
主題、分區與副本 基本概念 主題、分區和副本的關係 主題是一個邏輯概念,代表了一類消息,實際工作中我們使用主題來區分業務,而主題之下並不是消息,而是分區,分區是一個物理概念,它是磁碟上的一個目錄,目錄中是保存消息的日誌段文件。分區的目的是為了提高吞吐量,實現主題的負載均衡,一個主題至少有一個分區;而 ...
主題、分區與副本
基本概念
主題、分區和副本的關係
主題是一個邏輯概念,代表了一類消息,實際工作中我們使用主題來區分業務,而主題之下並不是消息,而是分區,分區是一個物理概念,它是磁碟上的一個目錄,目錄中是保存消息的日誌段文件。分區的目的是為了提高吞吐量,實現主題的負載均衡,一個主題至少有一個分區;而故障轉移這個功能就放在了副本上,一個分區至少有一個副本,一個分區的所有副本原則上其數據是一致的且分佈在不同的broker上,這樣其中某一個broker故障那麼其他的broker可以繼續提供針對該分區的數據讀寫。
主題的名稱是用戶自己設定,分區名稱是主題名稱-分區編號,其中分區編號從0開始而且用戶不可能自己設置。副本數量由用戶設置。前面說過分區是存放消息的物理文件,那麼消息也會被分配一個序列號,該序列號從0開始單調遞增。
副本的類型
上面我們知道副本的作用是防止數據丟失,那麼當有多個副本的時候這些副本都提供服務麽?在Kafka的機制里副本並不都對外提供服務,它分為兩類:Leader和Follower。前者對外提供讀寫服務後者只被動的從Leader副本同步數據。所以通過這裡我們就可以回答一個問題就是3台Kafka集群,所有伺服器都是活躍的不存在主從之分,伺服器是否對外提供讀寫服務完全取決於所持有的副本類型,如果是Leader則提供,如果是Follower則不提供。
Kafka會儘量保證所有副本不在同一臺機器上,但是如果副本數量大於集群機器數量那麼就無法保證了。

上面這個主題就是3個分區,每個分區有3個副本。橫向來看就是
Partition:0 這個分區當前的Leader副本在Broker.id為0的機器上
Replicas:1,0,2 表示副本有3個,以及這些副本都在哪些broker上
Isr:1,0,2 表示該集合中的所有副本的數據都與Leader副本保持同步狀態。意味著只要Isr中存在一個活著的副本那麼生產者已提交的數據就不會丟失,如果Isr中的某些副本落後Leader副本那麼該落後的副本就會被移出。
副本與ISR
我們知道副本就是備份,Kafka會儘量把分區的副本均衡的放在不同broker上,並從中挑選一個作為Leader副本來對外提供讀寫服務,那麼其他的就是Follower副本,而這些Follower副本保持與Leader副本的數據同步。
為什麼Kafka只能讓Leader副本提供讀寫操作呢?因為這樣可以實現所寫即所得,都是從Leader副本讀寫,所以寫入數據後,消費者就可以馬上讀取;另外就是單調讀,尤其是在副本數量多的時候,不會出現某些副本有這個數據,某些副本沒有。所以這就是只讓Leader副本提供讀寫操作的好處。
假如當前的Leader副本所在主機宕機,那麼Kafka集群就要從剩餘的Follower副本中重新挑選一個副本作為新的Leader副本,那麼顯然不是所有的Follower副本都具有競選資格,如果某些Follower副本數據落後太多那麼它們則不能成為Leader副本。所以這就有了ISR的概念。
ISR就是Kafka動態維護的一組同步副本集合,每個主題的分區都有自己的ISR列表,ISR中的所有副本都與Leader保持同步狀態,而且Leader副本也在ISR列表中,只有在ISR列表中的副本才有這個被選中為Leader。

不過這裡有人可能會糊塗,broker的id是從0、1、2,這裡的Isr也是0、1、2這三個數字,那麼Replicas和Isr中的數字表示的是broker的id呢還是分區的編號。下麵我們修改一下集群中的broker的id,不過這種操作線上上可不建議使用。我們要把log.dirs目錄中的數據刪除,然後修改配置文件,然後再啟動。
我們這裡建立一個新的主題叫做TestBBB

可以看到無論是Replicas還是Isr顯示的都是broker的id,而不是分區編號。下麵我們說一下ISR是怎麼同步的呢?
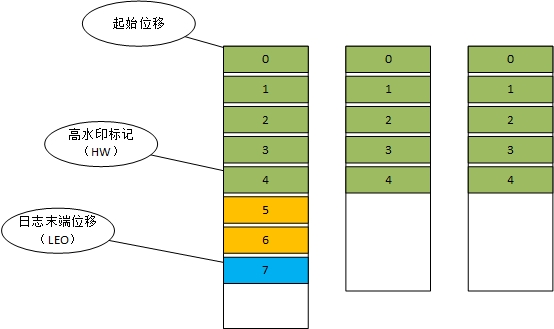
起始位移:表示副本中第一條消息的位置
高水位標記:表示副本最新一條被提交的消息的位置,這個值決定了客戶端可以讀取到的消息最大範圍,超過高水位標記的消息【5、6】屬於未提交消息,客戶端讀取不到。
日誌末端位移:表示下一條待寫入消息的位移,也就是說LEO指向的位置是沒有消息的。當寫入一條消息LEO會加1.
以上三個位移無論是在Leader副本還是Follower副本都具有。而分區的HW值就是Leader副本的HW值。並且Leader副本所在的broker上還保存了Follower副本的HW和LEO水位值。
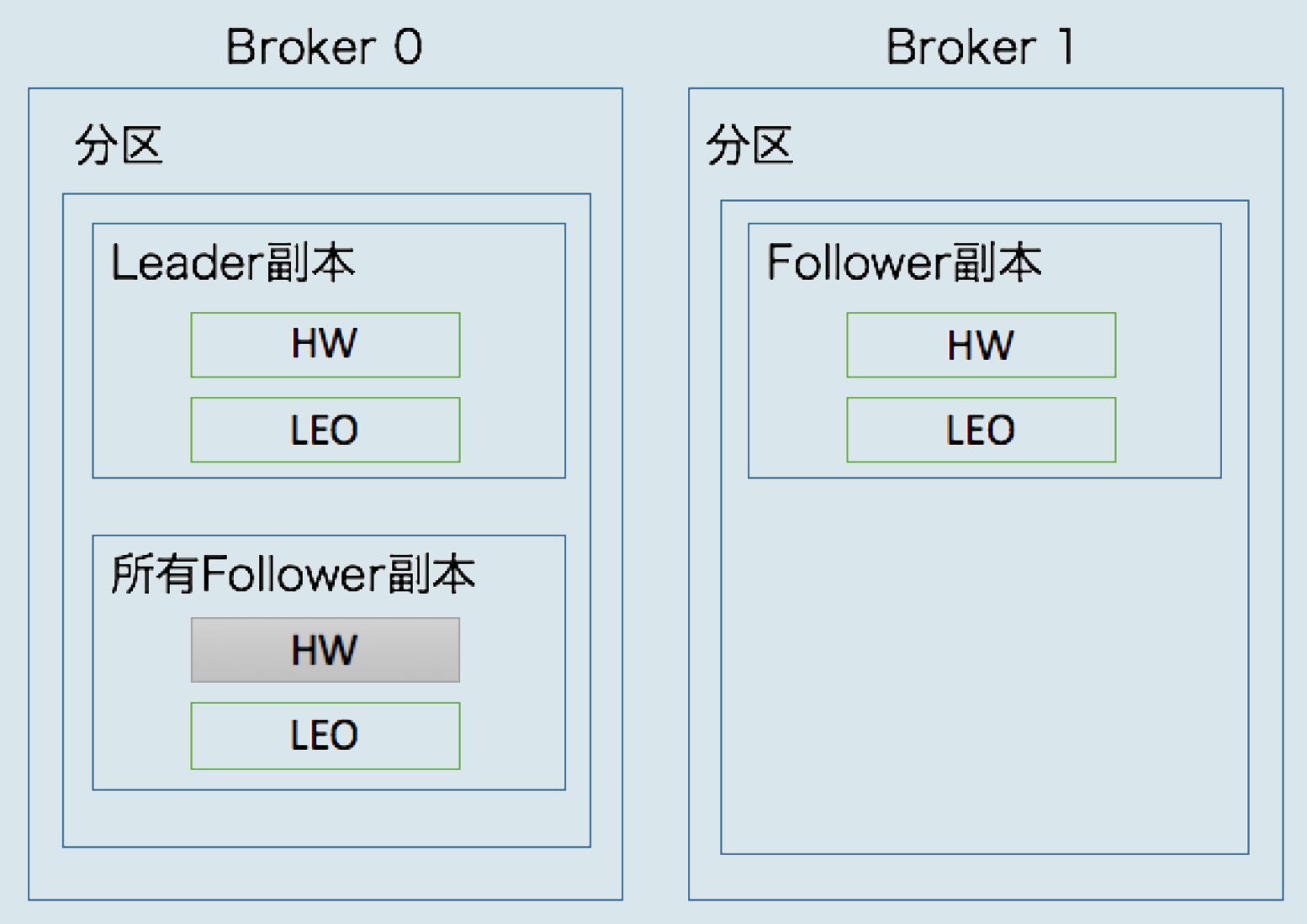
何時更新LEO值
從上圖看到Leader副本所在broker上保存了所有Follower副本的HW和LEO值,同時Follower副本所在broker也保存了自己的HW和LEO。
生產者向Leader副本寫入數據,那麼Leader的LEO值就會增加;Follower向Leader拉取數據並寫入自己的日誌文件時Follower的LEO也會增加。
在Leader的broker上保存的Follower副本的LEO值是在Leader收到Follower的拉取數據請求之後和真正發送數據給Follower之前進行更新的,而且來拉取的時候Follower會發送自己的HW值,Leader上保存的Follower副本的LEO值就是Follower拉取數據時發送過來的自己的HW值。
何時更新HW值
Follower收到數據然後就要寫入日誌,之後就要更新自己的LEO值,更新完成後再去更新自己的HW值,原則就是Leader發送過來的數據中包含Leader自己的HW,所以Follower在更新完自己的LEO之後嘗試更新自己的HW的時候會比較Leader的HW和自己的LEO哪個最小,它取最小值來設置自己的HW值。
Leader更新自己的HW發生在:
-
生產者寫入新的消息,Leader更新了自己的LEO後嘗試更新自己的HW
-
Leader從日誌中讀取了數據併發送給Follower之後嘗試更新自己的HW
上面都是嘗試更新,而不是一定更新,因為更新原則是取Leader副本的LEO和它所保存的所有Follower副本的LEO的最小值為Leader副本的HW值。比如在初始狀態(LEO為0、HW為0,保存的Follower的LEO也為0)下如果寫入一條消息雖然Leader更新了自己的LEO為1,而此時保存的的Follower的LEO為0,取最小值就是0,所以HW也是0,故不需要更新。
上述機制由於有時間差問題導致Follower需要進行兩輪拉取才能完成HW的更新,所以會出現數據丟失情況,所以在0.11版本中引入了Leader Epoch機制來解決。
如何判定不同步
這裡就有一個問題,如何被認定ISR中的副本落後Leader太久呢也就是判斷不同步的標準是什麼?0.9版本之前是按照消息個數來做的,0.9之後是時間,預設是10秒,如果一個Follower副本落後Leader的時間持續超過10秒則該Follower被認為不是同步的。
主題和分區的日常管理
創建主題
kafka-topics.sh --bootstrap-server 172.16.100.10:9092 --create --topic TestCCC --partitions 3 --replication-factor 3
列出所有主題
kafka-topics.sh --list --bootstrap-server 172.16.100.10:9092
查看主題詳情
kafka-topics.sh --describe --bootstrap-server 172.16.100.10:9092 --topic TestCCC
刪除主題
kafka-topics.sh --delete --bootstrap-server 172.16.100.10:9092 --topic TestCCC
這隻是標記主題為刪除,因為它是一個非同步操作,如果發現某些時候刪除了主題但是其ZK中的節點包括磁碟數據還都在,你可以手動清理一下:
刪除ZK中/admin/delete_topics下的需要刪除的主題名稱
手動刪除磁碟上的該主題分區目錄
在ZK中執行 rmr /controller 來觸發Controller的重新選舉,這一步要慎重因為它會造成大規模Leader重新選舉,不過只執行前兩步也行,只是Controller中的緩存沒有更新而已。
修改主題的分區數量
kafka-topics.sh --bootstrap-server 172.16.100.10:9092 --alter --topic TestCCC --partitions 4
只支持增加分區數量,不支持減少。
說明:這裡你可能發現命令中使用的都是 --bootstrap-server而不是之前的--zookeeper參數,因為使用--bootstrap-server是目前操作kafka的標準方式,而且也會經過kafka的安全體系。
這隻是標記主題為刪除,因為它是一個非同步操作,如果發現某些時候刪除了主題但是其ZK中的節點包括磁碟數據還都在,你可以手動清理一下:
刪除ZK中/admin/delete_topics下的需要刪除的主題名稱
手動刪除磁碟上的該主題分區目錄
在ZK中執行 rmr /controller 來觸發Controller的重新選舉,這一步要慎重因為它會造成大規模Leader重新選舉,不過只執行前兩步也行,只是Controller中的緩存沒有更新而已。
修改主題的分區數量
kafka-topics.sh --bootstrap-server 172.16.100.10:9092 --alter --topic TestCCC --partitions 4
只支持增加分區數量,不支持減少。
說明:這裡你可能發現命令中使用的都是 --bootstrap-server而不是之前的--zookeeper參數,因為使用--bootstrap-server是目前操作kafka的標準方式,而且也會經過kafka的安全體系。


