寫在前面 Facebook 開源的VideoPose3D模型致力於實現準確的人體骨骼3D重建。其效果令人驚嘆,只需要使用手機相機就可以實現相似的效果。 而一旦技術成熟,這種人體骨骼的三維重建在很多領域將會產生顛覆性的應用。 但是到目前為止,該技術還是有很多不足,其中制約該技術商業化運用的一個最大難點 ...
寫在前面
Facebook 開源的VideoPose3D模型致力於實現準確的人體骨骼3D重建。其效果令人驚嘆,只需要使用手機相機就可以實現相似的效果。
而一旦技術成熟,這種人體骨骼的三維重建在很多領域將會產生顛覆性的應用。
但是到目前為止,該技術還是有很多不足,其中制約該技術商業化運用的一個最大難點在於源碼理解困難,模型是純純黑盒。因此本文將嘗試理解該論文的實現方法。
介紹
論文一開始就闡述了核心技術,即使用2D關鍵點預測3D姿勢,最後再將3D姿勢反向投影回原先的2D關鍵點(半監督方法)。
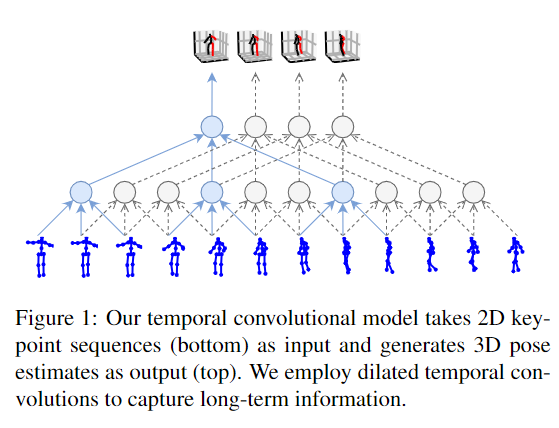
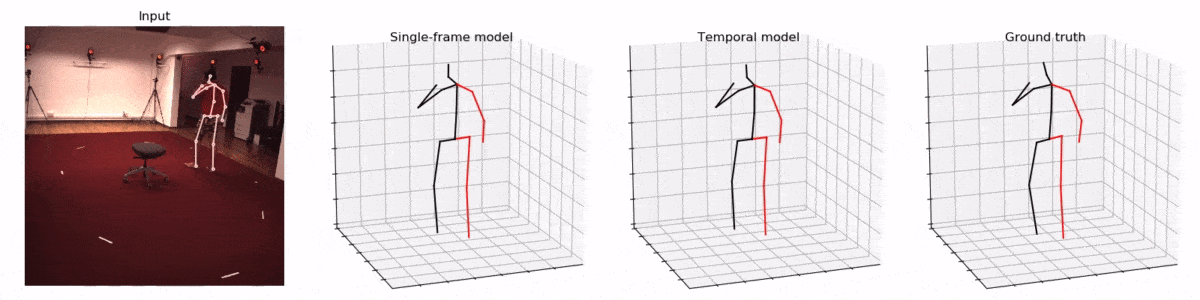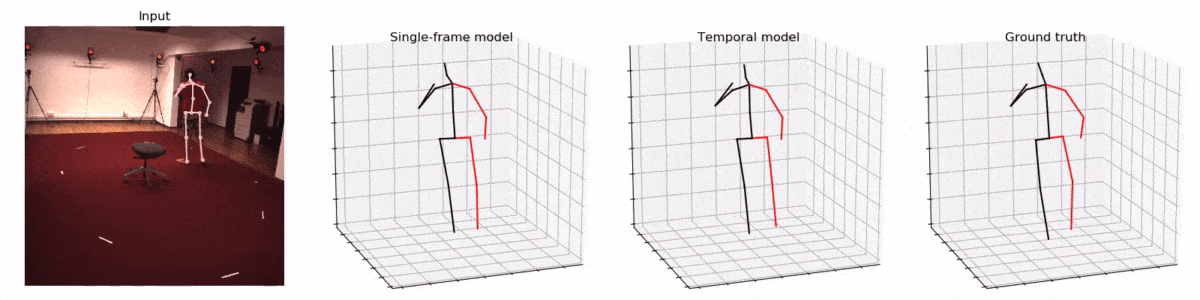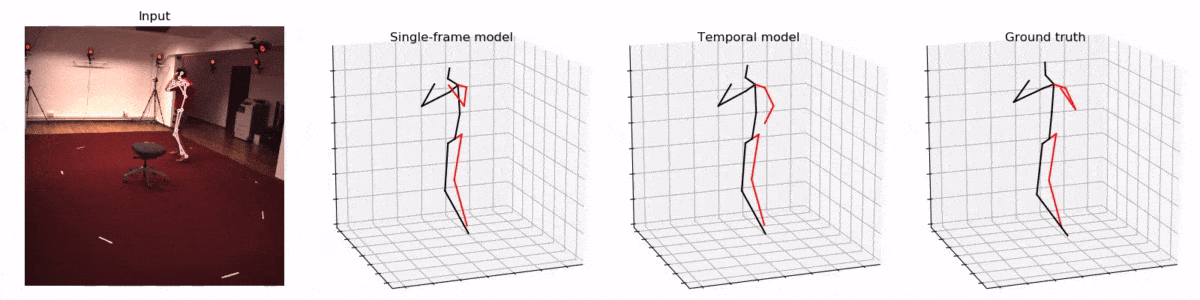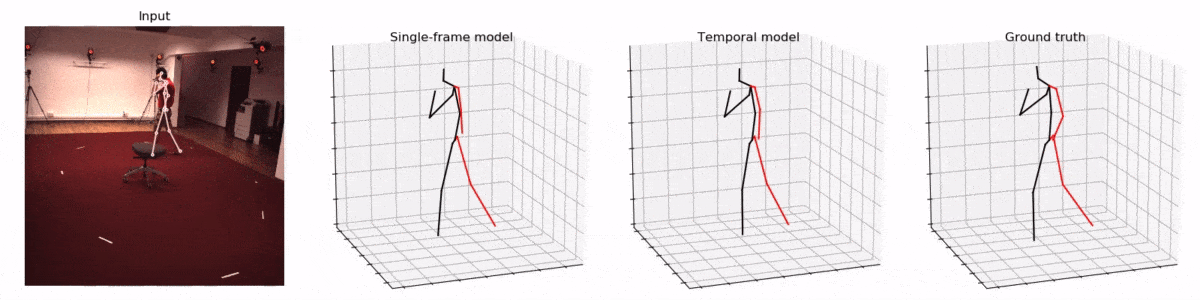
並且作者聲稱在2D關鍵點預測3D時使用了時間捲積架構(temporal convolutions),讓模型可以一次看見多個幀,從而提升3D姿態估計的準確性。
並且作者還介紹了一個基於半監督學習的技術方法,以提高標記 3D 真實姿態數據的的準確性。
這裡的幾個關鍵詞分別是:
2D關鍵點: 通過基於2D圖像檢測技術獲取的人體2D關鍵點。相關的技術庫主要有:Detectron,Openpose 等。

需要註意的是,這種技術僅檢測在圖片的2D坐標系內出現的人體骨骼關鍵點,並不包含深度信息(也就是第三軸),因此無法建立3D模型。
3D姿勢: 相對於上文的2D關鍵點,3D姿勢也可以說成是3D關鍵點,VideoPose3D模型通過獲取的2D關鍵點為這些關鍵點添加了深度信息,從而建立了3D模型。這也是這個模型的魅力所在。
將3D姿勢反向投影回原先的2D關鍵點,監督學習的技術方法:這兩個關鍵詞說的其實是一個技術。即在大量的未標記視頻中(例如油管視頻),通過2D關鍵點檢測技術生成2D關鍵點之後,應用VideoPose3D生成3D關鍵點,,之後,再將生成的3D關鍵點投影回原來的2D空間中,這時就會發現,你有兩套2D關鍵點了,一套是通過2D關鍵點檢測技術生成的2D關鍵點,另一套是3D關鍵點投影回來的2D關鍵點。然後就可以通過計算這兩套關鍵點之間的誤差來評價生成的3D模型的效果了。因此被稱為半監督學習的技術方法。而且作者借鑒了對抗神經網路(GAN)的理念,在兩套關鍵點差異過大時對模型予以懲罰,從而可以大量生成標記數據集,,,這真是挺強的。這個技術的理解難點在於將3D姿勢反向投影回2D,因為由VideoPose3D模型預測出來的3D關鍵點僅僅是各個關節的相對位置,而不包含當前世界場景下的絕對位置(也就是說,你不知道人物在視頻中的移動軌跡),所以如果想要將3D關鍵點反向投影回2D的話,必須要獲得人物的身體中心(或者原點)的移動軌跡,然後再將3D關鍵點投影上去。為此,作者還專門寫了一個軌跡模型(Trajectory model)用於預測人體在3D空間內的軌跡。但是作者沒有細說軌跡模型的實現方法。
時間捲積架構(temporal convolutions):
作者們利用了捲積神經網路的特性,讓模型可以一次'看見'時間軸上的先後的多個動作(視頻的幀),從而更好地估計3D姿態。這也是我認為本文的第二大創新點。
試想,讓你只看一張圖片就估計一個物體(人)的3D姿勢,和讓你包含了一個人連續動作的多個圖片來估計3D姿勢,可能後者會來得更準確一些。