
高可用性(英語:high availability,縮寫為 HA) IT術語,指系統無中斷地執行其功能的能力,代表系統的可用性程度。是進行系統設計時的準則之一。 高可用性系統意味著系統服務可以更長時間運行,通常通過提高系統的容錯能力來實現。高可用性或者高可靠度的系統不會希望有單點故障造成整體故障的情 ...
高可用性(英語:high availability,縮寫為 HA)
IT術語,指系統無中斷地執行其功能的能力,代表系統的可用性程度。是進行系統設計時的準則之一。 高可用性系統意味著系統服務可以更長時間運行,通常通過提高系統的容錯能力來實現。高可用性或者高可靠度的系統不會希望有單點故障造成整體故障的情形。 一般可以透過冗餘的方式增加多個相同機能的部件,只要這些部件沒有同時失效,系統(或至少部分系統)仍可運作,這會讓可靠度提高。
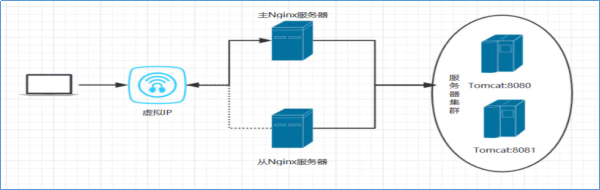
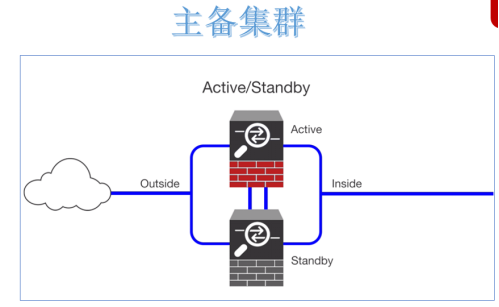
解決單點故障,實現系統服務高可用的核心並不是讓故障永不發生,而是讓故障的發生對業務的影響降到最小。因為軟硬體故障是難以避免的問題。 當下企業中成熟的做法就是給單點故障的位置設置備份,形成主備架構。通俗描述就是當主掛掉,備份頂上,短暫的中斷之後繼續提供服務。 常見的是一主一備架構,當然也可以一主多備。備份越多,容錯能力越強,與此同時,冗餘也越大,浪費資源。
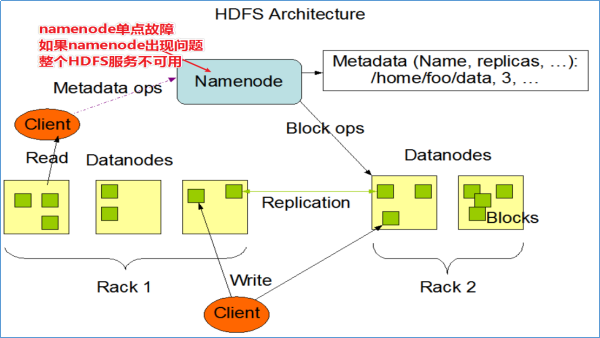
1-HDFS NAMENODE單點故障問題
在Hadoop 2.0.0之前,NameNode是HDFS集群中的單點故障(SPOF)。每個群集只有一個NameNode,如果該電腦或進程不可用,則整個群集在整個NameNode重新啟動或在另一臺電腦上啟動之前將不可用。
NameNode的單點故障從兩個方面影響了HDFS群集的總可用性:
- 如果發生意外事件(例如機器崩潰),則在重新啟動NameNode之前,群集將不可用。
- 計劃內的維護事件,例如NameNode電腦上的軟體或硬體升級,將導致群集停機時間的延長。
HDFS高可用性解決方案:在同一群集中運行兩個(從3.0.0起,超過兩個)冗餘NameNode。在機器崩潰的情況下快速故障轉移到新的NameNode,或者出於計劃維護的目的由管理員發起的正常故障轉移。
2-HDFS HA解決方案—QJM
QJM全稱Quorum Journal Manager,由cloudera公司提出,是Hadoop官方推薦的HDFS HA解決方案之一。
QJM中,使用zookeeper中ZKFC來實現主備切換;使用Journal Node(JN)集群實現edits log的共用以達到數據同步的目的。
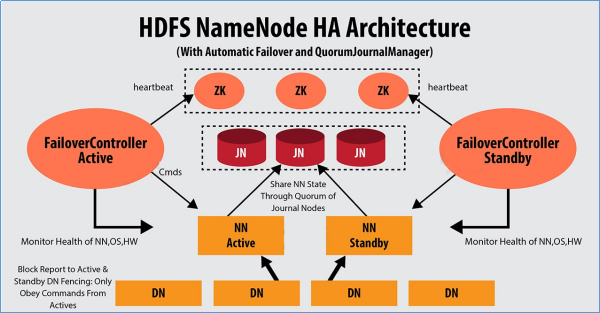
2.1-QJM—主備數據同步問題解決
Journal Node(JN)集群是輕量級分散式系統,主要用於高速讀寫數據、存儲數據。通常使用2N+1台JournalNode存儲共用Edits Log(編輯日誌)。

任何修改操作在 Active NN上執行時,JournalNode進程同時也會記錄edits log到至少半數以上的JN中,這時 Standby NN 監測到JN 裡面的同步log發生變化了會讀取JN裡面的edits log,然後重演操作記錄同步到自己的目錄鏡像樹裡面,
當發生故障Active NN掛掉後,Standby NN 會在它成為Active NN 前,讀取所有的JN裡面的修改日誌,這樣就能高可靠的保證與掛掉的NN的目錄鏡像樹一致,然後無縫的接替它的職責,維護來自客戶端請求,從而達到一個高可用的目的。
3-集群基礎環境準備
配置三台主機
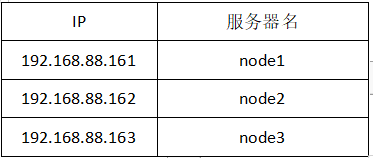
1.修改Linux主機名 /etc/hostname,修改和伺服器名稱對應,如node1配置。
vim /etc/hostname
node12.修改IP /etc/sysconfig/network-scripts/ifcfg-ens33
3.修改主機名和IP的映射關係 /etc/hosts
vim /etc/hosts
4.關閉防火牆參考文章(https://www.cnblogs.com/LaoPaoEr/p/16273501.html)
5.SSH免密登錄/集群時間同步參考文章(https://www.cnblogs.com/LaoPaoEr/p/16273456.html)
6.安裝java的JDK,配置環境變數等 /etc/profile(請自行百度)。
7.Zookeeper的集群環境搭建(自行百度)。
3.1-Ha集群規劃

在三台主機上分別創建目錄:
mkdir -p /opt/export/server/
mkdir -p /opt/export/data/
mkdir -p /opt/export/software/
3.2-上傳解壓Hadoop安裝包
自行複製鏈接下載:http://archive.apache.org/dist/hadoop/core/hadoop-3.1.4/hadoop-3.1.4.tar.gz
解壓命令:
cd /opt/export/software
tar -zxvf hadoop-3.1.4-bin-snappy-CentOS7.tar.gz -C /opt/export/server/3.3-在三台主機配置Hadoop環境變數
vim /etc/profile
#adoop高可用的節點配置文件
export HADOOP_HOME=/opt/export/server/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 
node1配置profile完成後分發配置給node2,node3
cd /etc
scp -r /etc/profile root@node2:$PWD
scp -r /etc/profile root@node3:$PWD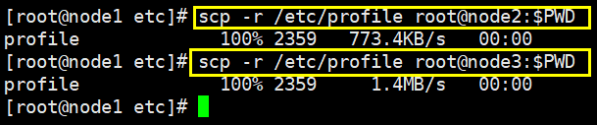
三台配置完之後一定要:
source /etc/profile3.4-修改Hadoop配置文件
cd /opt/export/server/hadoop-3.1.4/etc/hadoop
vim hadoop-env.sh增加配置:
JAVA_HOME=/export/server/jdk1.8.0_60 這裡配置自己伺服器java的JDK的版本
export JAVA_HOME=/export/server/jdk1.8.0_60
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root在node1上創建數據存放目錄,JournalNode數據的存放目錄:
mkdir -p /opt/export/server/hadoop-3.1.4/data
mkdir -p /opt/export/server/hadoop-3.1.4/qj_data編輯core-site.xml
cd /opt/export/server/hadoop-3.1.4/etc/hadoop
vim core-site.xml在<configuration></configuration>之間添加配置
<!-- HA集群名稱,該值要和hdfs-site.xml中的配置保持一致 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- hadoop本地磁碟存放數據的公共目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/export/server/hadoop-3.1.4/data</value>
</property>
<!-- ZooKeeper集群的地址和埠-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
編輯hdfs-site.xml
cd /opt/export/server/hadoop-3.1.4/etc/hadoop
vim hdfs-site.xml在<configuration></configuration>之間添加配置
<!--指定hdfs的nameservice為mycluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下麵有兩個NameNode,分別是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:9870</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:9870</value>
</property>
<!-- 指定NameNode的edits元數據在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁碟存放數據的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/export/server/hadoop-3.1.4/qj_data</value>
</property>
<!-- 開啟NameNode失敗自動切換 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定該集群出故障時,哪個實現類負責執行故障切換 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔離機制方法-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔離機制時需要ssh免登陸 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔離機制超時時間 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>編輯workers
cd /opt/export/server/hadoop-3.1.4/etc/hadoop
vim workers
#配置工作主機
node1
node2
node33.5-集群同步安裝包
在node2和node3伺服器上創建目錄 /opt/export/server
ssh node2
mkdir -p /opt/export/server
ssh node3
mkdir -p /opt/export/server分發到node2和node3,使用scp前需要提前配好免密登錄。
cd /opt/export/server
scp -r hadoop-3.1.4 root@node2:$PWD
scp -r hadoop-3.1.4 root@node3:$PWD4-HA集群初始化
4.1-啟動zk集群
這一步需要存在ZK集群。配置好ZK集群的環境變數。
zkServer.sh start
zkServer.sh status4.2-手動啟動JN集群
在三台主機(node1\node2\node3)上都要執行:
hdfs --daemon start journalnode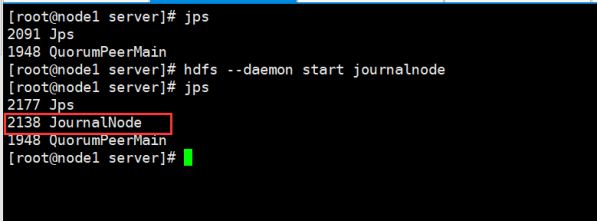
4.3-格式化Format namenode
在node1執行格式化namenode:
在node1啟動namenode進程:
hdfs namenode -format
hdfs --daemon start namenode在node2上進行namenode元數據同步
hdfs namenode -bootstrapStandby4.4-格式化zkfc
註意:在哪台機器上執行,哪台機器就將成為第一次的Active NN
hdfs zkfc -formatZK5- HA集群啟動
在node1上啟動HDFS集群
start-dfs.sh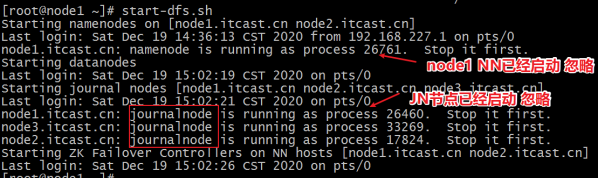
網頁訪問
node1:9870
node2:9870
選擇菜單Overview ,可以看到Node1已經啟動成功。
Overview 'node1:8020' (active)代表是主節點

Overview 'node2:8020' (standby)代表從節點

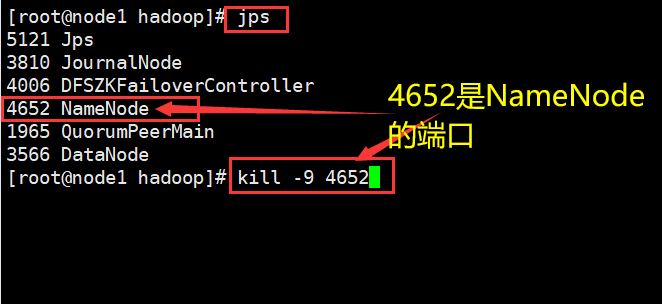
通過kill殺死node1的NameNode。重新刷新node1和node2網頁 可以查看node2以切換為主節點。
本篇遺憾是還未搭建Yarn調度集群。只是簡單搭建了HDFS的集群,具體Yarn搭建後,後期更新進入文章內。


