
資料庫安全,是指以保護資料庫系統、資料庫伺服器和資料庫中的數據、應用、存儲,以及相關網路連接為目的,防止資料庫系統及其數據遭到泄露、篡改或破壞的安全技術。 資料庫是企業最為核心的數據保護對象。與傳統的網路安全防護體系不同,資料庫安全技術更加註重從客戶內部的角度出發做安全,其安全要求包括了保密性、完整 ...
順序保證難點
本文主要分析 CDC 業務場景中任務級順序保證,技術選型為:debezium、kafka、flink,其構成了順序保證中至關重要的每一環,應該充分考慮、分析各組件的對於順序的支持。
首先 debezium 作為採集組件,其分別為 schema topic 和 data topic 提供了不同的時間欄位,如下圖 schema topic 中提供了事件時間,data topic 中提供了事件時間和採集時間,為後續數據處理提供了依據。


Kafka 作為一款性能優秀的消息隊列,在分散式事務中有著廣泛地應用,其為了做到水平擴展,達到提高併發的目的,將一個 topic 分佈到多個 broker(伺服器)上,即一個 topic 可以分為多個 partition,每個 partition 是一個有序的隊列。Kafka 在發送消息時,producer 可以知道相關 topic 的集群信息,從而將消息按照不同的策略發送到不同的分區。常見的分區策略有很多種(常用包括輪詢、隨機、按分區權重、就近原則、按消息鍵分區等策略)。各個分區中的消息比較獨立,很難有一種高效的方法來判斷不同分區的順序。
Flink 程式本質上是分散式並行程式。在程式執行期間,一個流有一個或多個流分區(Stream Partition),每個運算元有一個或多個運算元子任務(Operator Subtask),每個子任務彼此獨立,併在不同的線程、節點或容器中運行。
Flink 運算元之間可以通過一對一(直傳)模式或重新分發模式傳輸數據:
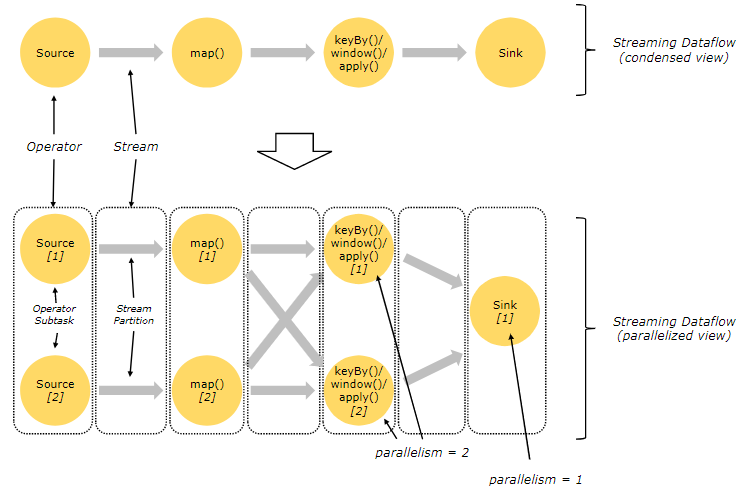
一對一模式(例如上圖 condensed view 中的 Source 和 map() 運算元之間)可以保留元素的分區和順序信息。這意味著 map() 運算元的輸入的數據以及其順序與 Source 運算元的輸出的數據和順序完全相同,即同一分區的數據只會進入到下游運算元的同一分區。
重新分發模式(例如上圖 parallelized view 中的 map() 和 keyBy/window 之間,以及 keyBy/window 和 Sink 之間)會更改數據所在的流分區。當你在程式中選擇使用:keyBy()(通過散列鍵重新分區)、broadcast()(廣播)或 rebalance()(隨機重新分發)會把數據發送到不同的目標子任務。如上圖所示的 keyBy/window 和 Sink 運算元之間數據的重新分發時,不同鍵(key)的聚合結果到達 Sink 的順序是不確定的。
綜上,順序保證中有兩大難點:kafka 多分區、flink 多並行度。
方案設計
用 flink 處理來自 kafka 的數據時,將為每一個 topic(schema topic、data topic)創建一個 consumer,對應轉換為一條流(schema stream、data stream),每一個流單獨處理,互不影響。但流內數據依然存在上述的 kafka 多分區、flink 多並行度導致的亂序問題。
單分區順序
解決亂序問題,首先想到的是排序,但是對於一個無界數據數據流無法進行排序,由此引入視窗的概念,將有界數據流切分為一個個有界的視窗,在視窗內便於執行排序操作。
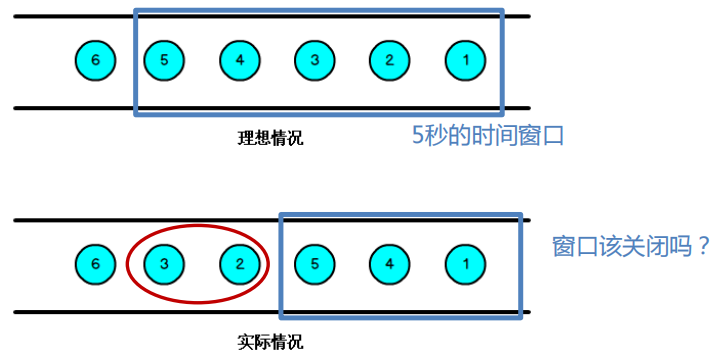
當一個視窗到了關閉時間,不應該立刻觸發視窗計算,而是等待一段時間,而是等遲到的數據來了再關閉視窗。數據流中的 Watermark 用於表示 timestamp 小於 Watermark 的數據都已經到達了,併在該視窗內按照事件時間處理該視窗內的數據即可保證數據處理順序。watermark 本質上是帶有特殊標記的時間戳,必須單調遞增,以確保任務的事件時間時鐘在向前推進,而不是在後退。
註意:watermark 的設置是開發者在實時性與準確性之間的權衡
-
如果 watermark 設置的延遲太大,收到結果的速度可能就會很慢,解決辦法是在水位線到達之前輸出一個近似結果(增量聚合)。
-
如果 watermark 到達得太小,則可能收到錯誤結果,不過 Flink 可以通過側輸出流、允許的延遲(allowed lateness)來解決這個問題。
流級順序
上面提到對於對於流處理並行任務來說順序保證中的兩大難點:kafka 多分區、流處理多並行度。flink 中給出了一個同時解決這兩個問題的解決方案,watermark 是一個流層面全局的概念,即一個流中維護一個全局的 watermark,保證流中多並行任務之間的順序,以下圖為例:
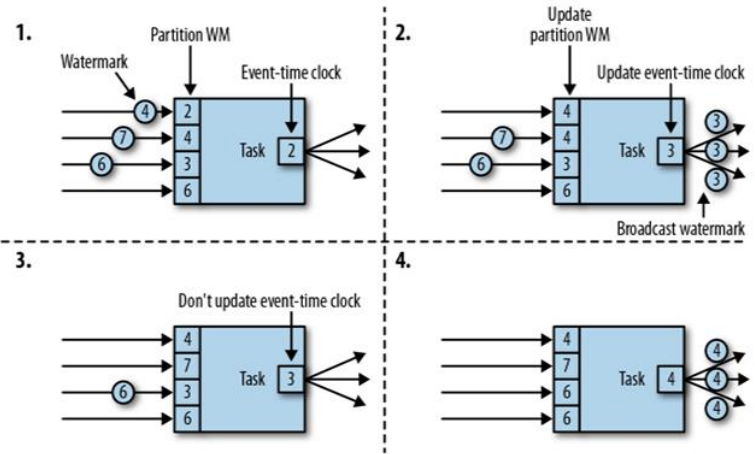
流中並行度為 4,partition WM 代表單個並行子任務的 watermark,Event-Time clock 代表該流中全局 watermark。
- 該時刻並行子任務的 watermark 分別為:2、4、3、6,全局 watermark 為並行子任務 watermark 的最小值 2;
- 第一個子任務中 watermark 變為 4,此時並行子任務的 watermark 分別為:4、4、3、6,最小值變為 3,因此全局 watermark 值為 3;
- 第二個子任務中 watermark 變為 7,此時並行子任務的 watermark 分別為:4、7、3、6,最小值仍為 3,全局 watermark 值不變;
- 第三個子任務中 watermark 變為 6,此時並行子任務的 watermark 分別為:4、7、6、6,最小值變為 4,全局 watermark 值變為 4;
由此可見全局 watermark 的值取決於並行子任務 watermark 的最小值,因此為減小各分區之間的 watermark 差值,建議 kafka 分區策略使用輪詢策略。
另外 flink 會根據 kafka 分區數取模 flink 並行度的方式(kafka partitions % flink parallelism)調整各子任務具體處理哪一分區的數據。有三種可能的情況:
-
kafka partitions = flink parallelism:這種情況是最理想的,因為每個消費者負責一個分區。如果消息在分區之間是平衡的,那麼工作將均勻分佈在 flink 並行任務之間;
-
kafka partitions < flink parallelism:一些 flink 並行任務處於空閑狀態,不會收到任何消息(flink 中提供了定期空閑狀態檢查機制);
-
kafka partitions > flink parallelism:在這種情況下,某些任務將處理多個分區,造成分區數據實際上以串列執行。
建議使用第一種 kafka 分區與 flink 並行度分配方式,將 flink 並行度設置為 kafka 分區相同。
任務級順序
上述流內亂序引入 window+watermark 之後即可解決,但是數據處理為達到任務級別的順序要求,不能只解決流內亂序,因為 schema stream 和 data stream 並非完全相互獨立,如下:
假設某表的原始結構為:CREATE TABLE tab1(uid bigint(20), name varchar(50))),下圖中 alter 代表:ALTER TABLE tab1 CHANGE COLUMN name uname varchar(50)。
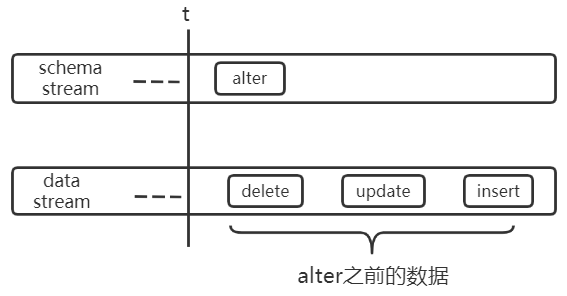
unknow column name
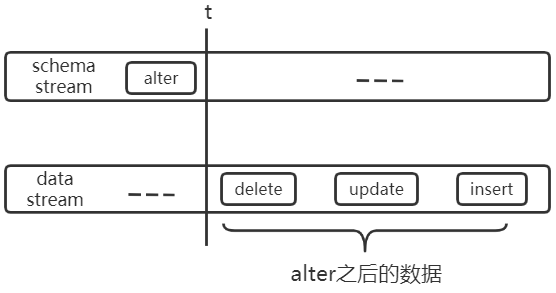
unknow column uname
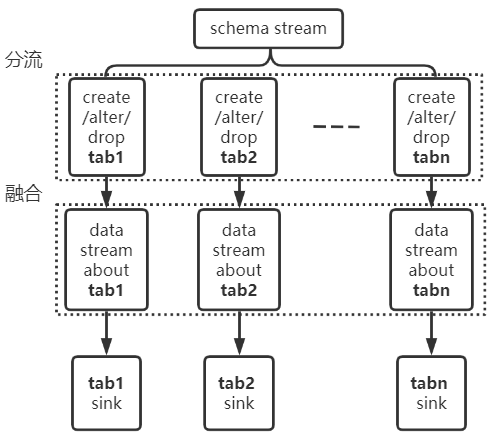
以上兩個實例說明瞭多流之間可能出現亂序的情況,為了保證任務級順序,需要在多流之間進行分流與融合的操作,如下:將關於 tab1 的 schema 流切分出來,將其與 tab1 的 data 流進行融合。保證其流內順序,即可解決上述問題。
關註公眾號 HEY DATA,添加作者微信,一起討論更多。


