
UniqueMergeTree 開發的業務背景 首先,我們看一下哪些場景需要用到實時更新。 我們總結了三類場景: 第一類是業務需要對它的交易類數據進行實時分析,需要把數據流同步到 ClickHouse 這類 OLAP 資料庫中。大家知道,業務數據諸如訂單數據天生是存在更新的,所以需要 OLAP 數據 ...
UniqueMergeTree 開發的業務背景
首先,我們看一下哪些場景需要用到實時更新。
我們總結了三類場景:
-
第一類是業務需要對它的交易類數據進行實時分析,需要把數據流同步到 ClickHouse 這類 OLAP 資料庫中。大家知道,業務數據諸如訂單數據天生是存在更新的,所以需要 OLAP 資料庫去支持實時更新。
-
第二個場景和第一類比較類似,業務希望把 TP 資料庫的表實時同步到 ClickHouse,然後藉助 ClickHouse 強大的分析能力進行實時分析,這就需要支持實時的更新和刪除。
-
最後一類場景的數據雖然不存在更新,但需要去重。大家知道在開發實時數據的時候,很難保證數據流里沒有重覆數據,因此通常需要存儲系統支持數據的冪等寫入。
我們可以總結一下這三類場景的共同點:
- 從數據的新鮮度看
這三個場景其實都不需要亞秒級的新鮮度,往往做到秒級或者分鐘級的數據新鮮度就可以了,因此可以採用 mini-batch 的實時同步方案。
- 從使用上看
這三類場景都可以通過提供基於唯一鍵的 upsert 功能來實現,不管是更新還是冪等處理的需求。
- 從讀寫要求上看
因為大家用 OLAP 資料庫最核心的訴求是希望查詢可以有一個非常低的延遲,所以對讀的性能要求是非常高的。對於寫,雖然也需要高吞吐,但更多關註 Scalability,即能否通過加資源來提高數據流的寫吞吐。
- 從高可用性上看
這三個場景都需要能支持多副本,來避免整個系統存在單點故障。
以上就是我們開發 UniqueMergeTree 的背景。
常見的列存儲實時更新方案
下麵介紹下在列存儲里支持實時更新的常見技術方案。
key-based merge on read
第一個方案叫 key-based merge on read,它的整個思想比較類似 LSMTree。對於寫入,數據先根據 key 排序,然後生成對應的列存文件。每個 Batch 寫入的文件對應一個版本號,版本號能用來表示數據的寫入順序。
同一批次的數據不包含重覆 key,但不同批次的數據包含重覆 key,這就需要在讀的時候去做合併,對 key 相同的數據返回去最新版本的值,所以叫 merge on read 方案。ClickHouse 的 ReplacingMergeTree 和 Doris 用的就是這種方案。
大家可以看到,它的寫路徑是非常簡單的,是一個很典型的寫優化方案。它的問題是讀性能比較差,有幾方面的原因。首先,key-based merge 通常是單線程的,比較難並行。其次 merge 過程需要非常多的記憶體比較和記憶體拷貝。最後這種方案對謂詞下推也會有一些限制。大家用過 ReplacingMergeTree 的話,應該對讀性能問題深有體會。
這個方案也有一些變種,比如說可以維護一些 index 來加速 merge 過程,不用每次 merge 都去做 key 的比較。
mark-delete + insert
mark-delete + insert 剛好反過來,是一個讀優化方案。在這個方案中,更新是通過先刪除再插入的方式實現的。
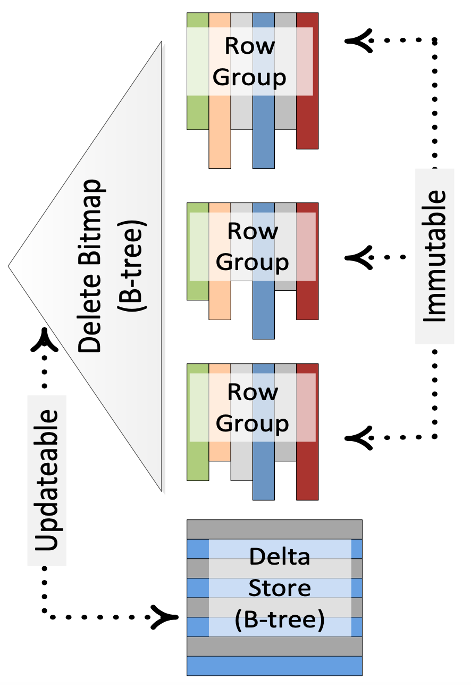
Ref “Enhancements to SQLServer Column Stores”
下麵以 SQLServer 的 Column Stores 為例介紹下這個方案。圖中,每個 RowGroup 對應一個不可變的列存文件,並用 Bitmap 來記錄每個 RowGroup 中被標記刪除的行號,即 DeleteBitmap。處理更新的時候,先查找 key 所屬的 RowGroup 以及它在 RowGroup 中行號,更新 RowGroup 的 DeleteBitmap,最後將更新後的數據寫入 Delta Store。查詢的時候,不同 RowGroup 的掃描可以完全並行,只需要基於行號過濾掉屬於 DeleteBitmap 的數據即可。
這個方案犧牲了寫入性能。一方面寫入時需要去定位 key 的具體位置,另一方面需要處理 write-write 衝突問題。
這個方案也有一些變種。比如說寫入時先不去查找更新 key 的位置,而是先將這些 key 記錄到一個 buffer 中,使用後臺任務將這些 key 轉成 DeleteBitmap。然後在查詢的時候通過 merge on read 的方式處理 buffer 中的增量 key。
由於 ClickHouse 的 ReplacingMergeTree 已經實現了方案一,所以我們希望 UniqueMergeTree 能實現讀優化的方案。
UniqueMergeTree 使用與實現
下麵介紹 UniqueMergeTree 的具體使用。我們先介紹一下它的特性。
UniqueMergeTree 表引擎特性
首先 UniqueMergeTree 支持通過 UNIQUE KEY 關鍵詞來指定這張表的唯一鍵,引擎會實現唯一約束。對於 UNIQUE 表的寫入,我們會採用 upsert 的語義,即如果寫入的是新 key,那就直接插入數據;如果寫入的 key 已經存在,那就更新對應的數據。
然後我們也支持,指定 UNIQUE KEY 的 value 來刪除數據,滿足實時行刪除的需求。然後和 ReplacingMergeTree 一樣,也支持指定一個版本欄位來解決回溯場景可能出現的低版本數據覆蓋高版本數據的問題。最後我們也支持數據在多副本的同步。
下麵是一個使用示例。首先我們建了一張 UniqueMergeTree 的表,表引擎的參數和 ReplacingMergeTree 是一樣的,不同點是可以通過 UNIQUE KEY 關鍵詞來指定這張表的唯一鍵,它可以是多個欄位,可以包含表達式等等。

下麵對這張表做寫入操作就會用到 upsert 的語義,比如說第 6 行寫了四條數據,但只包含 1 和 2 兩個 key,所以對於第 7 行的 select,每個 key 只會返回最高版本的數據。對於第 11 行的寫入,key 2 是一個已經存在的 key,所以會把 key 2 對應的 name 更新成 B3; key 3 是新 key,所以直接插入。最後對於行刪除操作,我們增加了一個 delete flag 的虛擬列,用戶可以通過這個虛擬列標記 Batch 中哪些是要刪除,哪些是要 upsert。
示例展示的是單 shard 的寫入,而生產環境通常包含多個 shard,。多個 shard 寫入的時候就涉及到了你要解決數據分片的問題,其實它的主要目的就是我們需要把相同的 key 的數據寫到同一個 shard 里,不然如果你的 key 可能存在多個 shard 的話,你的去重開銷就非常大。
分散式表寫入: 分片方案選擇
上面的示例展示了單 shard 的寫入,然而生產環境通常包含多個 shard,如何實現相同 key 的數據寫往同一個 shard 呢?這裡有兩種方案。
-
internal sharding: 即由引擎本身來實現數據的分片。具體來說,可以直接把數據寫到 ClickHouse 的分散式表,它會根據 sharding key 實現數據的分片和路由。Internal sharding 的優點是分片方式對用戶透明,不容易出錯;另外不同表的分片演算法是一致的,在做多表關聯的時候,可以利用數據的分片特征來優化查詢。這是 ByteHouse 雲數倉版使用的方式。
-
external sharding: 由用戶或者 SDK 負責數據的分片和路由,這是 ByteHouse 企業版使用的方式。Internal sharding 有個問題是,在實時寫入場景,每個微批本身就不大,如果再對它進行分片會產生更多的小文件,影響寫入吞吐。External sharding 在外部實現數據的攢批,每個微批只寫一個 shard,這樣 batch size 更大,整體的寫吞吐會更高。它的問題是需要由用戶端保證分片的正確性,比較容易出錯。External sharding 比較適合 kafka 導入等單一寫入場景。如果表有多個寫入通道,用戶需要保證多個通道採用一致的分片方式,成本更高。
單機版實現: UniqueMergeTree 讀寫鏈路
下麵介紹下 UniqueMergeTree 在單節點的讀寫鏈路。
-
寫鏈路: 首先要判斷寫入 key 所屬的 part 以及它在 part 中的行號,接著去更新對應 part 的 delete bitmap,將寫入 key 從原來的 part 里標記刪除掉,最後將新數據寫入新 part 里。為了實現上面的邏輯,我們為每個 part 新增了一個 key index,用於加速從唯一鍵值到行號的查找。另外每個 part 包含多個 delete file,每個 delete file 對應一個特定版本的 delete bitmap。
-
讀鏈路: 先獲取所有 part 的 delete bitmap 快照,然後讀取每個 part 的時候使用對應的 delete bitmap 過濾掉標記刪除的行。這樣就保證了整體的唯一性約束。
此外,還需要考慮併發場景的兩種衝突: write-write conflict 和 write-merge conflict。
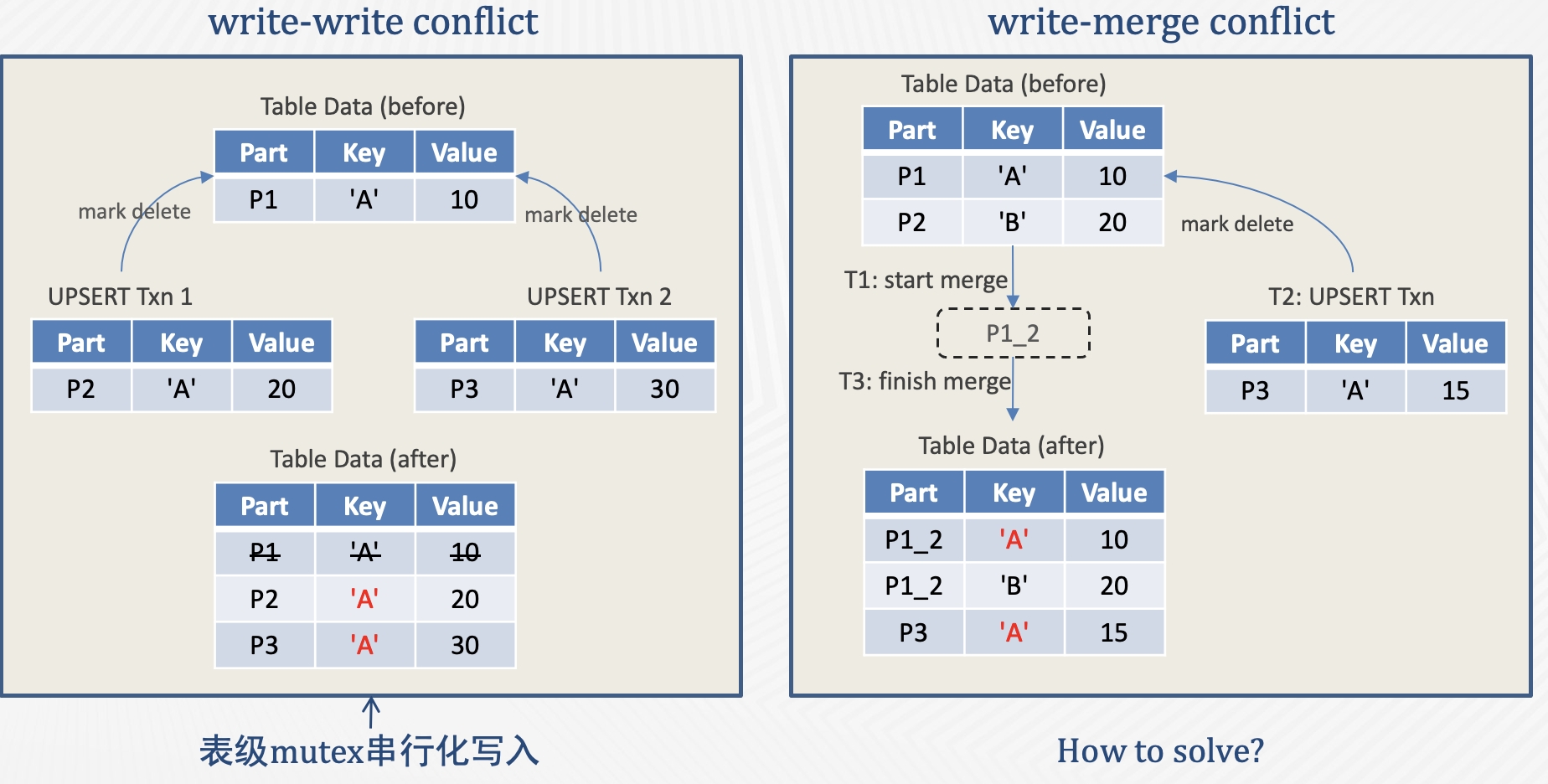
先介紹 write-write conflict。產生該衝突的原因是 write 使用了 upsert 語義,因此當兩個併發事務更新同一行的時候會產生衝突。比如左圖中的兩個併發事務同時更新 P1 的 Key A 行,如果不做併發控制,兩個事務可能都去標記刪除 P1 中的 Key A 行,然後寫出 P2 和 P3,最終 P2 和 P3 就同時包含了 Key A。
TP 資料庫一般通過鎖或者 OCC 的方式處理 write-write conflict,但在 AP 場景中用行鎖或者行級衝突檢測的代價是比較高的。考慮到 AP 場景數據都是批量寫入,我們採用了更簡單的表鎖來實現單表的寫入串列化。
再來看右圖的 write-merge conflict。多個 part 在後臺合併過程中,併發的前臺寫入事務可能會更新 part 的 delete bitmap。如果不做併發控制,就會發生寫入事務標記刪除的行在 part 合併後“複活”的現象。要解決這個問題,後臺合併任務需要感知到合併過程中,前臺寫入事務更新了哪些 key。
處理 Write-Merge Conflict
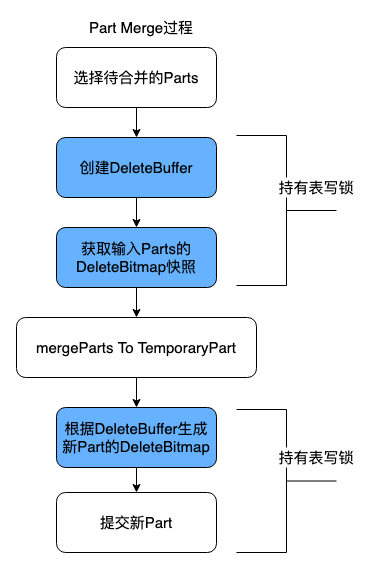
我們給每個 merge task 新增了一個 DeleteBuffer,用於緩存 merge 過程中前臺寫入任務刪除的 key。
Merge task 開始時,先獲取表鎖創建 DeleteBuffer,並獲取 input part 的 delete bitmap 快照。接著讀取 input part,過濾掉標記刪除的行,生成合併後的臨時 part。這個過程中,併發的寫入事務如果發現要更新 delete bitmap 的 part 正在被合併,就會將要刪除的 key 記錄到 merge task 的 DeleteBuffer。Merge task 在提交前會再次獲取表鎖,將 DeleteBuffer 中的 key 轉成新 part 的 delete bitmap。
那麼如何限制 DeleteBuffer 的記憶體使用呢?一種簡單有效的方式是,寫入事務如果發現 DeleteBuffer 的大小超過了閾值,就直接 abort 對應的 merge 任務,等待下次合併。因為 DeleteBuffer 比較大說明在合併過程中 input part 有很多增量的刪除,重試可以減小 merge 後的 part 大小。
性能評估
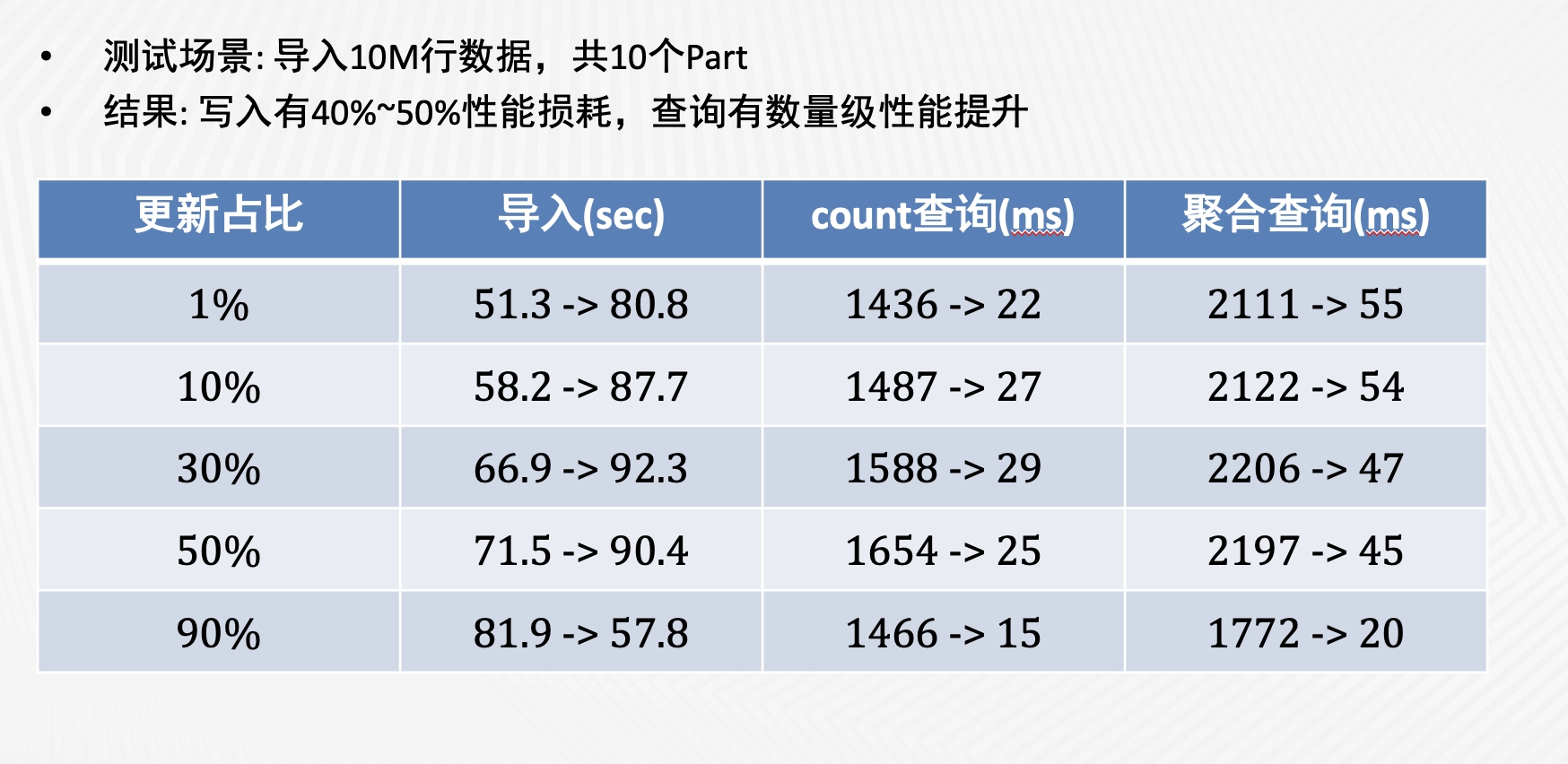
我們使用 YCSB 對 UniqueMergeTree 的寫入和查詢性能做了性能測試,結果如上圖。可以看到,與 ReplacingMergeTree 相比,UniqueMergeTree 的寫入性能雖然會有 40%到 50%的下降,但在查詢性能上取得了數量級的提升。我們進一步對比了 UniqueMergeTree 和普通 MergeTree 的查詢性能,發現兩者是非常接近的。查詢性能的提升主要歸功於以下幾點:
-
避免了單線程的 merge-on-read,流水線完全並行化
-
DeleteBitmap 的最新版本常駐記憶體
-
標記刪除的 Mark 可以直接跳過
-
Combine pre-where filter & delete filter,減少 IColumn::filter 次數
總結:經驗與後續規劃
我們在 2020 年初上線了 UniqueMergeTree,目前線上應用的表數量超過了 1000,還是非常受業務歡迎的。整個過程中,我認為做的比較對的決策有兩點:
-
在讀寫權衡方面,犧牲一部分寫性能來換取更高的讀性能。我們發現很多業務場景的痛點是查詢性能。雖然 UniqueMergeTree 的寫吞吐不如 MergeTree,但通過增加 shard 橫向擴展,已經能滿足大部分業務的需求。
-
設計上沒有對錶的數據量做太多限制。例如 KeyIndex,一種做法是假設 KeyIndex 可以完全存儲在記憶體中,但我們認為這會限制 UniqueMergeTree 的應用場景。因此雖然我們第一版實現的也是 in-meomry index,但後來比較順利地演進到了 disk-based index。
對於後續規劃,我們會重點嘗試兩個方向:
-
部分列更新:有些場景需要多個數據流更新同一張表的不同欄位,因此需要部分列更新的能力。
-
寫吞吐優化:寫吞吐會直接影響每個集群能接入的實時數據規模。我們在表鎖粒度和 KeyIndex 兩方面都看到了進一步優化的空間。
基於開源 ClickHouse 的分析型資料庫,支持用戶互動式分析 PB 級別數據,通過多種自研表引擎,靈活支持各類數據分析和應用。
歡迎關註位元組跳動數據平臺微信公眾號,回覆【1】進入官方交流群


