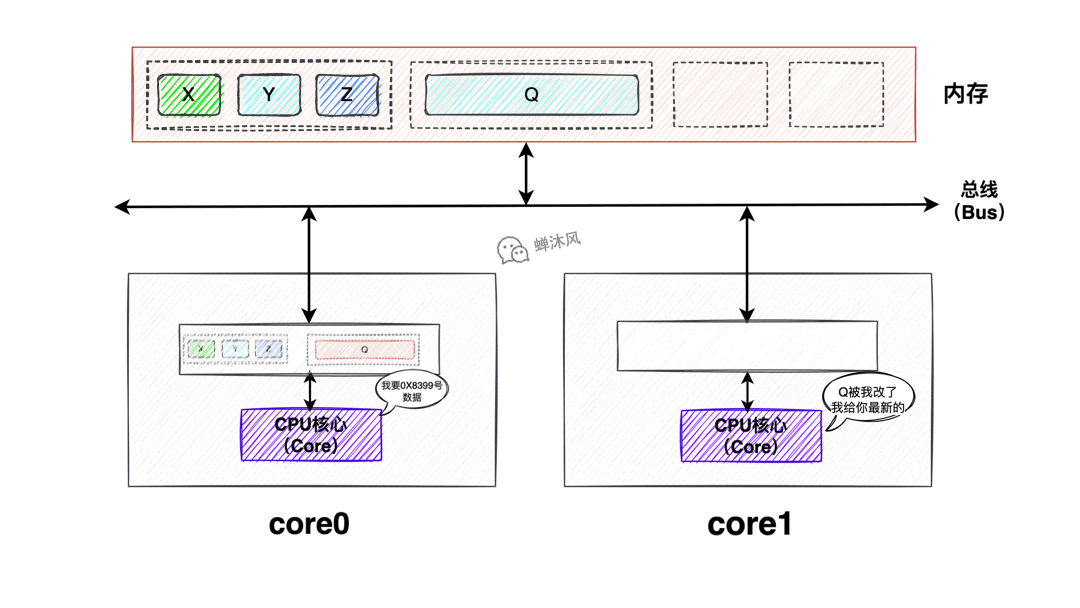
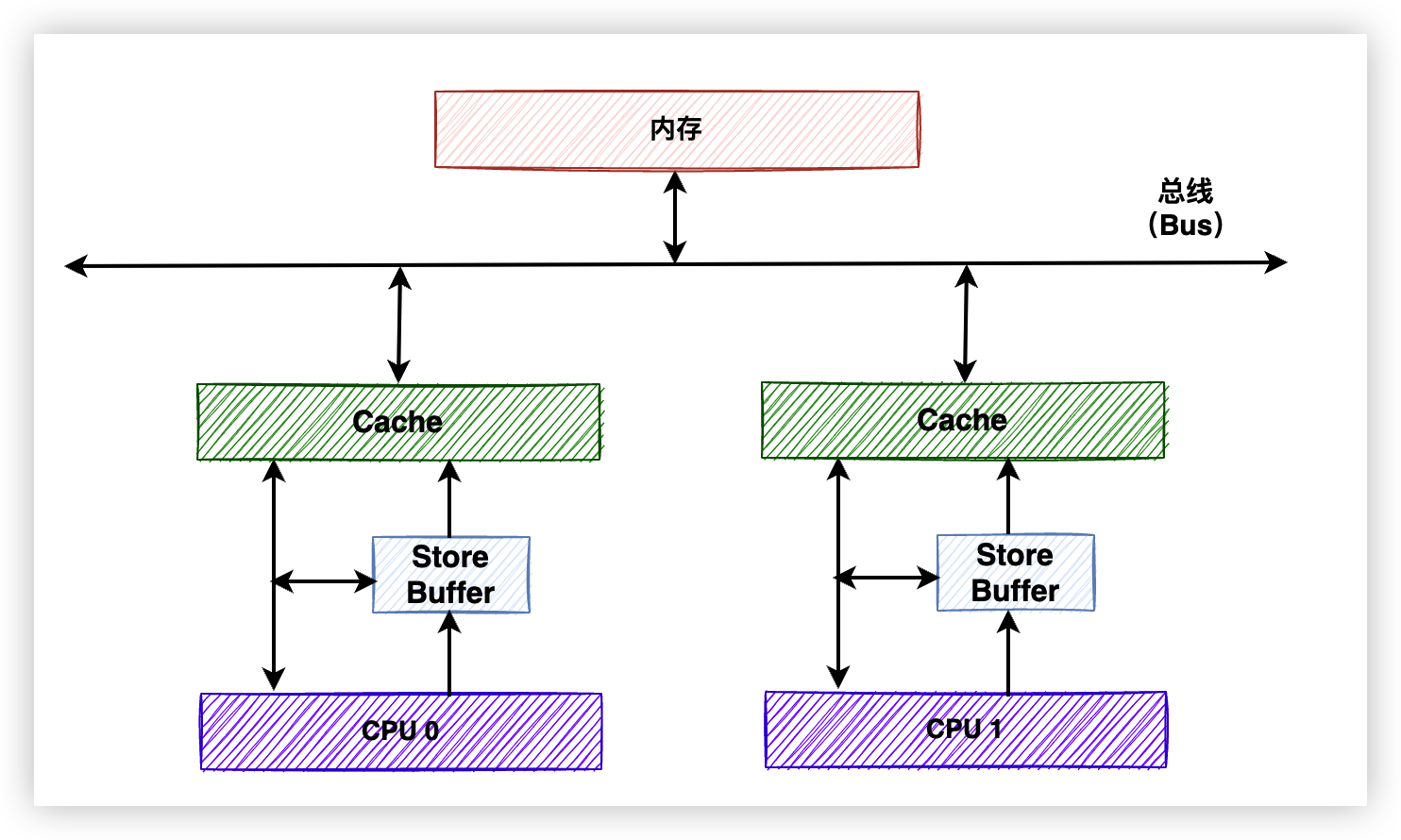
在緩存容量上,通常是記憶體 > L3 > L2 > L1,容量越小速度越快。其中L1和L2是由每個CPU核心獨享的,L3緩存是由所有CPU核心共用的。CPU的架構見下圖:
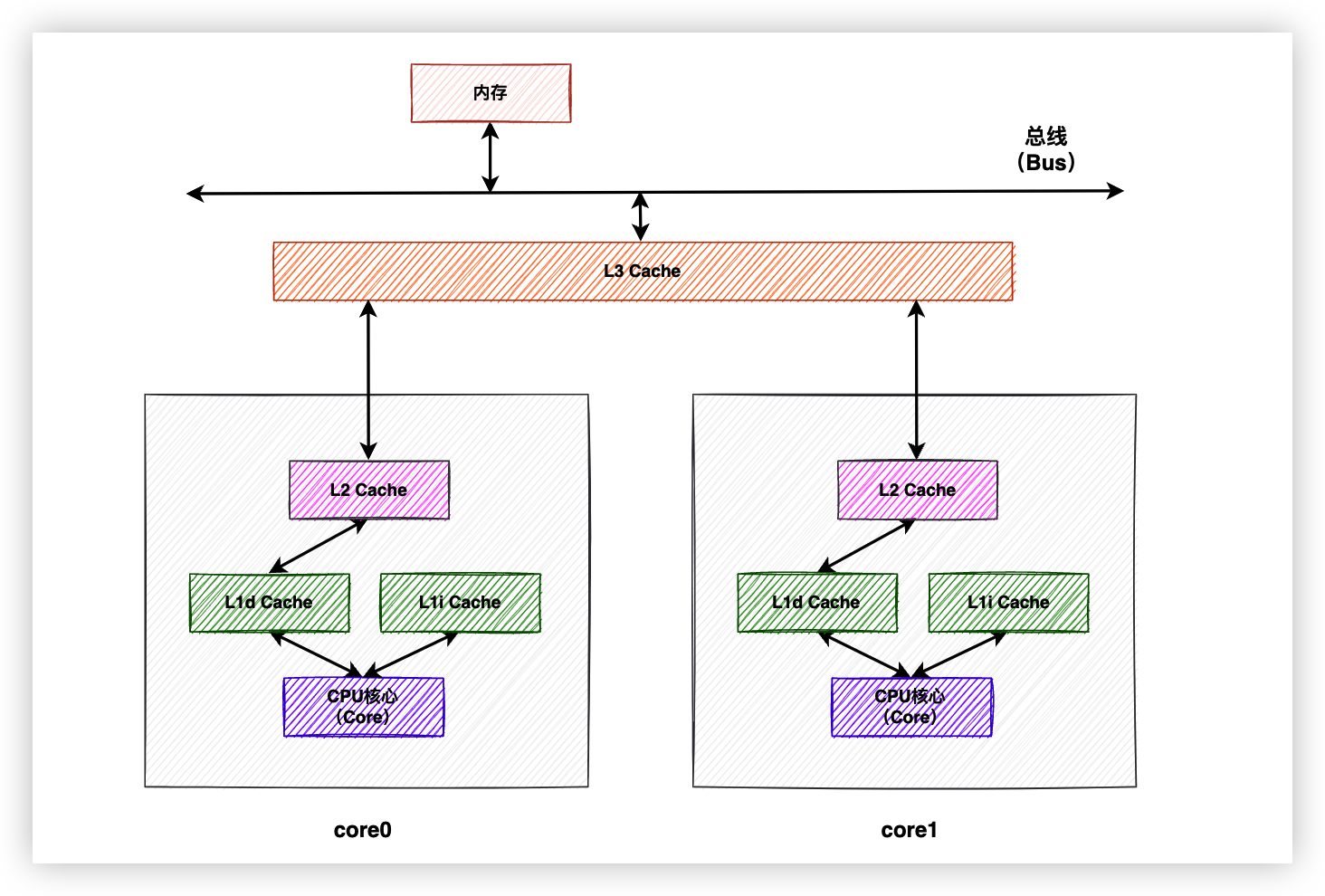
需要特別說明的是,L1緩存又分為了L1d數據緩存(L1 Data)和L1i指令緩存(L1 Instruct),上圖為了完整性一併畫出了,本文中的高速緩存一律指數據緩存。
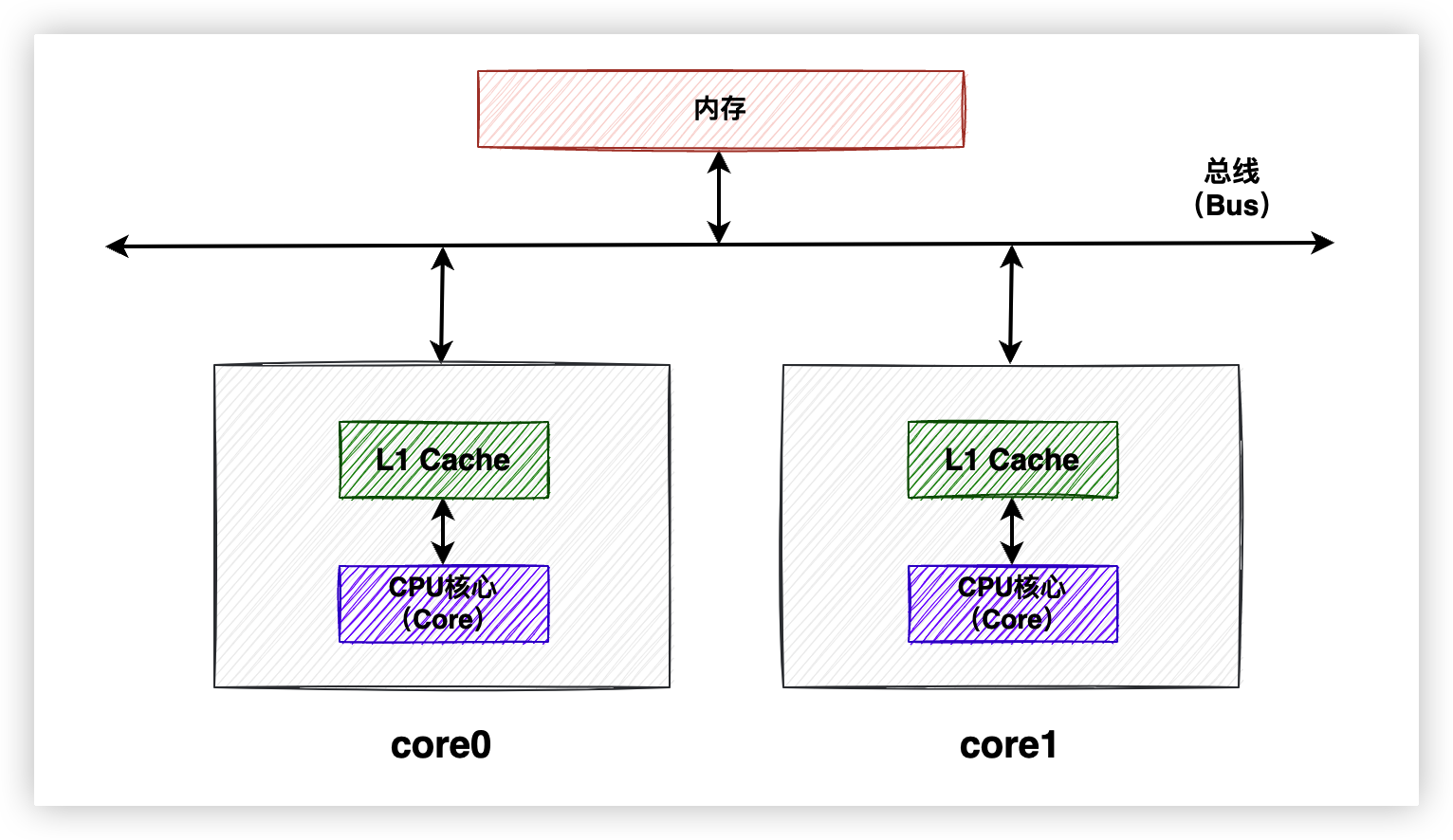
為了接下來方便講解,我們把三級緩存模型簡化為一級緩存模型,畢竟道理都是相通的嘛。看一下簡化之後的圖。
1.2. 緩存行
說完了什麼是Cache,接下來我們來看看Cache里裝的到底是什麼?
這不是廢話嘛,肯定裝的是數據啊。沒錯,是從記憶體中獲取到的數據,但是數據的單位呢?CPU每次只把需要的數據從記憶體中讀取到Cache就行了嗎?肯定不是,我們想一下,只把需要的一個數據從記憶體中讀到Cache,CPU再從Cache中繼續讀這個數據進行處理,Cache的存在完全就是多此一舉,還不如直接從記憶體讀數據呢。
所以要想讓Cache充分發揮作用,必須讓它做點“多餘”的事情。因此從記憶體中獲取數據的時候,我們把包含目標數據的一整塊記憶體數據都放入Cache中。別小看這個動作,它有個科學的解釋,叫做空間局部性。
位置相鄰的數據常常會在相近的時間內被訪問
根據空間局部性原理,如果目標數據相鄰的數據被訪問,CPU就不需要再從記憶體中獲取了,這種直接從Cache中獲取到目標數據的行為叫做“緩存命中”,極大地提高了CPU的工作效率。如果Cache裡邊沒有,就稱為Cache Miss,CPU需要再等待幾十個指令周期從記憶體中把這一整塊記憶體數據讀入Cache。
給存儲“一整塊記憶體數據”的地方起個名字,叫「緩存行」(Cache Line)。
Cache是由緩存行組成的,緩存行是CPU高速緩存和記憶體交互的最小單元。在X86架構中,緩存行的大小是64個位元組,大小和CPU具體型號有關。本文只關註緩存行的抽象概念,不涉及具體的緩存行大小。
接下來,終於要進入本文的正式部分了。

我一直認為,電腦的演進就是一部在挖坑和填坑之間反覆橫跳的發展史。對這一點的理解會隨著本文的後續講述逐漸加深。比如高速緩存Cache很好地解決了CPU與記憶體的速度矛盾,但是也為電腦系統帶來了更高的複雜度,我來舉個例子。
2. 偽共用問題
我們到目前為止說的都是CPU從Cache中read數據,但是總得有write的時候吧。既然有了Cache,肯定就得先把值write到Cache中,再更新到記憶體里啊。那麼,問題來了。
2.1. 什麼是偽共用
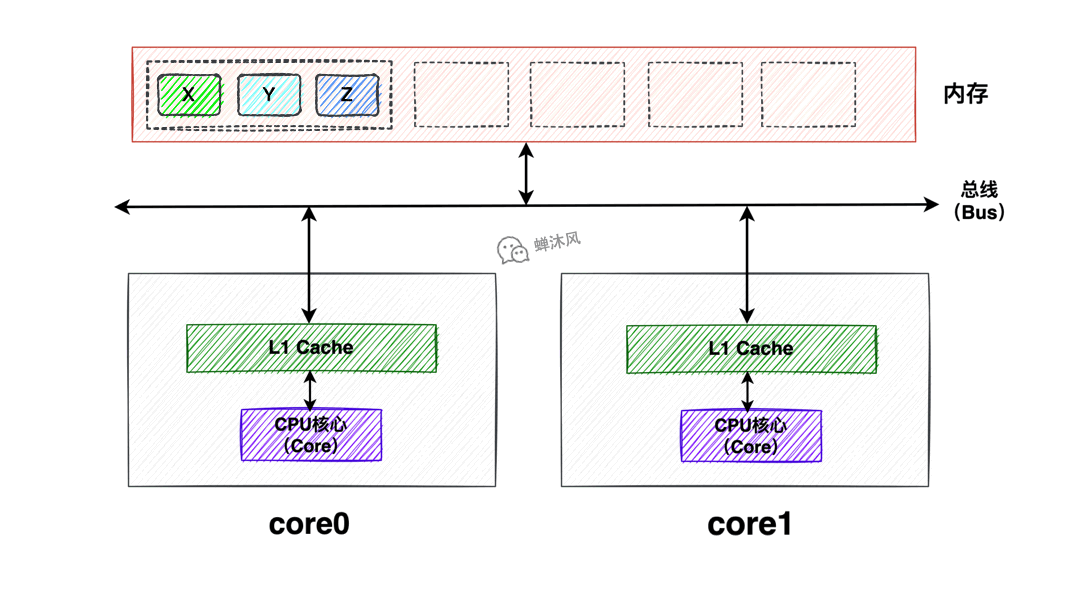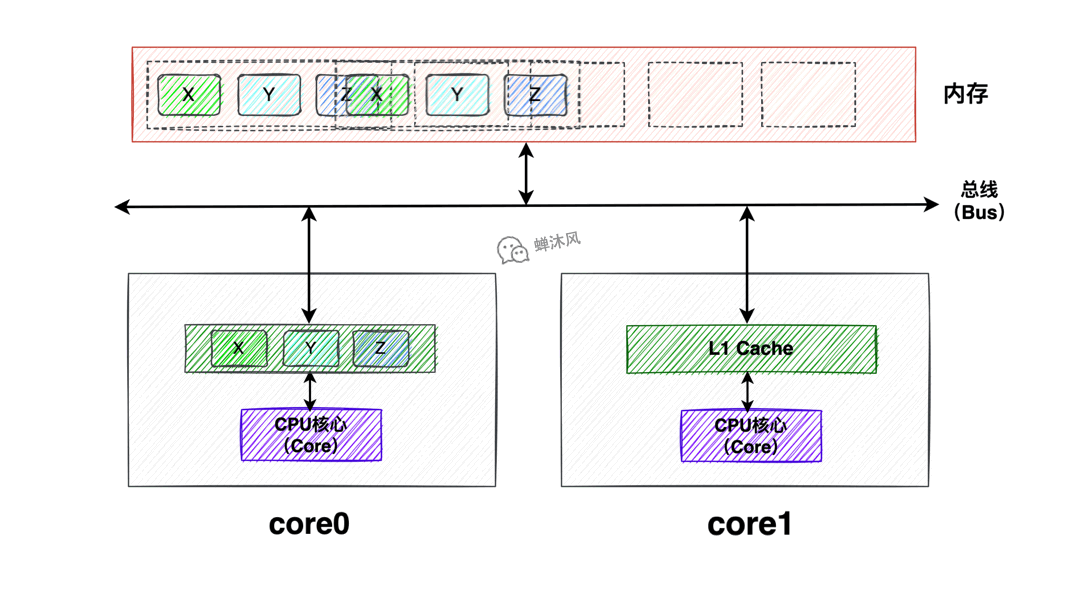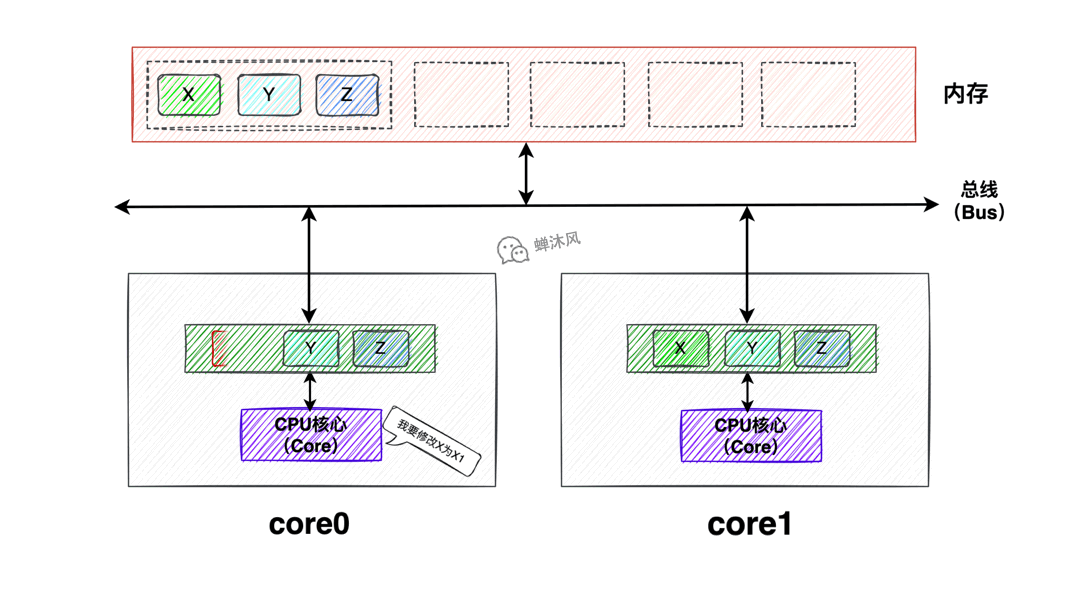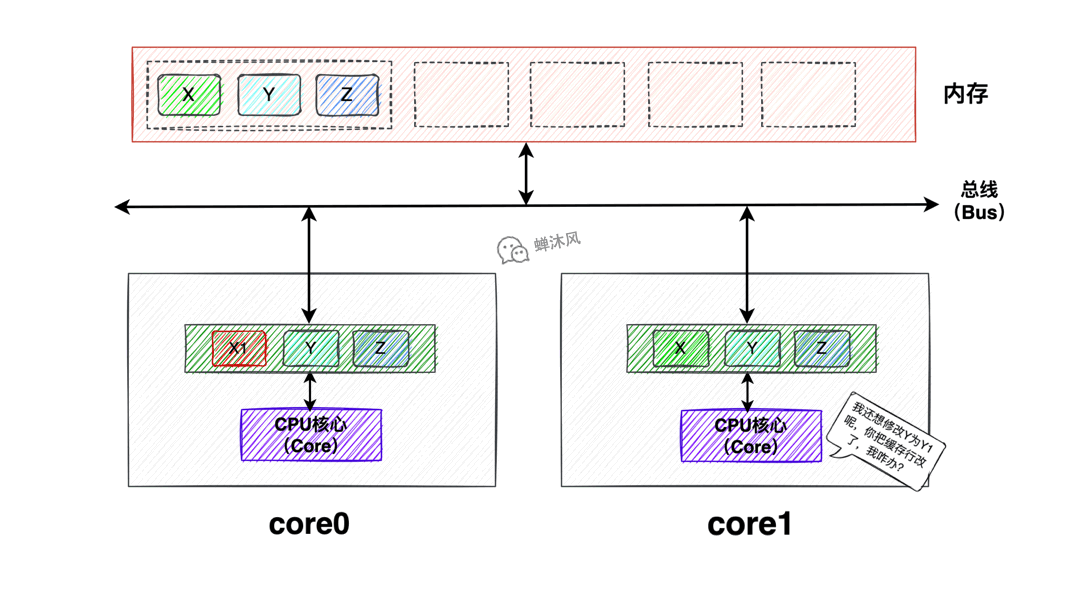
數據X、Y、Z同處於一個緩存行內,Core0和Core1同時載入了該緩存行到Cache中,此時Core0修改了該緩存行中的X為X1,如果此時Core1也想修改Y為Y1該怎麼辦呢?
由於緩存行是Cache和記憶體之間交互的最小單元,所以Core0根本不知道Core1修改的是緩存中的Y還是X,所以為了防止造成併發問題,最好的辦法就是讓Core1中的該緩存行失效,重新載入。這就是偽共用問題。
偽共用問題的定義:當多核心修改互相獨立的變數時,如果這些變數共用同一個緩存行,就會無意中影響彼此的性能,這就是偽共用。
2.2. 解決偽共用
既然問題是由多個變數共用一個緩存行導致的,那就讓Y變數獨享一個緩存行就好了。
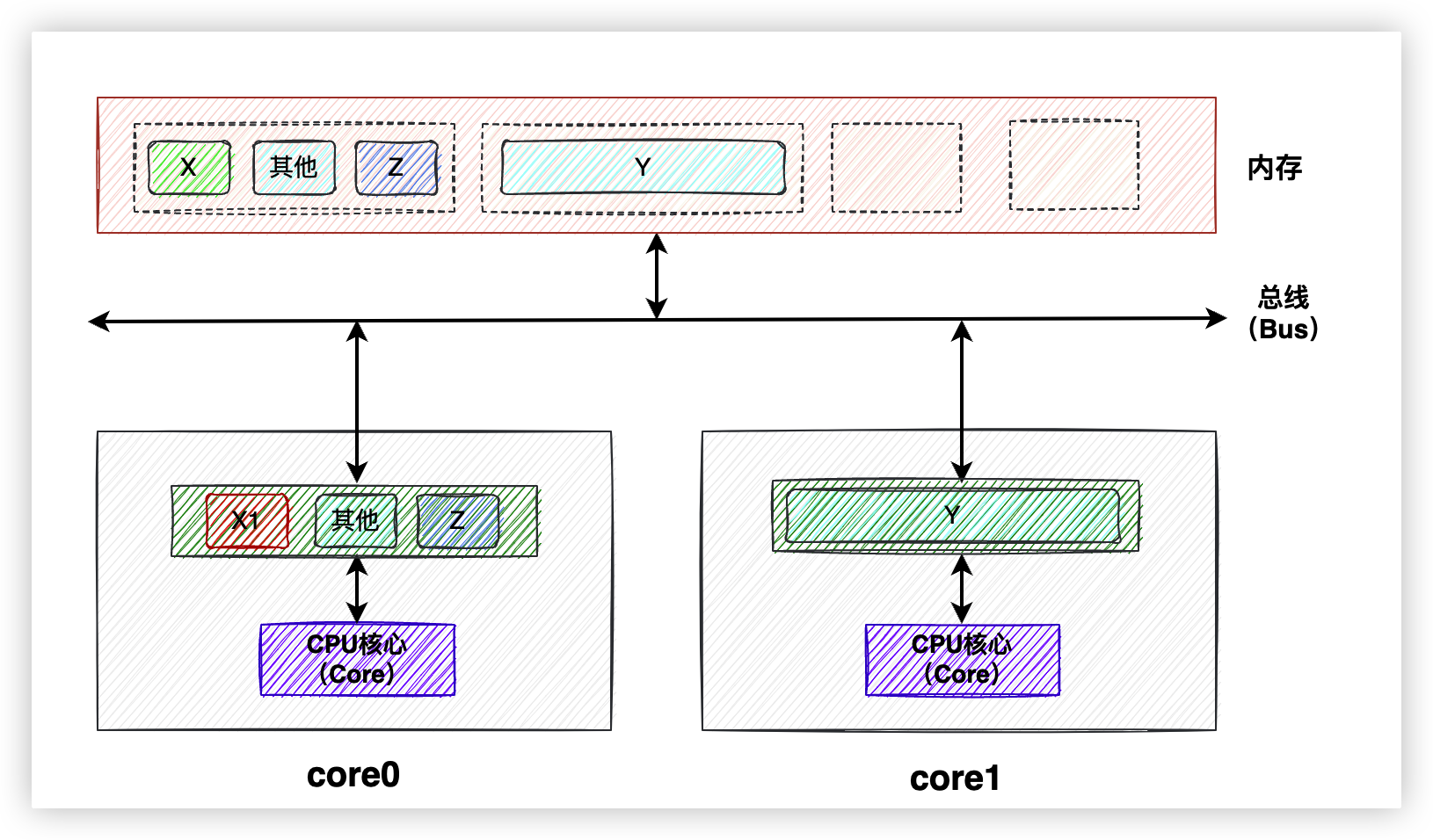
最簡單的方法就是通過代碼手動進行位元組填充,拿早期的LinkedTransferQueue中的部分源碼舉個例子,註意看註釋內容:
static final class PaddedAtomicReference<T> extends AtomicReference<T> {
// 追加15個對象引用,一個對象引用占據4個位元組
// 加上繼承自父類的value,共64位元組,正好占一個緩存行
Object p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe;
PaddedAtomicReference(T r) {
super(r);
}
}
//父類
public class AtomicReference<V> implements java.io.Serializable {
private volatile V value;
public AtomicReference(V initialValue) {
value = initialValue;
}
}
此外,JDK 8開始,提供了一個sun.misc.Contended註解來解決偽共用問題,加上這個註解的類會自動補齊緩存行。
稍微扯遠了一些,我們回到上方的動圖。Core0修改了緩存行中的X,我們說當前最合適的處理辦法就是讓Core1中的緩存行失效,否則就會出現緩存一致性問題。偽共用問題其實就是解決緩存一致性問題的副作用。只不過本文中我單獨把這個問題列了出來。
為瞭解決緩存一致性問題,CPU天然支持了匯流排鎖的功能。
3. 匯流排鎖
顧名思義就是,鎖住Bus匯流排。通過處理器發出lock指令,匯流排接受到指令後,其他處理器的請求就會被阻塞,直到此處理器執行完成。這樣,處理器就可以獨占共用記憶體的使用。
但是,匯流排鎖有一個非常大的缺點,一旦某個處理器獲取匯流排鎖,其他處理器都只能阻塞等待,多處理器的優勢就無法發揮。
於是,經過發展、優化,又產生了緩存鎖。
4. 緩存鎖
緩存鎖:不需鎖定匯流排,維護本處理器內部緩存和其他處理器緩存的一致性。相比匯流排鎖,會提高cpu利用率。
但是緩存鎖也不是萬能,有些場景和情況依然必須通過匯流排鎖才能完成。
緩存鎖其實是一種實現的效果,它是通過緩存一致性協議來實現的,可能有的讀者也聽說過Snoopy嗅探協議,我舉個例子幫助大家理解這三個概念。
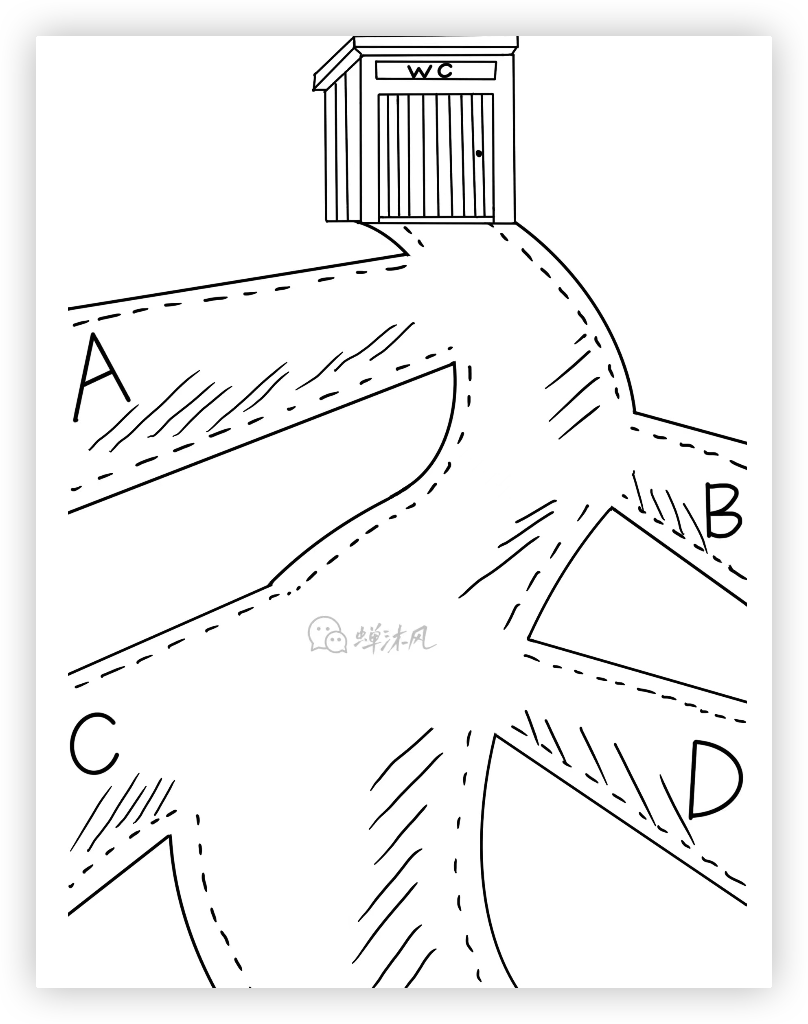
假如村裡有一個單人公廁,一條蜿蜒大道與公廁相連,大道旁邊住著A、B、C、D四個人,每個人要上廁所必須經過主幹道。
我們再設置一點前提,假設每個人都不想到了廁所門口的時候才知道廁所已經被人占用了。
為了合理使用廁所,保證每次只有一個人進入廁所,並且不會出現其他人在廁所門口等待的情況,ABCD四個人聚在一起開會討論,協商出了一條約定。
當有人去上廁所的時候,其他人在家老實呆著,不要去上廁所!
四個人紛紛拍著自己大腿叫絕。他們商議出來了一個聽起來確實能解決問題,但是實際上內容非常空洞的一個協議。
因為他們不知道現在有誰正在占用廁所,更不知道誰正在前往廁所的路上。
其中A靈機一動,想出了一個辦法。可以在每家和主幹道的岔路口設置一個監測設備,當有人上廁所經過岔路口的時候監測設備就提醒其他三個人已經有人去廁所了,老實在家等著吧。
如此一來,就達成了一種給廁所添加鎖的一種效果,這種效果就相當於上文提到的緩存鎖。4人商議出來的協議就相當於緩存一致性協議,A提出來的方法實現了協議,相當於Snoopy嗅探。
如果大家讀到這裡在思考例子中的廁所究竟表示記憶體還是緩存行,我勸大家趕緊止住。在生活中找到和電腦科學中非常貼切的例子是非常非常困難的。這個例子只是簡單說明一下緩存鎖和鎖存一致性協議以及Snoopy嗅探協議之間的關係罷了,不要深究!
自然,緩存一致性協議就是我們接下來的主角了。
5. 緩存一致性協議
每個處理器共用同一個主記憶體,並且都有自己的高速緩存。如果多個處理器都對同一塊主記憶體區域進行更改,將導致各自的的緩存數據不一致。那同步到主記憶體時該以誰的緩存數據為準呢?
緩存一致性協議就是為瞭解決這個問題提出的,這類協議有MSI、MESI和MOSI等。
我們以應用最廣泛的MESI為例進行介紹。
5.1. MESI
MESI是Modified、Exclusive、Shared、Invalid四個單詞的首字母縮寫,表示緩存行的4種狀態。
- Modified
緩存行被對應的CPU核心修改之後就會處於Modified狀態,並且保證該緩存行不會出現在任何其他CPU的緩存中。即使有,也是Invalid狀態,需要從記憶體或其他Cache中重新讀取。
因此,處於Modified狀態的緩存行可以說是被相應CPU核心獨占的。由於該緩存行擁有該數據的唯一最新副本,因此該緩存行最終負責將其寫回記憶體或將其傳遞給其他CPU。
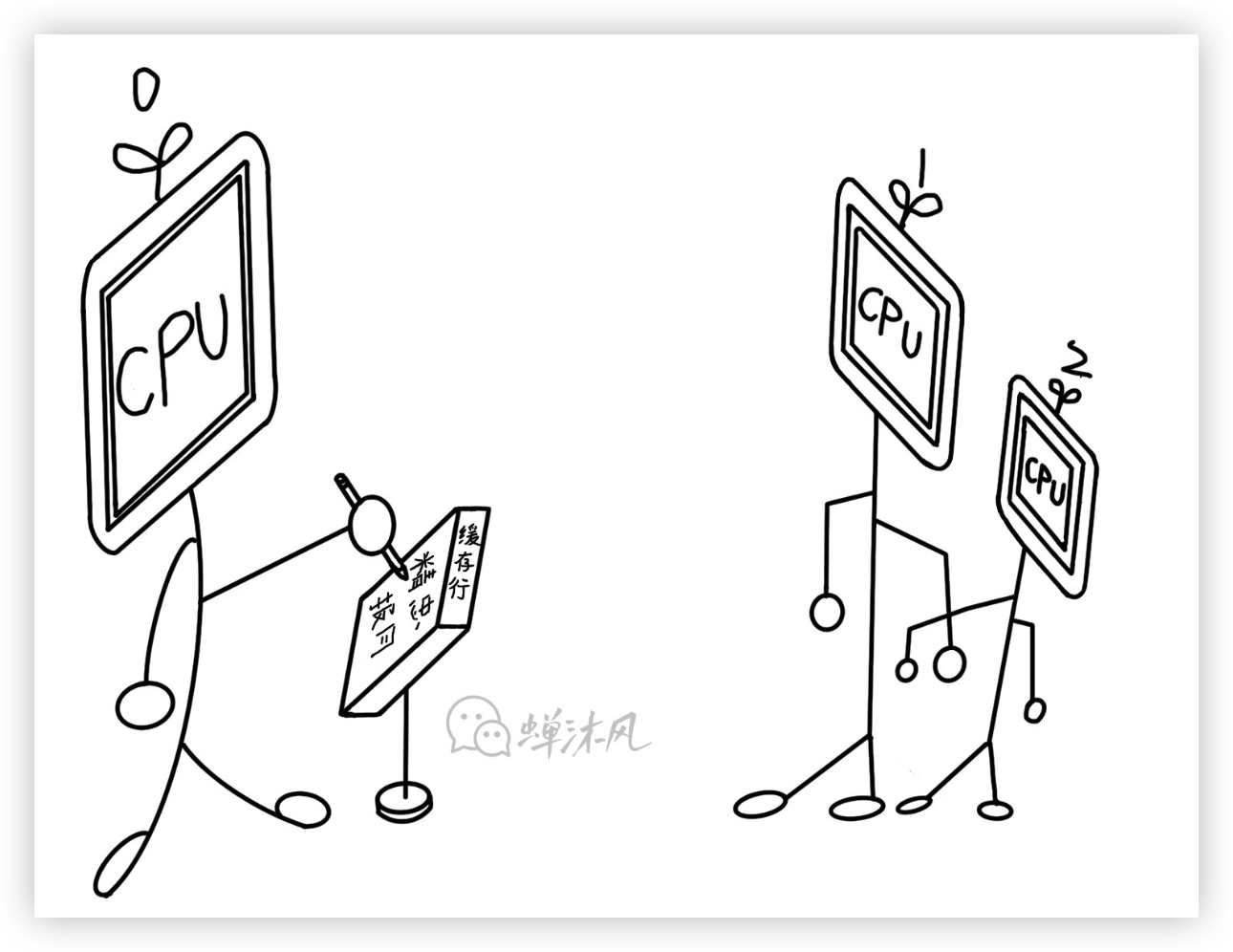
- Exclusive
Exclusive狀態就非常好理解了,意味著獨占、排他,和Modified狀態非常類似。唯一不同的一點就是這個緩存行還沒有被CPU核心修改,這也說明記憶體中的內容依然是最新的。即便如此,一旦某個緩存行處於該狀態,就意味著其他CPU核心不能擁有該緩存行的副本。

- Shared
處於Shared狀態的緩存行意味著同時出現在了一個或多個CPU Cache中,且多個CPU Cache的緩存行和記憶體中的數據一致。CPU核心不能在未與其他核心“協商”的情況下,修改其Cache中的該緩存行。至於什麼是“協商”,下文會講到。
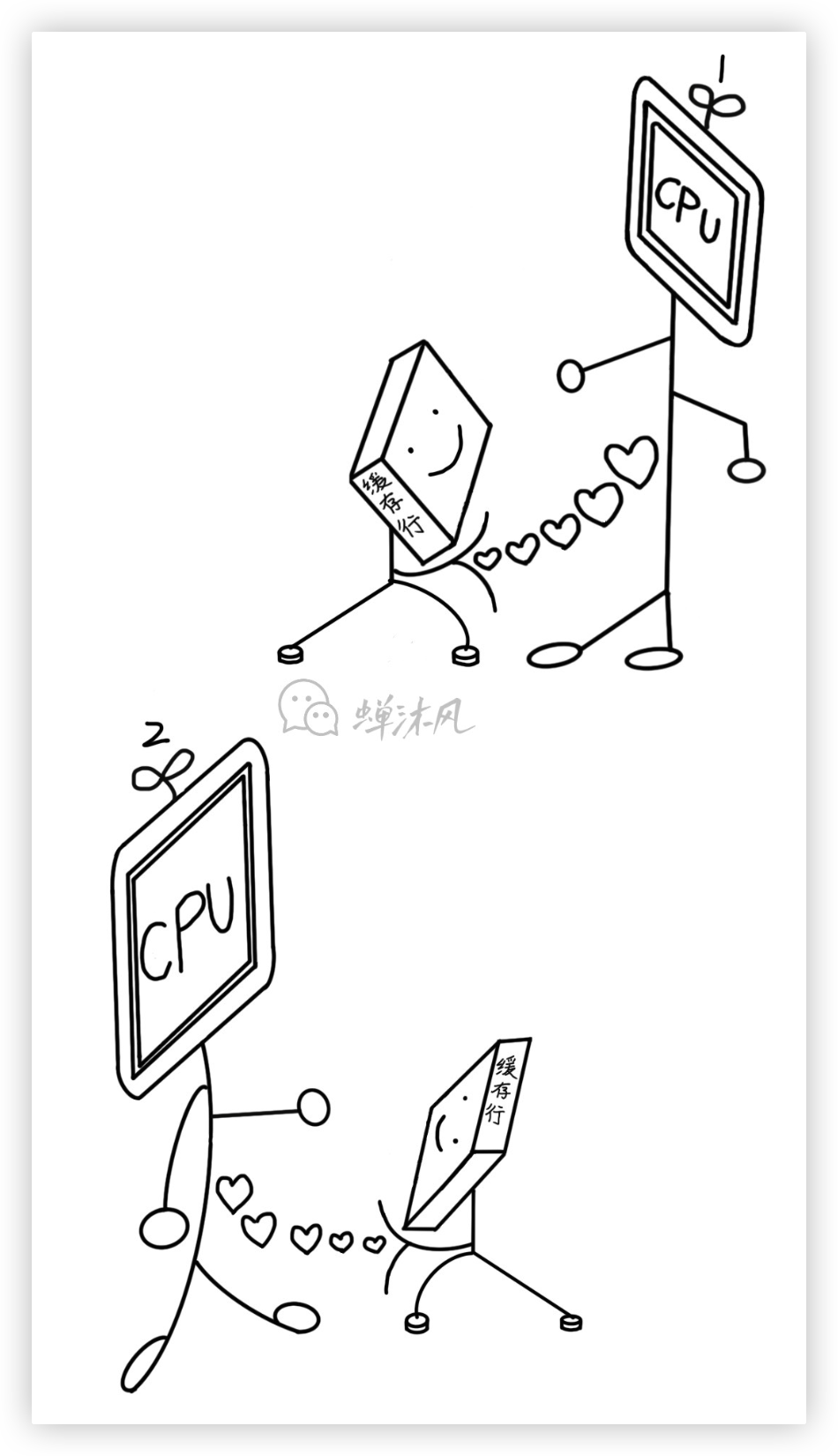
- Invalid
處於Invalid狀態的緩存行不包含任何數據,只是被打上了Invalid狀態的標簽而已。其他CPU修改了緩存行,就會導致本CPU中的該緩存行失效為Invalid狀態。當有新數據被放入Cache中時,會被優先放入Invalid狀態的緩存行中,避免置換出其他有用的緩存導致Cache Miss。
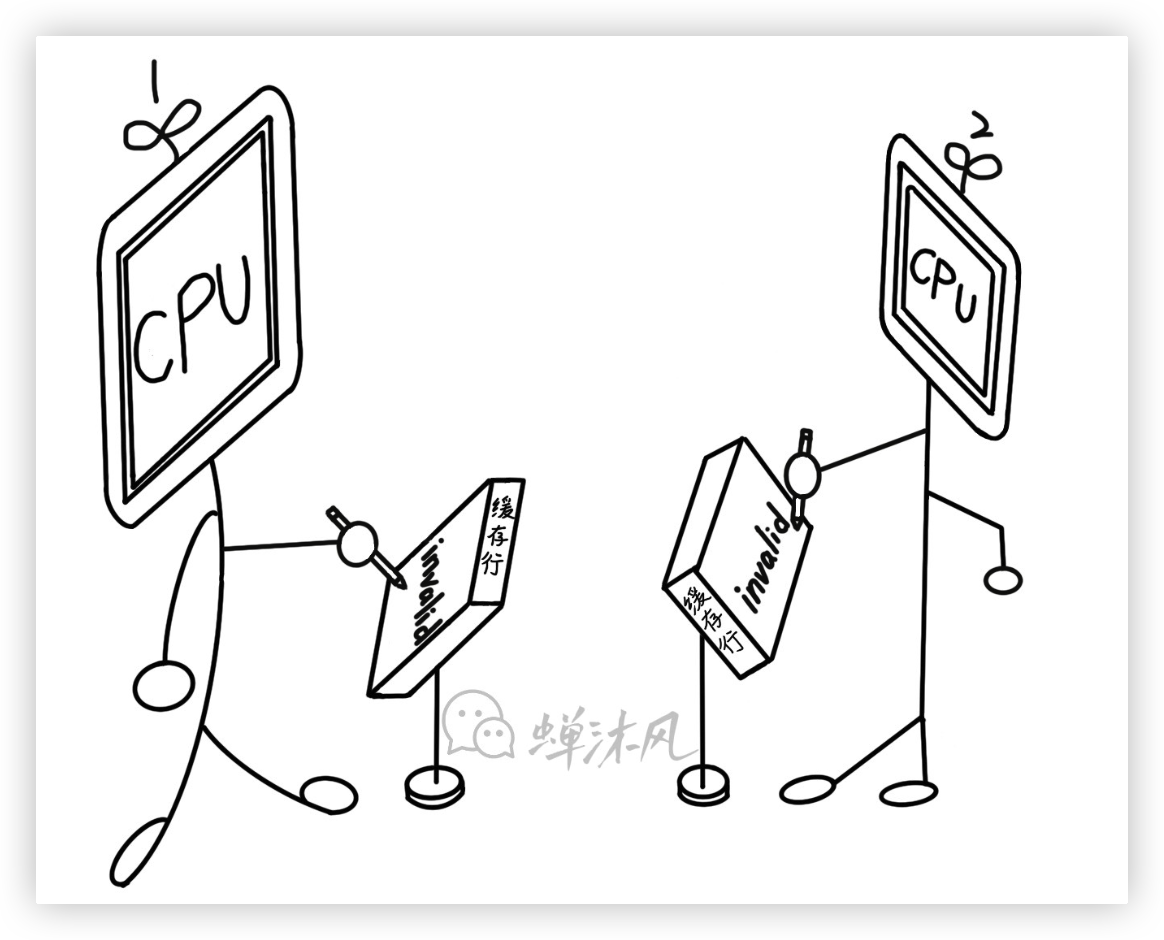
以上4種狀態之間的躍遷離不開各個CPU核心之間的協作,比如某個數據被同時緩存在多個CPU核心的Cache中,此時這些緩存行的狀態是Shared,假如Core0對緩存行做了write操作,為了避免緩存數據的不一致性,其他CPU核心需要將對應的緩存行狀態設置為Invalid狀態。那麼其他CPU核心是怎麼知道Core0修改了緩存行呢?換個問法,Core0怎麼讓其他核心知道自己修改了緩存行呢?
人有人言,獸有獸語。CPU核心之間的溝通也有自己的一套“黑話”,稱為緩存一致性消息。
5.2. CPU之間的“黑話”
消息分為請求和響應兩類。
處理器在進行數據讀寫的時候會往匯流排(Bus)中發請求消息,同時每個處理器核心還會嗅探(Snoop)匯流排中由其他處理器發出的請求消息併在一定條件下往匯流排中回覆響應消息。
- Read
Read消息表示要讀取某個緩存行,同時會攜帶目標緩存行對應的物理地址。
- Read Response
是對Read消息的反饋,反饋的內容就是發送Read消息的CPU核心請求的目標緩存行。Read Response可能來自於記憶體,也可能來自其他CPU核心。
比如,如果被請求的目標緩存行不存在於任何CPU Cache中,那麼只能從記憶體中獲取;如果被請求的目標緩存行恰好被其中一個CPU修改,此時該緩存行為Modified狀態,意味著該緩存行目前是最新數據,那麼理應讓其他同樣需要該緩存行的CPU核心獲取到該最新數據,更進一步,自然理應由該CPU核心把該緩存行的內容反饋給發出Read消息的CPU核心。
- Invalidate
Invalidate的含義是使某個緩存行失效,擁有該緩存行的其他CPU核心需要刪除該緩存行中的數據,並對發出Invalidate消息的核心做出反饋。
- Invalidate Acknowledge
這就是上面提到的Invalidate消息的反饋,意味著發出此消息的CPU核心已經將Invalidate消息的目標緩存行中的數據清除。

如果有多個CPU同時發出Invalidate消息怎麼辦?答案是匯流排裁決。首先占用消息匯流排的CPU核心獲勝,其他核心只能乖乖清空自己的緩存行,並向其發出Invalidate Acknowledge反饋。
- Read Invalidate
Read Invalidate相當於Read + Invalidate,既要讀取某個緩存行信息,又要讓屬於其他CPU核心的此緩存行失效。同樣,Read Invalidate也需要收到反饋,只不過此反饋既包含1條Read Response,又包含多條(如果其他CPU核心也擁有目標緩存行的話)Invalidate Acknowledge。
- Writeback
Writeback消息包含要寫回記憶體的地址和數據,通常指的是Modified狀態的數據,這樣Cache就可以根據需要彈出處於Modified狀態的緩存行,以便為其他數據騰出空間。
這倆消息很簡單,就不畫圖浪費你們的流量了。。。
5.3. MESI狀態躍遷示例
CPU之間通過緩存一致性消息的傳遞,才有了緩存行在MESI四種狀態之間的躍遷。
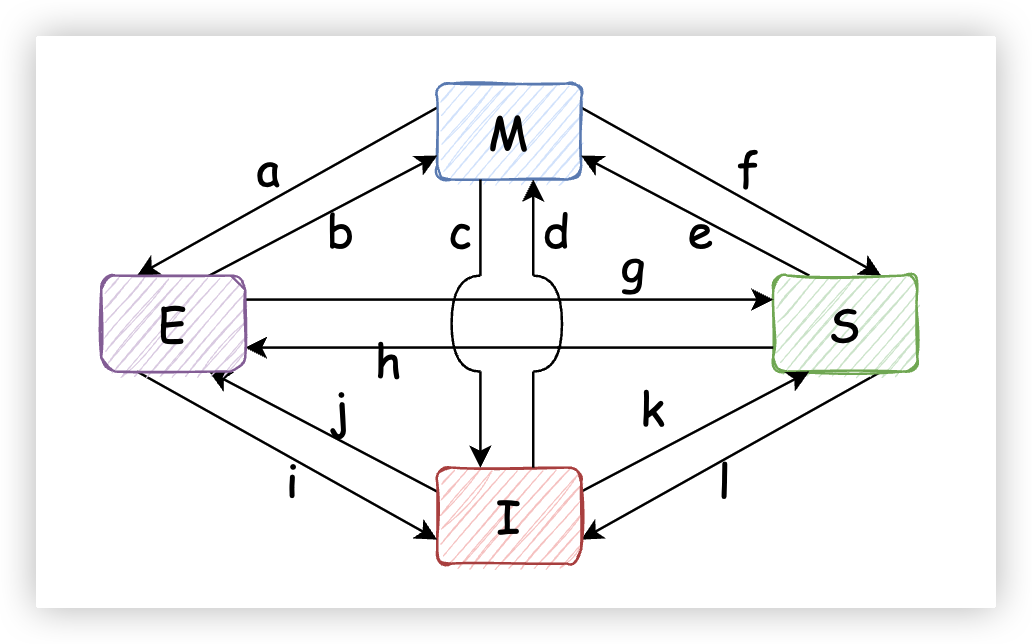
如上圖,每兩個狀態之間都可能會發生狀態越遷,是不是感覺很複雜?
如果之前的內容我給你解釋地很清楚的話,就很容易想明白每個狀態之間的躍遷場景了。為了不影響接下來的講解,我把每種場景解釋放在了文章最後(見附錄1),需要的讀者讀完文章之後可以翻閱一下(即使不看也不會影響接下來的閱讀哦)。
還有一個線上的網站可以幫助你更好地理解MESI協議(見附錄2),你可以站在CPU的角度發出指令,網站以動態方式展示緩存行的狀態變換,強烈建議閱讀完文章之後大家試一下。
截至目前,文章都是圍繞Cache展開的,高速緩存的引入極大地提高了電腦的整體運行效率。但在某些特殊情況下,CPU的性能表現卻是非常糟糕。
6. 不能讓CPU閑著
考慮這麼一個場景,CPU 0 和CPU 1 同時擁有某個緩存行,兩個緩存行都處於Shared狀態,CPU 0想對自己的緩存行執行write操作,必須先發送Invalidate消息讓CPU 1中的緩存行失效。如下圖所示:
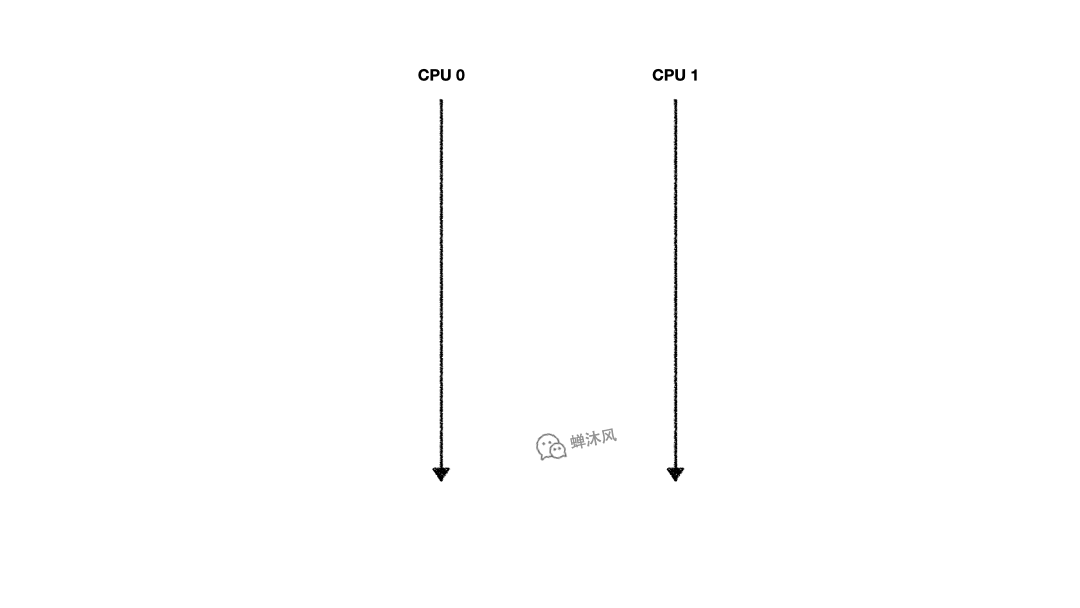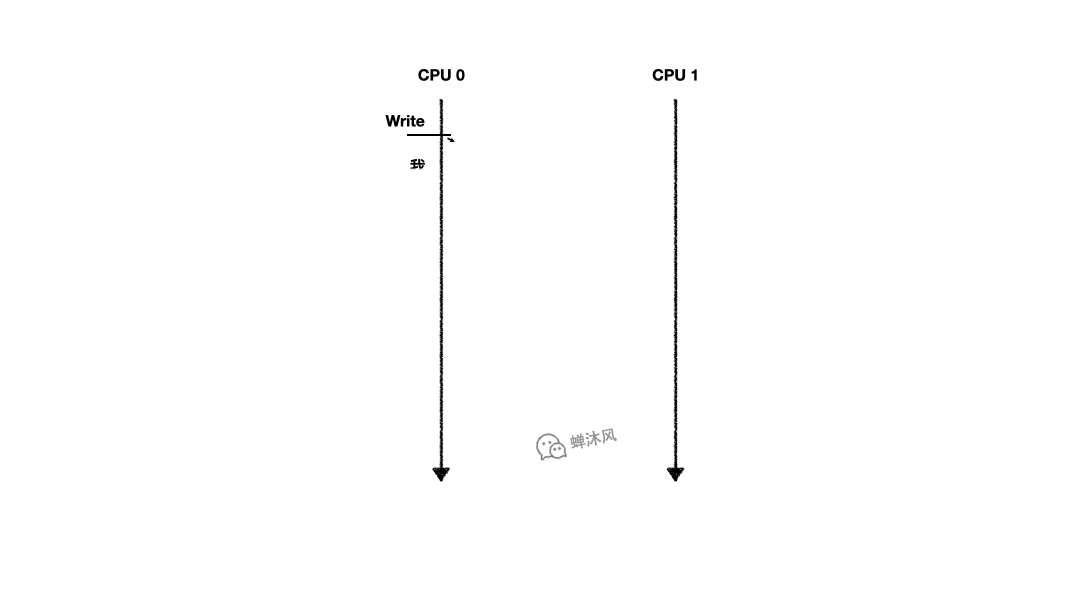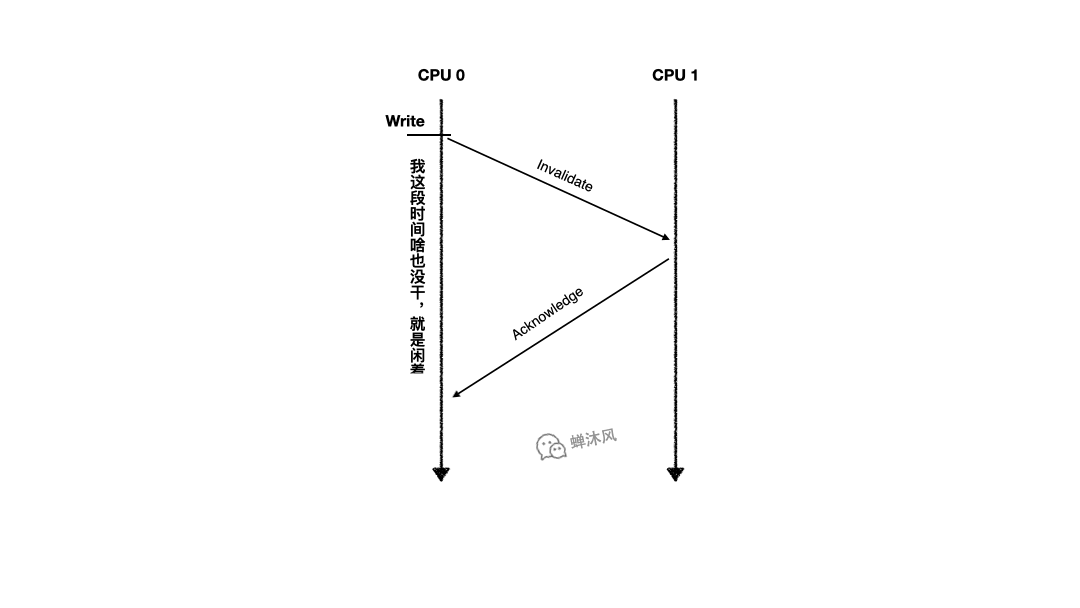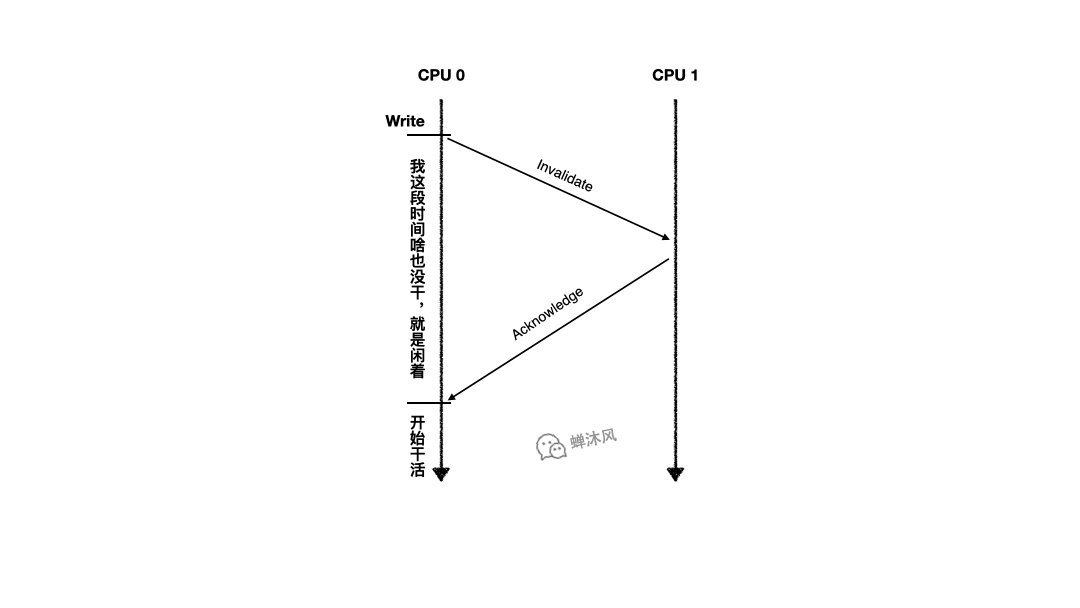
由於CPU 0必須等到CPU 1反饋了Invalidate Acknowledge之後才能確保自己可以操作緩存行,所以從發出Invalidate直到收到Invalidate Acknowledge的這段時間,CPU 0一直處於閑置狀態。
CPU是何等寶貴的資源,讓它閑著是不可能的,絕對不可能的!
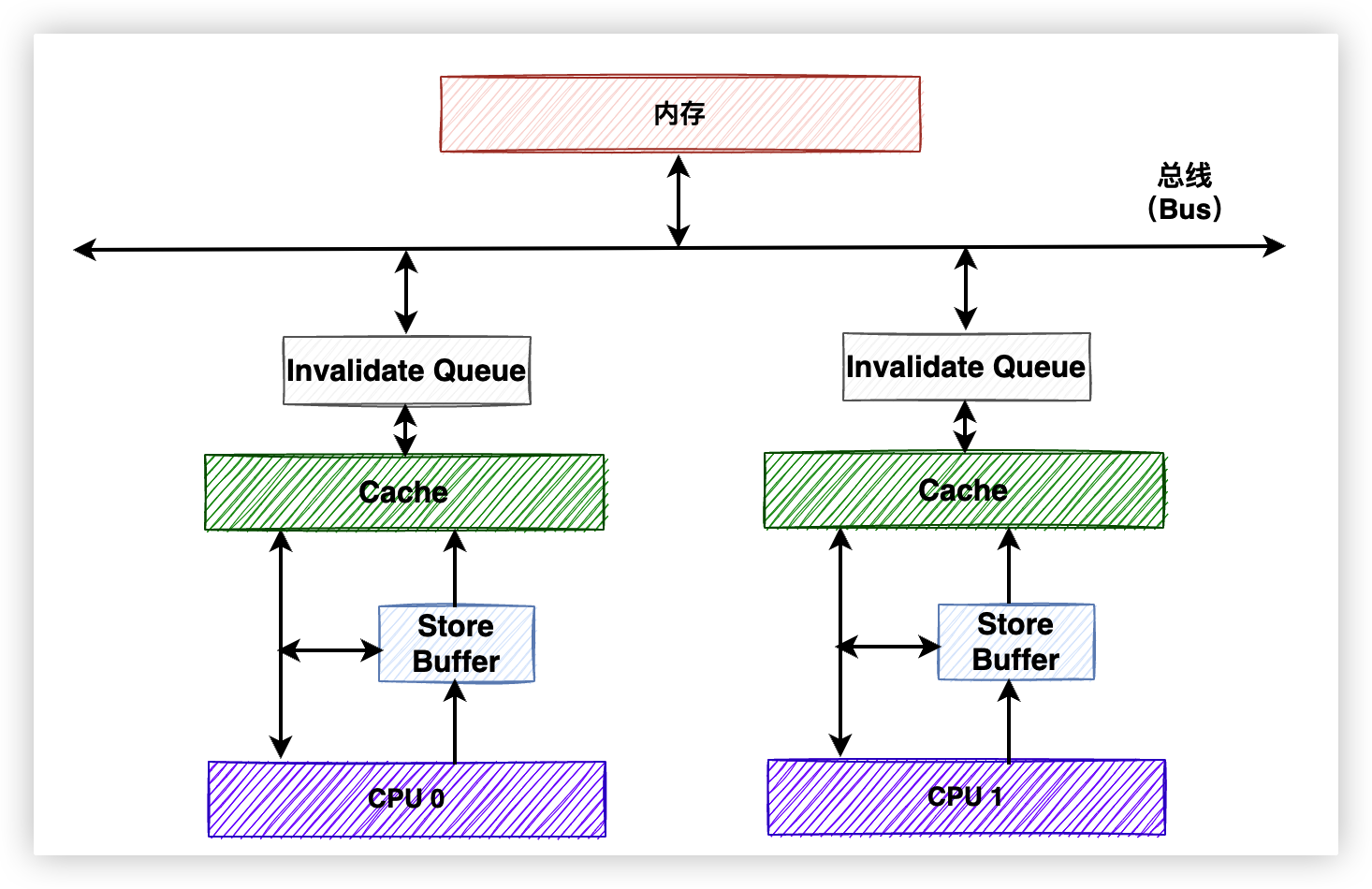
硬體工程師為瞭解決這個問題,引入了Store Buffers。
6.1. 引入Store Buffers
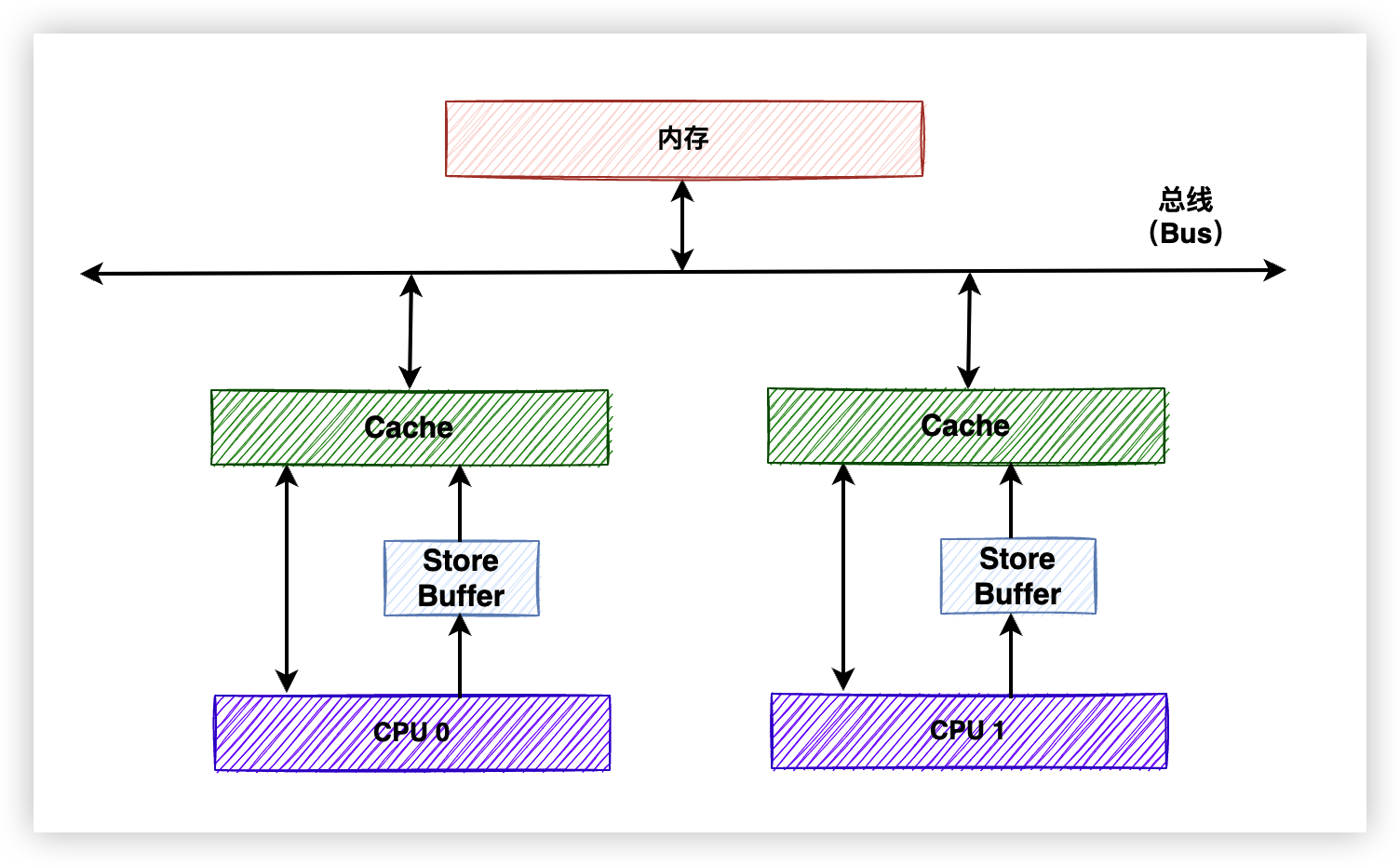
工程師在CPU和Cache之間添加了一個中間層——Store Buffer。當CPU 0想執行write指令時,先把想要write的值寫入到Store Buffer中,然後再繼續執行其他任務,無需傻傻地等待CPU 1。直到CPU 1傳回反饋之後,CPU 0再將Store Buffer中的最新值寫入到緩存行中。
電腦的發展就是不斷挖坑、填坑的過程。Store Buffers的引入解決了CPU閑置的問題,如果事情發展到現在就完美了該有多好,然而又引出了3個新問題。
6.2. Store Buffers引起的問題1
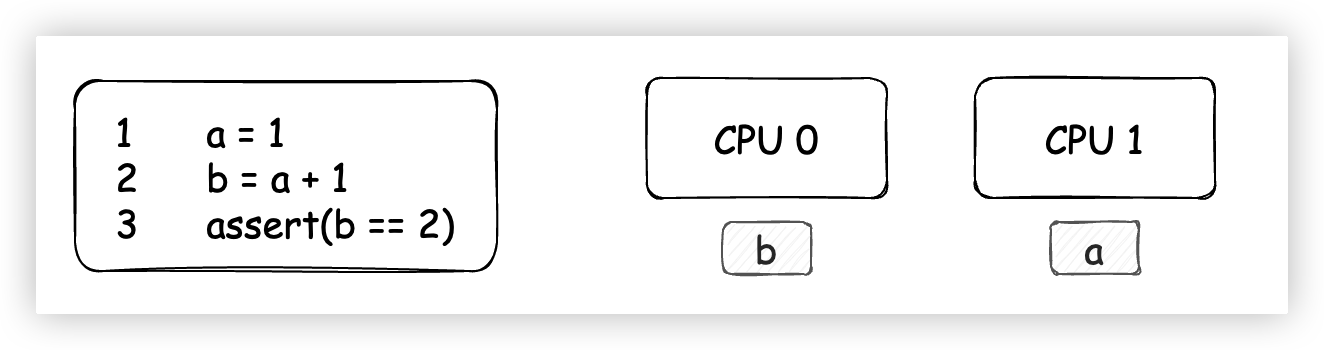
看一下上圖左側的代碼,其中a和b的初始值為0,在大多數時候,最後的斷言會為True。
之所以說大多數時候,因為左側的代碼在某個場景下可能會出現不符合我們預期的情況(斷言為False)。如果要證明,我們只需要舉出一個反例即可,因此我們進一步假設含有變數a的緩存行已經存在於CPU 1的Cache中,含有變數b的緩存行已經存在於CPU 0的Cache中。
下麵我們根據引入Store Buffers之後的CPU架構來執行上面的代碼,CPU 0 和CPU 1 的操作順序如下圖所示:
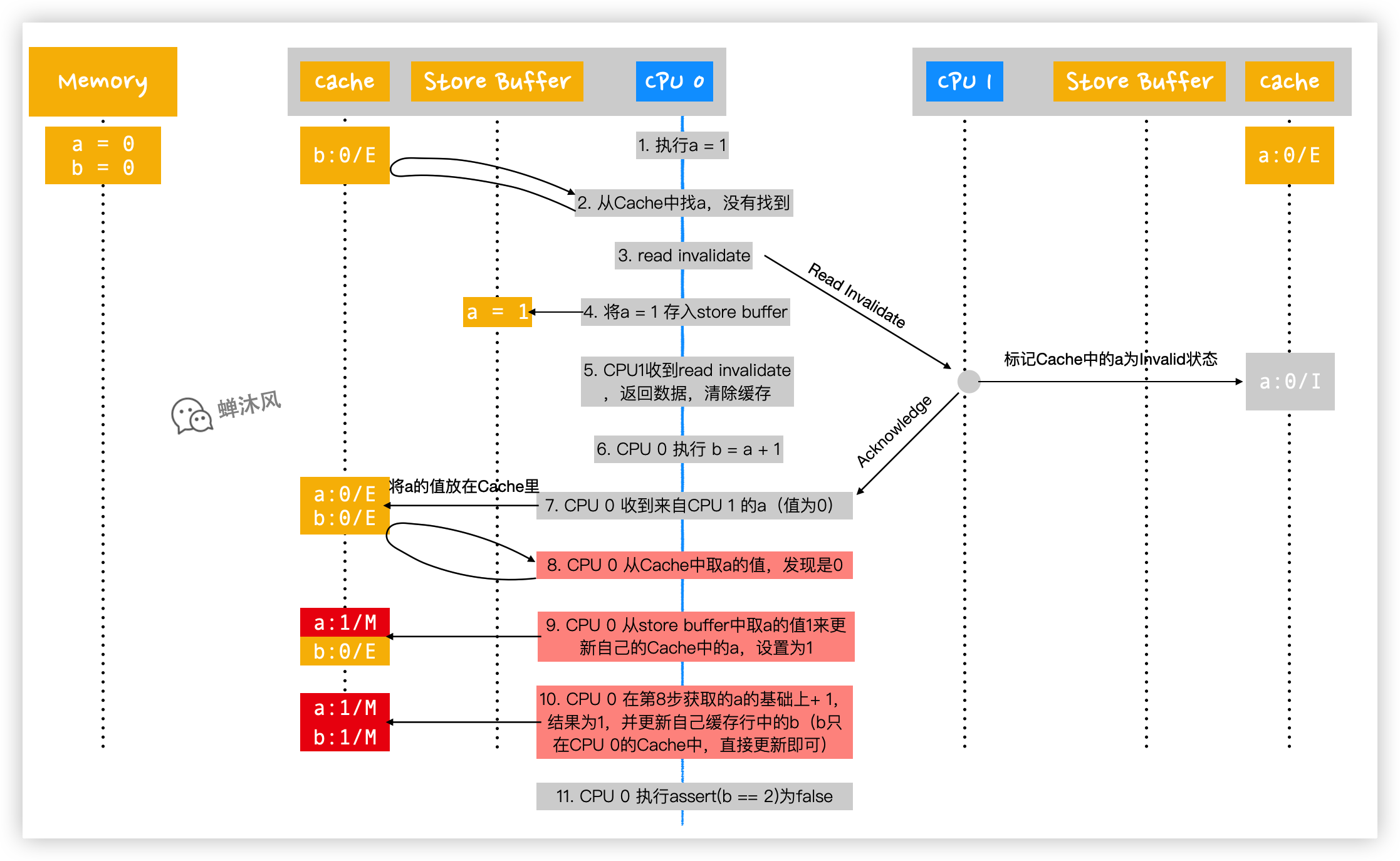
- CPU 0 執行
a = 1; - CPU 0 首先從自己的Cache中查找
a,發現沒有; - CPU 0 發送
Read Invalidate消息來獲取含有a的緩存行,並通知其他CPU,“老子要用,你們都給我銷毀!”; - CPU 0 在
Store Buffer中記錄下自己想賦給a的值,即a = 1。此時CPU 0並不會阻塞,會繼續向下執行,但是在時間線的發展上,緊接著是CPU 1的操作,見第5步; - CPU 1收到來自CPU 0的
Read Invalidate消息,於是把自己包含a的緩存行返回給CPU 0,並且把自己的緩存行狀態設置為Invalid; - CPU 0 開始執行
b = a + 1; - CPU 0 收到來自CPU 1 的緩存行,並放到自己的緩存行中,其中
a的值為0;此時CPU 0 的緩存行中的a和b的狀態都是Exclusive,因為這些緩存行都由CPU 0 獨占; - CPU 0 從緩存行中讀取
a,此時值為0; - CPU 0 根據自己之前在
Store Buffer中存放的a = 1來更新自己Cache中的a,設置為1; - CPU 0 在第8步獲取的
a值的基礎上+ 1(這一步不需要重新從緩存行中讀取數據,因為讀取的動作在第8步中已經做了),並更新自己緩存行中的b;此時包含b的緩存行的狀態為Modified; - CPU 0 執行斷言操作,發現斷言為False。
再給大家補充一個動圖:
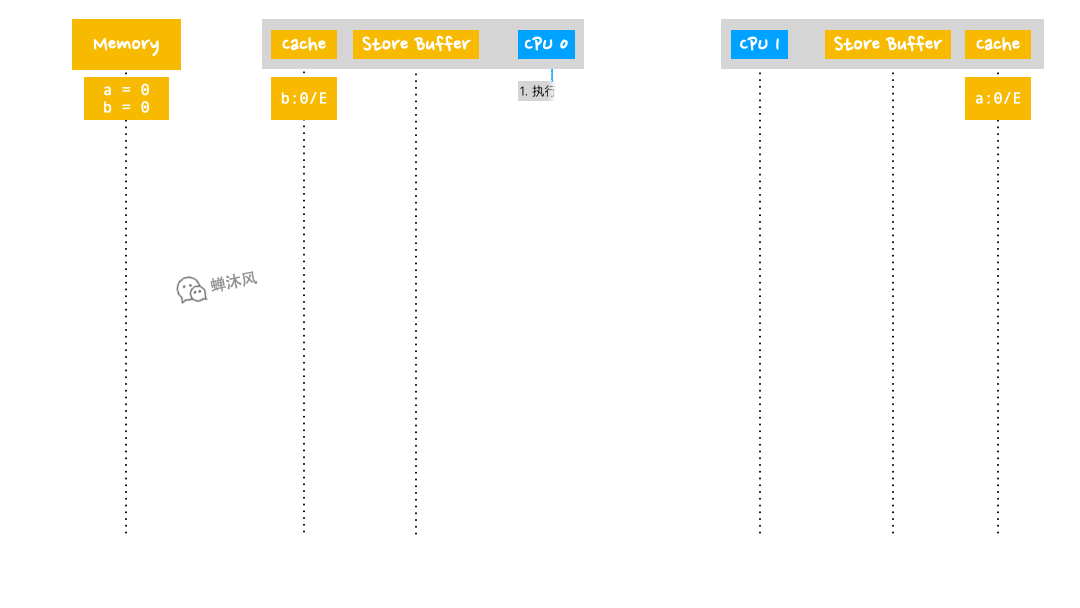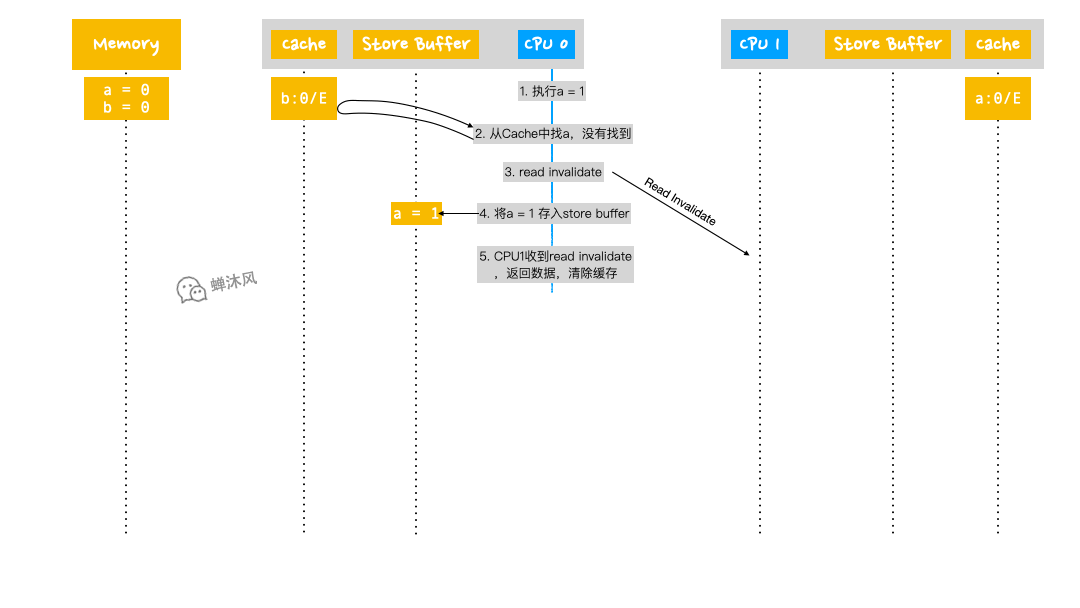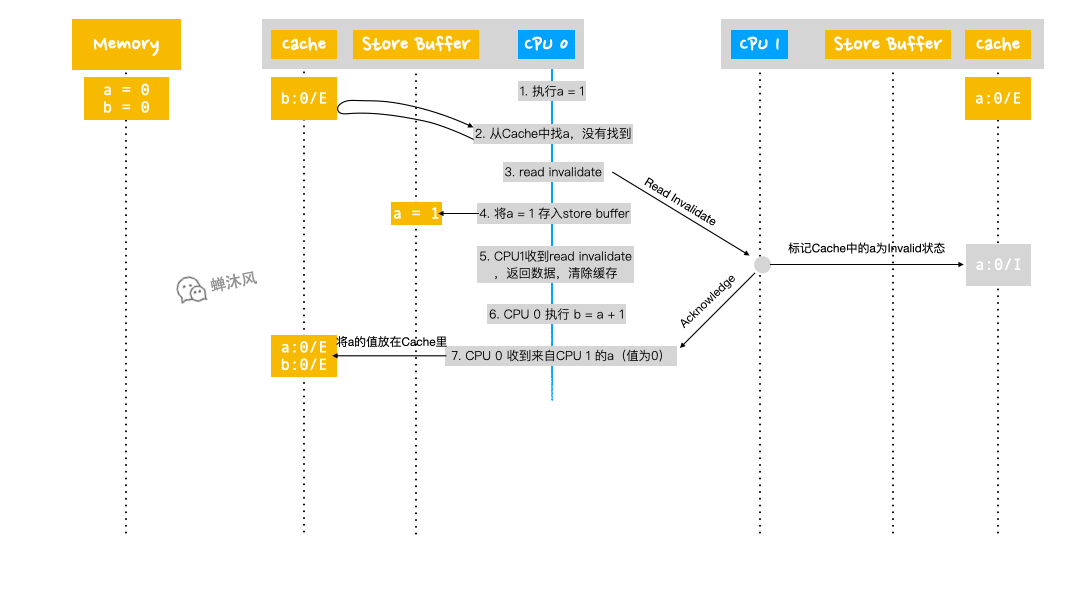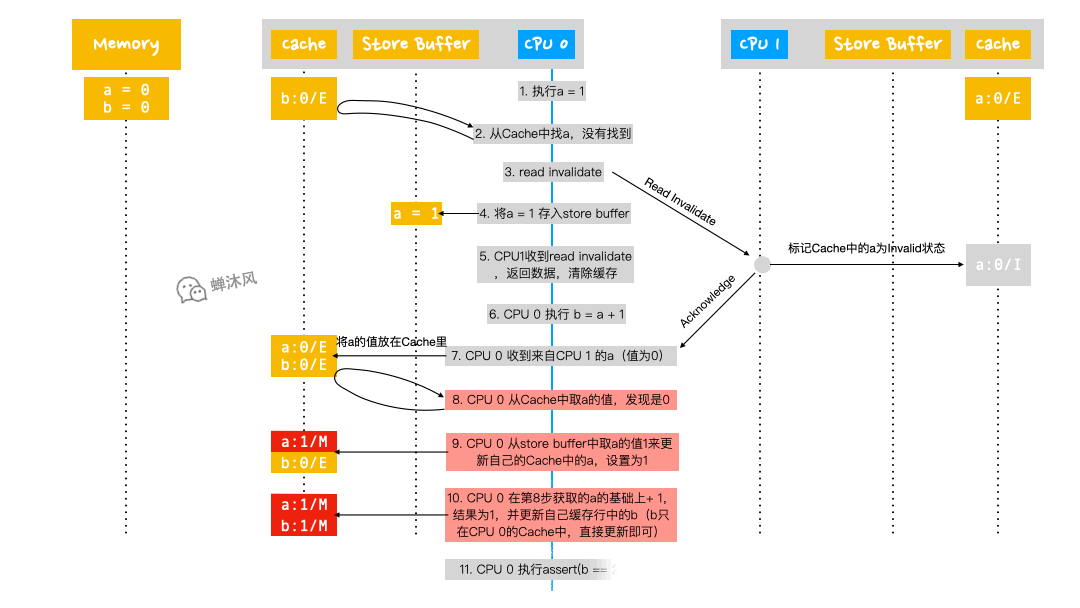
這確實是一件非常違反直覺的事情,我們本來以為CPU就是完全按照代碼的順序執行的(至少最終結果應該表現地像CPU是完全按照代碼的順序執行的一樣),我們認為b的最終結果就應該是2。
出現這個問題的原因是CPU 0 運行過程中出現了a的兩份數據拷貝,一份是在Store Buffer中,一份是在Cache中。為了不讓軟體工程師瘋掉,繼續保持軟體代碼的直觀性,硬體工程師又引入了Store Forwarding來解決這個問題。
6.3. 引入Store Forwarding
每個CPU在執行數據載入操作時都直接使用Store Buffer中的內容,而無需從Cache中獲取,如下圖所示。
請註意上圖和原來圖片的區別,上圖中的Store Buffer中的數據可以直接被CPU讀取。對應到上面的CPU 0 的操作步驟,就是第8步直接從Store Buffer中讀取最新的a,而不是從Cache中讀取,這樣整個程式的最終斷言結果就是True!
總之,引發的第1個問題,硬體工程師通過引入Store Forwarding為我們解決了。
6.4. Store Buffers引起的問題2
在多個CPU併發處理情況下也可能會導致代碼運行出現問題。
同樣也是舉一個極端一點的例子。見下圖左側的代碼,其中a和b的初始值為0,進一步假設含有變數a的緩存行已經存在於CPU 1的Cache中,含有變數b的緩存行已經存在於CPU 0的Cache中。CPU 0 執行foo方法,CPU 1 執行bar方法。正常情況下,bar方法中的斷言結果應該為True。
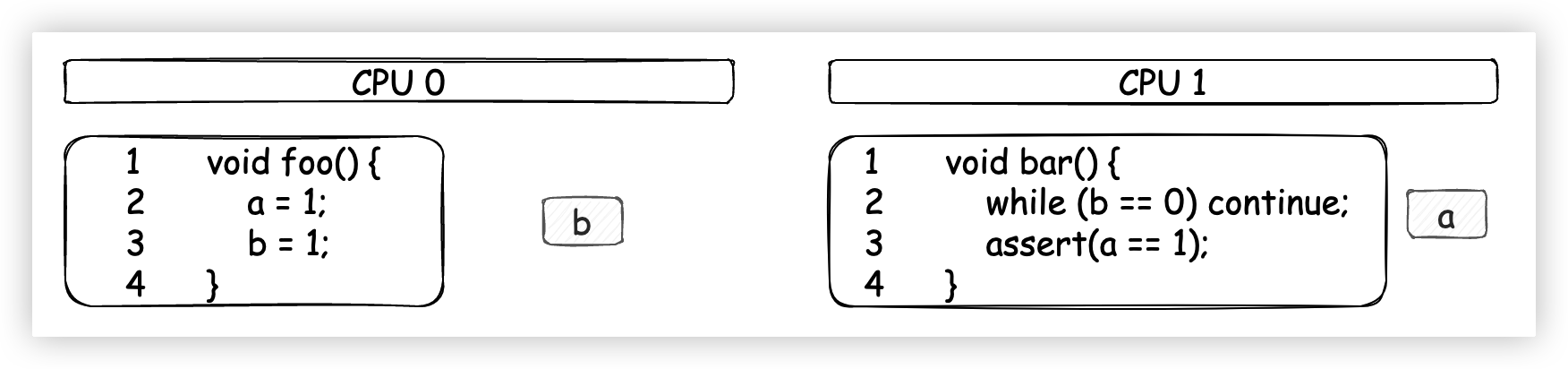
然而,我們按照下圖中的執行順序操作一遍之後,斷言卻是False!
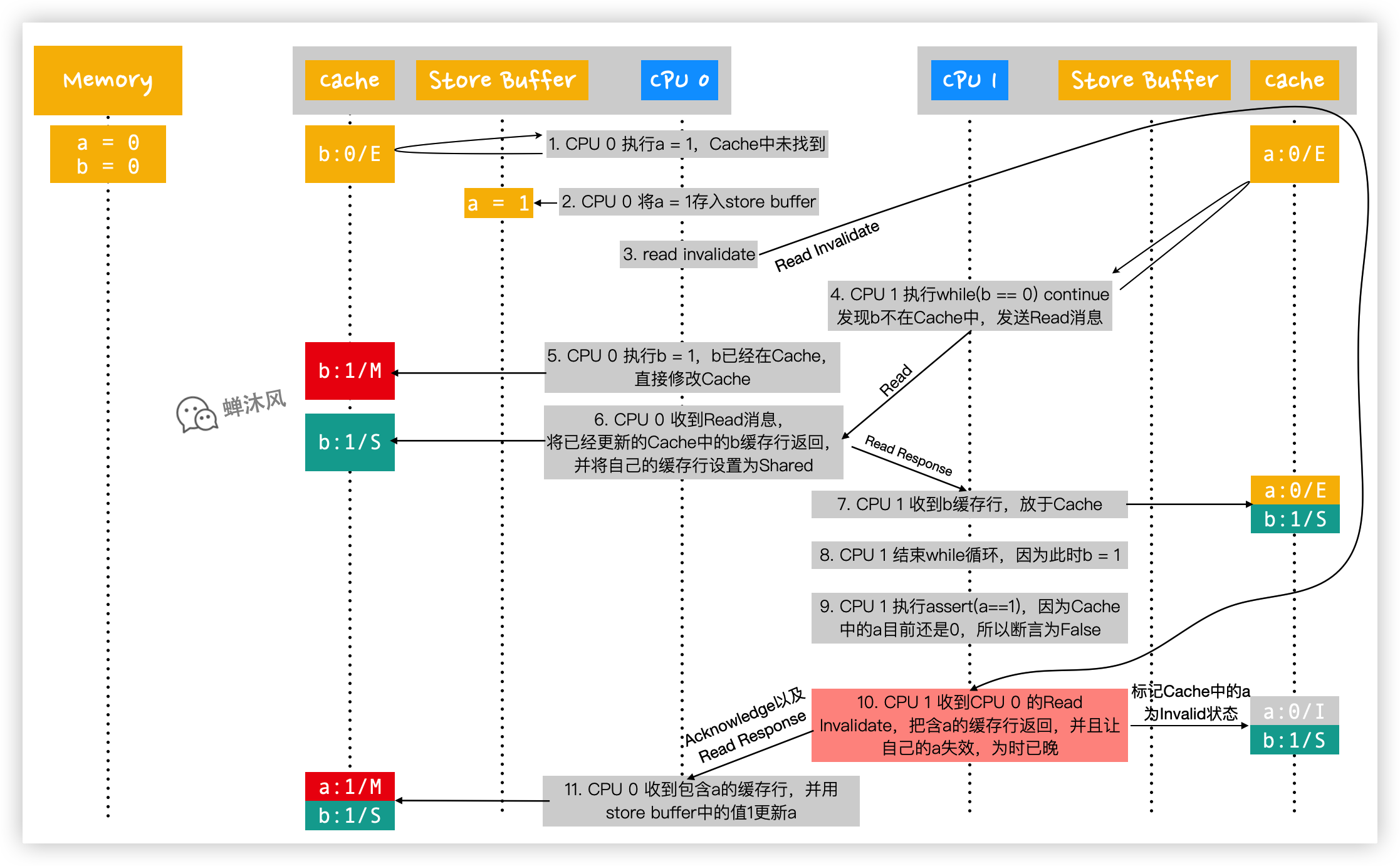
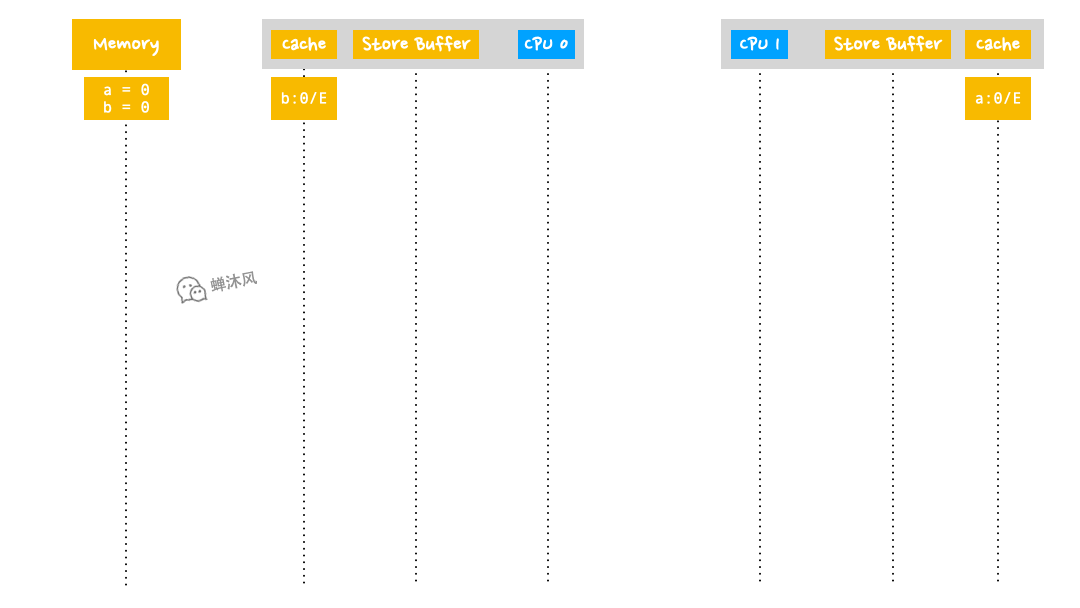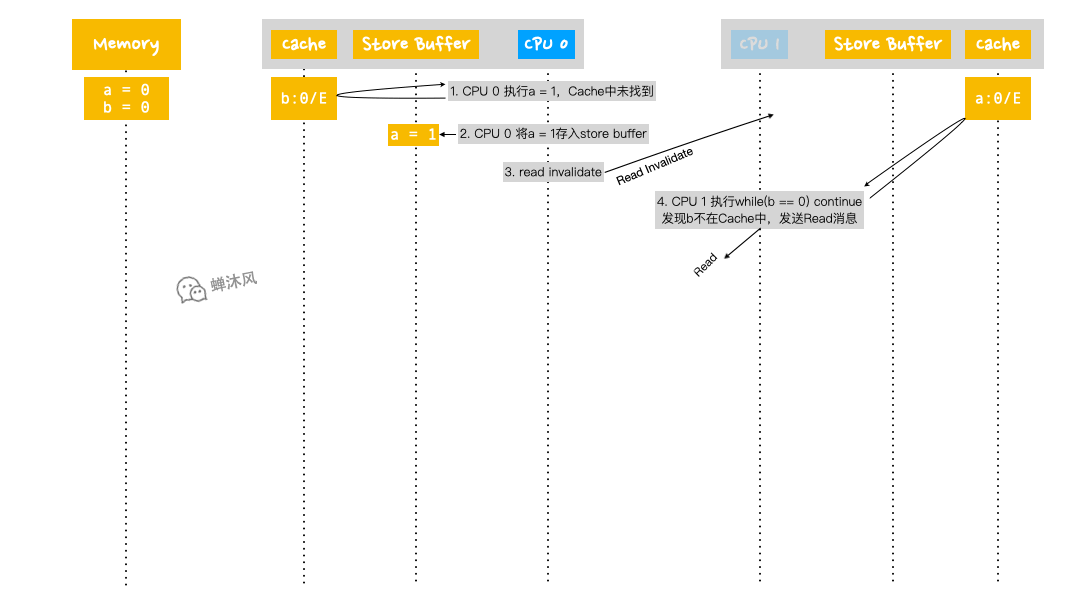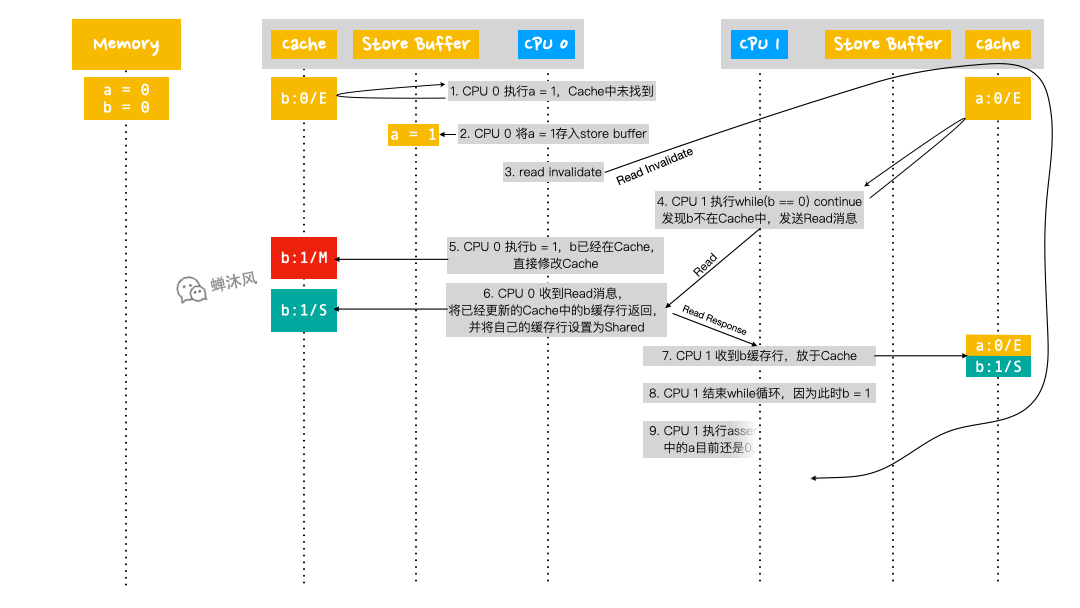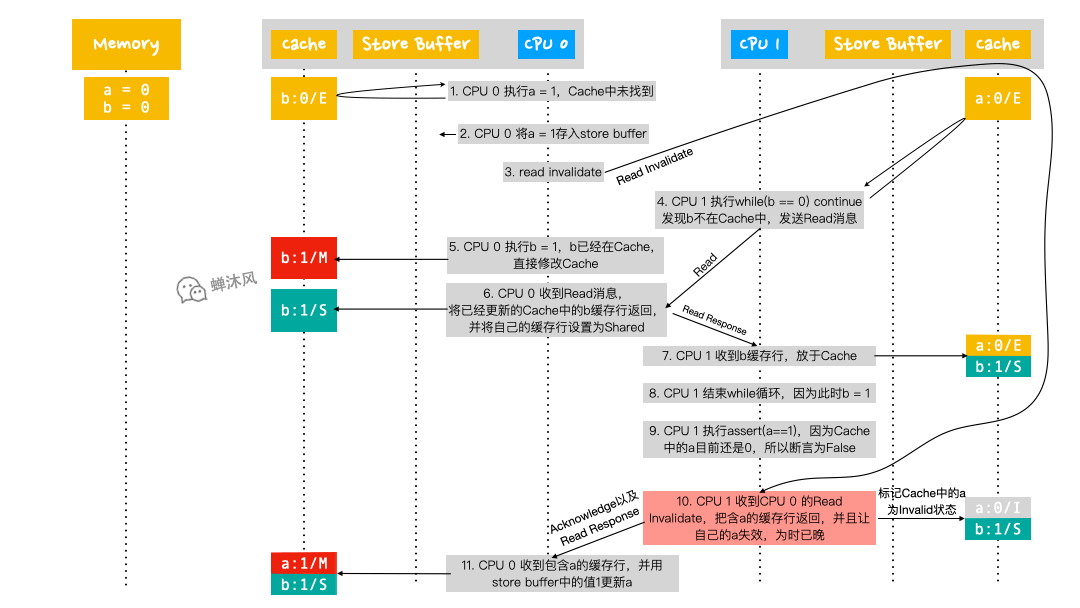
- CPU 0 執行
a = 1,首先從自己的Cache查找啊,發現沒有; - CPU 0 將
a的新值1寫入到自己的Store Buffer中; - CPU 0 發送
Read Invalidate消息(從發出這個消息到CPU 1 接收到,期間又運行了非常多的步驟,見下方GIF圖); - CPU 1 執行
while (b == 0) continue,發現b不在自己的Cache中,於是發送Read消息; - CPU 0 執行
b = 1,由於b已經存在於自己的Cache中了,所以直接將Cache中的b修改為1,並修改包含b的緩存行的狀態為Modified; - CPU 0 收到來自第4步CPU 1 發出的
Read消息,由於當前自己擁有的b是最新版本的,所以CPU 0 把含有b的緩存行返回給CPU 1,同時修改自己的緩存行狀態為Shared; - CPU 1 收到來自CPU 0 的
b緩存行數據,放到自己的Cache中,並設置為Shared狀態; - CPU 1 結束
while迴圈,因為此時的b值已經是1了; - CPU 1 執行
assert(a == 1),由於Cache中的a值是0(此時還沒收到來自CPU 0 的Read Invalidate消息,因此CPU 1 有理由認為自己的數據就是合法的),因此斷言結果為False; - CPU 1 終於收到來自CPU 0 的
Read Invalidate消息了,雖然已經晚了(當然CPU壓根不知道自己的這個消息接收的時機並不合適),但是還得按照約定把自己的a設置為Invalid狀態,並且給CPU 0 發送Invalidate Acknowledge以及Read Response反饋; - CPU 0 收到CPU 1 的反饋,利用
Store Buffer中的值更新a。
至此,流程全部結束,再送給大家一個GIF。
我們分析一下結果不符合我們預期的原因。
Store Buffer的加入導致Read Invalidate的發送是一個非同步操作,非同步可能導致的結果就是CPU 1 接收到CPU 0 的Read Invalidate消息太晚了,導致在Cache中的實際操作順序是b = 1,最後才是a = 1,就好像寫操作被重排序了一樣,這就是CPU的亂序執行。
如果沒有看懂上面一段就再看一下圖片中的CPU 0 Cache的時間線演化。
很多人看到「亂序執行」唯恐避之不及,它當初可是為了提高CPU的工作效率而誕生的,而且在大多數情況下並不會導致什麼錯誤,只是在多處理器(smp)併發執行的時候可能會出現問題,於是便有了下文。
也就是說,如果在第5步CPU 0 修改b之前,我們強制讓CPU 0先完成對a的修改就可以了。
為瞭解決這樣的問題,CPU提供了一些操作指令,來幫助我們避免這樣的問題,就是大名鼎鼎的記憶體屏障(Memory Barrier,mb)。
6.5. 記憶體屏障
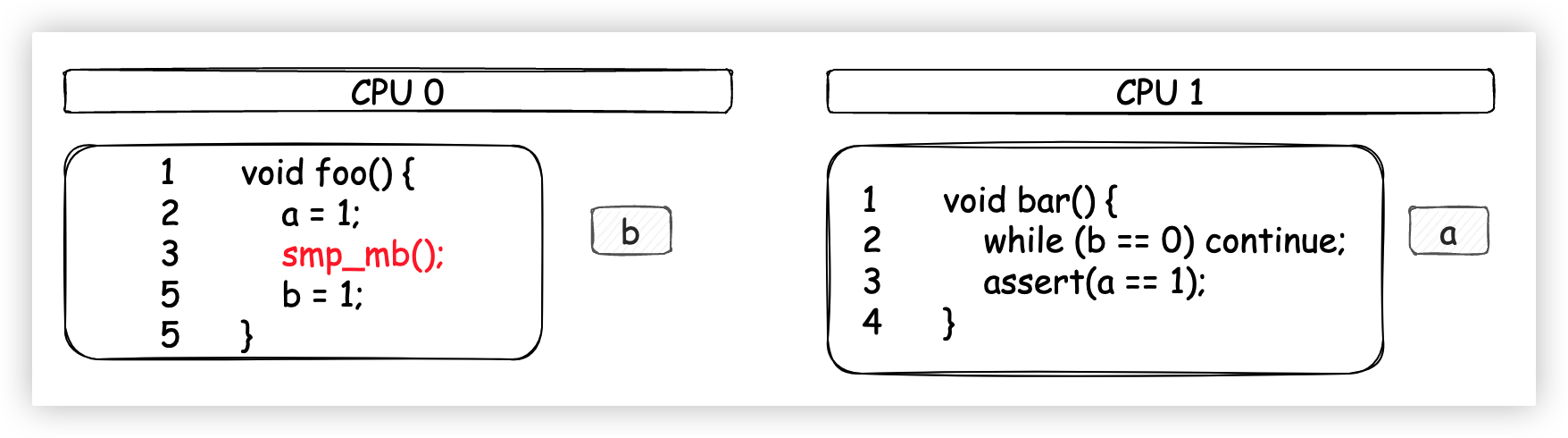
我們稍微修改一下foo方法,在b = 1之前添加一條記憶體屏障指令smp_mb()。
多說一點,
smp的全稱是Symmetrical Multi-Processing(對稱多處理)技術,是指在一個電腦上彙集了一組處理器(多CPU),各CPU之間共用記憶體子系統以及匯流排結構。
為什麼要特意加上smp呢?因為即便現代處理器會亂序執行,但在單個CPU上,指令能通過指令隊列順序獲取指令並執行,結果利用隊列順序返回寄存器,這使得程式執行時所有的記憶體訪問操作看起來像是按程式代碼編寫的順序執行的,因此沒必要使用記憶體屏障(前提是不考慮編譯器的優化的情況)。
記憶體屏障聽起來很高大上,但是對於軟體開發者而言其實非常簡單,總結一句話就是:
在記憶體屏障語句之後的所有針對Cache的寫操作開始之前,必須先把Store Buffer中的數據全部刷新到Cache中。
如果你看明白了我上面說的Store Buffer,這句話是不是賊好懂呢?換個角度再翻譯一下,就是一定要保證存到Store Buffer中的數據有序地刷新到Cache中,這樣就可以避免發生指令重排序了。
如何保證有序呢?
最簡單的方式就是讓CPU傻等,CPU 0 在執行第5步之前必須等著CPU 1給出反饋,直到清空自己的Store Buffer,然後才能繼續向下執行。
啥?又讓CPU閑著?一切讓CPU閑置的方法都是餿主意!
還有一個辦法就是讓數據在Store Buffer中排隊,誰先進入就必須先刷新誰,後邊的必須等著!
這樣一來,本來可以直接寫入Cache的操作(比如待操作的數據已經存在於自己的Cache中了)也必須先存到Store Buffer,然後依序進行刷新。
應用記憶體屏障之後的操作步驟就不給大家再寫一遍了,相信大家能夠想清楚。
總之,引發的第2個問題,我們通過使用記憶體屏障解決了。
6.6. Store Buffers引起的問題3
Store Buffer的容量通常很小,如果CPU此時需要對多個數據執行write操作,碰巧這些數據都不在該CPU的Cache中,那麼該CPU只能發送對應的Read Invalidate指令了,同時新數據寫入Store Buffer,非常容易導致Store Buffer空間被占滿。
一旦Store Buffer被占滿,CPU就只能乾等著目標CPU完成Read Invalidate操作,並且返給自己Invalidate Acknowledge,當前CPU才能逐步將Store Buffer中的值刷新到Cache,騰出空間,然後繼續執行。
CPU又又又閑下來了!所以我們肯定又得找個辦法來解決這個問題。
出現這個問題的主要原因在於Invalidate Acknowledge的反饋速度太慢了!
因為CPU太老實了,它只有在確認自己的緩存行被設置為Invalid狀態之後才會發送Invalidate Acknowledge。如果Cache的其他操作太頻繁,“設置緩存行為Invalid狀態”這個動作本身都會被延遲執行,更何況Invalidate Acknowledge的反饋動作呢,得等到猴年馬月啊!
上面的GIF圖中為了表現出「反饋慢」這種情況,我特意把
Invalidate消息的發送速度設置地很慢,其實消息地發送速度非常快,只是CPU處理Invalidate消息的速度太慢了而已,望悉知。
如果不想等,想直接獲取操作結果,你想到了什麼?
沒錯,是非同步!
實現方式就是再加一層消息隊列——Invalidate Queues。
6.7. 引入Invalidate Queues
如下圖,我們的硬體架構又升級了。在每個CPU的Cache之上,又設置了一個Invalidate Queue。
這樣一來,收到Invalidate消息的CPU核心會把Invalidate消息直接存儲到Invalidate Queue中,然後立即返回Invalidate Acknowledge,不需要再等著緩存行被實際設置成Invalid狀態再發送,極大地提高了反饋速度。
你可能會問,萬一Invalidate Queues中的Invalidate消息最終執行失敗,但是Acknowledge消息已經返回了,這該怎麼辦呢?
好問題!答案是,我不知道。我們就當作硬體工程師絕對不會留下這個bug就是了。
Invalidate Queue填了Store Buffer容量太小的坑,接下來看看它自己又挖了什麼坑吧。
6.7.1. Invalidate Queue引發的問題
這個坑比較嚴重,很有可能直接乾翻緩存屏障,再次引發亂序執行的問題。
老樣子,還是先準備一下翻車的環境。如下圖,我們假設變數a被CPU 0 和CPU 1 共用,為Shared狀態;變數b被CPU 0 獨占,為Exclusive狀態;CPU 0 和CPU 1 分別執行foo和bar方法。
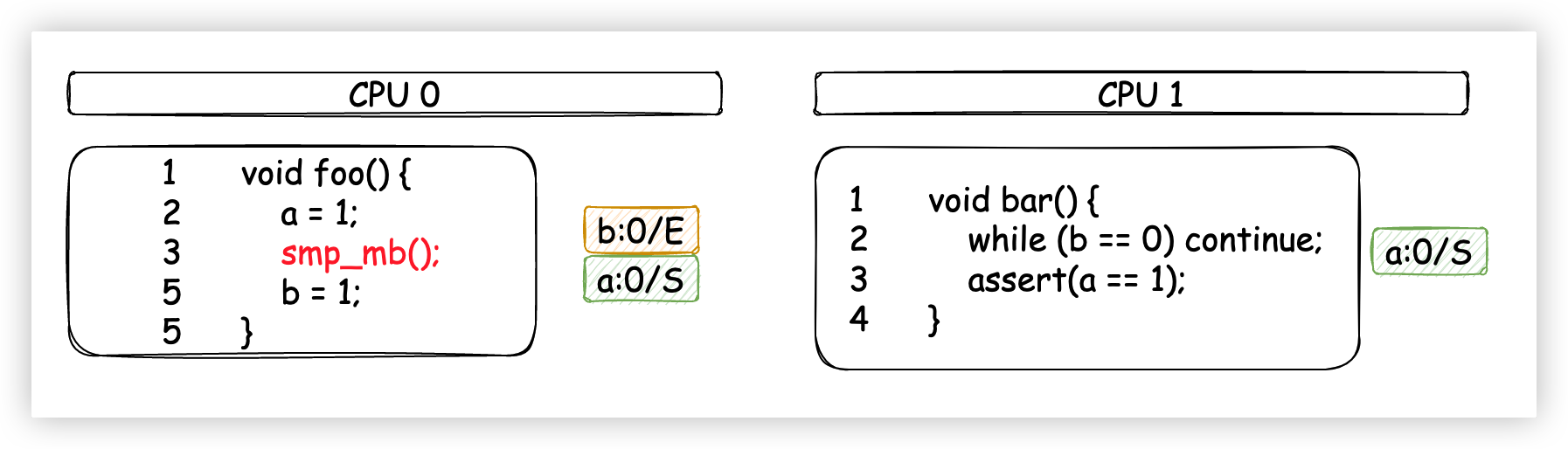
我們按照下圖中的執行順序操作一遍。
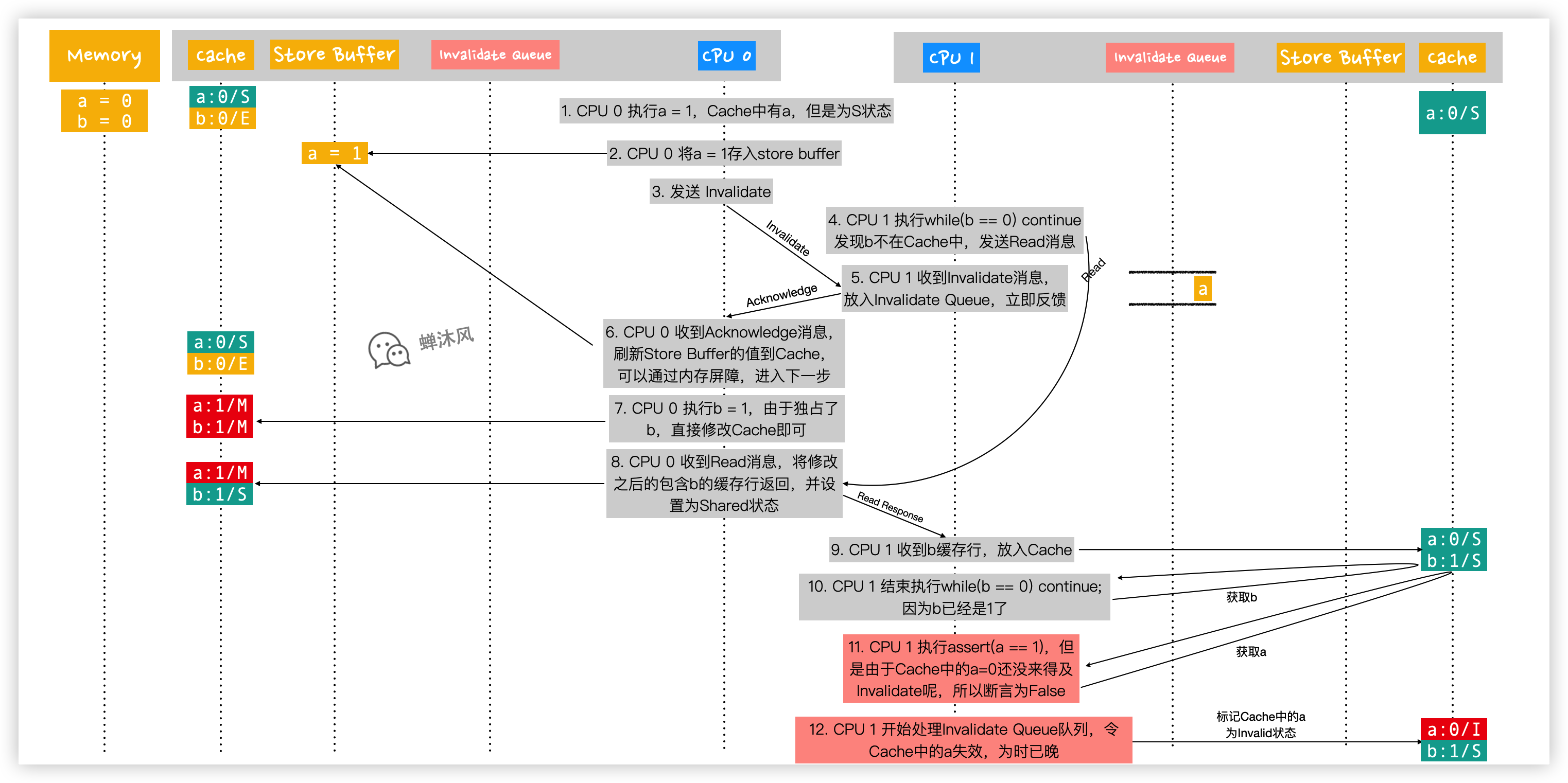
- CPU 0 執行
a = 1,因為CPU 0 的Cache中已經有a了,狀態為Shared,因此不能直接修改,需要發送Invalidate(不是Read Invalidate,因為自己有a)消息使其他緩存行失效; - CPU 0 把試圖修改的
a的最新值1放入Store Buffer; - CPU 0 發送
Invalidate消息; - CPU 1 執行
while(b == 0) continue;發現b不在自己的Cache中,於是發送Read消息來獲取b; - CPU 1 收到來自CPU 0 的
Invalidate消息,把該消息放入Invalidate Queue中(並沒有立即讓a失效),等候處理,然後立刻返回Anknowledge; - CPU 0 收到
Acknowledge消息,認為CPU 1 已經把a值設置為Invalid了,於是放心地把Store Buffer中的數據刷新到自己的Cache中,此時CPU 0 Cache中的a為1,狀態為Modified;然後就可以直接越過smp_mb()記憶體屏障,因為現在Store Buffer中的數據已經空了,滿足記憶體屏障的約束條件。 - CPU 0 執行
b = 1,因為其獨占了b,所以可以直接在Cache中修改b的值,此時b緩存行的狀態為Modified; - CPU 0 收到來自CPU 1 的
Read消息,將修改之後的b緩存行返回,並修改自己Cache中的b緩存行的狀態為Shared; - CPU 1 收到包含
b的緩存行數據,放在自己的Cache中,此時CPU 1 的Cache同時擁有了a和b; - CPU 1 結束執行
while(b == 0) continue;因為此時CPU 1 讀到的b已經是1了; - CPU 1 開始執行
assert(a == 1),CPU 1 從自己的Cache讀到a為0,斷言為False。 - CPU 1 開始處理
Invalidate Queue隊列,令Cache中的a失效,但是為時已晚!
至此流程全部結束,再上個GIF。

問題很明顯出在第11步,這就是臭名昭著著名的可見性問題。CPU 0 修改了a的值,CPU 1 卻不知道或者說知道的太晚!如果在第11步讀取a的值之前就趕緊刷新Invalidate Queue中的消息,讓a失效就好了,這樣CPU 1 就不得不重新Read,得到的結果自然就是1了。
原因搞明白了,怎麼解決呢?記憶體屏障再一次閃亮登場!
6.7.2. 記憶體屏障的另一個功能
上文已經解釋了記憶體屏障的功能,再抄一遍加深印象:
1.在記憶體屏障語句之後的所有針對Cache的寫操作開始之前,必須先把Store Buffer中的數據全部刷新到Cache中。
其實記憶體屏障還有另一個功能:
2.在記憶體屏障語句之後的所有針對Cache的讀操作開始之前,必須先把Invalidate Queue中的數據全部作用到Cache中。
使用緩存屏障之後的代碼就變成了這個樣子:
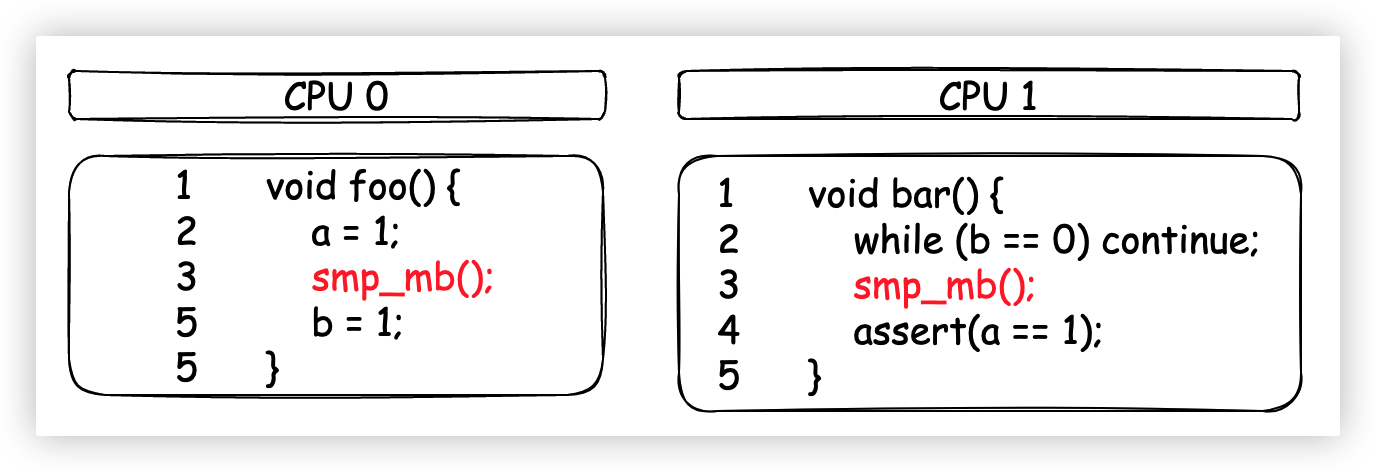
bar方法在assert之前添加了記憶體屏障,意味著在獲取a的值之前,所有在Invalidate Queue中的Invalidate消息必須作用到Cache中。
至此,我們再次用記憶體屏障解決了可見性問題。
問題還沒有結束......
7. 讀記憶體屏障 & 寫記憶體屏障
記憶體屏障有兩個功能,在foo方法中實際發揮作用的是功能1,功能2並沒有派上用場;同理,在bar方法中實際發揮作用的是功能2,功能1並沒有派上用場。於是很多不同型號的CPU架構(不是所有)將記憶體屏障功能分為了讀記憶體屏障和寫記憶體屏障,具體如下。
smp_mb(全記憶體屏障,包含讀和寫全部功能)smp_rmb(read memory barrier,僅包含功能2)smp_wmb(write memory barrier,僅包含功能1)
上文已經解釋地挺清楚了,因此就不再重覆介紹smp_rmb和smp_wmb的作用了。直接看修改之後的代碼吧。
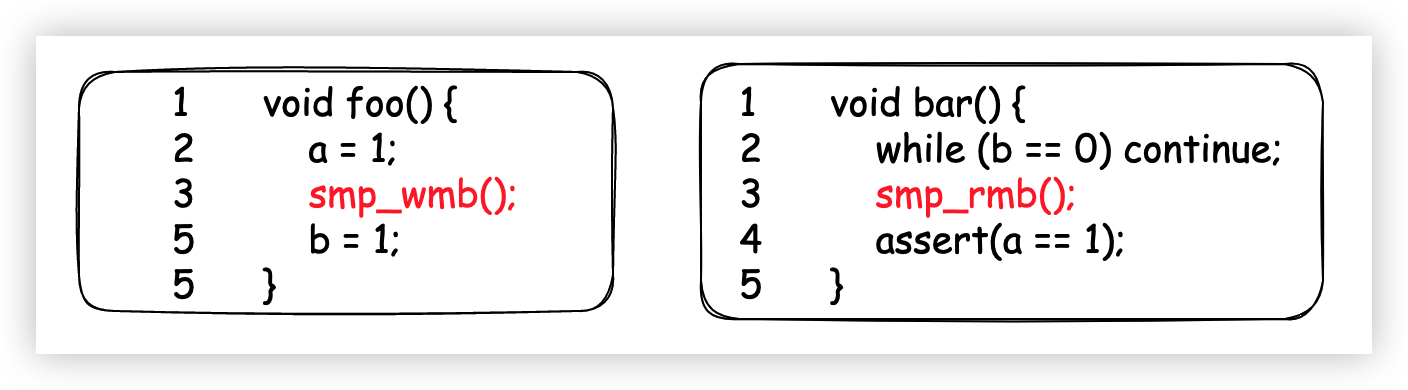
8. 總結
電腦的演進就是一部反覆挖坑、填坑的發展史。
為瞭解決記憶體和CPU之間速度差異過大的問題,引入了高速緩存Cache,結果導致了緩存一致性問題;
為了達到緩存一致的效果,CPU之間需要溝通啊,於是又設計了各種消息傳遞,結果消息傳遞導致了CPU的偶爾閑置;
為了不讓CPU停下來,硬體工程師加入了寫緩衝——Store Buffer,這一下子帶來了3個問題!
第一個問題比較簡單,通過引入Store Forwarding解決了;
第二個問題是操作重排序問題,我們又引入了記憶體屏障的第一個大招;
第三個問題是由於Store Buffer空間限制導致CPU又閑下來了,於是又設計了Invalidate Queues,然後又導致了亂序執行和可見性問題;
通過使用記憶體屏障的全部大招終於解決了亂序執行和可見性問題,又引出了大招傷害性過強的問題,於是又拆分成了更細粒度的讀屏障和寫屏障。。。。。。
9. 後記
問題其實還有很多,比如各種不同CPU結構是怎麼實現記憶體屏障的?可想而知,每個人都有每個人的想法,不同CPU的實現指定也不一樣,甚至可能拆分地更細或者更粗。不過這些與大部分軟體開發者(包括我)都沒有什麼關係了,更多問題還是留給晶元開發者以及操作系統開發者吧。
不要糾結於具體的實現細節,把文章中的大部分搞懂已經能幫助我們理解很多問題了。如果還想知道的更多,可以看看附錄3中的第1篇文章。
10. 附錄1——MESI躍遷場景解析
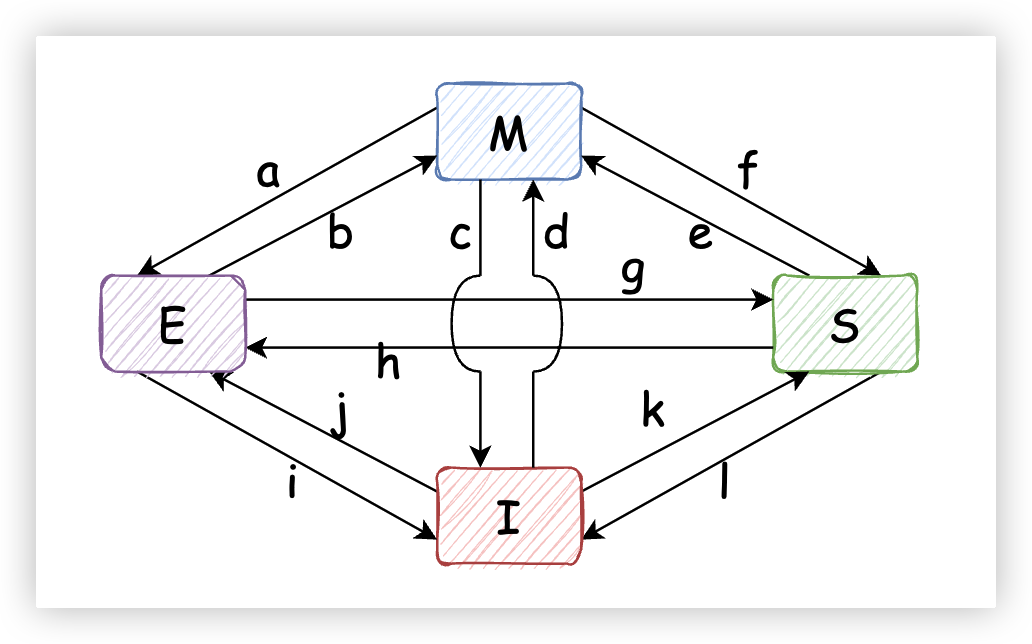
(a):通過Writeback消息把被修改過的緩存行刷新至記憶體,但是CPU的Cache仍然保留該數據;
(b):CPU修改了只保存在當前Cache中的緩存行;
(c):CPU收到了Read Invalidate消息,該消息的目標正是當前處於M狀態(被修改了)的緩存行。CPU不得不使自己的緩存行失效,並把該緩存行數據攜同Read Response以及Invalidate Acknowledge消息返回;
(d):CPU執行了一個原子操作,該操作包含讀和寫兩個子操作,並且不可分割。CPU首先發送Read Invalidate消息,收到Read Response消息之後立刻對數據進行更新,至此便完成了該原子操作。
(e):和d大致相同。CPU執行了一個原子操作,該操作包含讀和寫兩個子操作,並且不可分割。CPU首先發送Invalidate消息,收到Invalidate Acknowledge消息之後立刻對數據進行更新,至此便完成了該原子操作。
(f):當前CPU修改了一個緩存行數據,接著其他CPU核心對當前CPU的該緩存行發出Read消息,當前CPU將該緩存行數據隨Read Response消息反饋給其他CPU核心。至於該過程會不會涉及到緩存行數據刷新到記憶體,那就不一定了。
(g):當前CPU獨占了一個未經修改的緩存行,其他CPU對當前CPU的該緩存行發出Read消息,當前CPU將該緩存行隨Read Response消息反饋給其他CPU,並將緩存行的狀態由Exclusive改為Shared;
(h):多個CPU共用某個緩存行,其中一個CPU對其他CPU發出Invalidate消息,該CPU收到其他所有擁有該緩存行的CPU的Invalidate Acknowledge消息之後,將該緩存行狀態切換為Exclusive;或者其他CPU自己清空了該緩存行(比如為其他數據騰出空間)導致該CPU獨占該緩存行,同樣會發生這種狀態轉換。
(i):其他CPU對當前CPU獨占的一個緩存行發出一個Read Invalidate消息,當前CPU將該緩存行設置為Invalid,併發送Read Response以及Invalidate Acknowledge反饋;
(j):CPU對不在自己Cache的一個數據進行寫操作,因此發出Read Invalidate消息,收到一條Read Response(可能來自其他Cache,也可能來自記憶體)以及所有擁有該緩存行的CPU的Invalidate Acknowledge反饋(可能壓根沒有)之後,緩存行被當前CPU獨占;
(k):CPU讀取某個自己Cache中不存在的數據,於是發出Read消息,收到Read Response(該消息一定來自於其他CPU)之後,緩存行的狀態由Invalid變為了Shared;
(l):當前CPU和其他CPU共用了一個緩存行,突然有一個其他CPU向當前CPU發來一條Invalidate消息,當前緩存行只能默默把自己的緩存行設置為Invalidate,並回覆Invalidate Acknowledge。
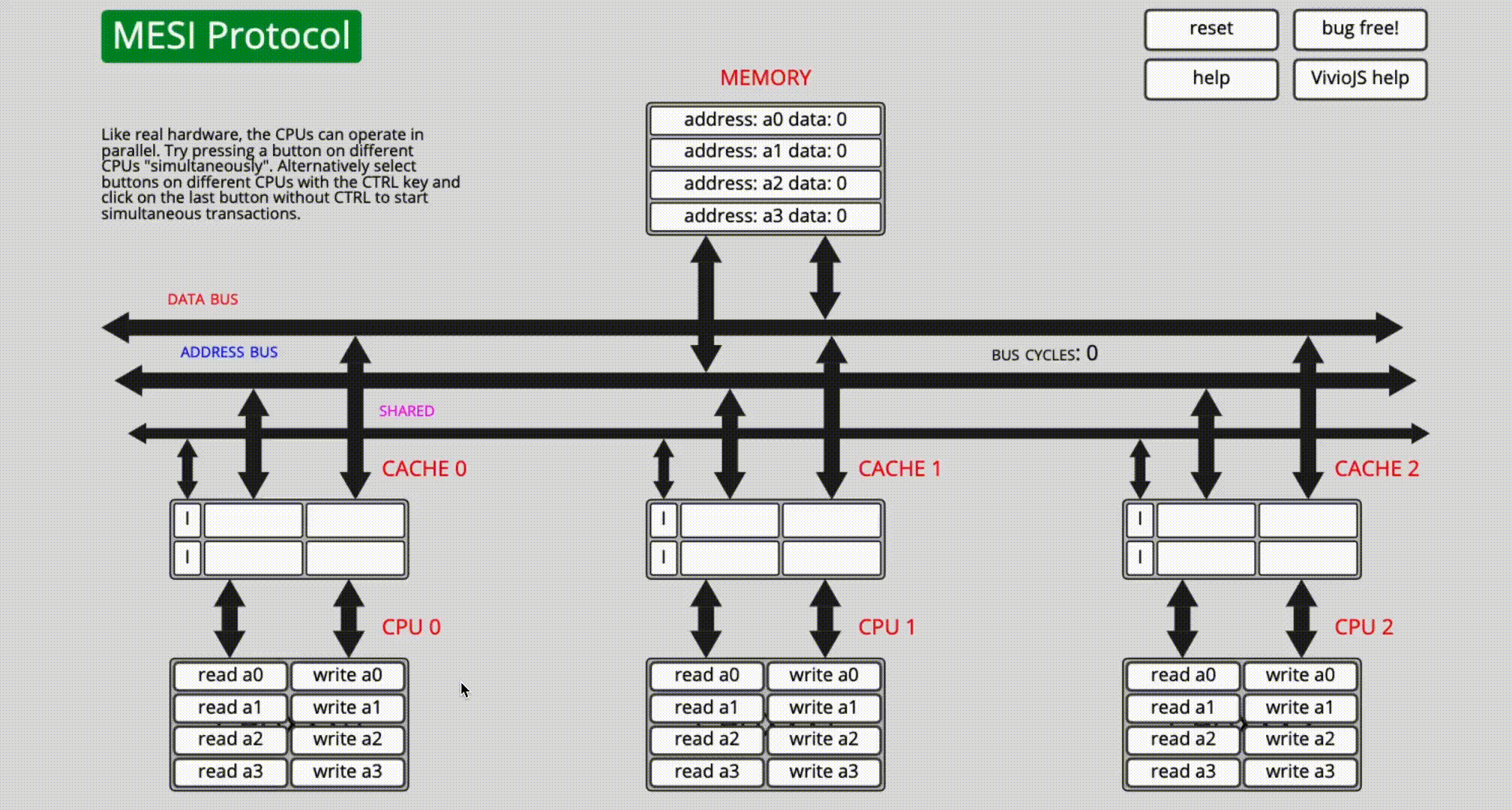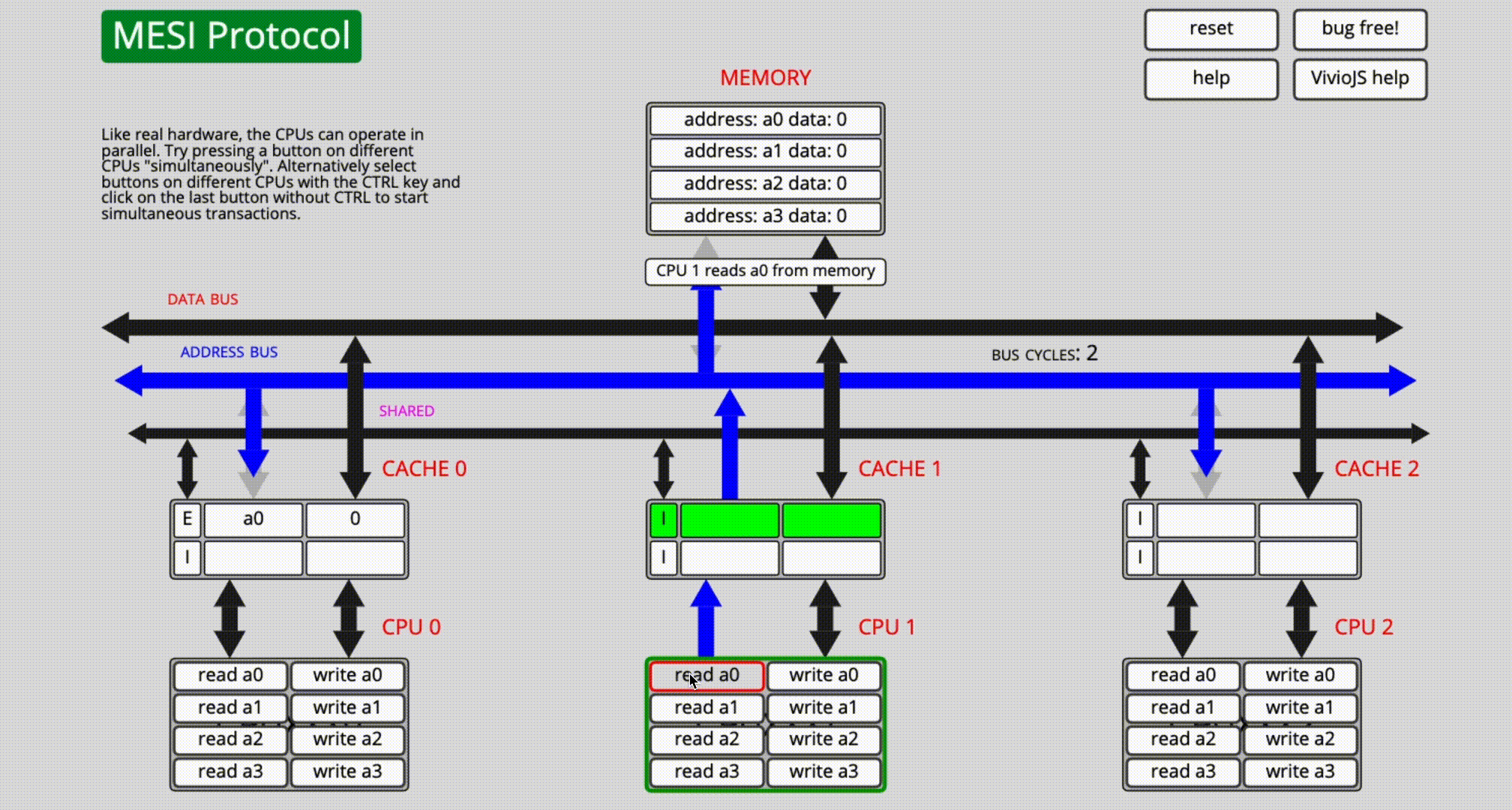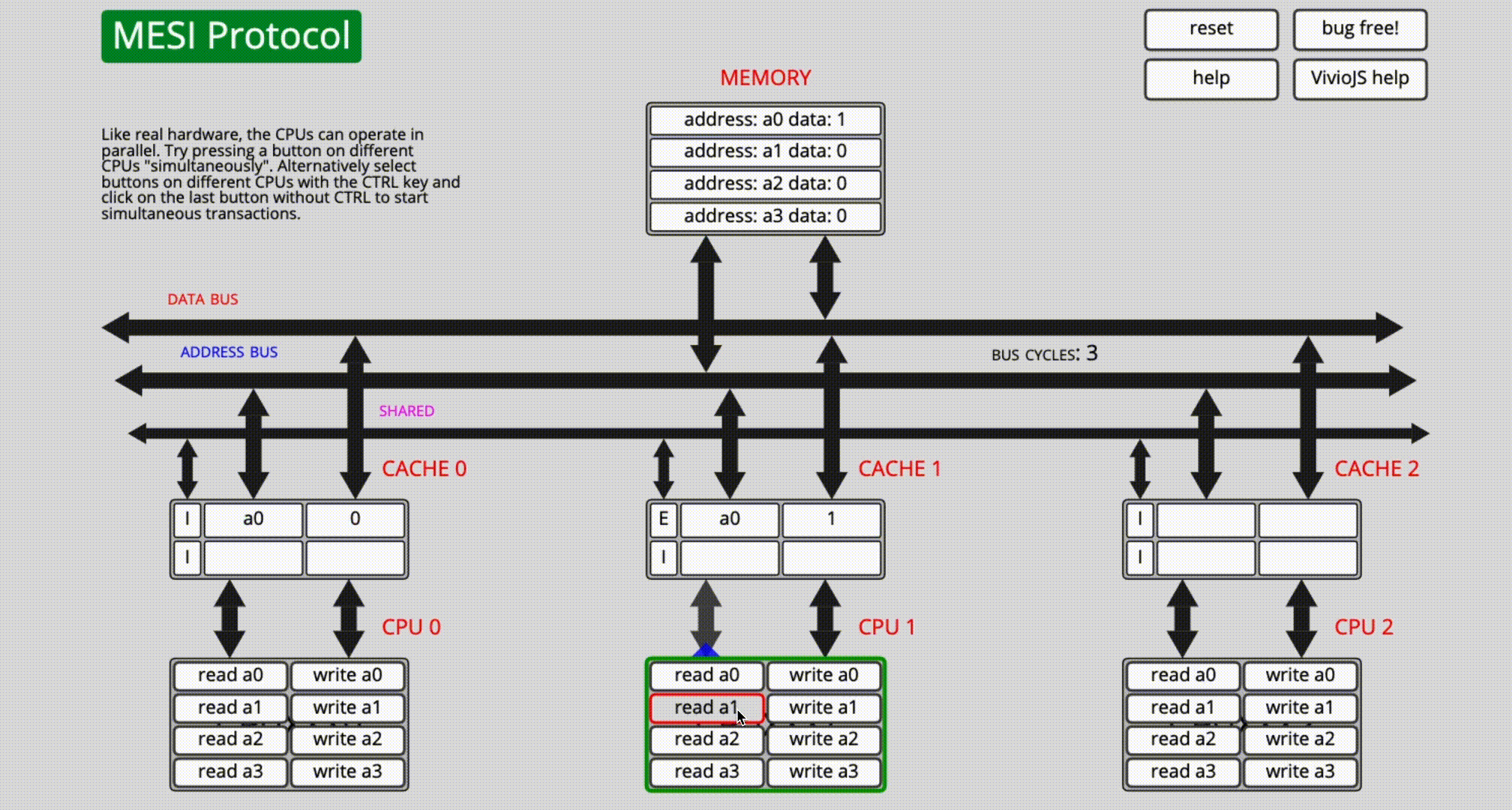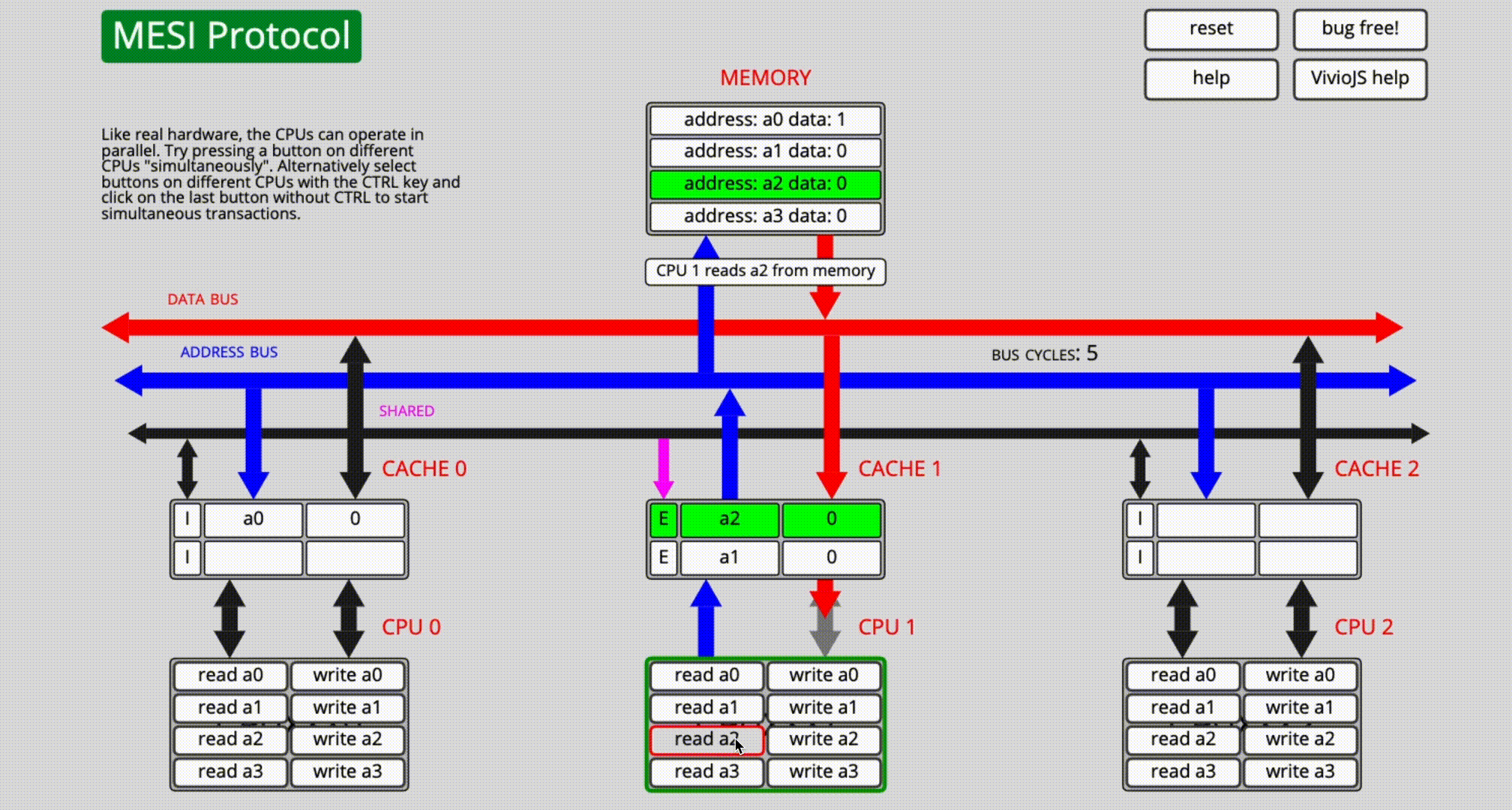
11. 附錄2——MESI線上網站使用
地址:https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
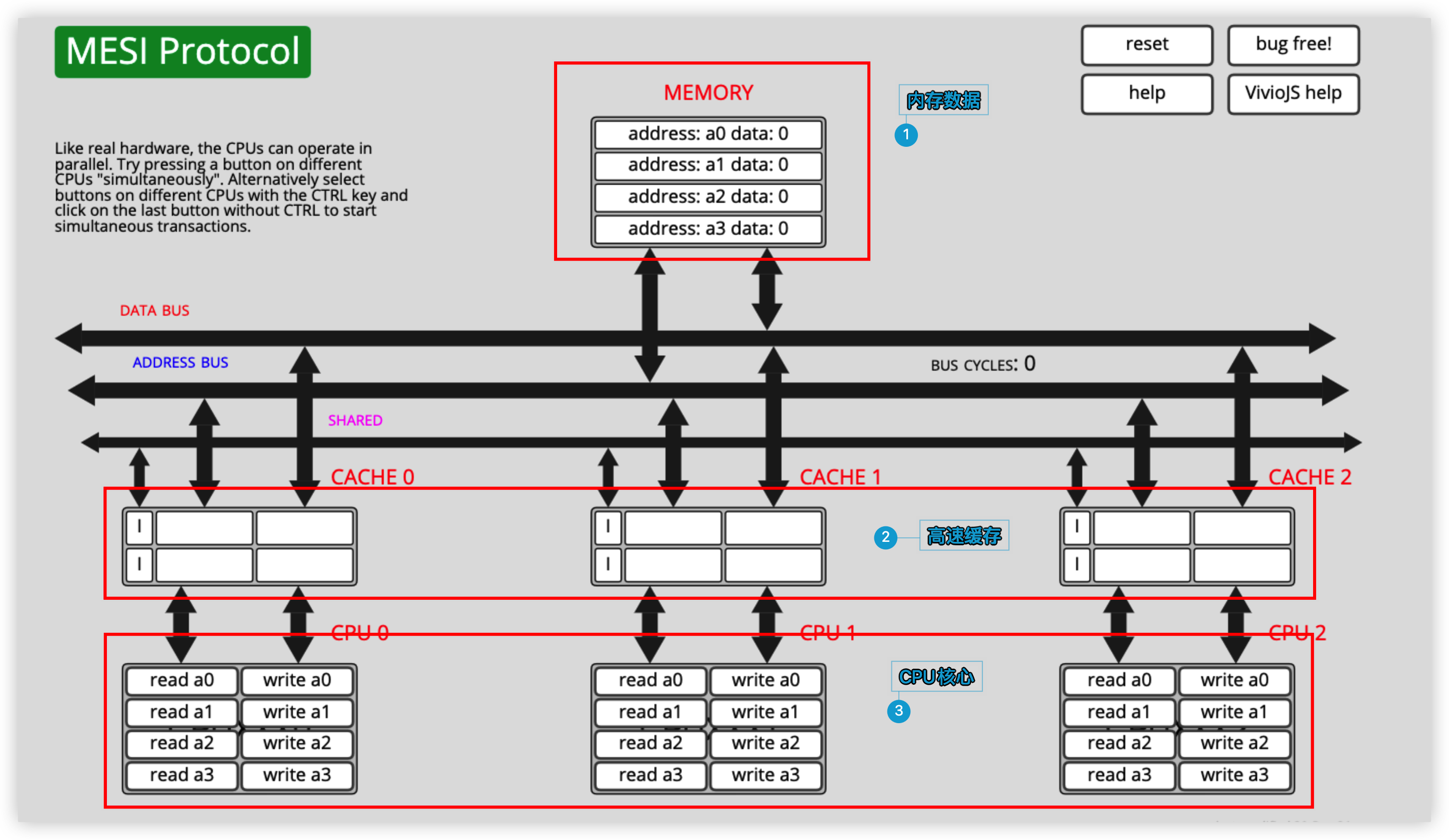
見上圖,網站主要分為3部分
- 記憶體數據
記憶體中保存了4個數據,初始值為0,地址分別為a0、a1、a2、a3。
- 高速緩存
顯示 CPU 緩存的變數數據和 MESI 協議狀態。該高速緩存能容納2個緩存行數據,所有緩存行的初始狀態為I(Invalid)。
- CPU核心
共有3個 CPU,每個 CPU 都有各自的 Cache,CPU 操作分為「讀」和「寫」,這部分是我們可以手動操作的部分。
舉個例子:
- CPU0執行
read a0,於是通過各種bus匯流排將記憶體中地址為a0的數據讀入緩存行內,由於目前只有CPU0獨占該緩存行,所以狀態變為Exclusive; - CPU1執行
read a0,又通過各種bus匯流排將a0的數據讀到自己的緩存行內,此時CPU0和CPU1的緩存行都變為Shared狀態; - CPU1執行
write a0,將地址為a0的數據+1後寫回記憶體,同時向CPU0發出Invalidate信號,導致CPU0將其緩存行置為Invalid狀態;此時CPU1獨占緩存行,因此緩存行為Exclusive狀態; - CPU1執行
read a1,類似第1步,通過各種bus匯流排將記憶體中地址為a1的數據讀入緩存行內,由於目前只有CPU1獨占該緩存行,所以狀態為Exclusive;此時CPU1的Cache被占滿; - 最後CPU1執行
read a2,由於CPU1的Cache已經被占滿了,只能彈出a0,存入a2,此時a2狀態為Exclusive。
12. 附錄3——參考文獻
[1] Paul E. McKenney. Memory Barriers: a Hardware View for Software Hackers.
[2] barrier和smp_mb
[3] 記憶體屏障和volatile語義
[4] 解密記憶體屏障
[5] MESI線上網站
[6] 看懂這篇,才能說瞭解併發底層技術
[7] Why Memory Barriers中文翻譯(下)
[8] MESI與記憶體屏障

