
案例標題:用python可視化分析,B站Top100排行榜數據。 分析流程: 一、數據讀取 二、數據概覽 三、數據清洗 四、可視化分析 ·相關性分析-散點圖(scatter) ·得分分佈-餅圖(pie) ·各指標分佈-箱形圖(boxplot) ·視頻作者分析-詞雲圖(wordcloud) ...
目錄
一、數據源
之前,我分享過一期爬蟲,用python爬取Top100排行榜:
最終數據結果,是這樣的:
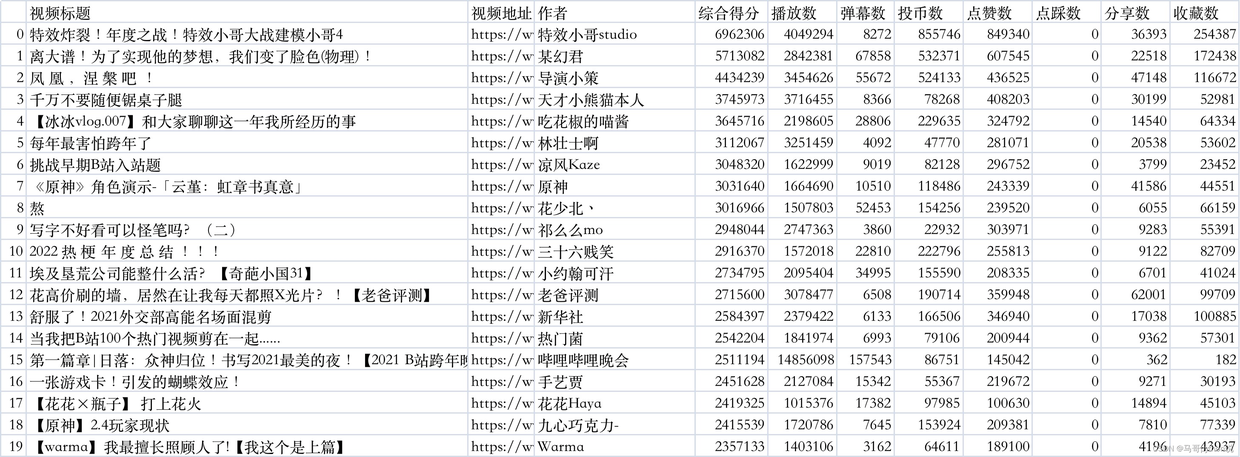
在此數據基礎上,做python可視化分析。
二、數據讀取
首先,讀取數據源:
# 讀取csv數據
df = pd.read_csv(csv)
三、數據概覽
用shape查看數據形狀:
# 查看數據形狀
df.shape
用head查看前n行:
# 查看前5行
df.head(5)
用info查看列信息:
# 查看列信息
df.info()
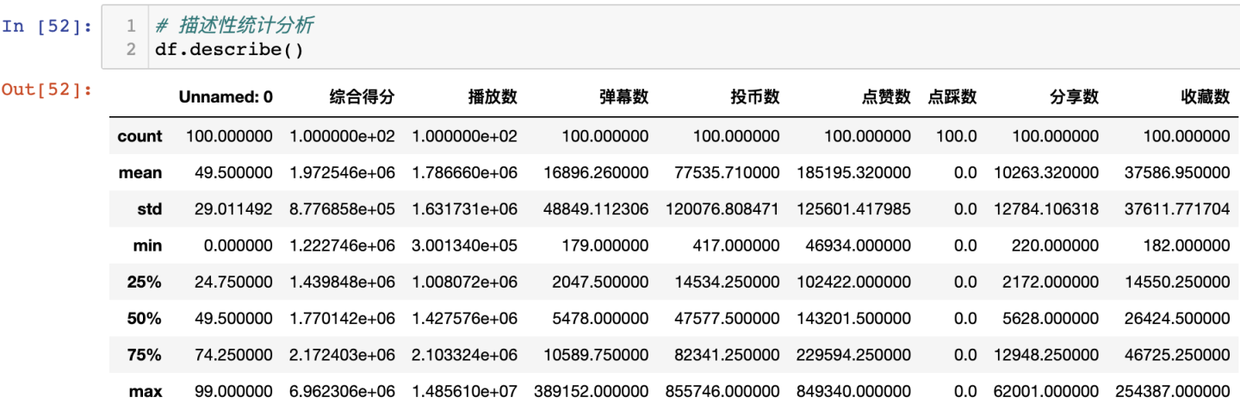
用describe查看統計性分析:
# 描述性統計分析
df.describe()
四、數據清洗
查看是否存在空值:
# 查看空值
df.isna().any()
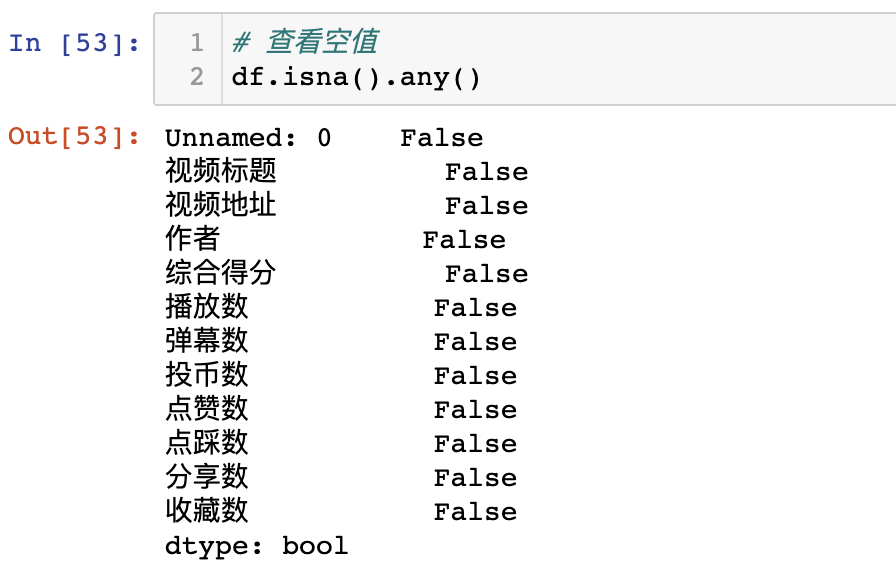
每列都是False,沒有空值。
查看是否存在重覆值:
#查看重覆值
df.duplicated().any()

False代表沒有重覆值。
上面我們看到,點踩數都是0,沒有分析意義,所以,用drop刪除此列:
# 刪除沒用的列
df.drop('點踩數', axis=1, inplace=True)
刪除之後,查看刪除結果:

沒有點踩數了。
五、可視化分析
5.1 相關性分析(Correlation)
數據中,有播放數、彈幕數、投幣數、點贊數、分享數、收藏數等眾多數據指標。
我想分析出,這些指標中,誰和綜合得分的關係最大,決定性最高。
直接採用pandas自帶的corr函數,得出相關性(spearman相關)矩陣:
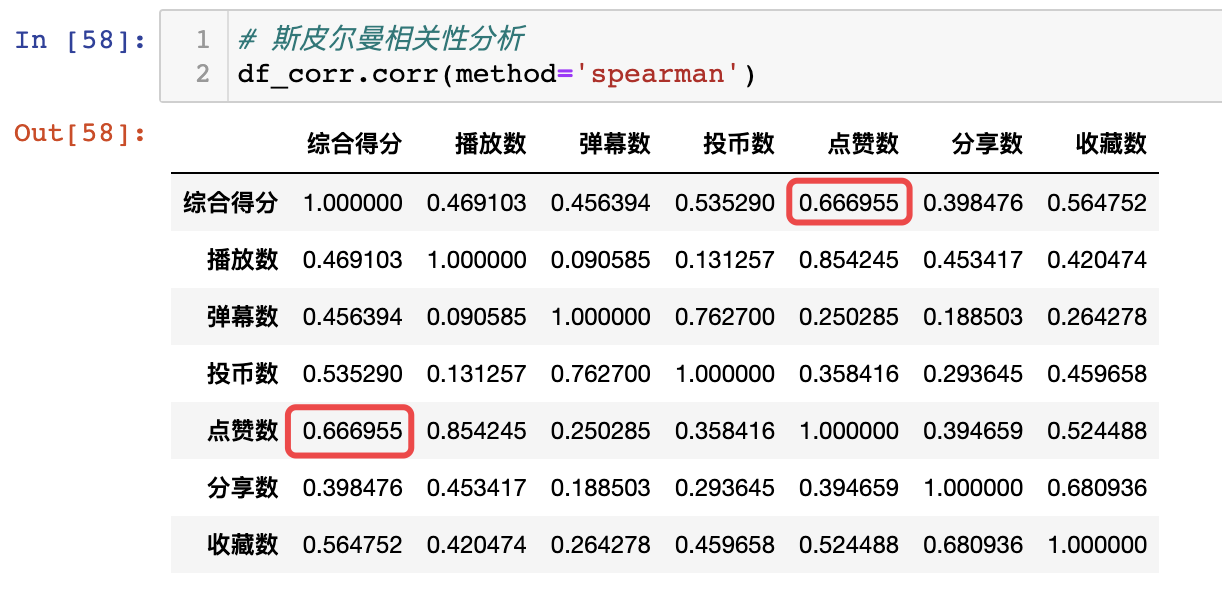
可以看出,點贊數和綜合得分的相關性最高,達到了0.66。
根據此分析結論,進一步畫出點贊數和綜合得分的分佈散點圖,驗證此結論的正確性。
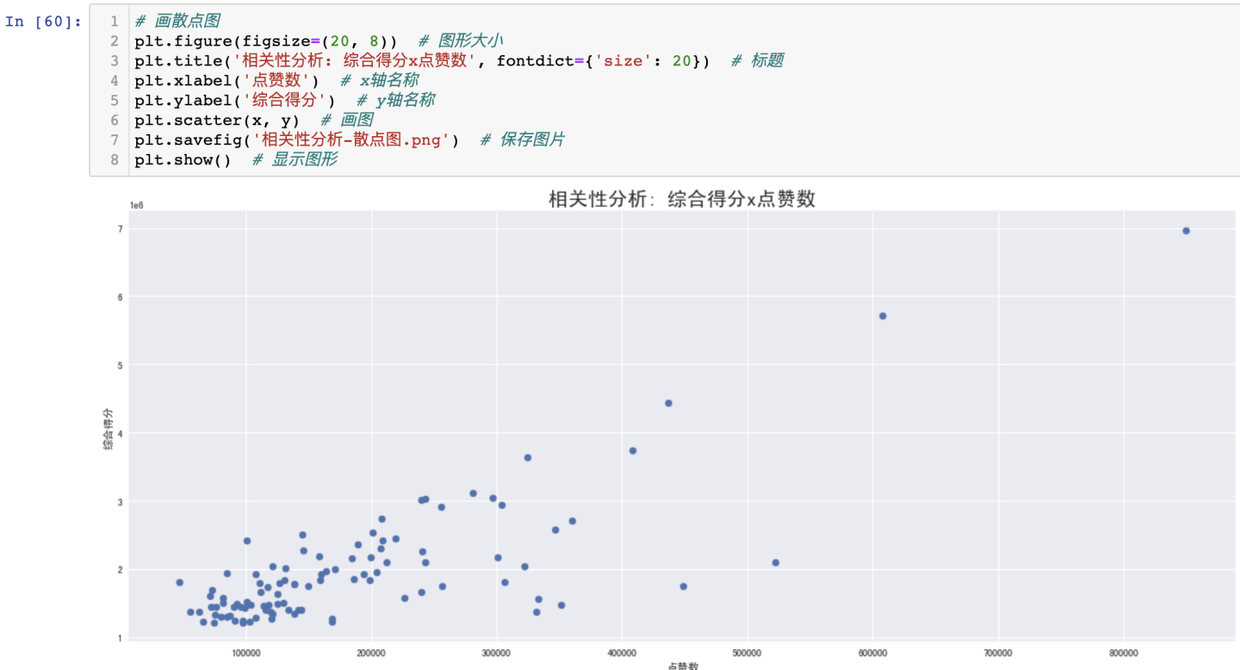
得出結論:隨著點贊數增多,綜合得分呈明顯上升趨勢,進一步得出,二者存在正相關的關係。
5.2 餅圖(Pie)
綜合得分劃分分佈區間,繪製出分佈餅圖。
首先,劃分數據區間:
# 設置分段
bins = [1000000, 1500000,2000000, 2500000, 3000000, 10000000]
# 設置標簽
labels = [
'100w-150w',
'150w-200w',
'200w-250w',
'250w-300w',
'300w-1000w'
]
# 按分段離散化數據
segments = pd.cut(score_list, bins, labels=labels) # 按分段切割數據
counts = pd.value_counts(segments, sort=False).values.tolist() # 統計個數
至於區間怎麼劃分,可以按照對數據的大致理解,和最終可視化呈現的效果,微調劃分區間。
繪製餅圖:

得出結論:綜合得分在100w至150w這個區間的視頻最多,有36個視頻(占比36%)
5.3 箱形圖(Boxplot)
箱形圖,是一種分析數據分佈、離散情況的數據分析方法。
首先,我嘗試了把這幾個數據指標,繪製在同一張圖裡:
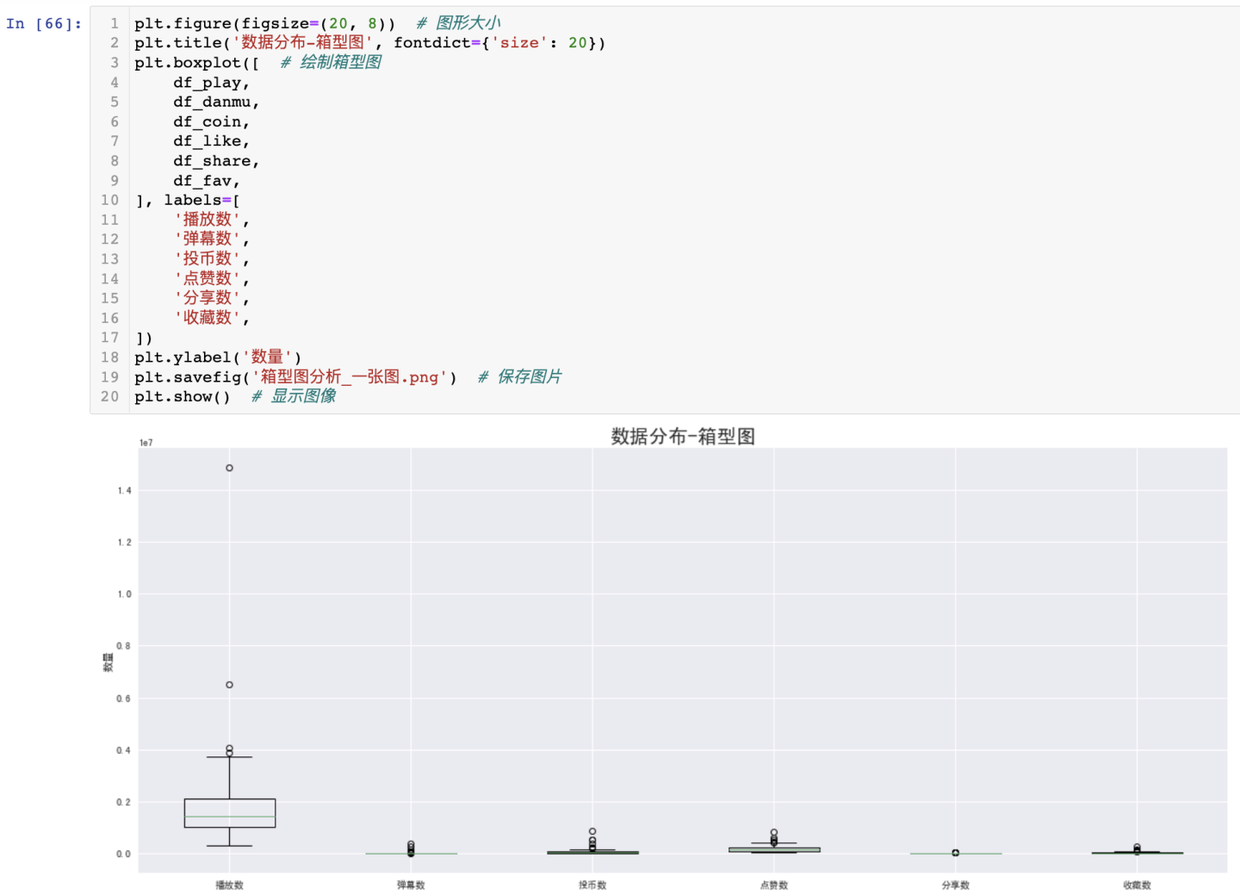
可以發現,由於播放數遠遠大於其他數據指標,不在一個數量級,導致其他數據指標的box都擠到一塊了,可視化效果很差,所以,我打算把每個box畫到一個圖裡,避免這種情況的發生。
以下代碼,含知識點(subplot(n_row, n_col, order) n_row代表幾行,n_col代表幾列,order代表第幾個)

得出結論:每個數據指標都存在極值的情況(最大值距離box很遠),數據比較離散,方差較大。
5.4 詞雲圖(wordcloud)
針對視頻作者,畫出詞雲圖。
代碼中各個細節設置項,已添加對應註釋,不再贅述。
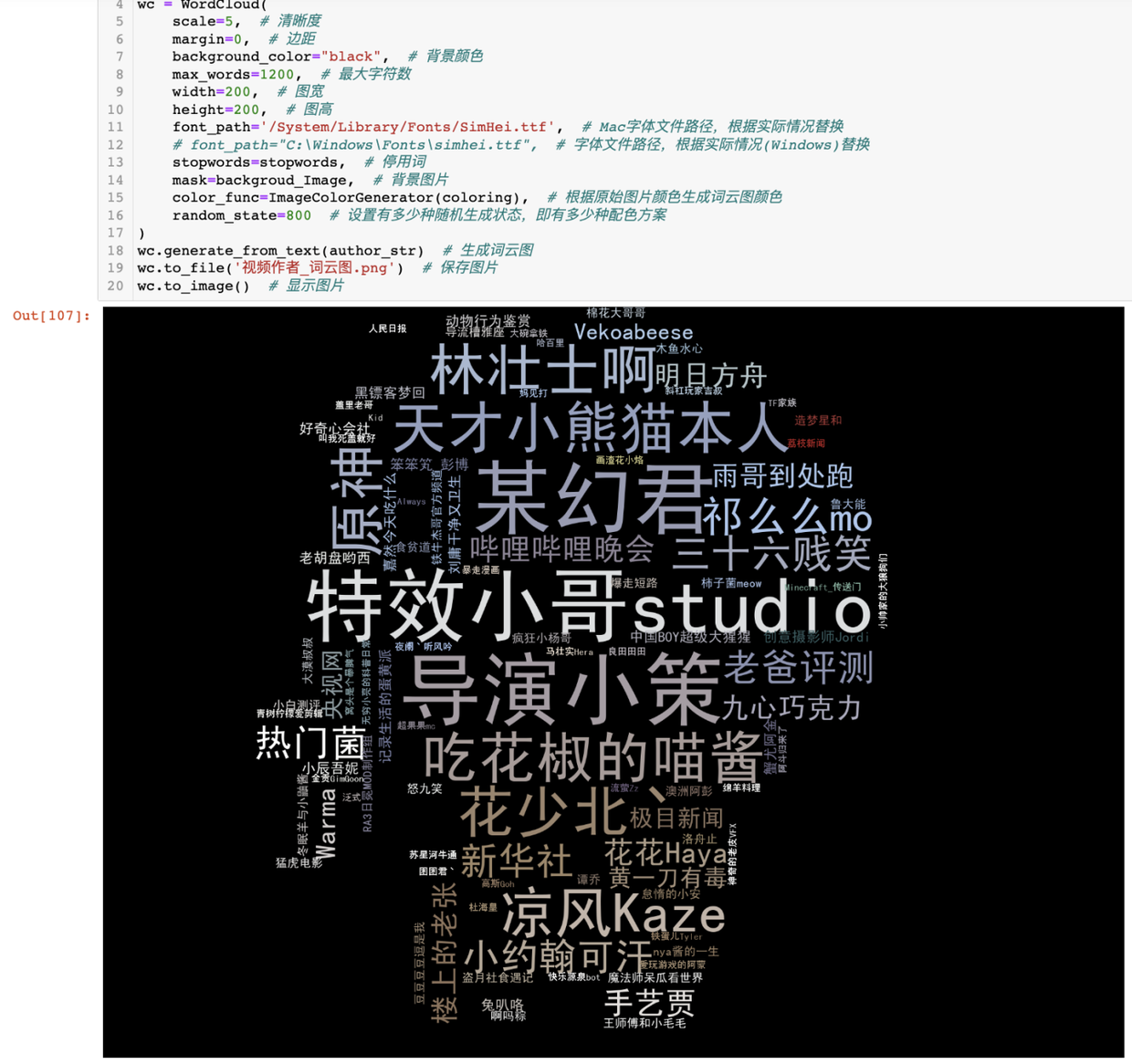
和原始背景圖對比:

這個背景圖,是我找的一個動漫小人的圖片,對比詞雲圖,你會發現:
-
詞雲圖和背景圖的形狀,大體一致(mask參數的作用)
-
詞雲圖和背景圖的顏色分佈,大體一致(color_func參數的作用)
至此,全部分析結束。
六、同步講解視頻
此案例的講解視頻:
https://www.zhihu.com/zvideo/1513851213354893312
by 馬哥python說


