
1.下載安裝包 1.1 下載elasticsearch 7.13.3 curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.3-linux-x86_64.tar.gz 1.2 解壓文件 t ...
背景
- 公司的一個項目,需要記錄某個介面的訪問pv、uv,並且不能丟失明細數據,需要記錄【用戶,調用介面,調用詳情,調用時間,調用次數】
- 之前使用MySQL記錄,每來一條記錄一條,例如: insert into log (id, user_id, resource_id, stat_date, view_count) values (default, user_id, view_id, '2022-06-11', 1)
- 存在的問題是
- 沒過多久MySQL中數據量級就到達千萬,沒法在毫秒的時間內返回結果
- 使用MySQL中的明細數據進行聚合分析也非常的慢
Doris聚合模型
- 首先簡單介紹下Doris,它是一個MPP資料庫,一般是數據倉庫進行多維分析使用,導入明細數據,通過創建物化視圖的方式可以實現亞秒級別多維查詢
- 發現Doris的Aggregate模型非常符合需求,聚合模型中存在聚合鍵,聚合類型,表中所有的欄位必須是兩者其一,聚合鍵顧名思義,用來判斷唯一性,可以理解為關係型資料庫中的主鍵,聚合類型存在多種,SUM(求和),REPLACE(替換,保留最新),MAX(最大),MIN(最小)
- 詳細介紹可以查看Doris官方文檔: https://doris.apache.org/branch-0.13/zh-CN/
- 演示聚合模型
- 創建聚合表
CREATE TABLE IF NOT EXISTS online_test.aggregate_table_name
(
user_id INT DEFAULT '0' COMMENT '用戶唯一標識'
,event_id INT DEFAULT '0' COMMENT '事件唯一標識'
,real_name VARCHAR(20) REPLACE DEFAULT '' COMMENT '用戶真實名稱,可能發生變化,每次記錄最新'
,view_count INT SUM DEFAULT '0' COMMENT '統計用戶查看某個事件的總次數'
,start_time DATE MIN DEFAULT '1970-01-01' COMMENT '第一條記錄的時間、開始時間'
,end_time DATE MAX DEFAULT '1970-01-01' COMMENT '最後一條記錄的時間、結束時間'
)
AGGREGATE KEY(user_id, event_id)
DISTRIBUTED BY HASH(event_id) BUCKETS 10
PROPERTIES("replication_num" = "1");
- 插入測試數據
insert into aggregate_table_name values
(1, 10, '張三', 1, '2022-06-12', '2022-06-12');
- 查詢結果
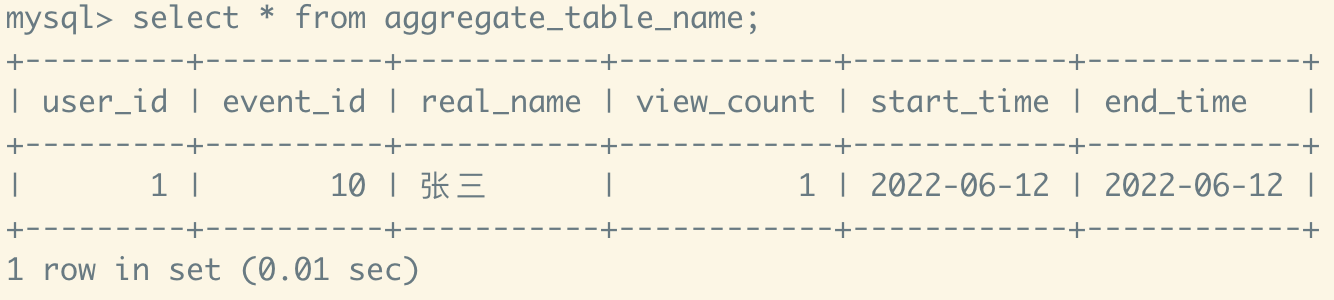
- 再次插入測試數據
insert into aggregate_table_name values
(1, 10, '張三豐', 1, '2022-06-13', '2022-06-13');
- 再次查詢結果

- 解釋: 真實名從張三->張三豐是用戶進行了修改名稱操作,只保留最新的名字,查詢次數1->2是進行了求和計算,end_time從2022-06-12 -> 2022-06-13是每次記錄最大的日期,相當於是保留最新的
使用Doris統計服務質量
- 項目需要統計調用者,調用明細,調用時間,於是設計一個服務指標維度表,這樣通用性更高
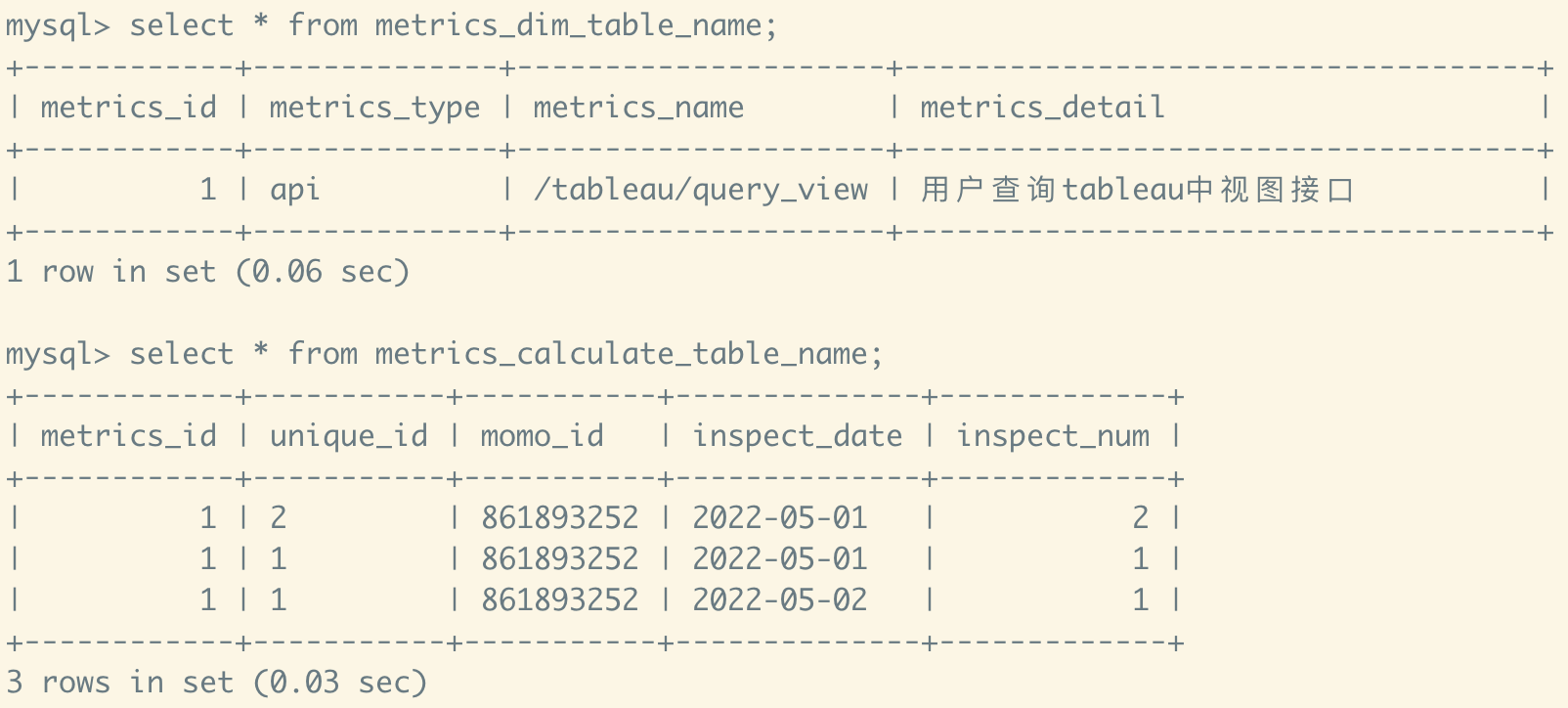
CREATE TABLE IF NOT EXISTS online_test.metrics_dim_table_name
(
`metrics_id` INT NOT NULL COMMENT "指標維度表唯一id標識",
`metrics_type` VARCHAR(50) NOT NULL COMMENT "指標類型",
`metrics_name` VARCHAR(50) NOT NULL COMMENT "指標名稱",
`metrics_detail` VARCHAR(500) COMMENT "指標詳情"
)
UNIQUE KEY(`metrics_id`, `metrics_type`, `metrics_name`)
DISTRIBUTED BY HASH(metrics_id) BUCKETS 10
PROPERTIES("replication_num" = "1");
CREATE TABLE IF NOT EXISTS online_test.metrics_calculate_table_name
(
metrics_id INT DEFAULT '0' COMMENT '所屬指標id'
,unique_id VARCHAR(50) DEFAULT '' COMMENT '指標唯一標識、可以是id或者name'
,momo_id VARCHAR(20) DEFAULT '' COMMENT '查看者momoid'
,inspect_date VARCHAR(10) DEFAULT '' COMMENT '查看時間、格式為YYYY-MM-DD、按天聚合'
,inspect_num INT SUM DEFAULT '0' COMMENT '查看次數、聚合模式、記錄每個人每天查看某個指標多少次'
)
AGGREGATE KEY(metrics_id, unique_id, momo_id, inspect_date)
DISTRIBUTED BY HASH(unique_id) BUCKETS 10
PROPERTIES("replication_num" = "1");
- 例如我需要記錄信息查詢介面調用情況,我需要先在維度表中手動插入一條數據,記錄這個指標的詳細信息
insert into metrics_dim_table_name values
(1, 'api', '/tableau/query_view', '用戶查詢tableau中視圖介面');
- 之後我在介面中埋點,每調用一次往doris中插入一條數據
insert into metrics_calculate_table_name values
(1, '1', '861893252', '2022-05-01', 1),
(1, '2', '861893252', '2022-05-01', 1),
(1, '2', '861893252', '2022-05-01', 1),
(1, '1', '861893252', '2022-05-02', 1);
- 聚合結果如下
使用Doris作為元數據
- 之後把doris當做關係型數據來使用,可以在毫秒內返回查詢結果,因為數據按天聚合過,數據量與MySQL相比也少了很多,針對這類需要都可以考慮使用doris聚合模型實現


