
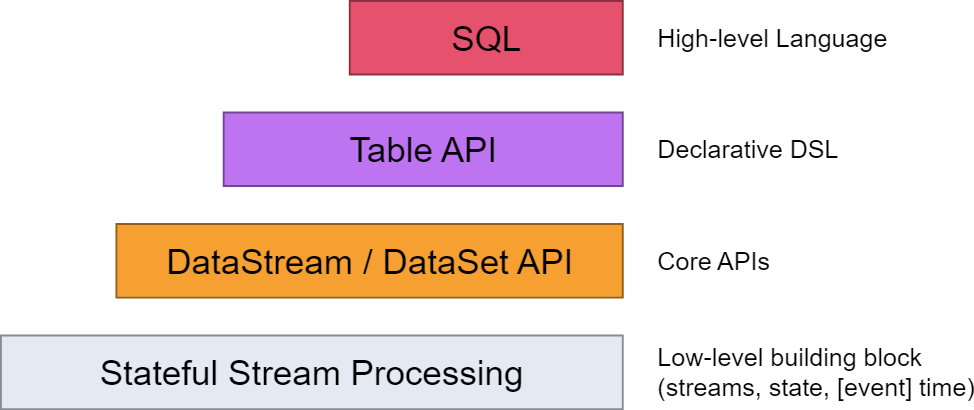
一、Table API 和 Flink SQL 是什麼 Table API 和 SQL 集成在同一套 API 中。 這套 API 的核心概念是Table,用作查詢的輸入和輸出,這套 API 都是批處理和流處理統一的上層 API,這意味著在無邊界的實時數據流和有邊界的歷史記錄數據流上,關係型 API ...
目錄
- 一、Table API 和 Flink SQL 是什麼
- 二、配置Table依賴(scala)
- 三、兩種 planner(old & blink)的區別
- 四、Catalogs
- 五、SQL 客戶端
- 六、表執行環境與表介紹
- 七、Table API
- 八、SQL
- 九、Table & SQL Connectors
一、Table API 和 Flink SQL 是什麼
Table API 和 SQL 集成在同一套 API 中。 這套 API 的核心概念是Table,用作查詢的輸入和輸出,這套 API 都是批處理和流處理統一的上層 API,這意味著在無邊界的實時數據流和有邊界的歷史記錄數據流上,關係型 API 會以相同的語義執行查詢,並產生相同的結果。Table API 和 SQL藉助了 Apache Calcite 來進行查詢的解析,校驗以及優化。它們可以與 DataStream 和DataSet API 無縫集成,並支持用戶自定義的標量函數,聚合函數以及表值函數。
Flink官方下載:https://flink.apache.org/downloads.html
官方文檔(最新版本):https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/common/
官方文檔(當前最新穩定版1.14.3):https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/common/
maven地址:
二、配置Table依賴(scala)
首先先配置flink基礎依賴
【問題提示】官方使用的2.11版本,但是我這裡使用的2.12版本。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>1.14.3</version>
</dependency>
除此之外,如果你想在 IDE 本地運行你的程式,你需要添加下麵的模塊,具體用哪個取決於你使用哪個 Planner:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.14.3</version>
</dependency>
添加擴展依賴(可選)
如果你想實現自定義格式或連接器 用於(反)序列化行或一組用戶定義的函數,下麵的依賴就足夠了,編譯出來的 jar 文件可以直接給 SQL Client 使用:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.14.3</version>
</dependency>
【溫馨提示】如果需要本地直接運行,得先把scope先註釋掉,要不然會報如下錯誤:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/table/api/bridge/scala/StreamTableEnvironment$
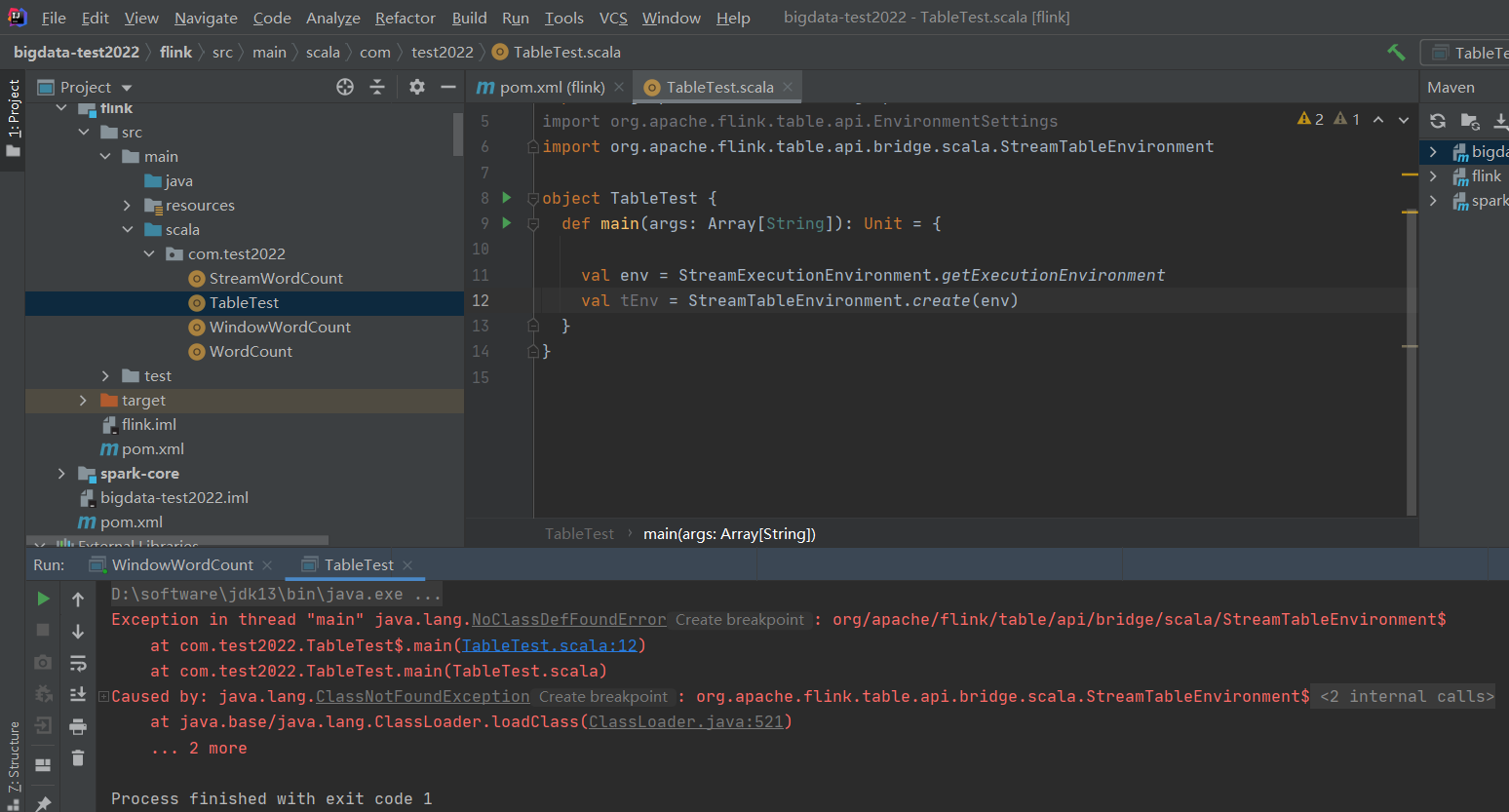
- flink-table-planner:planner 計劃器,是 table API 最主要的部分,提供了運行時環境和生
成程式執行計劃的 planner; - flink-table-api-scala-bridge:bridge 橋接器,主要負責 table API 和 DataStream/DataSet API
的連接支持,按照語言分 java 和 scala。 - flink-table-common:當然,如果想使用用戶自定義函數,或是跟 kafka 做連接,需要有一個 SQL client,這個包含在 flink-table-common 里。
【溫馨提示】這裡的flink-table-planner和flink-table-api-scala-bridge兩個依賴,是 IDE 環境下運行需要添加的;如果是生產環境,lib 目錄下預設已經有了 planner,就只需要有 bridge 就可以了。
三、兩種 planner(old & blink)的區別
- 批流統一:Blink 將批處理作業,視為流式處理的特殊情況。所以,blink 不支持表和
DataSet 之間的轉換,批處理作業將不轉換為 DataSet 應用程式,而是跟流處理一樣,轉換
為 DataStream 程式來處理。因 為 批 流 統 一 , Blink planner 也 不 支 持 BatchTableSource , 而 使 用 有 界 的StreamTableSource 代替。 - Blink planner 只支持全新的目錄,不支持已棄用的 ExternalCatalog。
- 舊 planner 和 Blink planner 的 FilterableTableSource 實現不相容。舊的 planner 會把
PlannerExpressions 下推到 filterableTableSource 中,而 blink planner 則會把 Expressions 下推。 - 基於字元串的鍵值配置選項僅適用於 Blink planner。
- PlannerConfig 在兩個 planner 中的實現不同。
- Blink planner 會將多個 sink 優化在一個 DAG 中(僅在 TableEnvironment 上受支持,而
在 StreamTableEnvironment 上不受支持)。而舊 planner 的優化總是將每一個 sink 放在一個新
的 DAG 中,其中所有 DAG 彼此獨立。 - 舊的 planner 不支持目錄統計,而 Blink planner 支持。
四、Catalogs
官方文檔:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/catalogs/
1)Catalog概述
-
Catalog 提供了元數據信息,例如資料庫、表、分區、視圖以及資料庫或其他外部系統中存儲的函數和信息。
-
數據處理最關鍵的方面之一是管理元數據。 元數據可以是臨時的,例如臨時表、或者通過 TableEnvironment 註冊的 UDF。 元數據也可以是持久化的,例如 Hive Metastore 中的元數據。Catalog 提供了一個統一的API,用於管理元數據,並使其可以從 Table API 和 SQL 查詢語句中來訪問。
2)Catalog 類型
- GenericInMemoryCatalog:GenericInMemoryCatalog 是基於記憶體實現的 Catalog,所有元數據只在 session 的生命周期內可用。
- JdbcCatalog:JdbcCatalog 使得用戶可以將 Flink 通過 JDBC 協議連接到關係資料庫。Postgres Catalog 和 MySQL Catalog 是目前 JDBC Catalog 僅有的兩種實現。 參考 JdbcCatalog 文檔 獲取關於配置 JDBC catalog 的詳細信息。
- HiveCatalog:HiveCatalog 有兩個用途:作為原生 Flink 元數據的持久化存儲,以及作為讀寫現有 Hive 元數據的介面。 Flink 的 Hive 文檔 提供了有關設置 HiveCatalog 以及訪問現有 Hive 元數據的詳細信息。
【溫馨提示】Hive Metastore 以小寫形式存儲所有元數據對象名稱。而 GenericInMemoryCatalog 區分大小寫。
- 用戶自定義 Catalog:Catalog 是可擴展的,用戶可以通過實現 Catalog 介面來開發自定義 Catalog。 想要在 SQL CLI 中使用自定義 Catalog,用戶除了需要實現自定義的 Catalog 之外,還需要為這個 Catalog 實現對應的 CatalogFactory 介面。CatalogFactory 定義了一組屬性,用於 SQL CLI 啟動時配置 Catalog。 這組屬性集將傳遞給發現服務,在該服務中,服務會嘗試將屬性關聯到 CatalogFactory 並初始化相應的 Catalog 實例。
3)如何創建 Flink 表並將其註冊到 Catalog
1、下載flink-sql-connector-hive相關版本jar包,放在$FLINK_HOME/lib目錄下
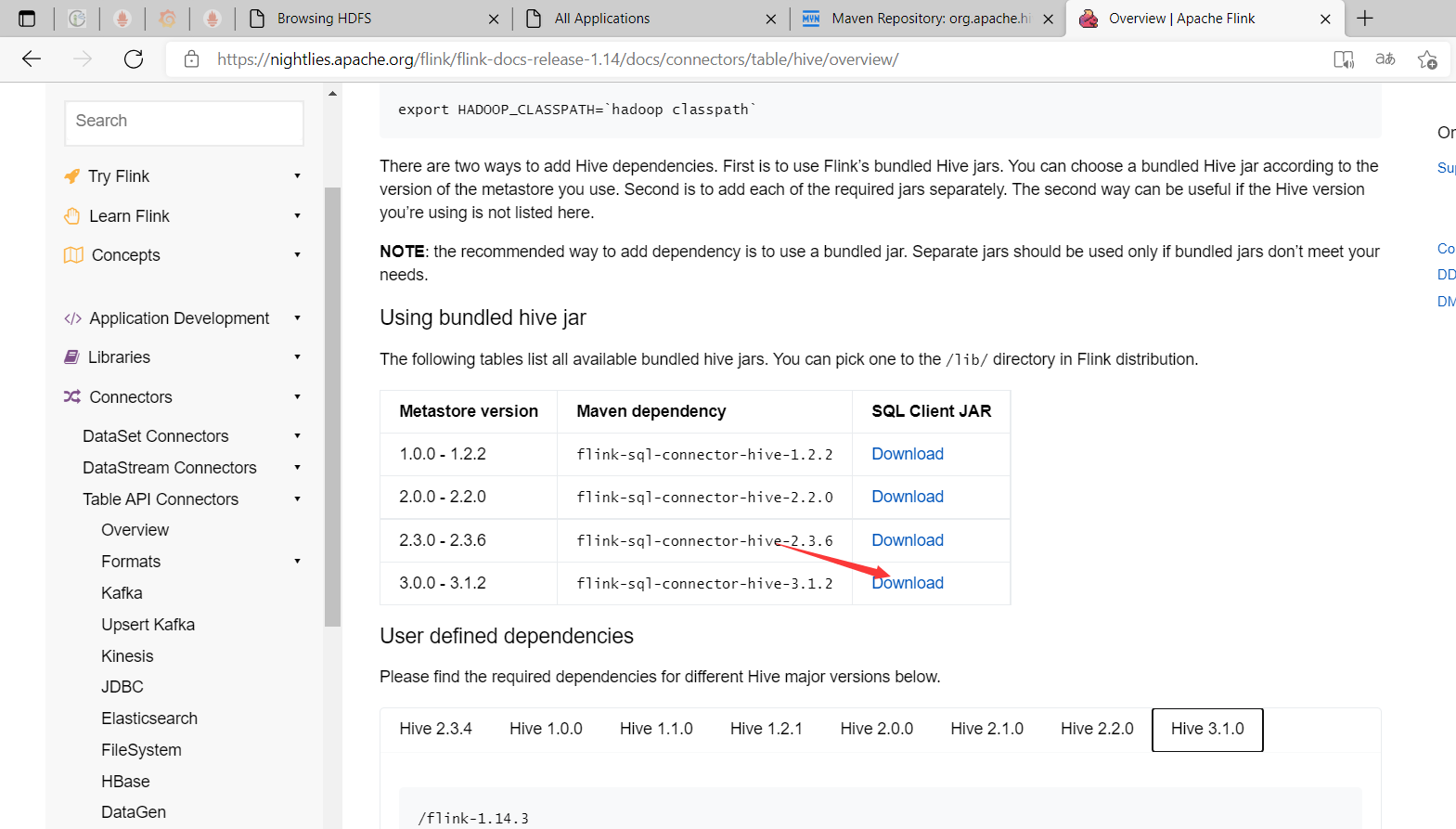
# 登錄安裝flink的機器
$ cd /opt/bigdata/hadoop/server/flink-1.14.3/lib
$ wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.11/1.14.3/flink-sql-connector-hive-3.1.2_2.11-1.14.3.jar
2、添加Maven 依賴
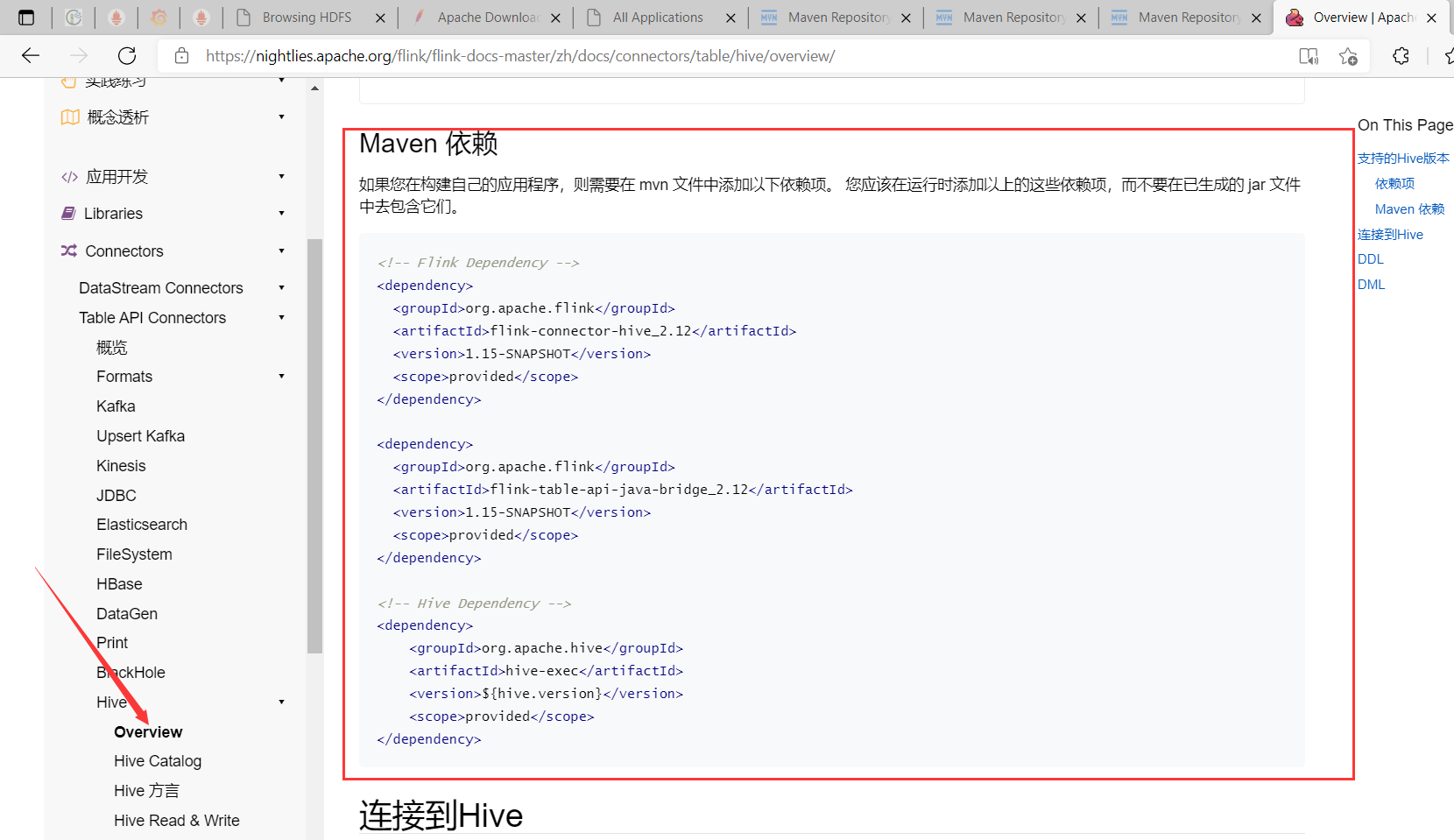
如果您在構建自己的應用程式,則需要在 mvn 文件中添加以下依賴項。 您應該在運行時添加以上的這些依賴項,而不要在已生成的 jar 文件中去包含它們。官方文檔
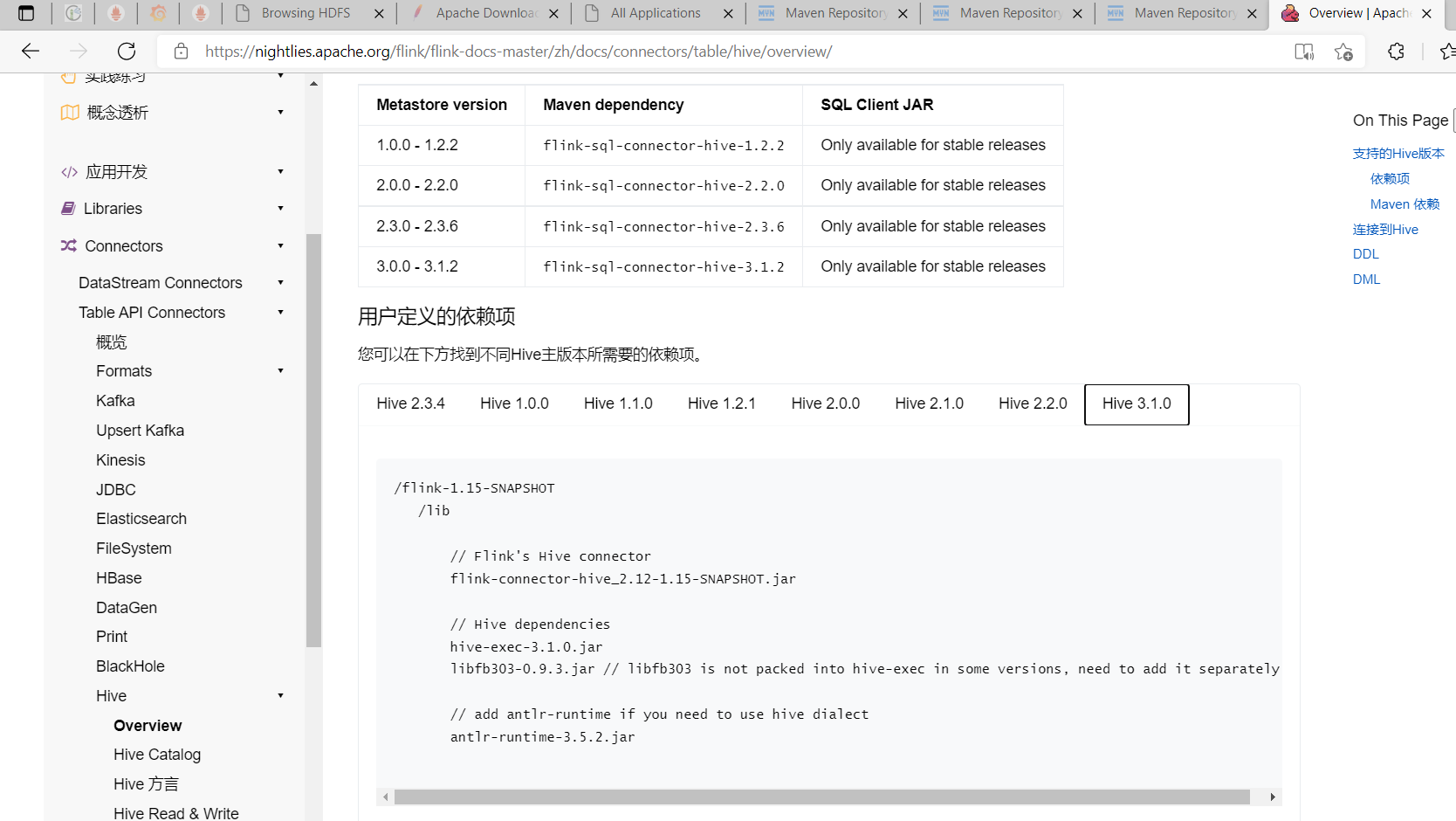
hive 版本
$ hive --version


Maven依賴配置如下(這裡不使用最新版,使用1.14.3):
使用新版,一般也不建議使用最新版,會有如下報錯:
Cannot resolve org.apache.flink:flink-table-api-java-bridge_2.12:1.15-SNAPSHOT

<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
還需要添加如下依賴,要不然會報如下錯誤:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/mapred/JobConf
version欄位是hadoop版本,查看hadoop版本(hadoop version)

<!--hadoop start-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
</dependency>
<!--hadoop end-->
2、使用 SQL DDL
用戶可以使用 DDL 通過 Table API 或者 SQL Client 在 Catalog 中創建表。
// 創建tableEnv
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
val settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
//.inBatchMode()
.build()
val tableEnv = TableEnvironment.create(settings)
// Create a HiveCatalog
val catalog = new HiveCatalog("myhive", null, "<path_of_hive_conf>");
// Register the catalog
tableEnv.registerCatalog("myhive", catalog);
// Create a catalog database
tableEnv.executeSql("CREATE DATABASE mydb WITH (...)");
// Create a catalog table
tableEnv.executeSql("CREATE TABLE mytable (name STRING, age INT) WITH (...)");
tableEnv.listTables(); // should return the tables in current catalog and database.
用戶可以用編程的方式使用Java 或者 Scala 來創建 Catalog 表。
import org.apache.flink.table.api._
import org.apache.flink.table.catalog._
import org.apache.flink.table.catalog.hive.HiveCatalog
val tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode())
// Create a HiveCatalog
val catalog = new HiveCatalog("myhive", null, "<path_of_hive_conf>")
// Register the catalog
tableEnv.registerCatalog("myhive", catalog)
// Create a catalog database
catalog.createDatabase("mydb", new CatalogDatabaseImpl(...))
// Create a catalog table
val schema = Schema.newBuilder()
.column("name", DataTypes.STRING())
.column("age", DataTypes.INT())
.build()
tableEnv.createTable("myhive.mydb.mytable", TableDescriptor.forConnector("kafka")
.schema(schema)
// …
.build())
val tables = catalog.listTables("mydb") // tables should contain "mytable"
五、SQL 客戶端
官方文檔:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/sqlclient/
1)啟動 SQL 客戶端命令行界面
SQL Client 腳本也位於 Flink 的 bin 目錄中。將來,用戶可以通過啟動嵌入式 standalone 進程或通過連接到遠程 SQL 客戶端網關來啟動 SQL 客戶端命令行界面。目前僅支持 embedded,模式預設值embedded。可以通過以下方式啟動 CLI:
$ cd $FLINK_HOME
$ ./bin/sql-client.sh
或者顯式使用 embedded 模式:
$ ./bin/sql-client.sh embedded
幫助文檔
Flink SQL> HELP;
2)執行 SQL 查詢
這裡主要講兩種模式standalone模式和yarn模式,部署環境,可以參考我之前的文章:大數據Hadoop之——實時計算流計算引擎Flink(Flink環境部署)
1、standalone模式(預設)
# 先啟動集群
$ cd $FLINK_HOME
$ ./bin/start-cluster.sh
# 啟動客戶端
$ ./bin/sql-client.sh
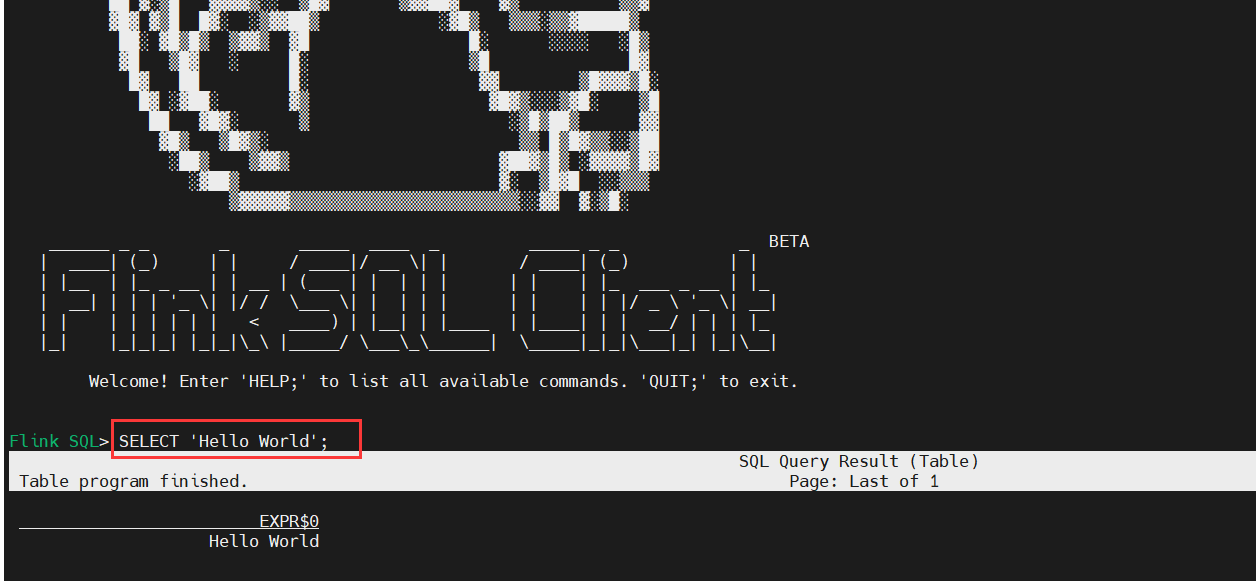
# SQL查詢
SELECT 'Hello World';
2、yarn-session模式(常駐集群)
【溫馨提示】yarn-session模式其實就是在yarn上生成一個standalone集群
$ cd $FLINK_HOME
$ bin/yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm flink-test -d
### 參數解釋:
# -s 每個TaskManager 的slots 數量
# -jm 1024 表示jobmanager 1024M記憶體
# -tm 1024表示taskmanager 1024M記憶體
#-d 任務後臺運行
### 如果你不希望flink yarn client一直運行,也可以啟動一個後臺運行的yarn session。使用這個參數:-d 或者 --detached。在這種情況下,flink yarn client將會只提交任務到集群然後關閉自己。註意:在這種情況下,無法使用flink停止yarn session,必須使用yarn工具來停止yarn session。
# yarn application -kill $applicationId
#-nm,--name YARN上為一個自定義的應用設置一個名字

3、啟動sql-client on yarn-session(測試驗證)
$ cd $FLINK_HOME
# 先把flink集群停掉
$ ./bin/stop-cluster.sh
# 再啟動sql客戶端
$ bin/sql-client.sh embedded -s yarn-session
# SQL查詢
SELECT 'Hello World';
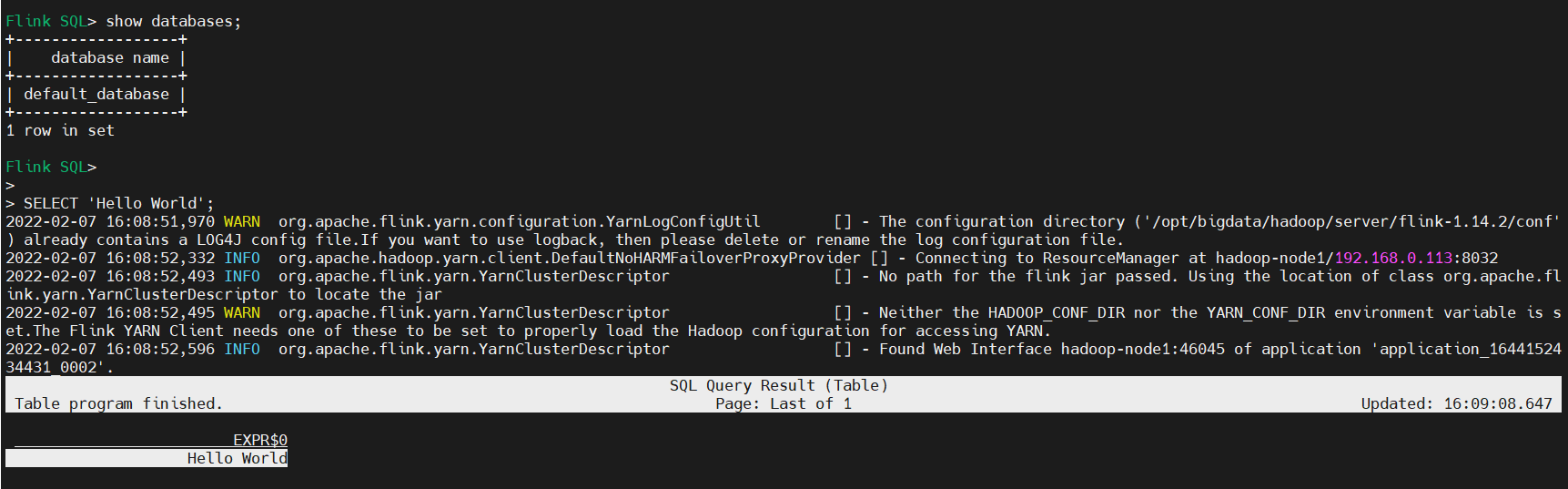
3)CLI 為維護和可視化結果提供三種模式
- 表格模式(table mode)在記憶體中實體化結果,並將結果用規則的分頁表格可視化展示出來。執行如下命令啟用(預設模式):
SET 'sql-client.execution.result-mode' = 'table';
- 變更日誌模式(changelog mode)不會實體化和可視化結果,而是由插入(+)和撤銷(-)組成的持續查詢產生結果流。執行如下命令啟用:
SET 'sql-client.execution.result-mode' = 'changelog';
- Tableau模式(tableau mode)更接近傳統的資料庫,會將執行的結果以製表的形式直接打在屏幕之上。具體顯示的內容會取決於作業 執行模式的不同(execution.type):
SET 'sql-client.execution.result-mode' = 'tableau';
你可以用如下查詢來查看三種結果模式的運行情況:
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
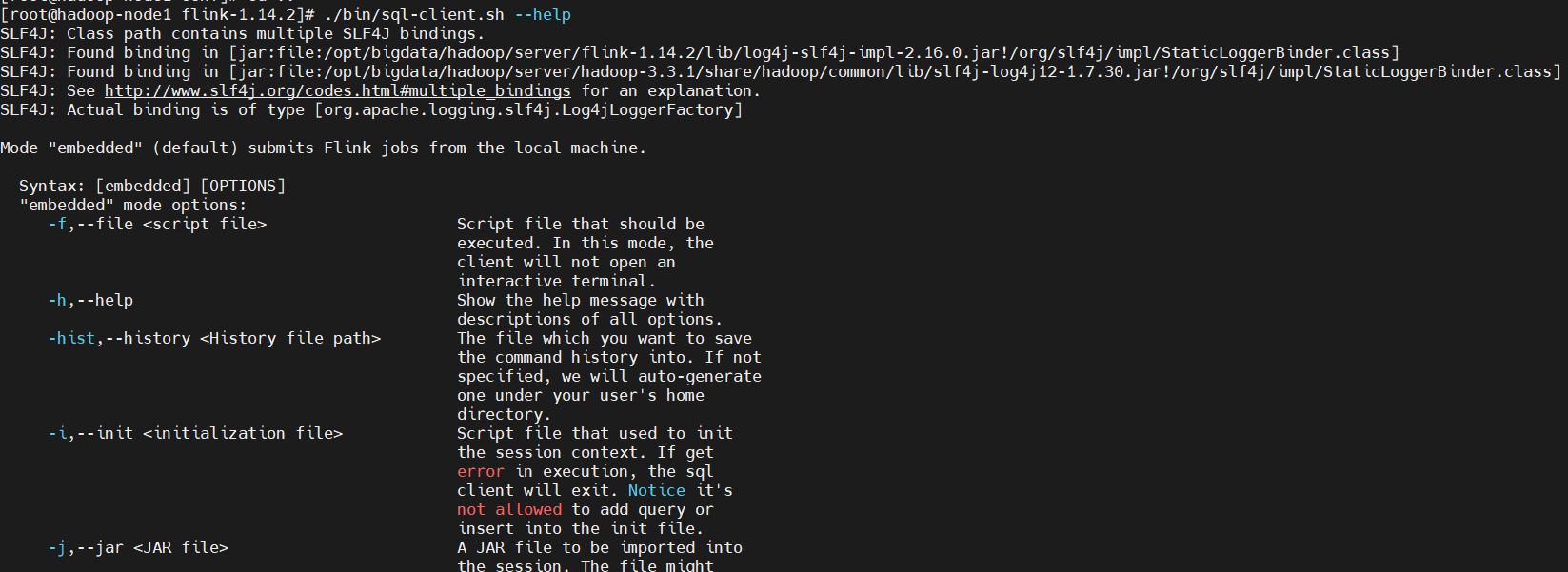
4)查看幫助
$ ./bin/sql-client.sh --help
SQL CLI已經演示了,這裡再演示一下-f接文件的操作。
$ cat>test.sql<<EOF
show databases;
show tables;
EOF
執行
$ bin/sql-client.sh embedded -s yarn-session -f test.sql
5)flink1.14.3中集成hive3.1.2(HiveCatalog )
HiveCatalog 有兩個用途:作為原生 Flink 元數據的持久化存儲,以及作為讀寫現有 Hive 元數據的介面。 Flink 的 Hive 文檔 提供了有關設置 HiveCatalog 以及訪問現有 Hive 元數據的詳細信息。
1、使用 Flink 提供的 Hive jar
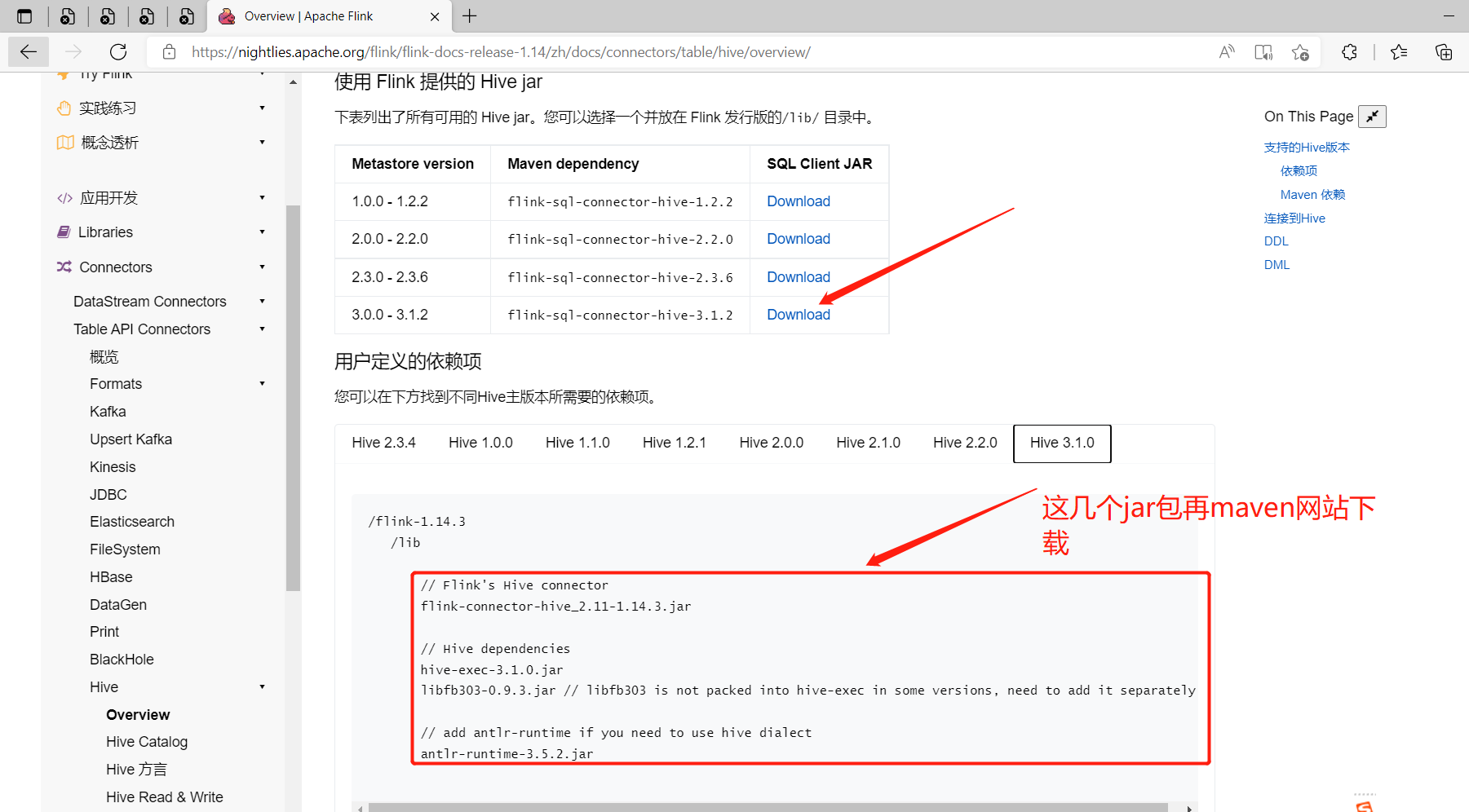
$ cd $FLINK_HOME/lib
$ wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.11/1.14.3/flink-sql-connector-hive-3.1.2_2.11-1.14.3.jar
# maven網站上下載地址
$ wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.12/1.14.3/flink-connector-hive_2.12-1.14.3.jar
$ wget https://repo1.maven.org/maven2/org/apache/hive/hive-exec/3.1.2/hive-exec-3.1.2.jar
$ wget https://search.maven.org/remotecontent?filepath=org/apache/thrift/libfb303/0.9.3/libfb303-0.9.3.jar
$ wget https://repo1.maven.org/maven2/org/antlr/antlr-runtime/3.5.2/antlr-runtime-3.5.2.jar
2、配置hive-site.xml並啟動metastore服務和hiveserver2服務
【溫馨提示】清楚hive metastore服務和hiveserver2服務,可以參考我之前的文章:大數據Hadoop之——數據倉庫Hive
hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 所連接的 MySQL 資料庫的地址,hive_remote2是資料庫,程式會自動創建,自定義就行 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop-node1:3306/hive_remote2?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value>
</property>
<!-- MySQL 驅動 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>MySQL JDBC driver class</description>
</property>
<!-- mysql連接用戶 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>user name for connecting to mysql server</description>
</property>
<!-- mysql連接密碼 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password for connecting to mysql server</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-node1:9083</value>
<description>IP address (or fully-qualified domain name) and port of the metastore host</description>
</property>
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop-node1</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2埠 預設是1000,為了區別,我這裡不使用預設埠-->
<property>
<name>hive.server2.thrift.port</name>
<value>11000</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
</configuration>
啟動服務
$ cd $HIVE_HOME
# hive metastore 服務
$ nohup ./bin/hive --service metastore &
# hiveserver2服務
$ nohup ./bin/hiveserver2 > /dev/null 2>&1 &
# 檢查埠
$ ss -atnlp|grep 9083
$ ss -tanlp|grep 11000

3、啟動flink集群(on yarn)
$ cd $FLINK_HOME
$ bin/yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm flink-test -d
3、配置flink sql
在flink1.14+中已經移除sql-client-defaults.yml配置文件了。參考地址:https://issues.apache.org/jira/browse/FLINK-21454
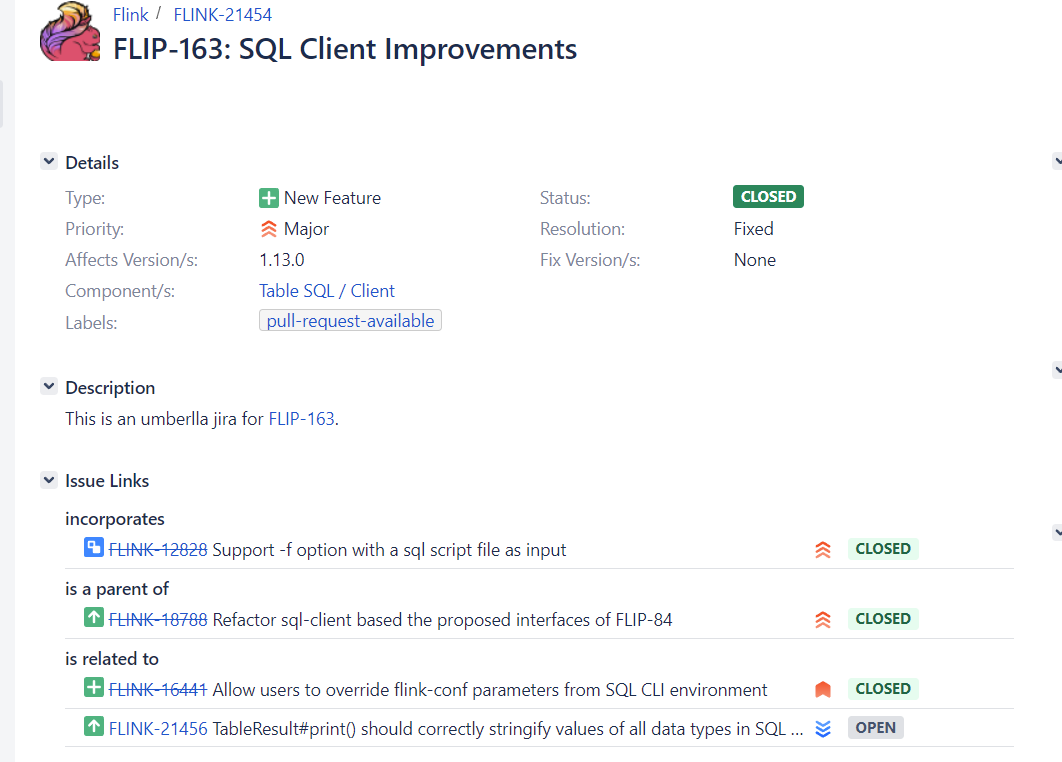
於是我順著這個issue找到了FLIP-163這個鏈接:https://cwiki.apache.org/confluence/display/FLINK/FLIP-163%3A+SQL+Client+Improvements
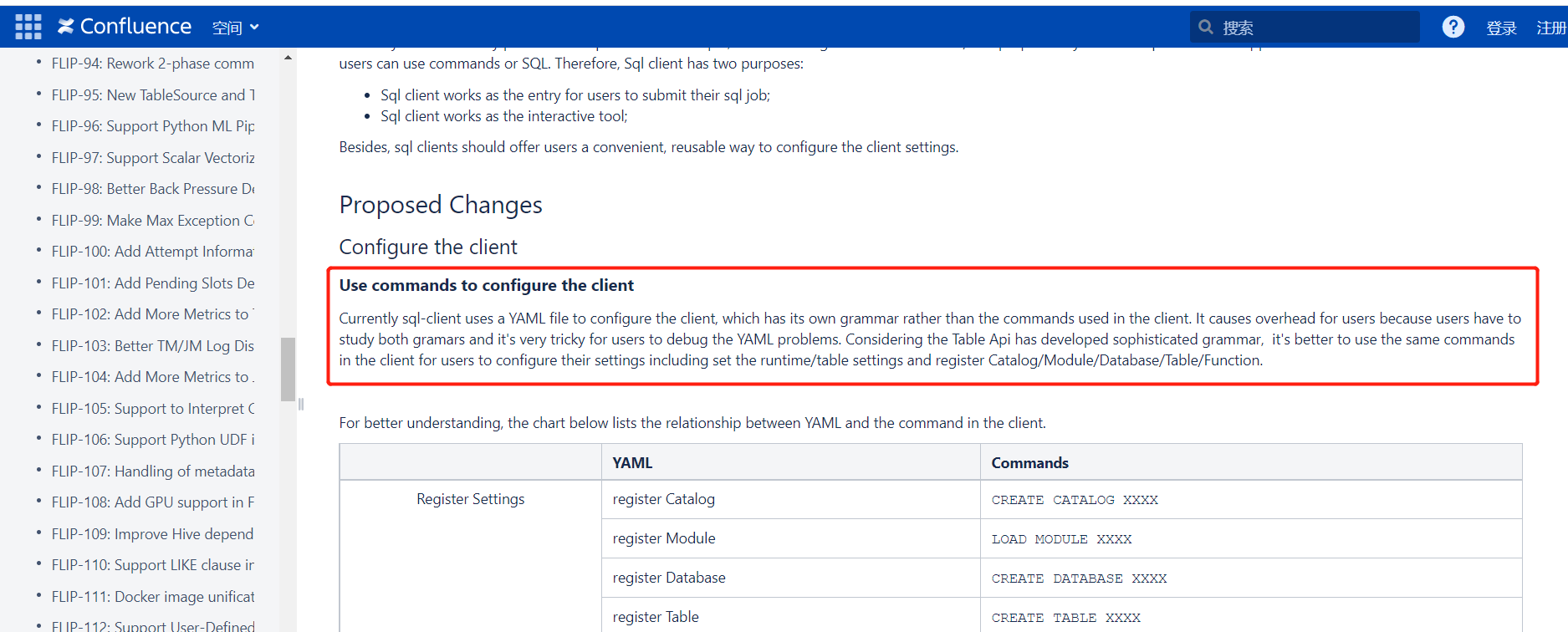
也就是目前這個sql客戶端還有很多bug,並且使用yaml文件和本身的命令語法會導致用戶學習成本增加,所以在未來會放棄使用這個配置項,可以通過命令行模式來配置。
$ cd $FLINK_HOME
$ bin/sql-client.sh embedded -s yarn-session
# 顯示所有catalog,databases
show catalogs;
show databases;
創建hive catalog
CREATE CATALOG myhive WITH (
'type' = 'hive',
'hive-conf-dir' = '/opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf/'
);
# 切換到myhive
use catalog myhive;
# 查看資料庫
show databases;
# 使用 Hive 方言(Flink 目前支持兩種 SQL 方言: default 和 hive)
登錄hive客戶端進行驗證
$ cd $HIVE_HOME
$ ./bin/beeline
!connect jdbc:hive2://hadoop-node1:11000
show databases;
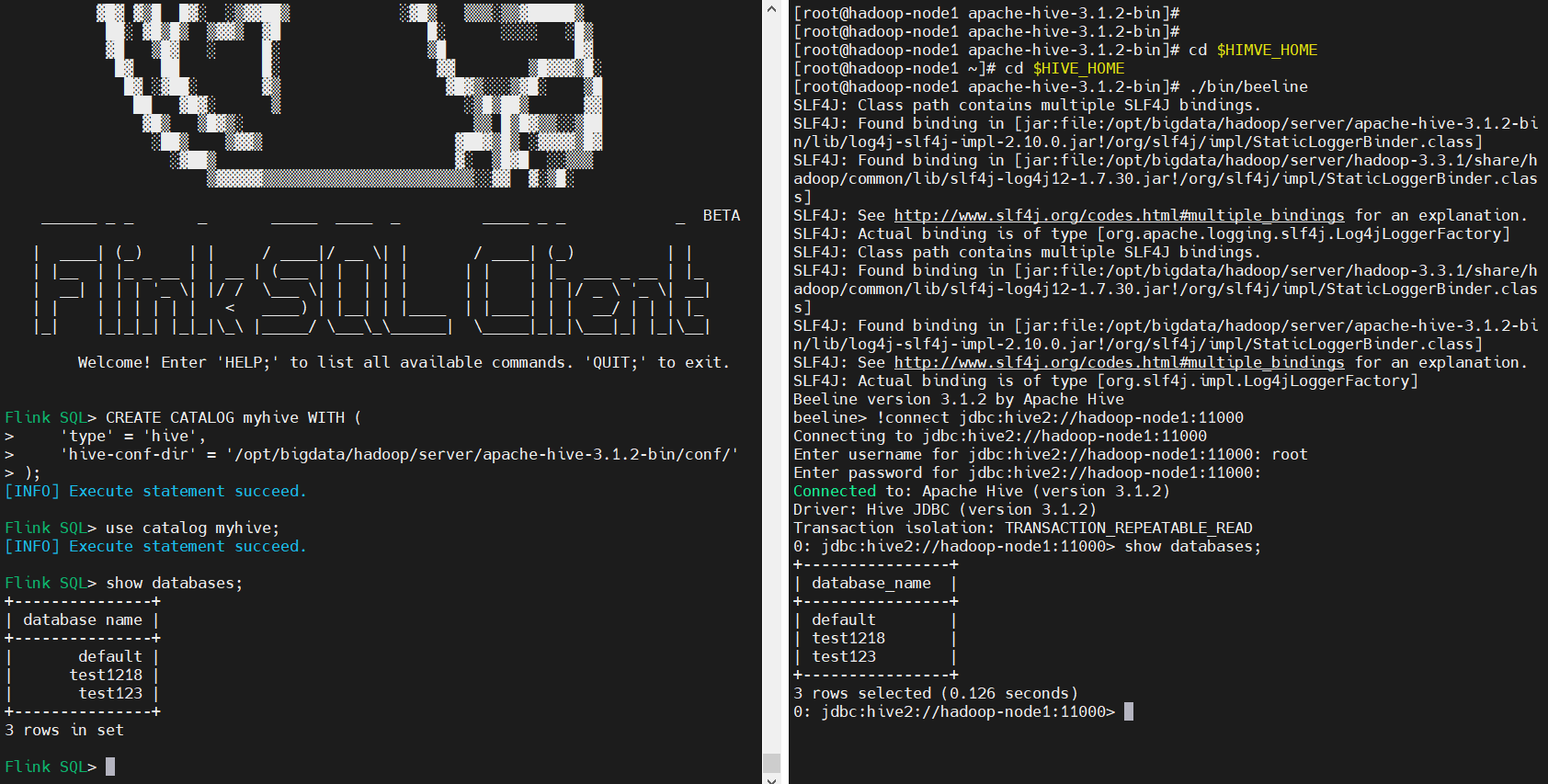
六、表執行環境與表介紹
1)創建表的執行環境(TableEnvironment)
TableEnvironment 是 Table API 和 SQL 的核心概念。它負責:
- 在內部的 catalog 中註冊 Table
- 註冊外部的 catalog
- 載入可插拔模塊
- 執行 SQL 查詢
- 註冊自定義函數 (scalar、table 或 aggregation)
- DataStream 和 Table 之間的轉換(面向 StreamTableEnvironment )
Table 總是與特定的 TableEnvironment 綁定。 不能在同一條查詢中使用不同 TableEnvironment 中的表,例如,對它們進行 join 或 union 操作。 TableEnvironment 可以通過靜態方法 TableEnvironment.create() 創建。
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
val settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
//.inBatchMode()
.build()
val tEnv = TableEnvironment.create(settings)
或者,用戶可以從現有的 StreamExecutionEnvironment 創建一個 StreamTableEnvironment 與 DataStream API 互操作。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = StreamTableEnvironment.create(env)
2)在 Catalog 中註冊表
1、表(Table)的概念
- TableEnvironment 可以註冊目錄 Catalog,並可以基於 Catalog 註冊表。它會維護一個
Catalog-Table 表之間的 map。 - 表(Table)是由一個“標識符”來指定的,由 3 部分組成:Catalog 名、資料庫(database)
名和對象名(表名)。如果沒有指定目錄或資料庫,就使用當前的預設值。 - 表可以是常規的(Table,表),或者虛擬的(View,視圖)。常規表(Table)一般可以
用來描述外部數據,比如文件、資料庫表或消息隊列的數據,也可以直接從 DataStream 轉
換而來。視圖可以從現有的表中創建,通常是 table API 或者 SQL 查詢的一個結果。
2、臨時表(Temporary Table)和永久表(Permanent Table)
-
表可以是臨時的,並與單個 Flink 會話(session)的生命周期相關,也可以是永久的,並且在多個 Flink 會話和群集(cluster)中可見。
-
永久表需要 catalog(例如 Hive Metastore)以維護表的元數據。一旦永久表被創建,它將對任何連接到 catalog 的 Flink 會話可見且持續存在,直至被明確刪除。
-
另一方面,臨時表通常保存於記憶體中並且僅在創建它們的 Flink 會話持續期間存在。這些表對於其它會話是不可見的。它們不與任何 catalog 或者資料庫綁定但可以在一個命名空間(namespace)中創建。即使它們對應的資料庫被刪除,臨時表也不會被刪除。
3、屏蔽(Shadowing)
可以使用與已存在的永久表相同的標識符去註冊臨時表。臨時表會屏蔽永久表,並且只要臨時表存在,永久表就無法訪問。所有使用該標識符的查詢都將作用於臨時表。
七、Table API
Table API 是批處理和流處理的統一的關係型 API。Table API 的查詢不需要修改代碼就可以採用批輸入或流輸入來運行。Table API 是 SQL 語言的超集,並且是針對 Apache Flink 專門設計的。Table API 集成了 Scala,Java 和 Python 語言的 API。Table API 的查詢是使用 Java,Scala 或 Python 語言嵌入的風格定義的,有諸如自動補全和語法校驗的 IDE 支持,而不是像普通 SQL 一樣使用字元串類型的值來指定查詢。
官網文檔已經很詳細了,這裡就不重覆了:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/tableapi/
八、SQL
本頁面描述了 Flink 所支持的 SQL 語言,包括數據定義語言(Data Definition Language,DDL)、數據操縱語言(Data Manipulation Language,DML)以及查詢語言。Flink 對 SQL 的支持基於實現了 SQL 標準的 Apache Calcite。
本頁面列出了目前 Flink SQL 所支持的所有語句:
- SELECT (Queries)
- CREATE TABLE, DATABASE, VIEW, FUNCTION
- DROP TABLE, DATABASE, VIEW, FUNCTION
- ALTER TABLE, DATABASE, FUNCTION
- INSERT
- SQL HINTS
- DESCRIBE
- EXPLAIN
- USE
- SHOW
- LOAD
- UNLOAD
九、Table & SQL Connectors
1)概述
Flink的Table API&SQL程式可以連接到其他外部系統,用於讀寫批處理表和流式表。表源提供對存儲在外部系統(如資料庫、鍵值存儲、消息隊列或文件系統)中的數據的訪問。表接收器向外部存儲系統發送表。根據源和匯的類型,它們支持不同的格式,如CSV、Avro、Parquet或ORC。
官方文檔:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/connectors/table/overview/

這裡主要講一下kafka連接器
2)Kafka安裝(單機)
1、下載安裝包
官方下載地址:http://kafka.apache.org/downloads
$ cd /opt/bigdata/hadoop/software
$ wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz
$ tar -xvf kafka_2.13-3.1.0.tgz -C ../server/
2、配置環境變數
# ~/.bashrc添加如下內容:
export PATH=$PATH:/opt/bigdata/hadoop/server/kafka_2.13-3.1.0/bin
載入生效
$ source ~/.bashrc
3、配置kafka
$ cd /opt/bigdata/hadoop/server/kafka_2.13-3.1.0/config
$ vi server.properties
#添加以下內容:
broker.id=0
listeners=PLAINTEXT://hadoop-node1:9092
zookeeper.connect=hadoop-node1:2181
# 可以配置多個:zookeeper.connect=hadoop-node1:2181,hadoop-node2:2181,hadoop-node3:2181
【溫馨提示】其中0.0.0.0是同時監聽localhost(127.0.0.1)和內網IP(例如hadoop-node2或192.168.100.105),建議改為localhost或c1或192.168.0.113。每台機的broker.id要設置一個唯一的值。
3、配置ZooKeeper
新版Kafka已內置了ZooKeeper,如果沒有其它大數據組件需要使用ZooKeeper的話,直接用內置的會更方便維護。
$ cd /opt/bigdata/hadoop/server/kafka_2.13-3.1.0/config
$ echo 0 > /tmp/zookeeper/myid
$ vi zookeeper.properties
#註釋掉
#maxClientCnxns=0
#設置連接參數,添加如下配置
#為zk的基本時間單元,毫秒
tickTime=2000
#Leader-Follower初始通信時限 tickTime*10
initLimit=10
#Leader-Follower同步通信時限 tickTime*5
syncLimit=5
#設置broker Id的服務地址
#hadoop-node1對應於前面在hosts裡面配置的主機映射,0是broker.id, 2888是數據同步和消息傳遞埠,3888是選舉埠
server.0=hadoop-node1:2888:3888
4、啟動kafka
【溫馨提示】kafka啟動時先啟動zookeeper,再啟動kafka;關閉時相反,先關閉kafka,再關閉zookeeper
$ cd /opt/bigdata/hadoop/server/kafka_2.13-3.1.0
$ ./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
$ ./bin/kafka-server-start.sh -daemon config/server.properties
$ jsp
# 會看到jps、QuorumPeerMain、Kafka
5、驗證
#創建topic
kafka-topics.sh --bootstrap-server hadoop-node1:9092 --create --topic topic1 --partitions 8 --replication-factor 1
#列出所有topic
kafka-topics.sh --bootstrap-server hadoop-node1:9092 --list
#列出所有topic的信息
kafka-topics.sh --bootstrap-server hadoop-node1:9092 --describe
#列出指定topic的信息
kafka-topics.sh --bootstrap-server hadoop-node1:9092 --describe --topic topic1
#生產者(消息發送程式)
kafka-console-producer.sh --broker-list hadoop-node1:9092 --topic topic1
#消費者(消息接收程式)
kafka-console-consumer.sh --bootstrap-server hadoop-node1:9092 --topic topic1

這裡只是搭建一個單機版的只為下麵做實驗用,更對關於kafka的內容,可以參考我之前的博文(基於k8s部署):Kafka原理介紹+安裝+基本操作
3)Formats
Flink 提供了一套與表連接器(table connector)一起使用的表格式(table format)。表格式是一種存儲格式,定義瞭如何把二進位數據映射到表的列上。
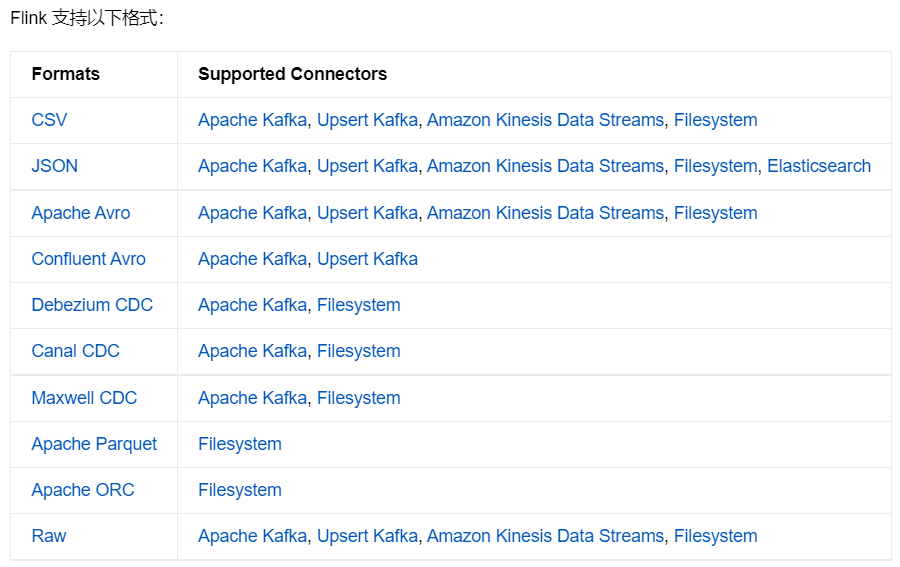
1、JSON Format
如果是maven,則可以添加如下依賴:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.14.3</version>
</dependency>
這裡選擇直接下載jar的方式
$ cd $FLIN_HOME/lib/
$ wget https://search.maven.org/remotecontent?filepath=org/apache/flink/flink-json/1.14.3/flink-json-1.14.3.jar
以下是一個利用 Kafka 以及 JSON Format 構建表的例子:
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'hadoop-node1:9092',
'properties.group.id' = 'testGroup',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
)
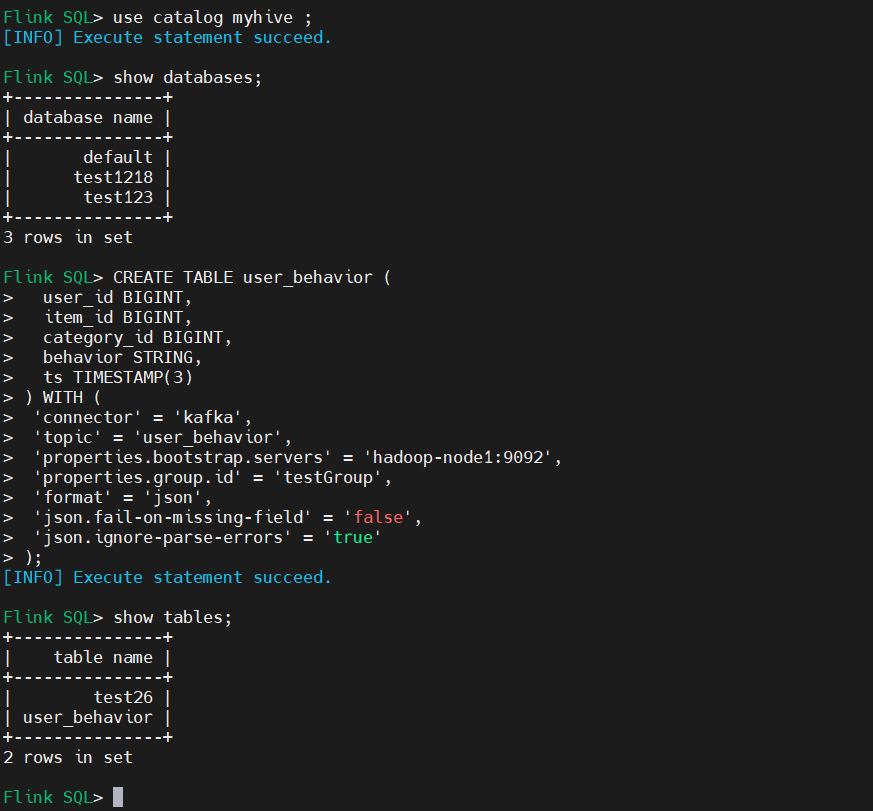
參數解釋:
json.fail-on-missing-field:當解析欄位缺失時,是跳過當前欄位或行,還是拋出錯誤失敗(預設為 false,即拋出錯誤失敗)。
json.ignore-parse-errors:當解析異常時,是跳過當前欄位或行,還是拋出錯誤失敗(預設為 false,即拋出錯誤失敗)。如果忽略欄位的解析異常,則會將該欄位值設置為null。
2、CSV Format
$ cd $FLIN_HOME/lib/
$ wget https://search.maven.org/remotecontent?filepath=org/apache/flink/flink-csv/1.14.3/flink-csv-1.14.3.jar
以下是一個使用 Kafka 連接器和 CSV 格式創建表的示例:
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'hadoop-node1:9092',
'properties.group.id' = 'testGroup',
'format' = 'csv',
'csv.ignore-parse-errors' = 'true',
'csv.allow-comments' = 'true'
)
參數解釋:
csv.ignore-parse-errors:當解析異常時,是跳過當前欄位或行,還是拋出錯誤失敗(預設為 false,即拋出錯誤失敗)。如果忽略欄位的解析異常,則會將該欄位值設置為null。
csv.allow-comments:是否允許忽略註釋行(預設不允許),註釋行以 '#' 作為起始字元。 如果允許註釋行,請確保 csv.ignore-parse-errors 也開啟了從而允許空行。其它格式也類似
4)Apache Kafka SQL 連接器
1、下載對應的jar包到$FLINK_HOME/lib目錄下
$ cd $FLIN_HOME/lib/
$ wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka_2.12/1.14.3/flink-connector-kafka_2.12-1.14.3.jar
2、創建 Kafka 表
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'hadoop-node1:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
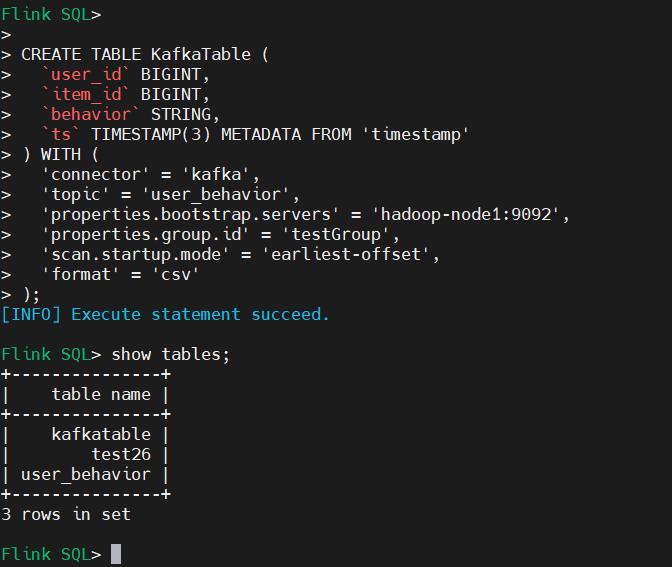
參數解釋:
scan.startup.mode:Kafka consumer 的啟動模式。有效值為:
earliest-offset,latest-offset,group-offsets,timestamp和specific-offsets。
group-offsets:從 Zookeeper/Kafka 中某個指定的消費組已提交的偏移量開始。earliest-offset:從可能的最早偏移量開始。latest-offset:從最末尾偏移量開始。timestamp:從用戶為每個 partition 指定的時間戳開始。specific-offsets:從用戶為每個 partition 指定的偏移量開始。
未完待續~

