
原文鏈接:當我們在聊「開源大數據調度系統Taier」的數據開發功能時,到底在討論什麼? 課件獲取:關註公眾號__ “數棧研習社”,後臺私信 “Taier”__ 獲得直播課件 視頻回放:點擊這裡 Taier 開源項目地址:github 丨 gitee 喜歡我們的項目給我們點個__ STAR!STAR! ...
原文鏈接:當我們在聊「開源大數據調度系統Taier」的數據開發功能時,到底在討論什麼?
課件獲取:關註公眾號__ “數棧研習社”,後臺私信 “Taier”__ 獲得直播課件
視頻回放:點擊這裡
Taier 開源項目地址:github 丨 gitee 喜歡我們的項目給我們點個__ STAR!STAR!!STAR!!!(重要的事情說三遍)__
技術交流釘釘 qun:30537511
本期我們帶大家回顧一下摘月同學的直播分享《Taier數據開發介紹》
之前三期內容,我們為大家分享了Taier入門、控制台以及Web前端架構的介紹。本次分享我們將從Taier的數據開發功能,到任務運行、功能可擴展點以及未來規劃為大家進行講解。
一、數據開發功能介紹
Taier 是袋鼠雲開源項目之一,是一個分散式可視化的DAG任務調度系統,旨在降低ETL開發成本、提高大數據平臺穩定性,Taier的數據開發功能主要分為以下三種:
1、資源管理
資源管理通常使用在UDF等自定義函數的場景中,也可以在任務開發中使用。在Taier中,對於函數引用,主要用在Spark、Flink自定義函數中,而在任務引用中,則主要用於Flink任務。

2、函數管理
自定義函數處理流程如下圖所示:
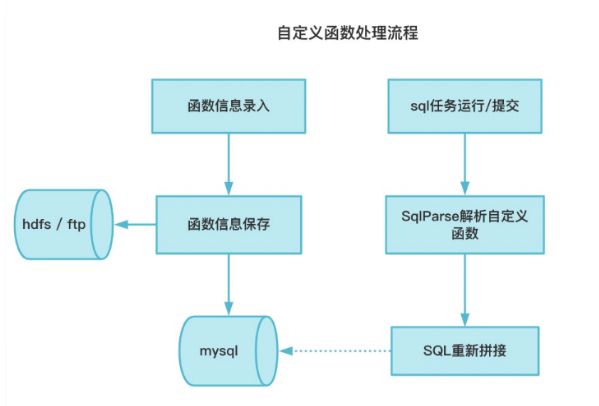
函數管理在Taier中的具體實現主要包括以下兩個方面:
-
基於calcite完成不同數據源SQL自定義函數解析
-
使用SQL運行前創建臨時函數替代創建永久函數,使函數使用更加靈活
3、任務管理
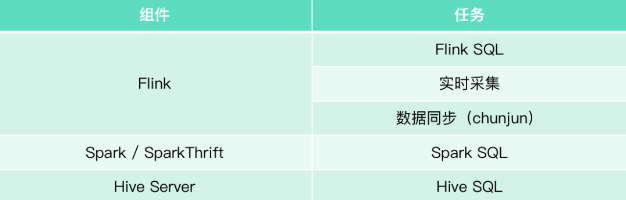
Taier現支持任務:Flink SQL、實時採集、數據同步(ChunJun)、Spark SQL、HiveSQL
Taier中有兩塊區分,分別為集群和數據開發,如果想在Taier中跑一個任務,需要先在集群中進行配置,具體組件與任務關係如下圖:
二、Taier任務運行講解
瞭解完Taier數據開發的功能介紹後,我們來為大家分享Taier的任務運行邏輯。
1、Spark Sql、Hive Sql臨時運行流程
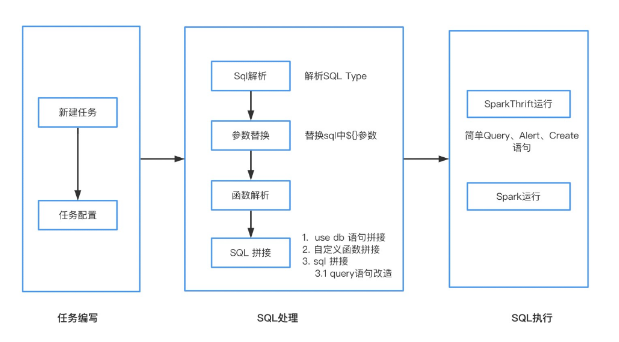
Spark Sql、Hive Sql 臨時運行流程主要分為任務編寫、SQL處理、SQL執行三步,以下圖為SparkSql執行流程:
2、Spark Sql 、Hive Sql 運行依賴
Spark Sql 、Hive Sql 運行依賴主要包括以下兩類:
● Sql解析(基於calcite進行)
· Sql Type 解析
· 函數、表名解析
● 數據源插件
· 統一不同數據源操作入口
· 封裝數據源對應的數據操作方法
三、功能可擴展點介紹
當前而言,Taier中的功能還較為簡單,只開放了主要流程的功能,在開源中還有許多可擴展點,接下來為大家介紹Taier的功能可擴展點。
1、功能擴展——數據許可權控制
在sparkThrift、hiveserver中去進行create、insert into、alter、select時,不同的公司、不同的人有不一樣的數據許可權控制,面對這種情況,可以利用Apache Ranger大數據許可權管理框架進行許可權配置。
具體地址為:
github:https://github.com/ranger/ranger
2、功能擴展——數據血源追蹤
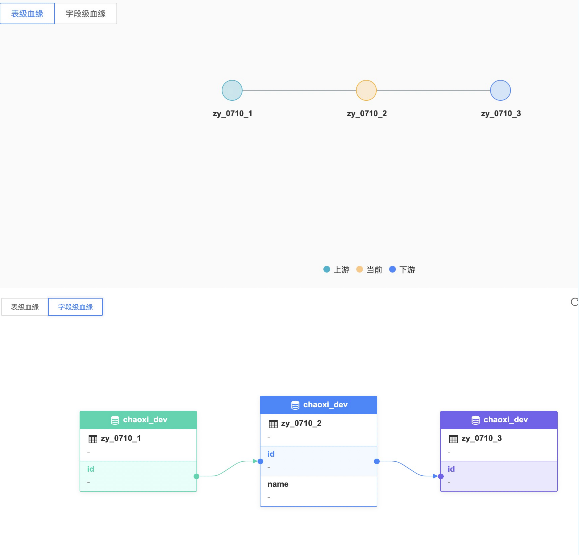
通過SQL解析可以得到表和表之間的關係,以及不同表中欄位之間的血源關係。
● 實現工具:calcite
● 可操作任務:SparkSql、HiveSql、數據同步(ChunJun)
用sql舉例:
create table zy_0710_1 (id int, name string);
create table zy_0710_2 as select id , name from zy_0710_1;
create table zy_0710_3 as select id , name from zy_0710_2;
四、Taier1.2嘗鮮
最後為大家介紹未來不久將發佈的Taier1.2新版本嘗鮮:
●集群管理
控制台ui升級
● 數據開發
-
集群租戶綁定流程簡化
-
任務開發代碼層面優化
-
任務新增schema配置
● 新增功能
-
FlinkSql支持jar包方式
-
新增工作流任務
-
自定義擴展開發任務
袋鼠雲開源框架釘釘技術交流qun(30537511),歡迎對大數據開源項目有興趣的同學加入交流最新技術信息,開源項目庫地址:https://github.com/DTStack


