
亂序問題 在業務編寫 FlinkSQL 時, 非常常見的就是亂序相關問題, 在出現問題時,非常難以排查,且無法穩定復現,這樣無論是業務方,還是平臺方,都處於一種非常尷尬的地步。 亂序問題 在業務編寫 FlinkSQL 時, 非常常見的就是亂序相關問題, 在出現問題時,非常難以排查,且無法穩定復現,這 ...
亂序問題
在業務編寫 FlinkSQL 時, 非常常見的就是亂序相關問題, 在出現問題時,非常難以排查,且無法穩定復現,這樣無論是業務方,還是平臺方,都處於一種非常尷尬的地步。
亂序問題
在業務編寫 FlinkSQL 時, 非常常見的就是亂序相關問題, 在出現問題時,非常難以排查,且無法穩定復現,這樣無論是業務方,還是平臺方,都處於一種非常尷尬的地步。
在實時 join 中, 如果是 Regular Join, 則使用的是 Hash Join 方式, 左表和右表根據 Join Key 進行hash,保證具有相同 Join Key 的數據能夠 Hash 到同一個併發,進行 join 的計算 。
在實時聚合中, 主要普通的 group window, over window, time window 這幾中開窗方式,都涉及到 task 和 task 之間 hash 方式進行數據傳輸。
因此, 在比較複雜的邏輯中, 一條數據在整個數據流中需要進行不同的 hash 方式, 特別時當我們處理 CDC 數據時, 一定要要求數據嚴格有序, 否則可能會導致產生錯誤的結果。
以下麵的例子進行說明, 以下有三張表, 分別是訂單表, 訂單明細表, 和商品類目 。
- 這三張表的實時數據都從 MySQL 採集得到並實時寫入 Kafka, 均會實時發生變化, 無法使用視窗計算
- 除了訂單表有訂單時間, 其他兩張表都沒有時間屬性, 因此無法使用watermark
CREATE TABLE orders (
order_id VARCHAR,
order_time TIMESTAMP
) WITH (
'connector' = 'kafka',
'format' = 'changelog-json'
...
);
CREATE TABLE order_item (
order_id VARCHAR,
item_id VARCHAR
) WITH (
'connector' = 'kafka',)
'format' = 'changelog-json'
...
);
CREATE TABLE item_detail (
item_id VARCHAR,
item_name VARCHAR,
item_price BIGINT
) WITH (
'connector' = 'kafka',
'format' = 'changelog-json'
...
);
使用 Regular Join 進行多路 Join,數據表打寬操作如下所示
SELECT o.order_id, i.item_id, d.item_name, d.item_price, o.order_time
FROM orders o
LEFT JOIN order_item i ON o.order_id = i.order_id
LEFT JOIN item_detail d ON i.item_id = d.item_id
最終生成的 DAG 圖如下所示:
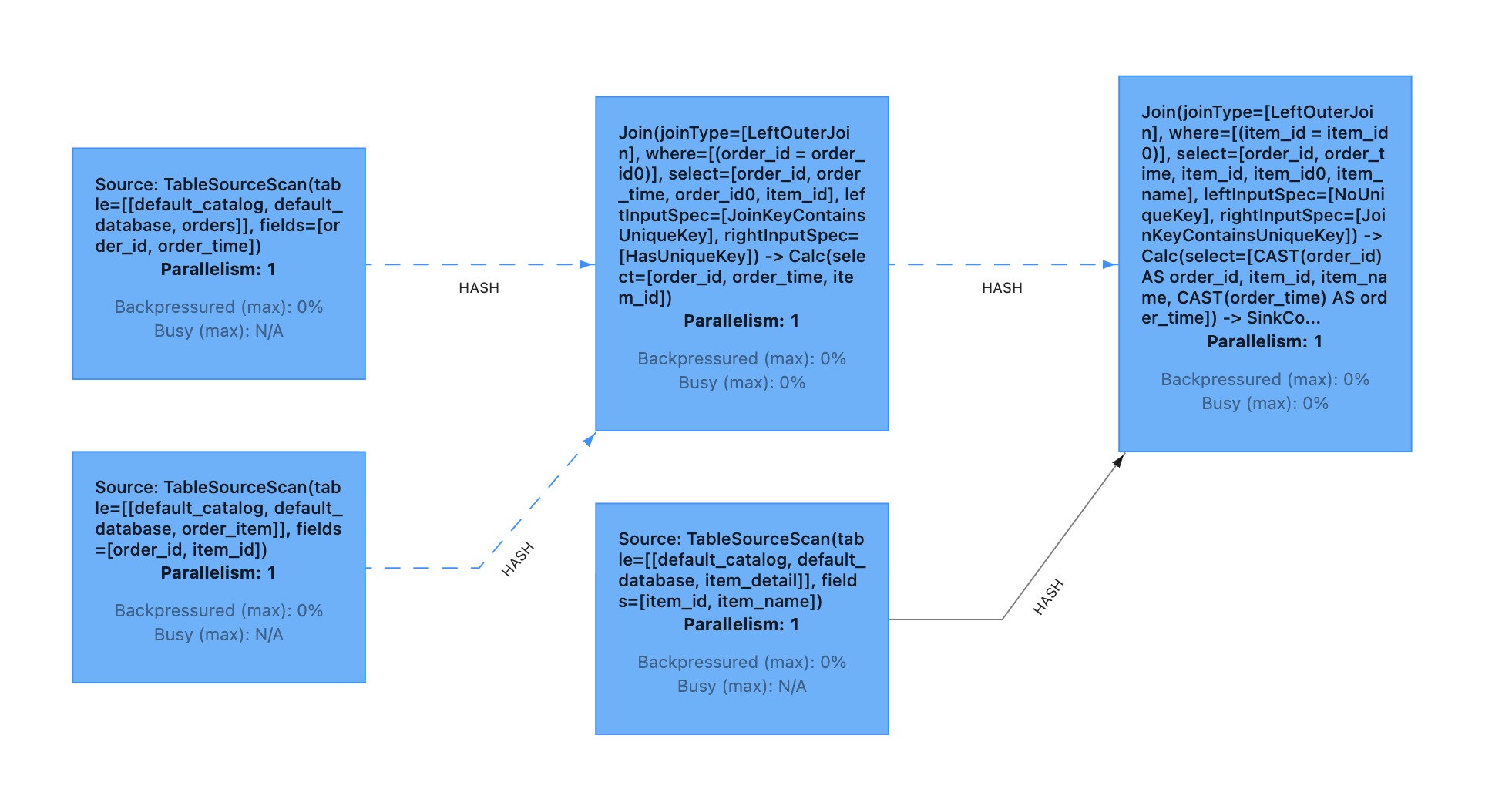
可以發現:
第一個 join (後面統一簡稱為ijoin1)的條件是 order_id,該 join 的兩個輸入會以 order_id 進行hash,具有相同 order_id 的數據能夠被髮送到同一個 subtask
第二個 join (後面統一簡稱為 join2)的條件則是 item_id, 該 join 的兩個輸入會以 item_id 進行hash,具有相同 item_id 的數據則會被髮送到同一個 subtask.
正常情況下, 具有相同 order_id 的數據, 一定具有相同的 item_id,但由於上面的示例代碼中,我們使用的是 left join 的寫法, 即使沒有 join 上, 也會輸出為 null 的數據,這樣可能導致了最終結果的不確定性。
以下麵的數據為示例,再詳細說明一下:
TABLE orders
| order_id | order_time |
|---|---|
| id_001 | 2022-06-03 00:00:00 |
TABLE order_item
| order_id | item_id |
|---|---|
| id_001 | item_001 |
TABLE item_detail
| item_id | item_name | item_price |
|---|---|---|
| item_001 | 類目1 | 10 |
輸出數據如下:
1) 表示輸出數據的併發
+I 表示數據的屬性 (+I, , -D, -U, +U)
第一個 JOIN 輸出
1) +I(id_001, null, 2022-06-03 00:00:00)
1) -D(id_001, null, 2022-06-03 00:00:00)
1) +I(id_001, item_001, 2022-06-03 00:00:00)
第二個 JOIN 輸出
1) +I(id_001, null, null, null, 2022-06-03 00:00:00)
1) -D(id_001, null, null, null, 2022-06-03 00:00:00)
2) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) +I(id_001, item_001, 類目1, 10, 2022-06-03 00:00:00)
以上結果只是上述作業可能出現的情況之一,實際運行時並不一定會出現。 我們可以發現 join1 結果發送到 join2 之後, 相同的 order_id 並不一定會發送到同一個 subtask,因此當數據經過了 join2, 相同的 order_id 的數據會落到不同的併發,這樣在後續的數據處理中, 有非常大的概率會導致最終結果的不確定性。
我們再細分以下場景考慮, 假設經過 join2 之後的結果為 join_view:
- 假設 join2 之後,我們基於 item_id 進行聚合, 統計相同類目的訂單數
SELECT item_id, sum(order_id)
FROM join_view
GROUP BY item_id
很顯然, 上述的亂序問題並不會影響這段邏輯的結果, item_id 為 null 的數據會進行計算, 但並不會影響 item_id 為 item_001 的結果.
- 假設 join2 之後, 我們將結果直接寫入 MySQL, MySQL 主鍵為 order_id
CREATE TABLE MySQL_Sink (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id) NOT ENFORCED
) with (
'connector' = 'jdbc'
);
INSERT INTO MySQL_Sink SELECT * FROM JOIN_VIEW;
由於我們在 Sink connector 中未單獨設置併發, 因此 sink 的併發度是和 join2 的併發是一樣的, 因此 join2 的輸出會直接發送給 sink 運算元, 並寫入到 MySQL 中。
由於是不同併發同時在寫 MySQL ,所以實際寫 MySQL的順序可能如下所示:
2) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) +I(id_001, item_001, 類目1, 10, 2022-06-03 00:00:00)
1) +I(id_001, null, null, 2022-06-03 00:00:00)
1) -D(id_001, null, null, 2022-06-03 00:00:00)
很顯然, 最終結果會是 為 空, 最終寫入的是一條 delete 數據
- 假設 join2 之後, 我們將結果直接寫入 MySQL, 主鍵為 order_id, item_id, item_name
CREATE TABLE MySQL_Sink (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id) NOT ENFORCED
) with (
'connector' = 'jdbc'
);
INSERT INTO MySQL_Sink SELECT * FROM JOIN_VIEW;
和示例2一樣, 我們未單獨設置 sink 的併發, 因此數據會之間發送到 sink 運算元, 假設寫入 MySQL 的順序和示例2一樣:
2) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) +I(id_001, item_001, 類目1, 10, 2022-06-03 00:00:00)
1) +I(id_001, null, null, null, 2022-06-03 00:00:00)
1) -D(id_001, null, null, null, 2022-06-03 00:00:00)
最終結果會是
2) +I(id_001, item_001, 類目1, 2022-06-03 00:00:00)
由於 MySQL 的主鍵是 order_id, item_id, item_name 所以最後的 -D 記錄並不會刪除 subtask 2 寫入的數據, 這樣最終的結果是正確的。
- 假設 join2 之後, 我們將結果寫入 kafka,寫入格式為 changelog-json , 下游作業消費 kafka 併進行處理
CREATE TABLE kafka_sink (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id, item_id, item_name) NOT ENFORCED
) with (
'connector' = 'kafka',
'format' = 'changelog-json',
'topic' = 'join_result'
);
INSERT INTO kafka_sink select * from JOIN_VIEW;
預設,如果不設置 partitioner, kafka sink 會以我們在 DDL 中配置的主鍵生成對應的 hash key, 用於通過 hash 值生成 partition id。
有一點我們需要註意, 由於 join2 的輸出已經在不同的併發了, 所以無論 kafka_sink 選擇以 order_id 作為唯一的主鍵, 還是以 order_id, item_id, item_name 作為主鍵, 我們都無法控制不同併發寫入 kafka 的順序, 我們只能確保相同的併發的數據能夠有序的被寫入 kafka 的同一 partition 。
- 如果設置 order_id 為主鍵, 我們可以保證上述的所有數據能夠被寫入同一個 partition
- 如果設置 order_id, item_id, item_name 則上面不同併發的輸出可能會被寫入到不同的 partition
所以,我們需要關註的是, 當數據寫入 kafka 之後, 下游怎麼去處理這一份數據:
- 基於 order_id 進行去重,並按天聚合,計算當天的累加值。
以下麵的 SQL 為例, 下游在消費 kafka 時, 為了避免數據重覆, 先基於 order_id 做了一次去重, 用 order_id 作為分區條件, 基於proctime() 進行去重 (增加table.exec.source.cdc-events-duplicate該參數, 框架會自動生成去重運算元).
-- https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/config/
set 'table.exec.source.cdc-events-duplicate'='true';
CREATE TABLE kafka_source (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id) NOT ENFORCED
) with (
'connector' = 'kafka',
'format' = 'changelog-json',
'topic' = 'join_result'
);
-- 按order_time 聚合, 計算每天的營收
SELECT DATE_FORMAT(order_time, 'yyyy-MM-dd'), sum(item_price)
FROM kafka_source
GROUP BY DATE_FORMAT(order_time, 'yyyy-MM-dd')
結果上述的計算,我們預計結果會如何輸出:
去重之後可能的輸出為:
1) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) +I(id_001, item_001, 類目1, 10, 2022-06-03 00:00:00)
1) -D(id_001, item_001, 類目1, 10, 2022-06-03 00:00:00)
1) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
經過聚合運算元運算元:
1) +I(2022-06-03, null)
1) -D(2022-06-03, null)
1) +I(2022-06-03, 10)
1) -D(2022-06-03, 10)
1) +I(2022-06-03, 0)
1) -D(2022-06-03, 0)
1) +I(2022-06-03, null)
1) -D(2022-06-03, null)
可以發現,最終輸出結果為2022-06-03, null,本文列舉的示例不夠完善, 正常情況下, 當天肯定會有其他的記錄, 結果當天的結果可能不會為 null, 但我們可以知道的是,由於數據的亂序, 數據和實際結果已經不准確了。
2) 基於order_id, item_id, item_name 去重,之後按天聚合,計算當天的累加值。
-- https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/config/
set 'table.exec.source.cdc-events-duplicate'='true';
CREATE TABLE kafka_source (
order_id VARCHAR,
item_id VARCHAR,
item_name VARCHAR,
item_price INT,
order_time TIMESTAMP,
PRIMARY KEY (order_id, item_id, item_name) NOT ENFORCED
) with (
'connector' = 'kafka',
'format' = 'changelog-json',
'topic' = 'join_result'
);
-- 按order_time 聚合, 計算每天的營收
SELECT DATE_FORMAT(order_time, 'yyyy-MM-dd'), sum(item_price)
FROM kafka_source
GROUP BY DATE_FORMAT(order_time, 'yyyy-MM-dd')
去重之後的輸出:
1) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
1) +I(id_001, item_001, 類目1, 10, 2022-06-03 00:00:00)
2) +I(id_001, item_001, null, null, 2022-06-03 00:00:00)
2) -D(id_001, item_001, null, null, 2022-06-03 00:00:00)
由於我們主鍵設置的是 order_id, item_id, item_name 所以
(id_001, item_001, null, null, 2022-06-03 00:00:00) 和
1) +I(id_001, item_001, 類目1, 10, 2022-06-03 00:00:00) 是不同的主鍵, 所以並不會互相影響。
經過聚合之後的結果:
1) +I(2022-06-03, null)
1) -D(2022-06-03, null)
1) +I(2022-06-03, 10)
1) -D(2022-06-03, 10)
1) +I(2022-06-03, 10)
1) -D(2022-06-03, 10)
1) +I(2022-06-03, 10)
以上就是最終結果的輸出, 可以發現我們最終的結果是沒有問題的。
原因分析
下圖是原始作業的數據流轉變化情況
graph LR orders(orders) --> |hash:order_id| join1(join1) order_item(order_item) -->|hash:order_id| join1 join1 --> |hash:item_id| join2(join2) item_detail(item_detail) --> |hash:item_id| join2- A 基於 item_id 聚合, 計算相同類目的訂單數 (結果正確)
- B 將join的數據 sink 至 MySQL (主鍵為 order_id) (結果錯誤)
- C 將join的數據 sink 至 MySQL (主鍵為 order_id, item_id, item_name) (結果正確)
- D 將 join 的數據 sink 至 kafka, 下游消費 kafka 數據併進行去重處理, 下游處理時,又可以分為兩種情況。
- D-1 按 order_id 分區並去重 (結果錯誤)
- D-2 按 order_id, item_id, item_name 分區並去重 (結果正確)
graph TD join2(join2) --> |forward| sink(sink key) sink --> |kafka client| kafka(Kafka fixed partitioner) kafka --> |hash:order_id+item_id+item_name| rank(rank orderby:proctime) rank --> |"hash:date_format(order_time, 'yyyy-MM-dd')"| group("group agg:sum(item_price)")
從上面 A, B, C, D-1, D-2 這四種 case, 我們不難發現, 什麼情況下會導致錯誤的結果, 什麼情況下不會導致錯誤的結果, 關鍵還是要看每個 task 之間的 hash 規則。
case B 產生亂序主要原因時在 sink operator, hash的條件由原來的 order_id+item_id_item_name 變成了 order_id
case D-1 產生亂序主要發生在去重的 operator, hash 的規則由原來的 order_id+item_id+item_name 變為了 order_id
我們大概能總結以下幾點經驗
- Flink 框架在可以保證 operator 和 operator hash 時, 一定是可以保證具有相同 hash 值的數據的在兩個 operator 之間傳輸順序性
- Flink 框架無法保證數據連續多個 operator hash 的順序, 當 operator 和 operator 之間的 hash 條件發生變化, 則有可能出現數據的順序性問題。
- 當 hash 條件由少變多時, 不會產生順序問題, 當 hash 條件由多變少時, 則可能會產生順序問題。
總結
大多數業務都是拿著原來的實時任務, 核心邏輯不變,只是把原來的 Hive 替換成 消息隊列的 Source 表, 這樣跑出來的結果,一般情況下就很難和離線對上,雖然流批一體是 Flink 的優勢, 但對於某些 case , 實時的結果和離線的結果還是會產生差異, 因此我們在編寫 FlinkSQL 代碼時, 一定要確保數據的準備性, 在編寫代碼時,一定要知道我們的數據大概會產生怎樣的流動, 產生怎樣的結果, 這樣寫出來的邏輯才是符合預期的。


