
分享嘉賓:張鴻志博士 美團 演算法專家 編輯整理:廖媛媛 美的集團 出品平臺:DataFunTalk **導讀:**美團作為中國最大的線上本地生活服務平臺,連接著數億用戶和數千萬商戶,其背後蘊含著豐富的與日常生活相關的知識。美團知識圖譜團隊從2018年開始著力於圖譜構建和利用知識圖譜賦能業務,改善用戶 ...
分享嘉賓:張鴻志博士 美團 演算法專家
編輯整理:廖媛媛 美的集團
出品平臺:DataFunTalk
導讀:美團作為中國最大的線上本地生活服務平臺,連接著數億用戶和數千萬商戶,其背後蘊含著豐富的與日常生活相關的知識。美團知識圖譜團隊從2018年開始著力於圖譜構建和利用知識圖譜賦能業務,改善用戶體驗。具體來說,“美團大腦”是通過對美團業務中千萬數量級的商家、十億級別的商品和菜品、數十億的用戶評論和百萬級別的場景進行深入的理解來構建用戶、商戶、商品和場景之間的知識關聯,進而形成的生活服務領域的知識大腦。目前,“美團大腦”已經覆蓋了數十億實體、數百億的三元組,在餐飲、外賣、酒店、到綜等領域驗證了知識圖譜的有效性。今天我們介紹美團大腦中生活服務知識圖譜的構建及應用,主要圍繞以下3個方面展開:
- “美團大腦”簡介
- 標簽圖譜構建及應用
- 菜品知識圖譜構建技術
--
01 “美團大腦”簡介
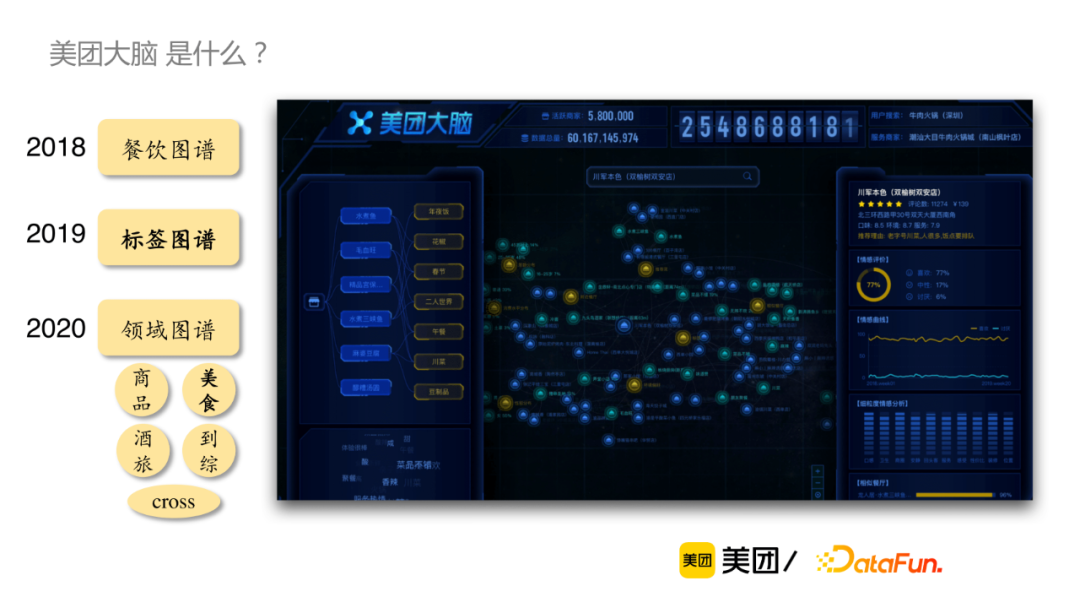
“美團大腦”是什麼?
以下是“美團大腦”構建的整體RoadMap,最先是2018年開始餐飲知識圖譜構建,對美團豐富的結構化數據和用戶行為數據進行初步挖掘,併在一些重要的數據維度上進行深入挖掘,比如說對到餐的用戶評論進行情感分析。2019年,以標簽圖譜為代表,重點對非結構化的用戶評論進行深入挖掘。2020年以後,開始結合各領域特點,逐個領域展開深度數據挖掘和建設,包括商品、美食、酒旅和到綜和cross圖譜等。
--
02 標簽圖譜構建及應用
1. 標簽知識圖譜介紹
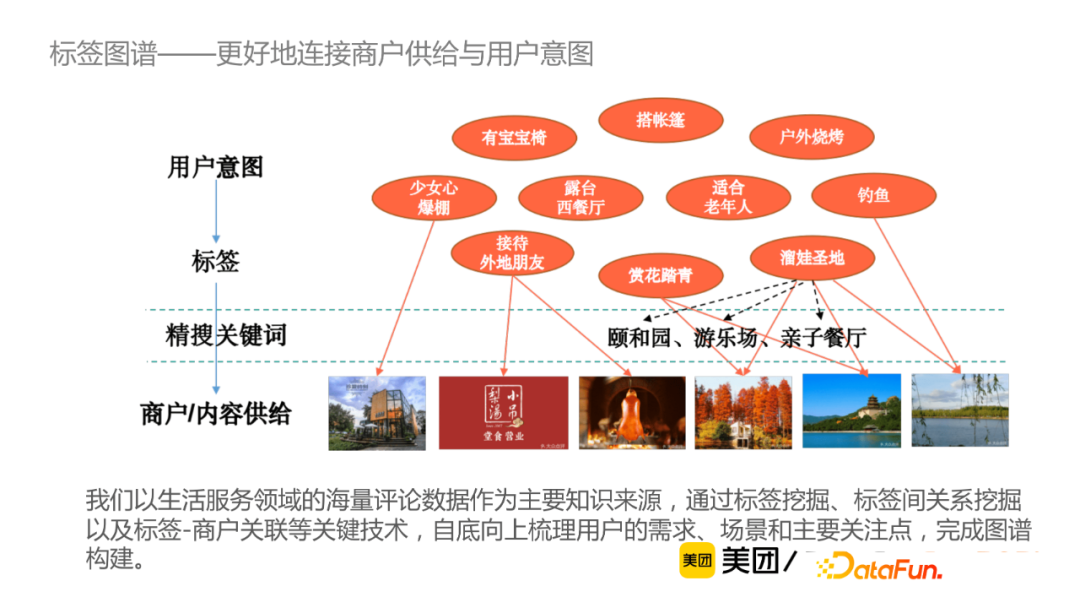
在搜索中,通常用戶需要將其意圖抽象為搜索引擎能夠支持的一系列精搜關鍵詞。標簽知識圖譜則是通過“標簽”來承載用戶需求,從而提升用戶搜索體驗。例如,通過標簽知識圖譜,用戶可直接搜索“帶孩子”或者“情侶約會”,就可返回合適的商戶/內容供給。從信息增益角度來說,用戶評論這種非結構化文本蘊含了大量的知識(比如某個商戶適合的場景、人群、環境等),通過對非結構化數據的挖掘實現信息增益。該團隊以生活服務領域的海量評論數據作為主要知識來源,通過標簽挖掘、標簽間關係挖掘以及標簽-商戶關聯等關鍵技術,自下而上梳理用戶需求,場景及主要關註點完成圖譜構建。
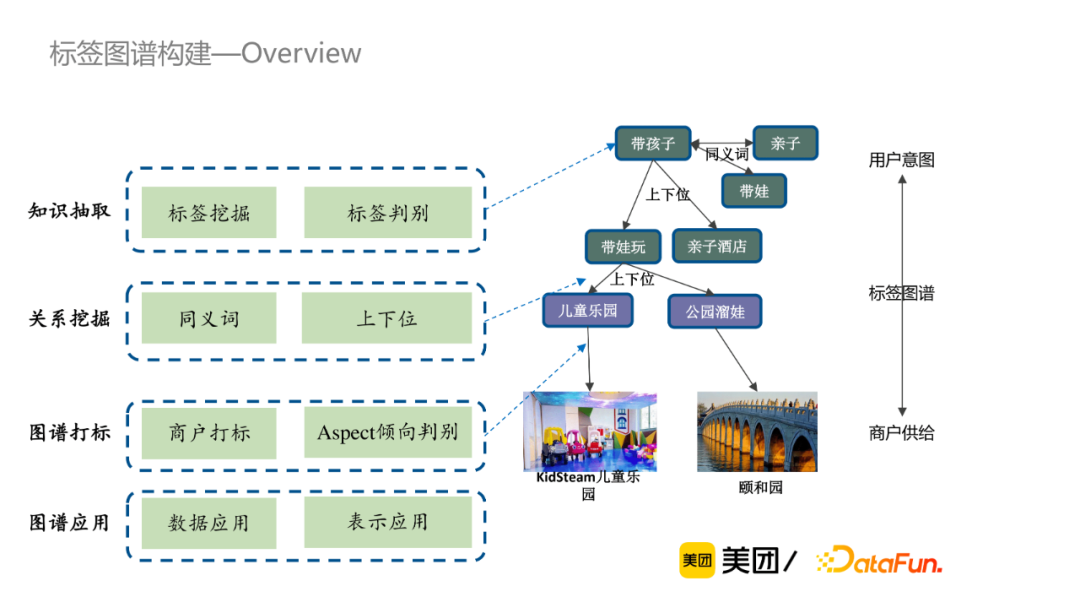
2. 標簽知識圖譜構建
標簽知識圖譜構建分為以下四個部分:知識抽取、關係挖掘、圖譜打標和圖譜應用。
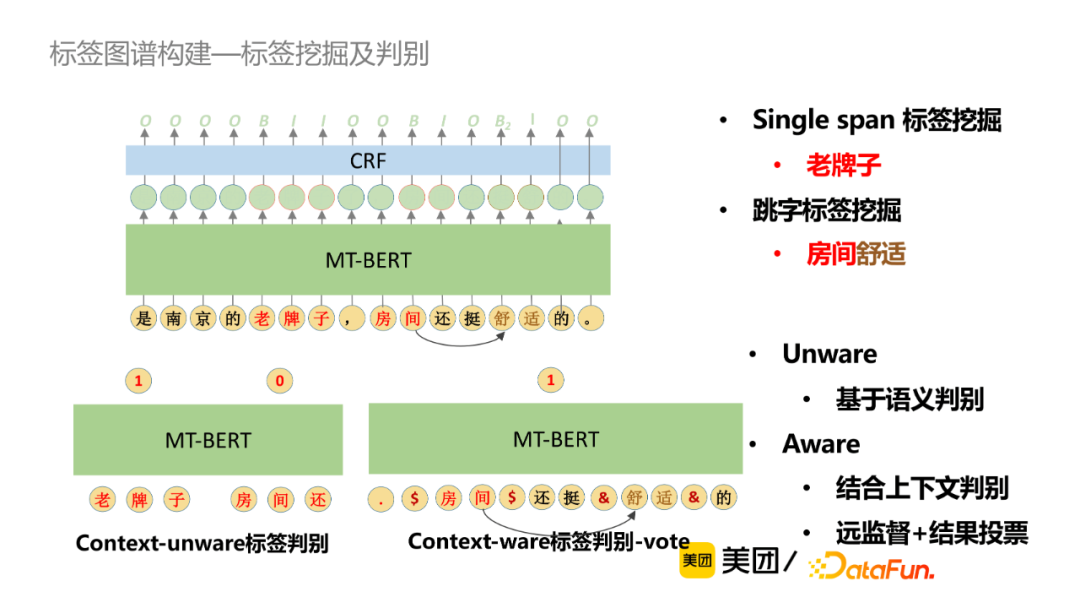
① 知識抽取
標簽挖掘採用簡單的序列標註架構,包括Single span標簽挖掘和跳字標簽挖掘,此外還會結合語義判別或者上下文判別,採用遠監督學習+結果投票方式獲取更精準的標簽。
② 關係挖掘
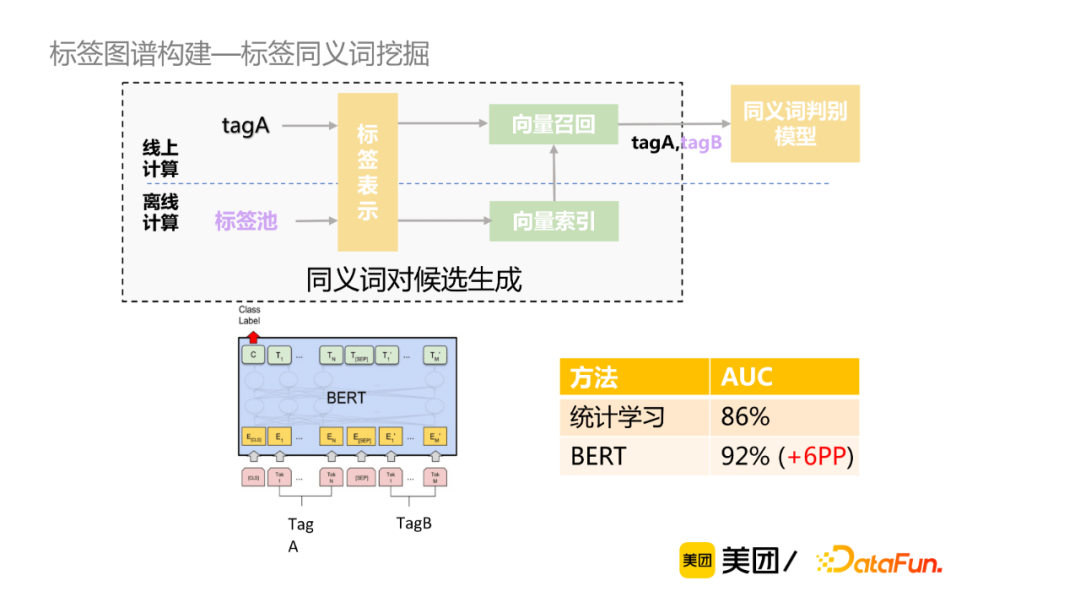
同義詞挖掘:同義詞挖掘被定義為給定包含N個詞的池子,M個業務標簽詞,查找M中每個詞在N中的同義詞。現有的同義詞挖掘方法包括搜索日誌挖掘、百科數據抽取、基於規則的相似度計算等,缺乏一定的通用性。當前我們的目標是尋找通用性強,可廣泛應用到大規模數據集的標簽同義詞挖掘方法。
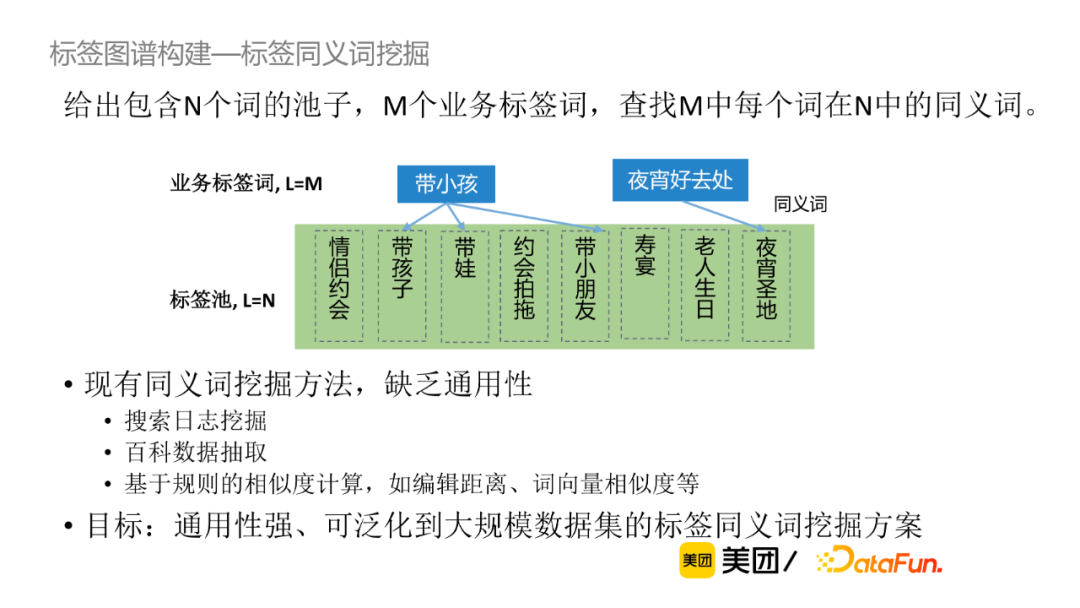
以下是作者給出的同義詞挖掘的具體方案,首先將離線標簽池或者線上查詢標簽進行向量表示獲取向量索引,再進行向量哈希召回,進一步生成該標簽的TopN的同義詞對候選,最後使用同義詞判別模型。該方案的優勢在於降低了計算複雜度,提升了運算效率;對比倒排索引候選生成,可召回字面無overlap的同義詞,準確率高,參數控制簡單。
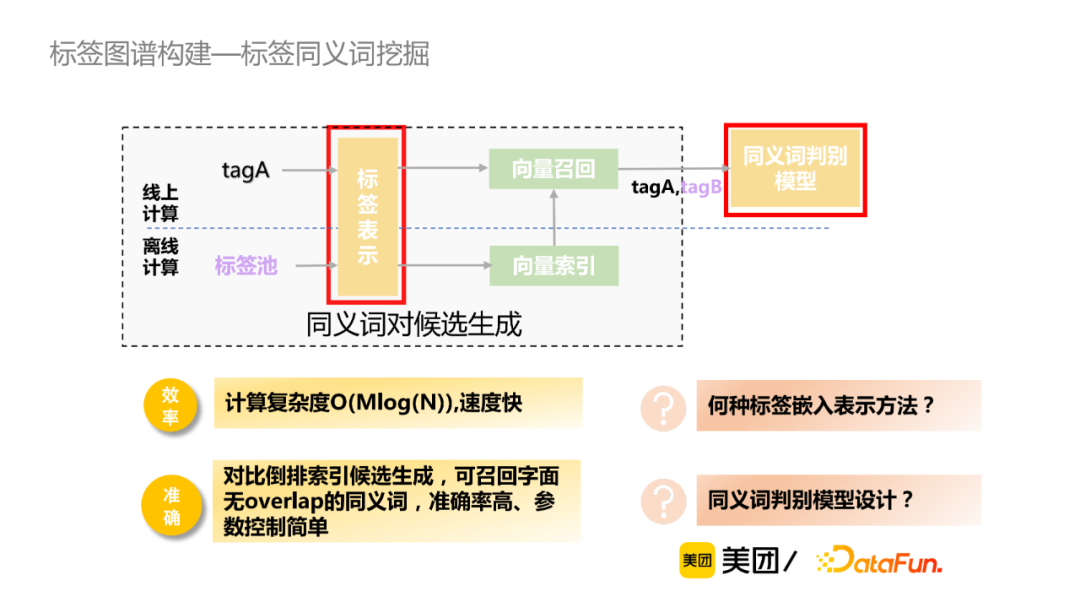
對於有標註數據,主流的標簽詞嵌入表示方法有word2vec、BERT等。word2vec方法實現較為簡單,詞向量取均值,忽略了詞的順序;BERT通過預訓練過程中能捕捉到更為豐富的語義表示,但是直接取[CLS]標誌位向量,其效果與word2vec相當。Sentence-Bert對於Bert模型做了相應的改進,通過雙塔的預訓練模型分別獲取標簽tagA和tagB表徵向量,然後通過餘弦相似性度量這兩個向量的相似性,由此獲取兩個標簽的語義相似性。
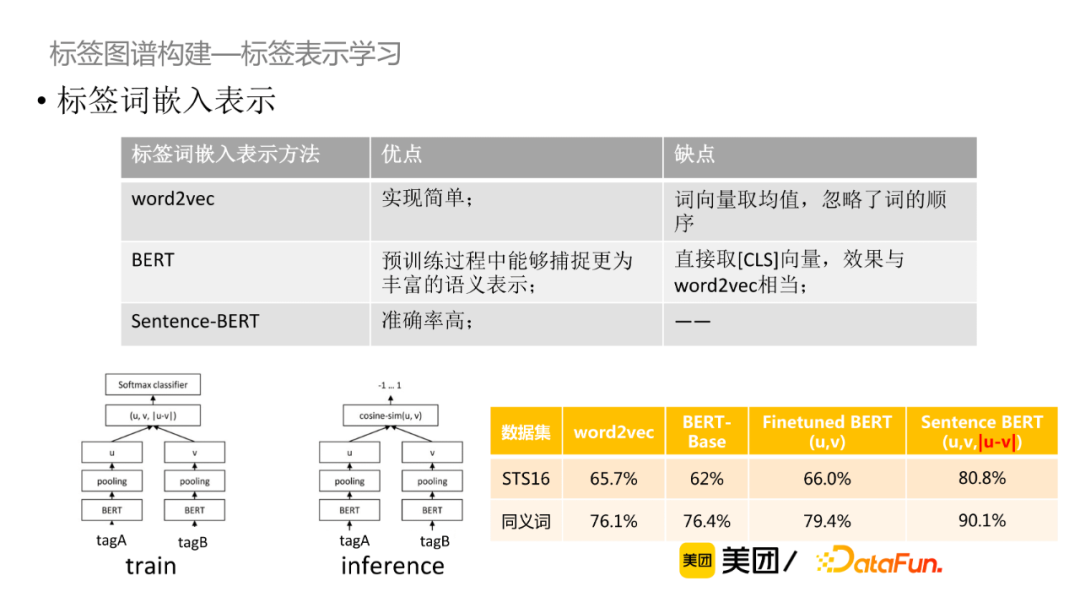
對於無標註數據來說,可以通過對比學習的方法獲取句子的表示。如圖所示,Bert原始模型對於不同相似度的句子的向量相似度都很高,經過對比學習的調整之後,向量的相似度能夠較好地體現出文本相似度。
對比學習模型設計:首先給定一個sentence,對這個樣本做擾動產生樣本pair,常規來說,在embedding層加上Adversarial Attack、在辭彙級別做Shuffling或者丟掉一些詞等構成pair;在訓練的過程中,最大化batch內同一樣本的相似度,最小化batch內其他樣本的相似度。最終結果顯示,無監督學習在一定程度上能達到監督學習的效果,同時無監督學習+監督學習相對於監督學習效果有顯著提升。
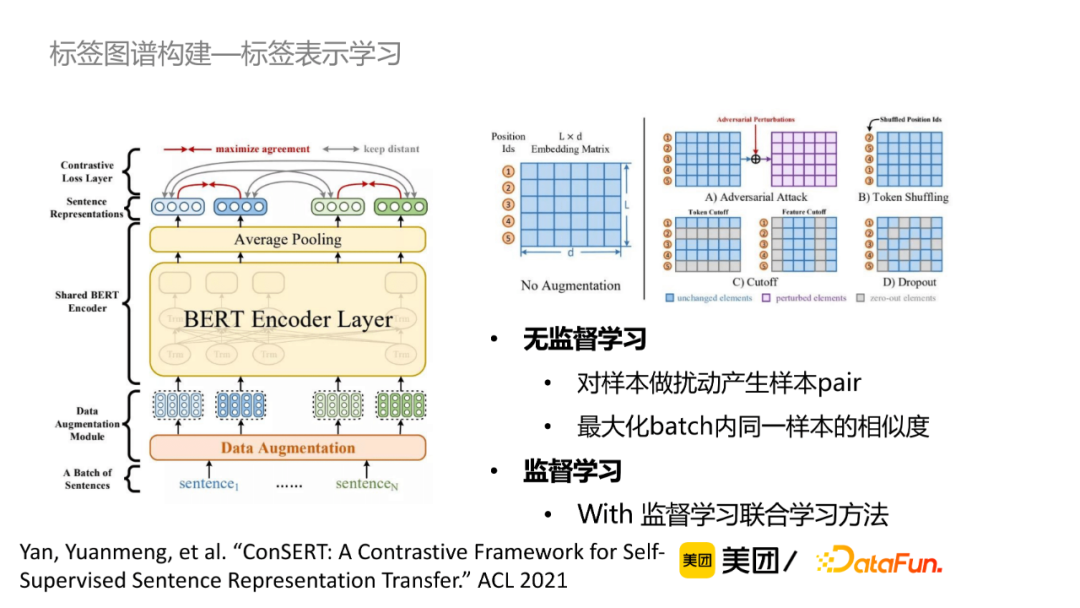
同義詞判別模型設計:將兩個標簽詞拼接到Bert模型中,通過多層語義交互獲取標簽。
標簽上下位挖掘:辭彙包含關係是最重要的上下位關係挖掘來源,此外也可通過結合語義或統計的挖掘方法。但當前的難點是上下位的標準較難統一,通常需要結合領域需求,對演算法挖掘結果進行修正。

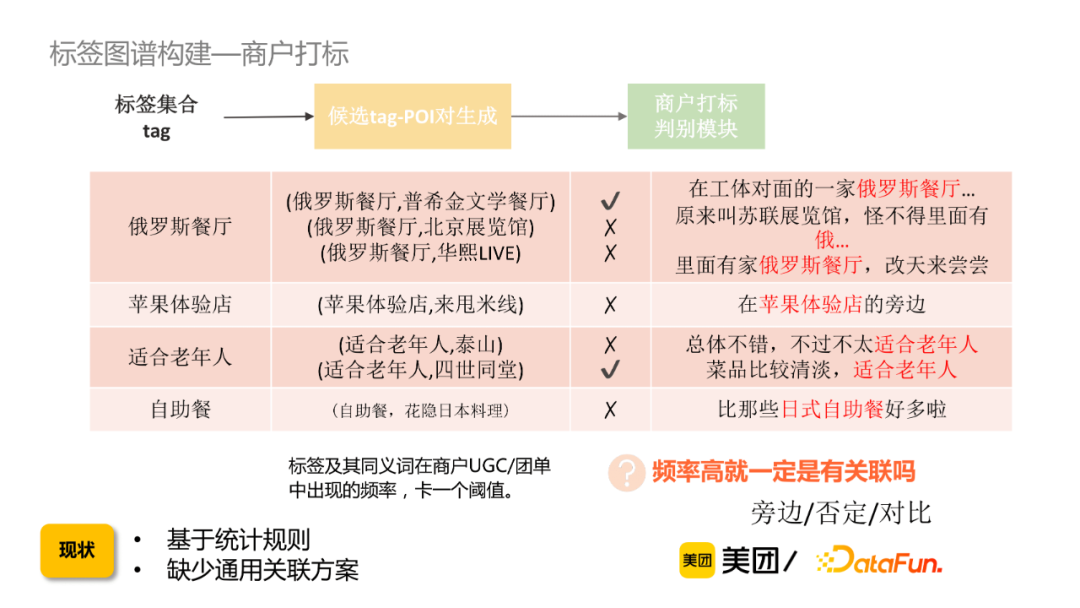
③ 圖譜打標:如何構建標簽和商戶供給的關聯關係?
給定一個標簽集合,通過標簽及其同義詞在商戶UGC/團單里出現的頻率,卡一個閾值從而獲取候選tag-POI。這樣會出現一個問題是,即使是頻率很高但不一定有關聯,因此需要通過一個商戶打標判別模塊去過濾bad case。
商戶打標考慮標簽與商戶、用戶評論、商戶Taxonomy等三個層次的信息。具體來講,標簽-商戶粒度,將標簽與商戶信息(商戶名、商戶三級類目、商戶top標簽)做拼接輸入到Bert模型中做判別。
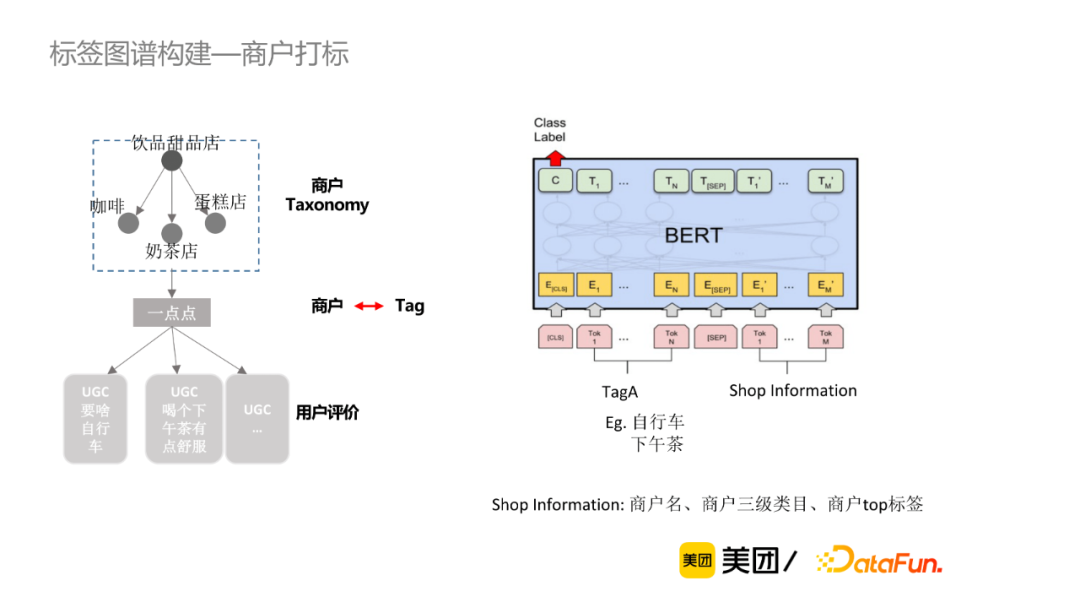
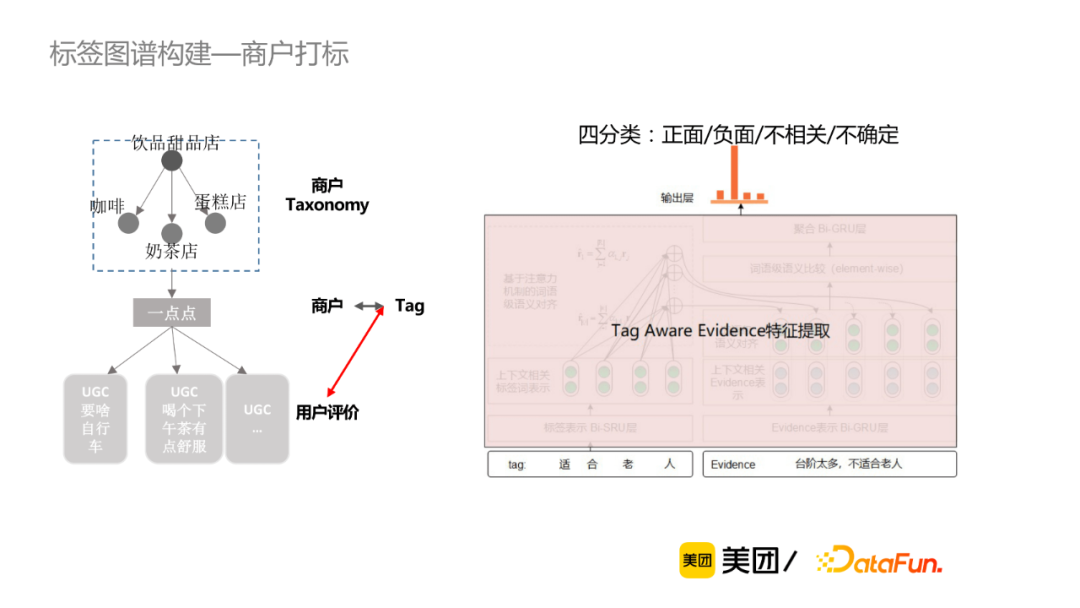
微觀的用戶評論粒度,判斷每一個標簽與提到該標簽的評論(稱為evidence)之間是正面、負面、不相關還是不確定的關係,因此可當作四分類的判別模型。我們有兩種方案可選擇,第一種是基於多任務學習的方法, 該方法的缺點在於新增標簽成本較高,比如新增一個標簽,必須為該標簽新增一些訓練數據。筆者最終採用的是基於語義交互的判別模型,將標簽作為參數輸入,使該模型能夠基於語義判別,從而支持動態新增標簽。
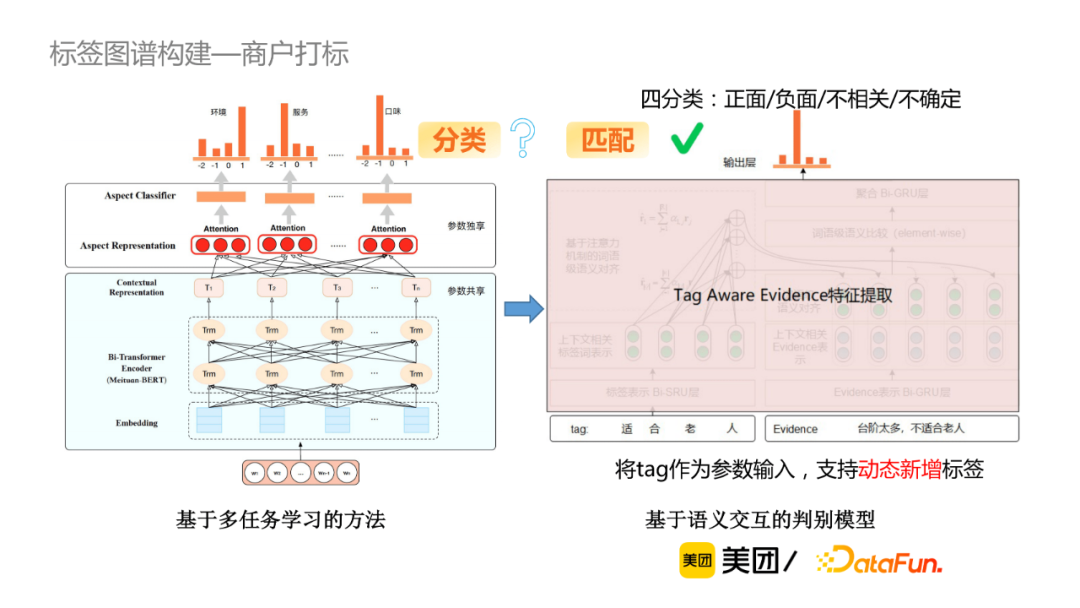
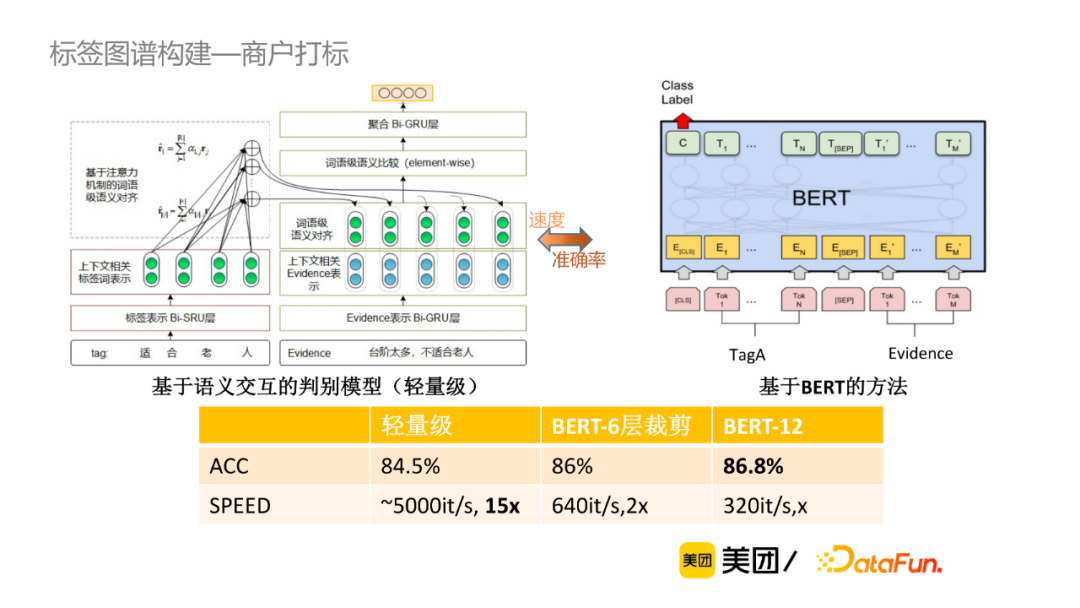
基於語義交互的判別模型,首先做向量表示,然後是交互,最終聚合比較結果,該方法的計算速度較快,而基於BERT的方法,計算量大但準確率較高。我們在準確率和速度上取balance,例如當POI有30多條的evidence,傾向於使用輕量級的方式;如果POI只有幾條evidence,可以採用準確率較高的方式進行判別。
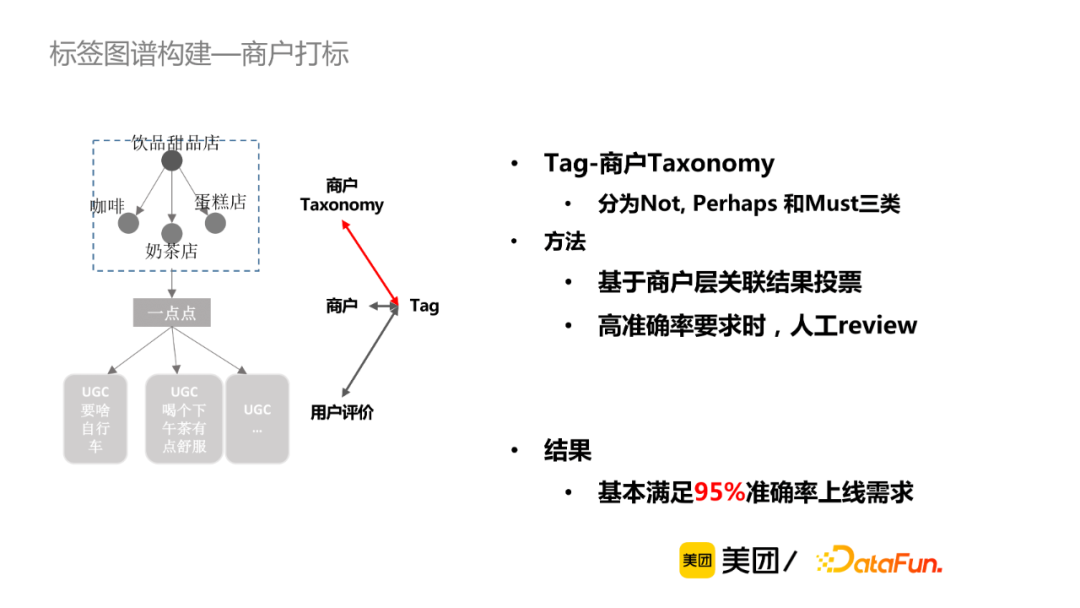
從巨集觀角度,主要看標簽和類目是否匹配,主要有三種關係:一定不會,可能會,一定會。一般通過商戶層關聯結果進行投票結果,同時會增加一些規則,對於準確率要求較高時,可進行人工review。
④ 圖譜應用:所挖掘數據的直接應用或者知識向量表示應用
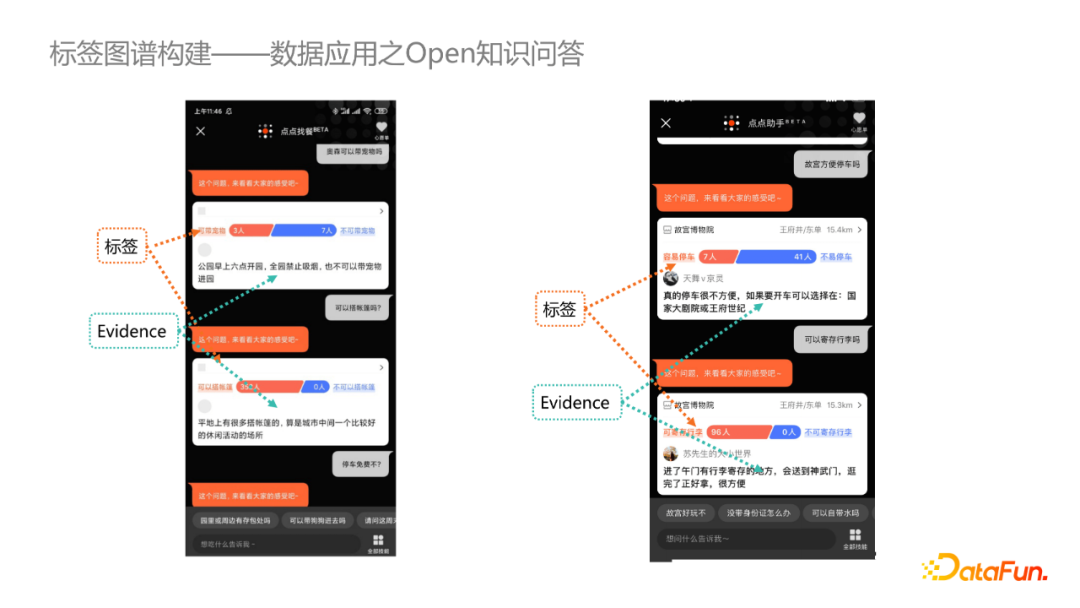
- Open知識問答
在商戶知識問答相關的場景,我們基於商戶打標結果以及標簽對應的evidence回答用戶問題。
- 搜索召回/排序
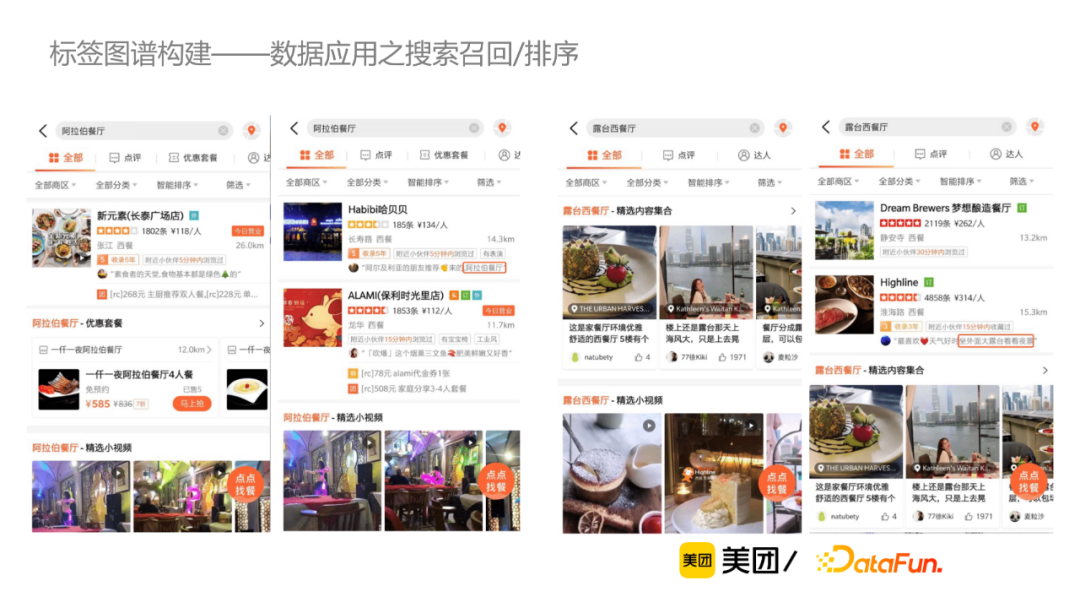
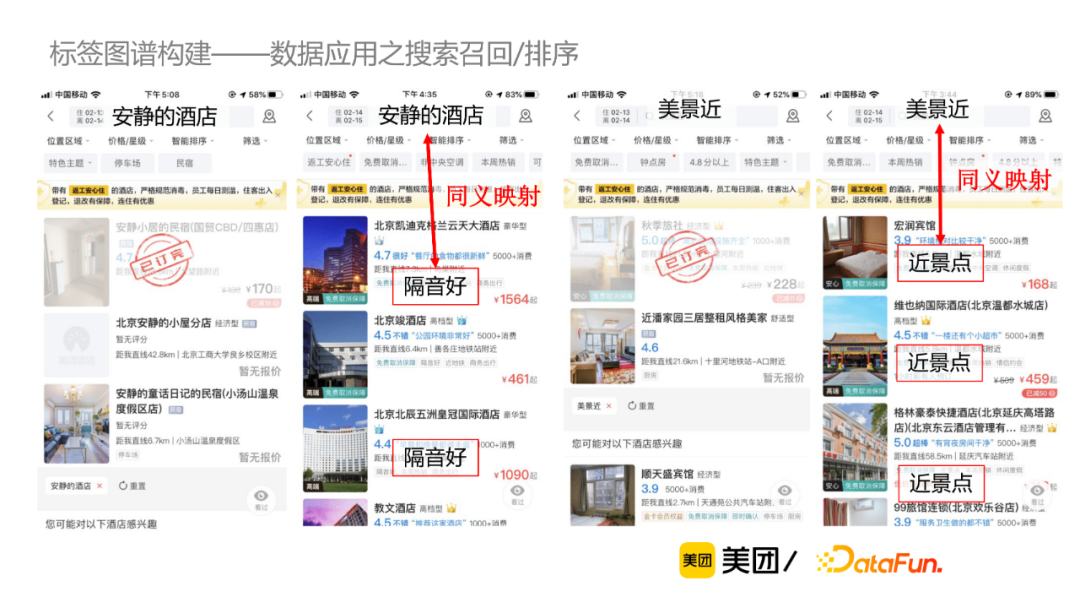
首先識別用戶query中的標簽並映射為id,然後通過搜索召回或者排序層透傳給索引層,從而召回出有打標結果的商戶,並展示給C端用戶。A/B實驗表明,用戶的長尾需求搜索體驗得到顯著提升。此外,也在酒店搜索領域做了一些上線實驗,通過同義詞映射等補充召回手段,搜索結果有明顯改善。
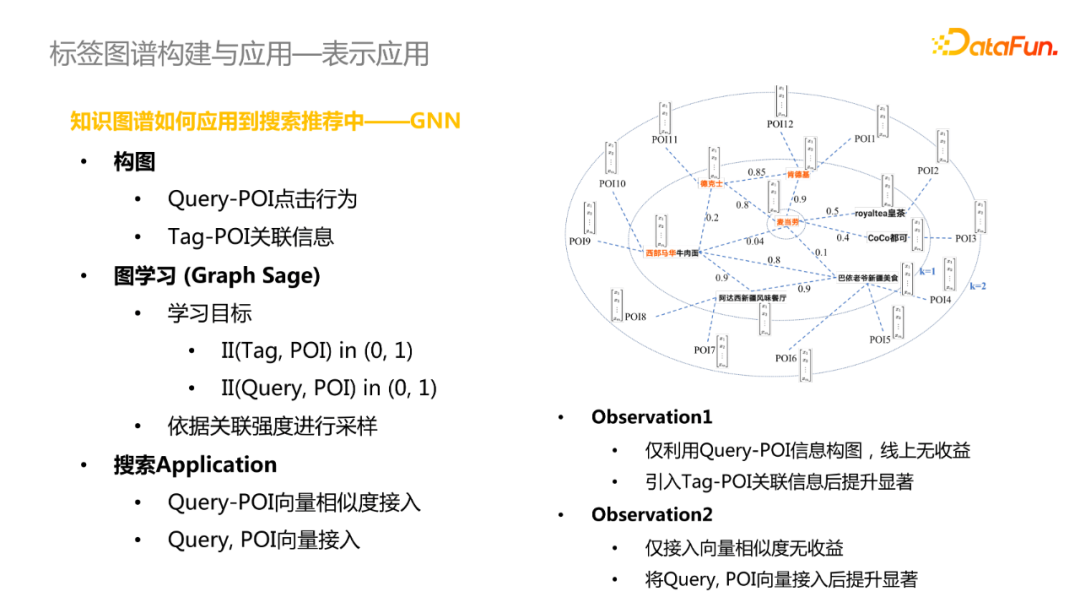
- 表示應用(知識圖譜如何應用到搜索推薦中)
主要採用GNN模型實現,在構圖中構建了兩種邊,Query-POI點擊行為和Tag-POI關聯信息;採用Graph Sage進行圖學習,學習的目標是判斷Tag和POI是否有關聯關係或者Query和POI是否點擊關係,進一步依據關聯強度進行採樣。上線後結果顯示,在僅利用Query-POI信息構圖時,線上無收益,在引入Tag-POI關聯信息後線上效果得到顯著提升。這可能是因為排序模型依賴於Query-POI點擊行為信息去學習,引入Graph Sage學習相當於換了一種學習的方式,信息增益相對較少;引入Tag-POI信息相當於引入了新的知識信息,所以會帶來顯著提升。
此外,僅接入Query-POI向量相似度線上效果提升不佳,將Query和POI向量接入後效果得到顯著提升。這可能是因為搜索的特征維度較高,容易忽略掉向量相似度特征,因此將Query和POI向量拼接進去後提升了特征維度。
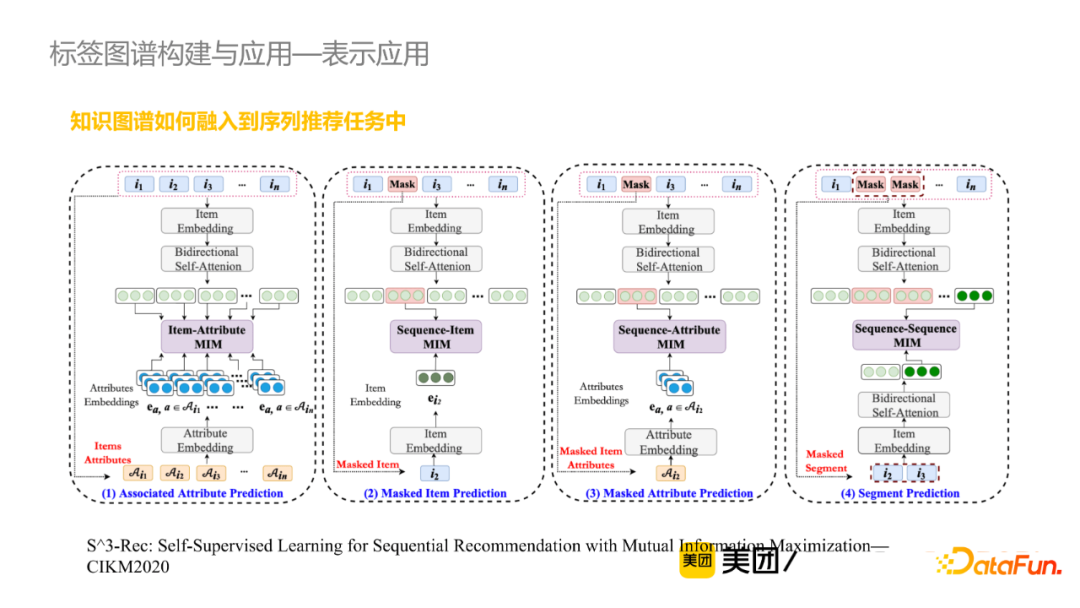
- 表示應用(知識圖譜如何融入到序列推薦任務中)
該任務通過當前已知的Item去預測用戶點擊的Masked Item。比如說獲取Item的上下文表徵的時候,將相關的Attribute信息也進行向量表徵,從而去判斷Item是否有Attribute信息。
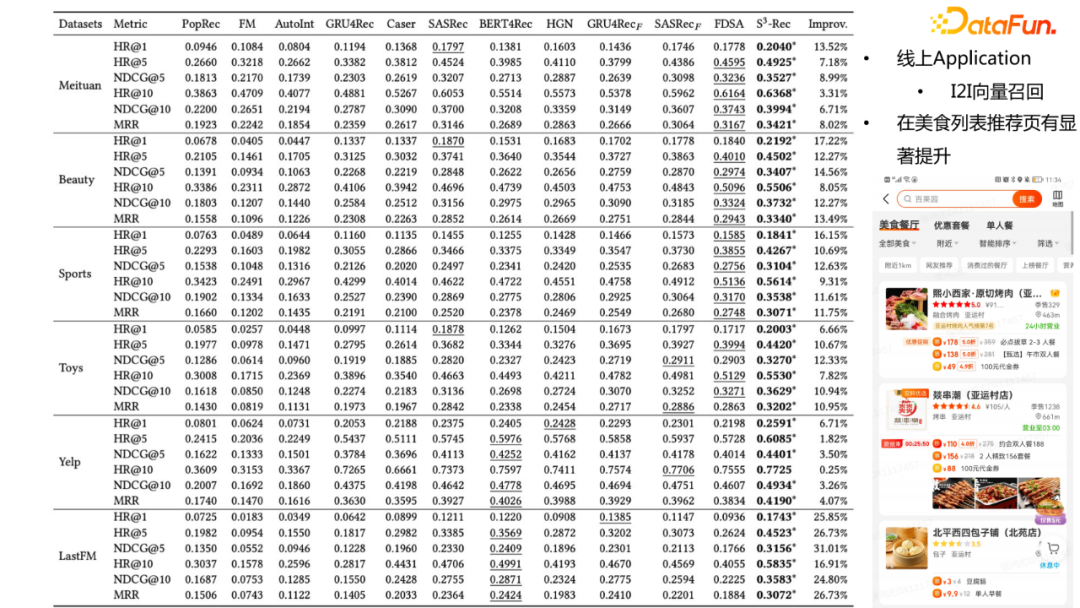
此外,還可以做Masked Item Attribute 預測,從而將標簽的知識圖譜信息融入到序列推薦任務中去。實驗結果表明,引入知識信息後的準確率在不同的數據集上均有數量級的提升。同時,我們也做了線上轉化的工作,將Item表徵做向量召回;具體來說,基於用戶歷史上點擊過的Item去召回topN相似的Item,從而補充線上推薦結果,在美食列表推薦頁有顯著提升。
--
03 標簽圖譜構建與應用
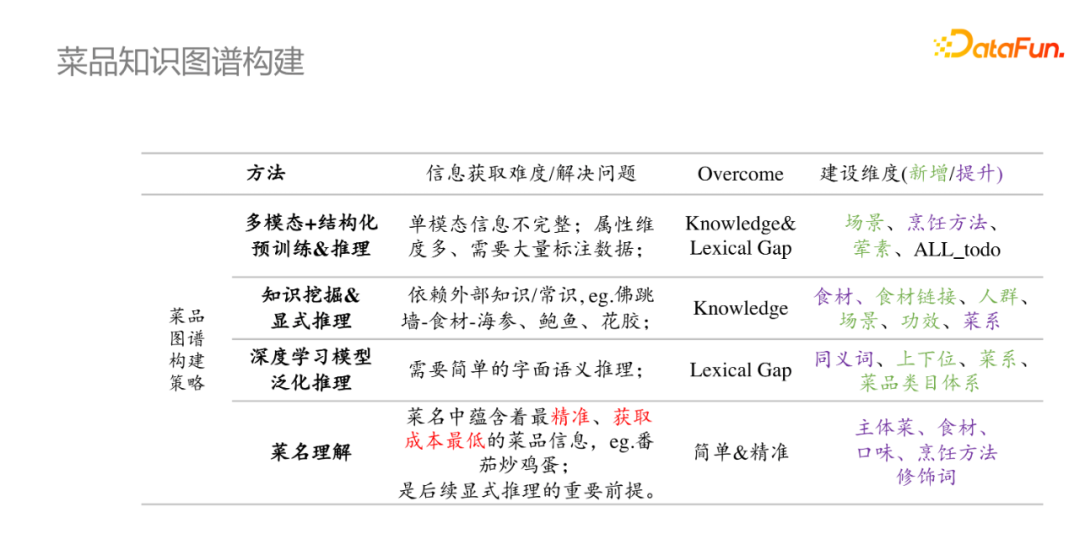
菜品知識圖譜的構建目標,一方面是構建對菜品的系統理解能力,另一方面是構建較為完備的菜品知識圖譜,這裡從不同的層次來說明菜品知識圖譜的構建策略。
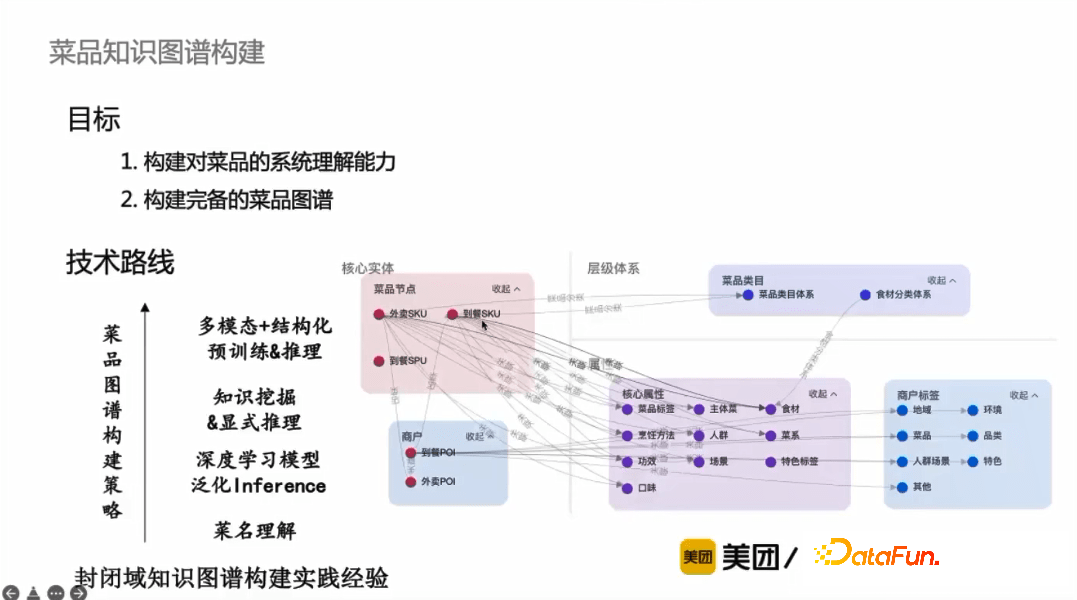
** * 菜名理解**
菜名中蘊含著最精準、獲取成本最低的菜品信息,同時對菜名的理解也是後續顯式知識推理泛化能力的前提。首先是抽取菜名的本質詞/主體菜,然後序列標註去識別菜名中的每個成分。針對兩種場景設計了不同的模型,對於有分詞情況,將分詞符號作為特殊符號添加到模型中,第一個模型是識別每個token對應的類型;對於無分詞情況,需要先做Span-Trans的任務,然後再復用有分詞情況的模塊。

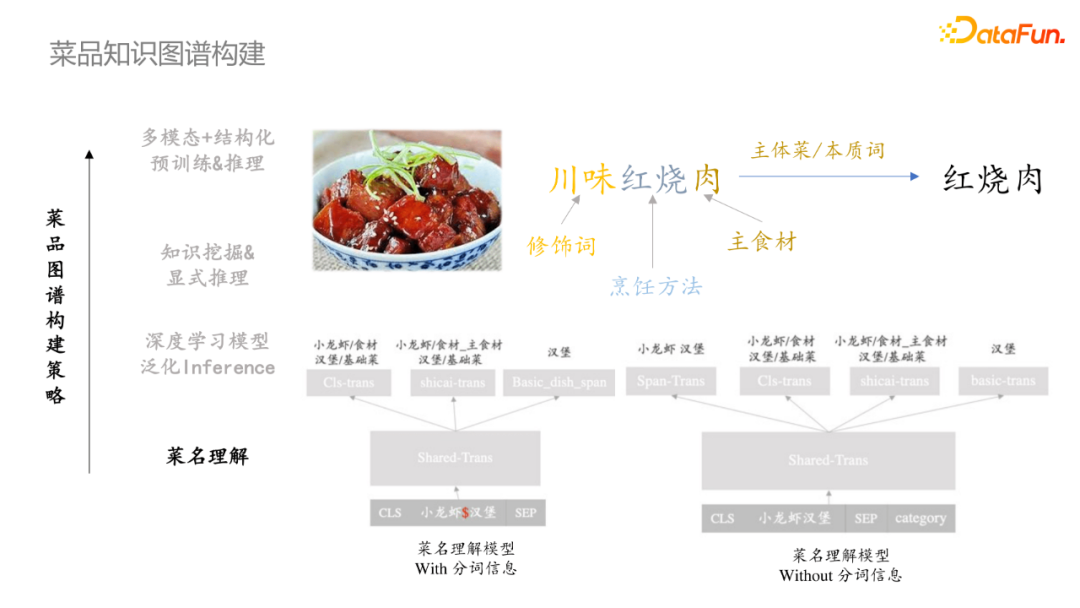
- 深度學習模型泛化Inference
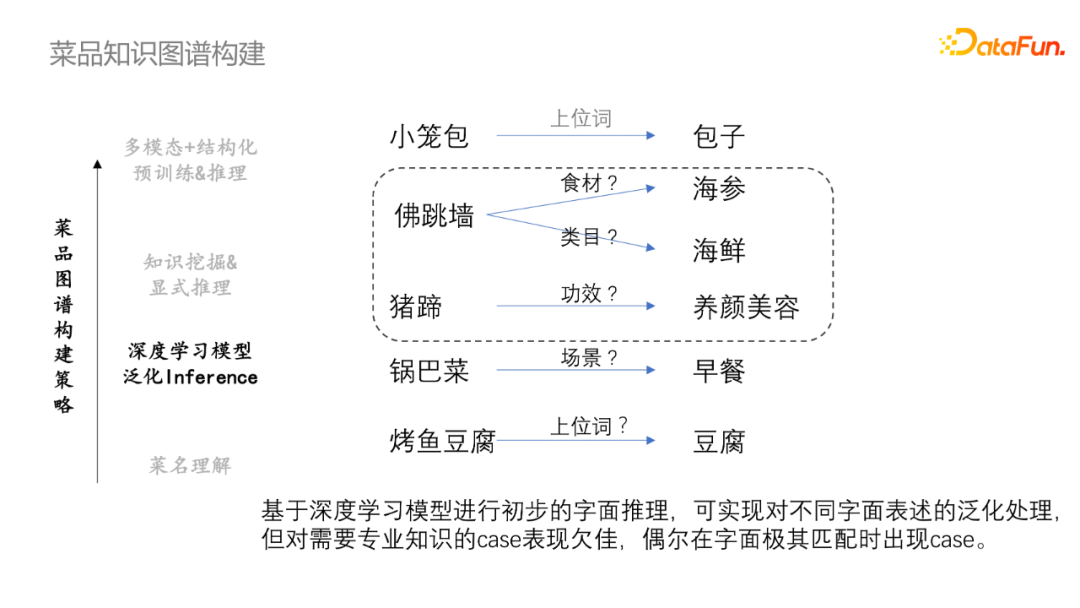
菜名理解是一個較為重要的信息來源,但是所蘊含的知識相對有限,從而提出了基於深度學習模型進行初步字元推斷,可實現對不同字面表述的泛化處理。但是對需要專業知識的case表現欠佳,偶爾在字面極其匹配時出現case。
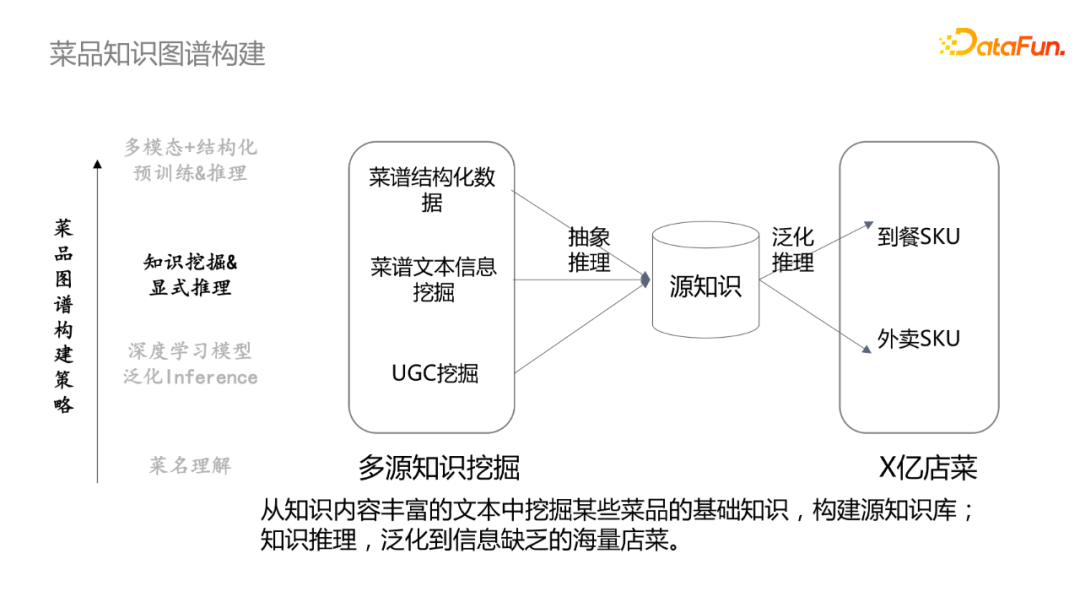
- 知識挖掘&顯式推理
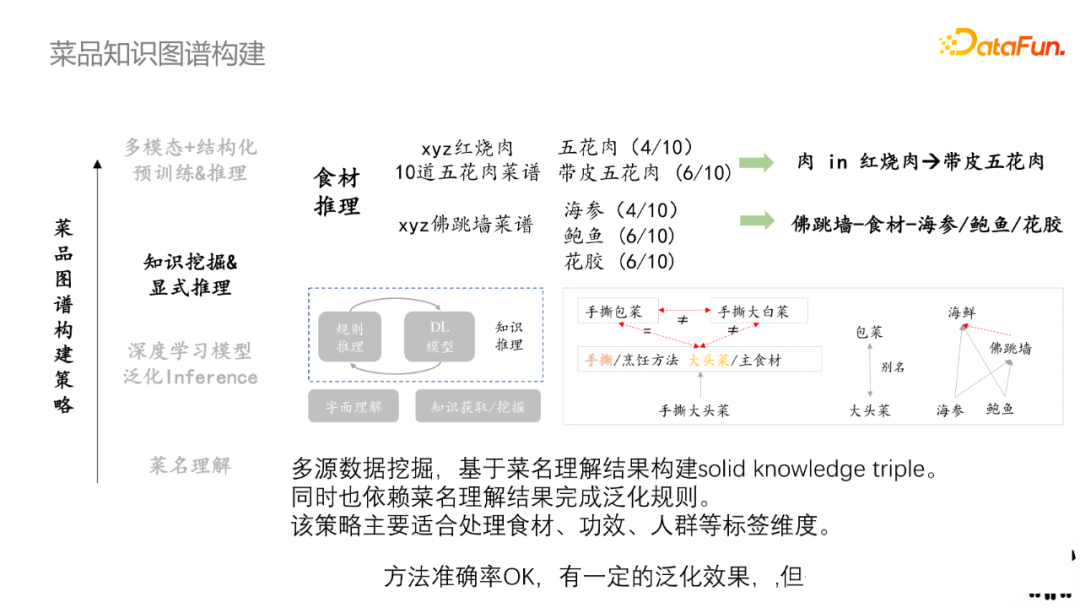
從知識內容豐富的文本中挖掘某些菜譜的基礎知識,來構建源知識庫;然後通過泛化推理去映射到具體SKU中。在食材推理中,比如菜品種有多道紅燒肉,統計10道五花肉中有4道是指五花肉,6道是指帶皮五花肉,因此肉就轉化為帶皮五花肉。對應地,佛跳牆有多道菜譜,先通過統計每種食材出現的概率,可以卡一個閾值,然後表明該菜譜的食譜是什麼。
多源數據挖掘,基於菜名理解結果構建solid knowledge triple,同時也依賴菜名理解結果泛化規則。該策略主要適用於處理食材、功效、人群等標簽。該方法準確率OK,有一定泛化能力,但覆蓋率偏低。
- 多模態+結構化預訓練及推理
業務內有一些比較好用的訓練數據,例如1000萬商戶編輯自洽的店內分類樹。基於該數據可產生5億的 positive pairs 和 30G corpus。在模型訓練中,會隨機替換掉菜譜分類的 tab/shop,模型判斷 tab/shop 是否被替換;50%的概率drop shop name,使得模型僅輸入菜名時表現魯棒。同時,對模型做了實體化改進,將分類標簽作為bert的詞進行訓練,將該方法應用到下游模型中,在10w標註數據下,菜譜上下位/同義詞模型準確率提升了1.8%。


- 多模態&多視圖半監督學習策略
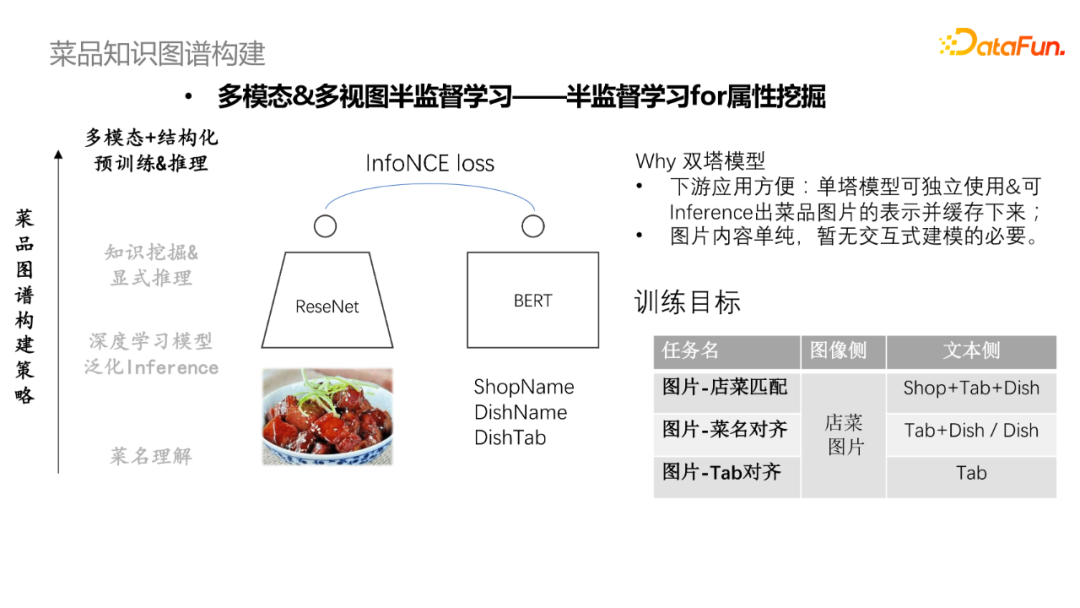
首先使用ReseNet對菜譜圖片進行編,使用Bert模型對菜譜文本信息做編碼,通過對比學習loss去學習文本和店菜的匹配信息。這裡採用雙塔模型,一方面是下游應用較為方便,單塔模型可獨立使用,也可inference出菜品圖片的表示並緩存下來;另一方面是圖片內容單純,暫無互動式建模的必要。訓練目標分別是圖片與店菜匹配、圖片與菜名對齊,圖片與Tab對齊。
- 多模態&多視圖半監督學習應用
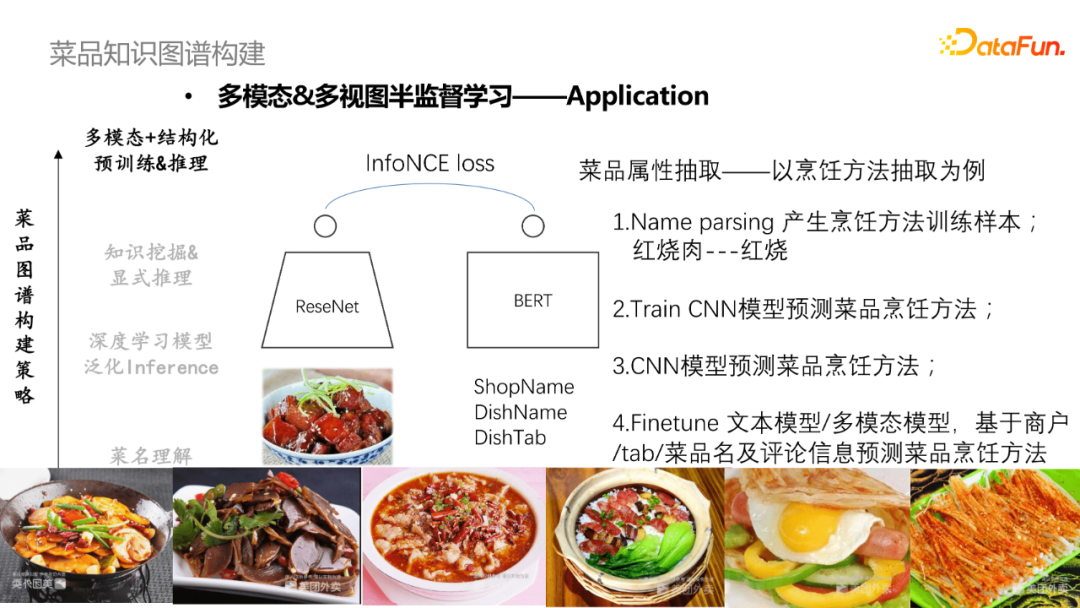
可基於多模態信息做菜品品類預測或者菜譜信息補全。比如,預測“豬肉白菜”加上了圖片信息將更加直觀和準確。基於文本和視圖模態信息進行多視圖半監督的菜譜屬性抽取,以烹飪方式抽取為例,首先通過產生烹飪方法訓練樣本(紅燒肉-紅燒);然後採用CNN模型去訓練預測菜譜烹飪方法,指導Bert模型Finetune文本模型或者多模態模型,基於商戶/tab/菜品及評論信息預測菜品烹飪方法;最終對兩個模型進行投票或者將兩個特征拼接做預測。
綜上,我們對菜品知識圖譜構建進行相應的總結。菜品理解比較適合SKU的初始化;深度學習推理模型和顯式推理模型比較適合做同義詞、上下位、菜系等;最終是想通過多模態+結構化預訓練和推理來解決單模態信息不完整、屬性維度多、需要大量標註數據等問題,因此該方法被應用到幾乎所有的場景中。
今天的分享就到這裡,謝謝大家。
分享嘉賓:

本文首發於微信公眾號“DataFunTalk”。

