
分享嘉賓:王懷遠 阿裡雲 表格存儲架構師 編輯整理:李瑤 DataFun 出品平臺:DataFunTalk 導讀: 大家好,我是王懷遠,我2015年加入阿裡雲,一直從事表格存儲的研發和架構相關工作,目前擔任表格存儲的架構師。我在存儲和資料庫領域有一些研發和架構方面的經驗。 本次分享的主題是一站式物聯 ...
分享嘉賓:王懷遠 阿裡雲 表格存儲架構師
編輯整理:李瑤 DataFun
出品平臺:DataFunTalk
導讀: 大家好,我是王懷遠,我2015年加入阿裡雲,一直從事表格存儲的研發和架構相關工作,目前擔任表格存儲的架構師。我在存儲和資料庫領域有一些研發和架構方面的經驗。
本次分享的主題是一站式物聯網存儲產品的架構設計,希望大家可以先回答以下幾個問題:
- 第1個問題:物聯網場景下的數據需求有哪些,如何分類?
- 第2個問題:如何針對物聯網場景設計一款存儲或資料庫產品?
- 第3個問題:怎麼達到成本性能相比傳統方案能夠優化10倍的目標,技術選型的原則和方向是什麼?
本次分享側重於技術分析,不介紹具體的產品功能。帶著這3個問題,我們進入今天的分享和討論。
今天的介紹會圍繞下麵四部分展開:
- 物聯網存儲的需求:通過分析物聯網存儲的場景,對場景中涉及到的數據進行分類,分析這些數據對於資料庫或者存儲系統的相關需求,後面我們對於解決方案和架構設計的分析也會基於這些具體的需求來展開。
- 物聯網存儲解決方案:介紹一些物聯網場景下的存儲解決方案,並由此引出為什麼需要一個一站式的物聯網存儲產品,要實現的技術目標是什麼。
- 架構設計:分析如何進行架構選型,從而實現我們對於一站式存儲產品的技術目標。
- 總結
--
01 物聯網儲存的需求
1. 物聯網數據
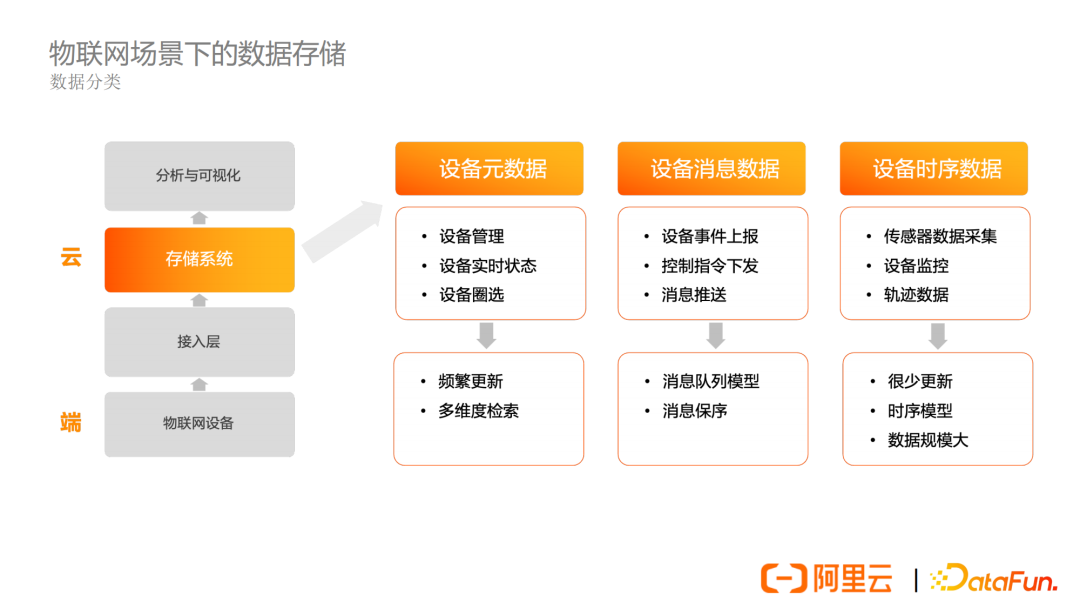
從整體來說,對於一個物聯網業務,首先要解決設備接入的問題。設備接入後,數據不斷上傳,存儲到存儲系統或者是資料庫中。然後再對這些數據進行分析和可視化。
常見的物聯網數據可以分為三個類別,分別是設備元數據、設備消息數據和設備時序數據。
設備元數據存儲了設備的標識、屬性、狀態等。這部分數據可以用來進行設備管理、設備狀態查詢和設備圈選等。
設備的消息數據,分為上行消息和下行消息,上行消息比如設備事件的上報,下行消息比如控制指令的下發、消息推送等等。消息數據常常用隊列模型來建模,每個設備可以設計兩個隊列用來區分上行消息和下行消息,在隊列模型下,對寫入同一個隊列的消息天然有保序的要求,新寫入的消息必須排在隊列的末尾,否則可能會出現消息漏收的問題。
第三類數據是設備的時序數據,時序數據一般是這三類數據中規模最大的。常見的時序數據比如端上感測器採集的數據、設備的監控數據、設備的軌跡數據等等。這些數據很少更新,一般採用時序模型進行存儲,數據規模大。
2. 對存儲系統的需求

首先是一些通用的要求,比如高可靠、高可用、低成本、高性能、易擴展、易運維等等。
其次,不同類型數據也有著不同的功能需求。
設備元數據的要求是需要支持多維度檢索、支持靈活分析、對於地理位置相關的場景需要支持地理空間的檢索能力。
消息數據的要求是要支持隊列模型、支持海量數據、支持消息保序等。
時序數據的要求是支持時序數據模型、支持時間序列的元數據檢索、支持數據的聚合計算等。由於時序數據存儲量大,對存儲成本的需求非常明顯。
總結一下,物聯網存儲的核心需求是,在海量數據下實現極低的成本、高併發寫入和查詢能力、可快速分析、支持元數據高頻更新和多條件檢索。
--
02 物聯網儲存解決方案
帶著這些需求,我們進入第二部分,物聯網存儲解決方案。
1. 車聯網場景例子
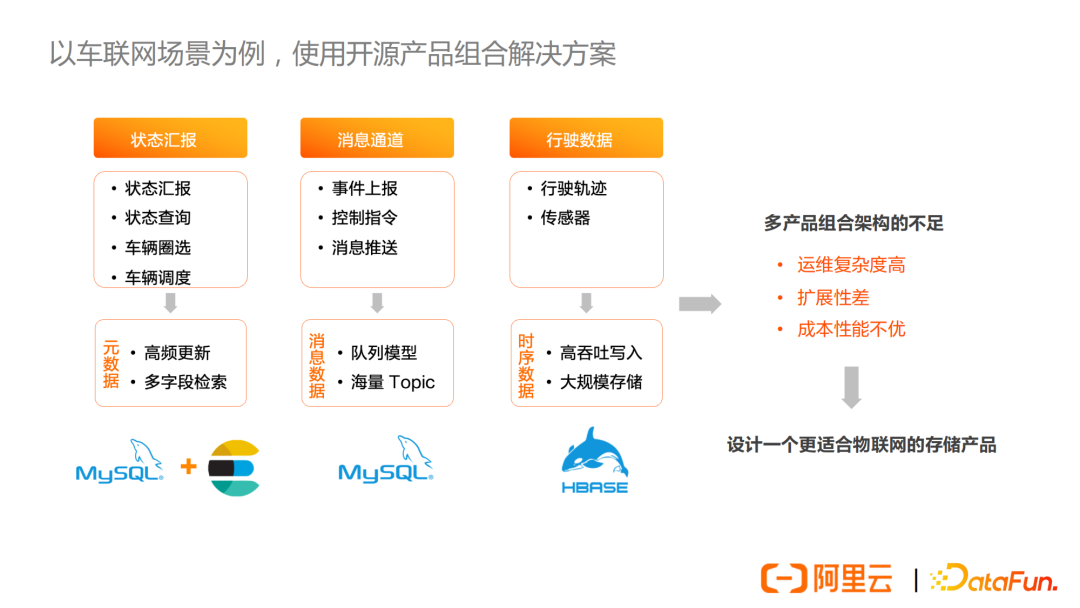
在開源資料庫或者存儲系統中,單一產品很難同時滿足一個物聯網場景中多種不同類型數據的需求。因此,常見的物聯網存儲解決方案需要使用多款產品。
這裡我們舉一個車聯網場景的例子。這個場景中也包含三類數據,第一類是車輛狀態彙報,屬於元數據場景,主要用於車輛圈選、車輛調度等;第二類是消息通道,屬於消息數據場景,包括事件上報、控制指令、消息推送等;第三類是行駛數據,屬於時序數據場景,包括行駛軌跡,以及行駛狀態的一些信息,如速度、發動機參數等。
每類數據對存儲都有著不同的要求。
使用開源的解決方案來解決以上三個場景需求,通常需要使用組合的解決方案。對於車輛元數據,可能會使用MySQL + Elasticsearch的方案,引入ES是為瞭解決多欄位組合條件檢索的問題。對於消息數據,使用MySQL來進行存儲。時序數據,則會採用HBase,來滿足高吞吐寫入和大規模存儲的需求。
這樣的組合解決方案在架構方面有著明顯不足:
- 首先是運維複雜度較高,因為要運維多個產品,並且需要維護多個產品之間的數據同步;
- 其次是擴展性差,當數據規模不斷增加時,某個產品在規模和性能方面可能會出現不足,這時候又要尋找新的解決方案,如果引入新的組件也會進一步加大運維複雜度和成本;
- 最後,整個方案的成本和性能並不優,一方面是這些產品並沒有針對物聯網場景進行優化,另一方面是由於資料庫的發展,也產生了很多新的技術。
為瞭解決以上問題,我們希望設計一個更適合物聯網的存儲產品。
2. 一站式存儲解決方案設想

首先,我們的目標是一個一站式的物聯網存儲產品。這個產品通過多模型來滿足不同類型數據的需求,對外提供多種訪問介面,包括標準SQL、API或SDK,另外也需要提供標準的數據訂閱介面,用於數據導出和生態對接。
在內核方面,存儲引擎和計算引擎應該針對物聯網場景的大規模、低成本、數據分析等需求進行優化。
在生態方面,需要對接物聯網生態的上下游,上游包括數據採集、寫入,以及大數據分析結果表的寫入。下游對接實時計算、大數據分析、BI、AI、以及一些可視化工具。
整體技術目標如下:
- 從功能方面,需要滿足元數據、時序、消息三類場景,支持高併發寫入和查詢,支持物聯網場景的分析需求。
- 從成本方面,希望存儲成本相比傳統解決方案能夠降低90%。
- 從性能方面,希望分析性能相比傳統解決方案可以提升10倍。
為什麼要提出這樣的目標呢?
一方面,從物聯網客戶的角度,數據規模在不斷膨脹,如果數據增長10倍,成本也增長10倍,那麼將是巨大的一筆IT支出。換個角度來說,必須存在一個成本為現有方案1/10的解決方案,才能支撐物聯網數據的高速增長。
另外一方面,傳統的解決方案並沒有很好地利用雲計算、資料庫方面的一些最近的發展和技術,在成本和性能方面並不優,所以我們才提出一個更高的目標。
那麼如何設計才能滿足這樣的成本和性能目標,這是一個長期需要討論的話題,本次分享跟大家一起討論一下我們在這方面的思考和經驗。
--
03 架構設計
1. 時序數據特征

首先,以時序場景為例,分析數據模型和特征。
以時序為例,主要有兩方面原因,一方面是因為時序數據是物聯網場景下占比最大的一類數據,另一方面時序數據本身也有元數據,所以針對時序數據的優化技術也可以應用到設備元數據場景中。
時序數據模型,是一個典型的時間線加多值數據點的結構。
時間線:描述產生數據的設備或者叫數據源,同時可以記錄相關標簽和屬性。如上圖表格中的前三列,第一列是度量類型,第二列是數據源標識,第三列是時間線的標簽。標簽是對數據源的一些描述,可以作為維度,基於標簽進行聚合。
數據點:即度量值,如上圖表格中的後三列,每個數據點都對應一個時間戳,每個時間可能對應單個點(單值模型)或多個點(多值模型)。
另一方面,時序數據模型是一種靈活的表結構模型。
標簽可以自定義、度量點可以自定義。
靈活表結構對用戶使用是非常方便的,但只有部分時序資料庫是支持靈活表結構的。
時序數據模型具有以下特點:
- 首先,從寫入角度,一般是由設備端按照一定頻率上報數據,一般只有新增,很少更新曆史數據。
- 其次,從查詢角度,熱數據查詢頻率較高,冷數據也會進行查詢,頻率較低,同時對熱數據或冷數據都有統計分析的需求。
在進行技術架構設計時,會針對這些數據特點進行設計。
2. 車聯網例子
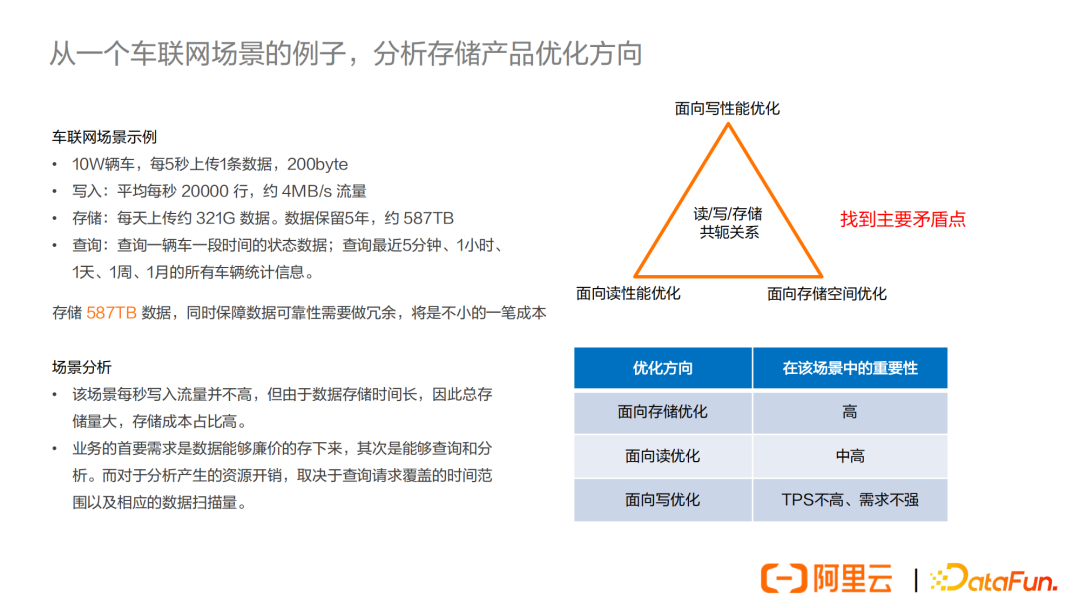
下麵我們通過一個具體的例子,來分析存儲產品的優化方向。這個例子主要是用來存儲車輛行駛數據:
- 10W輛車,每5秒上傳1條數據,200byte
- 寫入:平均每秒 20000 行,約 4MB/s 流量
- 存儲:每天上傳約 321G 數據。數據保留5年,約 587TB
- 查詢:查詢一輛車一段時間的狀態數據;查詢最近5分鐘、1小時、1天、1周、1月的所有車輛統計信息
在這個場景中,為了保障數據可靠性,需要做冗餘,比如採用多副本技術,那麼實際存儲量就可能會達到PB級別,將會是一筆不小的存儲成本。
對這個場景進行一定分析:
- 首先,該場景每秒寫入流量並不高,但由於數據存儲時間長,因此總存儲量大,存儲成本占比高。
- 其次,業務的首要需求是數據能夠廉價地存下來,其次是能夠查詢和分析。而對於分析產生的資源開銷,取決於查詢請求覆蓋的時間範圍以及相應的數據掃描量。
那麼怎麼針對這個場景做優化呢?
首先,我要介紹一個資料庫優化方面的經典理論,叫做讀/寫/存儲優化的共軛關係。這個理論簡單來說就是,一項技術很難同時優化讀/寫/存儲三個方面,往往只能優化其中一個或者兩個。比如面向讀優化的技術,往往是對寫性能不友好的。而面向寫優化的技術,往往又對讀性能是不友好的。有些可以同時優化讀和寫的技術,比如緩存技術,對存儲空間又是不友好的,即需要更大的存儲空間,比如我們經常說的一句話,就是用空間來換時間。因此,我們的設計原則就是要找到場景中的主要矛盾點,選擇不同的技術組合。
針對上述場景,主要的優化方向在哪裡呢?
前面我們已經分析過,存儲成本是這個場景中成本占比最高的部分,也是用戶最重要的需求。因此首要目標是面向存儲優化,其次是面向讀性能優化。而對於寫性能,因為本身TPS不高,在這個場景中需求並不強。
下麵就來分析如何進行存儲成本和讀性能的優化。
3. 面向存儲成本的優化
① 第一個問題,選擇怎樣的存儲格式?
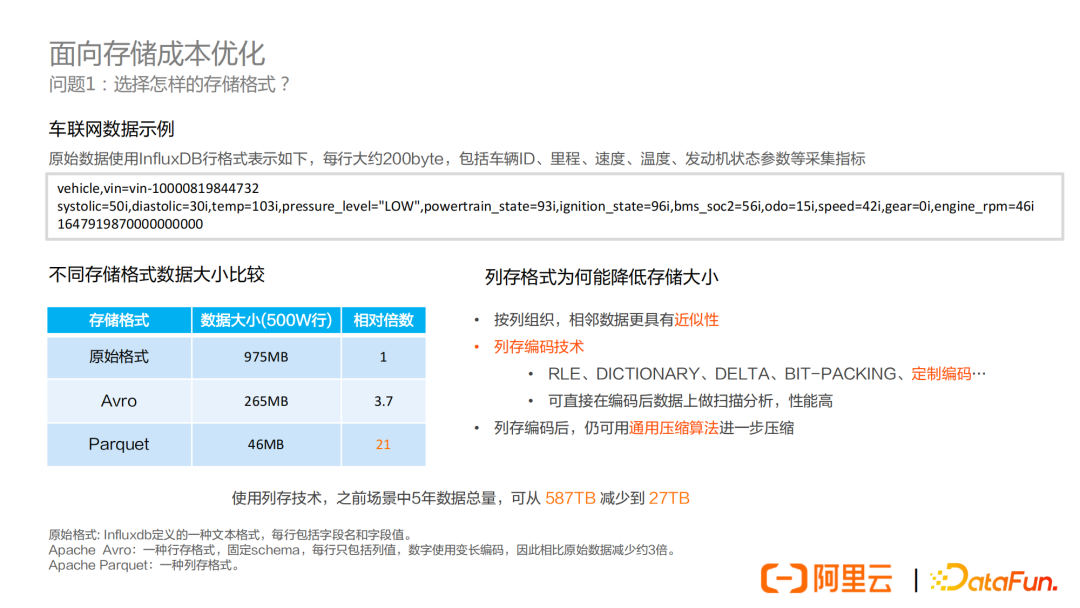
不同存儲格式有著不同的優缺點,我們這裡還是以剛纔的例子為例,對比一下不同的存儲格式,分析一下採用不同格式存儲,最終的存儲空間大小。
這個數據樣例如下,每行大約200byte,包括車輛ID、里程、速度、溫度、發動機狀態參數等採集指標。
原始數據生成500w行,大小為975MB,大約1GB。分別採用Apache Avro和Parquet格式進行存儲,其中Avro大小為265MB,相比原始優化3.7倍,Parquet大小為46MB,相比原始優化21倍。
可以看到使用不同的存儲格式,有著巨大的差異。
這裡簡單再介紹下Avro和Parquet。
Avro是一種行存格式,相比原始格式的優勢在於,Avro的schema是預先定義好的,每行只存儲一個列值。同時,數字使用變長編碼,相比原始數據減少了約3倍。
Parquet是一種列存格式,優化效果更加明顯。列存格式為何能降低存儲大小:
-
按列組織,相鄰數據更具有近似性
-
** 列存編碼技術**
a. RLE、DICTIONARY、DELTA、BIT-PACKING、定製編碼;
b. 可直接在編碼後數據上做掃描分析,性能高。 -
列存編碼後,仍可用通用壓縮演算法進一步壓縮
總結一下,使用列存技術,可以把數據從587TB減少到27TB。
套用之前的資料庫優化理論,列存技術是面向存儲空間優化,同時面向分析優化的一種存儲結構。當然,它也有一定的劣勢,比如對於寫性能會增加額外開銷,這種一般都是採用行模式寫入,後臺批量轉列存的方式來優化。另外對於整行數據讀取,列存會有多次IO,這個場景也相比行存有一定的劣勢。
② 第二個問題,選擇怎樣的存儲架構?
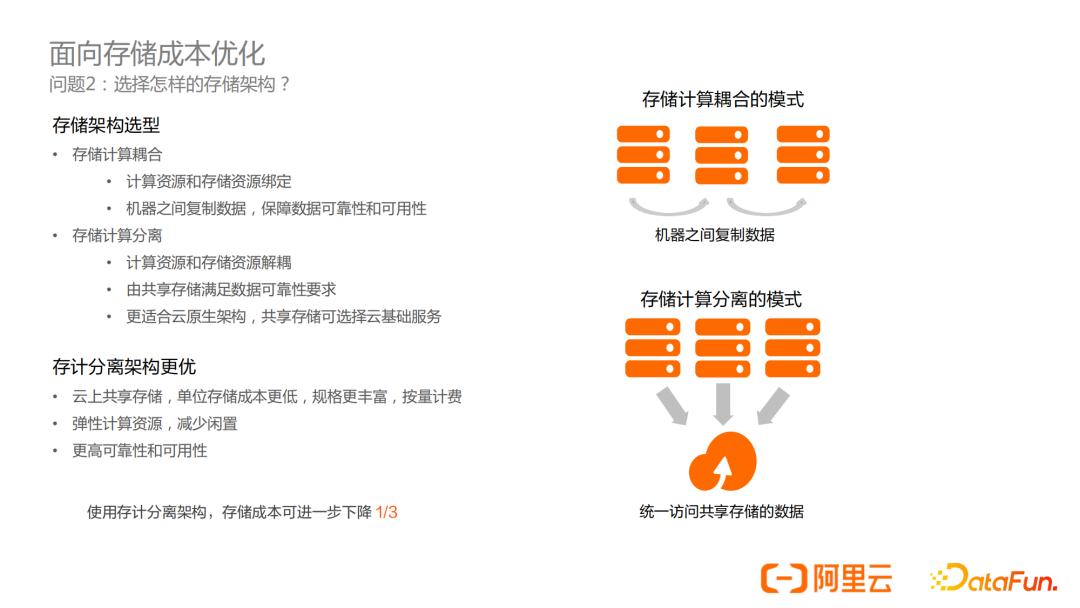
這裡的存儲架構選擇,指的是選擇存儲計算耦合的架構還是存儲計算分離的架構。
首先,還是對這兩種架構做一下介紹。
- 存儲計算耦合
計算資源和存儲資源綁定
機器之間複製數據,保障數據可靠性和可用性 - 存儲計算分離
計算資源和存儲資源解耦
由共用存儲滿足數據可靠性要求
更適合雲原生架構,共用存儲可選擇雲基礎服務
我們認為存儲計算分離的架構是更適合物聯網和大規模數據場景的:
- 雲上共用存儲,單位存儲成本更低,規格更豐富,按量計費
- 彈性計算資源,減少閑置
- 更高可靠性和可用性
使用存計分離架構,我們預計,存儲成本可以下降1/3,並且計算的彈性更好,可以降低計算成本。
③ 第三個問題,如何降低冷數據訪問成本?
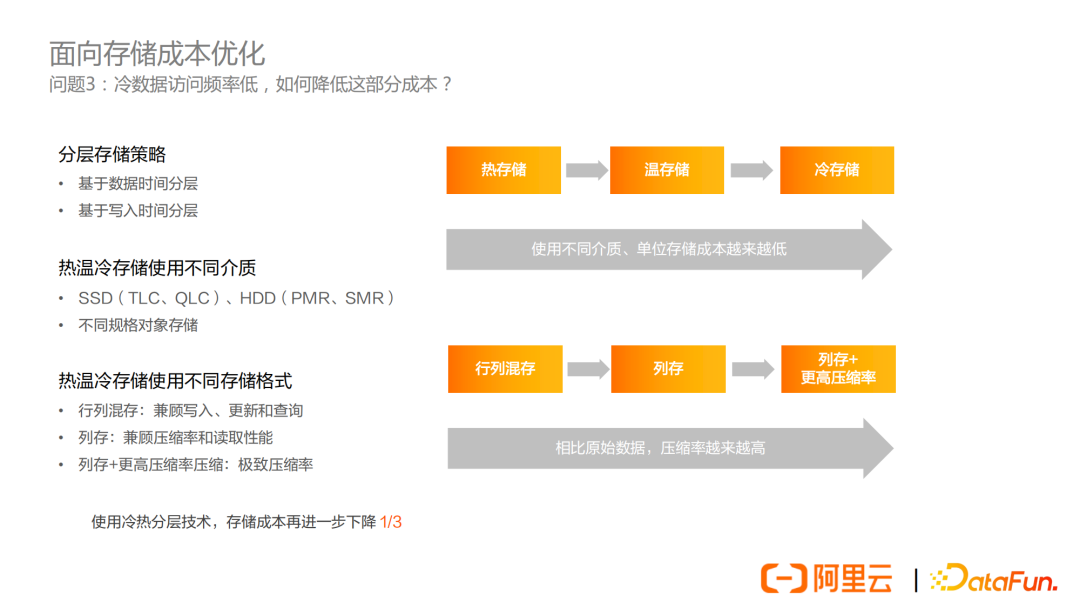
物聯網場景下,冷數據訪問頻率低,很多時候只是為了歸檔,並不怎麼查詢,因此思考如何優化這部分的成本。解決方案就是將數據進行分層存儲。
分層策略有如下兩種:
- 基於數據時間分層
- 基於寫入時間分層
分層之後我們可以做的第一個優化是,將不同層的數據採用不同介質來存儲,以降低單位存儲大小的成本,例如:
- SSD(TLC、QLC),HDD(PMR、SMR)
- 不同規格對象存儲
另外,不同層還可以採用不同的存儲格式,以平衡成本和性能的需求。
- 對於熱數據,行列混存:兼顧寫入、更新和查詢
- 對於溫數據,列存:兼顧壓縮率和讀取性能
- 對於冷數據,列存+更高壓縮率壓縮:追求極致壓縮率,降低存儲成本
後面在查詢性能分析時,也會對不同層的存儲結構選擇進行分析。
總結一下,使用冷熱分層技術,預計存儲成本再進一步下降1/3。那麼綜合之前講的存儲格式優化、存儲計算分離架構以及冷熱分層技術,我們希望達到存儲成本整體降低10倍的目的。
4. 面向讀性能優化
首先,我們還是分析一下物聯網查詢場景和特點。
下麵列舉了三類典型的查詢模式,分別是熱數據查詢,數據分析和元數據檢索。
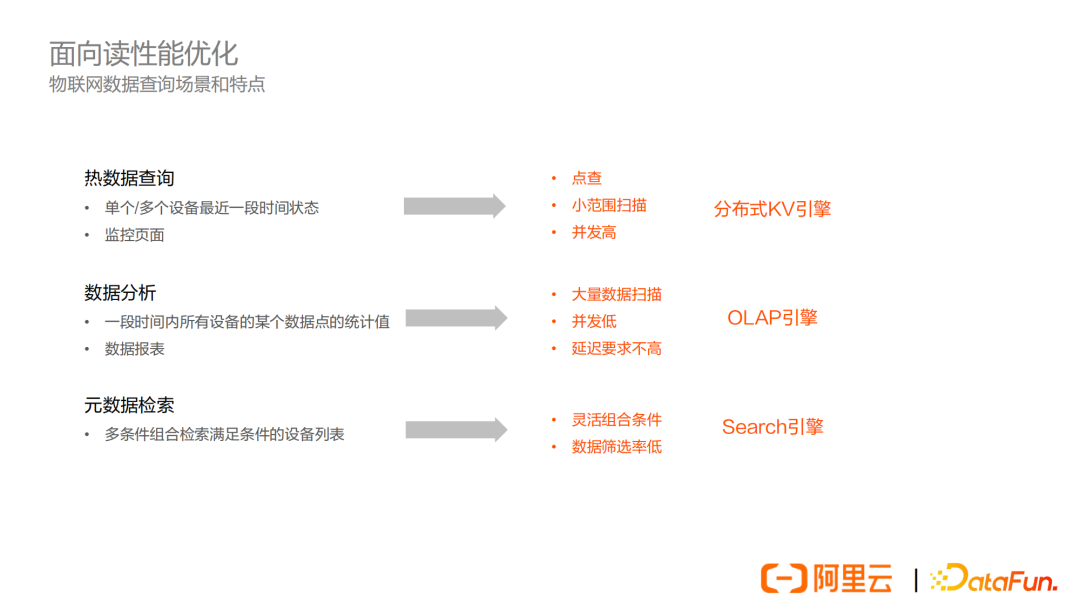
- 熱數據查詢場景,比如查詢單個或者多個設備最近一段時間的狀態,可用於監控等場景。
- 數據分析場景,比如分析一段時間內所有設備的某個數據點的統計值等等,用來做報表、數據統計或者異常點篩選等,一般會查詢熱數據或者溫數據。對於冷數據也會有分析統計需求,一般查詢頻率比較低。
- 元數據檢索場景,一般是根據多種組合條件來檢索滿足條件的設備列表,有多種用途。
這三類場景對資料庫的查詢模式也有很大差別:
- 第一類場景的查詢模式一般是點查和小範圍的掃描,單個請求開銷比較低,但是併發要求高,適合採用一些分散式的KV引擎技術。
- 第二類場景的查詢模式一般是大量數據掃描,單個請求掃描量比較大,但併發低,延遲要求一般不高,適合採用一些分散式的OLAP引擎技術。
- 第三類場景的查詢模式一般是通過靈活的組合條件做數據篩選,數據的篩選率比較低,一般是採用搜索引擎相關的技術。
綜上,物聯網查詢的需求非常豐富,但是我們可以總結出來一些基本規律:
- 對於熱數據,需要具備高併發查詢和分析能力
- 對於溫冷數據,查詢頻率低,但需要具備分析能力
- 對於元數據,需要支持多條件組合查詢等靈活的檢索能力
此外,還需要平衡查詢性能和存儲成本,不能為了滿足查詢需求而大幅增加整體成本。
① 第一個問題,如何在低成本存儲上滿足查詢分析需求?
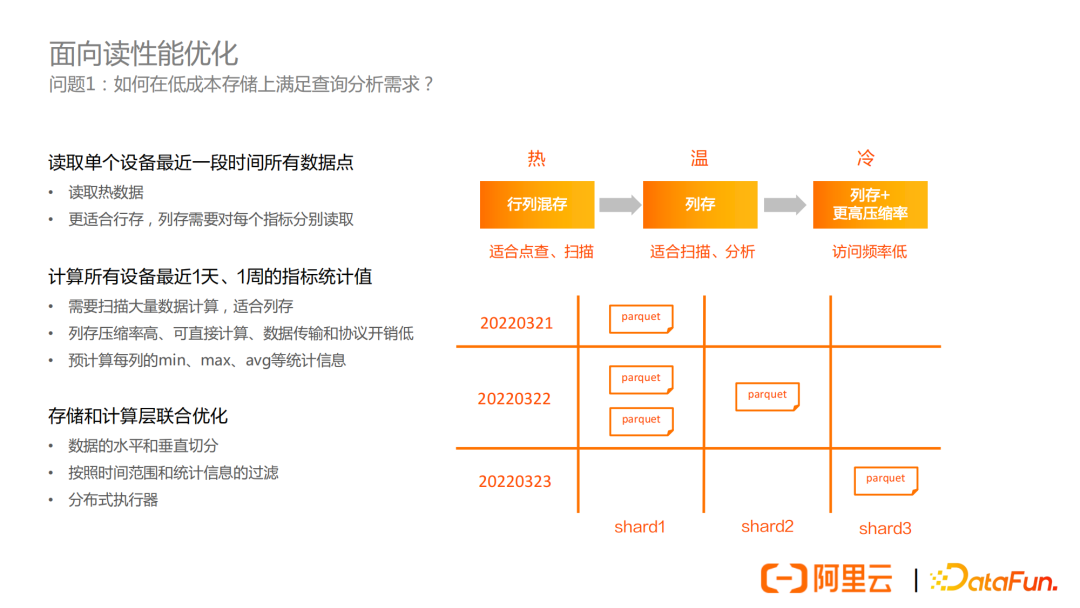
首先是分層,針對熱、溫、冷數據採用不同的存儲格式來進行優化。
- 對於熱數據,採用行列混存,這裡行列混存是結合了行存和列存優勢的一種存儲結構,在存儲空間上相比純列存會有一些冗餘。因為結合了行存和列存的優勢,因此既適合點查、小範圍掃描,也針對數據分析做了優化,同時也支持高併發的寫入和更新。
- 對於溫數據,採用純列存存儲,列存一方面壓縮率有優勢,另一方面也非常適合掃描和分析,可以很好的滿足對溫數據的分析需求。
- 對於冷數據,採用純列存,同時進行一些參數調整、使用更高壓縮率的演算法,降低存儲成本。
套用之前資料庫優化的理論,對於熱數據,採用的是空間換時間的方式,追求寫性能和讀性能;對於溫數據,面向存儲空間和讀性能優化;對於冷數據,面向存儲空間優化,但是會增加讀的開銷。
這樣的存儲架構,很好的滿足了對於查詢和分析的需求。
為了進一步優化性能,還需要存儲和計算層的聯合優化。這裡主要講以下幾個方面:
首先,數據可以進行水平切分和垂直切分。水平切分,指的是數據可以分為不同的shard,在不同的shard查詢時可以有一定的併發度,同時也可以靈活控制shard的大小。垂直切分是針對時間維度做分片。
基於這樣的切分,在查詢時,就可以根據時間範圍和一些文件級別的統計信息來過濾掉不需要掃描的數據文件。
另一方面,整個查詢需要一個分散式的執行器,從而提高查詢的併發度。
另外,也可以利用雲原生的能力,在需要進行大量數據分析需求之前,彈性地擴容一批機器,計算後再進行縮容。
總結一下,通過使用分層技術和採用不同存儲格式,既降低了存儲成本,同時也滿足了查詢和分析需求。另一方面,通過分散式的SQL執行能力,提升計算性能,通過雲原生的存計分離架構,可以彈性的擴容計算資源。
② 第二個問題,如何進行快速的元數據檢索
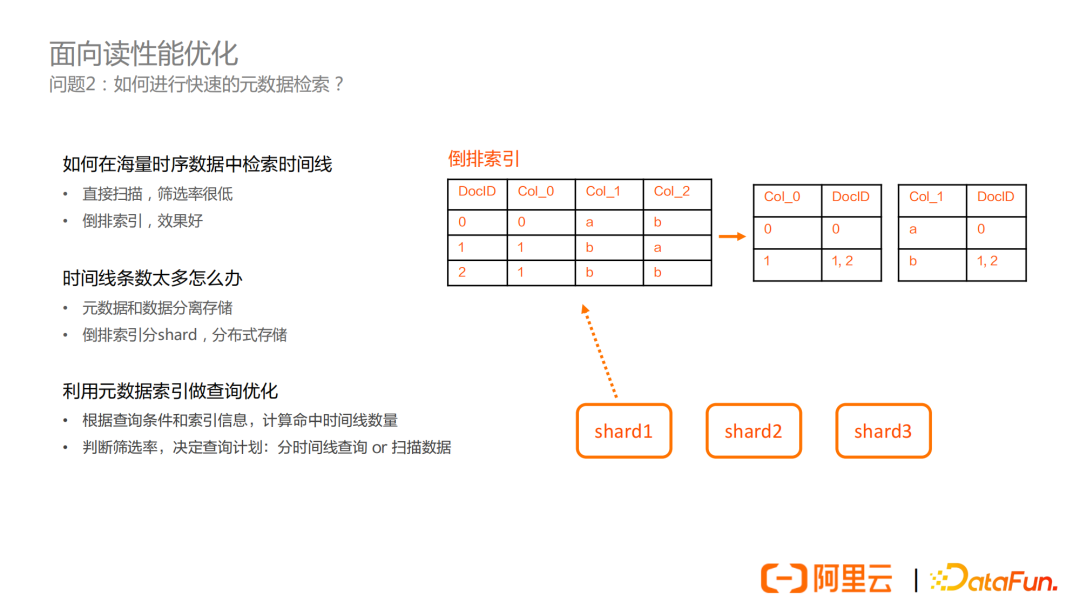
如何在海量的時序數據中檢索時間線?
第一個方案是直接在數據上進行掃描和過濾,但是由於元數據僅占數據的一小部分,所以直接掃描的篩選率很低,效果並不好。
第二個方案就是採用倒排索引,這也是很多時序資料庫都採用的方案。倒排索引的方案經常遇到的一個問題是規模問題,因為很多時序資料庫的倒排索引實現是一個單機版本,並且需要載入很多索引數據到記憶體中,因此只能支持較小規模的時間線。
為瞭解決規模問題,可以採用這樣的方案:
首先是元數據和數據分離存儲。
其次是要採用分散式的索引技術。具體來說,就是分shard來存儲索引部分,查詢時查詢多個shard的數據再進行合併。這樣總體時間線規模可以支撐到百億到千億的級別,這在物聯網場景下已經完全足夠了。
有了元數據索引之後,在數據查詢時也可以根據元數據索引進行查詢優化。
這部分主要涉及計算引擎的查詢優化器部分,查詢優化器可以根據查詢條件和索引信息,計算該查詢命中的時間線數量,結合其他的統計信息,就可以計算出一個篩選率。這個篩選率表示如果進行數據掃描,有多少比例數據是滿足時間線過濾條件的。根據這個篩選率可以決定查詢計劃是分時間線進行定位加小範圍掃描,還是直接掃描數據。
總結一下,為了滿足元數據檢索的需求,存儲引擎需要支持分散式倒排索引技術,同時計算引擎可以利用存儲引擎的索引信息做查詢優化,這部分查詢優化的前提是需要實現一個定製化的查詢優化器。
現在我們已經分析瞭如何優化存儲成本,如何優化查詢分析性能,如何優化元數據檢索性能。下麵我們總結一下這樣一個物聯網存儲產品的整體架構。
5. 整體架構
整體架構如下。

從訪問介面和模型方面,整個架構支持多數據模型訪問,包括時序、消息場景的定製模型,介面支持API、SDK介面,SQL、JDBC介面,以及數據訂閱介面。
從架構方面,需要採用存儲計算分離的架構,滿足彈性、高可靠、易擴展,支持數據分層存儲,以滿足低成本的需求。
從存儲引擎方面,需要支持多種存儲格式,內置不同存儲格式的轉換和生命周期管理,以平衡成本和性能的需求。另外,也要支持多元化的分散式索引技術,用於快速的數據檢索。
在SQL查詢引擎方面,需要定製查詢優化器,支持分散式執行,適應更多類型的查詢負載。
最後,也要選用一個合適的共用存儲底座。
--
04 總結
最後進行一下總結。

在前文中,首先介紹了物聯網場景下的幾類數據,包括元數據、消息、時序,時序是數據量最大的一類,架構設計部分也是以時序為例進行了場景分析。
其次,我們分析了物聯網場景對存儲產品的需求,我們也看到在很多場景下,存儲成本和分析能力是主要需求。
從場景和需求出發,我們進行了架構設計選型的分析,並且得到了一定的結論。在架構方面,要選擇雲原生、存計分離、分層存儲的架構。在存儲引擎方面,要選擇以列存為主,熱數據行列混存的存儲格式,同時支持元數據索引。在計算引擎方面,需要分散式的執行器和定製化的存儲計算聯合優化。同時,整個方案也需要充分利用雲的彈性和雲原生架構的優勢。
最終我們希望通過這樣的架構設計,在成本和性能方面相比傳統方案有著一個數量級的優化,同時做到功能上的一站式和一體化。這樣的架構優化也必然是一個持續的過程,最終持續助力物聯網的數據增長和更豐富的場景應用的出現。
本文首發於微信公眾號“DataFunTalk”。

