
1. ElasticSearch快速入門 1.1. 基本介紹 ElasticSearch特色 Elasticsearch是實時的分散式搜索分析引擎,內部使用Lucene做索引與搜索 實時性:新增到 ES 中的數據在1秒後就可以被檢索到,這種新增數據對搜索的可見性稱為“準實時搜索” 分散式:意味著可以 ...
1. ElasticSearch快速入門
1.1. 基本介紹
-
ElasticSearch特色
Elasticsearch是實時的分散式搜索分析引擎,內部使用Lucene做索引與搜索
-
實時性:新增到 ES 中的數據在1秒後就可以被檢索到,這種新增數據對搜索的可見性稱為“準實時搜索”
-
分散式:意味著可以動態調整集群規模,彈性擴容
-
集群規模:可以擴展到上百台伺服器,處理PB級結構化或非結構化數據
-
各節點組成對等的網路結構,某些節點出現故障時會自動分配其他節點代替其進行工作
Lucene是Java語言編寫的全文搜索框架,用於處理純文本的數據,但它只是一個庫,提供建立索引、執行搜索等介面,但不包含分散式服務,這些正是 ES 做的
-
-
ElasticSearch使用場景
ElasticSearch廣泛應用於各行業領域, 比如維基百科, GitHub的代碼搜索,電商網站的大數據日誌統計分析, BI系統報表統計分析等。
-
提供分散式的搜索引擎和數據分析引擎
比如百度,網站的站內搜索,IT系統的檢索, 數據分析比如熱點詞統計, 電商網站商品TOP排名等。
-
全文檢索,結構化檢索,數據分析
支持全文檢索, 比如查找包含指定名稱的商品信息; 支持結構檢索, 比如查找某個分類下的所有商品信息;
還可以支持高級數據分析, 比如統計某個商品的點擊次數, 某個商品有多少用戶購買等等。
-
支持海量數據準實時的處理
採用分散式節點, 將數據分散到多台伺服器上去存儲和檢索, 實現海量數據的處理, 比如統計用戶的行為日誌, 能夠在秒級別對數據進行檢索和分析。
-
-
ElasticSearch基本概念介紹
ElasticSearch Relational Database Index Database Type Table Document Row Field Column Mapping Schema Everything is indexed Index Query DSL SQL GET http://... SELECT * FROM table... PUT http://... UPDATE table SET... -
索引(Index)
相比傳統的關係型資料庫,索引相當於SQL中的一個【資料庫】,或者一個數據存儲方案(schema)。
-
類型(Type)
一個索引內部可以定義一個或多個類型, 在傳統關係資料庫來說, 類型相當於【表】的概念。
-
文檔(Document)
文檔是Lucene索引和搜索的原子單位,它是包含了一個或多個域的容器,採用JSON格式表示。相當於傳統資料庫【行】概念
-
集群(Cluster)
集群是由一臺及以上主機節點組成並提供存儲及搜索服務, 多節點組成的集群擁有冗餘能力,它可以在一個或幾個節點出現故障時保證服務的整體可用性。
-
節點(Node)
Node為集群中的單台節點,其可以為master節點亦可為slave節點(節點屬性由集群內部選舉得出)並提供存儲相關數據的功能
-
切片(shards)
切片是把一個大文件分割成多個小文件然後分散存儲在集群中的多個節點上, 可以將其看作mysql的分庫分表概念。 Shard有兩種類型:primary主片和replica副本,primary用於文檔存儲,每個新的索引會自動創建5個Primary shard;Replica shard是Primary Shard的副本,用於冗餘數據及提高搜索性能。
-
註意: ES7之後Type被捨棄,只有Index(等同於資料庫+表定義)和Document(文檔,行記錄)。
1.2 ElasticSearch安裝
-
下載ElasticSearch服務
下載最新版ElasticSearch7.10.2: https://www.elastic.co/cn/start
-
解壓安裝包
tar -xvf elasticsearch-7.10.2-linux-x86_64.tar.gz -
ElasticSearch不能以Root身份運行, 需要單獨創建一個用戶
1. groupadd elsearch 2. useradd elsearch -g elsearch -p elasticsearch 3. chown -R elsearch:elsearch /usr/local/elasticsearch-7.10.2執行以上命令,創建一個名為elsearch用戶, 並賦予目錄許可權。
-
修改配置文件
vi config/elasticsearch.yml, 預設情況下會綁定本機地址, 外網不能訪問, 這裡要修改下:
# 外網訪問地址 network.host: 0.0.0.0 -
關閉防火牆
systemctl stop firewalld.service systemctl disable firewalld.service -
指定JDK版本
-
最新版的ElasticSearch需要JDK11版本, 下載JDK11壓縮包, 併進行解壓。
-
修改環境配置文件
vi bin/elasticsearch-env
參照以下位置, 追加一行, 設置JAVA_HOME, 指定JDK11路徑。
JAVA_HOME=/usr/local/jdk-11.0.11 # now set the path to java if [ ! -z "$JAVA_HOME" ]; then JAVA="$JAVA_HOME/bin/java" else if [ "$(uname -s)" = "Darwin" ]; then # OSX has a different structure JAVA="$ES_HOME/jdk/Contents/Home/bin/java" else JAVA="$ES_HOME/jdk/bin/java" fi fi
-
-
啟動ElasticSearch
-
切換用戶
su elsearch
-
以後臺常駐方式啟動
bin/elasticsearch -d
-
-
問題記錄
出現max virtual memory areas vm.max_map_count [65530] is too low, increase to at least 錯誤信息
修改系統配置:
-
vi /etc/sysctl.conf
添加
vm.max_map_count=655360
執行生效
sysctl -p
-
vi /etc/security/limits.conf
在文件末尾添加
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 elsearch soft nproc 125535 elsearch hard nproc 125535重新切換用戶即可:
su - elsearch
-
-
訪問驗證

啟動狀態有green、yellow和red。 green是代表啟動正常。
1.3 Kibana服務安裝
Kibana是一個針對Elasticsearch的開源分析及可視化平臺,用來搜索、查看交互存儲在Elasticsearch索引中的數據。
-
到官網下載, Kibana安裝包, 與之對應7.10.2版本, 選擇Linux 64位版本下載,併進行解壓。
tar -xvf kibana-7.10.2-linux-x86_64.tar.gz -
Kibana啟動不能使用root用戶, 使用上面創建的elsearch用戶, 進行賦權:
chown -R elsearch:elsearch kibana-7.10.2-linux-x86_64 -
修改配置文件
vi config/kibana.yml , 修改以下配置:
# 服務埠 server.port: 5601 # 服務地址 server.host: "0.0.0.0" # elasticsearch服務地址 elasticsearch.hosts: ["http://192.168.116.140:9200"] -
啟動kibana
./kibana -q看到以下日誌, 代表啟動正常
log [01:40:00.143] [info][listening] Server running at http://0.0.0.0:5601如果出現啟動失敗的情況, 要檢查集群各節點的日誌, 確保服務正常運行狀態。
-
訪問服務
1.4 ES的基礎操作
-
進入Kibana管理後臺
地址: http://192.168.116.140:5601
進入"Dev Tools"欄:
在Console中輸入命令進行操作。
-
分片設置:
這裡增加名為orders的索引, 因為是單節點, 如果副本數, 是會出現錯誤。
PUT orders { "settings": { "index": { "number_of_shards": 2, "number_of_replicas": 2 } } }查看索引信息, 會出現yellow提示:
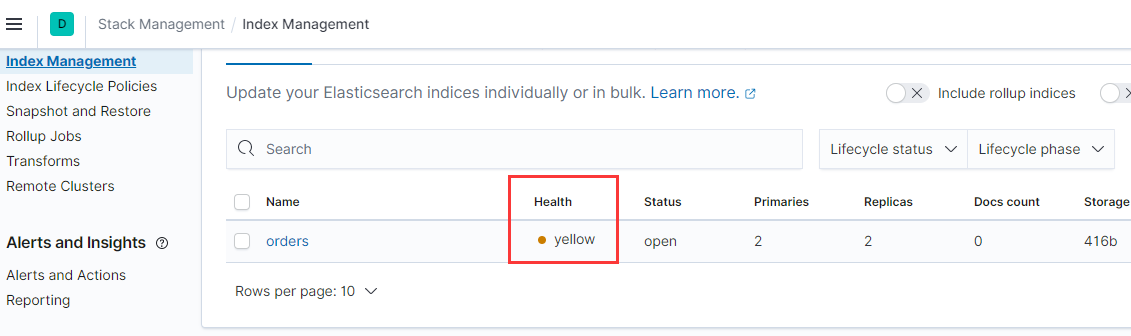
因為單節點模式, 只有主節點信息:
刪除重新創建:
PUT orders
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 0
}
}
}
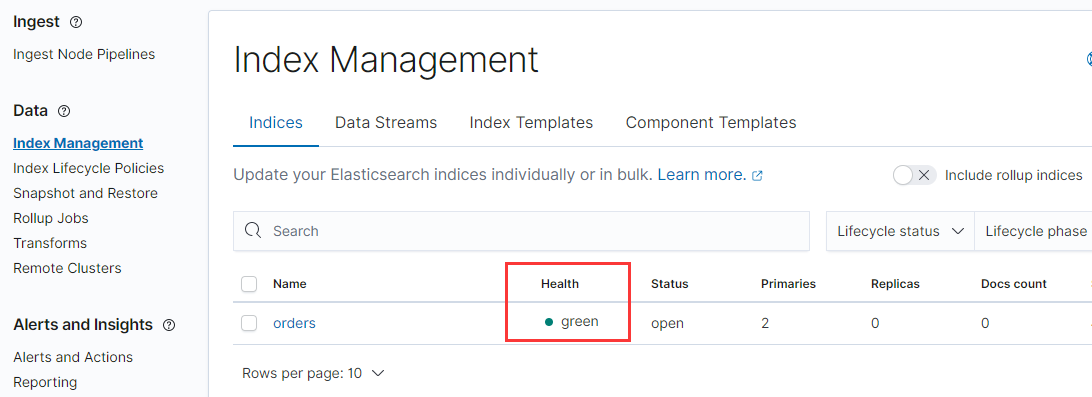
將分片數設為0, 再次查看, 則顯示正常:
-
索引
3.1 新建索引orders
## 創建索引 PUT orders3.2 查詢索引orders
## 查詢索引 GET orders

通過查詢命令, 能查看到對應信息, 預設分片數和副本數都為1:
"number_of_shards" : "1", ## 主分片數
"number_of_replicas" : "1", ## 副分片數
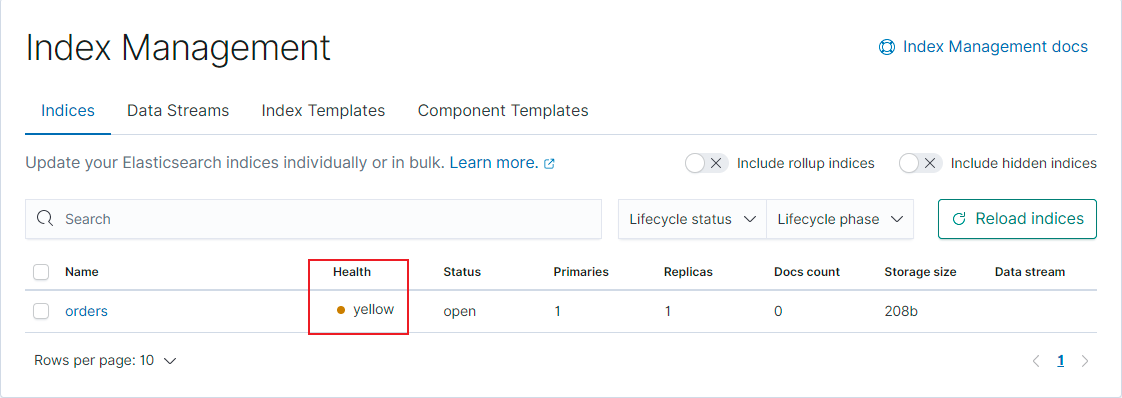
3.3 刪除索引
## 刪除索引
DELETE orders
3.4 索引的設置
## 設置索引
PUT orders
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
}
-
文檔
4.1 創建文檔
## 創建文檔,生成預設的文檔id POST orders/_doc { "name": "襪子1雙", "price": "200", "count": 1, "address": "北京市" } ## 創建文檔,生成自定義文檔id POST orders/_doc/1 { "name": "襪子1雙", "price": "2", "count": 1, "address": "北京市" }4.2 查詢文檔
## 根據指定的id查詢 GET orders/_doc/1 ## 根據指定條件查詢文檔 GET orders/_search { "query": { "match": { "address": "北京市" } } } ## 查詢全部文檔 GET orders/_search4.3 更新文檔
## 更新文檔 POST orders/_doc/1 { "price": "200" } ## 更新文檔 POST orders/_update/1 { "doc": { "price": "200" } }4.4 刪除文檔
## 刪除文檔 DELETE orders/_doc/1 -
域
對於映射,只能進行欄位添加,不能對欄位進行修改或刪除,如有需要,則重新創建映射。
## 設置mapping信息 PUT orders/_mappings { "properties":{ "price": { "type": "long" } } } ## 設置分片和映射 PUT orders { "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0 } }, "mappings": { "properties": { "name": { "type": "text" }, "price": { "type": "long" }, "count": { "type": "long" }, "address": { "type": "text" } } } }
1.5 ES數據類型
整體數據類型結構:
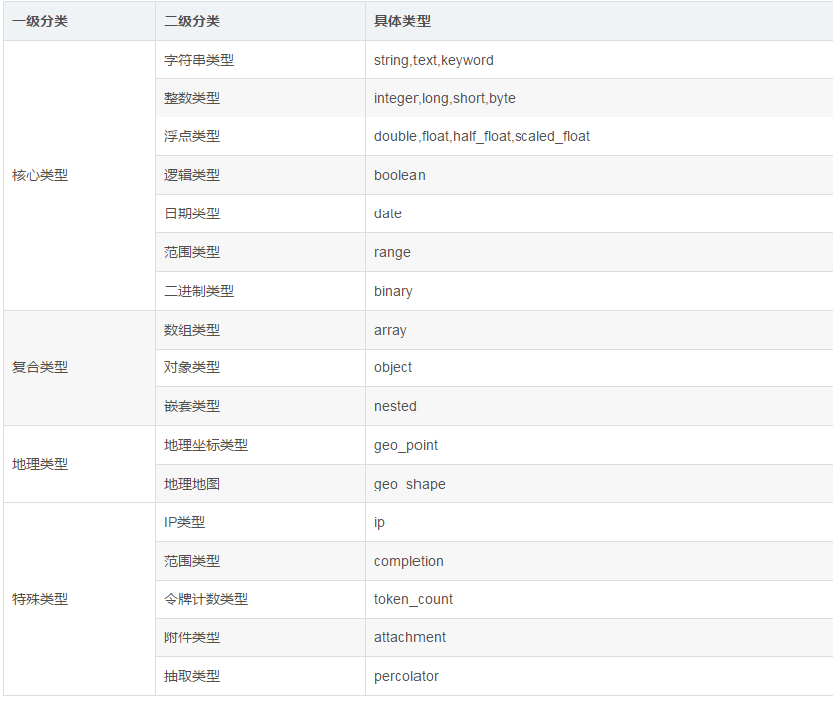
-
String 類型
主要分為text與keyword兩種類型。兩者區別主要在於能否分詞。
-
text類型
會進行分詞處理, 分詞器預設採用的是standard。
-
keyword類型
不會進行分詞處理。在ES的倒排索引中存儲的是完整的字元串。
-
-
Date時間類型
資料庫里的日期類型需要規範具體的傳入格式, ES是可以控制,自適應處理。
傳遞不同的時間類型:
PUT my_date_index/_doc/1 { "date": "2021-01-01" } PUT my_date_index/_doc/2 { "date": "2021-01-01T12:10:30Z" } PUT my_date_index/_doc/3 { "date": 1520071600001 } ## 查看日期數據: GET my_date_index/_mapping
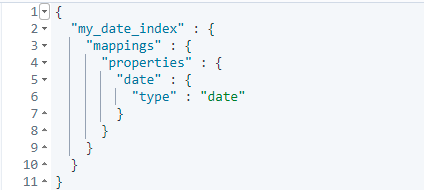
ES的Date類型允許可以使用的格式有:
yyyy-MM-dd HH:mm:ss
yyyy-MM-dd
epoch_millis(毫秒值)
-
複合類型
複雜類型主要有三種: Array、object、nested。
-
Array類型: 在Elasticsearch中,數組不需要聲明專用的欄位數據類型。但是,在數組中的所有值都必須具有相同的數據類型。舉例:
POST orders/_doc/1 { "goodsName":["足球","籃球","兵乓球", 3] } POST orders/_doc/1 { "goodsName":["足球","籃球","兵乓球"] } -
object類型: 用於存儲單個JSON對象, 類似於JAVA中的對象類型, 可以有多個值, 比如LIST
-
Nested類型
用於存儲多個JSON對象組成的數組,
nested類型是object類型中的一個特例,可以讓對象數組獨立索引和查詢。舉例:
創建nested類型的索引:
PUT my_index { "mappings": { "properties": { "users": { "type": "nested" } } } }發出查詢請求:
GET my_index/_search { "query": { "bool": { "must": [ { "nested": { "path": "users", "query": { "bool": { "must": [ { "match": { "users.name": "John" } }, { "match": { "users.age": "21" } } ] } } } } ] } } }採用以前的條件, 這個時候查不到任何結果, 將年齡改成22, 就可以找出對應的數據:
"hits" : [ { "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_score" : 1.89712, "_source" : { "group" : "america", "users" : [ { "name" : "John", "age" : "22" }, { "name" : "Alice", "age" : "21" } ] } } ]
-
GEO地理位置類型
現在大部分APP都有基於位置搜索的功能, 比如交友、購物應用等。這些功能是基於GEO搜索實現的。
對於GEO地理位置類型,分為地理坐標類型:Geo-point, 和形狀:Geo-shape 兩種類型。
經緯度 英文 簡寫 正數 負數 維度 latitude lat 北緯 南緯 經度 longitude lon或lng 東經 西經 創建地理位置索引:
PUT my_locations { "mappings": { "properties": { "location": { "type": "geo_point" } } } }添加地理位置數據:
# 採用object對象類型 PUT my_locations/_doc/1 { "user": "張三", "text": "Geo-point as an object", "location": { "lat": 41.12, "lon": -71.34 } } # 採用string類型 PUT my_locations/_doc/2 { "user": "李四", "text": "Geo-point as a string", "location": "45.12,-75.34" } # 採用geohash類型(geohash演算法可以將多維數據映射為一串字元) PUT my_locations/_doc/3 { "user": "王二麻子", "text": "Geo-point as a geohash", "location": "drm3btev3e86" } # 採用array數組類型 PUT my_locations/_doc/4 { "user": "木頭老七", "text": "Geo-point as an array", "location": [ -80.34, 51.12 ] }需求:搜索出距離我{"lat" : 40,"lon" : -70} 200km範圍內的人:
GET my_locations/_search { "query": { "bool": { "must": { "match_all": {} }, "filter": { "geo_distance": { "distance": "200km", "location": { "lat": 40, "lon": -70 } } } } } }
-
2. ES高可用集群配置
2.1 ElasticSearch集群介紹
-
主節點(或候選主節點)
主節點負責創建索引、刪除索引、分配分片、追蹤集群中的節點狀態等工作, 主節點負荷相對較輕, 客戶端請求可以直接發往任何節點, 由對應節點負責分發和返回處理結果。
一個節點啟動之後, 採用 Zen Discovery機制去尋找集群中的其他節點, 並與之建立連接, 集群會從候選主節點中選舉出一個主節點, 並且一個集群只能選舉一個主節點, 在某些情況下, 由於網路通信丟包等問題, 一個集群可能會出現多個主節點, 稱為“腦裂現象”, 腦裂會存在丟失數據的可能, 因為主節點擁有最高許可權, 它決定了什麼時候可以創建索引, 分片如何移動等, 如果存在多個主節點, 就會產生衝突, 容易產生數據丟失。要儘量避免這個問題, 可以通過 discovery.zen.minimum_master_nodes 來設置最少可工作的候選主節點個數。 建議設置為(候選主節點/2) + 1 比如三個候選主節點,該配置項為 (3/2)+1 ,來保證集群中有半數以上的候選主節點, 沒有足夠的master候選節點, 就不會進行master節點選舉,減少腦裂的可能。
主節點的參數設置:
node.master = true node.data = false -
數據節點
數據節點負責數據的存儲和CRUD等具體操作,數據節點對機器配置要求比較高、,首先需要有足夠的磁碟空間來存儲數據,其次數據操作對系統CPU、Memory和IO的性能消耗都很大。通常隨著集群的擴大,需要增加更多的數據節點來提高可用性。
數據節點的參數設置:
node.master = false node.data = true -
客戶端節點
客戶端節點不做候選主節點, 也不做數據節點的節點,只負責請求的分發、彙總等等,增加客戶端節點類型更多是為了負載均衡的處理。
node.master = false node.data = false -
提取節點(預處理節點)
能執行預處理管道,有自己獨立的任務要執行, 在索引數據之前可以先對數據做預處理操作, 不負責數據存儲也不負責集群相關的事務。
參數設置:
node.ingest = true -
協調節點
協調節點,是一種角色,而不是真實的Elasticsearch的節點,不能通過配置項來指定哪個節點為協調節點。集群中的任何節點,都可以充當協調節點的角色。當一個節點A收到用戶的查詢請求後,會把查詢子句分發到其它的節點,然後合併各個節點返回的查詢結果,最後返回一個完整的數據集給用戶。在這個過程中,節點A扮演的就是協調節點的角色。
ES的一次請求非常類似於Map-Reduce操作。在ES中對應的也是兩個階段,稱之為scatter-gather。客戶端發出一個請求到集群的任意一個節點,這個節點就是所謂的協調節點,它會把請求轉發給含有相關數據的節點(scatter階段),這些數據節點會在本地執行請求然後把結果返回給協調節點。協調節點將這些結果彙總(reduce)成一個單一的全局結果集(gather階段) 。
-
部落節點
在多個集群之間充當聯合客戶端, 它是一個特殊的客戶端 , 可以連接多個集群,在所有連接的集群上執行搜索和其他操作。 部落節點從所有連接的集群中檢索集群狀態並將其合併成全局集群狀態。 掌握這一信息,就可以對所有集群中的節點執行讀寫操作,就好像它們是本地的。 請註意,部落節點需要能夠連接到每個配置的集群中的每個單個節點。
2.2 ElasticSearch集群原理
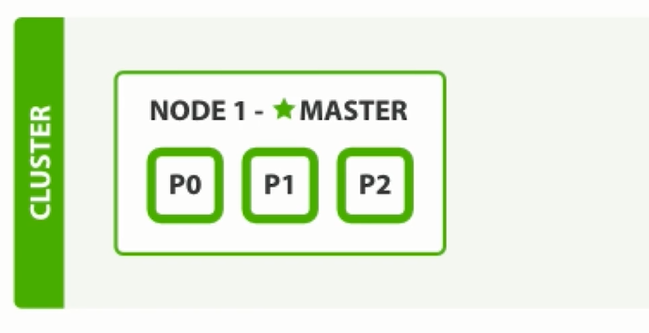
2.2.1 集群分散式原理
ES集群可以根據節點數, 動態調整主分片與副本數, 做到整個集群有效均衡負載。
單節點狀態下:
兩個節點狀態下, 副本數為1:

三個節點狀態下, 副本數為1:
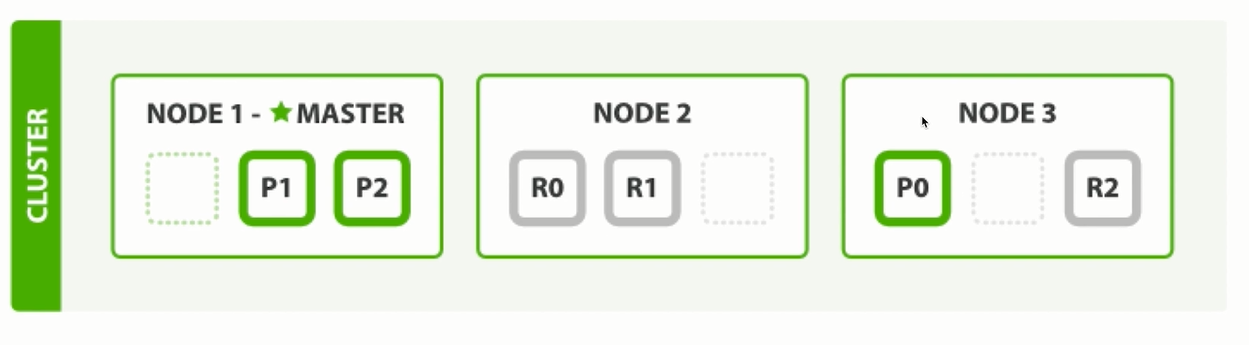
三個節點狀態下, 副本數為2:
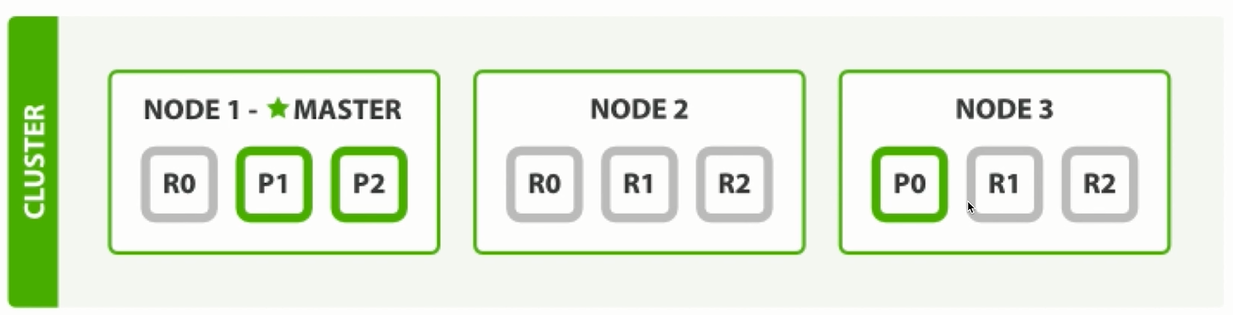
2.2.2 分片處理機制
設置分片大小的時候, 需預先做好容量規劃, 如果節點數過多, 分片數過小, 那麼新的節點將無法分片, 不能做到水平擴展, 並且單個分片數據量太大, 導致數據重新分配耗時過大。
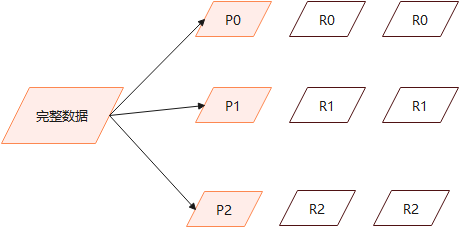
假設一個集群中有一個主節點、兩個數據節點。orders索引的分片分佈情況如下所示:
PUT orders
{
"settings":{
"number_of_shards":2, ## 主分片 2
"number_of_replicas":2 ## 副分片 4
}
}
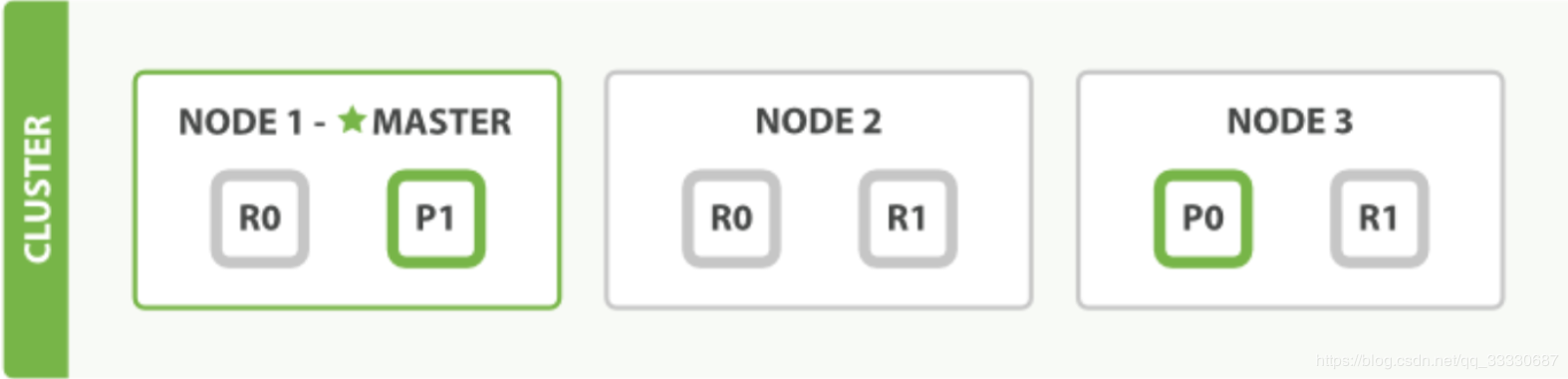
整個集群中存在P0和P1兩個主分片, P0對應的兩個R0副本分片, P1對應的是兩個R1副本分片。
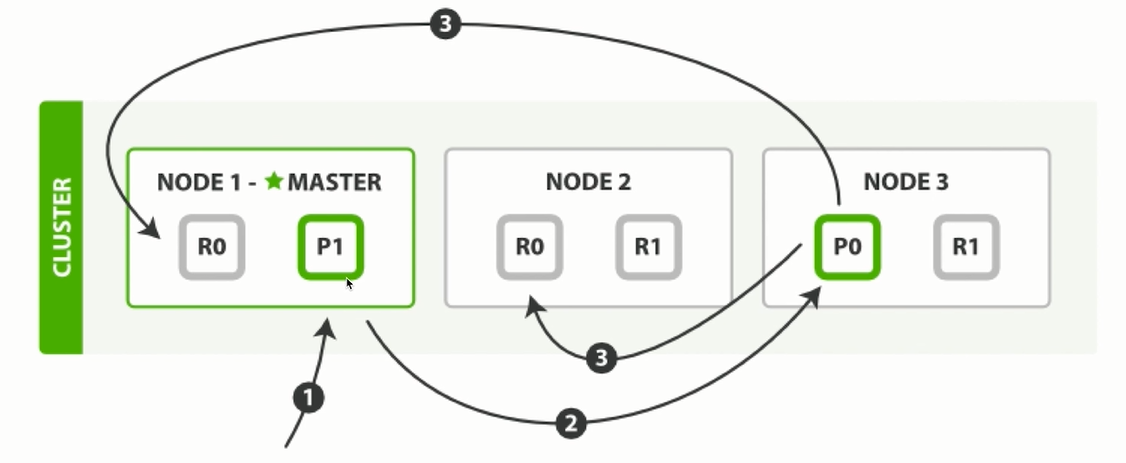
2.2.3 新建索引處理流程
-
寫入的請求會進入主節點, 如果是NODE2副本接收到寫請求, 會將它轉發至主節點。
-
主節點接收到請求後, 根據documentId做取模運算(外部沒有傳遞documentId,則會採用內部自增ID),
如果取模結果為P0,則會將寫請求轉發至NODE3處理。
-
NODE3節點寫請求處理完成之後, 採用非同步方式, 將數據同步至NODE1和NODE2節點。
2.2.4 讀取索引處理流程
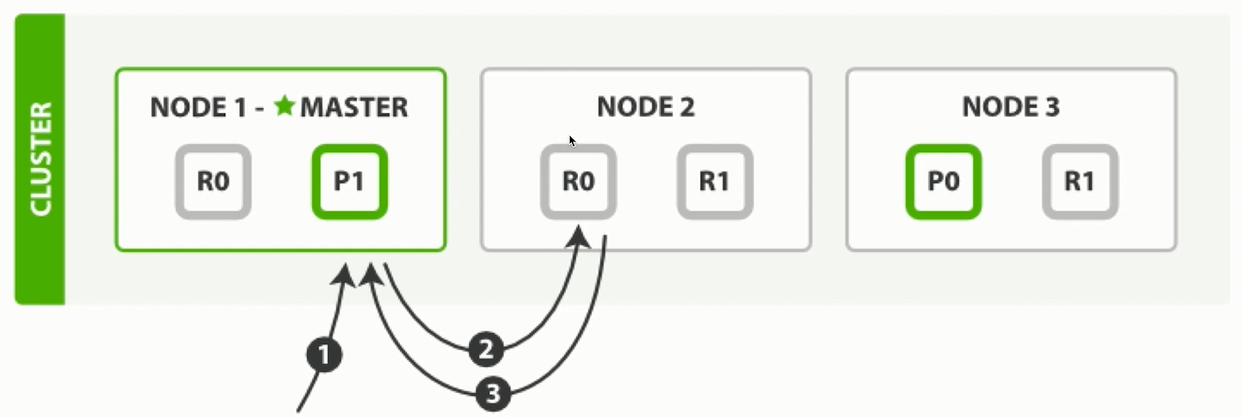
- 讀取的請求進入MASTER節點, 會根據取模結果, 將請求轉發至不同的節點。
- 如果取模結果為R0,內部還會有負載均衡處理機制,如果上一次的讀取請求是在NODE1的R0, 那麼當前請求會轉發至NODE2的R0, 保障每個節點都能夠均衡的處理請求數據。
- 讀取的請求如果是直接落至副本節點, 副本節點會做判斷, 若有數據則返回,沒有的話會轉發至其他節點處理。
2.3 ElasticSearch集群部署規劃
準備一臺虛擬機:
192.168.116.140: Node-1 (節點一), 埠:9200, 9300
192.168.116.140: Node-2 (節點二),埠:9201, 9301
192.168.116.140: Node-3 (節點三),埠:9202, 9302
2.4 ElasticSearch集群配置
-
解壓安裝包:
mkdir /usr/local/cluster cd /usr/local/cluster tar -xvf elasticsearch-7.10.2-linux-x86_64.tar.gz將安裝包解壓至/usr/local/cluster目錄。
-
修改集群配置文件:
vi /usr/local/cluster/elasticsearch-7.10.2-node1/config/elasticsearch.yml192.168.116.140, 第一臺節點配置內容:
# 集群名稱 cluster.name: my-application #節點名稱 node.name: node-1 # 綁定IP地址 network.host: 192.168.116.140 # 指定服務訪問埠 http.port: 9200 # 指定API端戶端調用埠 transport.tcp.port: 9300 #集群通訊地址 discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"] #集群初始化能夠參選的節點信息 cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"] #開啟跨域訪問支持,預設為false http.cors.enabled: true ##跨域訪問允許的功能變數名稱, 允許所有功能變數名稱 http.cors.allow-origin: "*"修改目錄許可權:
chown -R elsearch:elsearch /usr/local/cluster/elasticsearch-7.10.2-node1 -
複製ElasticSearch安裝目錄:
複製其餘兩個節點:
cd /usr/local/cluster cp -r elasticsearch-7.10.2-node1 elasticsearch-7.10.2-node2 cp -r elasticsearch-7.10.2-node1 elasticsearch-7.10.2-node3 -
修改其餘節點的配置:
192.168.116.140 第二台節點配置內容:
# 集群名稱 cluster.name: my-application #節點名稱 node.name: node-2 # 綁定IP地址 network.host: 192.168.116.140 # 指定服務訪問埠 http.port: 9201 # 指定API端戶端調用埠 transport.tcp.port: 9301 #集群通訊地址 discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"] #集群初始化能夠參選的節點信息 cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"] #開啟跨域訪問支持,預設為false http.cors.enabled: true ##跨域訪問允許的功能變數名稱, 允許所有功能變數名稱 http.cors.allow-origin: "*"192.168.116.140 第三台節點配置內容:
# 集群名稱 cluster.name: my-application #節點名稱 node.name: node-3 # 綁定IP地址 network.host: 192.168.116.140 # 指定服務訪問埠 http.port: 9202 # 指定API端戶端調用埠 transport.tcp.port: 9302 #集群通訊地址 discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"] #集群初始化能夠參選的節點信息 cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"] #開啟跨域訪問支持,預設為false http.cors.enabled: true ##跨域訪問允許的功能變數名稱, 允許所有功能變數名稱 http.cors.allow-origin: "*" -
啟動集群節點
先切換elsearch用戶, 在三台節點依次啟動服務:
su elsearch /usr/local/cluster/elasticsearch-7.10.2-node1/bin/elasticsearch -d /usr/local/cluster/elasticsearch-7.10.2-node2/bin/elasticsearch -d /usr/local/cluster/elasticsearch-7.10.2-node3/bin/elasticsearch -d註意: 如果啟動出現錯誤, 將各節點的data目錄清空, 再重啟服務。
-
集群狀態查看
集群安裝與啟動成功之後, 執行請求: http://192.168.116.140:9200/_cat/nodes?pretty
可以看到三個節點信息,三個節點會自行選舉出主節點:

2.5 ElasticSearch集群分片測試
修改kibana的配置文件,指向創建的集群節點:
elasticsearch.hosts: ["http://192.168.116.140:9200","http://192.168.116.140:9201","http://192.168.116.140:9202"]
重啟kibana服務, 進入控制台:
http://192.168.116.140:5601/app/home#/
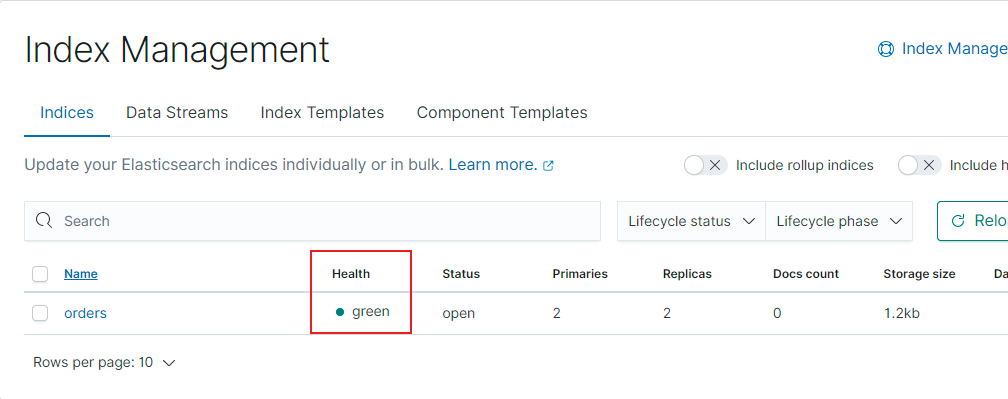
再次創建索引(副本數量範圍內):
PUT orders
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 2
}
}
}
可以看到, 這次結果是正常:
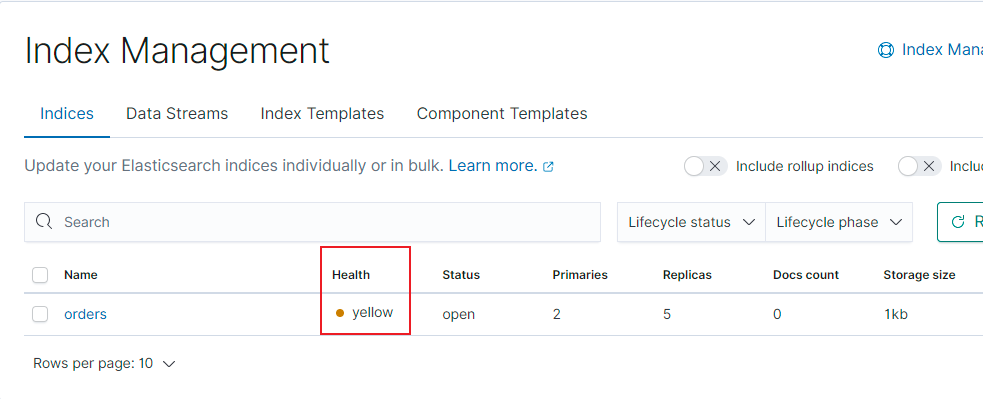
集群並非可以隨意增加副本數量, 創建索引(超出副本數量範圍):
PUT orders
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 5
}
}
}
可以看到出現了yellow警告錯誤:
好了,至此ES集群搭建完畢,歡迎志同道合的小伙伴,一起交流學習成長。進階架構師,Fighting!!!
本文由傳智教育博學谷 - 狂野架構師教研團隊發佈
如果本文對您有幫助,歡迎關註和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力
轉載請註明出處!

