
#RDD(2) ##RDD轉換運算元 RDD根據數據處理方式的不同將運算元整體上分為Value類型、雙Value類型、Key-Value類型 ###value類型 ####map 函數簽名 def map[U:ClassTag](f:T=>U):RDD[U] 函數說明 將處理的數據逐條進行映射轉換,這裡 ...
RDD(2)
RDD轉換運算元
RDD根據數據處理方式的不同將運算元整體上分為Value類型、雙Value類型、Key-Value類型
value類型
map
函數簽名
def map[U:ClassTag](f:T=>U):RDD[U]
函數說明
將處理的數據逐條進行映射轉換,這裡的轉換可以是類型的轉換,也可以是值的轉換
e.g.1
val source = sparkContext.parallelize(Seq(1, 2, 3, 4, 5, 6))
val map = source.map(item => item*10)
val result = map.collect()
result.foreach(println)
e.g.2
val data1: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4), 2)
// val data2: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4), 1)
val rdd1: RDD[Int] = data1.map(
num => {
println(">>>" + num)
num
}
)
val rdd2: RDD[Int] = rdd1.map(
num => {
println("<<<" + num)
num
}
)
rdd2.collect()
note:
RDD計算同一分區內數據有序,不同分區數據無序
(func)從伺服器日誌數據apache.log中獲取用戶請求URL資源路徑(例):
83.149.9.216 - - 17/05/2015:10:05:12 +0000 GET /presentations/logstash-monitorama-2013/plugin/zoom-js/zoom.js
83.149.9.216 - - 17/05/2015:10:05:07 +0000 GET /presentations/logstash-monitorama-2013/plugin/notes/notes.js
83.149.9.216 - - 17/05/2015:10:05:34 +0000 GET /presentations/logstash-monitorama-2013/images/sad-medic.png
code:
val data = sparkContext.textFile("input/apache.log")
val clean = data.map{
item => {
item.split(" ")(6)
}
}
clean.foreach(println(_))
mapPartitions
函數簽名
def mapPartitions[U:ClassTag](
f:Iterator[T] =>Iterator[U],
preservesPartitioning:Boolean = false):RDD[U]
函數說明
將待處理的數據以分區為單位發送到計算節點進行任意的處理(過濾數據亦可)
note: 函數會將整個分區的數據載入到記憶體中進行引用。記憶體較小、數據量較大的情況下,容易出現記憶體溢出。
val dataRDD1: RDD[Int]= dataRDD.mapPartitions(
datas =>{ //遍歷每個分區進行操作
datas.filter(_==2) //過濾每個分區中值為2的數據
}
)
(func)獲取每個數據分區的最大值
code:
object getMaxFromArea {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Max")
val sparkContext: SparkContext = new SparkContext(sparkConf)
val source: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4, 5, 6), 2)
val mapPartition: RDD[Int] = source.mapPartitions(p => List(p.max).iterator)
//多個分區獲取最大值,使用迭代器
val result: Array[Int] = mapPartition.collect()
result.foreach(println)
sparkContext.stop()
}
}
comparison:
map和mapPartitions的區別
數據處理角度
Map 運算元是分區內一個數據一個數據的執行,類似於串列操作。而 mapPartitions 運算元
是以分區為單位進行批處理操作。
功能的角度
Map 運算元主要目的將數據源中的數據進行轉換和改變。但是不會減少或增多數據。
MapPartitions 運算元需要傳遞一個迭代器,返回一個迭代器,沒有要求的元素的個數保持不變,
所以可以增加或減少數據
性能的角度
Map 運算元因為類似於串列操作,所以性能比較低,而是 mapPartitions 運算元類似於批處
理,所以性能較高。但是 mapPartitions 運算元會長時間占用記憶體,那麼這樣會導致記憶體可能
不夠用,出現記憶體溢出的錯誤。所以在記憶體有限的情況下,不推薦使用。使用 map 操作
mapPartitionsWithIndex
函數簽名
def mapPartitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean = false): RDD[U]
函數說明
將待處理的數據以分區為單位發送到計算節點進行處理,這裡的處理是指可以進行任意的處理,哪怕是過濾數據,在處理時同時可以獲取當前分區索引。
val dataRDD1 = dataRDD.mapPartitionsWithIndex(
(index, datas) => {
datas.map(index, _)
}
)
(func)獲取第二個數據分區的數據
code:
object getSecondArea {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Sec")
val sparkContext: SparkContext = new SparkContext(sparkConf)
val source: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4, 5, 6), 2)
val mapPartitionsWithIndex: RDD[Int] = source.mapPartitionsWithIndex(
(index, data) => {
if (index == 1) {
data
} else {
Nil.iterator
}
}
)
val result: Array[Int] = mapPartitionsWithIndex.collect()
result.foreach(println(_))
sparkContext.stop()
}
}
(func)獲取每個數據及其對應分區索引
code:
object getDataAndIndexOfArea {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Data")
val sparkContext: SparkContext = new SparkContext(conf)
val data: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4, 5, 6))
val dataAndIndex: RDD[(Int, Int)] = data.mapPartitionsWithIndex(
(index, iter) => {
iter.map(data => (data, index))
}
)
val result: Array[(Int, Int)] = dataAndIndex.collect()
result.foreach(println)
}
}
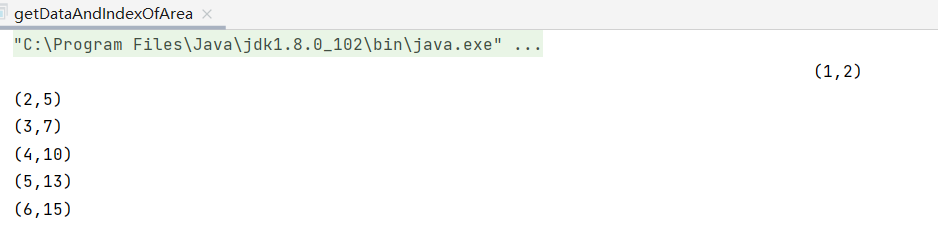
note:這裡沒有自定義分區數量,故預設最多分區數(與機器邏輯處理器數量相關),數據隨機存儲在這些分區中
flatMap
函數簽名
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
函數說明
將處理的數據進行扁平化後再進行映射處理,所以運算元也稱作扁平映射
val dataRDD = sparkContext.makeRDD(
List(List(1,2),List(3,4)),1)
val dataRDD1 = dataRDD.flatMap(list => list)
1
2
3
4
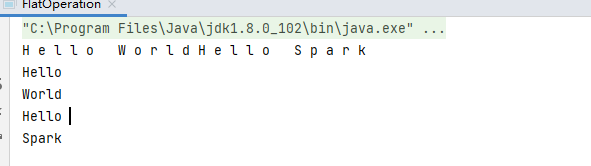
(func)將List("Hello World","Hello Spark")進行扁平化操作
1)字元扁平化
val data = sparkContext.makeRDD(List("Hello World","Hello Spark"),1)
val rdd: RDD[Char] = data.flatMap(list => list)
val result1: Array[Char] = rdd.collect()
result1.foreach(item => print(item+" "))
2)字元串扁平化
val data1: RDD[String] = sparkContext.parallelize(List("Hello World", "Hello Spark"), 1)
val rdd1: RDD[String] = data1.flatMap(list => {
list.split(" ")
})
val result2: Array[String] = rdd1.collect()
result2.foreach(item => println(item + " "))
(func)將List(List(1,2),3,List(4,5))進行扁平化操作
thinking:List(List(1,2),3,List(4,5)) => List(list,int,list) => RDD[Any]
當數據的格式不能夠滿足時我們可以使用match進行格式的匹配(類似java中的switch,case)
code:
val data2: RDD[Any] = sparkContext.parallelize(List(List(1, 2), 3, List(4, 5)))
val rdd2: RDD[Any] = data2.flatMap {
// 完整代碼:
// dat =>{
// dat match {
// case list: List[_] => list
// case int => List(int)
// }
// }
case list: List[_] => list
case int => List(int)
}
val result3: Array[Any] = rdd2.collect()
result3.foreach(item => print(item + " "))
result:
glom
函數簽名
def glom(): RDD[Array[T]]
函數說明
將同一個分區的數據直接轉換為相同類型的記憶體數組進行處理,分區不變
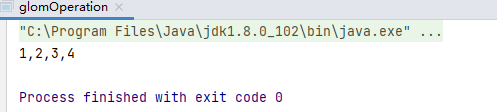
e.g.
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 1)
val glomer: RDD[Array[Int]] = dataRDD.glom()
val result: Array[Array[Int]] = glomer.collect()
result.foreach(data => println(data.mkString(",")))
result: 1,2,3,4
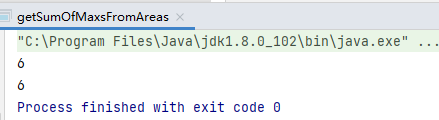
(func)計算所有分區最大值之和
thinking:原分區 (1,2),(3,4)=>glom()=>List(1,2),List(3,4)=>map()=>取出每個裡面的最大值,最後求和
code:
val data: RDD[Int] = sc.parallelize(List(1, 2, 3, 4), 2)
// method1:mapPartitions
val mapPartition: RDD[Int] = data.mapPartitions(p => List(p.max).iterator)
val sum: Int = mapPartition.collect().sum
println(sum)
// method2:glom
val glom: RDD[Array[Int]] = data.glom()
val max: RDD[Int] = glom.map(iter => iter.max)
val sum1: Int = max.collect().sum
print(sum1)
result:
6
6
groupby
函數簽名
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
函數說明
將數據根據指定規則進行分組,分區預設不變,但數據會被打亂重新組合,這個操作被稱作 shuffle
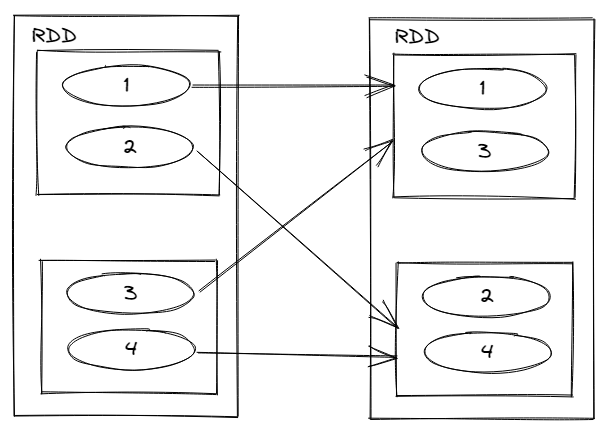
極限情況下,同一個組的數據可能被分在同一個分區中。註意,這並非意味著一個分區中只能有一個組。一如2-2-2組別分入兩個分區。
val dataRDD: RDD[Int] = sparkContext.parallelize(List(1, 2, 6, 3, 4, 5),5)
val groupByer1: RDD[(Int, Iterable[Int])] = dataRDD.groupBy(_ % 3)
val tuples: Array[(Int, Iterable[Int])] = groupByer1.collect()
tuples.foreach(println(_))
result:
(0,CompactBuffer(6, 3))
(1,CompactBuffer(1, 4))
(2,CompactBuffer(2, 5))

(func)將List("hello","spark","scala","hadoop")根據單詞首字母進行分組
code:
val data: RDD[String] = sparkContext.makeRDD(List("hello", "spark", "scala", "hadoop"), 2)
val gb: RDD[(Char, Iterable[String])] = data.groupBy(_.charAt(0))
val tuples: Array[(Char, Iterable[String])] = gb.collect()
tuples.foreach(println)
result:
(h,CompactBuffer(hello, hadoop))
(s,CompactBuffer(spark, scala))

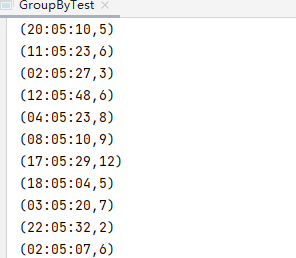
(func)從伺服器日誌數據apache.log中獲取每個時間段訪問量
code:
val data1: RDD[String] = sparkContext.textFile("input/apache.log")
val split: RDD[(String, Int)] = data1.map(
line => {
val fields: Array[String] = line.split(" ")
(fields(3).substring(11), 1)
}
)
val gb1: RDD[(String, Iterable[(String, Int)])] = split.groupBy(_._1)
val count: RDD[(String, Int)] = gb1.map(
iter => {
val count: Int = iter._2.size
(iter._1, count)
}
)
val tuples1: Array[(String, Int)] = count.collect()
tuples1.foreach(println(_))
result:
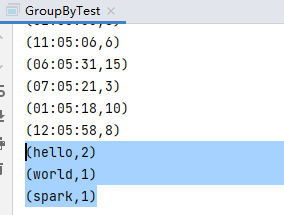
(func)WordCount
code:
val lines: RDD[String] = sparkContext.textFile("input/word.txt")
val words: RDD[String] = lines.flatMap(_.split(" "))
val groups: RDD[(String, Iterable[String])] = words.groupBy(word => word)
val count1: RDD[(String, Int)] = groups.map {
case (word, list) => {
(word, list.size)
}
}
val tuples2: Array[(String, Int)] = count1.collect()
tuples2.foreach(println(_))
result:
(hello,2)
(world,1)
(spark,1)
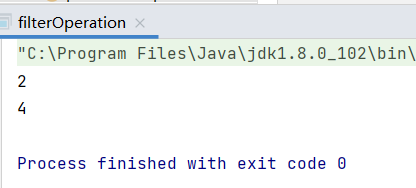
filter
函數簽名
def filter(f: T => **Boolean**): RDD[T]
函數說明
將數據根據指定的規則進行篩選過濾,符合規則的數據保留,不符合規則的數據丟棄。
當數據進行篩選過濾後,分區不變,但是分區內的數據可能分佈不均衡,生產環境下,可能出現數據傾斜
e.g.
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 1)
val filter: RDD[Int] = dataRDD.filter(_ % 2 == 0)
val result: Array[Int] = filter.collect()
result.foreach(println(_))
result:
2
4
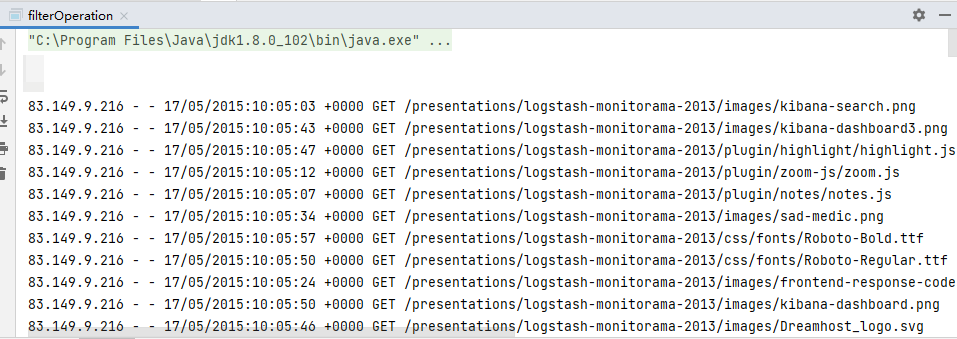
(func)從伺服器日誌數據apache.log中獲取2015年5月17日的請求路徑
code:
val data: RDD[String] = sparkContext.textFile("input/apache.log")
val filter1: RDD[String] = data.filter(line => {
val fields: Array[String] = line.split(" ")
fields(3).startsWith("17/05/2015")
})
val strings: Array[String] = filter1.collect()
strings.foreach(println(_))
result:
83.149.9.216 - - 17/05/2015:10:05:03 +0000 GET /presentations/logstash-monitorama-2013/images/kibana-search.png
83.149.9.216 - - 17/05/2015:10:05:43 +0000 GET /presentations/logstash-monitorama-2013/images/kibana-dashboard3.png
…………
sample
函數簽名
def sample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T]
函數說明
根據指定的規則從數據集中抽取數據
e.g.
val dataRDD = sparkContext.makeRDD(List(1,2,3,4,5,6,7,8,9,10))
//抽取數據不放回(伯努利演算法
//伯努利演算法:又叫0-1分佈。譬如丟硬幣,正反取其一
//具體實現: 根據種子和隨機演算法算出一個數和第二個參數設置幾率比較,小於第二個參數取得,大於第二個參數不取
//第一個參數:是否放回,true:放回
//第二個參數:數據源中每條數據被抽取的幾率,範圍在[0,1]之間,0:全不取;1:全取
//基準值的概念
//第三個參數:隨機數種子
//如果不填,將使用當前的系統時間作為種子數
val sample1: String = dataRDD.sample(true, 2).collect().mkString(",")
//隨機取,放回
println(sample1)
//抽取數據放回(泊松演算法
//第一個參數:抽取的數據是否放回,true:放回
//第二個參數:重覆數據的幾率,範圍大於等於0,表示每一個元素被期望抽到的次數
//第三個參數:隨機數種子
val sample2: String = dataRDD.sample(false, 0.4).collect().mkString(",")
println(sample2)
result:
1,1,2,3,4,4,5,5,5,6,7,8,8,8,10,10
1,3,5,7,10

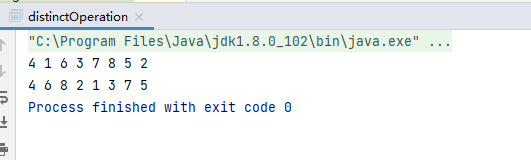
distinct
函數簽名
def distinct()(implicit ord: Ordering[T] = null): RDD[T] def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
函數說明
將數據集內重覆的數據去重
e.g.
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 7, 5, 3, 3, 2, 1), 1)
val dataRDD1: RDD[Int] = dataRDD.distinct()
val result1: Array[Int] = dataRDD1.collect()
result1.foreach({item =>print(item+" ")})
println()
val dataRDD2: RDD[Int] = dataRDD.distinct(2)
val result2: Array[Int] = dataRDD2.collect()
result2.foreach({item=>print(item+" ")})
result:
4 1 6 3 7 8 5 2
4 6 8 2 1 3 7 5
thinking:
distinct底層用到的是HashSet,dataRDD.distinct()替換思路如下
map(x=>(x,null)).reduceByKey((x,y)=>x,numPartitions).map(_,_1)
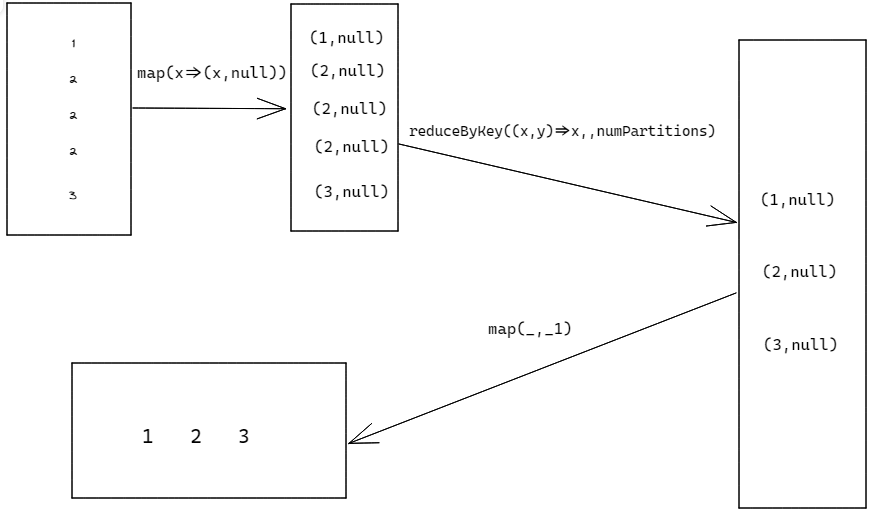
Spark源碼

coalesce
函數簽名
`
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
`
函數說明
根據數據量縮減分區,用於大數據集過濾後,提高小數據集的執行效率
當Spark程式中,存在過多小任務時,可以通過coalesce方法,收縮合併分區,減少分區的個數,減小任務調度成本
note:coalesce運算元不僅可以縮減分區,也可以擴充分區
但是coalesce不會將分區數據打亂組合,是將原先分區上數據整體遷移/增加分區
所以會產生數據傾斜。要讓數據均衡,可以添加參數進行shuffle操作(增加分區必須進行shuffle操作,因為擴充過程中會打亂原有的組合)。
e.g.
val dataRDD1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
// 縮減分區
val coalesce1: RDD[Int] = dataRDD1.coalesce(2)
coalesce1.saveAsTextFile("output/output_coalesce_3_2")
val coalesce1_2: RDD[Int] = dataRDD1.coalesce(2,shuffle = true)
coalesce1_2.saveAsTextFile("output/output_coalesce_3_2_shuffle")
thinking:
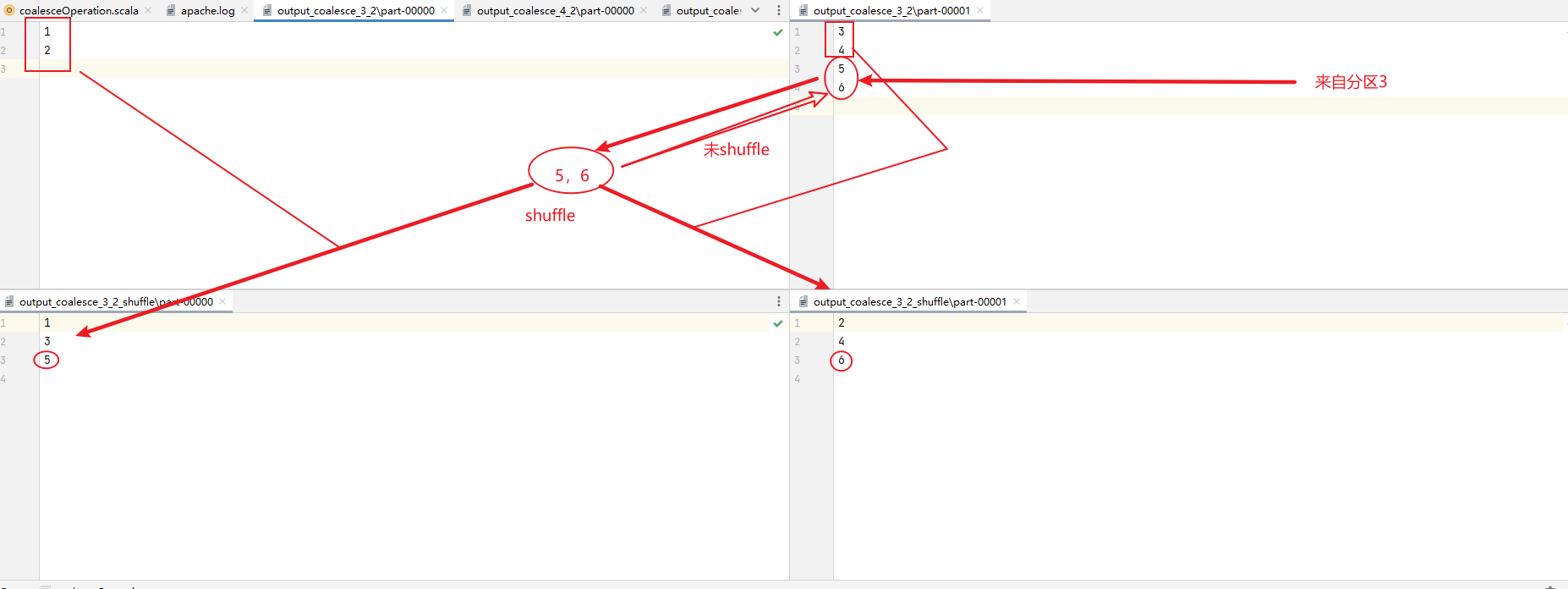
repartition
函數簽名
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
函數說明
該操作內部其實執行的是 coalesce 操作,參數 shuffle 的預設值為 true。無論是將分區數多的RDD轉換為分區數少的RDD,還是將分區數少的 RDD 轉換為分區數多的 RDD,repartition
操作都可以完成,因為無論如何都會經 shuffle 過程。
note:為了簡化,擴充分區的時候常用repartition運算元,直接重新分區。但其底層其實還是使用coalesce運算元實現的。
/**
* Return a new RDD that has exactly numPartitions partitions.
*
* Can increase or decrease the level of parallelism in this RDD. Internally, this uses
* a shuffle to redistribute data.
*
* If you are decreasing the number of partitions in this RDD, consider using `coalesce`,
* which can avoid performing a shuffle.
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true) // 底層使用的就是coalesce運算元
}
softBy
函數簽名
def sortBy[K](f: (T) => K,ascending: Boolean = true,numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
函數說明
該操作用於排序數據。在排序之前,可以將數據通過f函數進行處理,之後按照f函數處理的結果進行排序,預設為升序排列。排序後新產生的RDD的分區數與原RDD的分區數一致,中間存在shuffle的過程。
e.g.
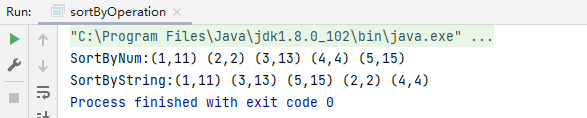
val dataRDD: RDD[(Int, String)] = context.parallelize(List((1, "11"), (2, "2"), (3, "13"), (4, "4"), (5, "15")))
print("SortByNum:")
val dataRDD1: RDD[(Int, String)] = dataRDD.sortBy(_._1)
dataRDD1.collect().foreach({
item=> print(item+" ")
})
println()
print("SortByString:")
val dataRDD2: RDD[(Int, String)] = dataRDD.sortBy(_._2)
dataRDD2.collect().foreach({
item=> print(item+" ")
})
result:
雙Value類型
雙Value類型,兩個數據源之間數據操作
intersection
函數簽名
def intersection(other: RDD[T]): RDD[T]
函數說明
對源RDD和參數RDD求交集(取共有部分的數據集)後返回一個新的RDD
e.g.
val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.intersection(dataRDD2)
note:如果兩個RDD數據類型不一致,編譯時會報錯。所以RDD類型必須保持一致
下麵的union、subtract運算元同樣適用這個準則
union
函數簽名
def union(other: RDD[T]): RDD[T]
函數說明
對源RDD和參數RDD求並集(取全部數據集)後返回一個新的RDD
e.g.
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.union(dataRDD2)
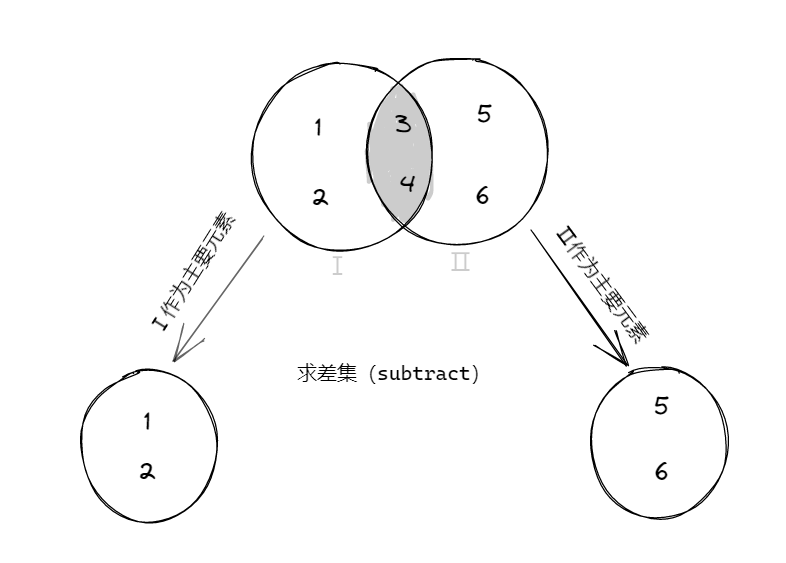
subtract
函數簽名
def subtract(other: RDD[T]): RDD[T]
函數說明
以一個RDD元素為主,去除兩個RDD中發生重覆的元素(所有),將其他元素保留下來,求差集
legend:
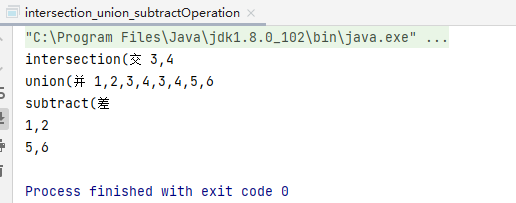
e.g.
val RDD1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4))
val RDD2: RDD[Int] = sparkContext.makeRDD(List(3, 4, 5, 6))
// intersection(交
print("intersection(交 ")
val value: RDD[Int] = RDD1.intersection(RDD2)
println(value.collect().mkString(","))
// union(並
print("union(並 ")
val value1: RDD[Int] = RDD1.union(RDD2)
println(value1.collect().mkString(","))
// subtract(差
println("subtract(差 ")
val value2: RDD[Int] = RDD1.subtract(RDD2)
println(value2.collect().mkString(","))
val value3: RDD[Int] = RDD2.subtract(RDD1)
println(value3.collect().mkString(","))
result:
zip
函數簽名
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
函數說明
將兩個RDD中的元素,以K-V(鍵值對)的形式合併。其中,鍵值對中的Key為第一個RDD中的元素,Value為第二個RDD中的相同位置的元素。
e.g.
val dataRDD1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4))
val dataRDD2: RDD[Int] = sparkContext.makeRDD(List(3, 4, 5, 6))
val dataRDD3: RDD[(Int, Int)] = dataRDD1.zip(dataRDD2)
val dataRDD4: RDD[(Int, Int)] = dataRDD2.zip(dataRDD1)
println(dataRDD3.collect().mkString(","))
println(dataRDD4.collect().mkString(","))
result:

note:
①zip運算元不要求兩個RDD的數據類型保持一致
"(other: RDD[U]): RDD[(T, U)"
origin code:
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {
zipPartitions(other, preservesPartitioning = false) { (thisIter, otherIter) =>
new Iterator[(T, U)] {
def hasNext: Boolean = (thisIter.hasNext, otherIter.hasNext) match {
case (true, true) => true
case (false, false) => false
case _ => throw new SparkException("Can only zip RDDs with " +
"same number of elements in each partition")
}
def next(): (T, U) = (thisIter.next(), otherIter.next())
}
}
}
②zip運算元要求兩個數據源的分區必須保持一致,相關報錯
"報錯:java.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions: List(2, 4)"
③zip運算元要求RDD相同分區下的數據量必須相同,相關報錯
"報錯:org.apache.spark.SparkException: Can only zip RDDs with same number of elements in each partition"
Key-Value類型
partitionBy
函數簽名
`def partitionBy(partitioner: Partitioner): RDD[(K, V)]
// RDD中通過隱式轉換將 partitionBy => PairRDDFunctions
implicit def rddToPairRDDFunctions[K, V](rdd: RDD[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null): PairRDDFunctions[K, V] = {
new PairRDDFunctions(rdd)
}
`
函數說明
將數據按照指定Partitioner重新進行分區。Spark中Partitioner運算元預設的分區器是HashPartitioner,按照key的hash_code進行分區判別
spark大多數運算元使用的都是預設分區器HashPartitioner,HashPartitioner會對數據的key進行 key.hascode%numpartitions 計算,得到的數值會放到對應的分區中,這樣能較為平衡的分配數據到partition,筆者將相關贅述放在模塊後面的分區器(Partitioner)專題中,如有需要可以查閱
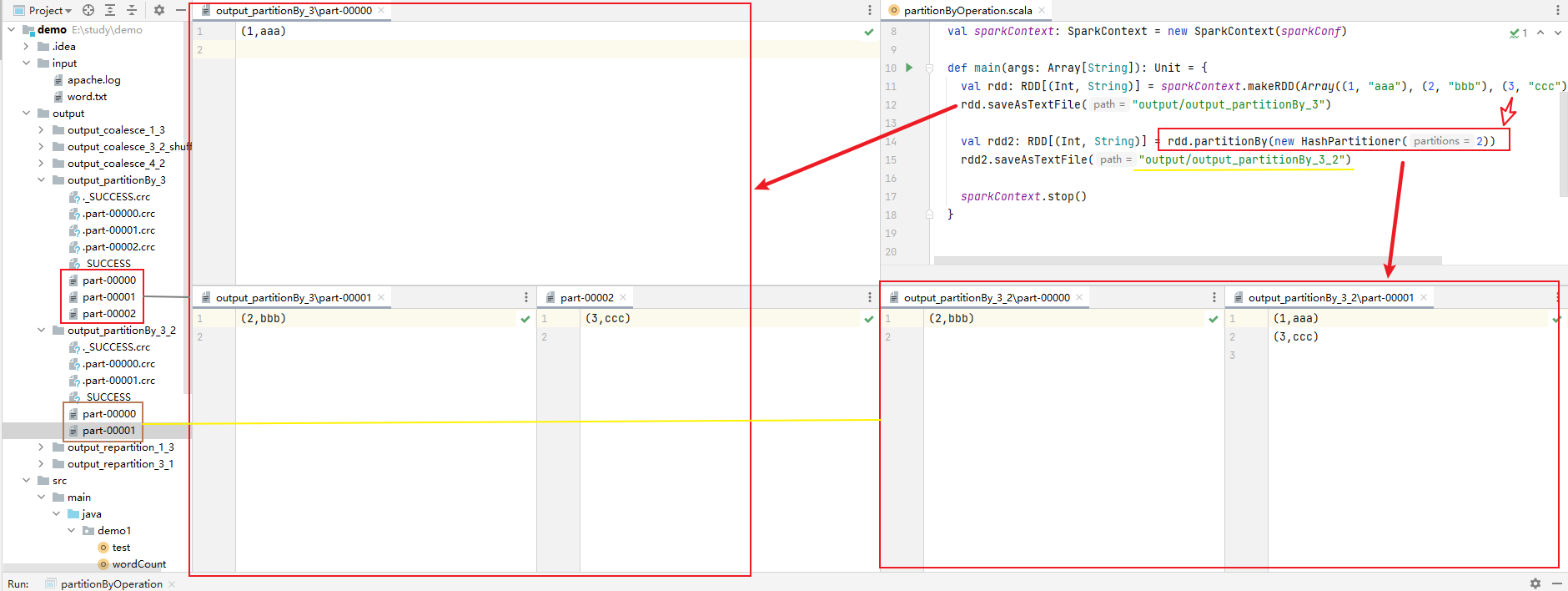
e.g.
val rdd: RDD[(Int, String)] = sparkContext.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)
rdd.saveAsTextFile("output/output_partitionBy_3")
val rdd2: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(2))
rdd2.saveAsTextFile("output/output_partitionBy_3_2")
result:
note:
①如果重分區的分區器和當前RDD的分區器一樣怎麼辦?
origin code:
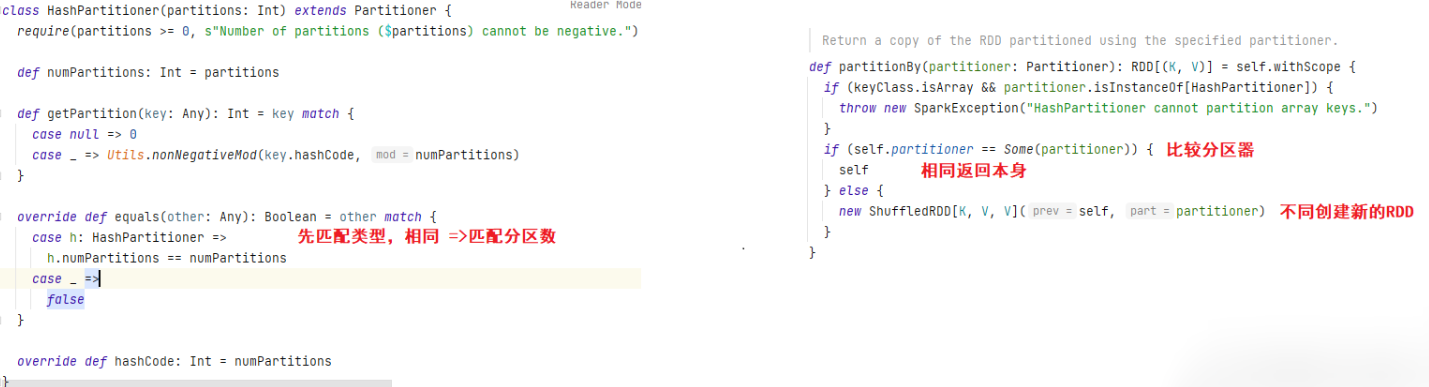
底層源碼會先匹配分區器的類型,如果分區器類型和分區數均相同,則返回RDD本身;如分區器類型不同則會創建新的RDD (類型和分區數確認都不變就不變,分區器類型變就返回新的)
②如圖所示,還有別的分區器,HashPartitioner只是大多數Spark運算元預設的分區器
origin code:
// Partitioner 抽象類 ---> 實現類
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
}
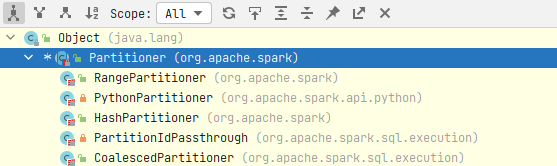
③如果有按照自己的方法進行數據分區的需求,需要自己創建分區器。
reduceByKey
函數簽名
def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
函數說明
可以將數據按照相同的Key對Value進行聚合,scala語言中一般的聚合操作都是兩兩聚合
e.g.
val dataRDD1: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("a", 1)))
// val dataRDD2: RDD[(String, Int)] = dataRDD1.reduceByKey(_ + _)
val dataRDD3: RDD[(String, Int)] = dataRDD1.reduceByKey(_ + _, 2)
dataRDD3.collect().foreach(println(_))
result:
(b,2)
(a,2)
(c,3)

note:
可以看到reduceByKey接收一個func參數,而這個func參數接收兩個V類型的參數並返回一個V類型的結果,這裡的V其實就是初始RDD中的元素,這裡需要傳入的func就是元素兩兩聚合計算的邏輯。
並且在整個過程中,key組只有一個數據的不會參與計算,最終直接輸出。
code:
val dataRDD1: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 1)))
// val dataRDD2: RDD[(String, Int)] = dataRDD1.reduceByKey(_ + _)
val dataRDD3: RDD[(String, Int)] = dataRDD1.reduceByKey(_ + _, 2)
dataRDD3.collect().foreach(println(_))
result:
(b,1)
(a,6)

如上所述,我們在進行reduceByKey運算元操作的時候進行過程計算數據的輸出,可見只有a的數據進行了累加,b的並沒有參與計算。
groupByKey
函數簽名
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
函數說明
將數據源的數據根據key對value進行分組
e.g.
val dataRDD1: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 1), ("a", 2), ("b", 3)))
val dataRDD2: RDD[(String, Iterable[Int])] = dataRDD1.groupByKey()
val dataRDD3: RDD[(String, Iterable[Int])] = dataRDD1.groupByKey(2)
val dataRDD4: RDD[(String, Iterable[Int])] = dataRDD1.groupByKey(new HashPartitioner(2))
dataRDD2.collect().foreach(println(_))
println()
dataRDD3.collect().foreach(println(_))
println()
dataRDD4.collect().foreach(println(_))
result:
(a,CompactBuffer(1, 2))
(b,CompactBuffer(3))
(b,CompactBuffer(3))
(a,CompactBuffer(1, 2))
(b,CompactBuffer(3))
(a,CompactBuffer(1, 2))
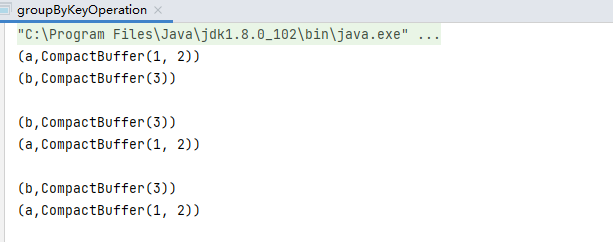
comparison:
①groupBy 與 groupByKey 區別:
e.g.1
code:
val dataRDD1: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 3)))
// 將數據源中相同的key的數據分在一個組,形成一個對偶元組
// (key,相同key的元素值集合)
val dataRDD2: RDD[(String, Iterable[Int])] = dataRDD1.groupByKey()
// groupBy相比groupByKey更加靈活,能夠對不同的value進行分組,而groupByKey只能對Key進行分組
// 兩者的結構有所不同:(key,相同key的元素集合)
val dataRDD3: RDD[(String, Iterable[(String, Int)])] = dataRDD1.groupBy(_._1)
println()
dataRDD2.collect().foreach(println(_))
println()
dataRDD3.collect().foreach(println(_))
result:
(a,CompactBuffer(1, 2, 3))
(b,CompactBuffer(3))
(a,CompactBuffer((a,1), (a,2), (a,3)))
(b,CompactBuffer((b,3)))

雖然都是按照key值進行分組,但是得到的分組的數據結構有區別
e.g.2
code:
// 計算初始RDD不同首字母開頭的元素數量
val rdd: RDD[String] = sc.makeRDD(List("Hello", "Java", "Python", "PHP", "Help"))
// ('H', ("Hello", "Help")), ('J', ("Java")), ('P', ("Python", "PHP"))
val groupRDD: RDD[(Char, Iterable[String])] = rdd.groupBy(_.charAt(0))
// ('H', 2), ('J', 1), ('P', 2)
val sizeRDD: RDD[Int] = groupRDD.map(_._2.size)
sizeRDD.collect().foreach(println)
result:
2
2
1
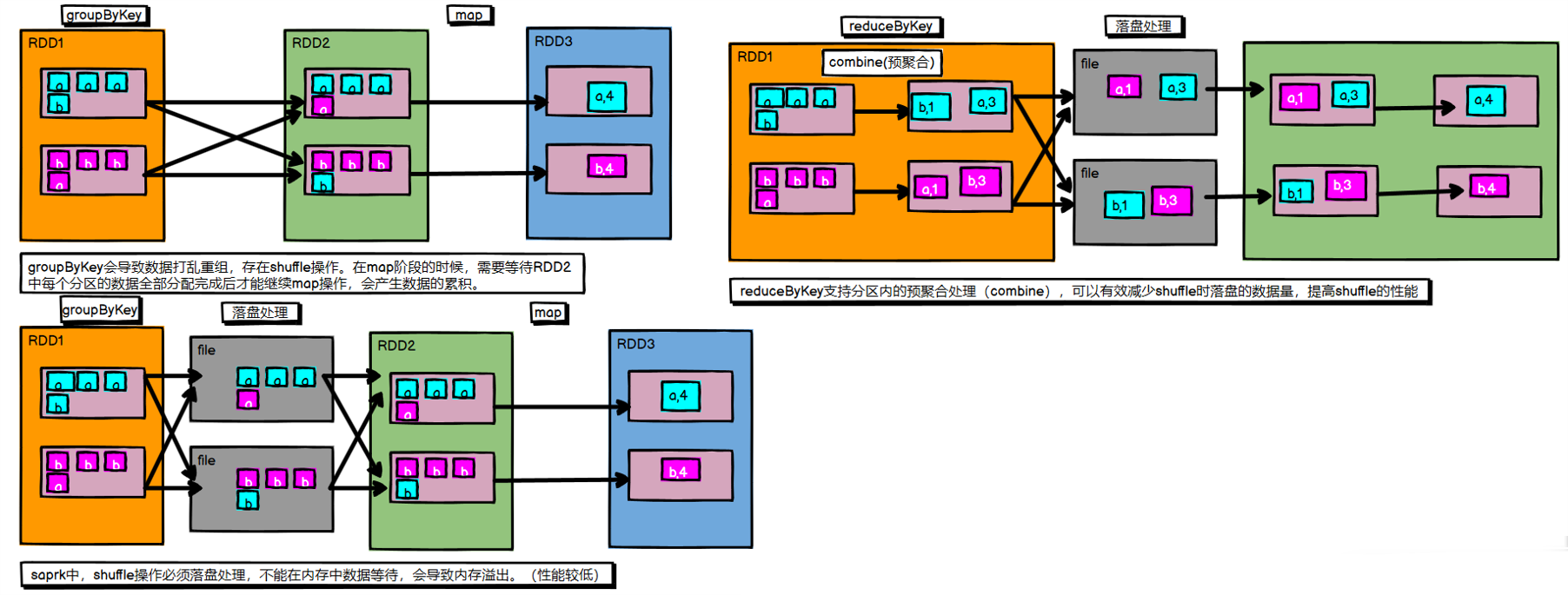
參考下圖,第二步添加了File落盤動作,因為groupBy操作會計算每個分區所有單詞的首字母並緩存下來,如果放在記憶體中若數據過多則會產生記憶體溢出;再就是第三步從文件讀取回來,並不一定是三個分區,這裡只是為了便於理解。
legend:
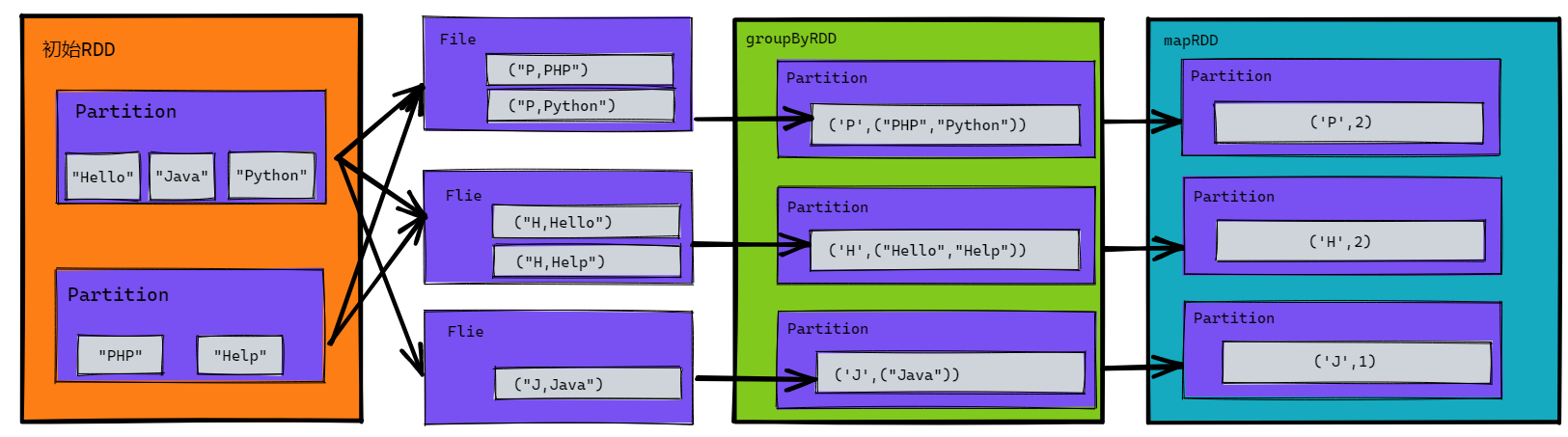
②groupByKey和reduceByKey的區別
legend:
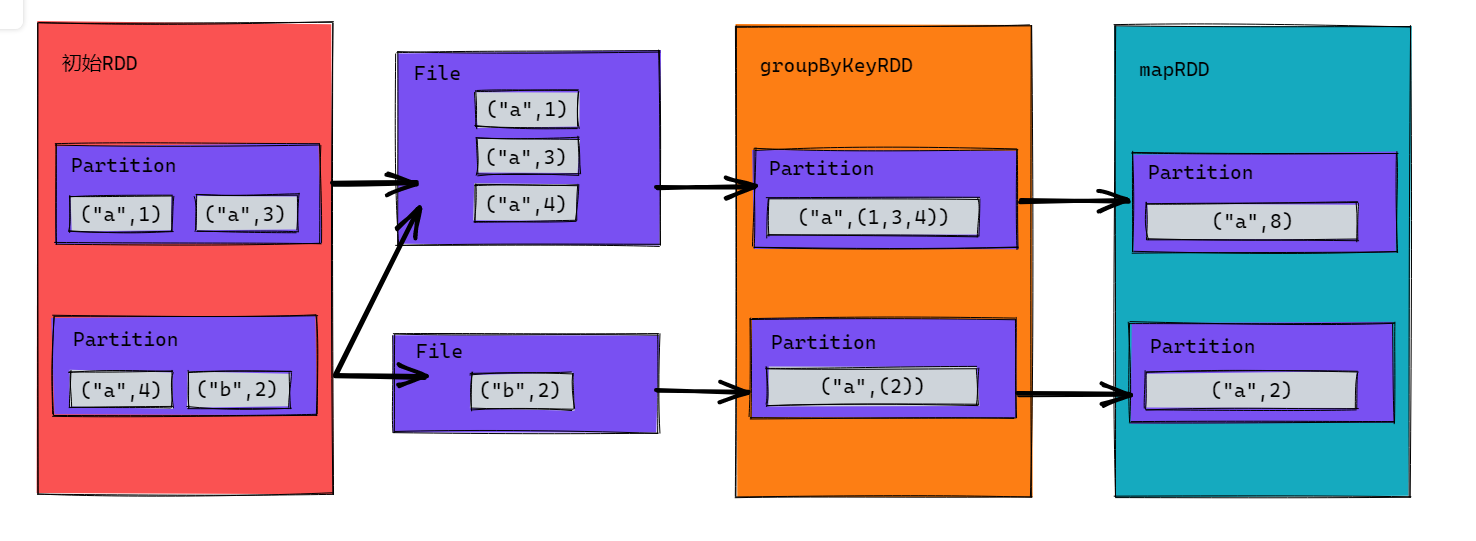
groupByKey
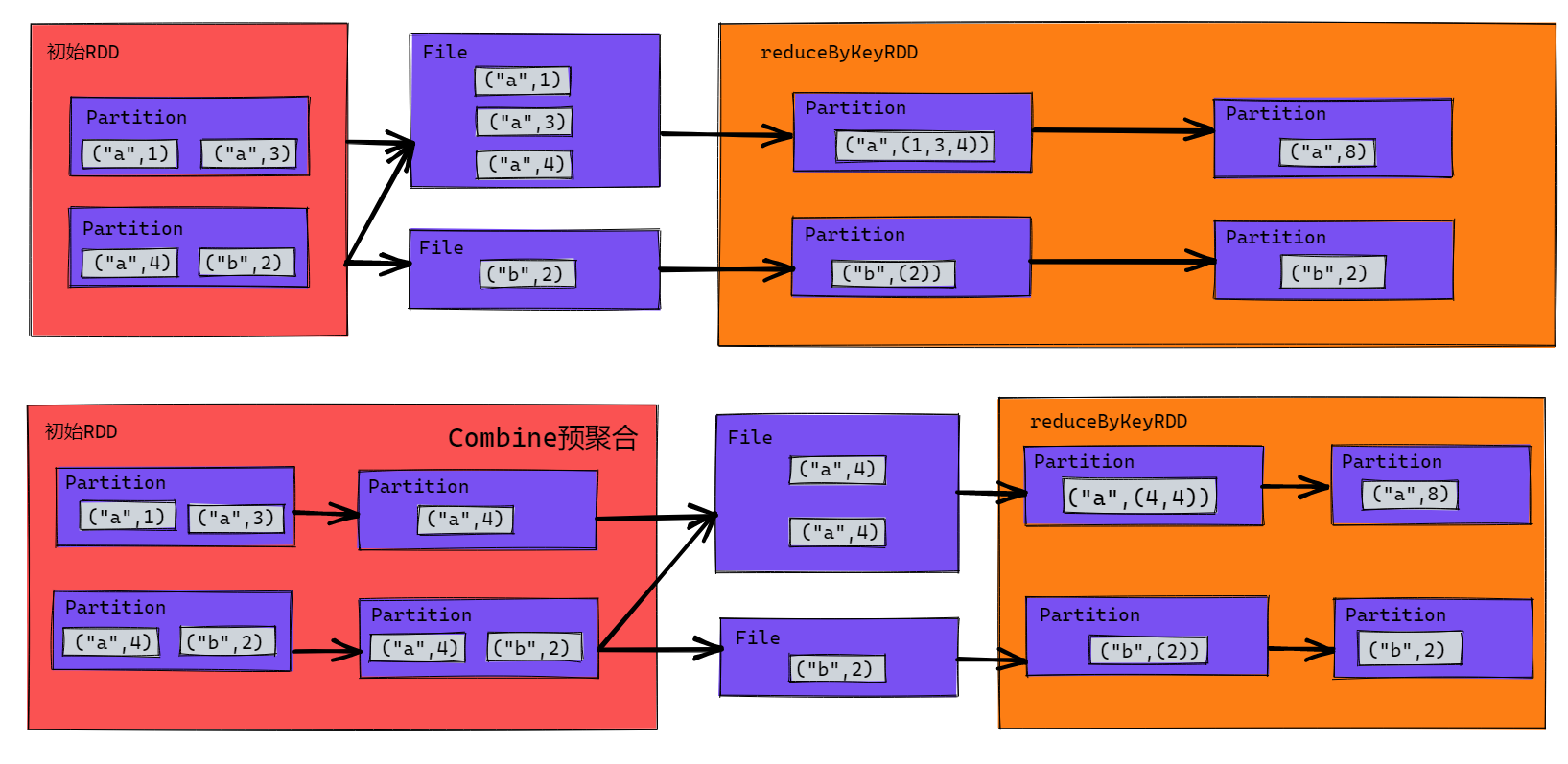
reduceByKey
從下圖中的第一張圖看相對於groupByKey只是少了map的步驟將它整合在reduceByKey中,但是實際上reduceByKey的作用不止於此,第二張圖才是實際的運行模式,它提供了Combine預聚合的功能,支持在分區中先進行聚合,稱作分區內聚合,然後再落盤等待分區間聚合。這樣下來它不只是減少了map的操作,同時提供了分區內聚合使得shuffle落盤時的數據量儘量小,IO效率也會提高不少。最後它引出了分區內聚合和分區間聚合,reduceByKey的分區內聚合和分區間聚合是一樣的。
- 從 shuffle 角度:
同:reduceByKey和groupByKey都存在shuffle的操作,
異: reduceByKey可以在shuffle前對分區內相同key值的數據進行預聚合(combine)功能,這樣會減少落盤的數據量
groupByKey 只是進行分組,不存在數據量減少的問題 - 從 功能 角度:
reduceByKey包含 分組 和 聚合的功能。
groupByKey****只能分組,不能聚合
所以 分組聚合 場景,使用reduceByKey更好。如果僅僅需要分組,不需要聚合,只能使用groupByKey
note:
reduceByKey 分區內 與 分區間 的 計算規則相同,都是按Key值進行分組聚合。但是在存在分區內 和 分區間 計算規則不同的情況(如 先求 分區內最大值,再求各分區間最大值的總和),這時reduceByKey不再適用,可以使用aggregateByKey運算元實現
aggregateByKey
函數簽名
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]
函數說明
將數據根據不同的規則進行分區內計算和分區間計算
e.g.
code:
val dataRDD1: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 1), ("a", 2), ("c", 3)))
val dataRDD2: RDD[(String, Int)] = dataRDD1.aggregateByKey(0)(_ + _, _ + _)
dataRDD2.collect().foreach(println(_))
result:
(a,3)
(c,3)
(func):
①取出每個分區內相同key地最大值,然後分區間相加
thinking:
(a,[1,2]) (a,[3,4])
=> (a,2) (a,4)
=> (a,6)
aggregateByKey存在函數柯里化(Currying),有兩個參數列表
- 第一個參數列表需要傳遞一個參數,表示初始值
- 主要用於碰見第一個key時,和value進行分區內的計算
- 第二參數列表需要傳遞兩個參數
- 參數1:表示分區內的計算規則
- 參數2:表示分區間的計算規則
code:
val dataRDD3: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 1), ("b", 3), ("b", 4), ("b", 5), ("a", 3), ("a", 4)), 2)
dataRDD3.aggregateByKey(0)(
(x, y) => math.max(x, y),
(x, y) => x + y
).collect().foreach(println)
result:
(b,9)
(a,5)
legend:
②求出相同Key的數據的平均值
aggregateByKey 最終返回的數據結果應該和初始值的數據類型保持一致,且整個過程中Key保持不變
code:
val dataRDD3: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 1), ("b", 3), ("b", 4), ("b", 5), ("a", 3), ("a", 4)), 2)
// (0,0) => (初始值,記錄同key組中數的數量 --- size)
val dataRDD4: RDD[(String, (Int, Int))] = dataRDD3.aggregateByKey((0, 0))(
// 分區內計算:t代表上一個(Int,Int)結果,v代表當前的 value 【即下一個(Int,Int)中第一個Int的值】
// 前值相加;後數目加一,用於統計單個分區內的數據量
(t, v) => {
(t._1 + v, t._2 + 1)
},
// 分區間計算:t1,t2代表兩個(Int,Int)的結果 (值與值相加,數的數量與數的數量相加)
// 前值相加;後數目相加,用於求所有分區內的數據量之和
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
//前為原數據分類,後為 值之總和 與 數據量之總和 求商 => 平均值
val dataRDD5: RDD[(String, Int)] = dataRDD4.map(item => (item._1, item._2._1 / item._2._2))
dataRDD5.collect().foreach(println)
// 與如下map運算元等效
val dataRDD6: RDD[(String, Int)] = dataRDD4.mapValues {
case (sum, count) => {
sum / count
}
}
dataRDD6.collect().foreach(println)
result:
(b,4)
(a,2)
foldByKey
函數簽名
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
函數說明
當 分區內 與 分區間 計算規則相同時,aggregateByKey 就可以簡化為foldByKey
e.g.
code:
val dataRDD: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 1), ("a", 3), ("a", 5), ("c", 3), ("c", 5), ("c", 6)))
dataRDD.foldByKey(0)(_+_).collect().foreach(println)
result:
(a,9)
(c,14)
combineByKey
函數簽名
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
函數說明
最通用的對 key-value 型 rdd 進行聚集操作的聚集函數(aggregation function)。類似於aggregate(),combineByKey()允許用戶返回值的類型與輸入不一致。
(func)數據 List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),求每個 key 的平均值:
code:
val source: RDD[(String, Int)] = sparkContext.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)))
val value1: RDD[(String, (Int, Int))] = source.combineByKey(
(_, 1),
(t, v) => (t._1 + v, t._2 + 1),
(t1, t2) => (t1._1 + t2._1, t1._2 + t2._2)
)
// (a,(274,3))
// (b,(286,3))
value1.map(t => (t._1, t._2._1 / t._2._2)).collect().foreach(println)
result:
(a,91)
(b,95)
legend:
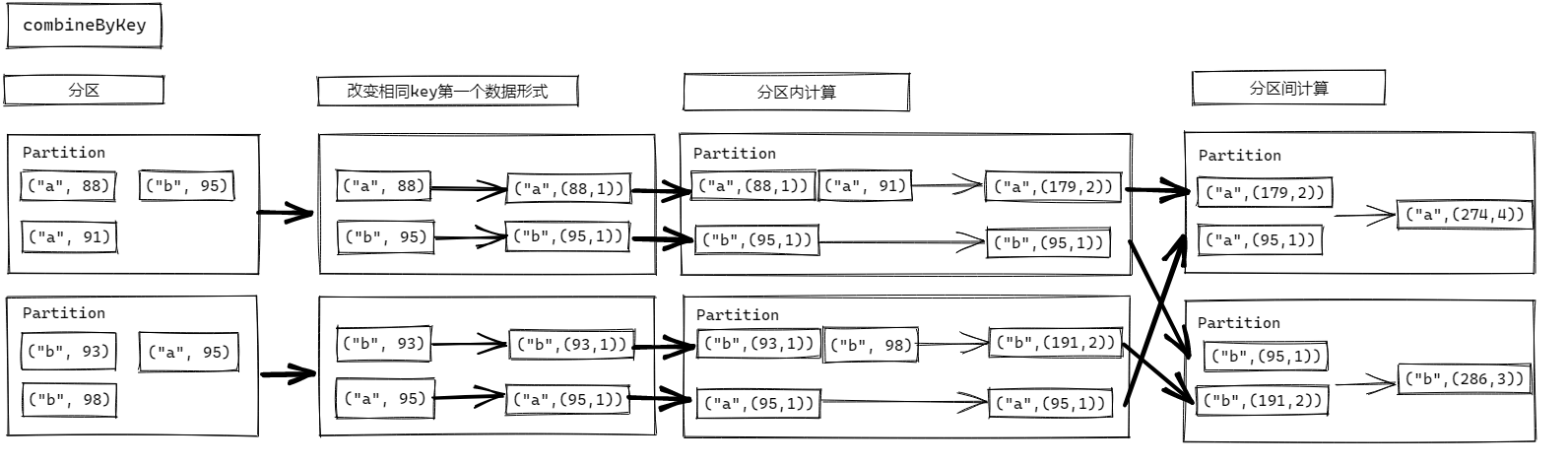
comparison:
reduceByKey、foldByKey、aggregateByKey、combineByKey 的區別?
- reduceByKey: 相同 key 的第一個數據不進行任何計算,分區內和分區間計算規則相同
- foldByKey: 相同 key 的第一個數據和初始值進行分區內計算,分區內和分區間計算規則相同
- aggregateByKey:相同 key 的第一個數據和初始值進行分區內計算,分區內和分區間計算規則可以不相同
- combineByKey:當計算時,發現數據結構不滿足要求時,可以讓第一個數據轉換結構,分區內和分區間計算規則不相同。
sortByKey
函數簽名
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)]
函數說明
在一個(K,V)的 RDD 上調用,K 必須實現 Ordered 介面(特質),返回一個按照 key 進行排序的
e.g.
code:
val dataRDD1 = sc.makeRDD(List(("a",1),("b",2),("c",3)))
val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(true)
val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(false)
(func)設置key為自定義類User
join
函數簽名
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
函數說明
在類型為(K,V)和(K,W)的 RDD 上調用,返回一個相同 key 對應的所有元素連接在一起的(K,(V,W))的 RDD
e.g.
code:
val dataRDD: RDD[(Int, String)] = sparkContext.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val dataRDD1: RDD[(Int, Int)] = sparkContext.makeRDD(Array((1, 3), (2, 4), (3, 5)))
dataRDD.join(dataRDD1).collect().foreach(println)
result:
(1,(a,3))
(2,(b,4))
(3,(c,5))
note:
① 如果key存在不相等的情況,不相等的部分不參與join,其他部分正常參與
code:
val dataRDD2: RDD[(Int, String)] = sparkContext.makeRDD(Array((1, "a"), (2, "b"), (4, "c")))
val dataRDD3: RDD[(Int, Int)] = sparkContext.makeRDD(Array((1, 3), (2, 4), (3, 5)))
dataRDD2.join(dataRDD3).collect().foreach(println)
result:
(1,(a,3))
(2,(b,4))
②如果兩個數據源中key沒有匹配上,那麼數據不會出現在結果中
③如果兩個數據源中key有多個相同的,會依次匹配,產生笛卡爾積
leftOuterJoin/rightOuterJoin
函數簽名
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
def rightOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
函數說明
類似於 SQL 語句的左、右外連接
e.g.
code:
val dataRDD1 = sc.makeRDD(List(("a",1),("b",2),("c",4)))
val dataRDD2 = sc.makeRDD(List(("a",1),("b",2),("d",3)))
// leftOuterJoin
val rdd1 = dataRDD1.leftOuterJoin(dataRDD2)
println("dataRDD1:dataRDD2")
rdd1.collect().foreach(println)
val rdd2 = dataRDD2.leftOuterJoin(dataRDD1)
println("dataRDD2:dataRDD1")
rdd2.collect().foreach(println)
// rightOuterJoin
val rdd3 = dataRDD1.rightOuterJoin(dataRDD2)
println("dataRDD1:dataRDD2")
rdd3.collect().foreach(println)
val rdd4 = dataRDD2.rightOuterJoin(dataRDD1)
println("dataRDD2:dataRDD1")
rdd4.collect().foreach(println)
result:
leftOuterJoin:
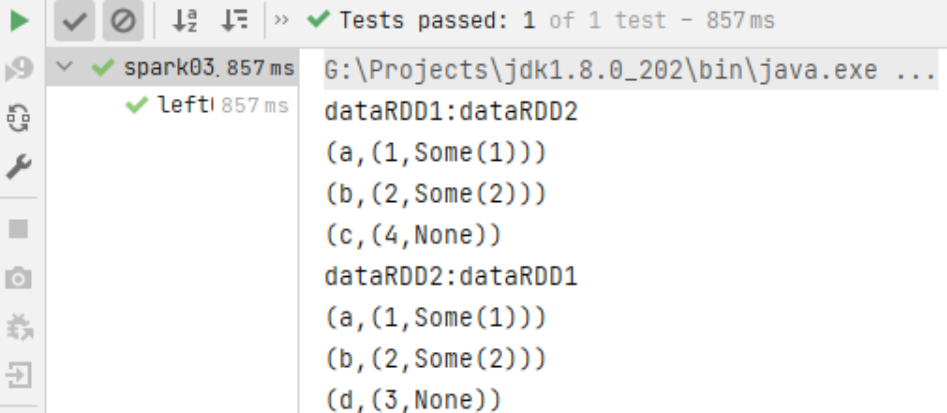
rightOuterJoin:

cogroup
函數簽名
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
函數說明
在類型為(K,V)和(K,W)的 RDD 上調用,返回一個(K,(Iterable
note:cogroup = connect + group,最多支持四個RDD的操作
e.g.1
code:
val dataRDD1 = sc.makeRDD(List(("a",1),("a",2),("c",3)))
val dataRDD2 = sc.makeRDD(List(("a",1),("c",2),("d",3)))
val value= dataRDD1.cogroup(dataRDD2)
value.collect().foreach(println)
result:
(a,(CompactBuffer(1, 2),CompactBuffer(1)))
(c,(CompactBuffer(3),CompactBuffer(2)))
(d,(CompactBuffer(),CompactBuffer(3)))
首先按照key進行分組,然後將分好的組進行連接;可能會存在空組的情況,如上圖所示
e.g.2
code:
val dataRDD1 = sc.makeRDD(List(("a",1),("a",2),("c",3)))
val dataRDD2 = sc.makeRDD(List(("a",1),("c",2),("d",3)))
val dataRDD3 = sc.makeRDD(List(("a",11),("c",22),("a",33)))
val dataRDD4 = sc.makeRDD(List(("a",1),("a",2),("d",3)))
dataRDD1.cogroup(dataRDD2,dataRDD3,dataRDD4).collect().foreach(println)
result:
(a,(CompactBuffer(1, 2),CompactBuffer(1),CompactBuffer(11, 33),CompactBuffer(1, 2)))
(c,(CompactBuffer(3),CompactBuffer(2),CompactBuffer(22),CompactBuffer()))
(d,(CompactBuffer(),CompactBuffer(3),CompactBuffer(),CompactBuffer(3)))

