
The DataStream API gets its name from the special DataStream class that is used to represent a collection of data in a Flink program. You can think of ...
The DataStream API gets its name from the special DataStream class that is used to represent a collection of data in a Flink program. You can think of them as immutable collections of data that can contain duplicates. This data can either be finite or unbounded, the API that you use to work on them is the same.
執行模式(流/批)
DataStream API 支持不同的運行時執行模式,你可以根據你的用例需要和作業特點進行選擇。
DataStream API 有一種”經典“的執行行為,我們稱之為流(STREAMING)執行模式。這種模式適用於需要連續增量處理,而且預計無限期保持線上的無邊界作業。
此外,還有一種批式執行模式,我們稱之為批(BATCH)執行模式。這種執行作業的方式更容易讓人聯想到批處理框架,比如 MapReduce。這種執行模式適用於有一個已知的固定輸入,而且不會連續運行的有邊界作業。
Apache Flink 對流處理和批處理統一方法,意味著無論配置何種執行模式,在有界輸入上執行的 DataStream 應用都會產生相同的最終 結果。重要的是要註意最終 在這裡是什麼意思:一個在流模式執行的作業可能會產生增量更新(想想資料庫中的插入(upsert)操作),而批作業只在最後產生一個最終結果。儘管計算方法不同,只要呈現方式得當,最終結果會是相同的。
通過啟用批執行,我們允許 Flink 應用只有在我們知道輸入是有邊界的時侯才會使用到的額外的優化。例如,可以使用不同的關聯(join)/ 聚合(aggregation)策略,允許實現更高效的任務調度和故障恢復行為的不同 shuffle。下麵我們將介紹一些執行行為的細節。
什麼時候可以/應該使用批處理模式?
批執行模式只能用於 有邊界 的作業/Flink 程式。邊界是數據源的一個屬性,告訴我們在執行前,來自該數據源的所有輸入是否都是已知的,或者是否會有新的數據出現,可能是無限的。而對一個作業來說,如果它的所有源都是有邊界的,則它就是有邊界的,否則就是無邊界的。
而流執行模式,既可用於有邊界任務,也可用於無邊界任務。
一般來說,在你的程式是有邊界的時候,你應該使用批執行模式,因為這樣做會更高效。當你的程式是無邊界的時候,你必須使用流執行模式,因為只有這種模式足夠通用,能夠處理連續的數據流。
一個明顯的例外是當你想使用一個有邊界作業去自展一些作業狀態,並將狀態使用在之後的無邊界作業的時候。例如,通過流模式運行一個有邊界作業,取一個 savepoint,然後在一個無邊界作業上恢復這個 savepoint。這是一個非常特殊的用例,當我們允許將 savepoint 作為批執行作業的附加輸出時,這個用例可能很快就會過時。
另一個你可能會使用流模式運行有邊界作業的情況是當你為最終會在無邊界數據源寫測試代碼的時候。對於測試來說,在這些情況下使用有邊界數據源可能更自然。
配置批執行模式
執行模式可以通過 execute.runtime-mode 設置來配置。有三種可選的值:
- STREAMING: 經典 DataStream 執行模式(預設)
- BATCH: 在 DataStream API 上進行批量式執行
- AUTOMATIC: 讓系統根據數據源的邊界性來決定
這可以通過 bin/flink run ... 的命令行參數進行配置,或者在創建/配置 StreamExecutionEnvironment 時寫進程式。
下麵是如何通過命令行配置執行模式:
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
這個例子展示瞭如何在代碼中配置執行模式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
我們不建議用戶在程式中設置運行模式,而是在提交應用程式時使用命令行進行設置。保持應用程式代碼的免配置可以讓程式更加靈活,因為同一個應用程式可能在任何執行模式下執行。
統計單詞案例
以批處理方式進行統計
-
流程
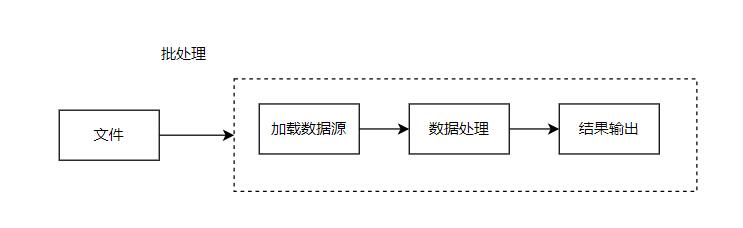
-
核心代碼
ParameterTool parameterFromArgs = ParameterTool.fromArgs(args);
String input = parameterFromArgs.getRequired("input");
// 初始化環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// 載入數據源
DataStreamSource<String> wordSource = env.readTextFile(input, "UTF-8");
// 數據轉換
SingleOutputStreamOperator<Word> wordStreamOperator = wordSource.flatMap(new TokenizerFunction());
// 按單詞分組
KeyedStream<Word, String> wordKeyedStream = wordStreamOperator.keyBy(new KeySelector<Word, String>() {
@Override
public String getKey(Word word) throws Exception {
return word.getWord();
}
});
// 求和
SingleOutputStreamOperator<Word> sumStream = wordKeyedStream.sum("frequency");
sumStream.print();
env.execute("WordCountBatch");
- 在IDE中運行時,需指定-input參數,輸入文件地址
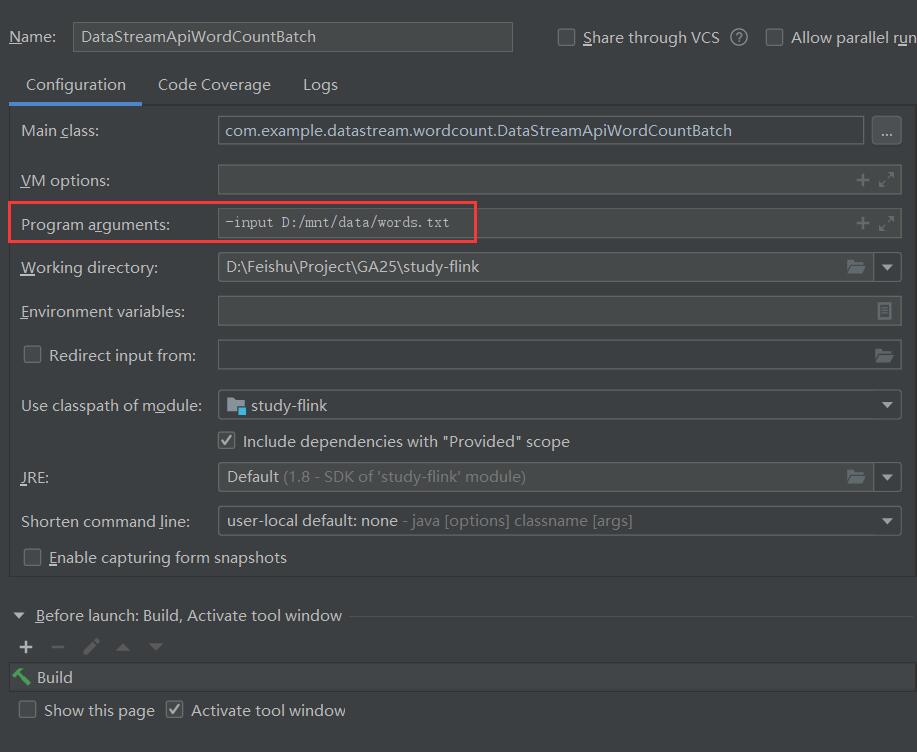
以流處理方式進行統計
-
流程
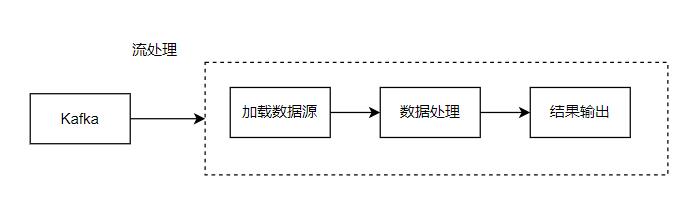
-
核心代碼
// 初始化環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 定義kafka數據源
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.0.192:9092")
.setTopics("TOPIC_WORD")
.setGroupId("TEST_GROUP")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
// 載入數據源
DataStreamSource<String> kafkaWordSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Word Source");
// 數據轉換
SingleOutputStreamOperator<Word> wordStreamOperator = kafkaWordSource.flatMap(new TokenizerFunction());
// 按單詞分組
KeyedStream<Word, String> wordKeyedStream = wordStreamOperator.keyBy(new KeySelector<Word, String>() {
@Override
public String getKey(Word word) throws Exception {
return word.getWord();
}
});
// 求和
SingleOutputStreamOperator<Word> sumStream = wordKeyedStream.sum("frequency");
sumStream.print();
env.execute("WordCountStream");
完整代碼地址
https://github.com/Mr-LuXiaoHua/study-flink
com.example.datastream.wordcount.DataStreamApiWordCountBatch --從文件讀取數據進行單詞統計
com.example.datastream.wordcount.DataStreamApiWordCountStream --從Kafka消費數據進行單詞統計
提交到flink集群執行:
bin/flink run -m 127.0.0.1:8081 -c com.example.datastream.wordcount.DataStreamApiWordCountBatch -input /mnt/data/words.txt /opt/apps/study-flink-1.0.jar
-input 指定輸入文件路徑


