
一、基本說明 • Oracle 中的函數可以返回表類型,但是這個表類型實際上是集合類型(與數組類似)。從 Oracle 9i 開始,提供了一個叫做"管道化表函數"來解決此問題。 • 管道化表函數,必須返回一個集合類型,且標明 pipelined。它不能返回具體變數,必須以一個空 return 返回, ...
第10章 企業級調優
10.1 執行計劃(Explain)
1)基本語法
EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query
2)案例實操
(1)查看下麵這條語句的執行計劃
沒有生成MR任務的
hive (default)> explain select * from emp;
Explain
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
TableScan
alias: emp
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: empno (type: int), ename (type: string), job (type: string), mgr (type: int), hiredate (type: string), sal (type: double), comm (type: double), deptno (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
ListSink
有生成MR任務的
hive (default)> explain select deptno, avg(sal) avg_sal from emp group by deptno;
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: emp
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: sal (type: double), deptno (type: int)
outputColumnNames: sal, deptno
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(sal), count(sal)
keys: deptno (type: int)
mode: hash
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: double), _col2 (type: bigint)
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0), count(VALUE._col1)
keys: KEY._col0 (type: int)
mode: mergepartial
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), (_col1 / _col2) (type: double)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 7020 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
(2)查看詳細執行計劃
hive (default)> explain extended select * from emp;
hive (default)> explain extended select deptno, avg(sal) avg_sal from emp group by deptno;
10.2 Fetch抓取
Fetch抓取是指,Hive中對某些情況的查詢可以不必使用MapReduce計算。例如:SELECT * FROM employees;在這種情況下,Hive可以簡單地讀取employee對應的存儲目錄下的文件,然後輸出查詢結果到控制台。
在hive-default.xml.template文件中hive.fetch.task.conversion預設是more,老版本hive預設是minimal,該屬性修改為more以後,在全局查找、欄位查找、limit查找等都不走mapreduce。
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
1)案例實操:
(1)把hive.fetch.task.conversion設置成none,然後執行查詢語句,都會執行mapreduce程式。
hive (default)> set hive.fetch.task.conversion=none;
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;
(2)把hive.fetch.task.conversion設置成more,然後執行查詢語句,如下查詢方式都不會執行mapreduce程式。
hive (default)> set hive.fetch.task.conversion=more;
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;
10.3 本地模式
大多數的Hadoop Job是需要Hadoop提供的完整的可擴展性來處理大數據集的。不過,有時Hive的輸入數據量是非常小的。在這種情況下,為查詢觸發執行任務消耗的時間可能會比實際job的執行時間要多的多。
對於大多數這種情況,Hive可以通過本地模式在單台機器上處理所有的任務。對於小數據集,執行時間可以明顯被縮短。
用戶可以通過設置hive.exec.mode.local.auto的值為true,來讓Hive在適當的時候自動啟動這個優化。
set hive.exec.mode.local.auto=true; //開啟本地mr
//設置local mr的最大輸入數據量,當輸入數據量小於這個值時採用local mr的方式,預設為134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//設置local mr的最大輸入文件個數,當輸入文件個數小於這個值時採用local mr的方式,預設為4
set hive.exec.mode.local.auto.input.files.max=10;
1)案例實操:
(1)開啟本地模式,並執行查詢語句
hive (default)> set hive.exec.mode.local.auto=true;
hive (default)> select * from emp cluster by deptno;
Time taken: 1.328 seconds, Fetched: 14 row(s)
(2)關閉本地模式,並執行查詢語句
hive (default)> set hive.exec.mode.local.auto=false;
hive (default)> select * from emp cluster by deptno;
Time taken: 20.09 seconds, Fetched: 14 row(s)
10.4 表的優化
10.4.1 小表大表Join(MapJoin)
將key相對分散,並且數據量小的表放在join的左邊,這樣可以有效減少記憶體溢出錯誤發生的幾率;再進一步,可以使用map join讓小的維度表(1000條以下的記錄條數)先進記憶體。在map端完成join。
實際測試發現:新版的hive已經對小表JOIN大表和大表JOIN小表進行了優化。小表放在左邊和右邊已經沒有明顯區別。
案例實操
1)需求
測試大表JOIN小表和小表JOIN大表的效率
2)開啟MapJoin參數設置
(1)設置自動選擇Mapjoin
set hive.auto.convert.join = true; 預設為true
(2)大表小表的閾值設置(預設25M以下認為是小表):
set hive.mapjoin.smalltable.filesize = 25000000;
3)MapJoin工作機制
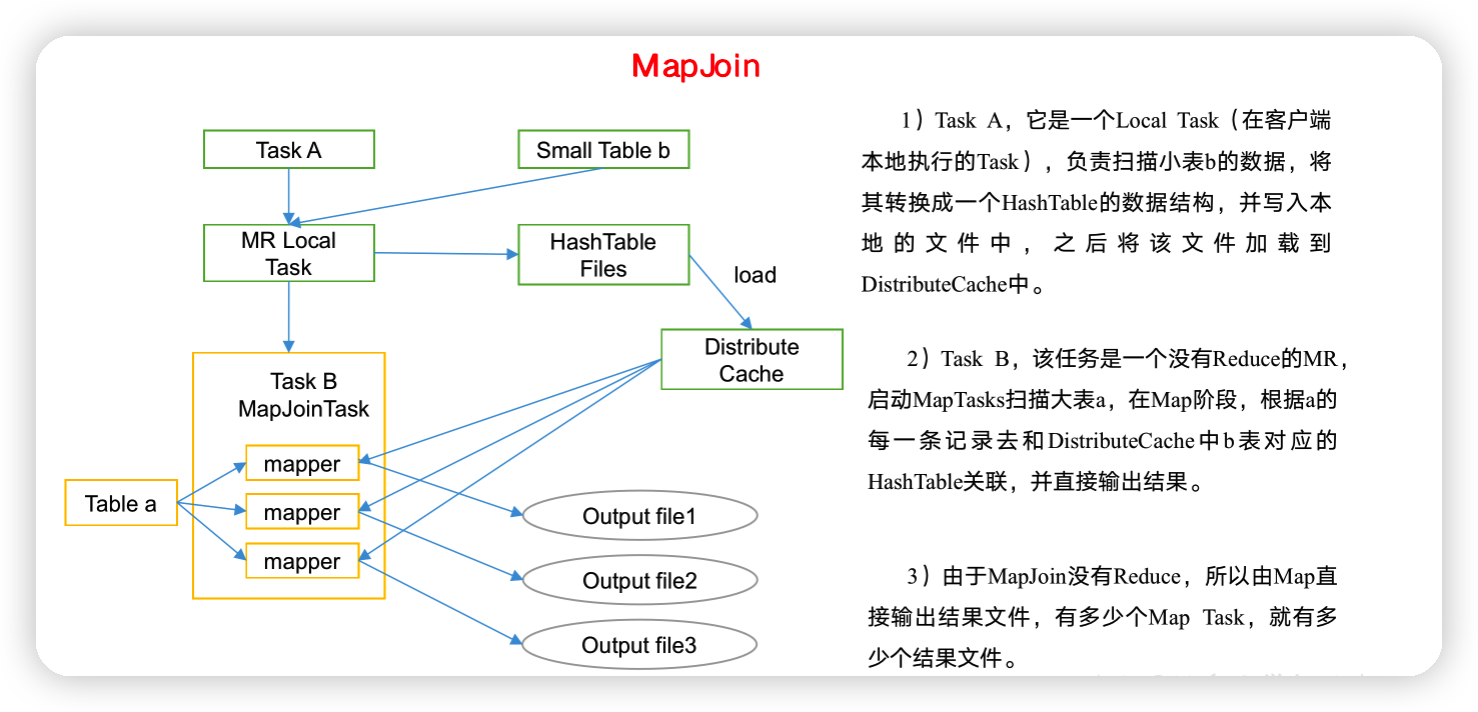
4)建大表、小表和JOIN後表的語句
// 創建大表
create table bigtable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 創建小表
create table smalltable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 創建join後表的語句
create table jointable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
5)分別向大表和小表中導入數據
hive (default)> load data local inpath '/opt/module/hive/datas/bigtable' into table bigtable;
hive (default)>load data local inpath '/opt/module/hive/datas/smalltable' into table smalltable;
6)小表JOIN大表語句
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from smalltable s
join bigtable b
on b.id = s.id;
Time taken: 35.921 seconds
No rows affected (44.456 seconds)
7)執行大表JOIN小表語句
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable b
join smalltable s
on s.id = b.id;
Time taken: 34.196 seconds
No rows affected (26.287 seconds)
10.4.2 大表Join大表
1)空KEY過濾
有時join超時是因為某些key對應的數據太多,而相同key對應的數據都會發送到相同的reducer上,從而導致記憶體不夠。此時我們應該仔細分析這些異常的key,很多情況下,這些key對應的數據是異常數據,我們需要在SQL語句中進行過濾。例如key對應的欄位為空,操作如下:
案例實操
(1)配置歷史伺服器
配置mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
啟動歷史伺服器
sbin/mr-jobhistory-daemon.sh start historyserver
查看jobhistory
http://hadoop102:19888/jobhistory
(2)創建原始數據表、空id表、合併後數據表
// 創建空id表
create table nullidtable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
(3)分別載入原始數據和空id數據到對應表中
hive (default)> load data local inpath '/opt/module/hive/datas/nullid' into table nullidtable;
(4)測試不過濾空id
hive (default)> insert overwrite table jointable select n.* from nullidtable n
left join bigtable o on n.id = o.id;
(5)測試過濾空id
hive (default)> insert overwrite table jointable select n.* from (select * from nullidtable where id is not null ) n left join bigtable o on n.id = o.id;
2)空key轉換
有時雖然某個key為空對應的數據很多,但是相應的數據不是異常數據,必須要包含在join的結果中,此時我們可以表a中key為空的欄位賦一個隨機的值,使得數據隨機均勻地分不到不同的reducer上。例如:
案例實操:
不隨機分佈空null值:
(1)設置5個reduce個數
set mapreduce.job.reduces = 5;
(2)JOIN兩張表
insert overwrite table jointable
select n.* from nullidtable n left join bigtable b on n.id = b.id;
結果:如下圖所示,可以看出來,出現了數據傾斜,某些reducer的資源消耗遠大於其他reducer。
隨機分佈空null值
(1)設置5個reduce個數
set mapreduce.job.reduces = 5;
(2)JOIN兩張表
insert overwrite table jointable
select n.* from nullidtable n full join bigtable o on
nvl(n.id,rand()) = o.id;
結果:如下圖所示,可以看出來,消除了數據傾斜,負載均衡reducer的資源消耗
3)SMB(Sort Merge Bucket join)
(1)創建第二張大表
create table bigtable2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/bigtable' into table bigtable2;
測試大表直接JOIN
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable s
join bigtable2 b
on b.id = s.id;
(2)創建分桶表1,桶的個數不要超過可用CPU的核數
create table bigtable_buck1(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
insert into bigtable_buck1 select * from bigtable;
(3)創建分通表2,桶的個數不要超過可用CPU的核數
create table bigtable_buck2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
insert into bigtable_buck2 select * from bigtable;
(4)設置參數
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
(5)測試
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
10.4.3 Group By
預設情況下,Map階段同一Key數據分發給一個reduce,當一個key數據過大時就傾斜了。

並不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端進行部分聚合,最後在Reduce端得出最終結果。
1)開啟Map端聚合參數設置
(1)是否在Map端進行聚合,預設為True
set hive.map.aggr = true
(2)在Map端進行聚合操作的條目數目
set hive.groupby.mapaggr.checkinterval = 100000
(3)有數據傾斜的時候進行負載均衡(預設是false)
set hive.groupby.skewindata = true
當選項設定為 true,生成的查詢計劃會有兩個MR Job。第一個MR Job中,Map的輸出結果會隨機分佈到Reduce中,每個Reduce做部分聚合操作,並輸出結果,這樣處理的結果是相同的Group By Key有可能被分發到不同的Reduce中,從而達到負載均衡的目的;第二個MR Job再根據預處理的數據結果按照Group By Key分佈到Reduce中(這個過程可以保證相同的Group By Key被分佈到同一個Reduce中),最後完成最終的聚合操作。
hive (default)> select deptno from emp group by deptno;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 23.68 sec HDFS Read: 19987 HDFS Write: 9 SUCCESS
Total MapReduce CPU Time Spent: 23 seconds 680 msec
OK
deptno
10
20
30
優化以後
hive (default)> set hive.groupby.skewindata = true;
hive (default)> select deptno from emp group by deptno;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 28.53 sec HDFS Read: 18209 HDFS Write: 534 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 5 Cumulative CPU: 38.32 sec HDFS Read: 15014 HDFS Write: 9 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 6 seconds 850 msec
OK
deptno
10
20
30
10.4.4 Count(Distinct) 去重統計
數據量小的時候無所謂,數據量大的情況下,由於COUNT DISTINCT操作需要用一個Reduce Task來完成,這一個Reduce需要處理的數據量太大,就會導致整個Job很難完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替換,但是需要註意group by造成的數據傾斜問題.
1) 案例實操
(1)創建一張大表
hive (default)> create table bigtable(id bigint, time bigint, uid string, keyword
string, url_rank int, click_num int, click_url string) row format delimited
fields terminated by '\t';
(2)載入數據
hive (default)> load data local inpath '/opt/module/datas/bigtable' into table bigtable;
(3)設置5個reduce個數
set mapreduce.job.reduces = 5;
(4)執行去重id查詢
hive (default)> select count(distinct id) from bigtable;
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.12 sec HDFS Read: 120741990 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 120 msec
OK
c0
100001
Time taken: 23.607 seconds, Fetched: 1 row(s)
(5)採用GROUP by去重id
hive (default)> select count(id) from (select id from bigtable group by id) a;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 17.53 sec HDFS Read: 120752703 HDFS Write: 580 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 4.29 sec2 HDFS Read: 9409 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 21 seconds 820 msec
OK
_c0
100001
Time taken: 50.795 seconds, Fetched: 1 row(s)
雖然會多用一個Job來完成,但在數據量大的情況下,這個絕對是值得的。
10.4.5 笛卡爾積
儘量避免笛卡爾積,join的時候不加on條件,或者無效的on條件,Hive只能使用1個reducer來完成笛卡爾積。
10.4.6 行列過濾
列處理:在SELECT中,只拿需要的列,如果有分區,儘量使用分區過濾,少用SELECT *。
行處理:在分區剪裁中,當使用外關聯時,如果將副表的過濾條件寫在Where後面,那麼就會先全表關聯,之後再過濾,比如:
案例實操:
1)測試先關聯兩張表,再用where條件過濾
hive (default)> select o.id from bigtable b
join bigtable o.id = b.id
where o.id <= 10;
Time taken: 34.406 seconds, Fetched: 100 row(s)
2)通過子查詢後,再關聯表
hive (default)> select b.id from bigtable b
join (select id from bigtable where id <= 10 ) o on b.id = o.id;
Time taken: 30.058 seconds, Fetched: 100 row(s)
10.4.7 分區
詳見7.1章。
10.4.8 分桶
詳見7.2章。
10.5 合理設置Map及Reduce數
1)通常情況下,作業會通過input的目錄產生一個或者多個map任務。
主要的決定因素有:input的文件總個數,input的文件大小,集群設置的文件塊大小。
2)是不是map數越多越好?
答案是否定的。如果一個任務有很多小文件(遠遠小於塊大小128m),則每個小文件也會被當做一個塊,用一個map任務來完成,而一個map任務啟動和初始化的時間遠遠大於邏輯處理的時間,就會造成很大的資源浪費。而且,同時可執行的map數是受限的。
3)是不是保證每個map處理接近128m的文件塊,就高枕無憂了?
答案也是不一定。比如有一個127m的文件,正常會用一個map去完成,但這個文件只有一個或者兩個小欄位,卻有幾千萬的記錄,如果map處理的邏輯比較複雜,用一個map任務去做,肯定也比較耗時。
針對上面的問題2和3,我們需要採取兩種方式來解決:即減少map數和增加map數;
10.5.1 複雜文件增加Map數
當input的文件都很大,任務邏輯複雜,map執行非常慢的時候,可以考慮增加Map數,來使得每個map處理的數據量減少,從而提高任務的執行效率。
增加map的方法為:根據
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M公式,調整maxSize最大值。讓maxSize最大值低於blocksize就可以增加map的個數。
案例實操:
1)執行查詢
hive (default)> select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2)設置最大切片值為100個位元組
hive (default)> set mapreduce.input.fileinputformat.split.maxsize=100;
hive (default)> select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 6; number of reducers: 1
10.5.2 小文件進行合併
1)在map執行前合併小文件,減少map數:CombineHiveInputFormat具有對小文件進行合併的功能(系統預設的格式)。HiveInputFormat沒有對小文件合併功能。
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2)在Map-Reduce的任務結束時合併小文件的設置:
在map-only任務結束時合併小文件,預設true
SET hive.merge.mapfiles = true;
在map-reduce任務結束時合併小文件,預設false
SET hive.merge.mapredfiles = true;
合併文件的大小,預設256M
SET hive.merge.size.per.task = 268435456;
當輸出文件的平均大小小於該值時,啟動一個獨立的map-reduce任務進行文件merge
SET hive.merge.smallfiles.avgsize = 16777216;
10.5.3 合理設置Reduce數
1)調整reduce個數方法一
(1)每個Reduce處理的數據量預設是256MB
hive.exec.reducers.bytes.per.reducer=256000000
(2)每個任務最大的reduce數,預設為1009
hive.exec.reducers.max=1009
(3)計算reducer數的公式
N=min(參數2,總輸入數據量/參數1)
2)調整reduce個數方法二
在hadoop的mapred-default.xml文件中修改
設置每個job的Reduce個數
set mapreduce.job.reduces = 15;
3)reduce個數並不是越多越好
- 過多的啟動和初始化reduce也會消耗時間和資源;
- 另外,有多少個reduce,就會有多少個輸出文件,如果生成了很多個小文件,那麼如果這些小文件作為下一個任務的輸入,則也會出現小文件過多的問題;
在設置reduce個數的時候也需要考慮這兩個原則:處理大數據量利用合適的reduce數;使單個reduce任務處理數據量大小要合適;
10.6 並行執行
Hive會將一個查詢轉化成一個或者多個階段。這樣的階段可以是MapReduce階段、抽樣階段、合併階段、limit階段。或者Hive執行過程中可能需要的其他階段。預設情況下,Hive一次只會執行一個階段。不過,某個特定的job可能包含眾多的階段,而這些階段可能並非完全互相依賴的,也就是說有些階段是可以並行執行的,這樣可能使得整個job的執行時間縮短。不過,如果有更多的階段可以並行執行,那麼job可能就越快完成。
通過設置參數hive.exec.parallel值為true,就可以開啟併發執行。不過,在共用集群中,需要註意下,如果job中並行階段增多,那麼集群利用率就會增加。
set hive.exec.parallel=true; //打開任務並行執行
set hive.exec.parallel.thread.number=16; //同一個sql允許最大並行度,預設為8。
當然,得是在系統資源比較空閑的時候才有優勢,否則,沒資源,並行也起不來。
10.7 嚴格模式
Hive可以通過設置防止一些危險操作:
1)分區表不使用分區過濾
將hive.strict.checks.no.partition.filter設置為true時,對於分區表,除非where語句中含有分區欄位過濾條件來限制範圍,否則不允許執行。換句話說,就是用戶不允許掃描所有分區。進行這個限制的原因是,通常分區表都擁有非常大的數據集,而且數據增加迅速。沒有進行分區限制的查詢可能會消耗令人不可接受的巨大資源來處理這個表。
2)使用order by沒有limit過濾
將hive.strict.checks.orderby.no.limit設置為true時,對於使用了order by語句的查詢,要求必須使用limit語句。因為order by為了執行排序過程會將所有的結果數據分發到同一個Reducer中進行處理,強制要求用戶增加這個LIMIT語句可以防止Reducer額外執行很長一段時間。
3)笛卡爾積
將hive.strict.checks.cartesian.product設置為true時,會限制笛卡爾積的查詢。對關係型資料庫非常瞭解的用戶可能期望在 執行JOIN查詢的時候不使用ON語句而是使用where語句,這樣關係資料庫的執行優化器就可以高效地將WHERE語句轉化成那個ON語句。不幸的是,Hive並不會執行這種優化,因此,如果表足夠大,那麼這個查詢就會出現不可控的情況。
10.8 JVM重用
詳見hadoop優化文檔中jvm重用
10.9 壓縮
詳見第9章。
IT學習網站
大數據高薪訓練營 完結
鏈接:https://pan.baidu.com/s/1ssRD-BYOiiMw30EV_BLMWQ
提取碼:dghu
失效加V:x923713
QQ交流群 歡迎加入



