
一、Apache Pig概述 Apache PIG提供一套高級語言平臺,用於對結構化與非結構化數據集進行操作與分析。這種語言被稱為Pig Latin,其屬於一種腳本形式,可直接立足於PIG shell執行或者通過Pig Server進行觸發。用戶所創建的腳本會在初始階段由Pig Latin處理引擎進 ...
目錄
- 如果是MapReduce模式需要提前準備好文件傳到HDFS上,上面已經演示過了,這裡就不重覆了,很簡單
一、Apache Pig概述
Apache PIG提供一套高級語言平臺,用於對結構化與非結構化數據集進行操作與分析。這種語言被稱為
Pig Latin,其屬於一種腳本形式,可直接立足於PIG shell執行或者通過Pig Server進行觸發。用戶所創建的腳本會在初始階段由Pig Latin處理引擎進行語義有效性解析,而後被轉換為包含整體執行初始邏輯的定向非迴圈圖(簡稱DAG)。
官網:https://pig.apache.org/
官方文檔:https://pig.apache.org/docs/r0.17.0/
Apache Pig具有以下特點:
-
豐富的運算符集 - 它提供了許多運算符來執行諸如join,sort,filer等操作。
-
易於編程 - Pig Latin與SQL類似,如果你善於使用SQL,則很容易編寫Pig腳本。
-
優化機會 - Apache Pig中的任務自動優化其執行,因此程式員只需要關註語言的語義。
-
可擴展性 - 使用現有的操作符,用戶可以開發自己的功能來讀取、處理和寫入數據。
-
用戶定義函數 - Pig提供了在其他編程語言(如Java)中創建用戶定義函數的功能,並且可以調用或嵌入到Pig腳本中。
-
處理各種數據 - Apache Pig分析各種數據,無論是結構化還是非結構化,它將結果存儲在HDFS中。
Pig包括兩部分:
- 用於描述數據流的語言,稱為
Pig Latin,Pig Latin是類似SQL的語言。 - 用於運行PigLatin程式的 執行環境 。一個是 本地 的單JVM執行環境,一個就是在 hadoop集群上的分散式執行環境。
二、Apache Pig架構
1)架構圖
要執行特定任務使用Pig的程式員,程式員需要使用Pig Latin語言編寫Pig腳本,並使用任何執行機制(Grunt Shell,UDF,Embedded)執行它們。執行後,這些腳本將經過Pig Framework應用的一系列轉換,以產生所需的輸出。
在內部,Apache Pig將這些腳本轉換為一系列MapReduce作業,因此它使程式員的工作變得輕鬆。Apache Pig的體繫結構如下所示:
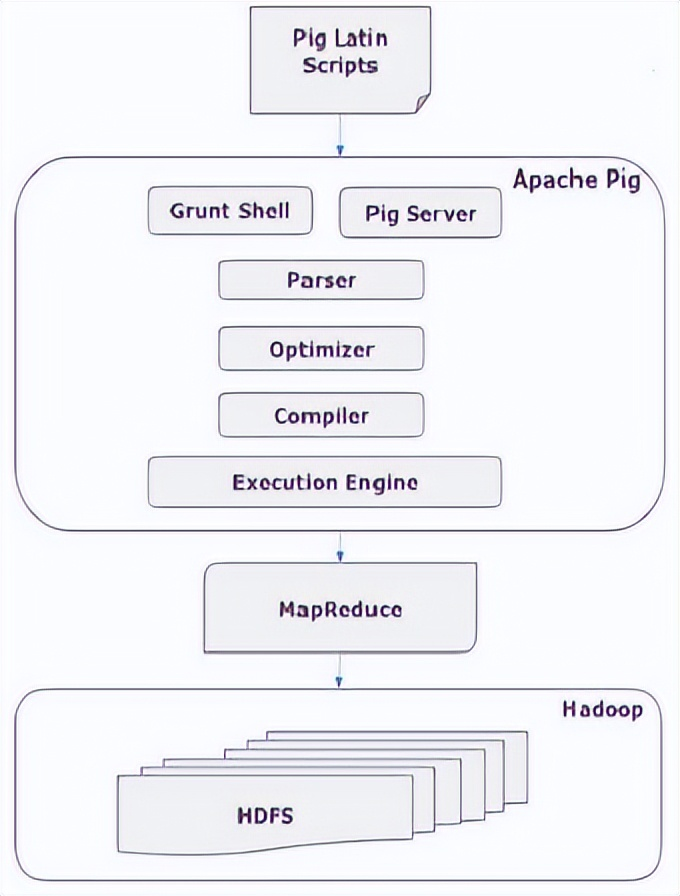
2)Apache Pig組件
1、Parser(解析器)
最初,Pig腳本由解析器處理,它檢查腳本的語法,類型檢查和其他雜項檢查。解析器的輸出將是DAG(有向無環圖),它表示Pig Latin語句和邏輯運算符。在DAG中,腳本的邏輯運算符表示為節點,數據流表示為邊。
2、Optimizer(優化器)
邏輯計劃(DAG)傳遞到邏輯優化器,邏輯優化器執行邏輯優化,例如投影和下推。
3、Compiler(編譯器)
編譯器將優化的邏輯計劃編譯為一系列MapReduce作業。
4、Execution engine(執行引擎)
最後,MapReduce作業以排序順序提交到Hadoop。這些MapReduce作業在Hadoop上執行,產生所需的結果。
三、Apache Pig安裝
如果使用的不是本地模式,就是必須安裝好Haood基礎環境,可以參考我之前的文章:
大數據Hadoop原理介紹+安裝+實戰操作(HDFS+YARN+MapReduce)
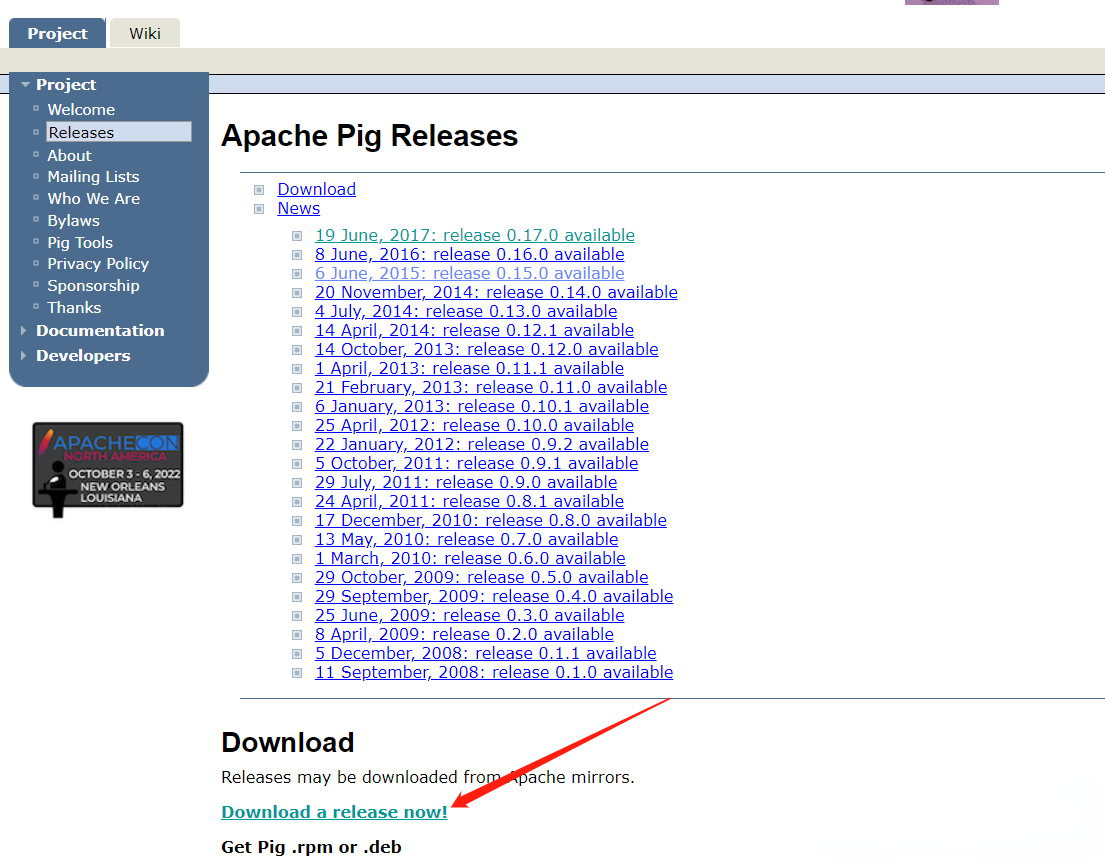
1)下載Apache Pig
下載地址:https://pig.apache.org/releases.html
下載最新版本:
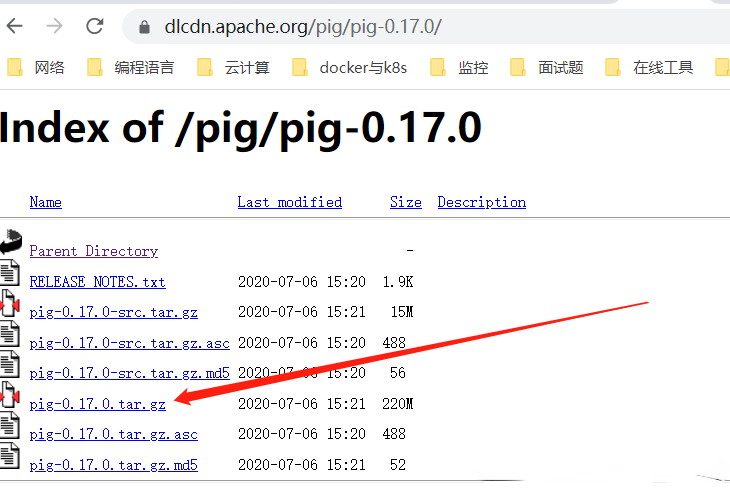
$ mkdir -p /opt/bigdata/hadoop/software/pig ; cd /opt/bigdata/hadoop/software/pig
$ wget https://dlcdn.apache.org/pig/pig-0.17.0/pig-0.17.0.tar.gz
$ tar -xf pig-0.17.0.tar.gz -C /opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server/pig-0.17.0
2)配置環境變數
$ vi /etc/profile
export PIG_HOME=/opt/bigdata/hadoop/server/pig-0.17.0
export PATH=$PATH:${PIG_HOME}/bin
export PIG_CONF_DIR=${PIG_HOME}/conf
# 將 PIG_CLASSPATH 環境變數設置為hadoop集群配置目錄的位置(包含 core-site.xml、hdfs-site.xml 和 mapred-site.xml 文件的目錄):
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
# 如果您使用的是 Tez,您還需要將 Tez 配置目錄(包含 tez-site.xml 的目錄),我這裡不加:
# export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop:/tez/conf
# 如果您使用的是 Spark,您還需要指定 SPARK_HOME 並指定 SPARK_JAR,這是您上傳 $SPARK_HOME/lib/spark-assembly*.jar 的 hdfs 位置:
# export SPARK_HOME=/mysparkhome/; export SPARK_JAR=hdfs://example.com:8020/spark-assembly*.jar
載入生效
$ source /etc/profile
$ pig -version
3)修改配置
$ cd $PIG_CONF_DIR
# 在Pig的 conf 文件夾中,我們有一個名為 pig.properties 的文件。在pig.properties文件中,可以設置如下所示的各種參數。
# 查看配置幫助
$ pig -h properties
四、Apache Pig執行模式
1)本地模式
要在本地模式下運行 Pig,您需要訪問單台機器;所有文件都使用本地主機和文件系統安裝和運行。使用 -x 標誌(
pig -x local)指定本地模式。
2)Tez 本地模式
在 Tez 本地模式下運行 Pig。它類似於本地模式,除了內部 Pig 將調用 Tez 運行時引擎。使用 -x 標誌 (
pig -x tez_local) 指定 Tez 本地模式。
【溫馨提示】 Tez是基於Hadoop YARN之上的DAG(有向⽆環圖,Directed Acyclic Graph)計算引擎。核⼼思想是將Map和Reduce兩個操作進⼀步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output
等。
3)Spark 本地模式
在 spark 本地模式下運行 Pig。它類似於本地模式,除了內部 Pig 將調用 spark 運行時引擎。使用 -x 標誌 (
pig -x spark_local) 指定 Spark 本地模式。
上面三個模式是本地模式,下麵三個模式是基於Hadoop集群,Hadoop環境部署可以參考我之前的文章:大數據Hadoop原理介紹+安裝+實戰操作(HDFS+YARN+MapReduce)
4)MapReduce模式(預設模式)
要在 MapReduce 模式下運行 Pig,依賴Hadoop集群。Mapreduce 模式是預設模式;您可以但不需要使用 -x 標誌(
pig 或者 pig -x mapreduce)指定它。
5)Tez 模式
要在 Tez 模式下運行 Pig,依賴Hadoop集群。使用 -x 標誌 (
-x tez) 指定 Tez 模式。
6)Spark 模式
要在 Spark 模式下運行 Pig,依賴Hadoop集群。使用 -x 標誌 (-x spark) 指定 Spark 模式。在 Spark 執行模式下,需要將
env::SPARK_MASTER設置為適當的值(local - local 模式,yarn-client - yarn-client 模式,mesos://host:port - mesos 上的 spark 或 spark://host :port - spark 集群。在 Spark 上運行的 Pig 腳本可以利用動態分配功能。只需啟用spark.dynamicAllocation.enabled即可啟用該功能。關於spark,可以參考我之前的文章:大數據Hadoop之——計算引擎Spark
五、Apache Pig執行機制
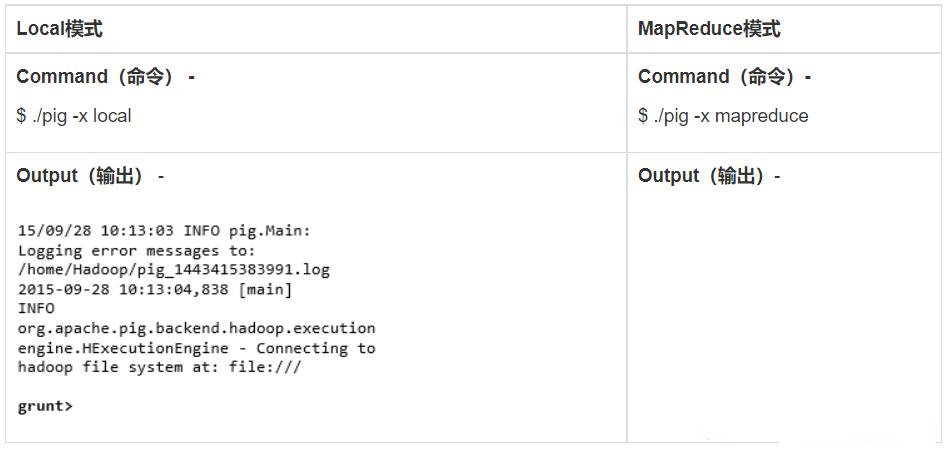
1)交互模式 (Grunt shell)
您可以使用Grunt shell以交互模式運行Apache Pig。在這個shell中,您可以輸入Pig Latin語句並獲取輸出(使用Dump操作符)。
調用Grunt Shell
您可以使用 -x 選項以所需的模式(local / MapReduce)調用Grunt shell,如下所示。
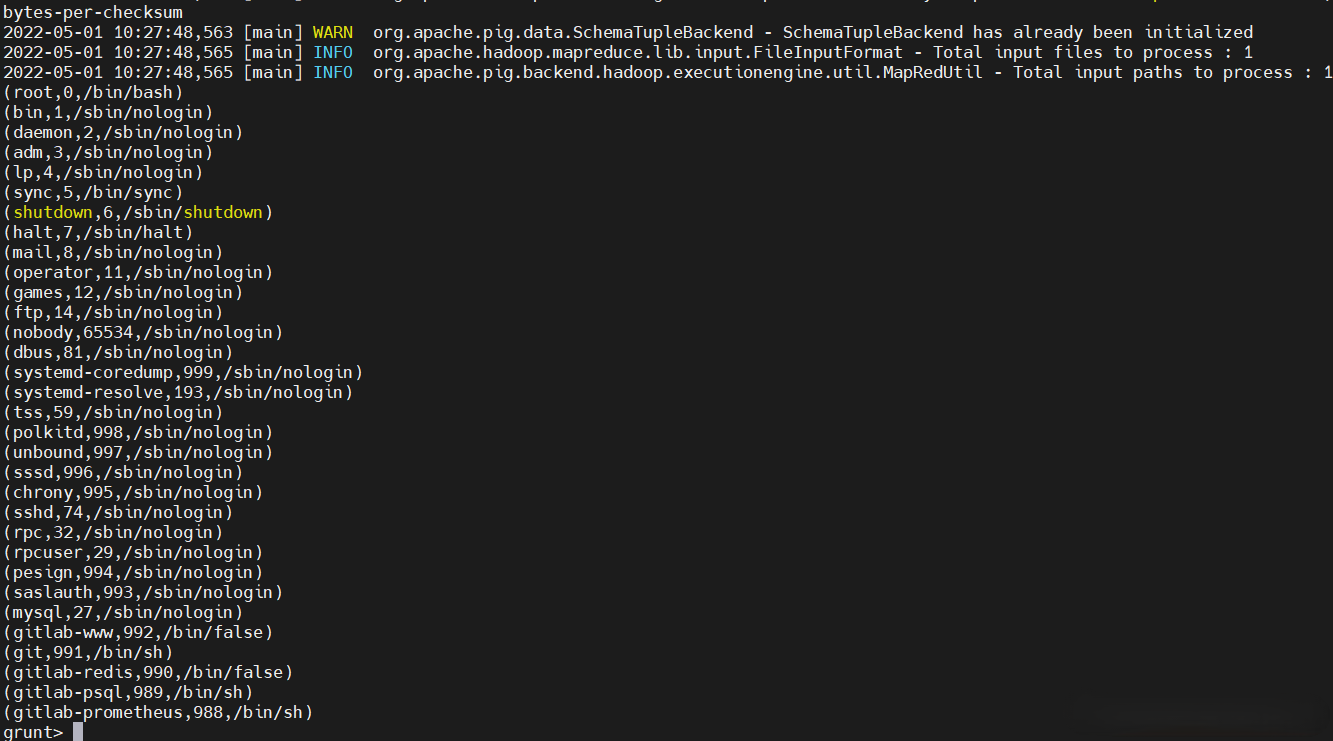
【local模式示例】示例一
# 執行完的文件會被刪掉,也就是/tmp/passwd執行完會刪除
$ cp /etc/passwd /tmp/passwd
$ pig -x local
# 分隔字元串
A = load 'passwd' using PigStorage(':');
# 遍歷
B = foreach A generate $0,$2,$6 as id;
# 輸出屏幕
dump B;
# 輸出到本地文件
store B into 'passwd.out';
【local模式示例】示例二
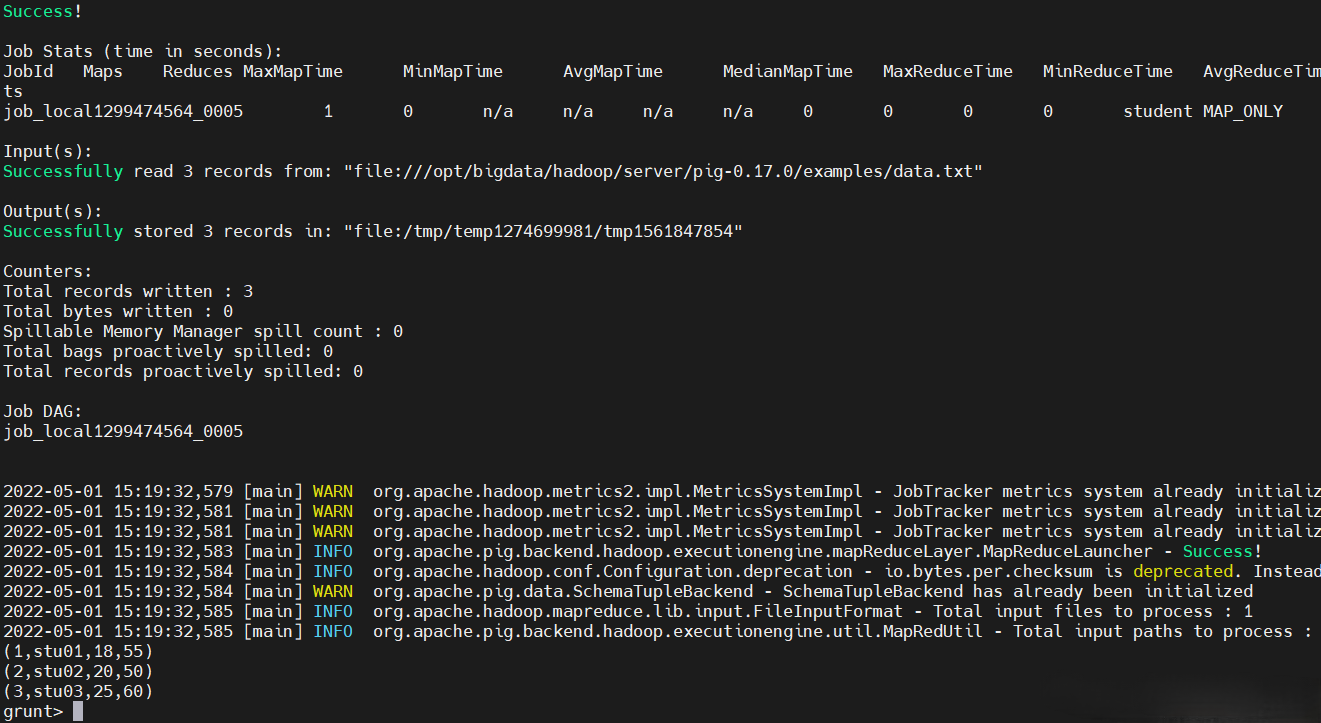
先準備好數據
$ vi data.txt
001,stu01,18,55
002,stu02,20,50
003,stu03,25,60
運行pig
$ pig -x local
# Tuple(元祖)數據格式
student = LOAD './data.txt' USING PigStorage(',') as (id:int,name:chararray,age:int,height:int);
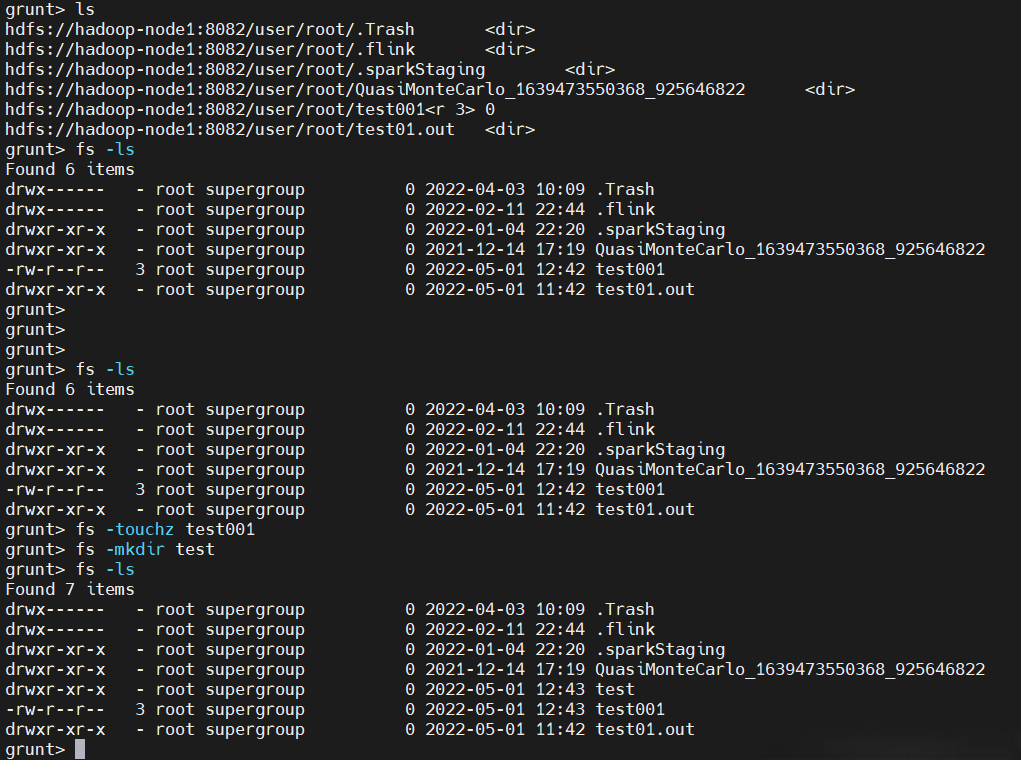
【MapReduce模式示例】
$ pig
ls
fs -ls
fs -touchz test001
fs -mkdir test
help
2)批處理模式 (腳本)
您可以在批處理模式下運行Apache Pig,方法是將Pig Latin腳本以 .pig 擴展名寫入單個文件。
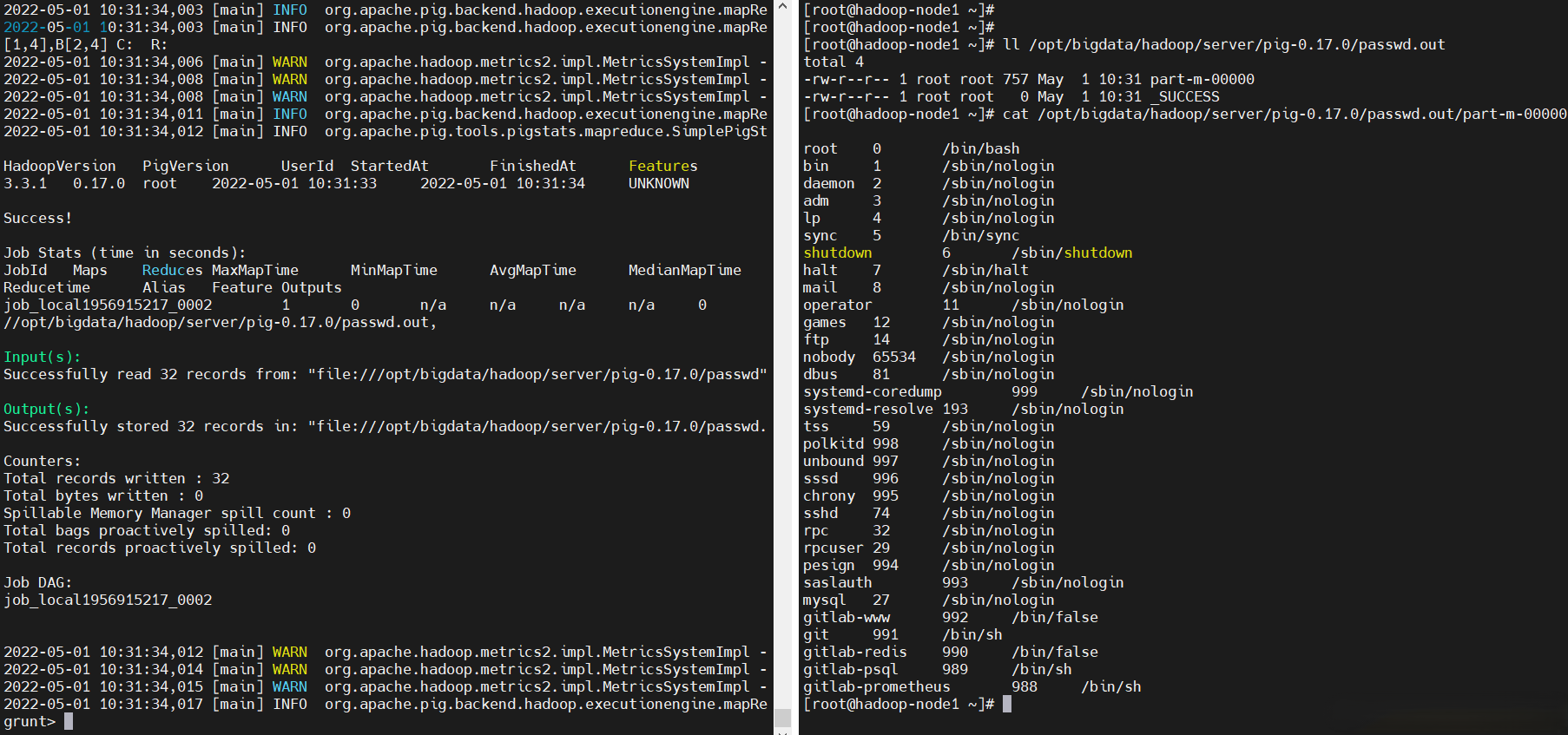
pig腳本
$ cp /etc/passwd /tmp/passwd
$ vi test01.pig
### pig腳本註釋有以下兩種:
# 對於多行註釋,請使用 /* ...。*/
# 對於單行註釋,使用 --
A = load '/tmp/passwd' using PigStorage(':'); -- load the passwd file
B = foreach A generate $0,$2,$6 as p; -- extract the user IDs
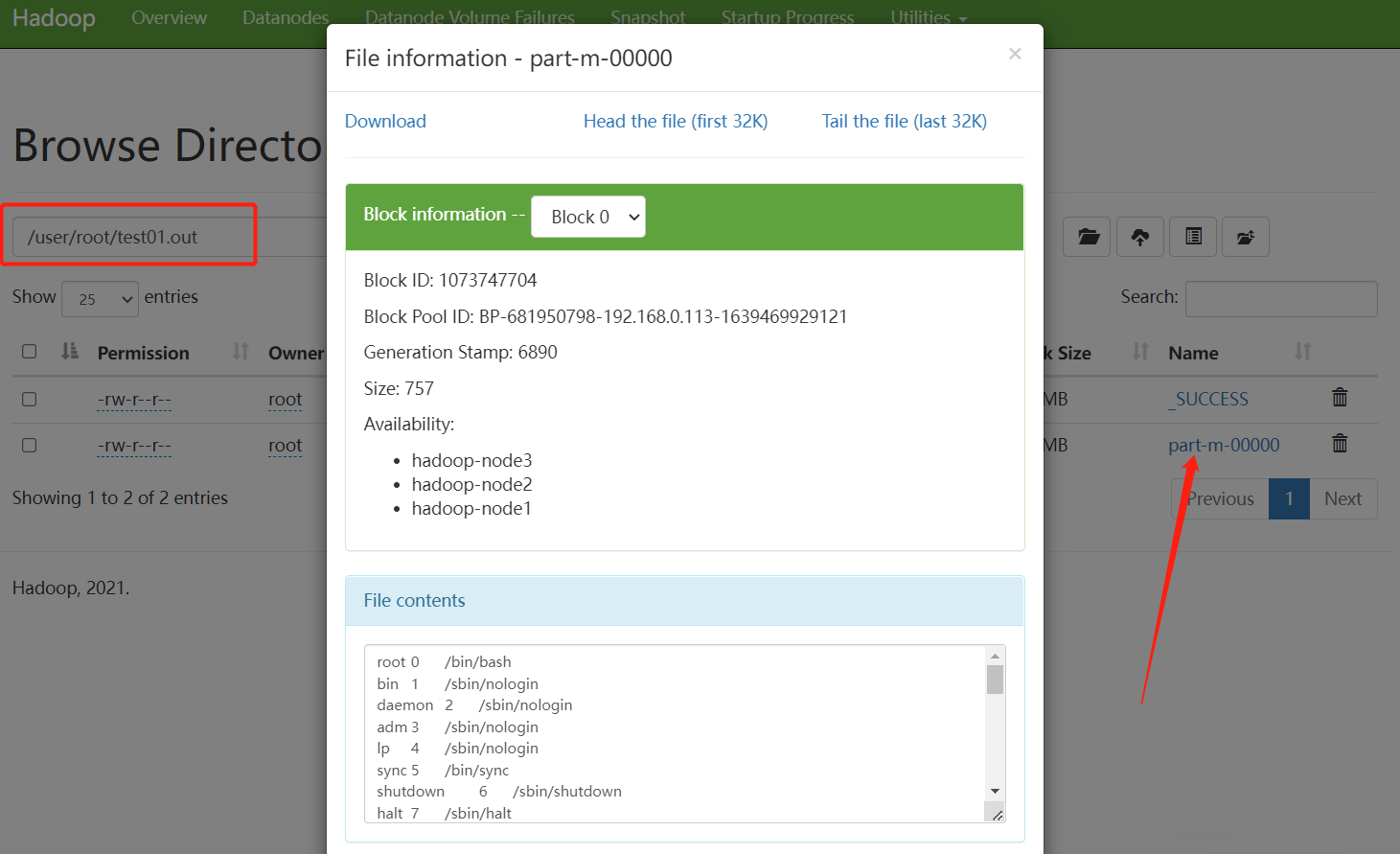
store B into 'test01.out'; -- write the results to a file name id.out
執行
# 以各種模式執行
$ pig -x local test01.pig
$ pig -x tez_local test01.pig
$ pig -x spark_local test01.pig
$ pig -x spark test01.pig
$ pig -x tez test01.pig
# MapReduce模式,這裡演示一下這個模式,這個模式會提交yarn mr任務
# 先啟動hadoop和historyserver服務
$ start-all.sh
$ mr-jobhistory-daemon.sh start historyserver
# 使用這個模式,文件就是HDFS上的
$ hadoop fs -put /tmp/passwd /tmp/
$ pig test01.pig
$ pig -x mapreduce test01.pig
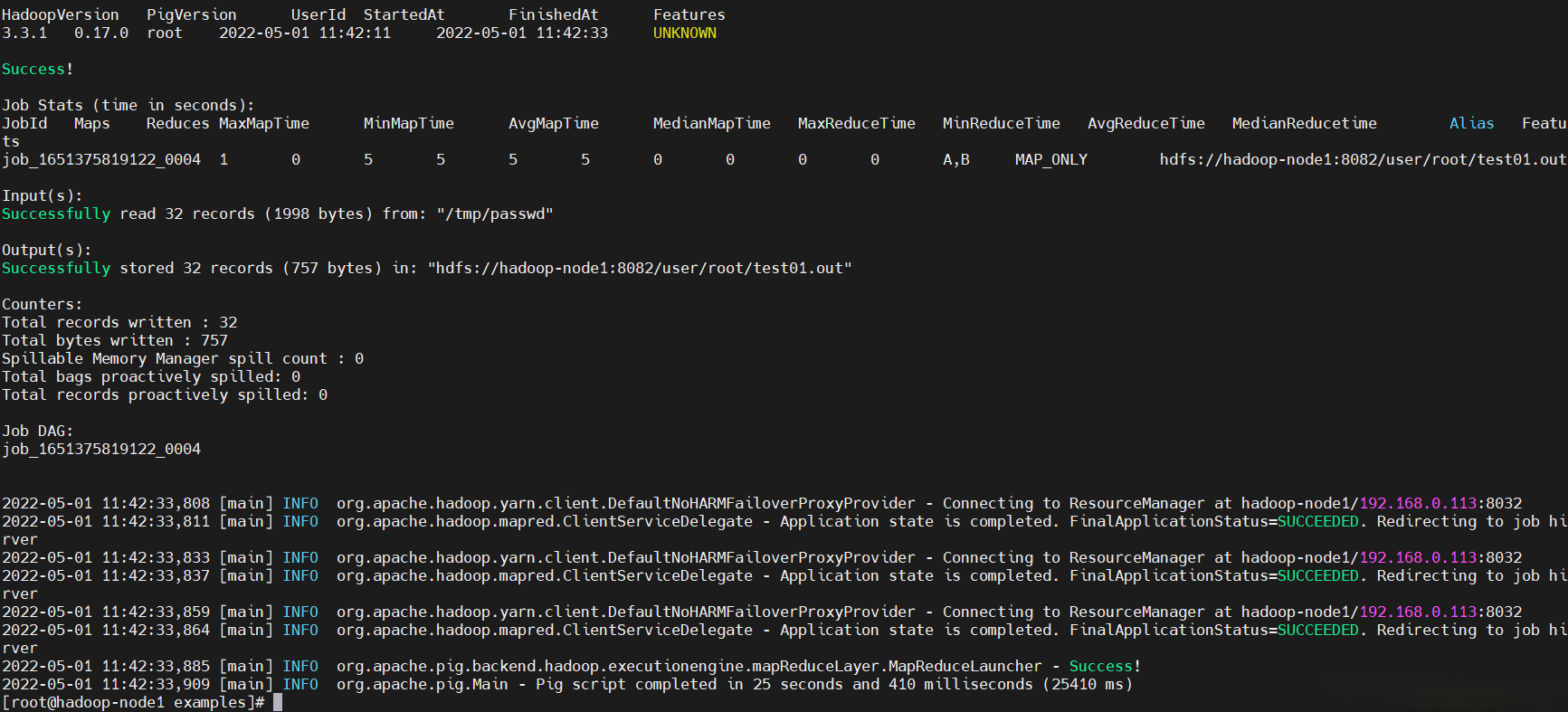
yarn任務
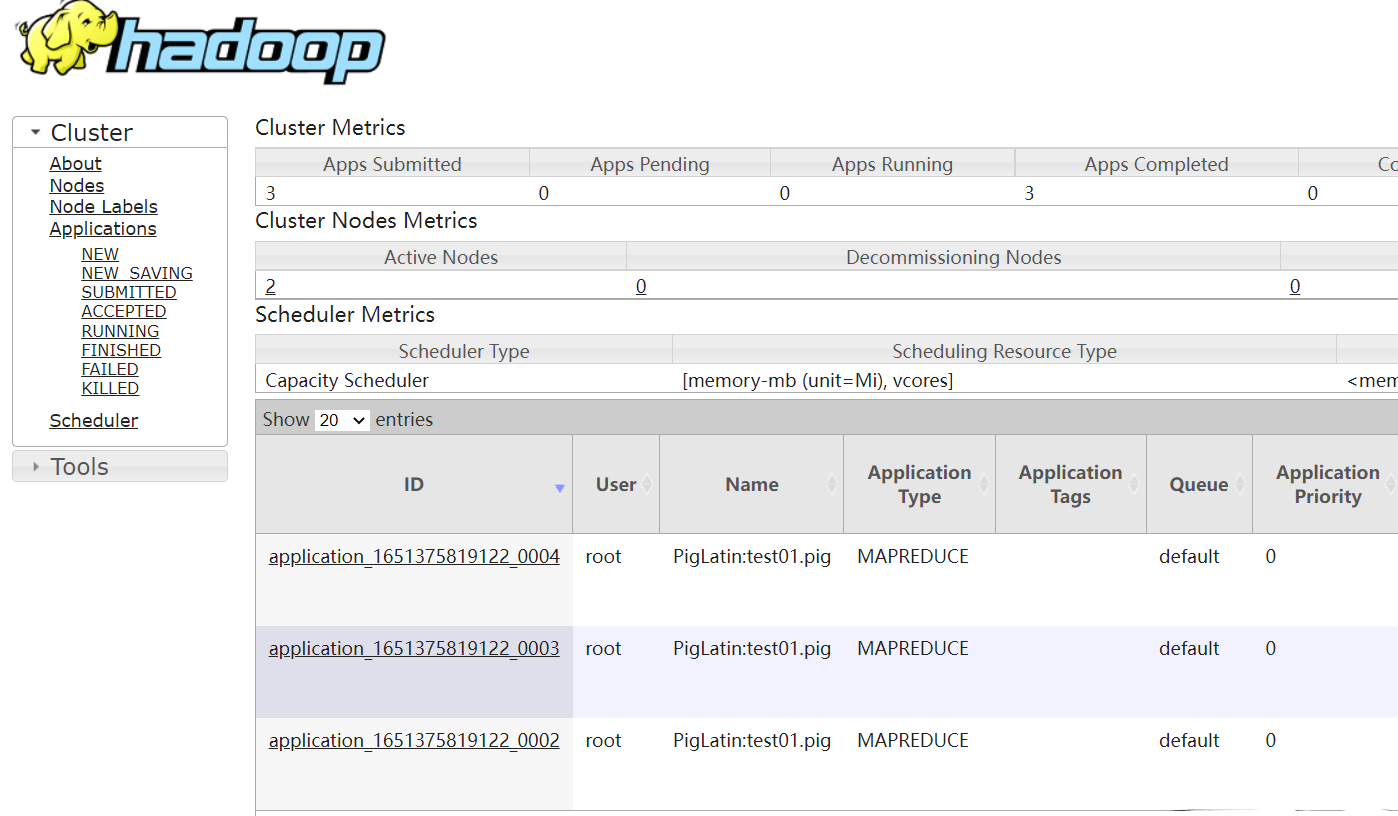
HDFS查看輸出結果
3)嵌入式模式(UDF)
Apache Pig允許在Java等編程語言中定義我們自己的函數(UDF用戶定義函數),併在我們的腳本中使用它們。
六、Pig Latin基礎知識
Pig Latin是用於使用Apache Pig在Hadoop中分析數據的語言。
1)數據模型
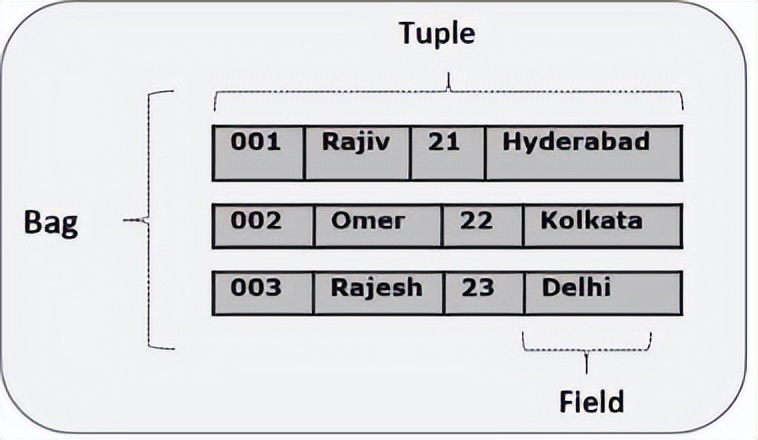
Pig Latin的數據模型是完全嵌套的,它允許複雜的非原子數據類型,例如
map和tuple。下麵給出了Pig Latin數據模型的圖形表示。
- Atom(原子)
Pig Latin中的任何單個值,無論其數據類型,都稱為 Atom 。它存儲為字元串,可以用作字元串和數字。int,long,float,double,chararray和bytearray是Pig的原子值。一條數據或一個簡單的原子值被稱為欄位。例:“raja“或“30"
- Tuple(元組)
由有序欄位集合形成的記錄稱為元組,欄位可以是任何類型。元組與RDBMS表中的行類似。例:(Raja,30)
- Bag(包)
一個包是一組無序的元組。換句話說,元組(非唯一)的集合被稱為包。每個元組可以有任意數量的欄位(靈活模式)。包由“{}"表示。它類似於RDBMS中的表,但是與RDBMS中的表不同,不需要每個元組包含相同數量的欄位,或者相同位置(列)中的欄位具有相同類型。例:{(Raja,30),(Mohammad,45)}
包可以是關係中的欄位;在這種情況下,它被稱為內包(inner bag)。例:{Raja,30, {9848022338,[email protected],} }
- Map(映射)
映射(或數據映射)是一組key-value對。key需要是chararray類型,且應該是唯一的。value可以是任何類型,它由“[]"表示。例:[name#Raja,age#30]
- Relation(關係)
一個關係是一個元組的包。Pig Latin中的關係是無序的(不能保證按任何特定順序處理元組)。
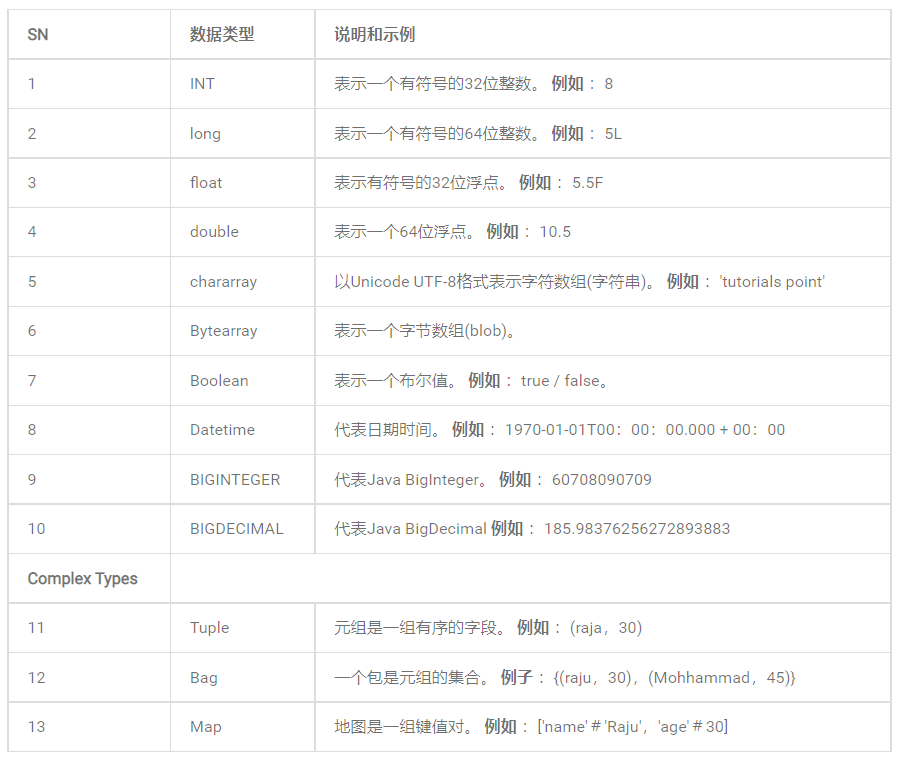
2)數據類型
空值
- 所有上述數據類型的值都可以為NULL。Apache Pig以與SQL相似的方式處理空值。
- null可以是未知值或不存在的值。它用作可選值的占位符。這些空值可以自然發生,也可以是操作的結果。
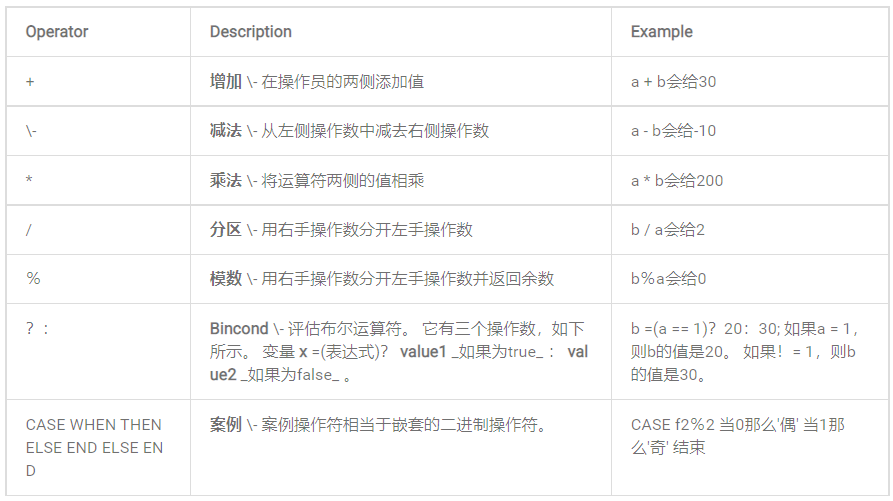
3)算術操作符
下表描述了Pig Latin的算術運算符。假設a = 10和b = 20。
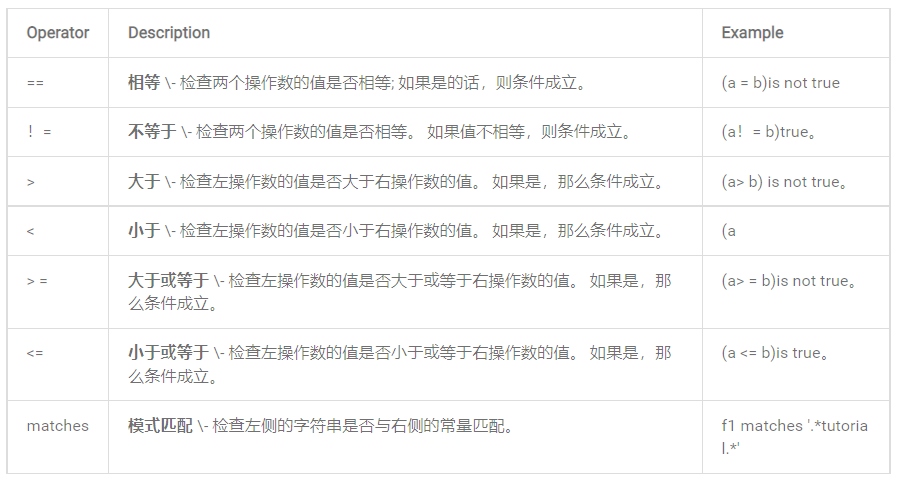
4)比較運算符
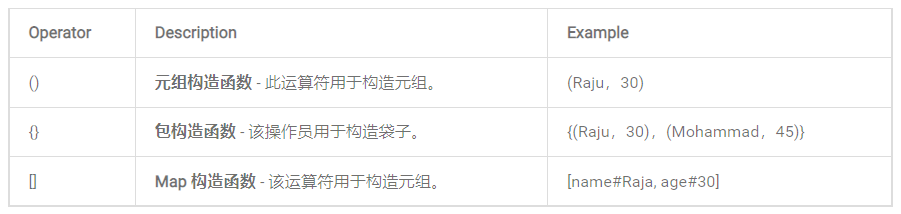
5)類型結構運算符
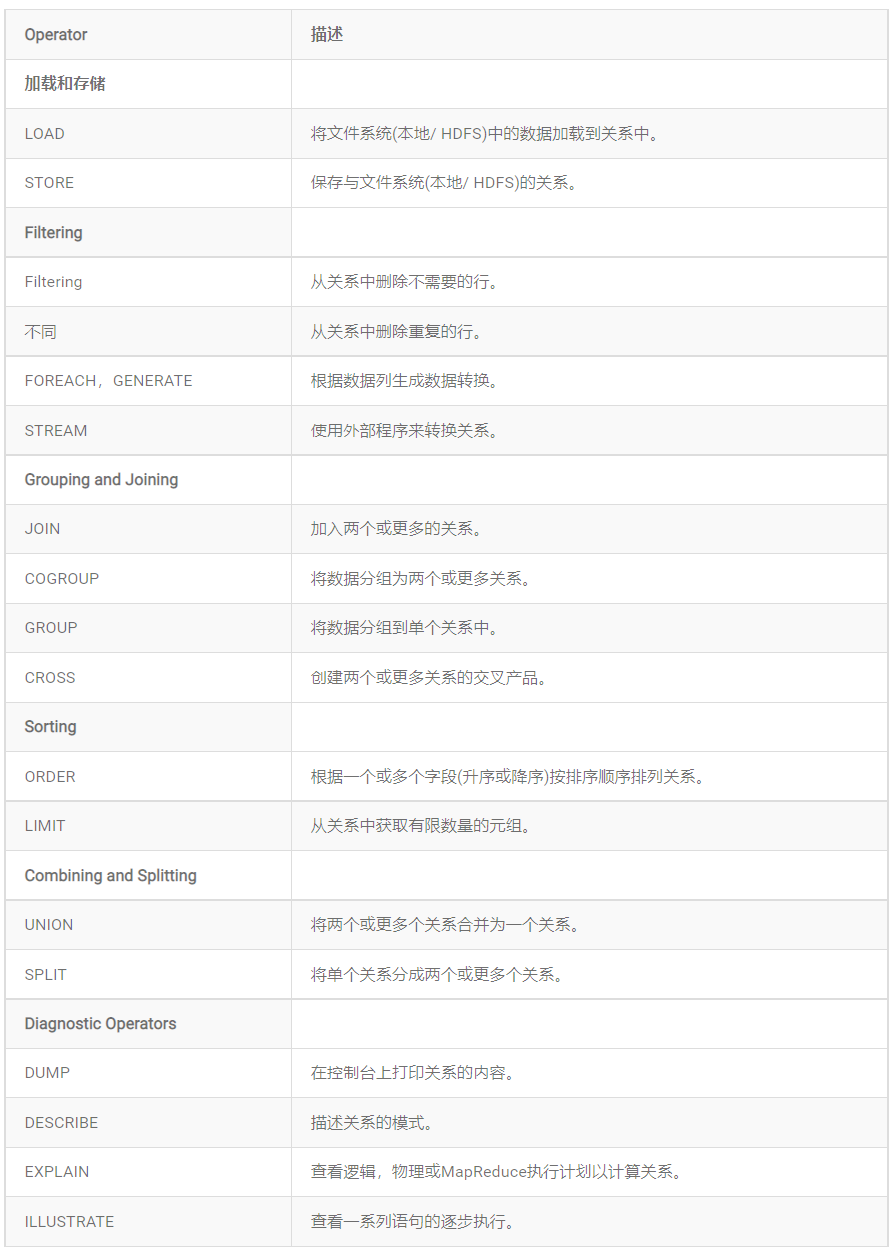
6)關係操作
關於更多Pig Latin基礎知識,可參考官方文檔:https://pig.apache.org/docs/r0.17.0/start.html
七、簡單使用
1)從文件系統(HDFS / Local)將數據載入到Apache Pig中
語法:
如果是MapReduce模式需要提前準備好文件傳到HDFS上,上面已經演示過了,這裡就不重覆了,很簡單
relation_name = LOAD 'Input file path' USING function as schema;
-
relation_name——存儲數據的關係變數。
-
輸入文件路徑(Input file path)——我們必須提到存儲文件的HDFS目錄。 (在MapReduce模式下)
-
函數(function )——我們必須從Apache Pig提供的一組載入函數( BinStorage,JsonLoader,PigStorage,TextLoader )中選擇一個函數。
-
模式(schema)——我們必須定義數據的模式。 我們可以按照以下方式定義所需的模式,例如:(column1 : data type, column2 : data type, column3 : data type);
【溫馨提示】我們載入數據而不指定模式。 在這種情況下,這些列將被作為$0、$2、$2依次類推,代表第幾列數據。
2)Pig存儲數據
語法:
STORE relation_name INTO ' required_directory_path ' [USING function];
【示例】
$ pig
# 不指定絕對路徑就存儲當前用戶目錄下
STORE student INTO 'hdfs://hadoop-node1:8082/pig_Output/ ' USING PigStorage (',');
3)將結果顯示列印在屏幕
$ vi data.txt
001,stu01,18,55
002,stu02,20,50
003,stu03,25,60
$ hadoop fs -put data.txt /tmp/
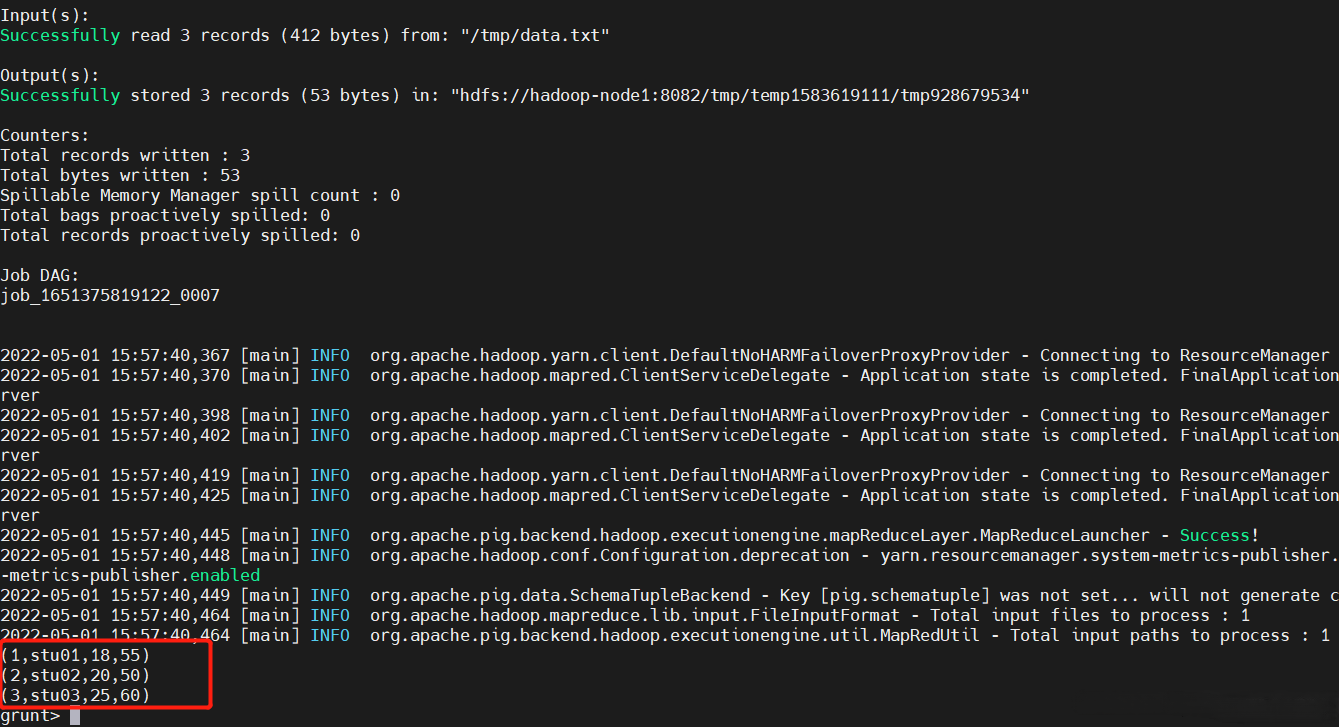
$ student = LOAD '/tmp/data.txt' USING PigStorage(',') as (id:int,name:chararray,age:int,height:int);
# dump不區分大小寫
Dump student
dump student
4)描述操作符
Describe Relation_name
Describe student
5)解釋運算符
explain Relation_name;
explain student;
6)圖解運算符(表結構)
illustrate Relation_name;
illustrate student;
以下操作是類sql操作,如果小伙伴對傳統關係型數據瞭解的話,很容易理解。
7)分組操作(GROUP)
group_data = GROUP Relation_name BY age;
group_data = GROUP student BY age;
dump group_data;
8)協同組操作
該 協同組 操作符的工作或多或少以同樣的方式為group運算。兩個操作符之間的唯一區別是, 組 操作符通常與一個關係一起使用,而 cogroup 操作符用於涉及兩個或更多個關係的語句中。
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad
002,siddarth,Battacharya,22,9848022338,Kolkata
003,Rajesh,Khanna,22,9848022339,Delhi
004,Preethi,Agarwal,21,9848022330,Pune
005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar
006,Archana,Mishra,23,9848022335,Chennai
007,Komal,Nayak,24,9848022334,trivendram
008,Bharathi,Nambiayar,24,9848022333,Chennai
employee_details.txt
001,Robin,22,newyork
002,BOB,23,Kolkata
003,Maya,23,Tokyo
004,Sara,25,London
005,David,23,Bhuwaneshwar
006,Maggy,22,Chennai
將文件上傳到HDFS
$ hadoop fs -put student_details.txt employee_details.txt /tmp/
pig執行
$ pig
student_details = LOAD '/tmp/student_details.txt' USING PigStorage(',')
as (id:int, firstname:chararray, lastname:chararray, age:int, phone:chararray, city:chararray);
employee_details = LOAD '/tmp/employee_details.txt' USING PigStorage(',')
as (id:int, name:chararray, age:int, city:chararray);
cogroup_data = COGROUP student_details by age, employee_details by age;
Dump cogroup_data;
9)JOIN連接操作
在 JOIN 操作符是用來記錄從兩個或兩個以上的關係結合起來。在執行連接操作時,我們聲明每個關係中的一個(或一組)元組作為關鍵字。當這些鍵匹配時,兩個特定的元組匹配,否則記錄被丟棄。聯接可以是以下類型(跟傳統資料庫很相似,但是本質是不一樣的):
- 自連接
- 內部聯接
- 外連接 - 左連接,右連接和完全連接
準備好數據
customers.txt
1,Ramesh,32,Ahmedabad,2000.00
2,Khilan,25,Delhi,1500.00
3,kaushik,23,Kota,2000.00
4,Chaitali,25,Mumbai,6500.00
5,Hardik,27,Bhopal,8500.00
6,Komal,22,MP,4500.00
7,Muffy,24,Indore,10000.00
orders.txt
102,2009-10-08 00:00:00,3,3000
100,2009-10-08 00:00:00,3,1500
101,2009-11-20 00:00:00,2,1560
103,2008-05-20 00:00:00,4,2060
1、自連接
自連接 用於將表與自身連接在一起,就像該表是兩個關係一樣,臨時重命名至少一個關係。
$ pig -x local
customers1 = LOAD './customers.txt' USING PigStorage(',')
as (id:int, name:chararray, age:int, address:chararray, salary:int);
customers2 = LOAD './customers.txt' USING PigStorage(',')
as (id:int, name:chararray, age:int, address:chararray, salary:int);
result = JOIN customers1 BY id, customers2 BY id;
dump result ;
發現就是把兩個表連接在一起顯示了。

2、內部聯接
它通過基於連接謂片語合兩個關係(稱為A和B)的列值來創建新的關係。查詢將A的每一行與B的每一行進行比較,以查找滿足連接謂詞的所有行對。當滿足連接謂詞時,A和B的每對匹配行的列值合併到一個結果行中,去掉重覆列。如果A和B沒有匹配的行就會丟棄。
# 使用本地模式
$ pig -x local
customers = LOAD './customers.txt' USING PigStorage(',')
as (id:int, name:chararray, age:int, address:chararray, salary:int);
orders = LOAD './orders.txt' USING PigStorage(',')
as (oid:int, date:chararray, customer_id:int, amount:int);
# 通過customer id進行關聯
result = JOIN customers BY id, orders BY customer_id;
dump result;

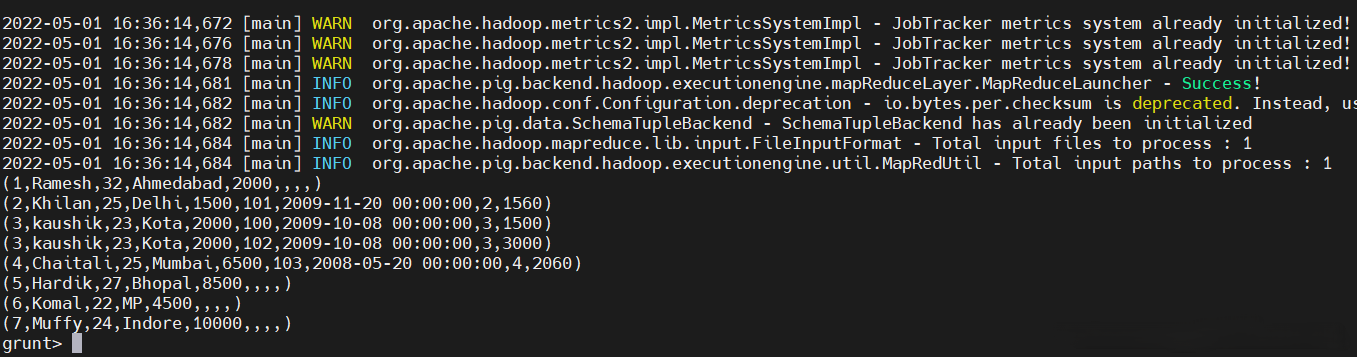
3、左外連接
在 LEFT OUTER JOIN 操作左表返回所有的行,即使是在正確的關係不匹配,如果不匹配右表列會被置空。
# 使用本地模式
$ pig -x local
customers = LOAD './customers.txt' USING PigStorage(',')
as (id:int, name:chararray, age:int, address:chararray, salary:int);
orders = LOAD './orders.txt' USING PigStorage(',')
as (oid:int, date:chararray, customer_id:int, amount:int);
# 通過customer id進行關聯
result = JOIN customers BY id LEFT OUTER, orders BY customer_id;
dump result;
4、右外連接
跟左外連接正好相反,把關鍵詞換成RIGHT執行就行。很簡單,這裡就不演示了。
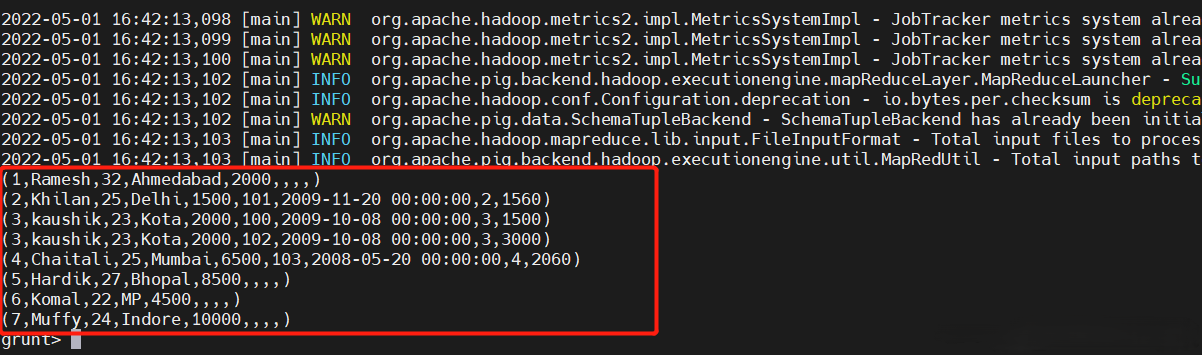
5、全外聯接
當一個關係匹配時, 完整的外部聯接 操作返回行。不匹配的都保留,缺失的補空。
result = JOIN customers BY id FULL OUTER, orders BY customer_id;
dump result
6、多個鍵分組操作
employee.txt
001,Rajiv,Reddy,21,programmer,003
002,siddarth,Battacharya,22,programmer,003
003,Rajesh,Khanna,22,programmer,003
004,Preethi,Agarwal,21,programmer,003
005,Trupthi,Mohanthy,23,programmer,003
006,Archana,Mishra,23,programmer,003
007,Komal,Nayak,24,teamlead,002
008,Bharathi,Nambiayar,24,manager,001
employee_contact.txt
001,9848022337,[email protected],Hyderabad,003
002,9848022338,[email protected],Kolkata,003
003,9848022339,[email protected],Delhi,003
004,9848022330,[email protected],Pune,003
005,9848022336,[email protected],Bhuwaneshwar,003
006,9848022335,[email protected],Chennai,003
007,9848022334,[email protected],trivendram,002
008,9848022333,[email protected],Chennai,001
pig執行
$ pig -x local
employee = LOAD './employee.txt' USING PigStorage(',')
as (id:int, firstname:chararray, lastname:chararray, age:int, designation:chararray, jobid:int);
employee_contact = LOAD './employee_contact.txt' USING PigStorage(',')
as (id:int, phone:chararray, email:chararray, city:chararray, jobid:int);
result = JOIN employee BY (id,jobid), employee_contact BY (id,jobid);
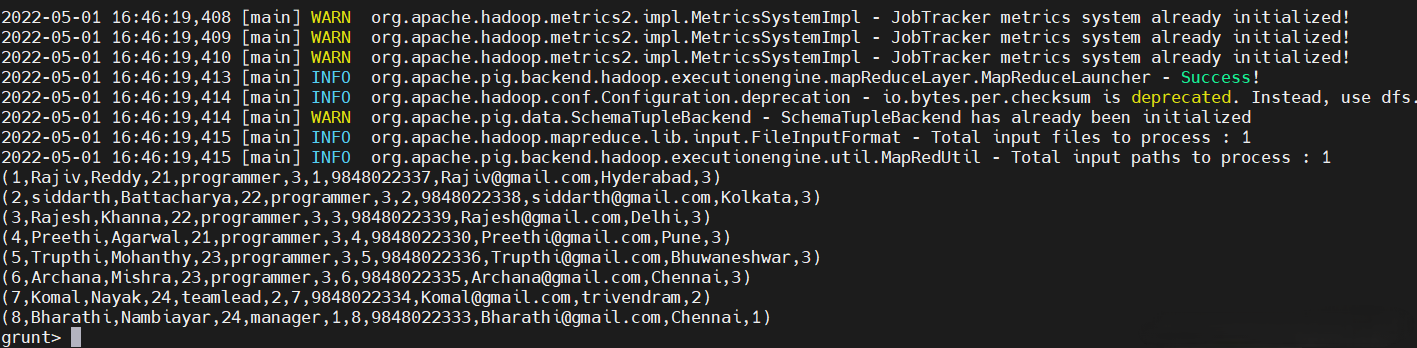
10)交叉操作
該 CROSS 操作符計算兩個或兩個以上關係的跨產品,其實也是求笛卡爾積。
先準備好數據
customers.txt
1,Ramesh,32,Ahmedabad,2000.00
2,Khilan,25,Delhi,1500.00
3,kaushik,23,Kota,2000.00
4,Chaitali,25,Mumbai,6500.00
5,Hardik,27,Bhopal,8500.00
6,Komal,22,MP,4500.00
7,Muffy,24,Indore,10000.00
orders.txt
102,2009-10-08 00:00:00,3,3000
100,2009-10-08 00:00:00,3,1500
101,2009-11-20 00:00:00,2,1560
103,2008-05-20 00:00:00,4,2060
pig執行
# 使用local模式,但是最好使用MapReduce模式,但是這裡為了方便演示,就選擇local模式了
$ pig -x local
customers = LOAD './customers.txt' USING PigStorage(',')
as (id:int, name:chararray, age:int, address:chararray, salary:int);
orders = LOAD './orders.txt' USING PigStorage(',')
as (oid:int, date:chararray, customer_id:int, amount:int);
result = CROSS customers, orders;
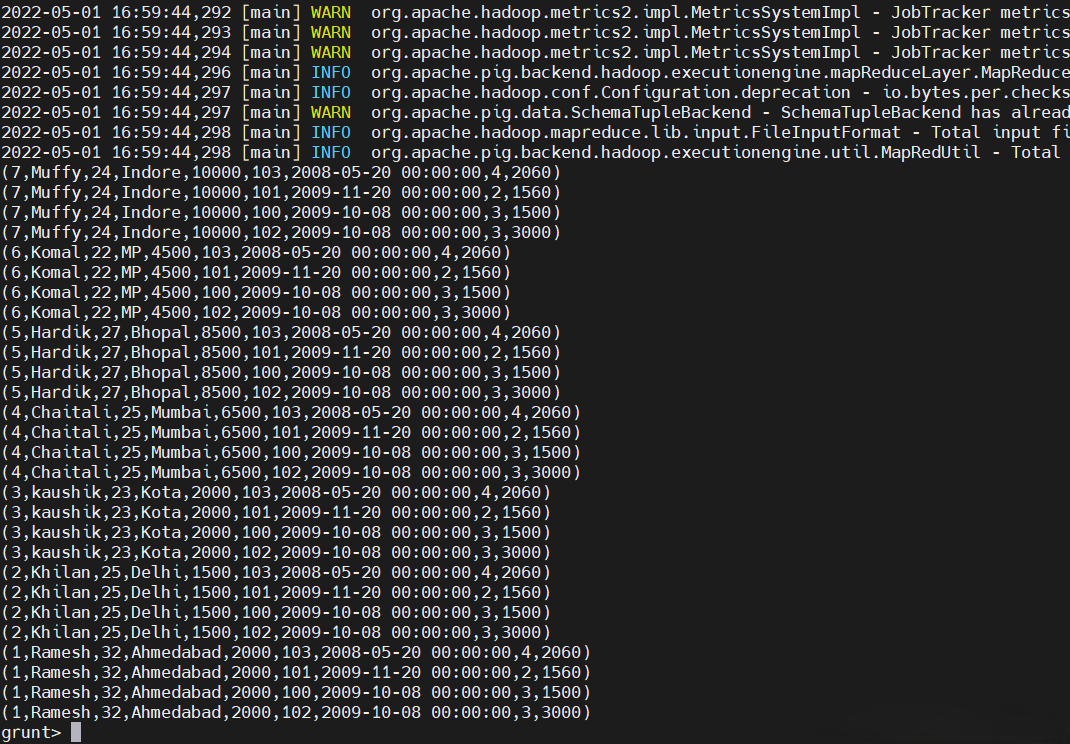
11)聯合操作
Pig Latin 的 UNION 操作符用於合併兩個關係的內容。要對兩個關係執行UNION操作,其列和域必須相同。
先準備好數據
student_data1.txt
001,Rajiv,Reddy,9848022337,Hyderabad
002,siddarth,Battacharya,9848022338,Kolkata
003,Rajesh,Khanna,9848022339,Delhi
004,Preethi,Agarwal,9848022330,Pune
005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar
006,Archana,Mishra,9848022335,Chennai
student_data2.txt
7,Komal,Nayak,9848022334,trivendram
8,Bharathi,Nambiayar,9848022333,Chennai
pig執行
# 使用local模式,但是最好使用MapReduce模式,但是這裡為了方便演示,就選擇local模式了
$ pig -x local
student1 = LOAD './student_data1.txt' USING PigStorage(',')
as (id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray);
student2 = LOAD './student_data2.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray);
result = UNION student1, student2;
dump restult
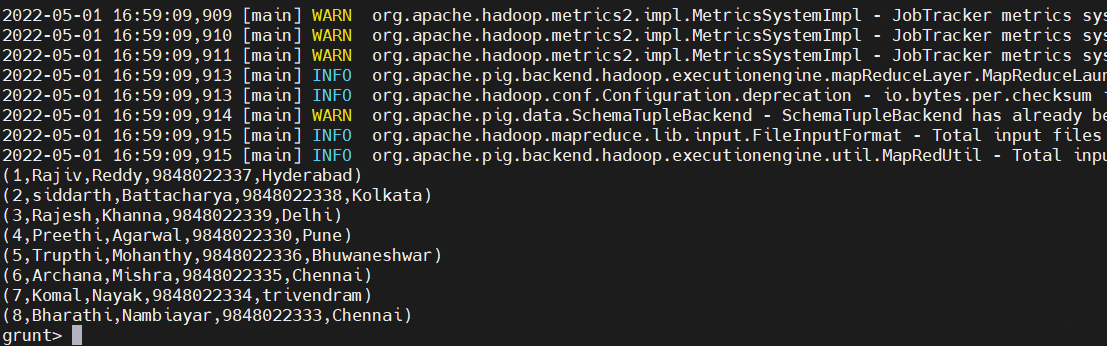
其實像JOIN操作、分組操作,交叉操作、聯合操作等跟傳統資料庫操作是一樣的,但是本質是不一樣,但是可以用傳統的資料庫的思想去理解語句,如有不清楚的小伙伴,可以給我留言。
12)split
該 SPLIT 運算符用於關係分成兩個或更多的關係。
以示例驅動理解,先準備好數據
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad
002,siddarth,Battacharya,22,9848022338,Kolkata
003,Rajesh,Khanna,22,9848022339,Delhi
004,Preethi,Agarwal,21,9848022330,Pune
005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar
006,Archana,Mishra,23,9848022335,Chennai
007,Komal,Nayak,24,9848022334,trivendram
008,Bharathi,Nambiayar,24,9848022333,Chennai
pig執行
$ pig -x local
student_details = LOAD './student_details.txt' USING PigStorage(',')
as (id:int, firstname:chararray, lastname:chararray, age:int, phone:chararray, city:chararray);
# 現在讓我們將關係分為兩部分,一部分列出年齡小於23歲的員工,另一部分列出年齡在22至25歲之間的員工。
SPLIT student_details into student_details1 if age<23, student_details2 if (22<age and age>25);
# 列印輸出
Dump student_details1;
Dump student_details2;
13)條件過濾操作
連接【12)split】的操作
filter_data = FILTER student_details BY city == 'Chennai';
Dump filter_data;
14)去重操作
該 DISTINCT 運算符用於從關係去除冗餘(一式兩份)的元組。
連接【12)split】的操作
distinct_data = DISTINCT student_details;
Dump distinct_data;
15)Foreach遍歷操作
連接【12)split】的操作
foreach_data = FOREACH student_details GENERATE id,age,city;
Dump foreach_data;
16)Order排序操作
連接【12)split】的操作
order_by_data = ORDER student_details BY age DESC;
Dump order_by_data;
17)Limit限制操作
連接【12)split】的操作
limit_data = LIMIT student_details 4;
Dump limit_data;
18)函數操作
Apache Pig提供了各種內置函數,即 eval,load,store,math,string,bag 和 tuple等 函數。
1、評估函數
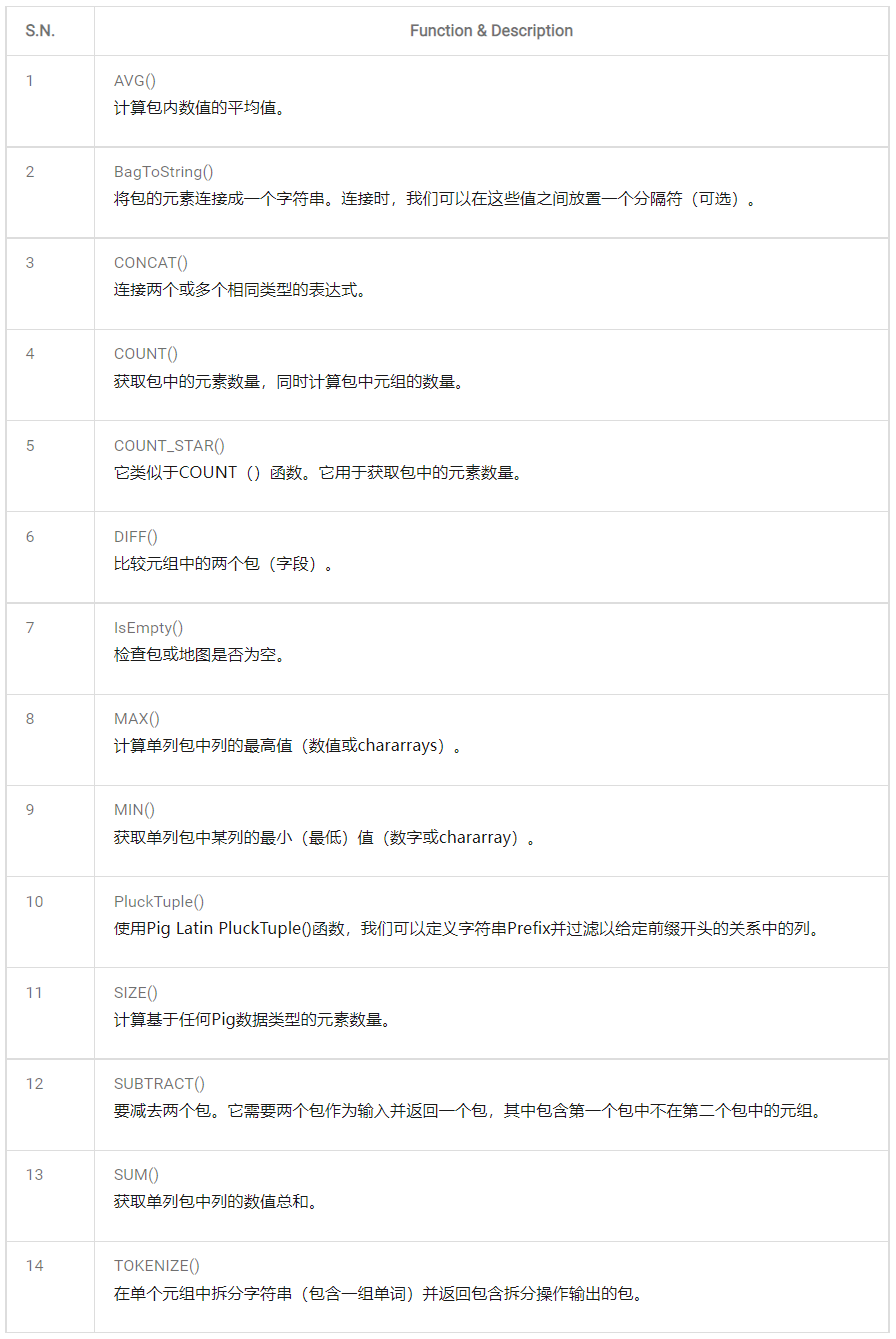
2、載入和存儲函數
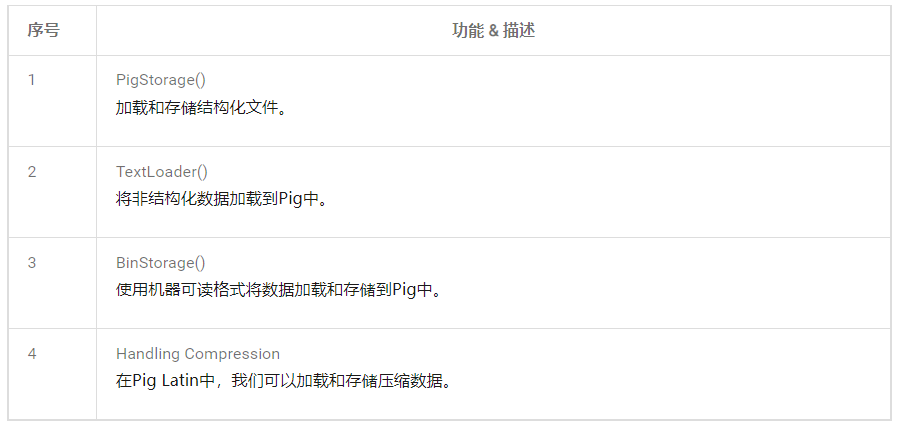
3、Bag和Tuple函數

4、字元串函數

5、日期時間函數

6、數學函數

7、用戶定義函數
除了內置的功能,Apache的pig提供了廣泛的支持 User Defined Functions(UDF的)。 使用這些UDF,我們可以定義我們自己的功能並使用它們。UDF支持以六種編程語言提供,即Java,Jython,Python,JavaScript,Ruby和Groovy。
在使用Java編寫UDF時,我們可以創建和使用以下三種類型的函數:
-
過濾器功能 - 過濾器功能用作過濾器語句中的條件。 這些函數接受一個Pig值作為輸入並返回一個布爾值。
-
評估函數 - Eval函數用於FOREACH-GENERATE語句。 這些函數接受Pig值作為輸入並返回Pig結果。
-
代數函數 - 代數函數在FOREACHGENERATE語句中作用於內袋。 這些功能用於在內袋上執行完整的MapReduce操作。
使用Java編寫UDF
1、在pom.xml文件添加配置依賴
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.pig</groupId>
<artifactId>pig</artifactId>
<version>0.17.0</version>
</dependency>
代碼如下:
/**
* 自定義行數
* 在編寫UDF時,必須繼承EvalFunc類併為exec() 函數提供實現。在這個函數中,寫入UDF所需的代碼。
*
*/
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
public class UDFTest001 extends EvalFunc<String>{
public String exec(Tuple input) throws IOException {
if (input == null || input.size() == 0)
return null;
String str = (String)input.get(0);
return str.toUpperCase();
}
}
在沒有錯誤編譯類之後,右鍵單擊UDFTest001.java文件。它給你一個菜單。IDEA導出jar包
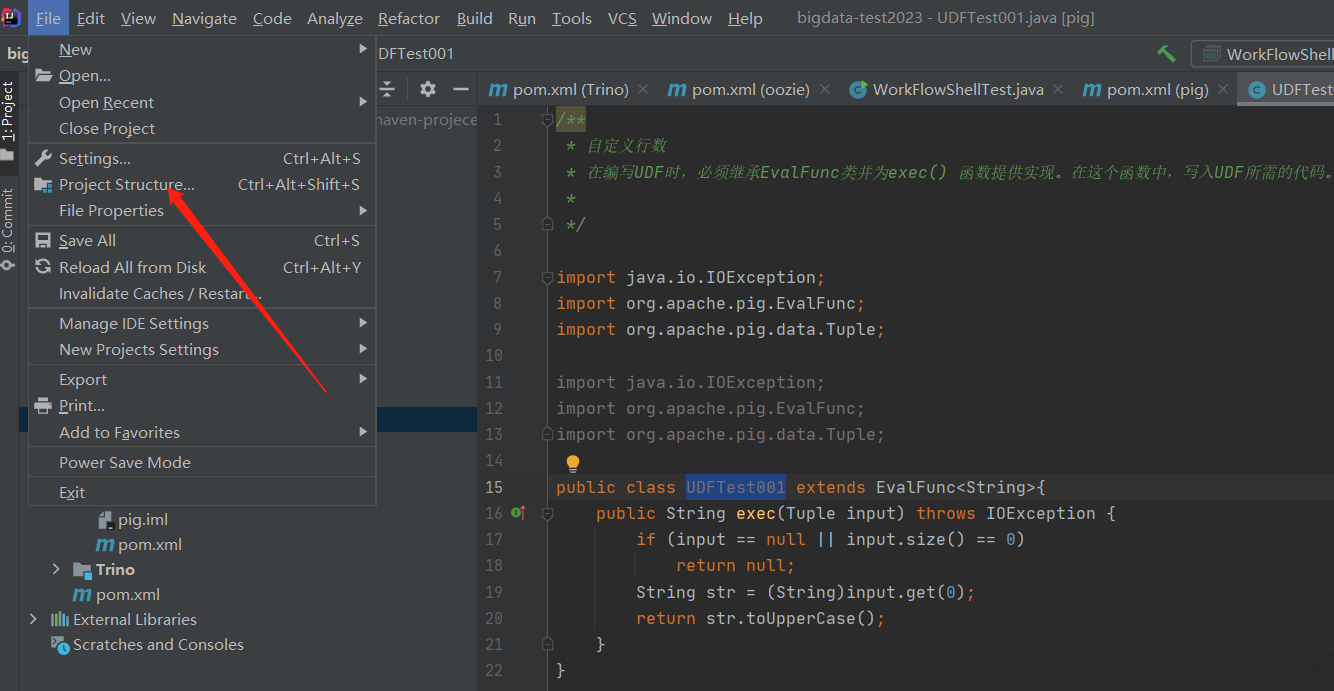
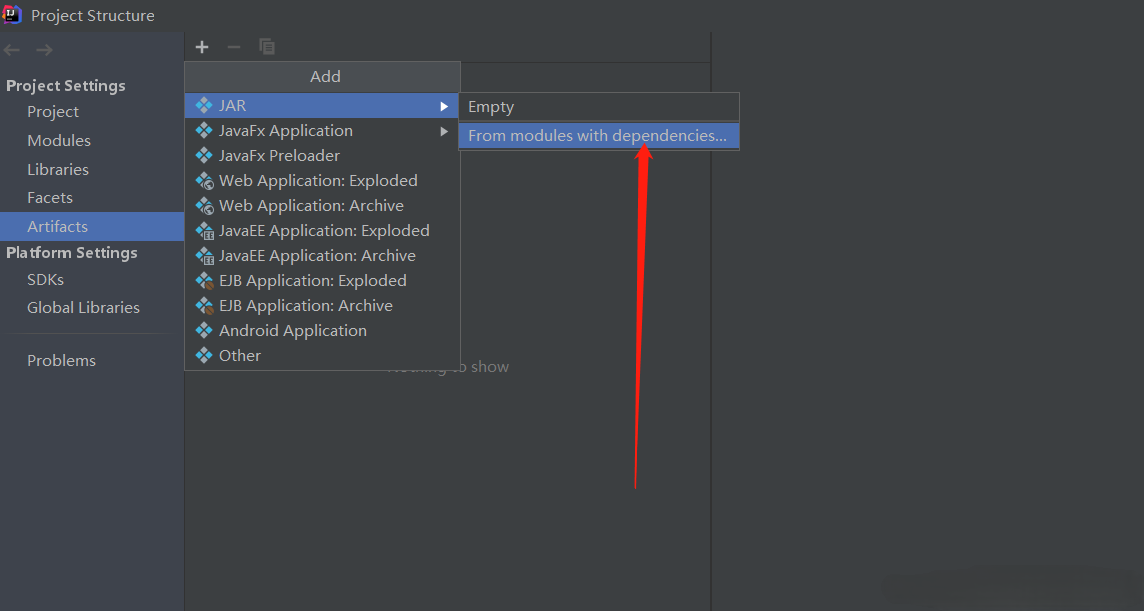
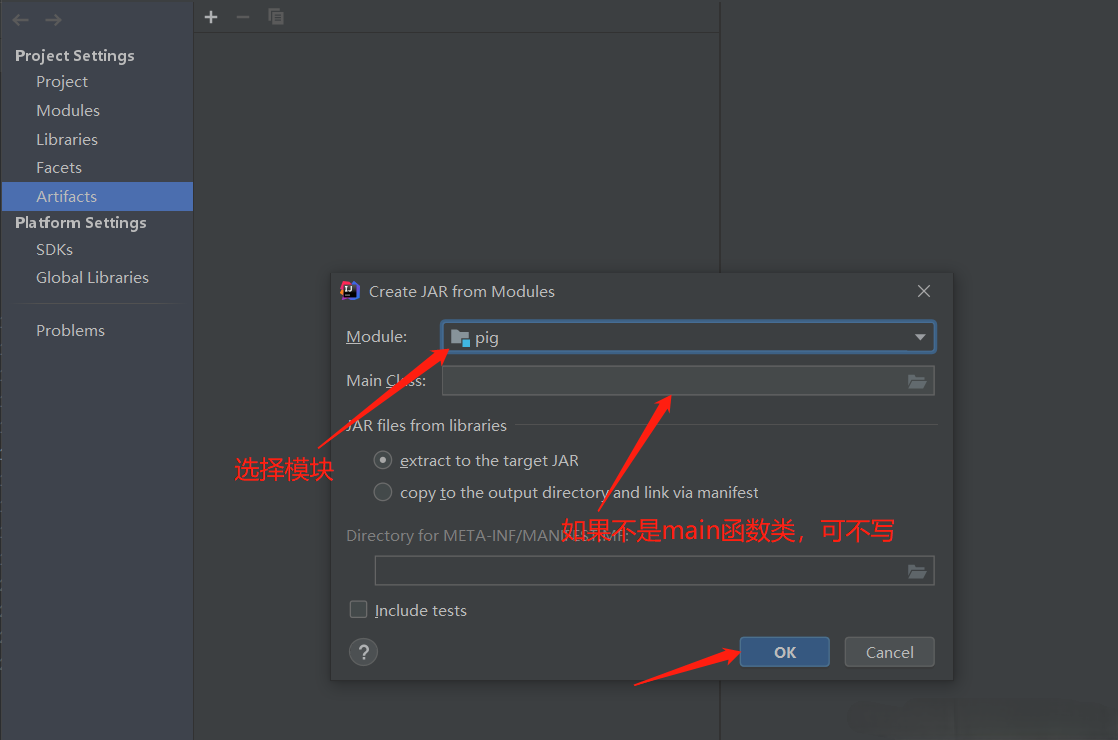
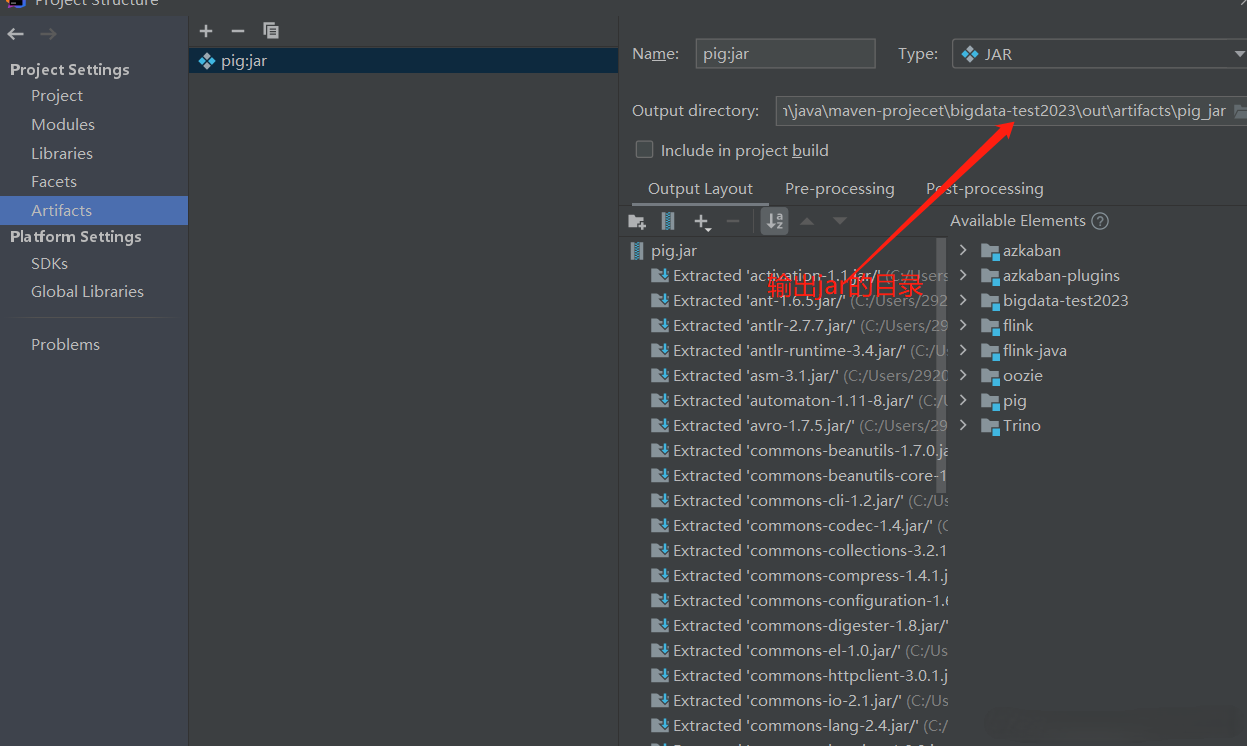
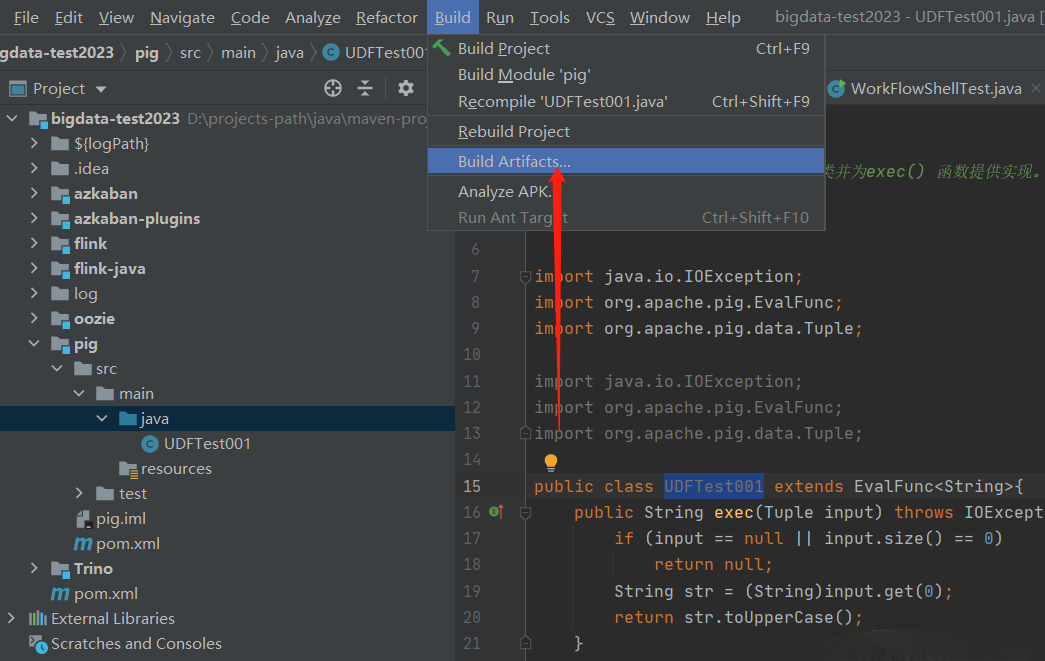
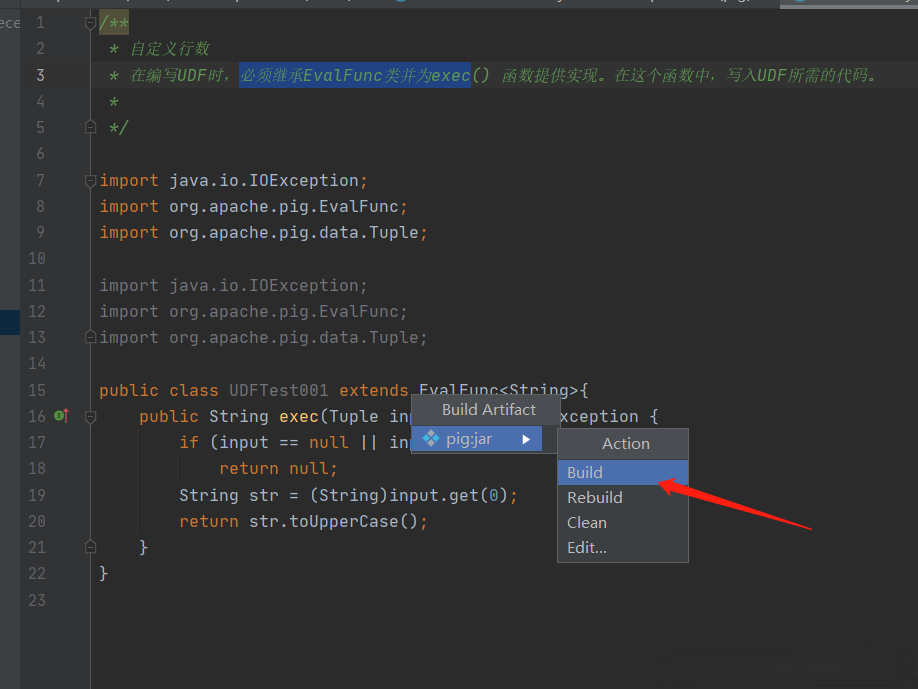
使用UDF,在編寫UDF並生成Jar文件之後,請按照以下步驟進行操作:
第1步:註冊Jar文件
$ pig -x local
REGISTER ./pig.jar
第2步:定義別名
DEFINE alias {function | [
command[input] [output] [ship] [cache] [stderr] ] };
【示例】
DEFINE UDFTest001 UDFTest001()
第3步:使用UDF
準備數據
udfdata.txt
001,Robin,22,newyork
002,BOB,23,Kolkata
003,Maya,23,Tokyo
004,Sara,25,London
005,David,23,Bhuwaneshwar
006,Maggy,22,Chennai
007,Robert,22,newyork
008,Syam,23,Kolkata
009,Mary,25,Tokyo
010,Saran,25,London
011,Stacy,25,Bhuwaneshwar
012,Kelly,22,Chennai
pig執行
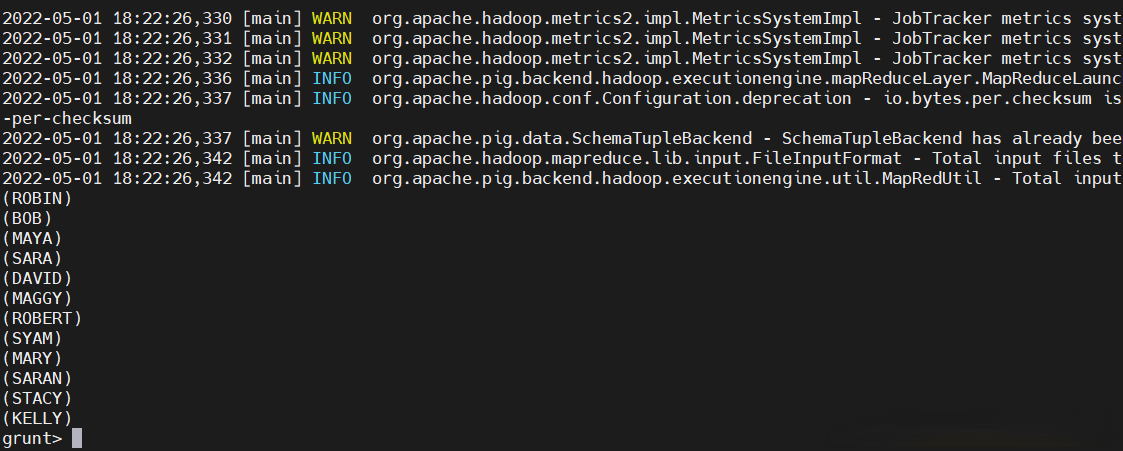
$ pig -x local
udfdata = LOAD './udfdata.txt' USING PigStorage(',') as (id:int, name:chararray, age:int, city:chararray);
Upper_case = FOREACH udfdata GENERATE UDFTest001(name);
dump Upper_case
全部把名字轉換成大寫了
19)執行腳本
# 互動式執行腳本
$ pig -x mapreduce
exec xxx.pig
# 非互動式執行腳本
$ pig -x mapreduce xxx.pig
八、Apache Pig與其它組件對比
1)Apache Pig與MapReduce對比

2)Apache Pig與SQL對比
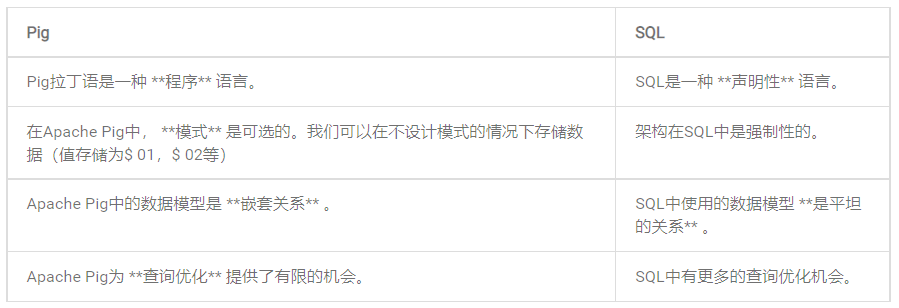
除了上述差異之外,Apache Pig Latin 還有以下幾個優勢:
- 允許在管道中分割。
- 允許開發人員在管道中的任何地方存儲數據。
- 聲明執行計劃。
- 提供操作員執行ETL(提取,轉換和載入)功能。
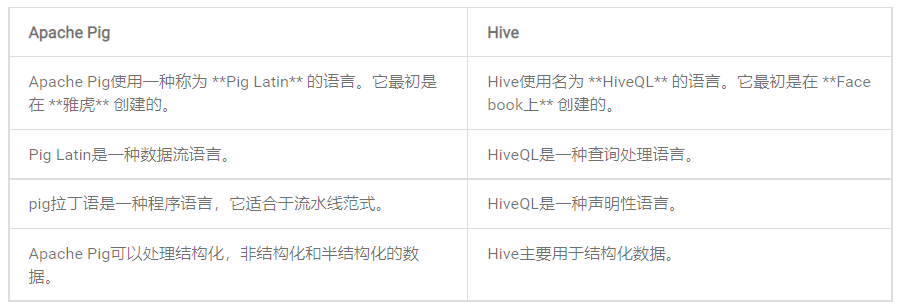
3)Apache Pig與Hive對比
Apache Pig和Hive都用於創建MapReduce作業。並且在某些情況下,Hive以類似Apache Pig的方式在HDFS上運行。在下表中,我們列出了一些將Apache Pig與Hive分開的重要觀點。
Apache Pig到這裡就結束了,操作起來還是比較簡單,有疑問的小伙伴,歡迎給我留言,小伙伴也可以參考官方文檔。後續會有更多關於大數據文章,請耐心等待。


