
JVM 一、什麼是JVM 定義 Java Virtual Machine,JAVA程式的運行環境(JAVA二進位位元組碼的運行環境) 好處 一次編寫,到處運行 自動記憶體管理,垃圾回收機制 數組下標越界檢查 比較 JVM JRE JDK的區別 二、記憶體結構 整體架構 1、程式計數器 作用 用於保存JVM ...
JVM
一、什麼是JVM
定義
Java Virtual Machine,JAVA程式的運行環境(JAVA二進位位元組碼的運行環境)
好處
- 一次編寫,到處運行
- 自動記憶體管理,垃圾回收機制
- 數組下標越界檢查
比較
JVM JRE JDK的區別

二、記憶體結構
整體架構
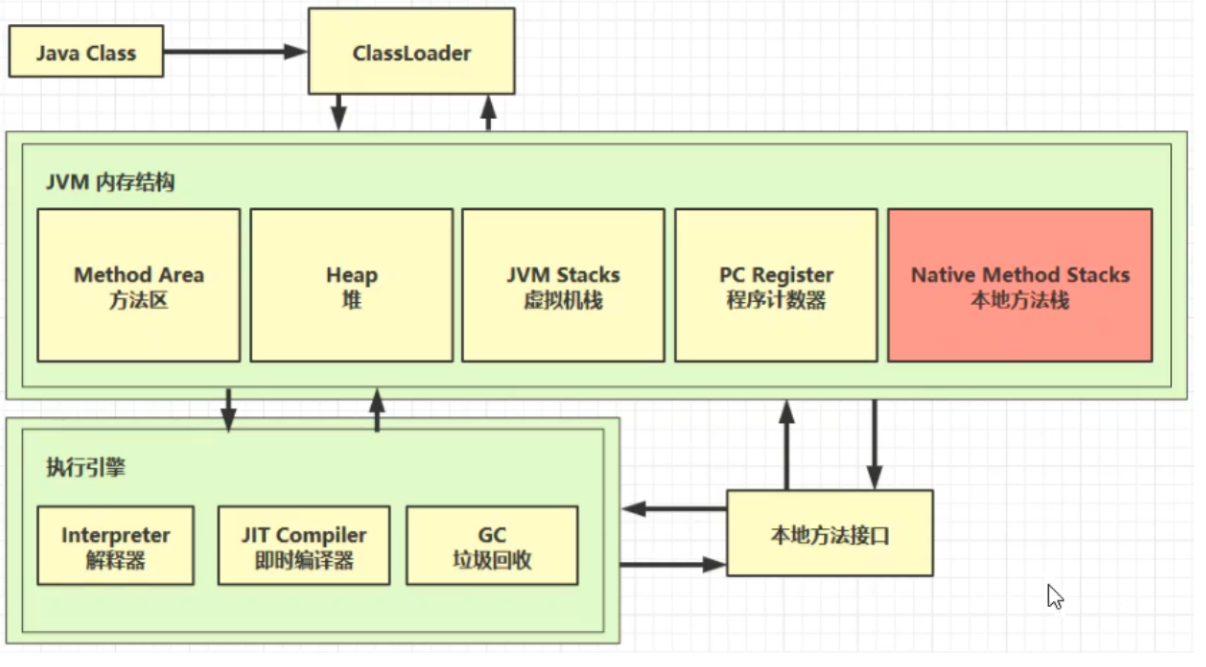
1、程式計數器
作用
用於保存JVM中下一條所要執行的指令的地址
特點
- 線程私有
- CPU會為每個線程分配時間片,噹噹前線程的時間片使用完以後,CPU就會去執行另一個線程中的代碼
- 程式計數器是每個線程所私有的,當另一個線程的時間片用完,又返回來執行當前線程的代碼時,通過程式計數器可以知道應該執行哪一句指令
- 不會存在記憶體溢出
2、虛擬機棧
定義
- 每個線程運行需要的記憶體空間,稱為虛擬機棧
- 每個棧由多個棧幀組成,對應著每次調用方法時所占用的記憶體
- 每個線程只能有一個活動棧幀,對應著當前正在執行的方法(棧頂部的第一個方法)
演示
代碼
public class Main {
public static void main(String[] args) {
method1();
}
private static void method1() {
method2(1, 2);
}
private static int method2(int a, int b) {
int c = a + b;
return c;
}
}Copy
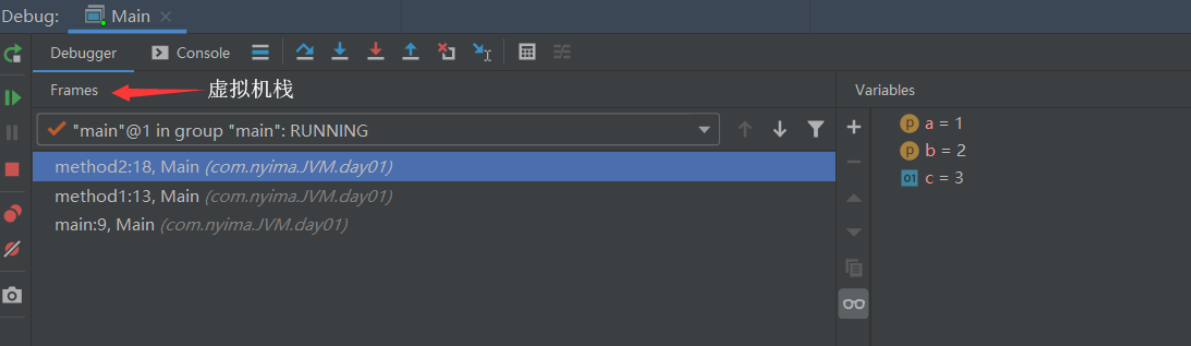
在控制臺中可以看到,主類中的方法在進入虛擬機棧的時候,符合棧的特點
問題辨析
- 垃圾回收是否涉及棧記憶體?
- 不需要。因為虛擬機棧中是由一個個棧幀組成的,在方法執行完畢後,對應的棧幀就會被彈出棧。所以無需通過垃圾回收機制去回收記憶體。
- 棧記憶體的分配越大越好嗎?
- 不是。因為物理記憶體是一定的,棧記憶體越大,可以支持更多的遞歸調用,但是可執行的線程數就會越少。
- 方法內的局部變數是否是線程安全的?
- 看變數是被線程私有還是共用,共用則不安全
- 看變數的作用範圍

記憶體溢出
Java.lang.stackOverflowError 棧記憶體溢出
發生原因
- 虛擬機棧中,棧幀過多(無限遞歸)
- 每個棧幀所占用過大
線程運行診斷
CPU占用過高
- Linux環境下運行某些程式的時候,可能導致CPU的占用過高,這時需要定位占用CPU過高的線程
- top命令,查看是哪個進程占用CPU過高
- ps H -eo pid, tid(線程id), %cpu | grep 剛纔通過top查到的進程號 通過ps命令進一步查看是哪個線程占用CPU過高
- jstack 進程id 通過查看進程中的線程的nid,剛纔通過ps命令看到的tid來對比定位,註意jstack查找出的線程id是16進位的,需要轉換
3、本地方法棧
一些帶有native關鍵字的方法就是需要JAVA去調用本地的C或者C++方法,因為JAVA有時候沒法直接和操作系統底層交互,所以需要用到本地方法
4、堆
定義
通過new關鍵字創建的對象都會被放在堆記憶體
特點
- 所有線程共用,堆記憶體中的對象都需要考慮線程安全問題
- 有垃圾回收機制
堆記憶體溢出
java.lang.OutofMemoryError :java heap space. 堆記憶體溢出
堆記憶體診斷
jps
jmap
jconsole
jvirsalvm
5、方法區
結構
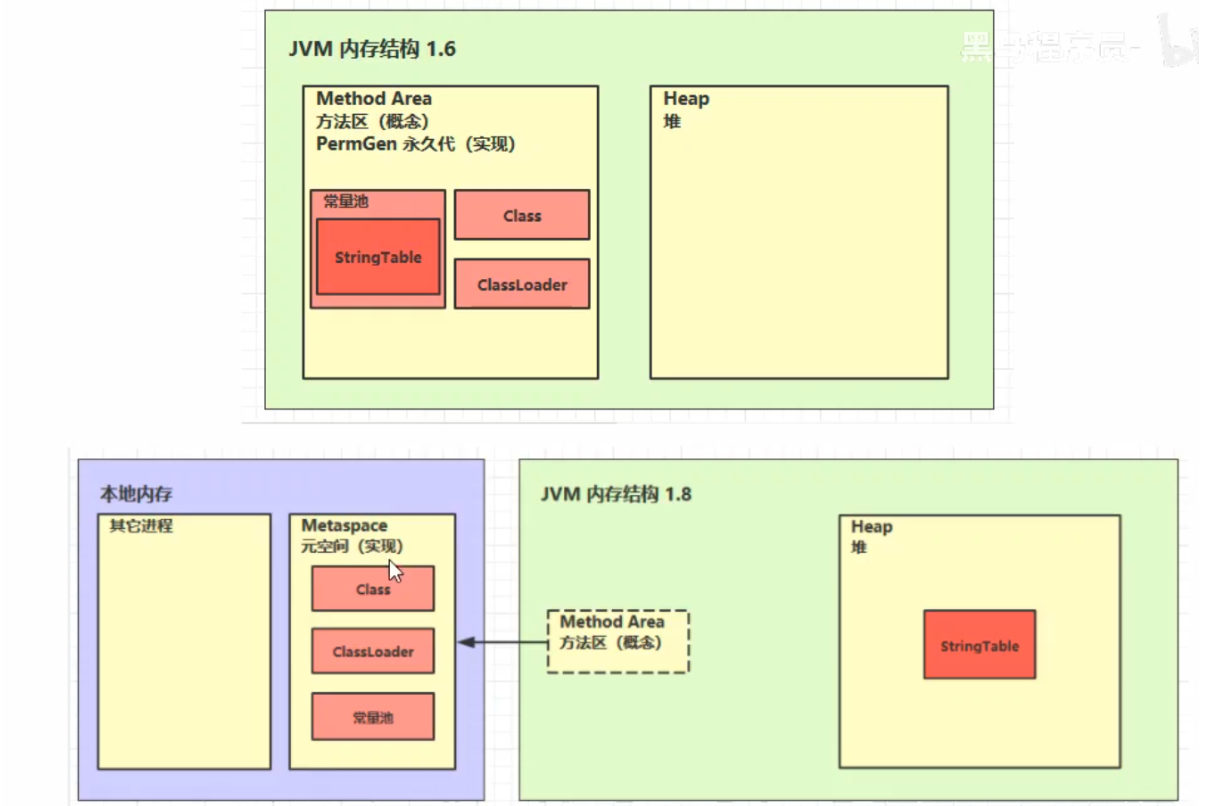
記憶體溢出
- 1.8以前會導致永久代記憶體溢出
- 1.8以後會導致元空間記憶體溢出
常量池
二進位位元組碼的組成:類的基本信息、常量池、類的方法定義(包含了虛擬機指令)
通過反編譯來查看類的信息
-
獲得對應類的.class文件
-
在JDK對應的bin目錄下運行cmd,也可以在IDEA控制台輸入

-
輸入 javac 對應類的絕對路徑
F:\JAVA\JDK8.0\bin>javac F:\Thread_study\src\com\nyima\JVM\day01\Main.javaCopy輸入完成後,對應的目錄下就會出現類的.class文件
-
-
在控制台輸入 javap -v 類的絕對路徑
javap -v F:\Thread_study\src\com\nyima\JVM\day01\Main.classCopy -
然後能在控制台看到反編譯以後類的信息了
-
類的基本信息

-
常量池

-
虛擬機中執行編譯的方法(框內的是真正編譯執行的內容,**#號的內容需要在常量池中查找**)

-
運行時常量池
- 常量池
- 就是一張表(如上圖中的constant pool),虛擬機指令根據這張常量表找到要執行的類名、方法名、參數類型、字面量信息
- 運行時常量池
- 常量池是*.class文件中的,當該類被載入以後,它的常量池信息就會放入運行時常量池,並把裡面的符號地址變為真實地址
常量池與串池的關係
串池StringTable
特征
- 常量池中的字元串僅是符號,只有在被用到時才會轉化為對象
- 利用串池的機制,來避免重覆創建字元串對象
- 字元串變數拼接的原理是StringBuilder
- 字元串常量拼接的原理是編譯器優化
- 可以使用intern方法,主動將串池中還沒有的字元串對象放入串池中
- 註意:無論是串池還是堆裡面的字元串,都是對象
用來放字元串對象且裡面的元素不重覆
public class StringTableStudy { public static void main(String[] args) { String a = "a"; String b = "b"; String ab = "ab"; } }
常量池中的信息,都會被載入到運行時常量池中,但這是a b ab 僅是常量池中的符號,還沒有成為java字元串
0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: returnCopy
當執行到 ldc #2 時,會把符號 a 變為 “a” 字元串對象,並放入串池中(hashtable結構 不可擴容)
當執行到 ldc #3 時,會把符號 b 變為 “b” 字元串對象,並放入串池中
當執行到 ldc #4 時,會把符號 ab 變為 “ab” 字元串對象,並放入串池中
最終StringTable [“a”, “b”, “ab”]
註意:字元串對象的創建都是懶惰的,只有當運行到那一行字元串且在串池中不存在的時候(如 ldc #2)時,該字元串才會被創建並放入串池中。
使用拼接字元串變數對象創建字元串的過程
public class StringTableStudy { public static void main(String[] args) { String a = "a"; String b = "b"; String ab = "ab"; //拼接字元串對象來創建新的字元串 String ab2 = a+b; } }
通過拼接的方式來創建字元串的過程是:StringBuilder().append(“a”).append(“b”).toString()
最後的toString方法的返回值是一個新的字元串,但字元串的值和拼接的字元串一致,但是兩個不同的字元串,一個存在於串池之中,一個存在於堆記憶體之中
- 使用拼接字元串常量的方法來創建新的字元串時,因為內容是常量,javac在編譯期會進行優化,結果已在編譯期確定為ab,而創建ab的時候已經在串池中放入了“ab”,所以ab3直接從串池中獲取值,所以進行的操作和 ab = “ab” 一致。
- 使用拼接字元串變數的方法來創建新的字元串時,因為內容是變數,只能在運行期確定它的值,所以需要使用StringBuilder來創建
intern方法 1.8
調用字元串對象的intern方法,會將該字元串對象嘗試放入到串池中
- 如果串池中沒有該字元串對象,則放入成功
- 如果有該字元串對象,則放入失敗
無論放入是否成功,都會返回串池中的字元串對象
註意:此時如果調用intern方法成功,堆記憶體與串池中的字元串對象是同一個對象;如果失敗,則不是同一個對象
intern方法 1.6
調用字元串對象的intern方法,會將該字元串對象嘗試放入到串池中
- 如果串池中沒有該字元串對象,會將該字元串對象複製一份,再放入到串池中
- 如果有該字元串對象,則放入失敗
無論放入是否成功,都會返回串池中的字元串對象
註意:此時無論調用intern方法成功與否,串池中的字元串對象和堆記憶體中的字元串對象都不是同一個對象
StringTable 垃圾回收
StringTable在記憶體緊張時,會發生垃圾回收
StringTable調優
-
因為StringTable是由HashTable實現的,所以可以適當增加HashTable桶的個數,來減少字元串放入串池所需要的時間
-XX:StringTableSize=xxxxCopy -
考慮是否需要將字元串對象入池
可以通過intern方法減少重覆入池
6、直接記憶體
- 屬於操作系統,常見於NIO操作時,用於數據緩衝區
- 分配回收成本較高,但讀寫性能高
- 不受JVM記憶體回收管理
文件讀寫流程
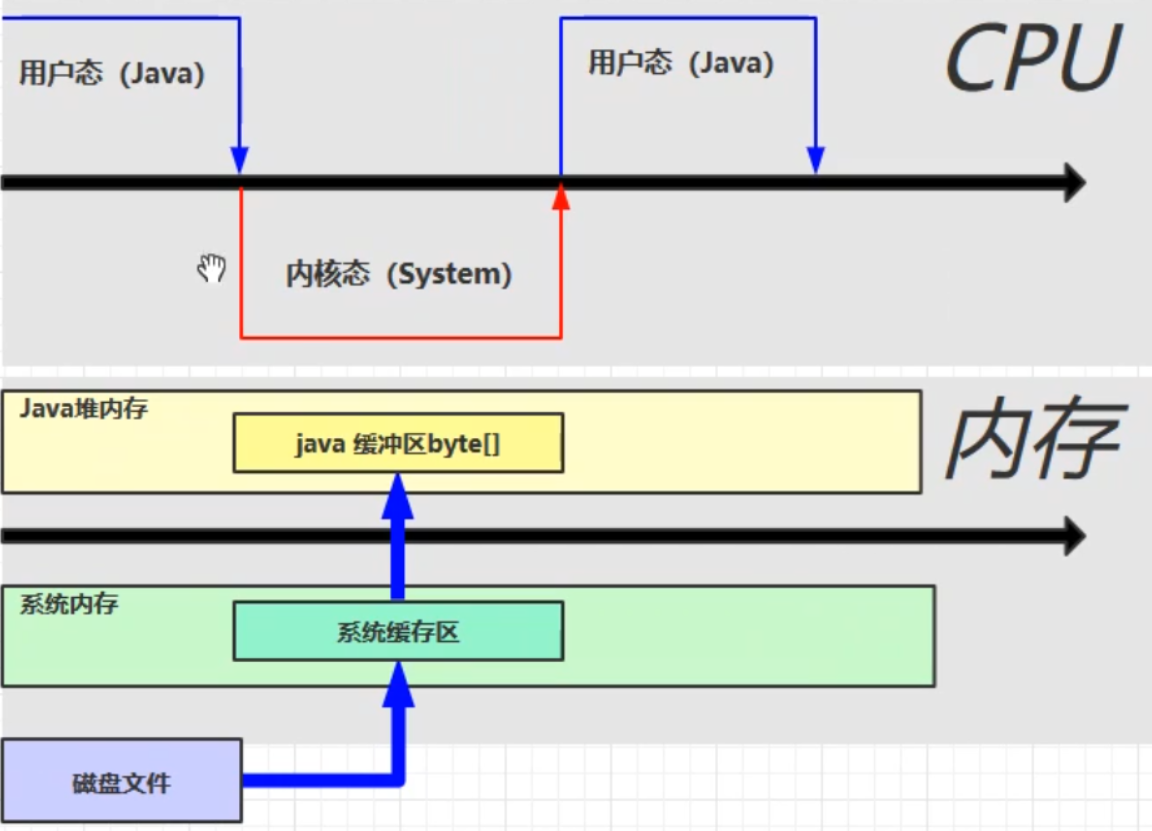
使用了DirectBuffer
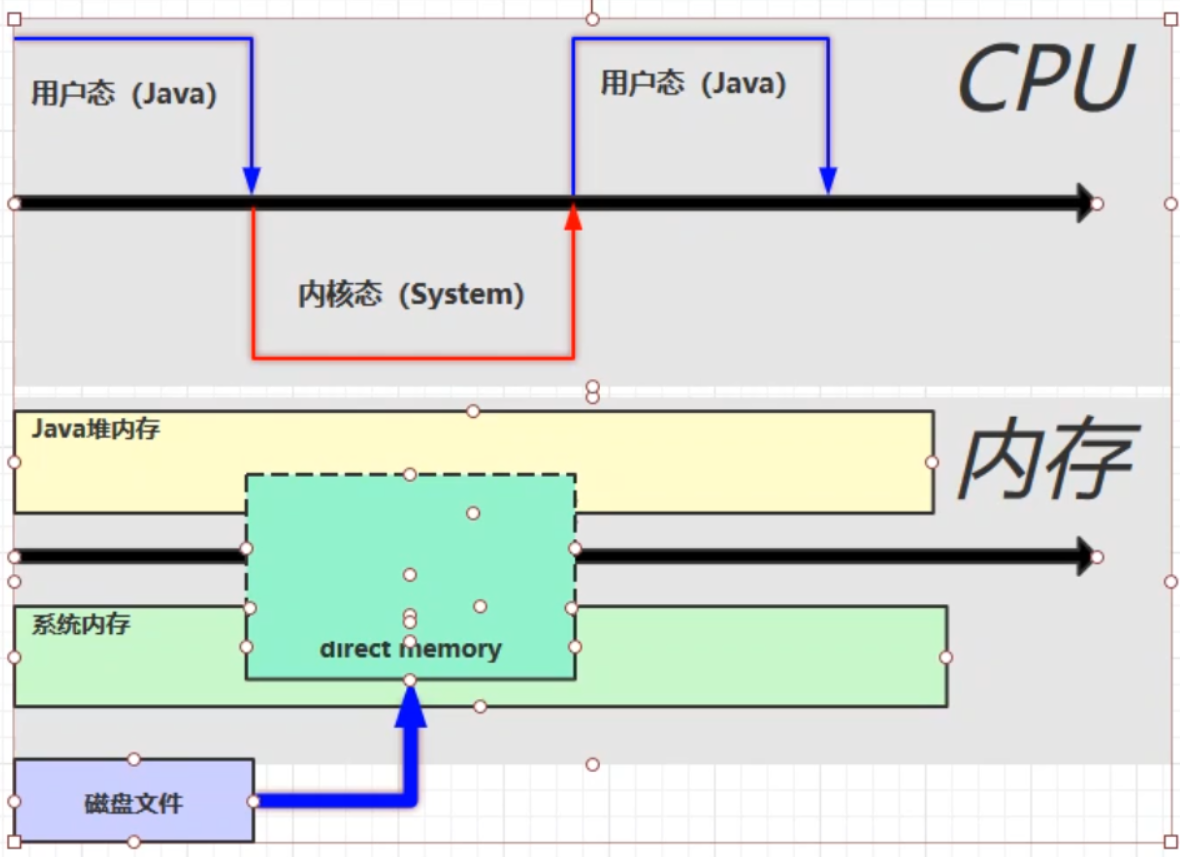
直接記憶體是操作系統和Java代碼都可以訪問的一塊區域,無需將代碼從系統記憶體複製到Java堆記憶體,從而提高了效率
釋放原理
直接記憶體的回收不是通過JVM的垃圾回收來釋放的,而是通過unsafe.freeMemory來手動釋放
通過
//通過ByteBuffer申請1M的直接記憶體 ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1M);Copy
申請直接記憶體,但JVM並不能回收直接記憶體中的內容,它是如何實現回收的呢?
allocateDirect返回一個DirectByteBuffer對象,裡面申請記憶體,通過虛引用對象釋放記憶體
DirectByteBuffer類
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size); //申請記憶體
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); //通過虛引用,來實現直接記憶體的釋放,this為虛引用的實際對象
att = null;
}Copy
這裡調用了一個Cleaner的create方法,且後臺線程還會對虛引用的對象監測,如果虛引用的實際對象(這裡是DirectByteBuffer)被回收以後,就會調用Cleaner的clean方法,來清除直接記憶體中占用的記憶體
public void clean() {
if (remove(this)) {
try {
this.thunk.run(); //調用run方法
} catch (final Throwable var2) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null) {
(new Error("Cleaner terminated abnormally", var2)).printStackTrace();
}
System.exit(1);
return null;
}
});
}Copy
對應對象的run方法
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address); //釋放直接記憶體中占用的記憶體
address = 0;
Bits.unreserveMemory(size, capacity);
}Copy
直接記憶體的回收機制總結
- 使用了Unsafe類來完成直接記憶體的分配回收,回收需要主動調用freeMemory方法
- ByteBuffer的實現內部使用了Cleaner(虛引用)來檢測ByteBuffer。一旦ByteBuffer被垃圾回收,那麼會由ReferenceHandler來調用Cleaner的clean方法調用freeMemory來釋放記憶體
三、垃圾回收
1、如何判斷對象可以回收
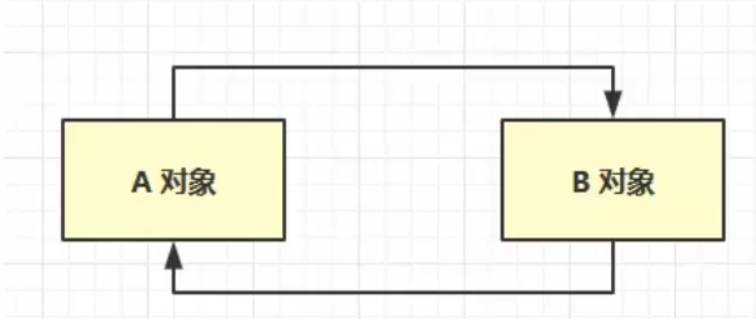
引用計數法
弊端:迴圈引用時,兩個對象的計數都為1,導致兩個對象都無法被釋放
可達性分析演算法
- JVM中的垃圾回收器通過可達性分析來探索所有存活的對象
- 掃描堆中的對象,看能否沿著GC Root對象為起點的引用鏈找到該對象,如果找不到,則表示可以回收
- 可以作為GC Root的對象
- 虛擬機棧(棧幀中的本地變數表)中引用的對象。
- 方法區中類靜態屬性引用的對象
- 方法區中常量引用的對象
- 本地方法棧中JNI(即一般說的Native方法)引用的對象
五種引用
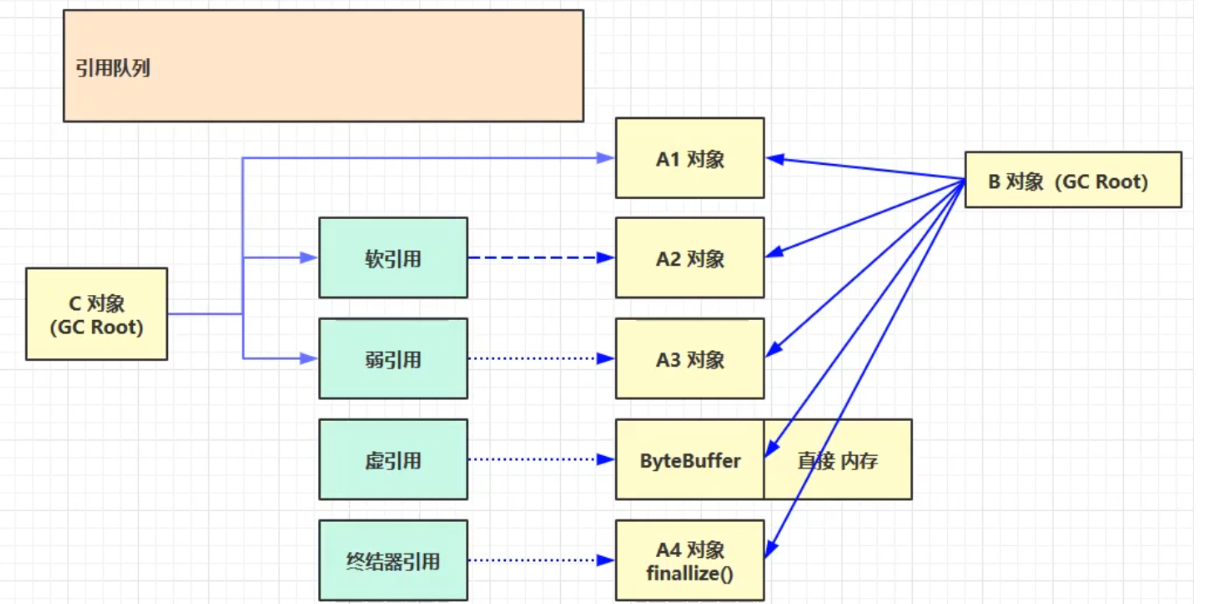
強引用
只有GC Root都不引用該對象時,才會回收強引用對象
- 如上圖B、C對象都不引用A1對象時,A1對象才會被回收
軟引用
當GC Root指向軟引用對象時,在記憶體不足時,會回收軟引用所引用的對象
- 如上圖如果B對象不再引用A2對象且記憶體不足時,軟引用所引用的A2對象就會被回收
軟引用的使用
public class Demo1 {
public static void main(String[] args) {
final int _4M = 4*1024*1024;
//使用軟引用對象 list和SoftReference是強引用,而SoftReference和byte數組則是軟引用
List<SoftReference<byte[]>> list = new ArrayList<>();
SoftReference<byte[]> ref= new SoftReference<>(new byte[_4M]);
}
}Copy
如果在垃圾回收時發現記憶體不足,在回收軟引用所指向的對象時,軟引用本身不會被清理
如果想要清理軟引用,需要使用引用隊列
public class Demo1 {
public static void main(String[] args) {
final int _4M = 4*1024*1024;
//使用引用隊列,用於移除引用為空的軟引用對象
ReferenceQueue<byte[]> queue = new ReferenceQueue<>();
//使用軟引用對象 list和SoftReference是強引用,而SoftReference和byte數組則是軟引用
List<SoftReference<byte[]>> list = new ArrayList<>();
SoftReference<byte[]> ref= new SoftReference<>(new byte[_4M]);
//遍歷引用隊列,如果有元素,則移除
Reference<? extends byte[]> poll = queue.poll();
while(poll != null) {
//引用隊列不為空,則從集合中移除該元素
list.remove(poll);
//移動到引用隊列中的下一個元素
poll = queue.poll();
}
}
}Copy
大概思路為:查看引用隊列中有無軟引用,如果有,則將該軟引用從存放它的集合中移除(這裡為一個list集合)
弱引用
只有弱引用引用該對象時,在垃圾回收時,無論記憶體是否充足,都會回收弱引用所引用的對象
- 如上圖如果B對象不再引用A3對象,則A3對象會被回收
弱引用的使用和軟引用類似,只是將 SoftReference 換為了 WeakReference
虛引用
當虛引用對象所引用的對象被回收以後,虛引用對象就會被放入引用隊列中,調用虛引用的方法
- 虛引用的一個體現是釋放直接記憶體所分配的記憶體,當引用的對象ByteBuffer被垃圾回收以後,虛引用對象Cleaner就會被放入引用隊列中,然後調用Cleaner的clean方法來釋放直接記憶體
- 如上圖,B對象不再引用ByteBuffer對象,ByteBuffer就會被回收。但是直接記憶體中的記憶體還未被回收。這時需要將虛引用對象Cleaner放入引用隊列中,然後調用它的clean方法來釋放直接記憶體
終結器引用
所有的類都繼承自Object類,Object類有一個finalize方法。當某個對象不再被其他的對象所引用時,會先將終結器引用對象放入引用隊列中,然後根據終結器引用對象找到它所引用的對象,然後調用該對象的finalize方法。調用以後,該對象就可以被垃圾回收了
- 如上圖,B對象不再引用A4對象。這是終結器對象就會被放入引用隊列中,引用隊列會根據它,找到它所引用的對象。然後調用被引用對象的finalize方法。調用以後,該對象就可以被垃圾回收了
引用隊列
- 軟引用和弱引用可以配合引用隊列
- 在弱引用和虛引用所引用的對象被回收以後,會將這些引用放入引用隊列中,方便一起回收這些軟/弱引用對象
- 虛引用和終結器引用必須配合引用隊列
- 虛引用和終結器引用在使用時會關聯一個引用隊列
2、垃圾回收演算法
標記-清除
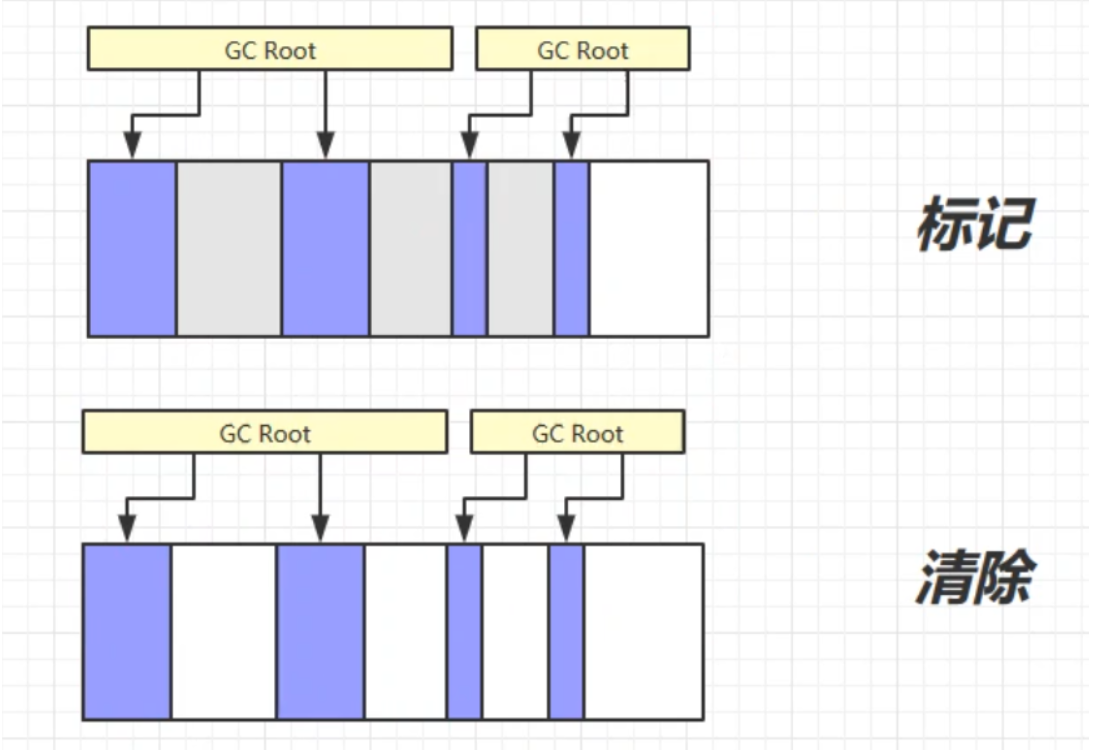
定義:標記清除演算法顧名思義,是指在虛擬機執行垃圾回收的過程中,先採用標記演算法確定可回收對象,然後垃圾收集器根據標識清除相應的內容,給堆記憶體騰出相應的空間
- 這裡的騰出記憶體空間並不是將記憶體空間的位元組清0,而是記錄下這段記憶體的起始結束地址,下次分配記憶體的時候,會直接覆蓋這段記憶體
缺點:容易產生大量的記憶體碎片,可能無法滿足大對象的記憶體分配,一旦導致無法分配對象,那就會導致jvm啟動gc,一旦啟動gc,我們的應用程式就會暫停,這就導致應用的響應速度變慢
標記-整理
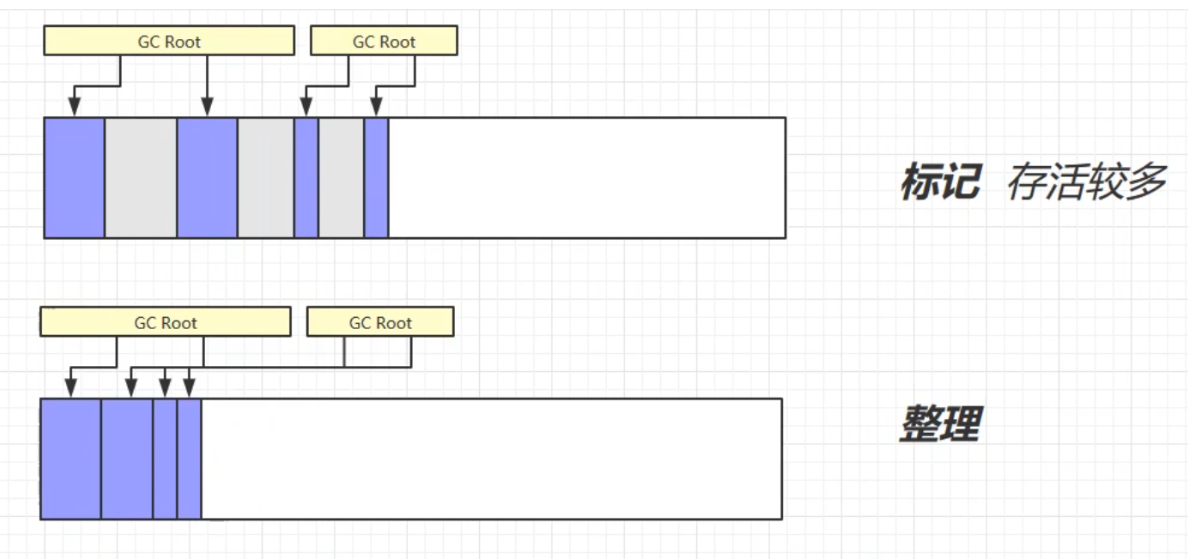
標記-整理 會將不被GC Root引用的對象回收,清楚其占用的記憶體空間。然後整理剩餘的對象,可以有效避免因記憶體碎片而導致的問題,但是因為整體需要消耗一定的時間,所以效率較低
複製
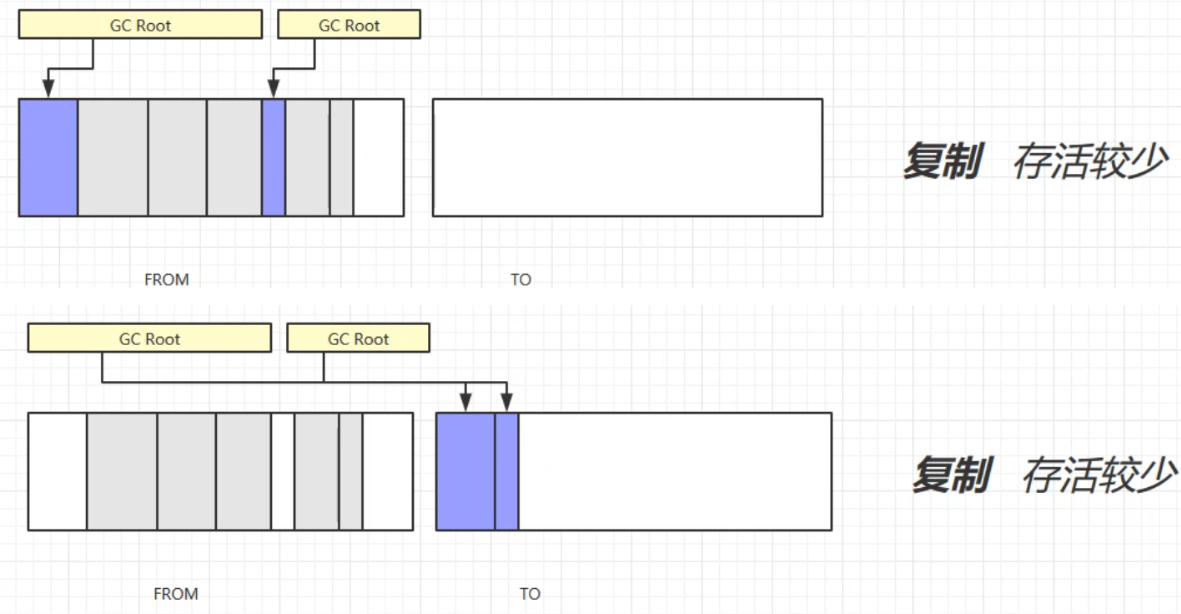
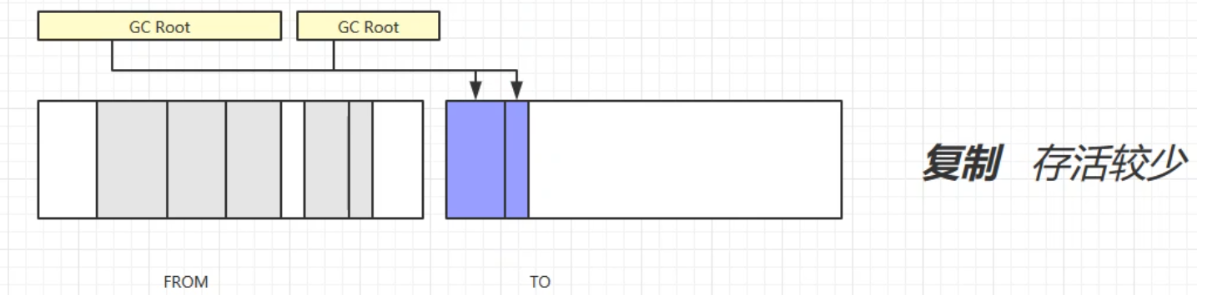
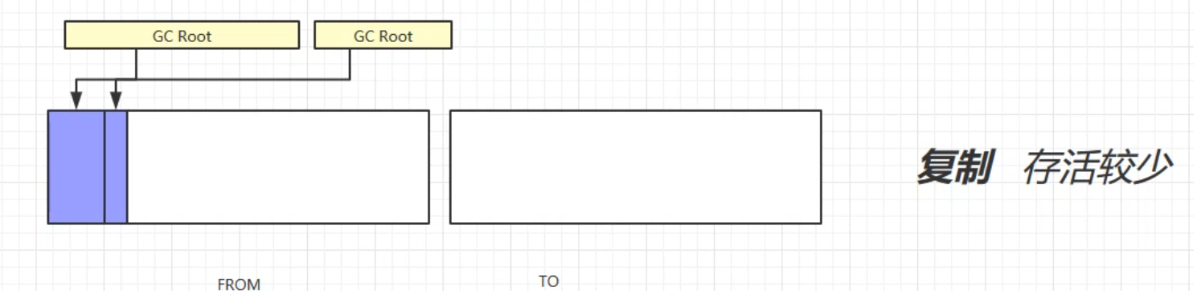
將記憶體分為等大小的兩個區域,FROM和TO(TO中為空)。先將被GC Root引用的對象從FROM放入TO中,再回收不被GC Root引用的對象。然後交換FROM和TO。這樣也可以避免記憶體碎片的問題,但是會占用雙倍的記憶體空間。
3、分代回收
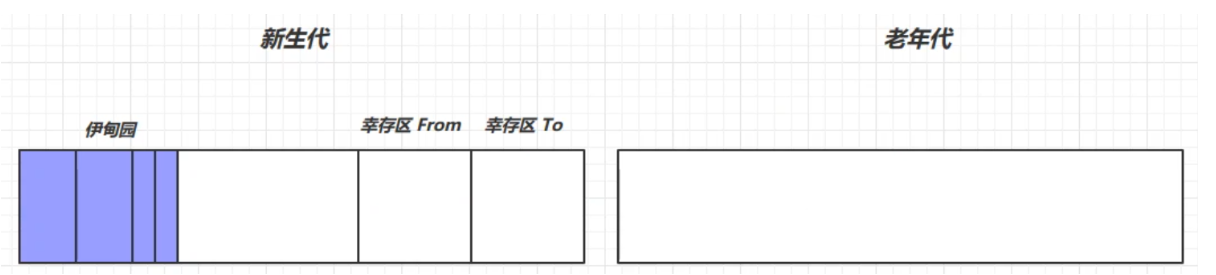
回收流程
新創建的對象都被放在了新生代的伊甸園中
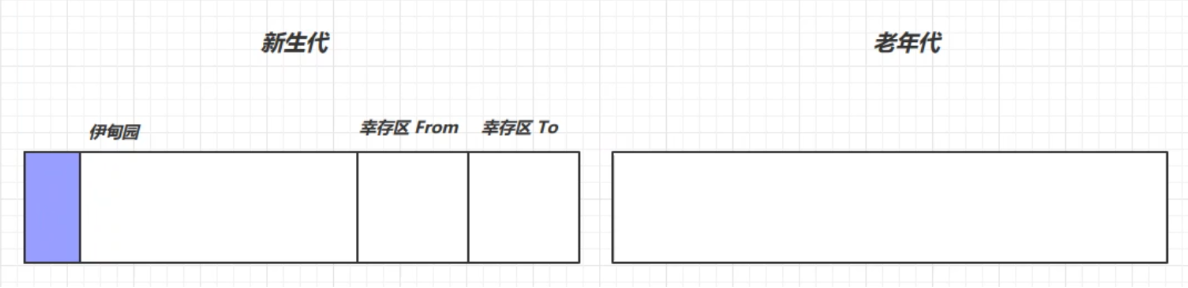
當伊甸園中的記憶體不足時,就會進行一次垃圾回收,這時的回收叫做 Minor GC
Minor GC 會將伊甸園和幸存區FROM存活的對象先複製到 幸存區 TO中, 並讓其壽命加1,再交換兩個幸存區
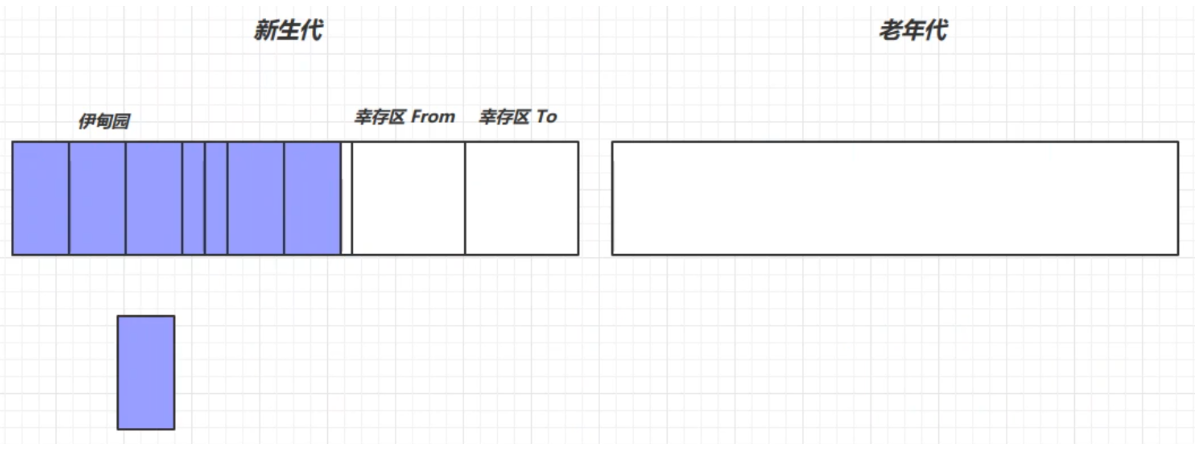
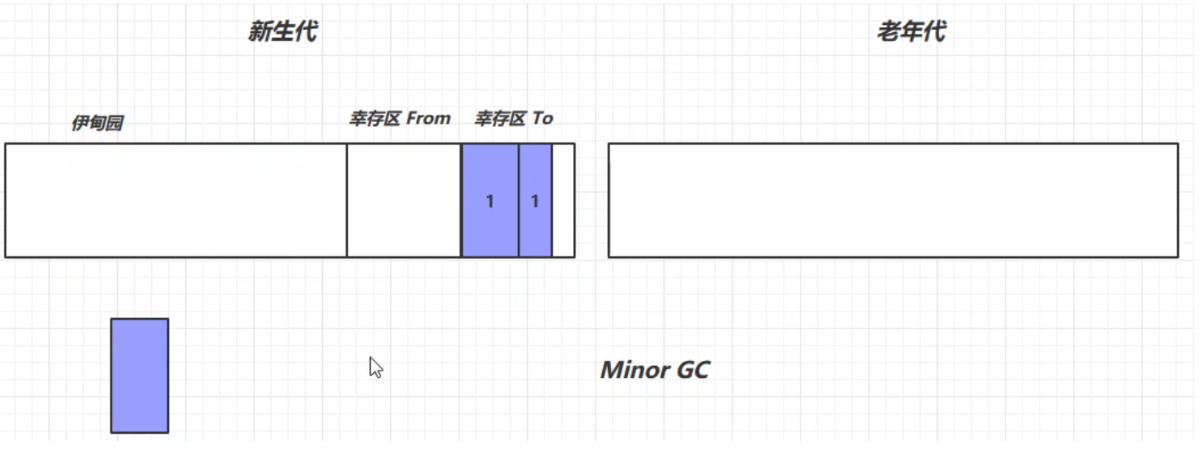
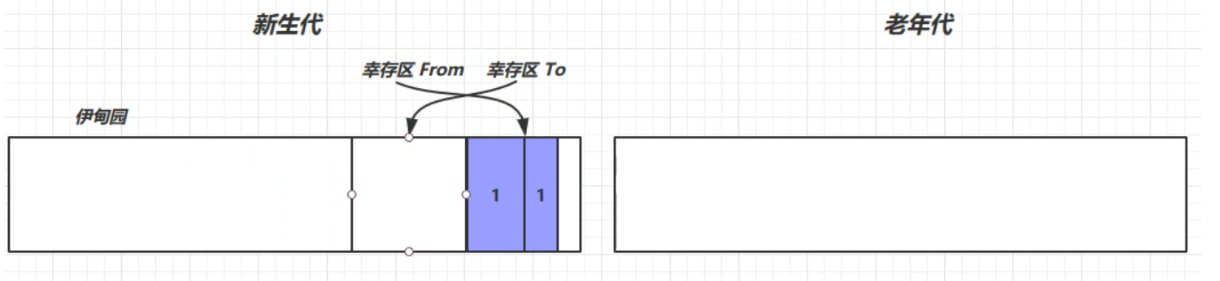
再次創建對象,若新生代的伊甸園又滿了,則會再次觸發 Minor GC(會觸發 stop the world, 暫停其他用戶線程,只讓垃圾回收線程工作),這時不僅會回收伊甸園中的垃圾,還會回收幸存區中的垃圾,再將活躍對象複製到幸存區TO中。回收以後會交換兩個幸存區,並讓幸存區中的對象壽命加1
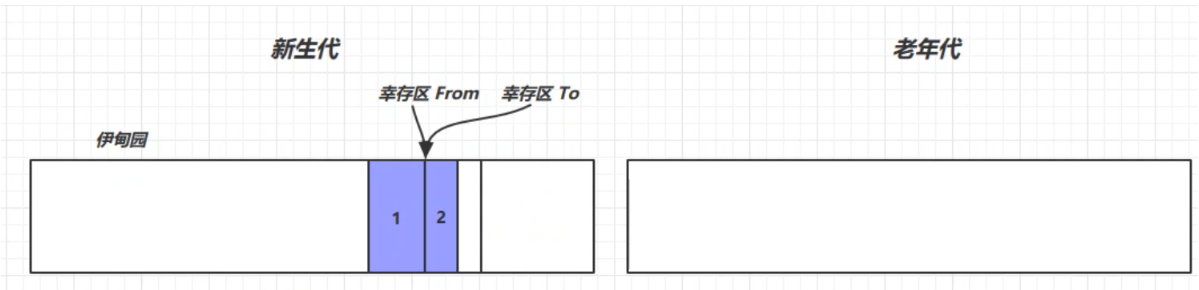
如果幸存區中的對象的壽命超過某個閾值(最大為15,4bit),就會被放入老年代中
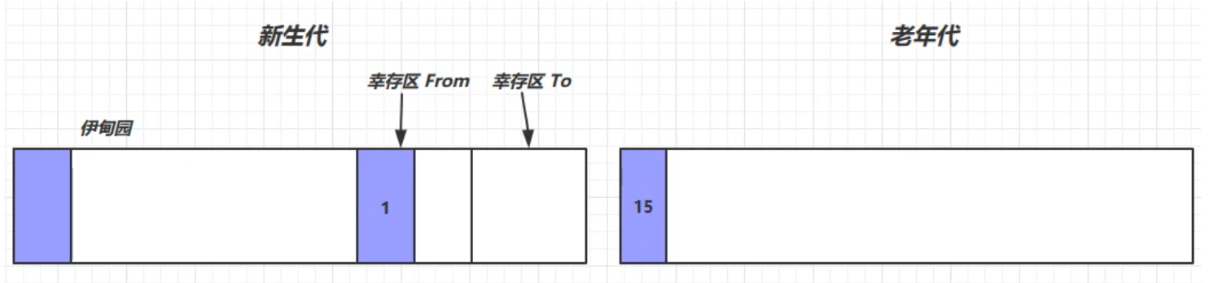
如果新生代老年代中的記憶體都滿了,就會先觸發Minor GC,再觸發Full GC,掃描新生代和老年代中所有不再使用的對象並回收
GC 分析
大對象處理策略
當遇到一個較大的對象時,就算新生代的伊甸園為空,也無法容納該對象時,會將該對象直接晉升為老年代
線程記憶體溢出
某個線程的記憶體溢出了而拋異常(out of memory),不會讓其他的線程結束運行
這是因為當一個線程拋出OOM異常後,它所占據的記憶體資源會全部被釋放掉,從而不會影響其他線程的運行,進程依然正常
4、垃圾回收器
相關概念
並行收集:指多條垃圾收集線程並行工作,但此時用戶線程仍處於等待狀態。
併發收集:指用戶線程與垃圾收集線程同時工作(不一定是並行的可能會交替執行)。用戶程式在繼續運行,而垃圾收集程式運行在另一個CPU上
吞吐量:即CPU用於運行用戶代碼的時間與CPU總消耗時間的比值(吞吐量 = 運行用戶代碼時間 / ( 運行用戶代碼時間 + 垃圾收集時間 )),也就是。例如:虛擬機共運行100分鐘,垃圾收集器花掉1分鐘,那麼吞吐量就是99%
串列
- 單線程
- 記憶體較小,個人電腦(CPU核數較少)
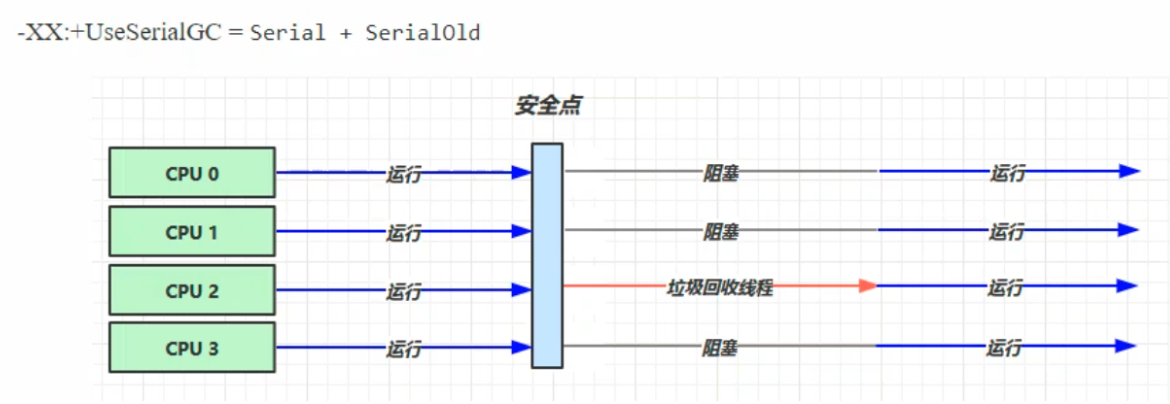
安全點:讓其他線程都在這個點停下來,以免垃圾回收時移動對象地址,使得其他線程找不到被移動的對象
因為是串列的,所以只有一個垃圾回收線程。且在該線程執行回收工作時,其他線程進入阻塞狀態
Serial 收集器
Serial收集器是最基本的、發展歷史最悠久的收集器
特點:單線程、簡單高效(與其他收集器的單線程相比),採用複製演算法。對於限定單個CPU的環境來說,Serial收集器由於沒有線程交互的開銷,專心做垃圾收集自然可以獲得最高的單線程手機效率。收集器進行垃圾回收時,必須暫停其他所有的工作線程,直到它結束(Stop The World)
ParNew 收集器
ParNew收集器其實就是Serial收集器的多線程版本
特點:多線程、ParNew收集器預設開啟的收集線程數與CPU的數量相同,在CPU非常多的環境中,可以使用-XX:ParallelGCThreads參數來限制垃圾收集的線程數。和Serial收集器一樣存在Stop The World問題
Serial Old 收集器
Serial Old是Serial收集器的老年代版本
特點:同樣是單線程收集器,採用標記-整理演算法
吞吐量優先
- 多線程
- 堆記憶體較大,多核CPU
- 單位時間內,STW(stop the world,停掉其他所有工作線程)時間最短
- JDK1.8預設使用的垃圾回收器
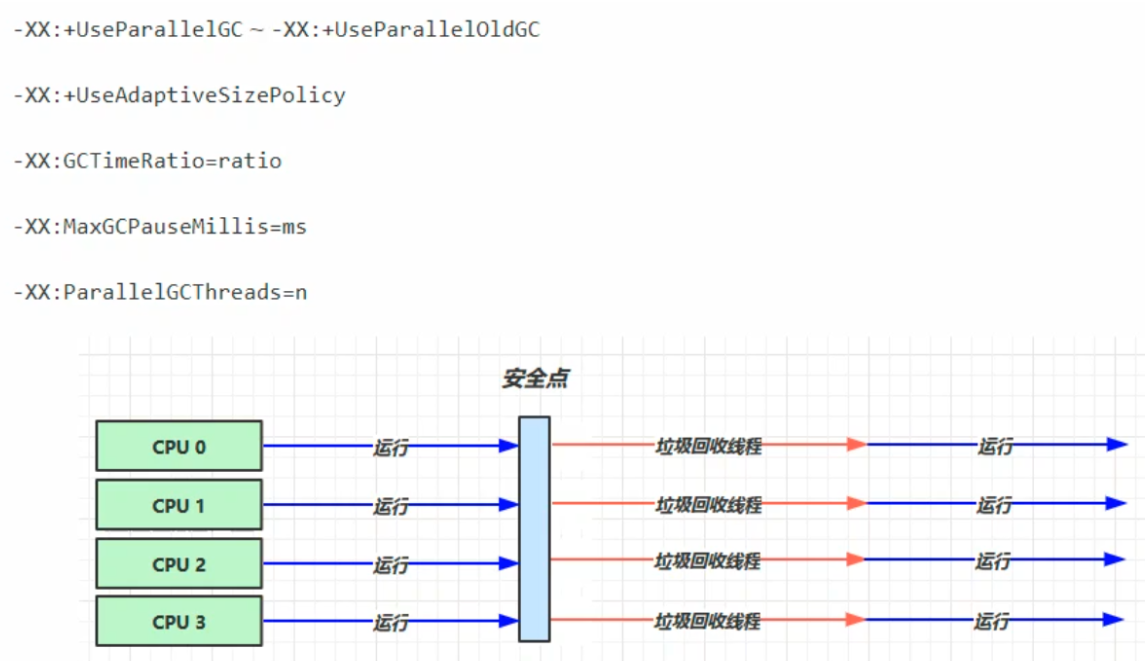
Parallel Scavenge 收集器
與吞吐量關係密切,故也稱為吞吐量優先收集器
特點:屬於新生代收集器也是採用複製演算法的收集器(用到了新生代的幸存區),又是並行的多線程收集器(與ParNew收集器類似)
該收集器的目標是達到一個可控制的吞吐量。還有一個值得關註的點是:GC自適應調節策略(與ParNew收集器最重要的一個區別)
GC自適應調節策略:Parallel Scavenge收集器可設置-XX:+UseAdptiveSizePolicy參數。當開關打開時不需要手動指定新生代的大小(-Xmn)、Eden與Survivor區的比例(-XX:SurvivorRation)、晉升老年代的對象年齡(-XX:PretenureSizeThreshold)等,虛擬機會根據系統的運行狀況收集性能監控信息,動態設置這些參數以提供最優的停頓時間和最高的吞吐量,這種調節方式稱為GC的自適應調節策略。
Parallel Scavenge收集器使用兩個參數控制吞吐量:
- XX:MaxGCPauseMillis 控制最大的垃圾收集停頓時間
- XX:GCRatio 直接設置吞吐量的大小
Parallel Old 收集器
是Parallel Scavenge收集器的老年代版本
特點:多線程,採用標記-整理演算法(老年代沒有幸存區)
響應時間優先
- 多線程
- 堆記憶體較大,多核CPU
- 儘可能讓單次STW時間變短(儘量不影響其他線程運行)
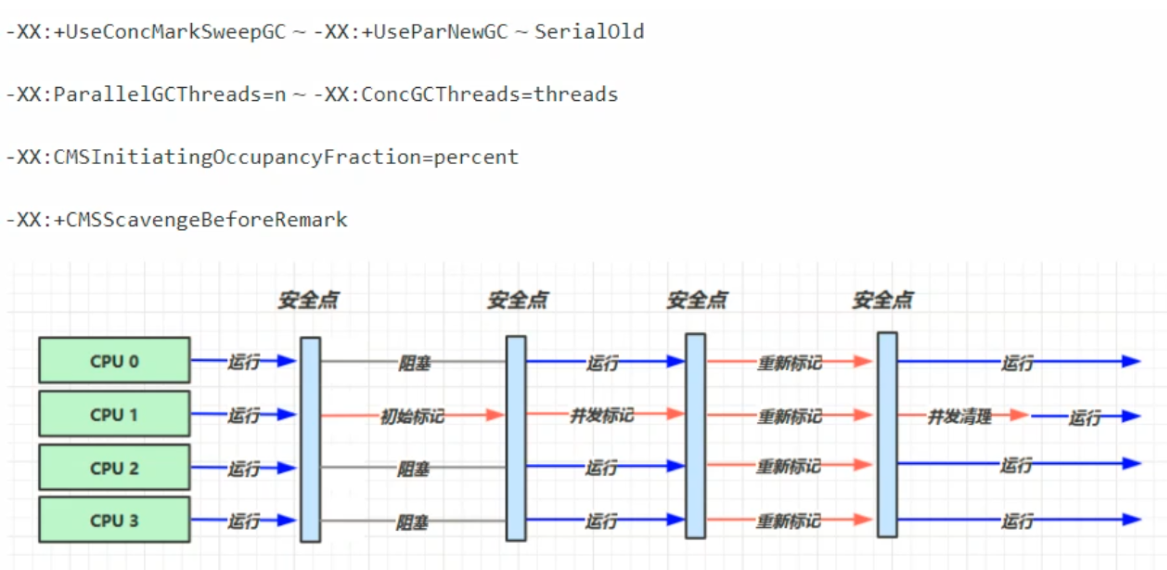
CMS 收集器
Concurrent Mark Sweep,一種以獲取最短回收停頓時間為目標的老年代收集器
特點:基於標記-清除演算法實現。併發收集、低停頓,但是會產生記憶體碎片
應用場景:適用於註重服務的響應速度,希望系統停頓時間最短,給用戶帶來更好的體驗等場景下。如web程式、b/s服務
CMS收集器的運行過程分為下列4步:
初始標記:標記GC Roots直接關聯的對象
併發標記:遍歷整個對象圖
重新標記:修正併發標記期間由於用戶線程運作而標記產生變動的那一部分對象。仍然存在Stop The World問題
併發清除:對標記的對象進行清除回收
CMS收集器的記憶體回收過程是與用戶線程一起併發執行的
G1
定義:
Garbage First
JDK 9以後預設使用,而且替代了CMS 收集器
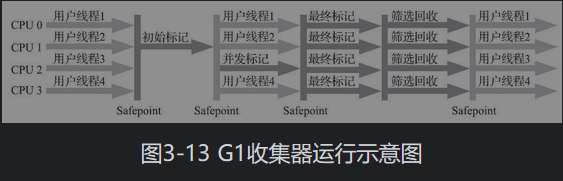
適用場景
- 同時註重吞吐量和低延遲(響應時間)
- 超大堆記憶體(記憶體大的),會將堆記憶體劃分為多個大小相等的區域
- 整體上是標記-整理演算法,兩個區域之間是複製演算法
相關參數:JDK8 並不是預設開啟的,所需要參數開啟

G1垃圾回收階段

新生代伊甸園垃圾回收—–>記憶體不足,新生代回收+併發標記—–>回收新生代伊甸園、幸存區、老年代記憶體——>新生代伊甸園垃圾回收(重新開始)
Young Collection
分區演算法region
分代是按對象的生命周期劃分,分區則是將堆空間劃分連續幾個不同小區間,每一個小區間獨立回收,可以控制一次回收多少個小區間,方便控制 GC 產生的停頓時間
E:伊甸園 S:幸存區 O:老年代
- 會STW
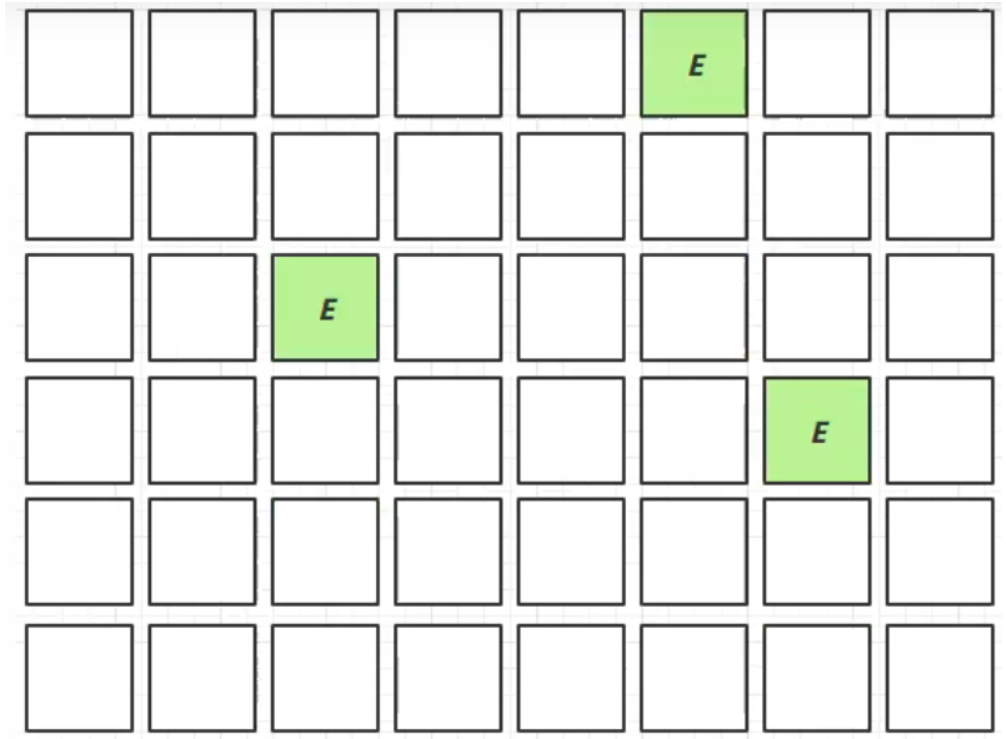
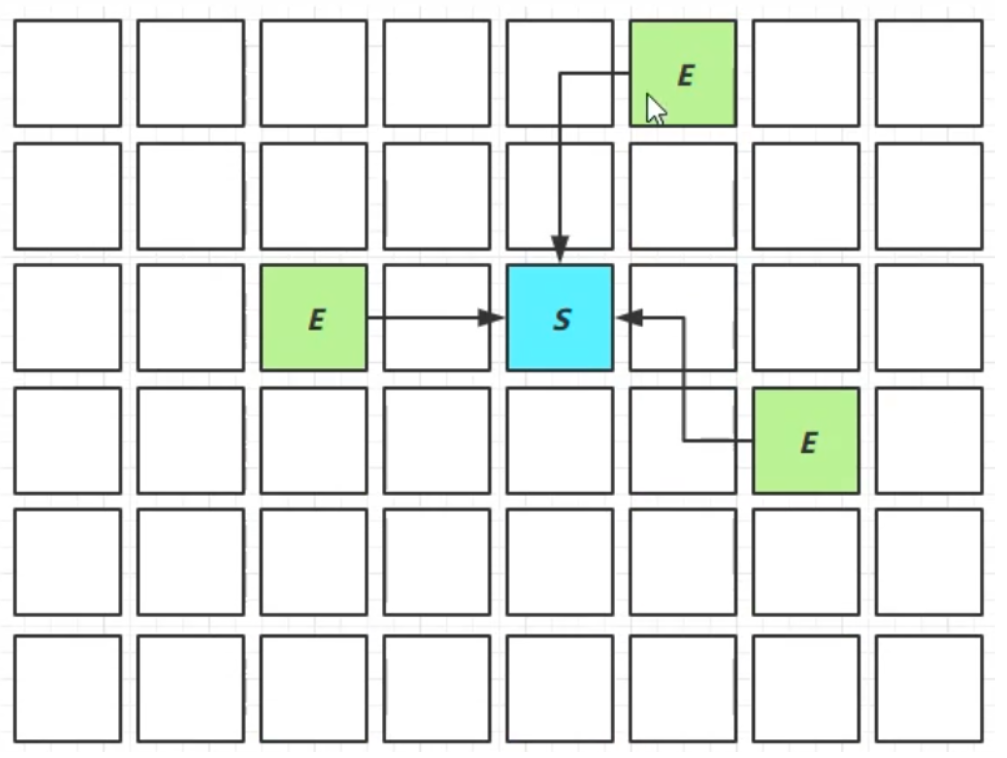
Young Collection + CM
CM:併發標記
- 在 Young GC 時會對 GC Root 進行初始標記
- 在老年代占用堆記憶體的比例達到閾值時,對進行併發標記(不會STW),閾值可以根據用戶來進行設定
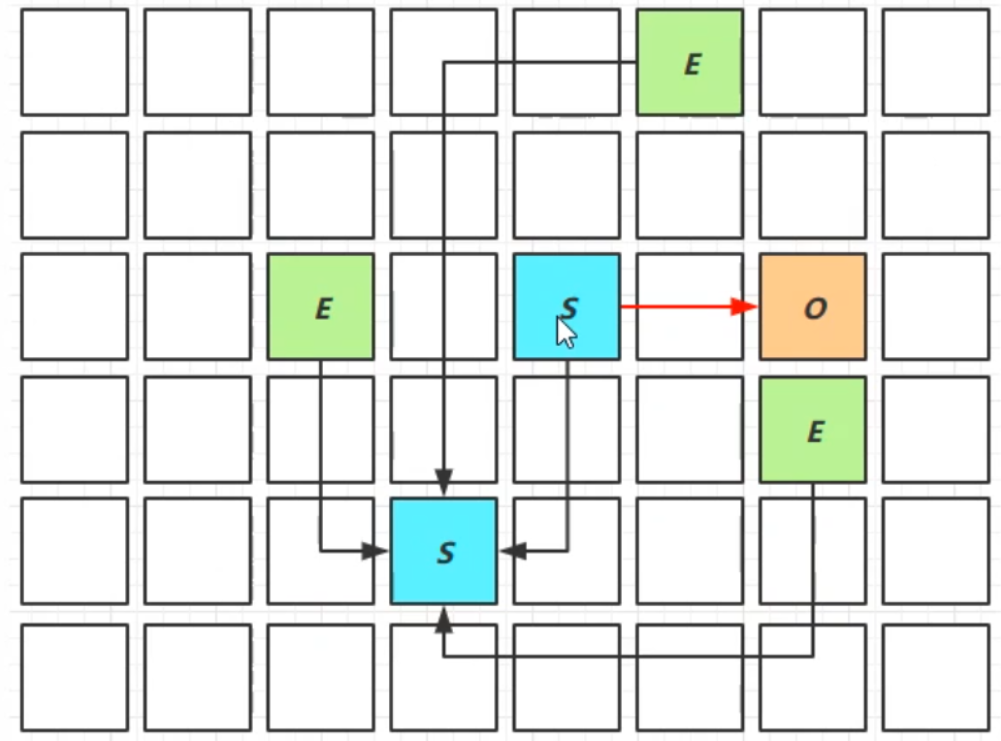
Mixed Collection
會對E S O 進行全面的回收
- 最終標記
- 拷貝存活
-XX:MaxGCPauseMills:xxx 用於指定最長的停頓時間
為什麼不是所有的老年代會被回收?
因為指定了最大停頓時間,如果對所有老年代都進行回收,耗時可能過高。為了保證時間不超過設定的停頓時間,會回收最有價值的老年代(回收後,能夠得到更多記憶體)
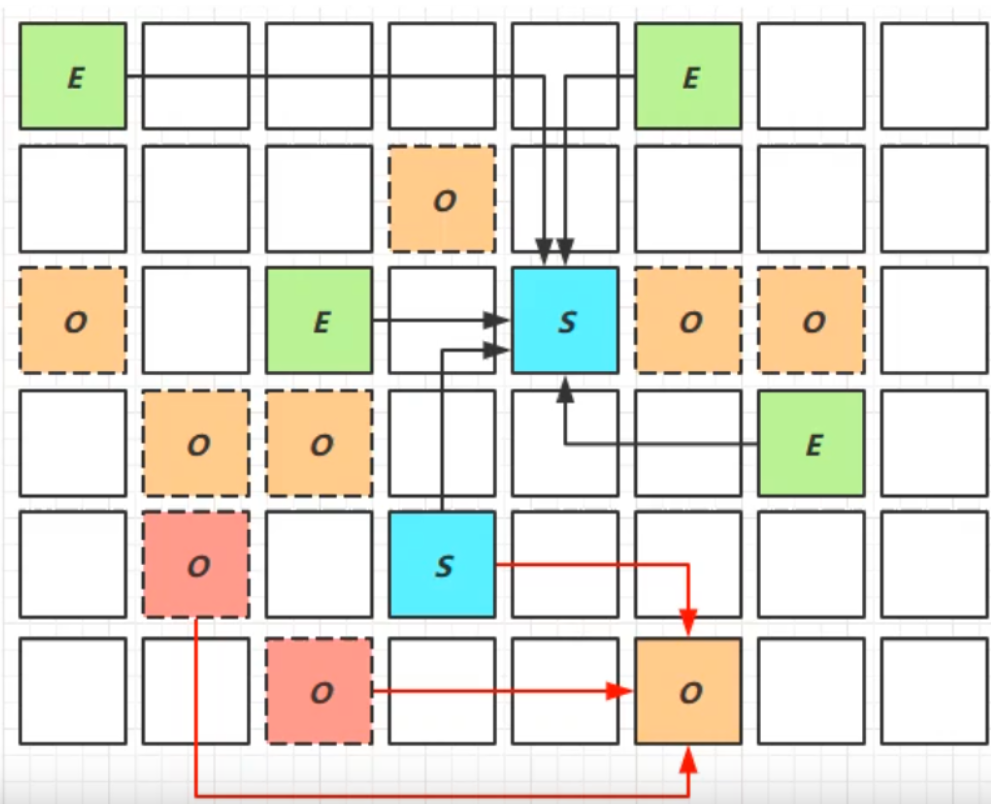
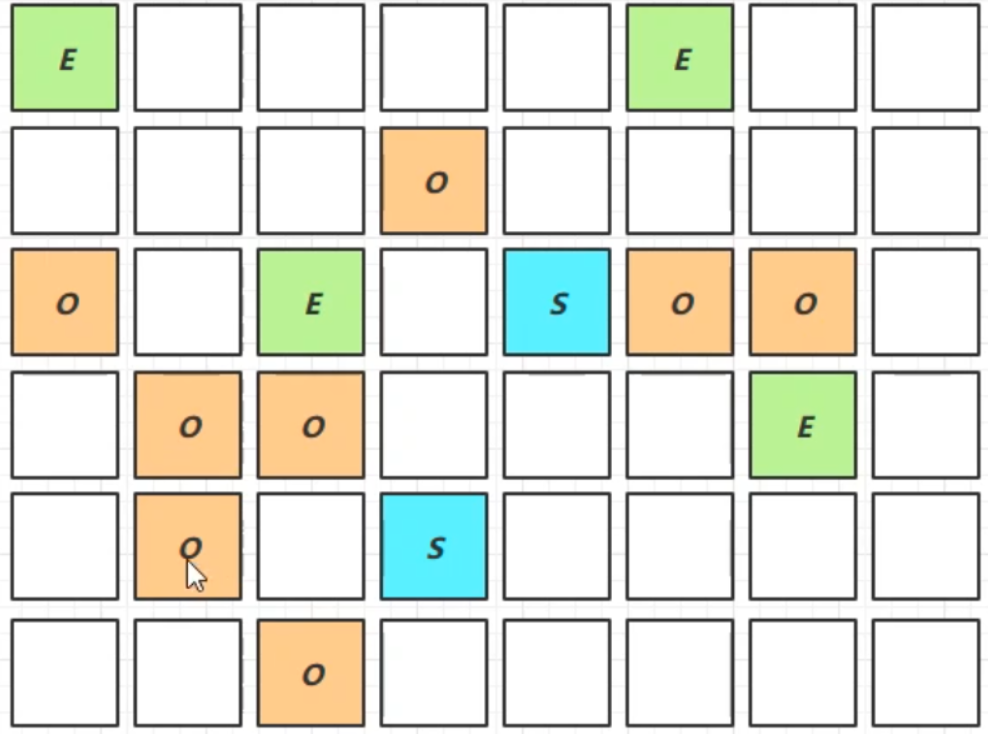
Full GC
G1在老年代記憶體不足時(老年代所占記憶體超過閾值)
- 如果垃圾產生速度慢於垃圾回收速度,不會觸發Full GC,還是併發地進行清理
- 如果垃圾產生速度快於垃圾回收速度,便會觸發Full GC
5、GC 調優
查看虛擬機參數命令
"F:\JAVA\JDK8.0\bin\java" -XX:+PrintFlagsFinal -version | findstr "GC"Copy
可以根據參數去查詢具體的信息
調優領域
- 記憶體
- 鎖競爭
- CPU占用
- IO
- GC
確定目標
低延遲/高吞吐量? 選擇合適的GC
- CMS G1 ZGC
- ParallelGC
- Zing
最快的GC是不發生GC
首先排除減少因為自身編寫的代碼而引發的記憶體問題
- 查看Full GC前後的記憶體占用,考慮以下幾個問題
- 數據是不是太多?
- 數據表示是否太臃腫
- 對象圖
- 對象大小
- 是否存在記憶體泄漏
新生代調優
- 新生代的特點
- 所有的new操作分配記憶體都是非常廉價的
- TLAB
- 死亡對象回收零代價
- 大部分對象用過即死(朝生夕死)
- MInor GC 所用時間遠小於Full GC
- 所有的new操作分配記憶體都是非常廉價的
- 新生代記憶體越大越好麽?
- 不是
- 新生代記憶體太小:頻繁觸發Minor GC,會STW,會使得吞吐量下降
- 新生代記憶體太大:老年代記憶體占比有所降低,會更頻繁地觸發Full GC。而且觸發Minor GC時,清理新生代所花費的時間會更長
- 新生代記憶體設置為內容納[併發量*(請求-響應)]的數據為宜
- 不是
幸存區調優
- 幸存區需要能夠保存 當前活躍對象+需要晉升的對象
- 晉升閾值配置得當,讓長時間存活的對象儘快晉升
老年代調優
四、類載入與位元組碼技術
1、類文件結構
首先獲得.class位元組碼文件
方法:
- 在文本文檔里寫入java代碼(文件名與類名一致),將文件類型改為.java
- java終端中,執行javac X:…\XXX.java

以下是位元組碼文件
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
0000020 00 16 00 17 08 00 18 0a 00 19 00 1a 07 00 1b 07
0000040 00 1c 01 00 06 3c 69 6e 69 74 3e 01 00 03 28 29
0000060 56 01 00 04 43 6f 64 65 01 00 0f 4c 69 6e 65 4e
0000100 75 6d 62 65 72 54 61 62 6c 65 01 00 12 4c 6f 63
0000120 61 6c 56 61 72 69 61 62 6c 65 54 61 62 6c 65 01
0000140 00 04 74 68 69 73 01 00 1d 4c 63 6e 2f 69 74 63
0000160 61 73 74 2f 6a 76 6d 2f 74 35 2f 48 65 6c 6c 6f
0000200 57 6f 72 6c 64 3b 01 00 04 6d 61 69 6e 01 00 16
0000220 28 5b 4c 6a 61 76 61 2f 6c 61 6e 67 2f 53 74 72
0000240 69 6e 67 3b 29 56 01 00 04 61 72 67 73 01 00 13
0000260 5b 4c 6a 61 76 61 2f 6c 61 6e 67 2f 53 74 72 69
0000300 6e 67 3b 01 00 10 4d 65 74 68 6f 64 50 61 72 61
0000320 6d 65 74 65 72 73 01 00 0a 53 6f 75 72 63 65 46
0000340 69 6c 65 01 00 0f 48 65 6c 6c 6f 57 6f 72 6c 64
0000360 2e 6a 61 76 61 0c 00 07 00 08 07 00 1d 0c 00 1e
0000400 00 1f 01 00 0b 68 65 6c 6c 6f 20 77 6f 72 6c 64
0000420 07 00 20 0c 00 21 00 22 01 00 1b 63 6e 2f 69 74
0000440 63 61 73 74 2f 6a 76 6d 2f 74 35 2f 48 65 6c 6c
0000460 6f 57 6f 72 6c 64 01 00 10 6a 61 76 61 2f 6c 61
0000500 6e 67 2f 4f 62 6a 65 63 74 01 00 10 6a 61 76 61
0000520 2f 6c 61 6e 67 2f 53 79 73 74 65 6d 01 00 03 6f
0000540 75 74 01 00 15 4c 6a 61 76 61 2f 69 6f 2f 50 72
0000560 69 6e 74 53 74 72 65 61 6d 3b 01 00 13 6a 61 76
0000600 61 2f 69 6f 2f 50 72 69 6e 74 53 74 72 65 61 6d
0000620 01 00 07 70 72 69 6e 74 6c 6e 01 00 15 28 4c 6a
0000640 61 76 61 2f 6c 61 6e 67 2f 53 74 72 69 6e 67 3b
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
0000700 00 07 00 08 00 01 00 09 00 00 00 2f 00 01 00 01
0000720 00 00 00 05 2a b7 00 01 b1 00 00 00 02 00 0a 00
0000740 00 00 06 00 01 00 00 00 04 00 0b 00 00 00 0c 00
0000760 01 00 00 00 05 00 0c 00 0d 00 00 00 09 00 0e 00
0001000 0f 00 02 00 09 00 00 00 37 00 02 00 01 00 00 00
0001020 09 b2 00 02 12 03 b6 00 04 b1 00 00 00 02 00 0a
0001040 00 00 00 0a 00 02 00 00 00 06 00 08 00 07 00 0b
0001060 00 00 00 0c 00 01 00 00 00 09 00 10 00 11 00 00
0001100 00 12 00 00 00 05 01 00 10 00 00 00 01 00 13 00
0001120 00 00 02 00 14Copy
根據 JVM 規範,類文件結構如下
u4 magic
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];Copy
2、位元組碼指令
javap工具
Oracle 提供了 javap 工具來反編譯 class 文件
javap -v F:\Thread_study\src\com\nyima\JVM\day01\Main.classCopy
F:\Thread_study>javap -v F:\Thread_study\src\com\nyima\JVM\day5\Demo1.class
Classfile /F:/Thread_study/src/com/nyima/JVM/day5/Demo1.class
Last modified 2020-6-6; size 434 bytes
MD5 checksum df1dce65bf6fb0b4c1de318051f4a67e
Compiled from "Demo1.java"
public class com.nyima.JVM.day5.Demo1
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // hello world
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // com/nyima/JVM/day5/Demo1
#6 = Class #22 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 Demo1.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = Class #23 // java/lang/System
#17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;
#18 = Utf8 hello world
#19 = Class #26 // java/io/PrintStream
#20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V
#21 = Utf8 com/nyima/JVM/day5/Demo1
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/System
#24 = Utf8 out
#25 = Utf8 Ljava/io/PrintStream;
#26 = Utf8 java/io/PrintStream
#27 = Utf8 println
#28 = Utf8 (Ljava/lang/String;)V
{
public com.nyima.JVM.day5.Demo1();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 7: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String hello world
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 9: 0
line 10: 8
}Copy
通過位元組碼指令來分析問題
構造方法
cinit()V
public class Demo3 {
static int i = 10;
static {
i = 20;
}
static {
i = 30;
}
public static void main(String[] args) {
System.out.println(i); //結果為30
}
}Copy
編譯器會按從上至下的順序,收集所有 static 靜態代碼塊和靜態成員賦值的代碼,合併為一個特殊的方法 cinit()V :
stack=1, locals=0, args_size=0
0: bipush 10
2: putstatic #3 // Field i:I
5: bipush 20
7: putstatic #3 // Field i:I
10: bipush 30
12: putstatic #3 // Field i:I
15: returnCopy
init()V
public class Demo4 {
private String a = "s1";
{
b = 20;
}
private int b = 10;
{
a = "s2";
}
public Demo4(String a, int b) {
this.a = a;
this.b = b;
}
public static void main(String[] args) {
Demo4 d = new Demo4("s3", 30);
System.out.println(d.a);
System.out.println(d.b);
}
}Copy
編譯器會按從上至下的順序,收集所有 {} 代碼塊和成員變數賦值的代碼,形成新的構造方法,但原始構造方法內的代碼總是在後
Code:
stack=2, locals=3, args_size=3
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: ldc #2 // String s1
7: putfield #3 // Field a:Ljava/lang/String;
10: aload_0
11: bipush 20
13: putfield #4 // Field b:I
16: aload_0
17: bipush 10
19: putfield #4 // Field b:I
22: aload_0
23: ldc #5 // String s2
25: putfield #3 // Field a:Ljava/lang/String;
//原始構造方法在最後執行
28: aload_0
29: aload_1
30: putfield #3 // Field a:Ljava/lang/String;
33: aload_0
34: iload_2
35: putfield #4 // Field b:I
38: returnCopy
3、編譯期處理
所謂的 語法糖 ,其實就是指 java 編譯器把 *.java 源碼編譯為 *.class 位元組碼的過程中,自動生成和轉換的一些代碼,主要是為了減輕程式員的負擔,算是 java 編譯器給我們的一個額外福利
預設構造函數
public class Candy1 {
}Copy
經過編譯期優化後
public class Candy1 {
//這個無參構造器是java編譯器幫我們加上的
public Candy1() {
//即調用父類 Object 的無參構造方法,即調用 java/lang/Object." <init>":()V
super();
}
}Copy
自動拆裝箱
基本類型和其包裝類型的相互轉換過程,稱為拆裝箱
在JDK 5以後,它們的轉換可以在編譯期自動完成
public class Demo2 {
public static void main(String[] args) {
Integer x = 1;
int y = x;
}
}Copy
轉換過程如下
public class Demo2 {
public static void main(String[] args) {
//基本類型賦值給包裝類型,稱為裝箱
Integer x = Integer.valueOf(1);
//包裝類型賦值給基本類型,稱謂拆箱
int y = x.intValue();
}
}Copy
泛型集合取值
泛型也是在 JDK 5 開始加入的特性,但 java 在編譯泛型代碼後會執行 泛型擦除 的動作,即泛型信息在編譯為位元組碼之後就丟失了,實際的類型都當做了 Object 類型來處理:
public class Demo3 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(10);
Integer x = list.get(0);
}
}Copy
對應位元組碼
Code:
stack=2, locals=3, args_size=1
0: new #2 // class java/util/ArrayList
3: dup
4: invokespecial #3 // Method java/util/ArrayList."<init>":()V
7: astore_1
8: aload_1
9: bipush 10
11: invokestatic #4 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
//這裡進行了泛型擦除,實際調用的是add(Objcet o)
14: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
19: pop
20: aload_1
21: iconst_0
//這裡也進行了泛型擦除,實際調用的是get(Object o)
22: invokeinterface #6, 2 // InterfaceMethod java/util/List.get:(I)Ljava/lang/Object;
//這裡進行了類型轉換,將Object轉換成了Integer
27: checkcast #7 // class java/lang/Integer
30: astore_2
31: returnCopy
所以調用get函數取值時,有一個類型轉換的操作
Integer x = (Integer) list.get(0);Copy
如果要將返回結果賦值給一個int類型的變數,則還有自動拆箱的操作
int x = (Integer) list.get(0).intValue();Copy
可變參數
public class Demo4 {
public static void foo(String... args) {
//將args賦值給arr,可以看出String...實際就是String[]
String[] arr = args;
System.out.println(arr.length);
}
public static void main(String[] args) {
foo("hello", "world");
}
}Copy
可變參數 String… args 其實是一個 String[] args ,從代碼中的賦值語句中就可以看出來。 同 樣 java 編譯器會在編譯期間將上述代碼變換為:
public class Demo4 {
public Demo4 {}
public static void foo(String[] args) {
String[] arr = args;
System.out.println(arr.length);
}
public static void main(String[] args) {
foo(new String[]{"hello", "world"});
}
}Copy
註意,如果調用的是foo(),即未傳遞參數時,等價代碼為foo(new String[]{}),創建了一個空數組,而不是直接傳遞的null
foreach
public class Demo5 {
public static void main(String[] args) {
//數組賦初值的簡化寫法也是一種語法糖。
int[] arr = {1, 2, 3, 4, 5};
for(int x : arr) {
System.out.println(x);
}
}
}Copy
編譯器會幫我們轉換為
public class Demo5 {
public Demo5 {}
public static void main(String[] args) {
int[] arr = new int[]{1, 2, 3, 4, 5};
for(int i=0; i<arr.length; ++i) {
int x = arr[i];
System.out.println(x);
}
}
}Copy
如果是集合使用foreach
public class Demo5 {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
for (Integer x : list) {
System.out.println(x);
}
}
}Copy
集合要使用foreach,需要該集合類實現了Iterable介面,因為集合的遍歷需要用到迭代器Iterator
public class Demo5 {
public Demo5 {}
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
//獲得該集合的迭代器
Iterator<Integer> iterator = list.iterator();
while(iterator.hasNext()) {
Integer x = iterator.next();
System.out.println(x);
}
}
}Copy
switch字元串
public class Demo6 {
public static void main(String[] args) {
String str = "hello";
switch (str) {
case "hello" :
System.out.println("h");
break;
case "world" :
System.out.println("w");
break;
default:
break;
}
}
}Copy
在編譯器中執行的操作
public class Demo6 {
public Demo6() {
}
public static void main(String[] args) {
String str = "hello";
int x = -1;
//通過字元串的hashCode+value來判斷是否匹配
switch (str.hashCode()) {
//hello的hashCode
case 99162322 :
//再次比較,因為字元串的hashCode有可能相等
if(str.equals("hello")) {
x = 0;
}
break;
//world的hashCode
case 11331880 :
if(str.equals("world")) {
x = 1;
}
break;
default:
break;
}
//用第二個switch在進行輸出判斷
switch (x) {
case 0:
System.out.println("h");
break;
case 1:
System.out.println("w");
break;
default:
break;
}
}
}Copy
過程說明:
- 在編譯期間,單個的switch被分為了兩個
- 第一個用來匹配字元串,並給x賦值
- 字元串的匹配用到了字元串的hashCode,還用到了equals方法
- 使用hashCode是為了提高比較效率,使用equals是防止有hashCode衝突(如BM和C.)
- 第二個用來根據x的值來決定輸出語句
- 第一個用來匹配字元串,並給x賦值
switch枚舉
public class Demo7 {
public static void main(String[] args) {
SEX sex = SEX.MALE;
switch (sex) {
case MALE:
System.out.println("man");
break;
case FEMALE:
System.out.println("woman");
break;
default:
break;
}
}
}
enum SEX {
MALE, FEMALE;
}Copy
編譯器中執行的代碼如下
public class Demo7 {
/**
* 定義一個合成類(僅 jvm 使用,對我們不可見)
* 用來映射枚舉的 ordinal 與數組元素的關係
* 枚舉的 ordinal 表示枚舉對象的序號,從 0 開始
* 即 MALE 的 ordinal()=0,FEMALE 的 ordinal()=1
*/
static class $MAP {
//數組大小即為枚舉元素個數,裡面存放了case用於比較的數字
static int[] map = new int[2];
static {
//ordinal即枚舉元素對應所在的位置,MALE為0,FEMALE為1
map[SEX.MALE.ordinal()] = 1;
map[SEX.FEMALE.ordinal()] = 2;
}
}
public static void main(String[] args) {
SEX sex = SEX.MALE;
//將對應位置枚舉元素的值賦給x,用於case操作
int x = $MAP.map[sex.ordinal()];
switch (x) {
case 1:
System.out.println("man");
break;
case 2:
System.out.println("woman");
break;
default:
break;
}
}
}
enum SEX {
MALE, FEMALE;
}Copy
枚舉類
enum SEX {
MALE, FEMALE;
}Copy
轉換後的代碼
public final class Sex extends Enum<Sex> {
//對應枚舉類中的元素
public static final Sex MALE;
public static final Sex FEMALE;
private static final Sex[] $VALUES;
static {
//調用構造函數,傳入枚舉元素的值及ordinal
MALE = new Sex("MALE", 0);
FEMALE = new Sex("FEMALE", 1);
$VALUES = new Sex[]{MALE, FEMALE};
}
//調用父類中的方法
private Sex(String name, int ordinal) {
super(name, ordinal);
}
public static Sex[] values() {
return $VALUES.clone();
}
public static Sex valueOf(String name) {
return Enum.valueOf(Sex.class, name);
}
}Copy
匿名內部類
public class Demo8 {
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("running...");
}
};
}
}Copy
轉換後的代碼
public class Demo8 {
public static void main(String[] args) {
//用額外創建的類來創建匿名內部類對象
Runnable runnable = new Demo8$1();
}
}
//創建了一個額外的類,實現了Runnable介面
final class Demo8$1 implements Runnable {
public Demo8$1() {}
@Override
public void run() {
System.out.println("running...");
}
}Copy
如果匿名內部類中引用了局部變數
public class Demo8 {
public static void main(String[] args) {
int x = 1;
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(x);
}
};
}
}Copy
轉化後代碼
public class Demo8 {
public static void main(String[] args) {
int x = 1;
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(x);
}
};
}
}
final class Demo8$1 implements Runnable {
//多創建了一個變數
int val$x;
//變為了有參構造器
public Demo8$1(int x) {
this.val$x = x;
}
@Override
public void run() {
System.out.println(val$x);
}
}Copy
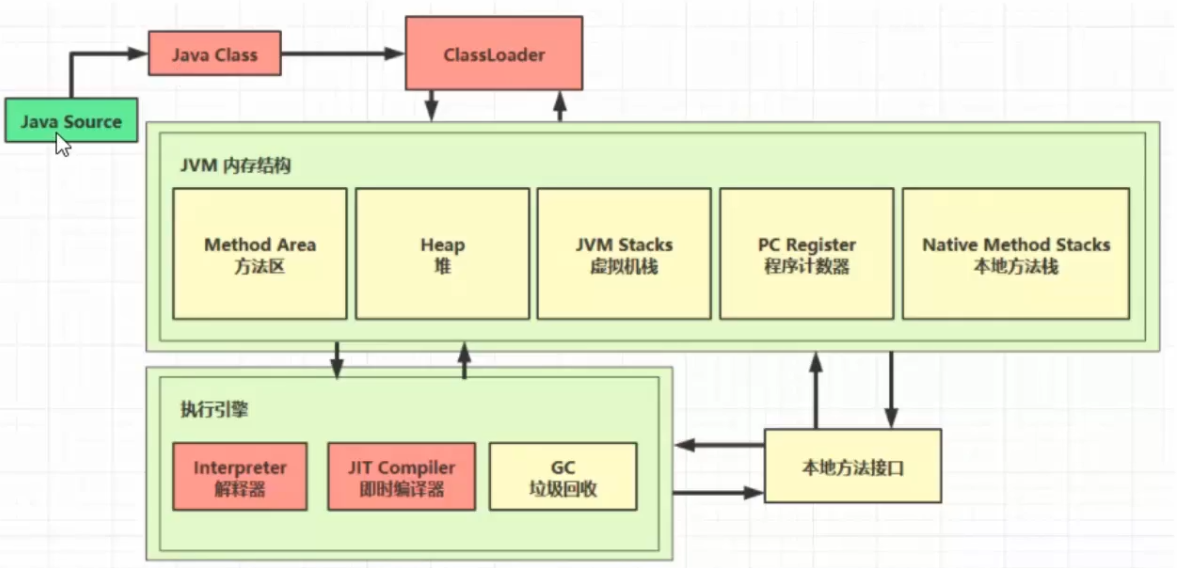
4、類載入階段
載入
-
將類的位元組碼載入
方法區
(1.8後為元空間,在本地記憶體中)中,內部採用 C++ 的 instanceKlass 描述 java 類,它的重要 field 有:
- _java_mirror 即 java 的類鏡像,例如對 String 來說,它的鏡像類就是 String.class,作用是把 klass 暴露給 java 使用
- _super 即父類
- _fields 即成員變數
- _methods 即方法
- _constants 即常量池
- _class_loader 即類載入器
- _vtable 虛方法表
- _itable 介面方法
-
如果這個類還有父類沒有載入,先載入父類
-
載入和鏈接可能是交替運行的
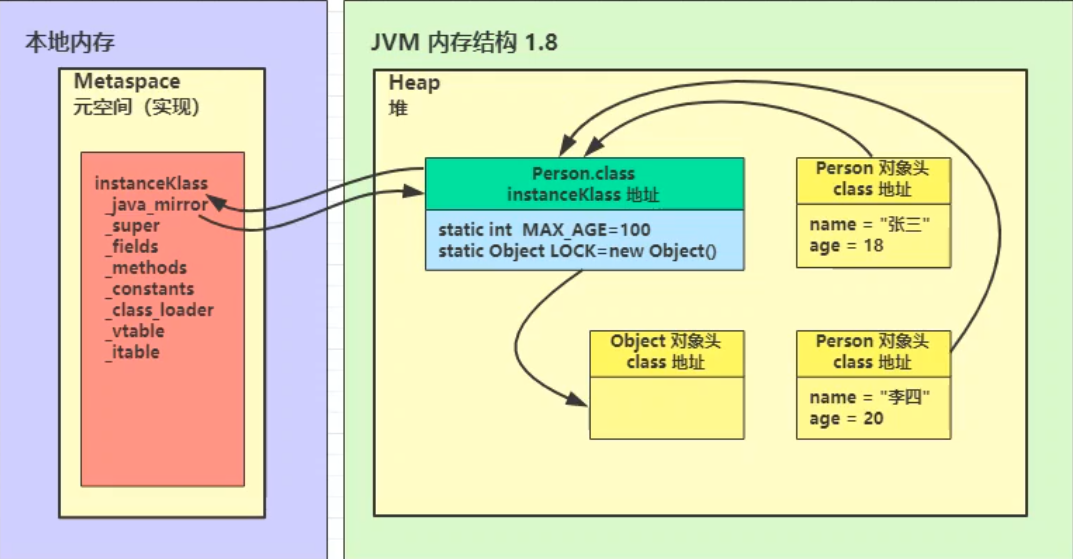
- instanceKlass保存在方法區。JDK 8以後,方法區位於元空間中,而元空間又位於本地記憶體中
- _java_mirror則是保存在堆記憶體中
- InstanceKlass和*.class(JAVA鏡像類)互相保存了對方的地址
- 類的對象在對象頭中保存了*.class的地址。讓對象可以通過其找到方法區中的instanceKlass,從而獲取類的各種信息
鏈接
驗證
驗證類是否符合 JVM規範,安全性檢查
準備
為 static 變數分配空間,設置預設值
- static變數在JDK 7以前是存儲與instanceKlass末尾。但在JDK 7以後就存儲在_java_mirror末尾了
- static變數在分配空間和賦值是在兩個階段完成的。分配空間在準備階段完成,賦值在初始化階段完成
- 如果 static 變數是 final 的基本類型,以及字元串常量,那麼編譯階段值就確定了,賦值在準備階段完成
- 如果 static 變數是 final 的,但屬於引用類型,那麼賦值也會在初始化階段完成
解析
將常量池中的符號引用解析為直接引用
- 未解析時,常量池中的看到的對象僅是符號,未真正的存在於記憶體中 <

