
導讀: 本次分享的內容為圖深度學習在自然語言處理領域的方法與應用,主要內容和素材都來自於我們Graph4NLP團隊的一篇調研文章:Graph Neural Networks for Natural Language Processing:A Survery,以及我們團隊所開發的Graph4NLP的p ...

導讀: 本次分享的內容為圖深度學習在自然語言處理領域的方法與應用,主要內容和素材都來自於我們Graph4NLP團隊的一篇調研文章:Graph Neural Networks for Natural Language Processing:A Survery,以及我們團隊所開發的Graph4NLP的python開源庫和教程。主要包括以下幾大方面內容:
- DLG4NLP背景與發展
- DLG4NLP方法和模型
- DLG4NLP典型的應用
- DLG4NLP Python開源庫
--
01 DLG4NLP背景與發展
我將首先闡述一下為什麼需要圖結構來處理NLP任務,然後介紹一下傳統的圖方法在NLP裡面的應用,最後引出圖神經網路並且簡單介紹圖深度學習的基礎理論。
1. 為什麼需要圖來處理NLP任務
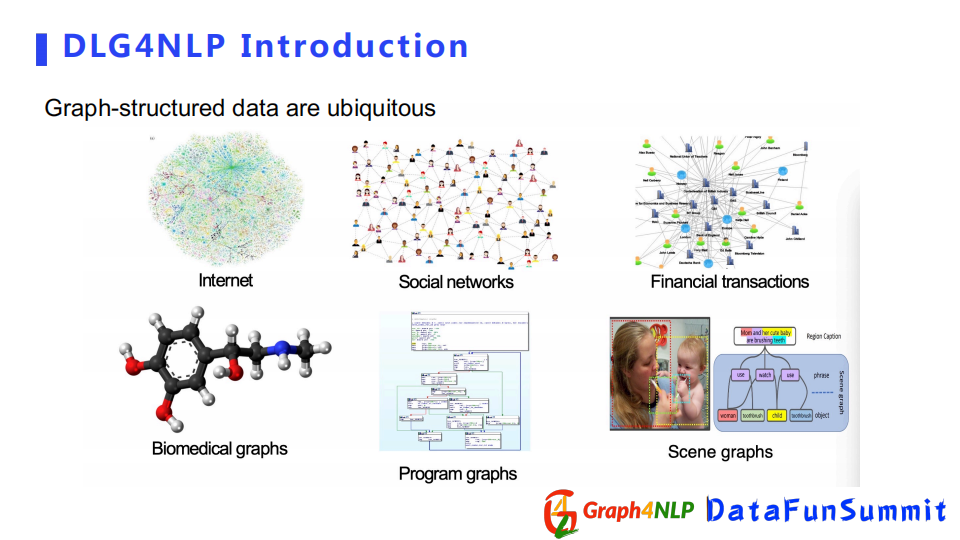
我們知道圖結構數據是由節點和邊組成的數據類型,在生活的方方面面都可以看到,尤其在大數據時代,比如互聯網、社交網路、金融的交易網。還有可以表示成圖結構的蛋白質等化學物質。我們也可以用圖結構來表示邏輯關係的程式腳本。從圖像領域來看,有表示圖像里物體間相互交互關係的圖結構。
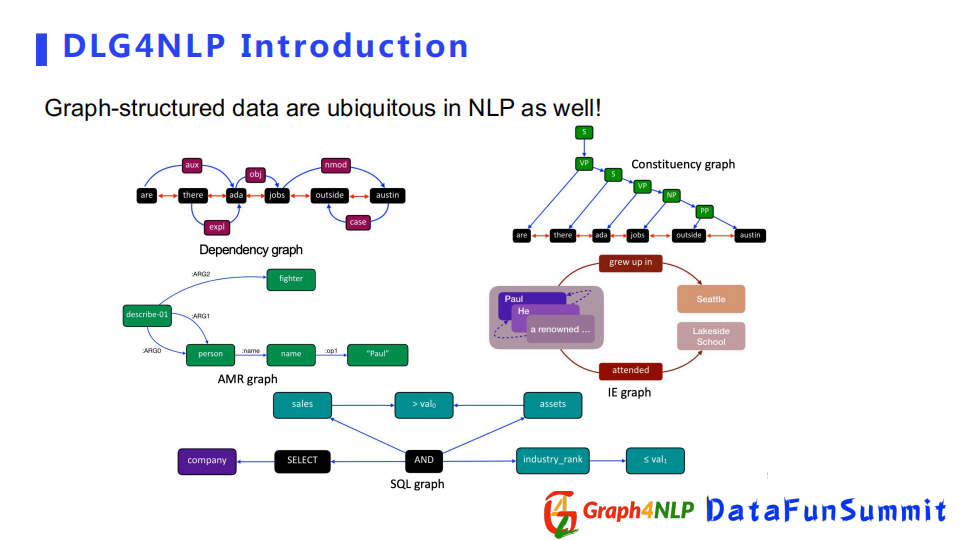
同樣在NLP的領域里,我們也會發現很多很多可以表示為圖結構的數據。比如針對一個句子,如果我們想表示這個句子里的句法信息的話,可以建立一個dependency graph或者constituency graph;如果我們想捕捉句子的語義信息的話,可以建立一個AMR graph或者IE graph;如果我們把程式語言也看作一種自然語言的話,我們可以構建出捕捉程式邏輯關係的SQL graph。
2. 傳統圖方法在NLP任務的應用
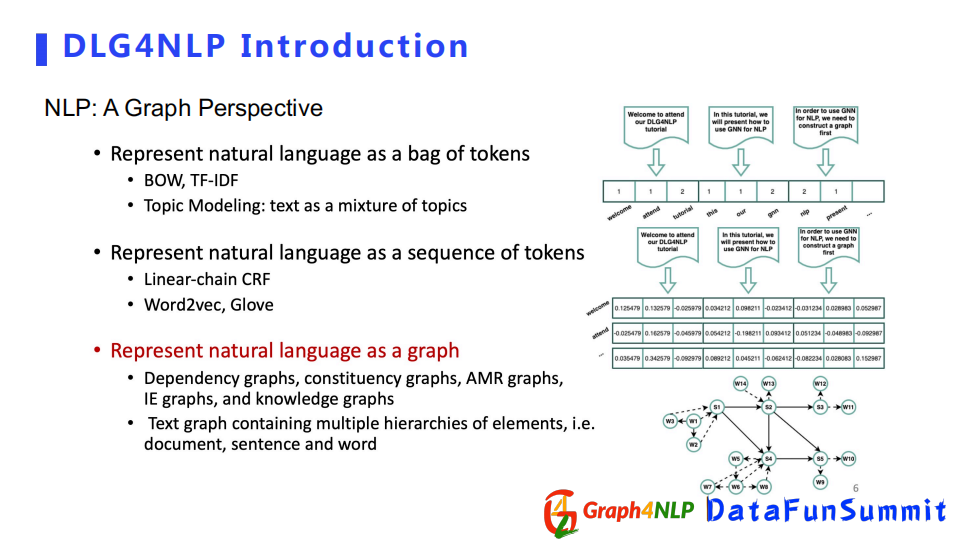
傳統NLP領域的表徵方法一般分為3種:
第一種採用詞袋來表徵文本,該方法依靠統計每個詞在句子或文檔里的頻率,但是這種方式無法捕捉詞語之間順序或者無法捕捉詞語之間的語義信息。
第二種把文本表示成序列,相對於詞袋會捕捉更多的序列信息,並且會包含詞對之間的前後關係,典型方法有Word2vec和Glove。
第三種把文本表示成圖,比較常見的有dependency graph和constituency graph等。當我們把一個文本表示成圖後,就不再局限於前後位置的序列關係,我們可以捕捉到任意兩個位置之間的關係,除了位置關係、語法關係,我們還可以捕捉語義關係。所以當我們對句子的文本表示越徹底越全面時,對錶徵學習任務幫助越大。

現在把自然語言表示成圖結構已經不是一件新鮮事情,早在深度學習之前就有演算法去這麼做。例如採用Random Walk演算法和Graph Matching演算法計算文本之間的相似性。雖然傳統方法表徵成了圖結構,但是對語言的處理具有比較大的局限性。
其一是沒有後續特征的提取環節,其二解決的任務比較有限,比如句子生成,詞與句子分類,尤其對於預處理模型同時求多個任務時,需要應用圖深度學習來解決圖特征提取環節。
3. 圖深度學習基礎理論
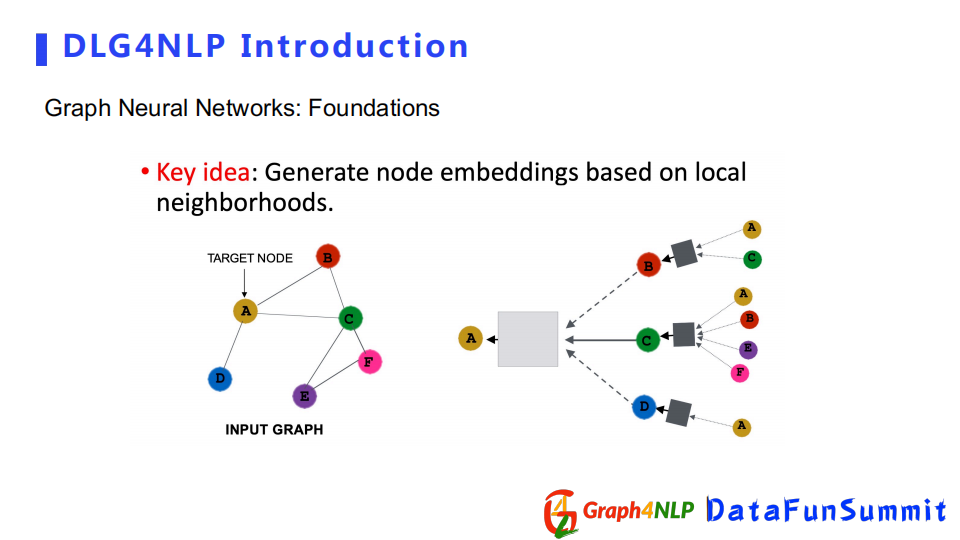
圖神經網路的核心思想是依靠鄰居節點的表徵向量對目標節點的影響,不斷地更新和學習每個節點的隱式表徵。不同的圖神經網路之間的差異在於所定義的鄰居節點對目標節點的影響方式和信息傳遞的方式不同。圖神經網路既可以計算節點的表徵向量node embedding,也可以計算整個圖的表徵向量graph-level embedding。通過圖捲積方式計算節點的表徵向量的不同,圖捲積有四個比較典型的代表:Spectral-based,Spatial-based,Attention-based,Recurrent-based。該四個類型並不相互排斥,一種圖捲積方法既可以是Spatial-based也可以是Attention-based。

我們介紹下基本的圖捲積操作。
第一個公式為圖捲積運算,它的輸入為A鄰接矩陣和H node embedding(節點表徵);對於節點分類和鄰接預測的任務,得到節點的表徵向量即可。對於圖分類和圖的生成任務,需要採用pooling(池化操作)對整個圖做表徵向量,常見的方法有Flat Graph Pooling(求平均、最大、最小值pooling方式);另外一種是Hierarchical Graph Pooling(Diff pool方式),根據圖結構把整個node embedding聚合到一起組成一個graph embedding network。

根據不同的圖捲積方式和pooling(池化)層,我們可以得到不同的圖神經網路模型,比如GCN,GAT等。
--
02 DLG4NLP方法和模型
下麵我們進入第二部分,即如何用圖神經網路去解決自然語言處理的任務。這一環節我會從三個方面進行介紹,首先是如何去構造自然語言任務里的圖結構,其次是如何在圖結構基礎上進行表徵學習,最後講兩個比較典型的圖神經網路構架。
1. 如何構造NLP的圖結構
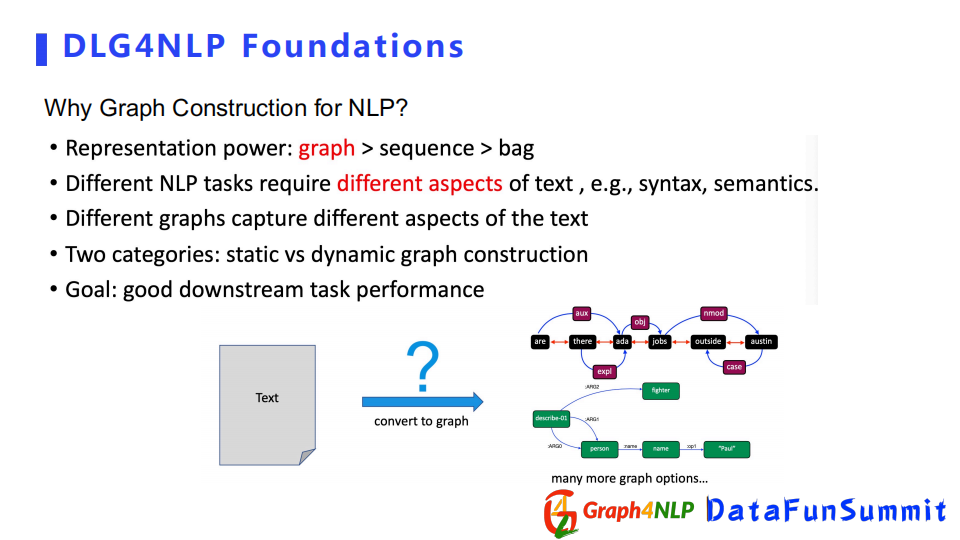
自然語言里對文本的圖構造可以分為兩類:
- 靜態圖構造
- 動態圖構造
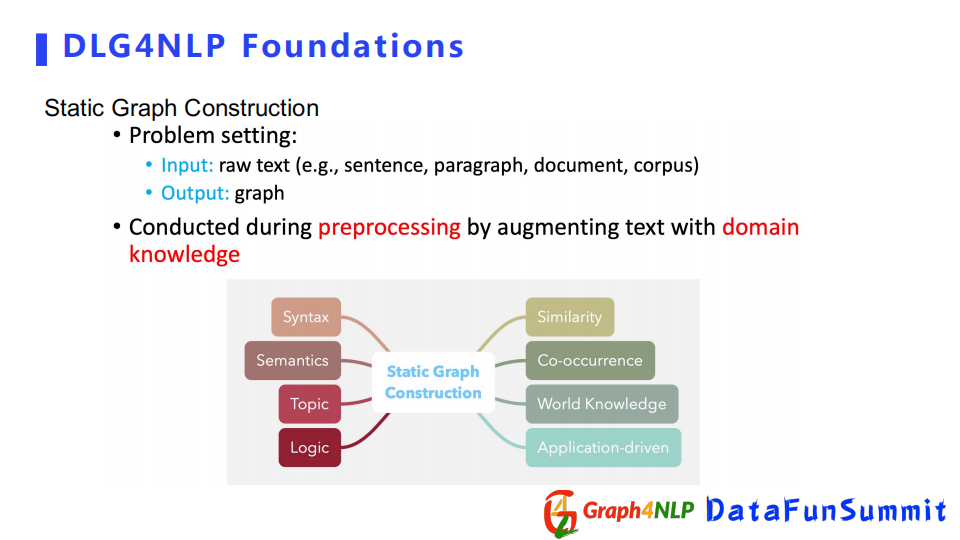
靜態圖構造的輸入可以為原始的句子、段落或者文檔,輸出是我們針對輸入所構造出的圖結構。靜態圖可以在預處理階段完成,但是它需要有一些對句子或文檔文本的領域信息,比如一些語法信息、語義信息、邏輯信息和主題信息,根據領域信息對句子或者文本構造一個圖。
根據不同的信息或者文本,靜態圖可以進一步細分。
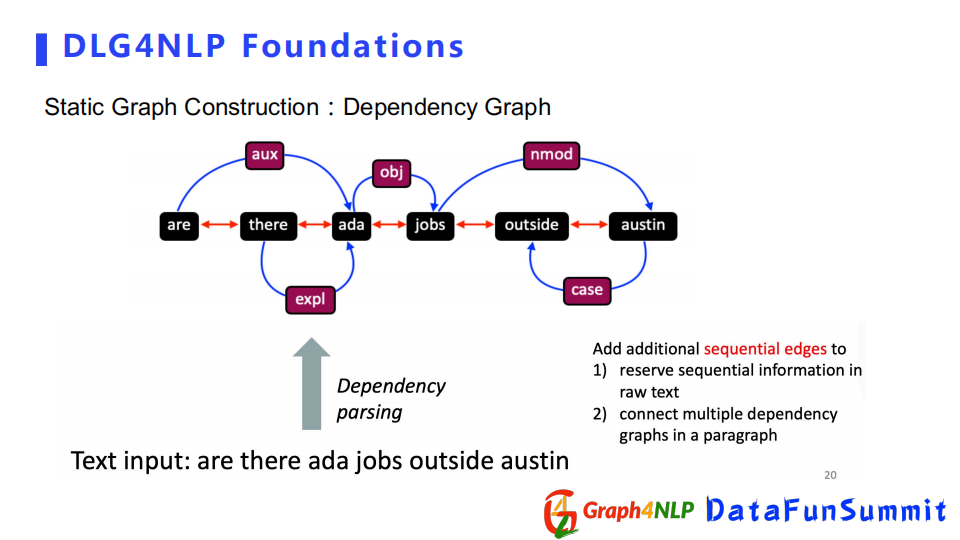
首先是Dependence Graph,該圖結構依賴於dependence parsing,可以用來捕捉句子的句法信息,它更註重兩個詞之間的句法關係,所以該圖結構是一個比較簡潔的構圖表示。如果我們想用圖表示整個文檔的話,我們可以結合連續邊的信息來表示文檔中句子之間的前後關係。
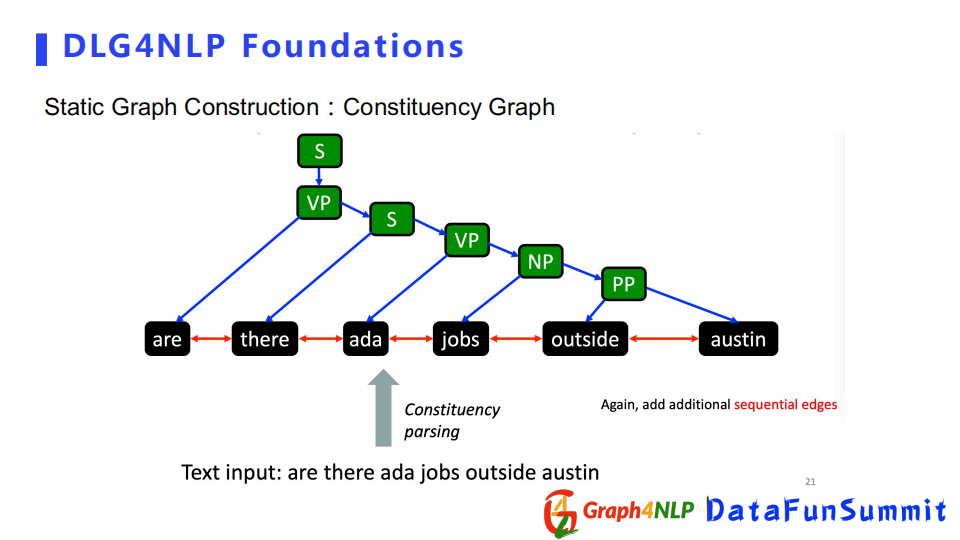
相對Dependence Graph,Constituency Graph展現的是句子的句法信息,更註重整個句子的結構,而不是局限於句子中兩個詞之間的句法關係。所以它更全面地展示了整個句子的結構性。
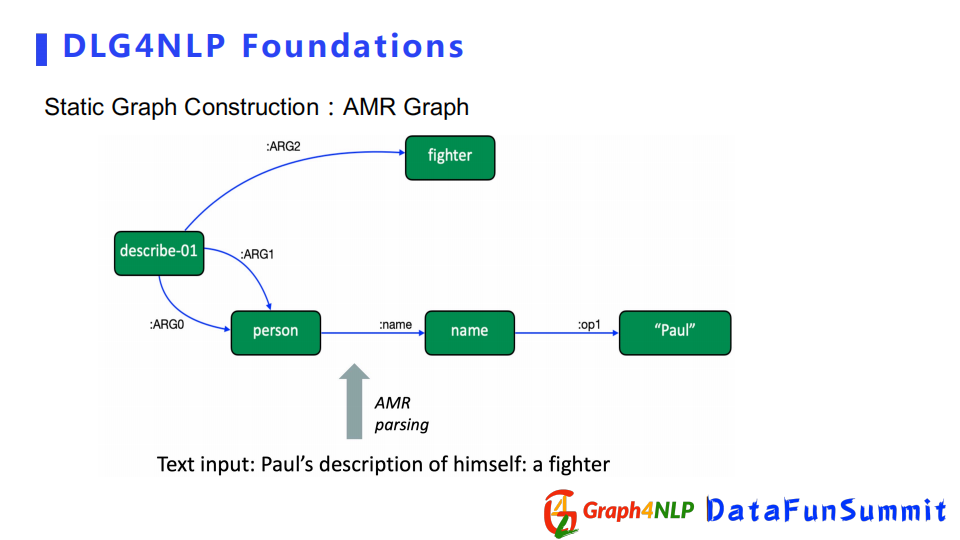

其次介紹AMR Graph和IE Graph,它們都是用來捕捉句子的語義信息,更註重兩個詞之間語義關係。比如IE Graph例子裡面Paul是個人名,然後Seattle是個地名,所以我們首先需要表示它們倆屬於實體,同時也需要知道兩個實體之間的關係是一種grew up in的語義關係。根據實體關係,可以構造出IE Graph作為最終的構圖。
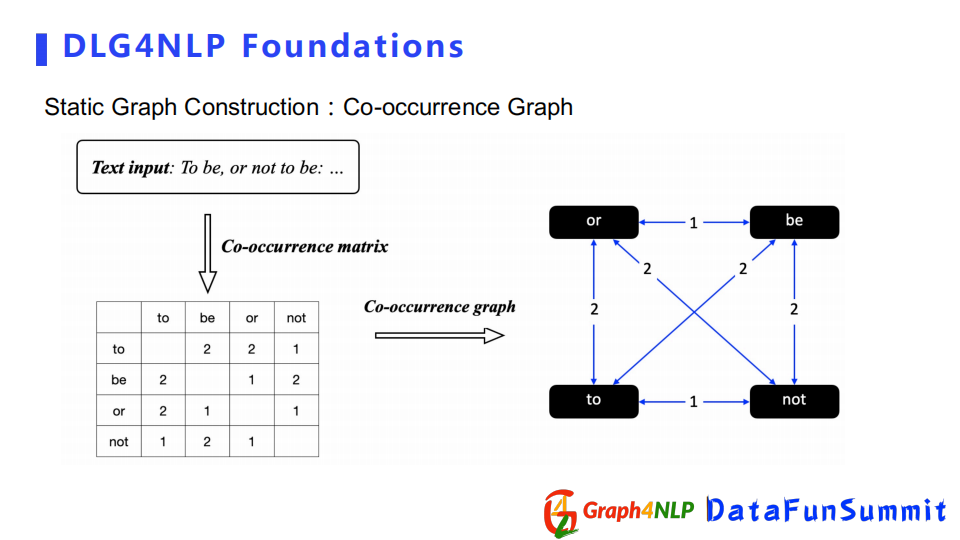
除了之前幾種構造圖外,還有Co-occurrence Graph,它是通過統計兩個詞同時出現的次數,得到Co-occurrence矩陣,然後將矩陣作為構圖的鄰接矩陣。
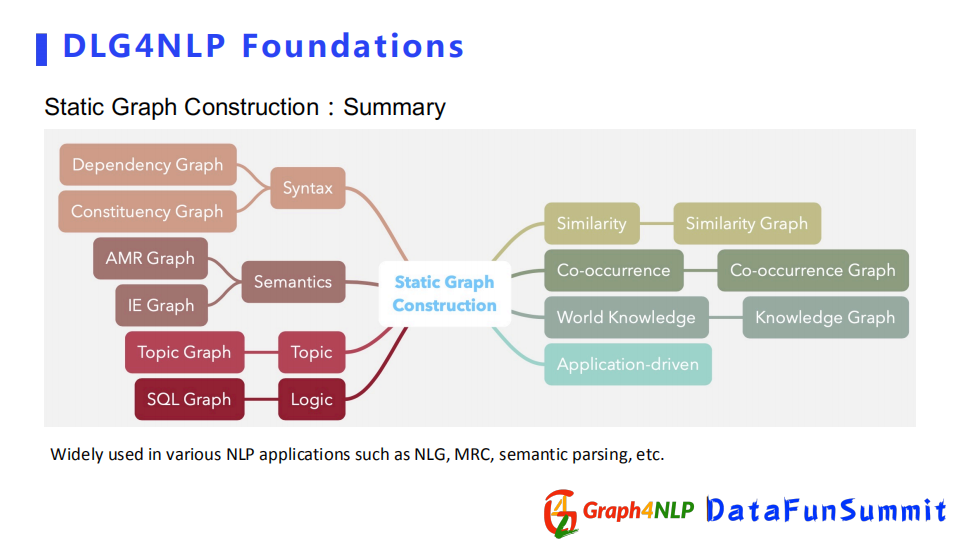
總結以上例子,靜態圖構建是需要額外的領域信息來增強句子本身的信息組成的圖結構。常用的信息有句法信息、語義信息、主題邏輯信息、co-occurrence信息,甚至基於應用的信息。所以根據不同的領域信息,可以構造出不同的靜態圖結構。
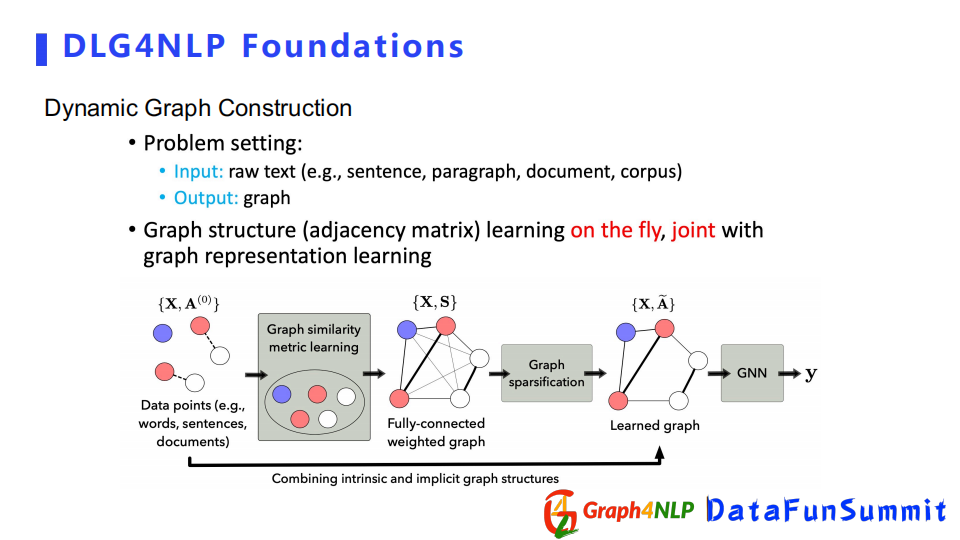
下麵介紹另外一種構圖方式即動態構圖,動態圖構造不需要有額外的領域知識去指導如何構圖。該方法直接把文本丟給機器,讓機器自己去學習圖結構。
例如有若幹個表示為word或者句子的未知關係節點,首先通過圖相似矩陣學習的方式去構造一個全連接圖,然後對其做稀疏化操作得到稀疏圖,然後進行圖表徵學習。

動態圖構建中最重要的一個步驟是相似矩陣學習,其核心是計算任意兩個節點特征向量相似度。首先需要設置一個相似的kernel去定義這兩個embedding的相似度。兩種典型的做法:一個是Node Embedding Based方法,第二個是Structure-aware方法,下麵分別介紹這兩種方法。
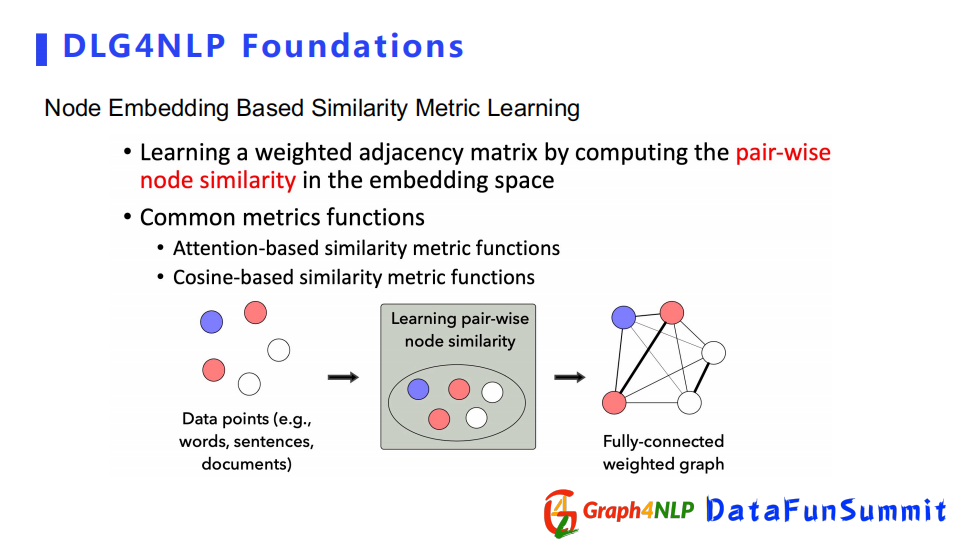
Node Embedding Based方法依靠兩個節點的表徵向量(embedding)。先計算兩個節點embedding的相似度,然後把相似度作為加權的鄰接矩陣裡面的值。特征向量計算相似度的方式也分兩種,一個是attention based,一個是cosine based。
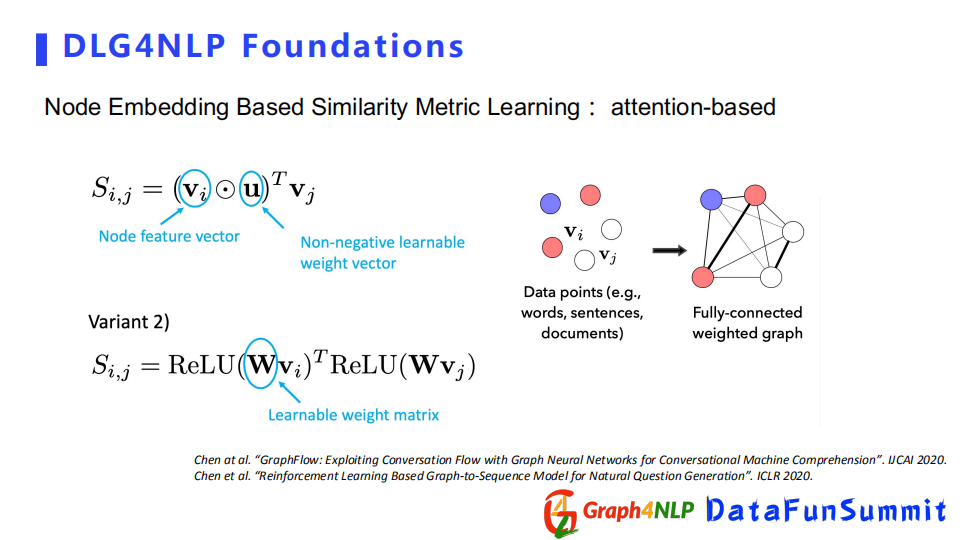
Attention-based的方式在計算相似度時,會有可學習的參數來幫助計算每對節點對之間的attention,它其實有兩種方式來計算attention:
第一種是假設對所有的節點都共用可學習的參數,可學習參數是一個向量。
第二種方式是每一對節點都有自己的可學習的參數,這裡可學習的參數是一個矩陣了,矩陣裡面N代表節點的數量。

Cosine-based方法是先把節點的表徵向量都乘以一個可學習的參數矩陣,相當於將其投影到另一個新的空間,再計算新空間下兩個表徵向量之間的cosine值。如果想讓函數更加具有張力,可以借鑒多頭機制(multi-head)設置多個投影空間,即學多個參數。對於每一個頭參數都會有一個cosine值,然後把所有的cosine求平均,即為最終的cosine值。
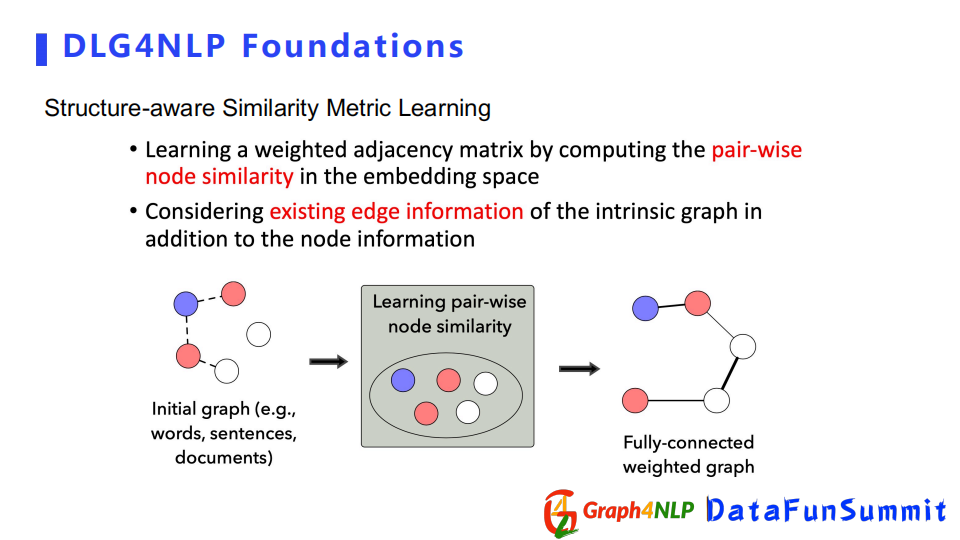
在計算相似度時有時不僅要考慮node embedding,還要考慮圖本身的結構。可以用structure-aware相似矩陣來學習本身的初始結構,但該結構不確定對下游任務的影響,但是可以先用起來,然後去算structure-aware相似度。
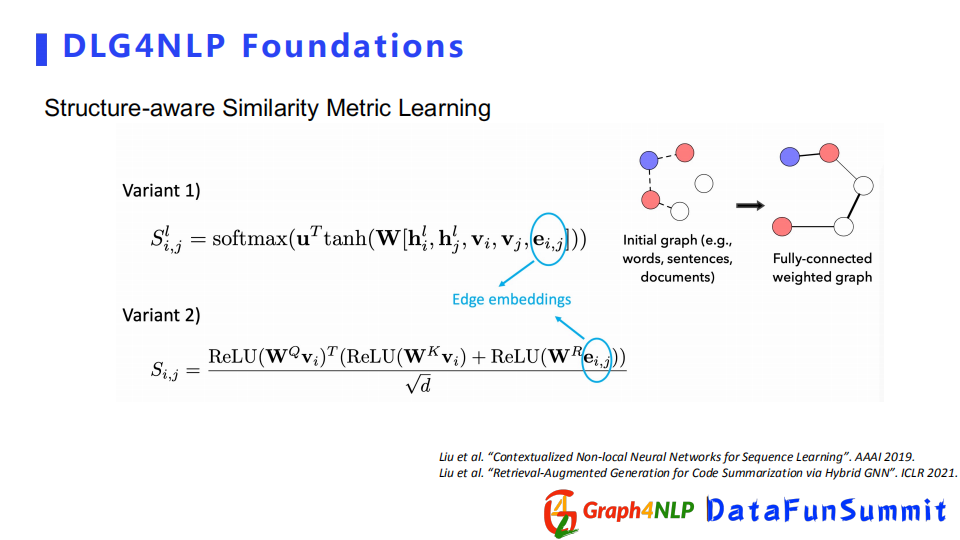
structure-aware相似矩陣計算其相似度也有兩種方式,計算相似度時都將邊界的embedding算進去。

下麵對動態圖和靜態圖的構造做一個總結:
a) 靜態圖的優點可以依靠認為構造去捕捉一些先驗目標知識,其缺點是人為構造會產生雜訊。同時無法確定構建的圖結構對下游任務是否有所幫助。當我們確定所掌握的領域知識是跟下游任務是匹配時,可以應用靜態圖結構。
b) 動態圖的優點是比較簡便,不需要額外的領域知識直接讓機器去學最優的圖結構,其圖結構和圖表徵的學習過程可以相互促進。缺點是圖結構的可解釋性幾乎為零,不太能解釋兩個節點之間的關係和代表的含義,第二個缺點是由於是全連接的圖導致穩定性很差。當缺少一些領域知識或者不確定用什麼圖去解決下游任務時,可以選擇動態圖構建來幫我們去學最優的圖結構。下麵介紹如何做表徵學習。
2. 如何做NLP的圖表徵學習

圖表徵學習分為三種,為Homogeneous Graph、Multi-relational Graph和Heterogenous graph。Homogeneous Graph只有一種節點類型以及一種邊類型。Multi-relational Graph是一種節點類型以及多種邊類型。Heterogenousgraph則是多種節點類型和多種邊類型。
下麵分別介紹這三種不同的圖表徵學習。

Homogeneous Graph的神經網路比較簡單,構建來源有兩種,一種是本身圖結構就是homogeneous,第二種是通過轉換操作,把non-homogeneous graph轉化成一個homogeneous graph。
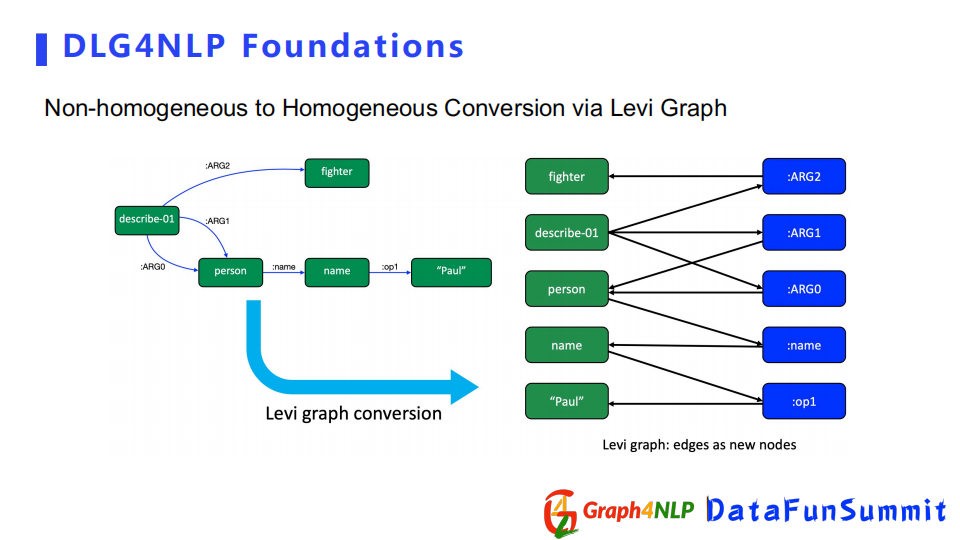
接下來舉例子介紹,如何把不適合的non-homogeneous graph轉化成homogeneous graph。左邊圖結構是一個AMR graph,有多種不同的關係,把每個關係的ARG值當成一個節點,這樣就可以把它轉化成了只有一種ARG值的graph,如果將節點看作同等對,其就是一個homogeneous graph。
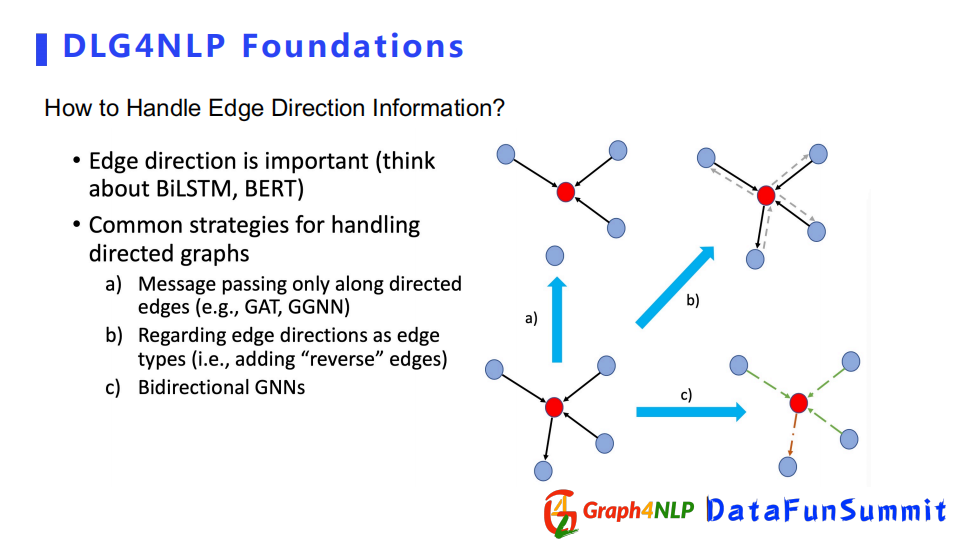
還有一個比較關鍵的問題,在構圖中會經常遇到連接的邊具有方向性。邊的方向性在表示兩個節點關係上是非常重要的。比如說在處理序列時,BiLSTM結構之所以效果很好,其實也是考慮到這種方向性,所以在圖結構上也要考慮這個方向性。目前處理方向有三個選擇:
第一個是在信息傳遞時,只讓信息沿著方向傳播,例如a中的紅色節點跟四個節點連接,但是因為讓信息只沿著節點的箭頭方向傳播,所以它只受三個鄰居節點的影響。
第二個是把edge的兩個方向當成兩個edge種類,產生一個多關係的graph。
第三個是設計Bidirectional GNNs,直接用這種特殊的圖神經網路去解決問題。
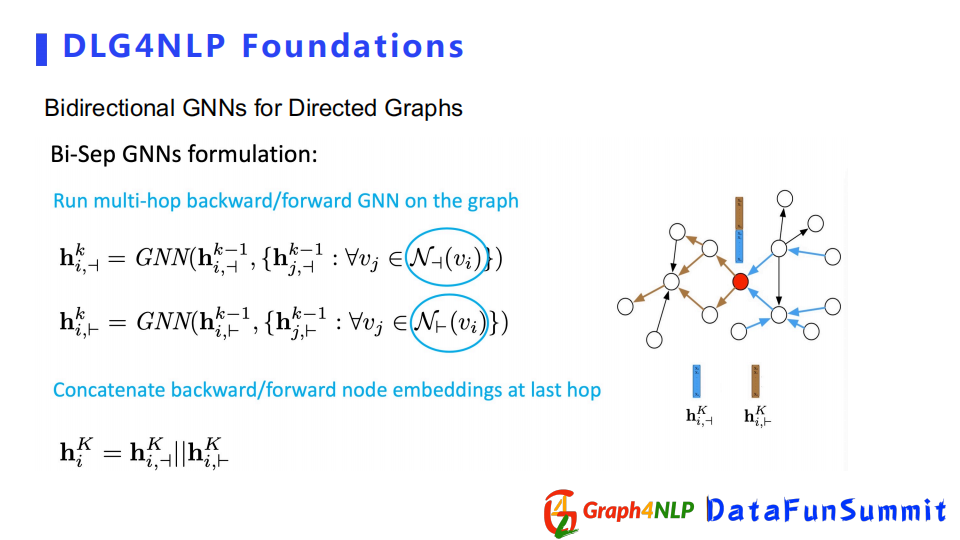
下麵詳細介紹特殊的Bidirectional GNNs,該圖神經網路分兩個類型:
第一種類型是對每一個方向都會搭建兩個獨立的捲積網路,分別學習embedding,到最後一層時,再把兩個方向得到的節點表徵連接到一起得到最終的表徵。
另外一種類型不同之處在於,雖然有兩個不同方向的捲積網路,但在每一層捲積之後都會把學到的節點表徵合到一起,把新的節點表徵去分別送到下一層兩個方向的捲積。
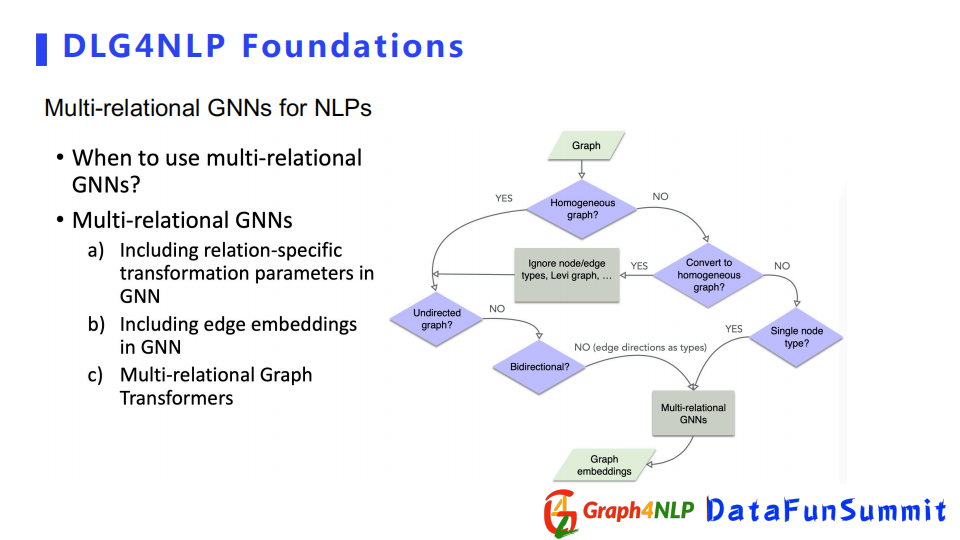
接下來介紹Multi-relation GNNs,其方法分為三類:
第一種是引入不同的與type相關的可訓練捲積參數。
第二種直接引入edge embeddings,來表示不同的關係。
第三種利用專門的Multi-Relation Graph Transformer。
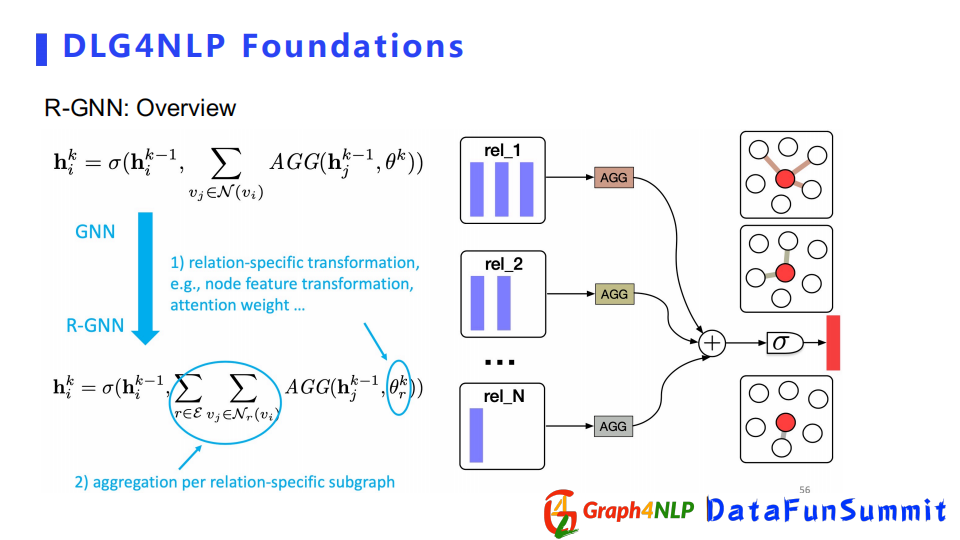
下麵是處理Multi-relation的方法。
第一種方法是對每一個關係學一個捲積核,相比於傳統的GNN,R-GGN有一個參數θ,對每個type都會學一個θ,每一個關係都會得到節點表徵,然後把得到的節點表徵做一個加和。
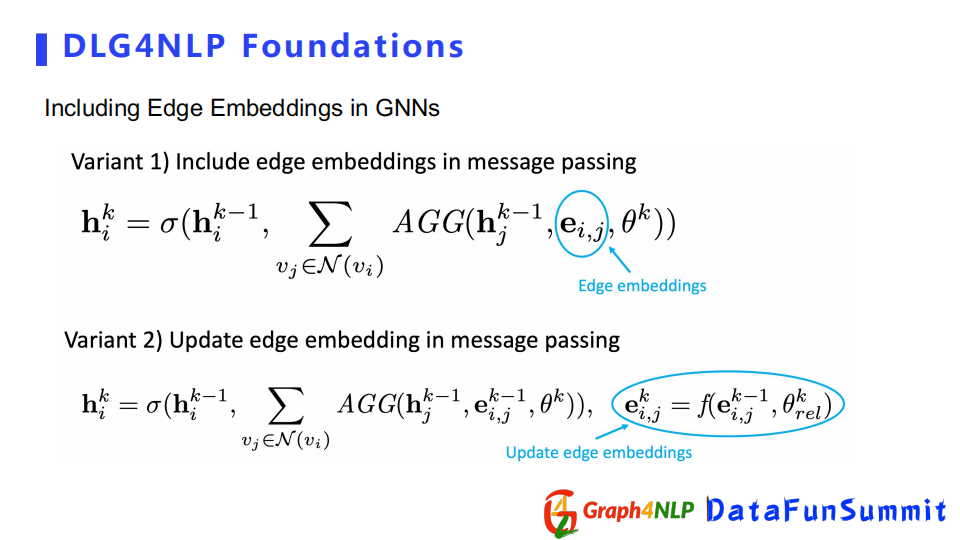
第二種直接引入邊的表徵向量,其核心是在做message傳播時,把邊的表徵向量加進來可以捕捉不同邊的種類。引入邊表徵向量有兩種方式,一種是邊表徵向量從頭到尾是固定不變的,另外一種是邊的表徵向量像節點一樣,在傳播中不斷地更新迭代。
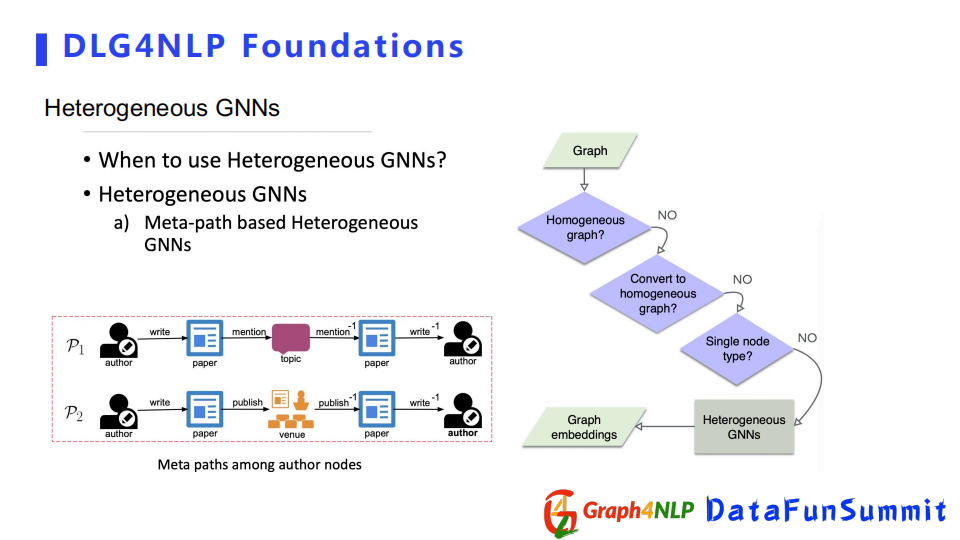
eterogeneousGraph在NLP領域裡面更多用的是基於meta-path的GNNs。詳細介紹可以看ACL2020的文章。
3. NLP任務重的圖編碼解碼模型

在經典的NLP任務裡面,seq2seq的架構相對比較流行,比如自然語言翻譯這種實際問題,但是這種結構只能處理序列轉換,無法解決圖結構,所以為了把圖結構引入整個NLP任務,需要採用Graph2Seq的結構。
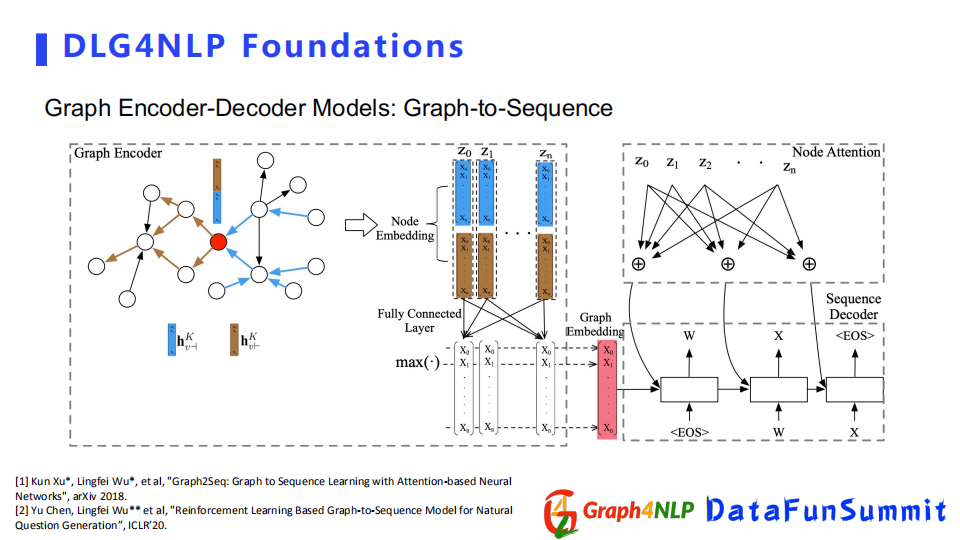
目前有兩個比較主流的結構,第一個是由encoder-decoder組成,其encoder是基於GNN神經網路組成,將圖作為輸入圖的embedding,然後decoder選擇為NLP里針對不同下游任務所使用的語言生成器。
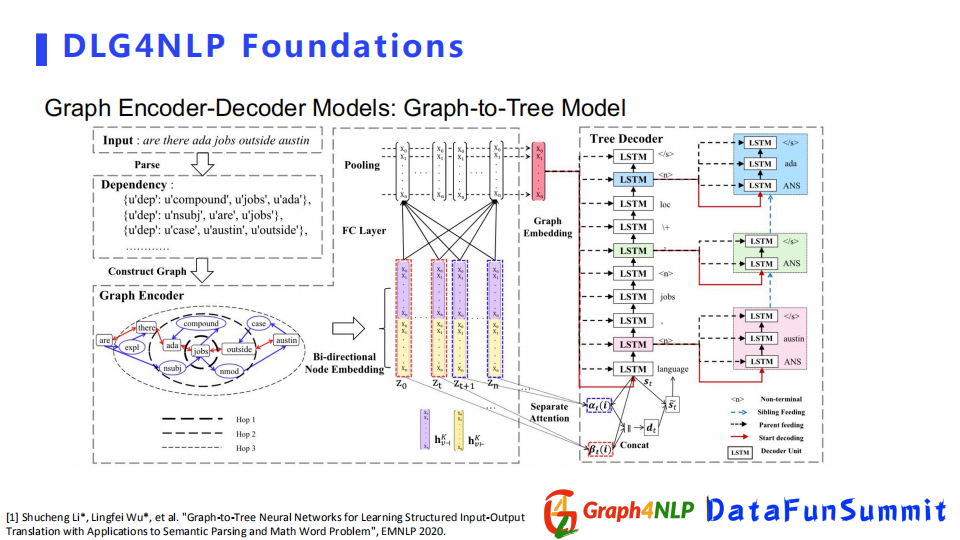
第二種結構是graph-to-Tree Model,輸出不只是需要sequence,我們還需要更詳細的圖結構文本。比如程式語言的生成,需要把它表示成為tree的結構模型來解決任務。
--
03 DLG4NLP典型的應用
接下來介紹Graph NLP裡面主要模型和方法的兩個典型應用。
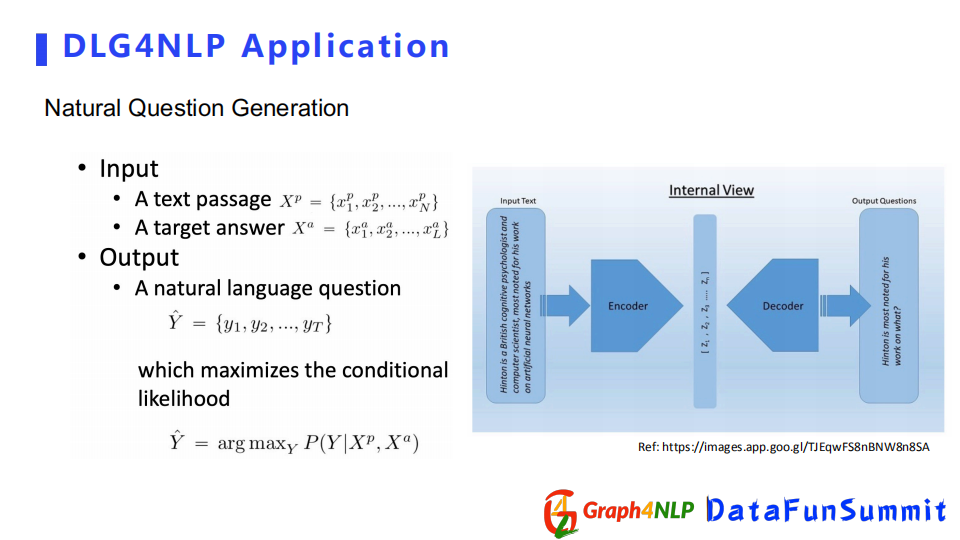
一種廣泛的應用是文本問題生成,即根據輸入的答案,生成對應的問題。該應用可以看成一個生成問題,目的是希望decoder學到一個基於條件的分佈。
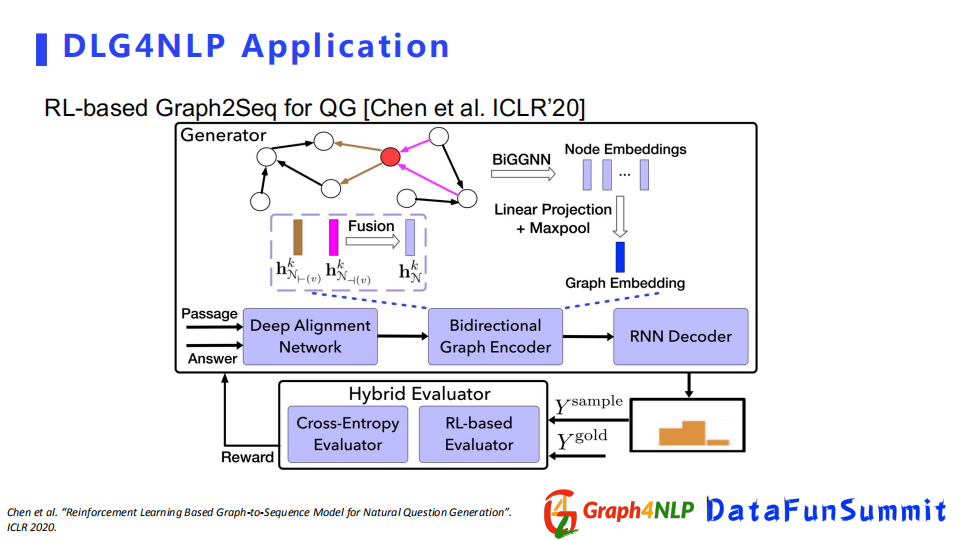
在ICLR220的這篇文章中,它是利用Graph2Seq的結構去解決生成問題,把輸入表示成一個圖結構,用BiGGNN去學習節點表徵,再配上RNN decoder做最後的問題生成。
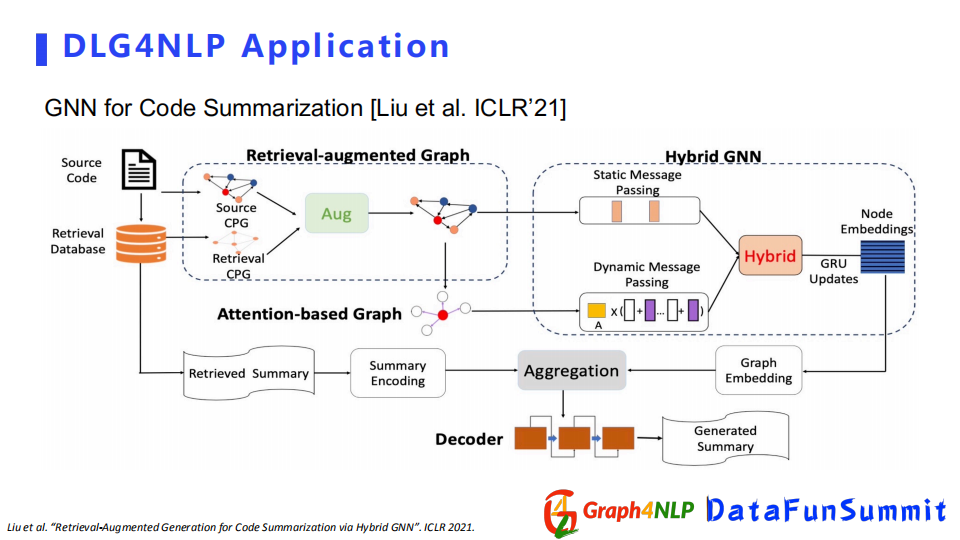
另外一篇文章是總結概要的應用,它的目的就是把整個比較大的文章輸入進去,得到一個短摘要。該文章收錄在ICLR2021的summary session中。
--
04 DLG4NLP Python開源庫
最後介紹一下我們團隊開發的開源python庫Graph4NLP。
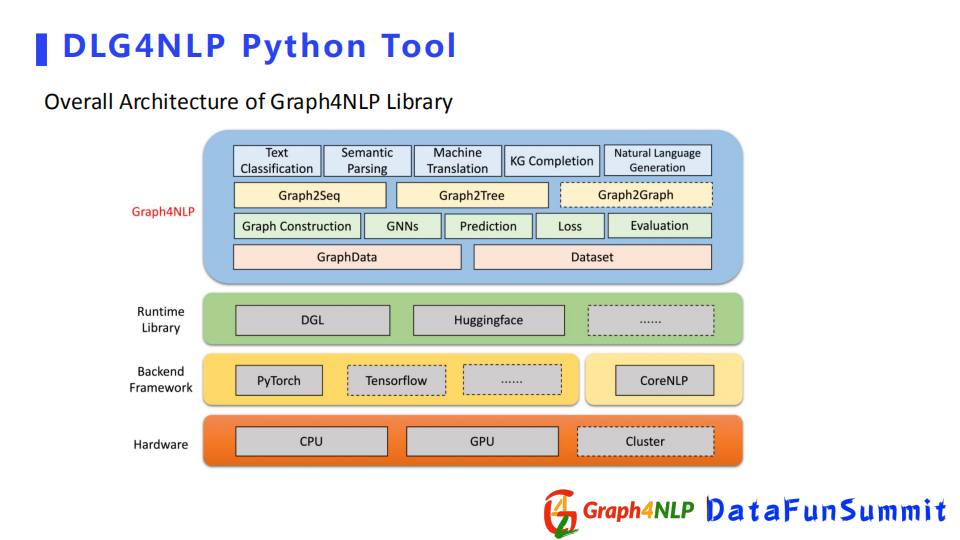
首先我們開源庫基於pytorch、DGL和CoreNLP開發,並且提供了Huggingface介面,進而可以使用bert之類的模型。
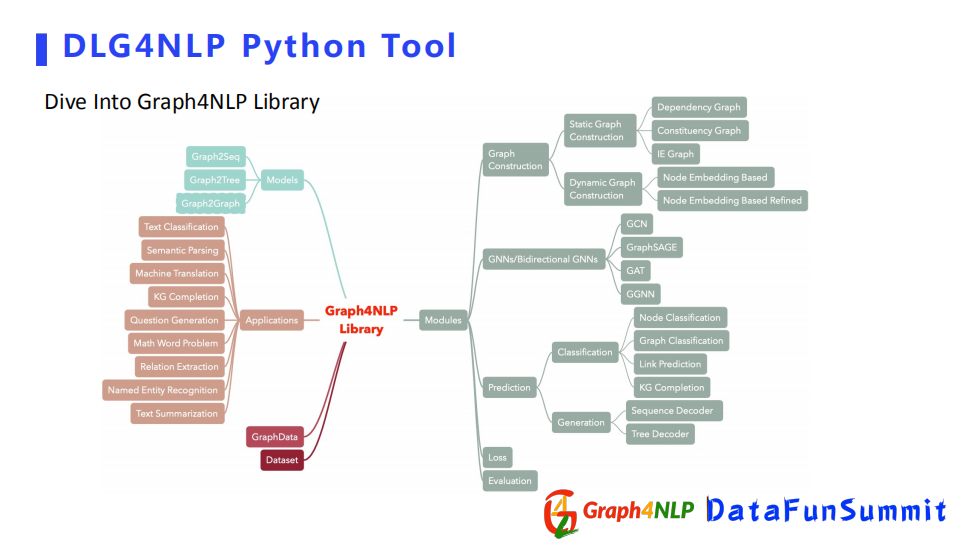
下麵是對開源庫功能函數的概覽,其核心的module包含了Graph Construction即靜態圖構建和動態圖構建。還有其下游的任務,比如分類任務和生成任務。另外還包括一些比較典型的圖神經網路GCN和GraphSAGE等。我們還用python庫去實現了一些比較經典文章里的一些模型,並且取得了不錯的效果。
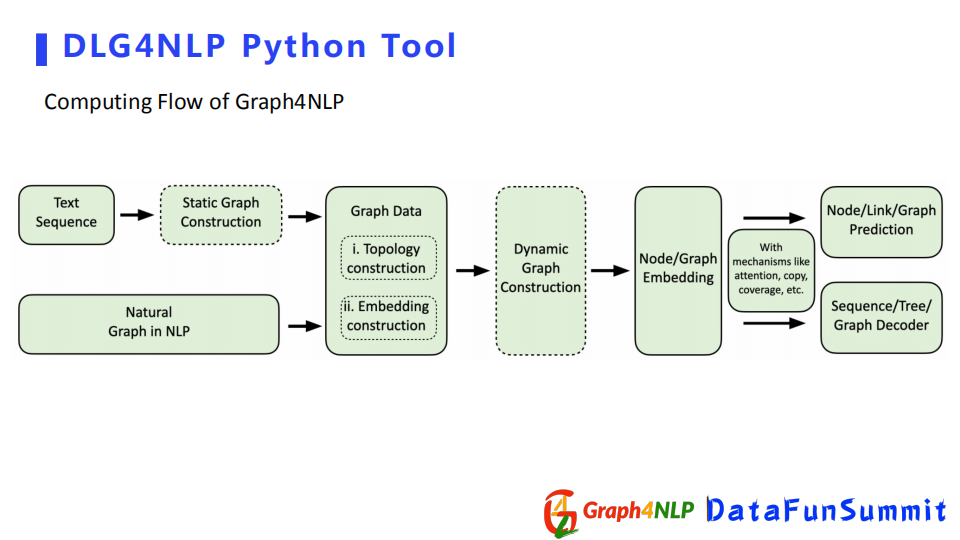
接下來展示下python庫如何做完成NLP任務。
流程為首先做一個圖構建,將圖結構輸進去,用python庫的Graph Data產生Data數據類型,然後用GNN圖學習模塊優化該圖,或者進行圖的表徵學習,最後可以根據具體的任務去選擇下游的模塊,或者做分類、生成任務等。
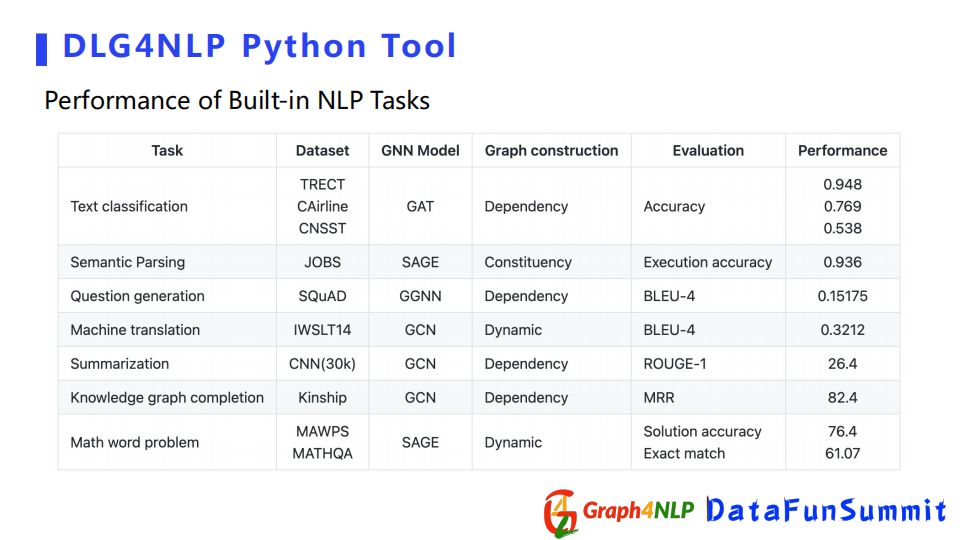
這個表格展示了python庫在不同NLP任務上取得的不錯結果。如果大家想探索圖深度學習在NLP應用的話,請關註和嘗試該library,歡迎大家多提寶貴的意見,因為我們還在不斷的去更新我們的開源庫。今天就是我分享的全部內容,謝謝大家的關註。
--
05 精彩問答
Q1:現在像知識圖譜的圖表示學習的演算法多嗎?
A:目前邊的網路更多的是生成homogeneous graph, Heterogeneous graph也有一兩篇文章。
Q2:Bert加圖學習訓練不起來怎麼辦?
A:有可能是構建圖結構有問題,或者調參沒調好,可以試下上面講的開源python庫。先去做一個嘗試,然後對照排查問題。
Q3:最近transformer相對比較火,在用於NLP文本建模時用全連接的圖來進行建模,如果找一些比較稀疏的有語義的圖,也可以取得非常好的結果。您覺得有沒有可能把這兩種方法結合起來,同時利用全連接的圖和語義的圖?
A:我覺得transformer本身就是一種GNN形式,只不過它學的是個全連接圖,它有點類似於我剛纔講的動態圖構建,因為動態圖的構建本身也是學一個全連接圖,如果你本身有原始的圖,可以借用原始的圖把它放到動態圖,然後兩兩去結合促進後面的圖學習。
Q4:將圖神經網路用於NLP,重點是在於圖的構建還是在於新的模型?
A:目前圖學習的效果已經不錯了,但基於不同應用,我覺得圖的構建是比較關鍵的一件事情,尤其是如果你做靜態圖構建的時候,你的信息選取不對或者添加的圖信息不對的話,你有可能會引入一些bias或一些noise,然後導致學不到你想要的一個信息,或者得到了更多noise。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號“DataFunTalk”


