
lab1 要求按照論文實現一個mapReduce 框架 lab1 :https://pdos.csail.mit.edu/6.824/labs/lab-mr.html 論文:https://zhuanlan.zhihu.com/p/122571315 在mrsequential.go文件中有個單機版 ...
lab1 要求按照論文實現一個mapReduce 框架
lab1 :https://pdos.csail.mit.edu/6.824/labs/lab-mr.html
論文:https://zhuanlan.zhihu.com/p/122571315
在mrsequential.go文件中有個單機版mapReduce實現很簡單建議閱讀。
整體框架流程:
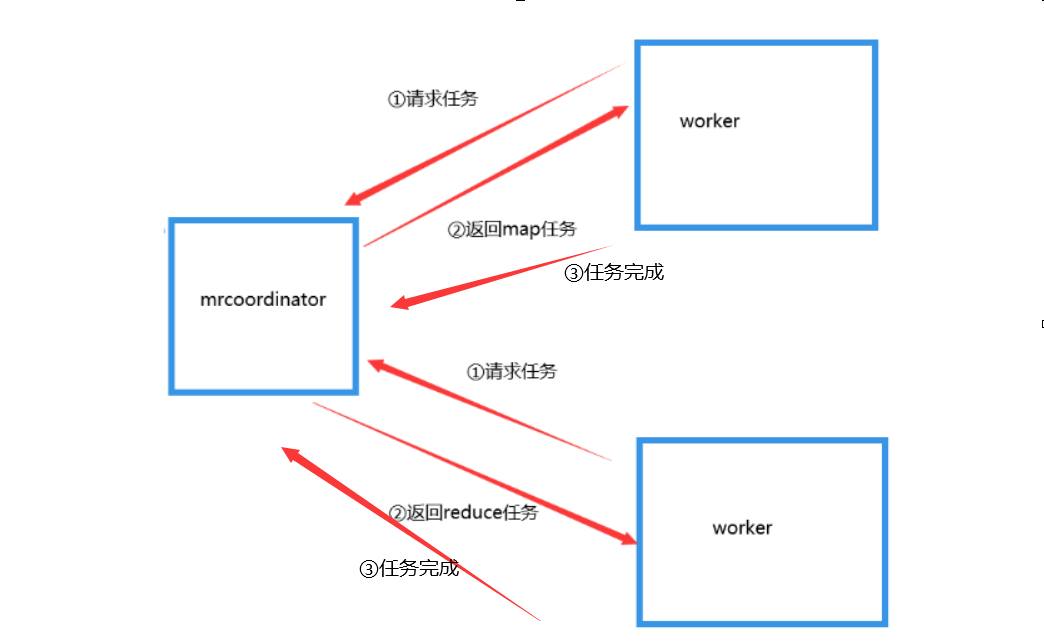
Coordinator 是協調器,負責
① 給woker分發任務
② 合併由map任務執行產生的中間文件
③ 任務超時重新分配任務
woker 是工作器,負責
①迴圈申請map 或reduce任務
先看woker:
worker 向 Coordinator 發送任務申請後,判斷得到的是什麼樣類型的任務
//申請任務
for {
args := Args{}
args.Signal = REQUEST_WORKER
reply := RpcCall(args)
switch reply.STATUS {
case COORDINATOR_MAP: //獲得map任務
MapHandle(&reply,mapf)
case COORDINATOR_REDUCE: //獲得reduce任務
ReduceHandle(&reply,reducef)
case COORDINATOR__MAP_END: //沒申請到任務重新獲取
continue
case END: //結束
return
}
Recude任務
處理方式和mrsequential.go中幾乎是一樣的不多說了。
map任務
會從Coordinator 獲得文件名、任務id、Nreduce(中間文件個數)

kva是通過mapf 對文件處理得到的數據。
我開啟兩個任務分發器,和Nreduce 個文件寫入器,進行併發處理數據。將數據寫入到Nreduce個中間文件中,分發依據為ihash函數。
kva := MapMachingFile(reply.FileName, mapf)
midFileName := "mr-out-" + reply.FileName
chanArray := make([]chan KeyValue, 10)
for i := 0; i < 10; i++ {
chanArray[i] = make(chan KeyValue, 10)
}
//開啟reduceNumber個文件寫入線程
var w sync.WaitGroup
var mapW sync.WaitGroup
w.Add(reply.Neduce)
mapW.Add(2)
for i := 0; i < 10; i++ {
go GoMakeMidFile(midFileName+strconv.Itoa(i), chanArray[i], &w)
}
// 開啟分發線程,分發數據到文件寫入線程
lenght := len(kva)
go MapDistributeMidData(chanArray, kva[:lenght/2], &mapW)
go MapDistributeMidData(chanArray, kva[lenght/2:], &mapW)
//所有分發線程結束
mapW.Wait()
for cIndex := 0; cIndex < 10; cIndex++ {
close(chanArray[cIndex])
}
//所有文件寫入線程結束
w.Wait()
worker結束剩下看Coordinator 。
1 type Coordinator struct { 2 filebit //數據分發記錄 3 Nreduce int 4 midFileMergeC chan int 5 Mergefiled //已處理數據記錄 6 monitorC []chan int //監聽每個worker是否按時完成 7 STATUS 8 RedeceS 9 *sync.Mutex 10 End bool 11 }
Coordinator 結構記錄的信息主要為三部分
2、3、4、5行記錄map相關
6 為監聽chan,監聽任務是否超時
7位Coordinator 當前的狀態,通過狀態判斷要分發map任務、reduce任務、結束
判斷worker的目的,請求任務就分發任務處理,完成map任務就將所有map產生中間數據一一對應合併到Nreduce個文件中。
//信號處理 func (c *Coordinator) SignalTask (args *Args, reply *Reply) error { switch args.Signal { case REQUEST_WORKER: c.distributeTask(args,reply) //中間文件處理 case COMPLETE: c.midFileMerge(args,reply) } return nil }
在初始化Coordinator時,還會打開一些線程。本線程會開啟10個中間文件寫入線程,當每個worker處理完map任務後,會將自己處理的map文件相關信息傳給Coordinator,Coordinator通過chan將數據發給每個文件合併線程StartMergeFile。
舉個例子
workerMap A產生了 1,2,3 個中間文件
1號文件 合併到 mr-out-m-1
2號文件 合併到 mr-out-m-2
3號文件 合併到 mr-out-m-3
workerMap B 又產生1、2、3個中間文件
1號文件 合併到 mr-out-m-1
2號文件 合併到 mr-out-m-2
3號文件 合併到 mr-out-m-3
//開啟Nreduce個中間文件寫入線程
//返迴文件寫入chan 切片
func (c *Coordinator)runFileWorker () []chan int {
cLi := make([]chan int,c.Nreduce)
for i := 0 ; i < c.Nreduce ; i ++ {
cLi[i] = make(chan int,10)
}
for fid := 0 ; fid < c.Nreduce ; fid ++ {
go c.StartMergeFile(fid,cLi[fid])
}
return cLi
}
記錄信息是否已處理的結構:
filebit 、ReduceS 核心是通過一個簡單的bitmap實現的
type filebit struct{
rw *sync.Mutex
bitMap
file []string
}
type RedeceS struct {
filebit
}
type bitMap struct {
bit int16
size int
}
//獲取一個未使用位置
func (b *bitMap) GetOne() int {
for i := int(0) ; i < b.size ; i ++ {
if b.isZero(i) {
b.seTUsed(i)
return i
}
}
//這裡超過size限制會直接報錯
return -1
}
//第i位是否為0
//為0未使用
func (b *bitMap) isZero (index int) bool {
return ((1 << index) & b.bit) == 0
}
//設置index位已使用
func (b *bitMap) seTUsed (index int) {
b.bit = (1 << index) | b.bit
}
func (b *bitMap) setEnUsed (index int) {
b.bit = (0 << index) | b.bit
}
任務超時處理:
func (c *Coordinator) monitorWorker (id int) { timer := time.NewTimer(time.Duration(time.Second*10)) select { case <-c.monitorC[id]: return case <-timer.C: //超時設置為未分配,重新分配 c.SetEnUsed(id) } }
每次分發一個任務出去,就會開啟一個線程監聽剛發送出去的任務。
當Coordinator 接收到任務完成信號,就會給任務id對應的信號監聽函數發送信息,結束監聽函數。
當未在規定時間內發送信號給監聽函數,則將當前監聽的任務id在filebit結構中標記在為未分發,重新輪循分發給下一個到來的worker。
如果這個未按時完成任務的worker後來完成任務並且發送信號過來,當這個任務已經還是為未分髮狀態則捨棄這個worker請求。
如果這個任務同時分發給了其他worker,則接收這個worker,捨棄最後來的。(這裡設計的不太好)


