
大家好,我是小寒~ 今天給大家帶來一篇 flink 作業提交相關的文章。 我們都知道,在開發完一個 flink 應用程式後,打包成 jar 包,然後通過 FLink CLI 或者 Web UI 提交作業到 FLink 集群。其實,Flink 的 jar 文件並不是 FLink 集群的可執行文件,需要 ...
大家好,我是小寒~
今天給大家帶來一篇 flink 作業提交相關的文章。
我們都知道,在開發完一個 flink 應用程式後,打包成 jar 包,然後通過 FLink CLI 或者 Web UI 提交作業到 FLink 集群。其實,Flink 的 jar 文件並不是 FLink 集群的可執行文件,需要經過轉換之後提交給集群。其轉換過程分為兩個大的步驟。
- 在 FLink Client 中通過反射啟動 Jar 中的 main 函數,生成 Flink StreamGraph、JobGraph,將 JobGraph 提交給 Flink 集群。
- FLink 集群收到 JobGraph 之後,將 JobGraph 翻譯成 ExecutionGraph,然後開始調度執行,啟動成功之後開始消費數據。
總的來說,對用戶API的調用,可以轉換為 StreamGraph -> JobGraph -> ExecutionGraph -> 物理執行拓撲(Task DAG)
提交流程
FLink 作業在開發完畢之後,需要提交到 FLink 集群執行。ClientFrontend 是入口,觸發用戶開發的 Flink 應用 jar 文件中的 main 方法,然後交給 PipelineExecutor#execue 方法,最終會觸發一個具體的 PipelineExecutor 執行,如下圖所示。
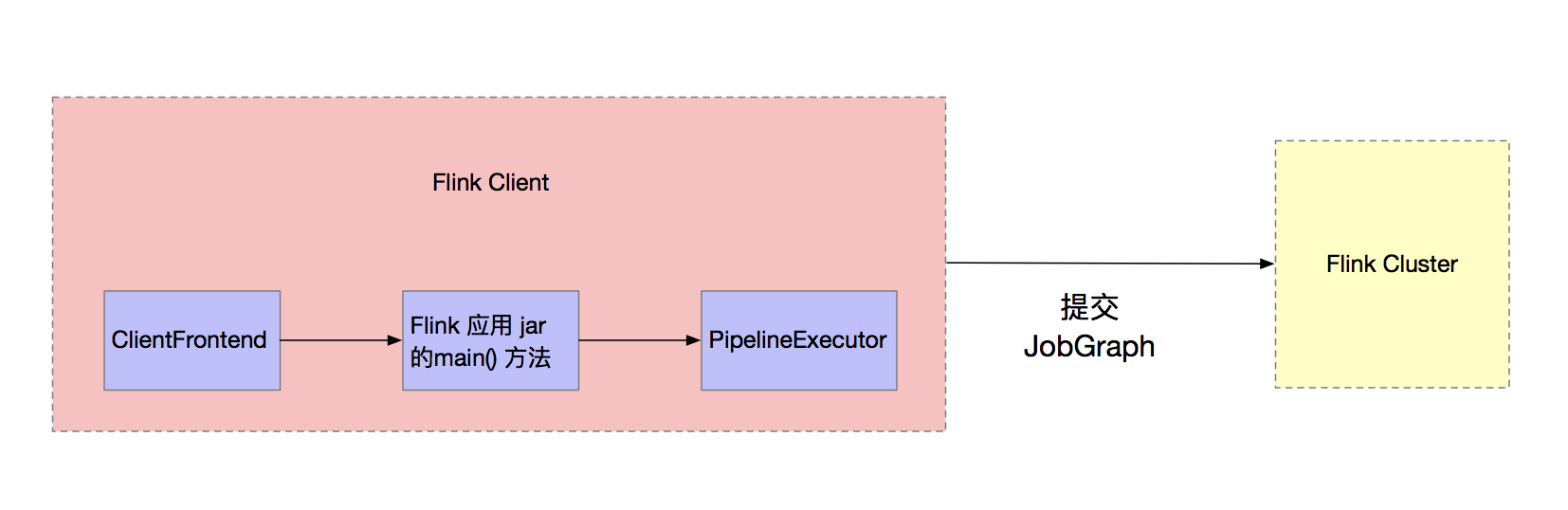
作業執行可以選擇 Session 和 Per-Job 模式兩種集群。
- Session 模式的集群,一個集群中運行多個作業。
- Per-Job 模式的集群,一個集群中只運行一個作業,作業執行完畢則集群銷毀。
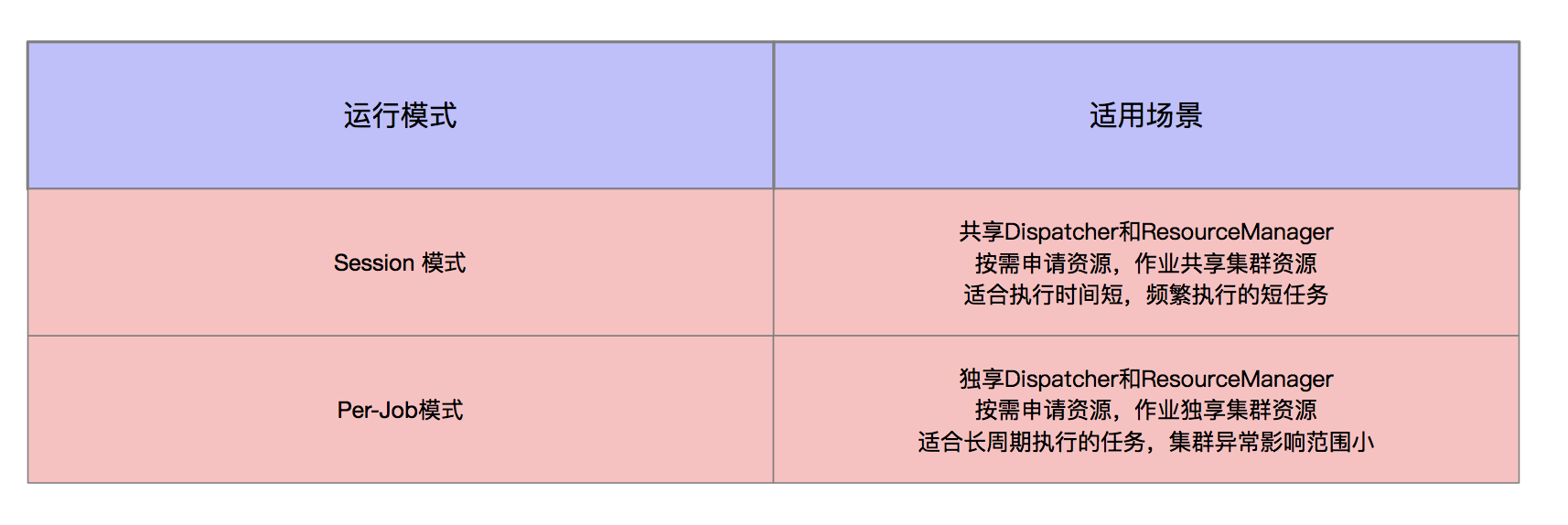
流水線執行器 PipelineExecutor
流水線執行器在 FLink 中叫作 PipelineExecutor,是 FLink Client 生成 JobGraph 之後,將作業提交給集群的重要環節。
集群有 Session 和 Per-Job 兩種模式。在這兩種模式下,集群的啟動時機、提交作業的方式不同,所以在生產環境中有兩種 PipelineExecutor。Session 模式對應於 AbstractSessionClusterExecutor,Per-Job 模式對應於 AbstractJobClusterExecutor。
- Session 模式
該模式下,作業共用集群資源,作業通過 Http 協議進行提交。
在 Flink 1.10 版本中提供了三種會話模式:Yarn 會話模式、K8s 會話模式、Standalone。Standalone 模式比較特別,Flink 安裝在物理機上,不能像在資源集群上一樣,可以隨時啟動一個新集群,所有的作業共用 Standalone 集群。
在 Session 模式下, Yarn 作業提交使用 yarn-session.sh 腳本, K8s 作業提交使用 kubernetes-session.sh 腳本。兩者的具體實現不同 ,但邏輯是類似的 ,在啟動腳本的時候就會檢查是否存在已經啟動好的 Flink Session 模式集群,如果沒有,則啟動一個 Flink Session 模式集群,然後在 PipelineExecutor 中,通過 Dispatcher 提供的 Rest 介面提交 JobGraph,Dispatcher 為每一個作業啟動一個 JobMaster,然後進入作業執行階段。
- Per-Job 模式
該模式下,一個作業一個集群,作業之間相互隔離。
在 FLink 1.10 版本中,只有 Yarn 上實現了 Per-Job 模式。
Per-Job 模式下,因為不需要共用集群,所以在 PipelineExecutor 中執行作業提交的時候,可以創建集群並將 JobGraph 以及所需要的文件等一同交給 Yarn 集群,Yarn 集群在容器中啟動 JobManager 進程,進行一系列的初始化動作,初始化完畢之後,從文件系統中獲取 JobGraph ,交給 Dispatcher。 之後的執行流程與 Session 模式下的執行流程相同。
yarn session 的提交流程
從總體上來說,在 Yarn 集群上使用 Session 模式提交 Flink 作業的過程分為 3 個階段。首先在 Yarn 上啟動 Flink Session 模式的集群;其次通過 Flink Client 提交作業 ,最後進行作業的調度執行。
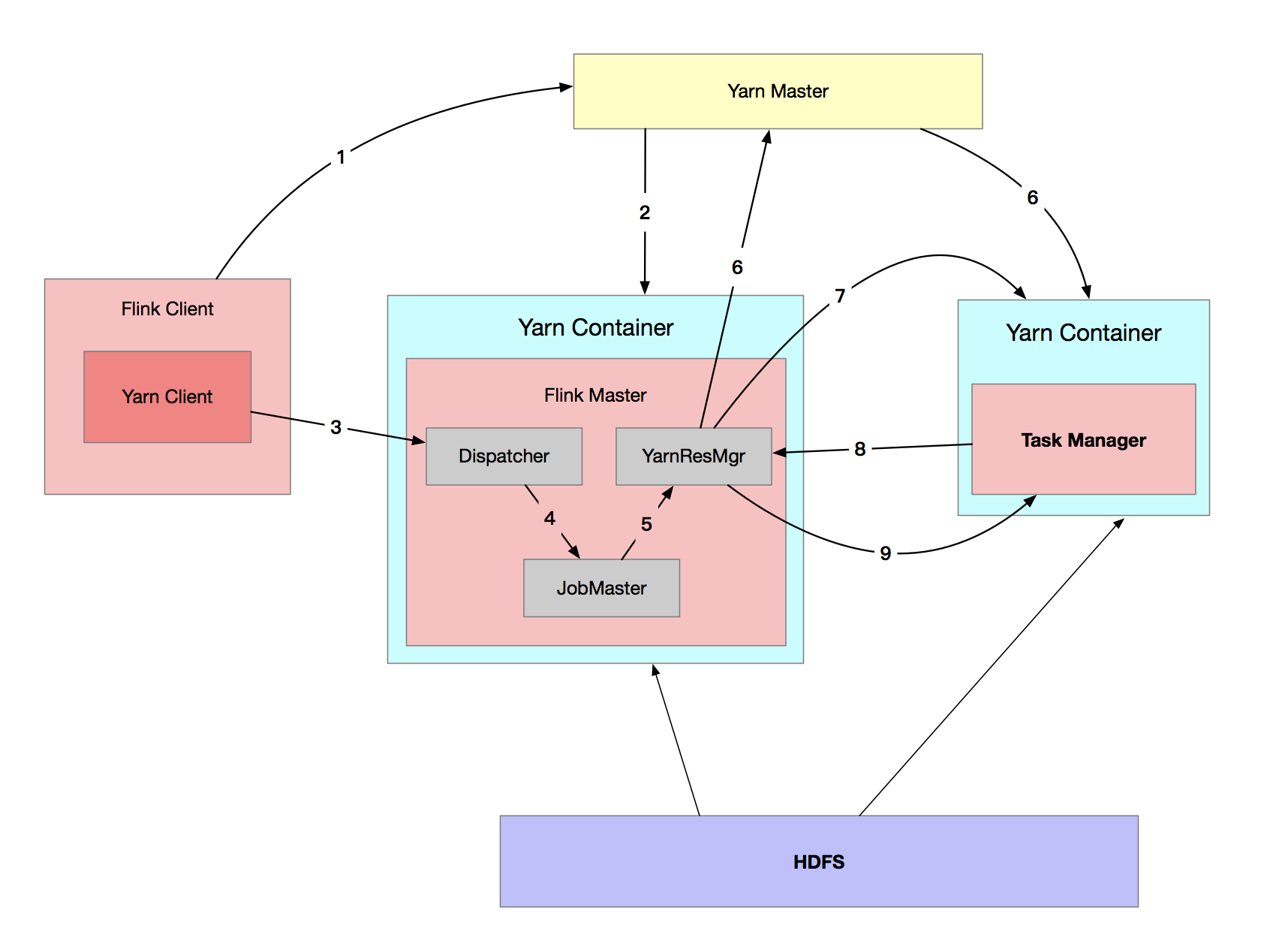
- 啟動集群
(1) 使用 yarn-session.sh 提交會話模式的作業
如果提交到已經存在的集群, 則獲取 Yarn 集群信息、應用 ID,並準備提交作業。
如果是啟動新的 Yarn Session 集群,則進入到步驟 (2)。
(2)Yarn 啟動新的 Flink 集群
如果沒有集群,則創建一個新的 Session 模式的集群。首先,將應用的配置文件(flink-conf.yaml、logback.xml、log4j.properties)和相關文件(Flink jar、用戶 jar 文件、JobGraph 對象等)上傳至分散式存儲(如 HDFS)的應用暫存目錄。
然後通過 Yarn Client 向 Yarn 提交 Flink 創建集群的申請,Yarn 分配資源,在申請的 Yarn Container 中初始化並啟動 FLink JobManager 進程,在 JobManager 進程中運行 YarnSessionClusterEntrypoint 作為集群啟動的入口(不同的集群部署模式有不同的 ClusterEntrypoint 的實現),初始化 Dispatcher、ResourceManager。啟動相關的 RPC 服務,等待 Client 通過 Rest 介面提交作業。
2、作業提交
Yarn 集群準備好後,開始作業提交。
(1)Flink Client 通過 Rest 向 Dispatcher 提交 JobGraph。
(2)Dispatcher 是 Rest 介面,不負責實際的調度、執行方面的工作,當收到 JobGraph 後,為作業創建一個 JobMaster,將工作交給 JobMaster(負責作業調度、管理作業和 Task 的生命周期 ),構建 ExecutionGraph(Job Graph的並行化版本)
- 作業調度執行
(1)JobMaster 向 YarnResourceManager 申請資源,開始調度 ExecutionGraph 的執行;初次提交作業,集群尚沒有 TaskManager,此時資源不足,開始申請資源。
(2)YarnResourceManager 收到 JobMaster 的資源請求,如果當前有空閑的 Slot,則將 Slot 分配給 JobMaster,否則 YarnResourceManager 將向 Yarn Master(Yarn 集群的 ResourceManager) 請求創建 TaskManager。
(3)YarnResourceManager 將資源請求加入等待請求隊列,並通過心跳向 YARN RM 申請新的 Container 資源來啟動 TaskManager 進程;Yarn 分配新的 Container 給 TaskManager。
(4)YarnResourceManager 從 HDFS 載入 Jar 文件等所需的相關資源,在容器中啟動 TaskManager。
(5)TaskManager 啟動之後,向 YarnResourceManager 進行註冊,並把自己的 Slot 資源情況彙報給 YarnResourceManager 。
(6)YarnResourceManager 從等待隊列中取出 Slot 請求,向 TaskManager 確認資源可用情況,並告知 TaskManager 將 Slot 分配給了哪個 JobMaster。
(7)TaskManager 向 JobMaster 提供 Slot,JobMaster 調度 Task 到 TaskManager 的此 Slot 上執行。
至此,作業進入執行階段。
Yarn Per-Job 提交流程
Yarn Per-Job 模式提交作業與 Yarn-Session 模式提交作業基本類似。Per-Job 模式下,JobGraph 和集群資源請求一起提交給 Yarn。
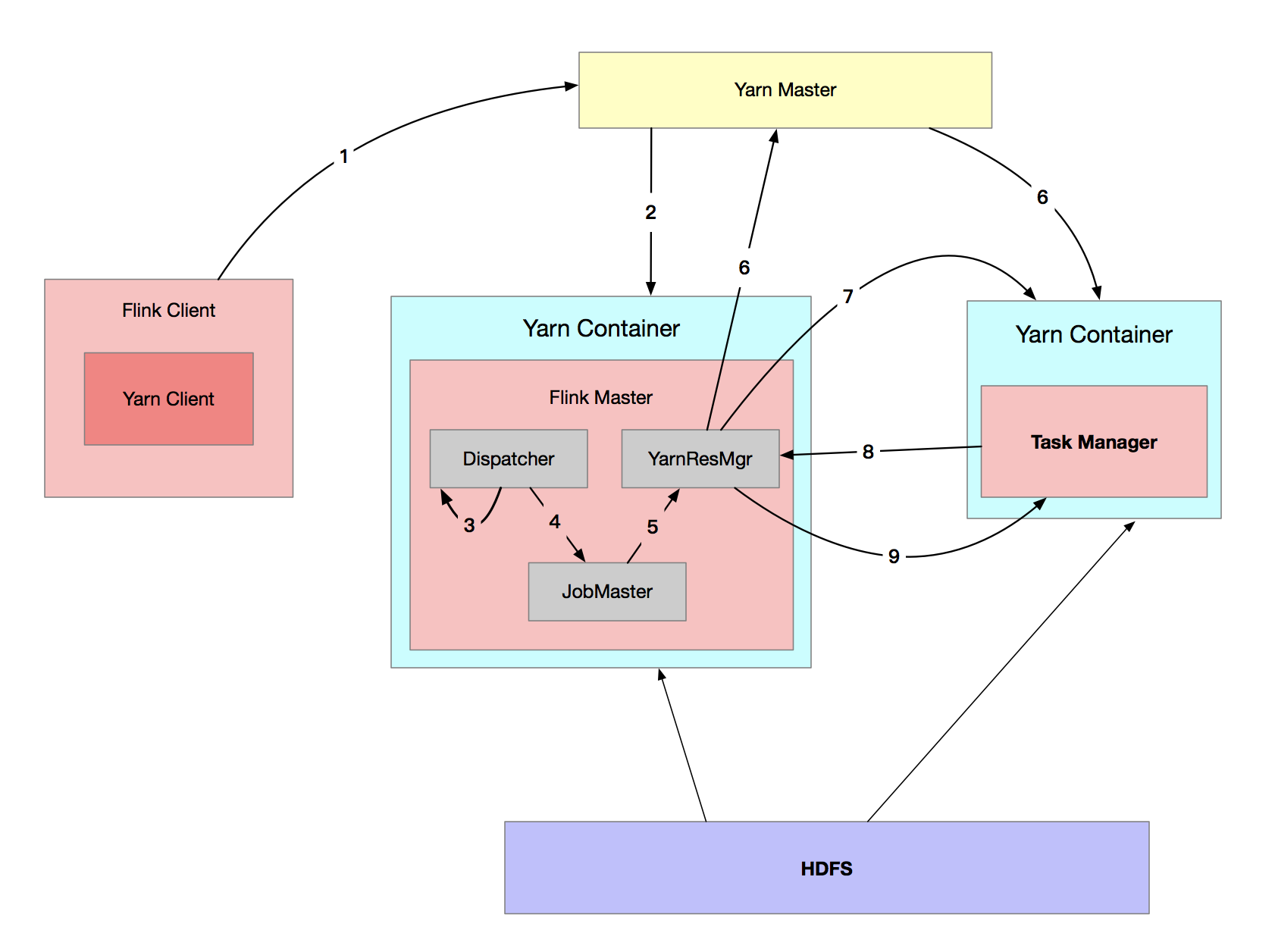
-
啟動集群
(1)使用 flink run -m yarn-cluster 提交 Per-Job 模式的作業。
(2)Yarn 啟動 Flink 集群。該模式下 Flink 集群的啟動入口是 YarnJobClusterEntryPoint,其它與 Yarn-Session 模式啟動類似。
-
作業提交
該步驟與 Session 模式下的不同之處在於,Client 並不會通過 Rest 向 Dispacher 提交 JobGraph,由 Dispacher 從本地文件系統獲取 JobGraph,其後的步驟與 Session 模式一樣。
-
作業調度執行
與 Yarn-Session 模式下一致。
流處理的轉換過程
StreamGraph
使用 DataStream API 開發的應用程式,首先被轉換為 Transformation,然後被映射為 StreamGraph。
我們以熟知的 WordCount 程式為例,它的 StreamGraph 如下圖所示。
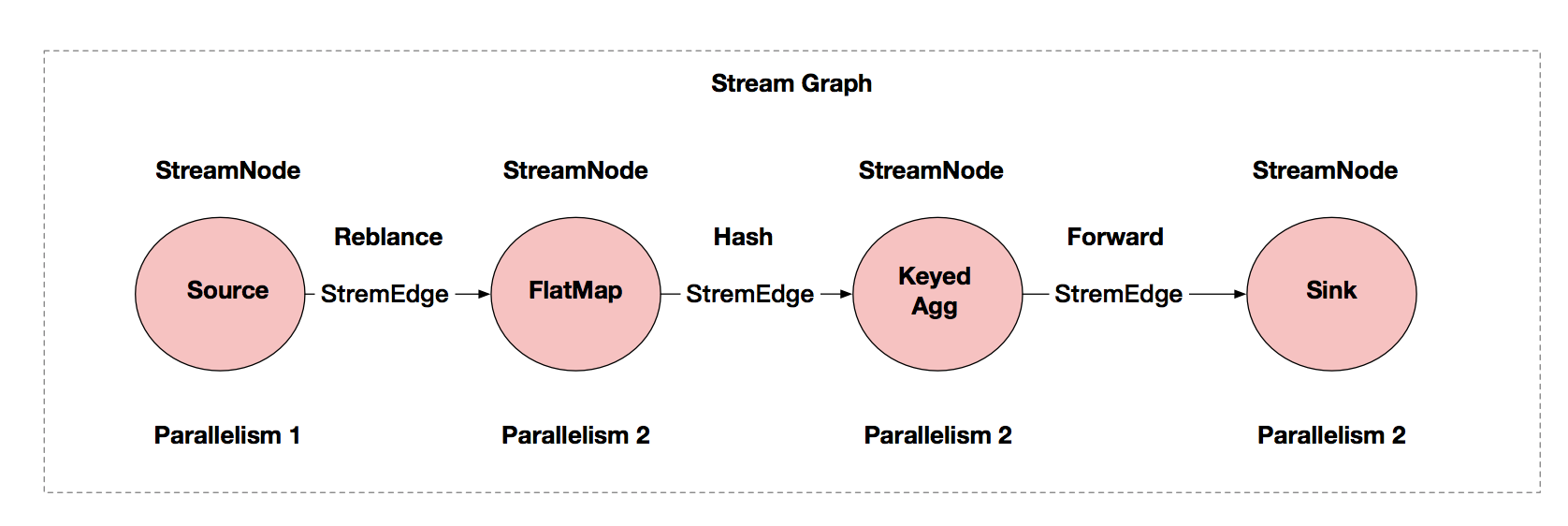
從圖中我們可以看到,StreamGraph 是由 StreamNode 和 StreamEdge 構成。
-
StreamNode
StreamNode 是 StreamGraph 中的節點,從 Transformation 轉換而來,可以簡單理解為一個 StreamNode 表示為一個運算元;從邏輯上來說,StreamNode 在 StreamGraph 中存在實體和虛擬的 StreamNode。StreamNode 可以有多個輸入,也可以有多個輸出。
實體的 StreamNode 會最終變為物理的運算元。虛擬的 StreamNode 會附著在 StreamEdge 上。
-
StreamEdge
StreamEdge 是 StreamGraph 中的邊, 用來連接兩個 StreamNode,一個 StreamNode 可以有多個出邊、入邊。 StreamEdge 中包含了盤路輸出、分區器、欄位篩選輸出等的信息。
作業圖
JobGraph 可以由流計算的 StreamGraph 轉換而來。
流計算中,在 StreamGraph 的基礎上進行了一些優化,如通過 OperatorChain 機制將運算元合併起來,在執行時,調度在同一個 Task 線程上,避免數據的跨線程、跨網路的傳遞。
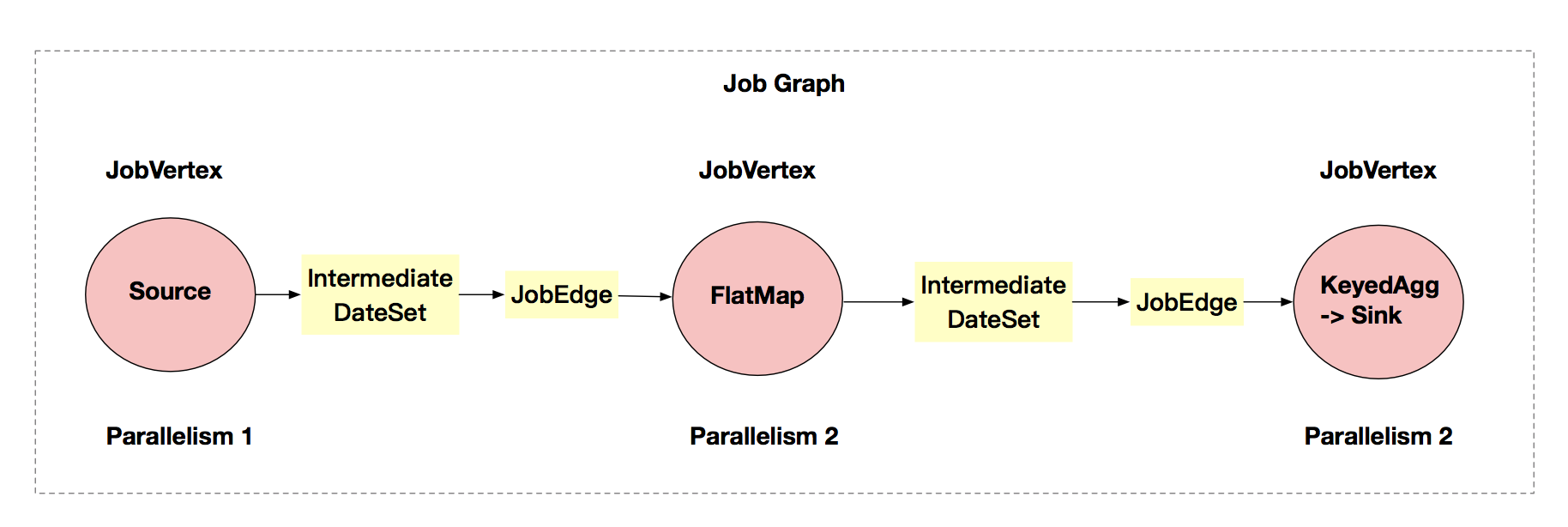
從 JobGraph 的圖裡可以看到,數據從上一個運算元流到下一個運算元的過程中,上游作為生產者提供了中間數據集(IntermediateDateSet),而下游作為消費者需要 JobEdge。JobEdge 是一個通信管道,連接了上游生產的中間數據集和 JobVertex 節點。
JobGraph 的核心對象是 JobVertex、JobEdge 和 IntermediateDateSet。
-
JobVertex
經過運算元融合優化後符合條件的多個 StreamNode 可能會融合在一起生成一個 JobVertex,即一個 JobVertex 包含一個或多個運算元,JobVertex 的輸入是 JobEdge,輸出是 IntermediateDateSet。
-
JobEdge
JobEdge 是 JobGraph 中連接 IntermediateDateSet 和 JobVertex 的邊,表示 JobGraph 中的一個數據流轉通道,其上游數據源是 IntermediateDateSet,下游消費者是 JobVertex ,即數據通過 JobEdge 由 IntermediateDateSet 傳遞給目標 JobVertex 。
JobEdge 中的數據分發模式會直接影響執行時 Task 之間的數據連接關係,是點對點連接還是全連接。
-
IntermediateDateSet
中間數據集 IntermediateDataSet 是一種邏輯結構,用來表示 JobVertex 的輸出,即該 JobVertex 中包含的運算元會產生的數據集。不同的執行模式下,其對應的結果分區類型不同,決定了在執行時刻數據交換的模式。
IntermediateDataSet 的個數與該 JobVertex 對應的 StreamNode 的出邊數量相同,可以是一個或者多個。
執行圖
ExecutionGraph 是調度 Flink 作業執行的核心數據結構,包含了作業中所有並行執行的 Task 的信息、Task 之間的關聯關係、數據流轉關係等。
StreamGraph、JobGraph 在 Flink 客戶端中生成,然後提交給 Flink 集群。JobGraph 到 ExecutionGraph 的轉換在 JobMaster 中完成。在轉化過程中,有如下重要變化。
- 加入了並行度的概念,成為真正可調度的圖結構。
- 生成了與 JobVertex 對應的 ExecutionJobVertex 和 ExecutionVertex,與IntermediateDataSet 對應的 IntermediateResult 和 IntermediateResultPartition 等。
生成的圖如下圖所示。
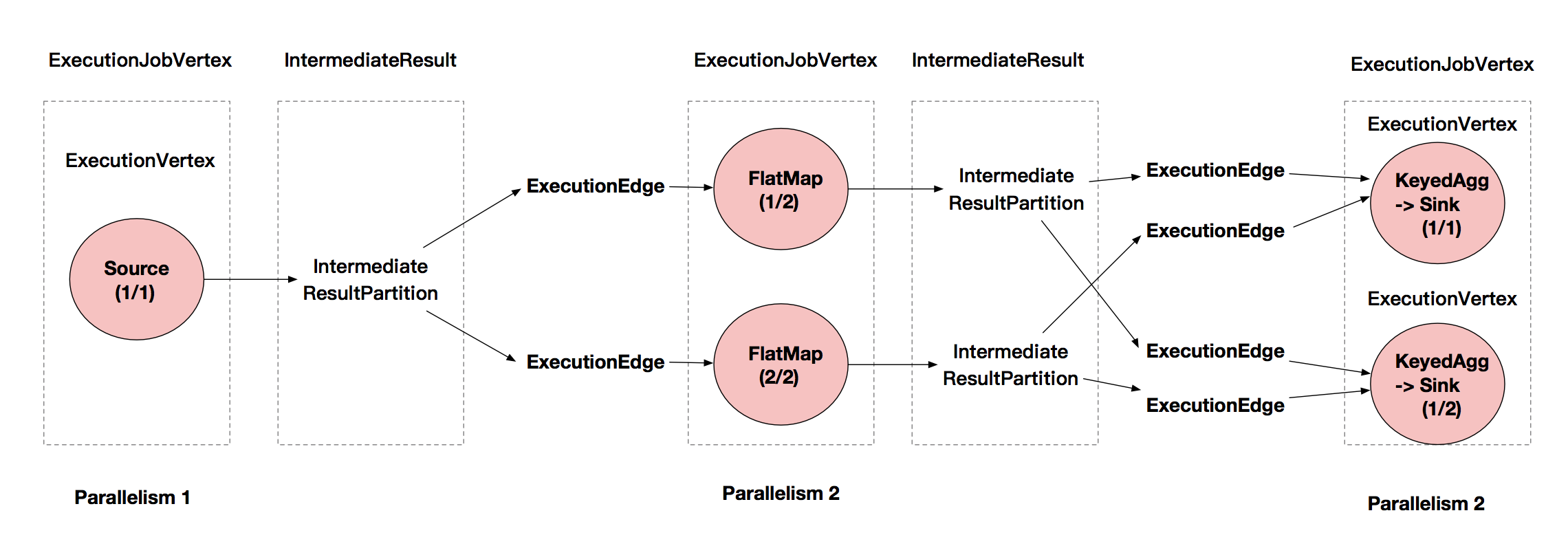
ExecutionGraph 的核心對象有 ExecutionJobVertex 、ExecutionVertex、IntermediateResult 、IntermediateResultPartition、ExecutionEdge 和 Execution。
-
ExecutionJobVertex
該對象和 JobGraph 中的 JobVertex 一一對應。該對象還包含一組 ExecutionVertex,數量與該 JobVertex 中所包含的 StreamNode 的並行度一致,假設 StreamNode 的並行度為3,那麼 ExecutionJobVertex 也會包含 3個 ExecutionVertex。
-
ExecutionVertex
ExecutionJobVertex 中會對作業進行並行化處理,構造可以並行執行的實例,每一個並行執行的實例就是 ExecutionVertex。
構造 ExecutionVertex 的同時,也會構建 ExecutionVertex 的輸出 IntermediateResult。
-
IntermediateResult
IntermediateResult 又叫中間結果集,該對象是個邏輯概念,表示 ExecutionJobVertex 的輸出,和 JobVertex 中的 IntermediateDataSet 一一對應,同樣,一個ExecutionJobVertex 可以有多個中間結果,取決於當前 JobVertex 有幾個出邊(JobEdge)
一個中間結果包含多個中間結果分區 IntermediateResultPartition,其個數等於該 JobVertex 的併發度,或者叫作運算元的並行度。
-
IntermediateResultPartition
IntermediateResultPartition 又叫作中間結果分區,表示一個 ExecutionVertex 的輸出結果,與 ExecutionEdge 相關聯。
-
ExecutionEdge
表示 ExecutionVertex 的輸入,連接到上游產生的 IntermediateResultPartition 。
-
Execution
ExecutionVertex 相當於每個 Task 的模板,在真正執行的時候,會將 ExecutionVertex 中的信息包裝為一個 Execution,執行一個 ExecutionVertex 的一次嘗試。JobManager 和 TaskManager 之間關於 Task 的部署和 Task 的執行狀態的更新都是通過 ExecutionAttemptID 來標識實例的。在發生故障或者數據需要重算的情況下,ExecutionVertex 可能會有多個ExecutionAttemptID 。一個 Execution 通過 ExecutionAttemptID 來唯一標識。
總結
Flink 作業執行前需要提交 Flink 集群, Flink 集群可以與不同的資源框架(Yarn、K8s、Mesos 等)進行集成,可以按照不同的模式(Session 模式和 Per-Job模式)運行,所以在 Flink 作業提交過程中,可能在資源框架上啟動Flink集群。Flink 就緒之後,進入作業提交階段,在Flink客戶端進行StreamGraph、JobGraph的轉換,提交 JobGraph 到 Flink 集群,然後 Flink 集群負責將 JobGraph 轉換為 ExecutionGraph,之後進入調度執行階段。


