
分享嘉賓:張建 PingCAP TiDB優化器與執行引擎技術負責人 編輯整理:Druid中國用戶組第6次大數據MeetUp 出品平臺:DataFunTalk 導讀: 本次報告張老師主要從原理上帶大家深入瞭解 TiDB SQL 優化器中的關鍵模塊,比如應用一堆邏輯優化規則的邏輯優化部分,基於代價的物理 ...
分享嘉賓:張建 PingCAP TiDB優化器與執行引擎技術負責人
編輯整理:Druid中國用戶組第6次大數據MeetUp
出品平臺:DataFunTalk
導讀: 本次報告張老師主要從原理上帶大家深入瞭解 TiDB SQL 優化器中的關鍵模塊,比如應用一堆邏輯優化規則的邏輯優化部分,基於代價的物理優化部分,還有和代價估算密切相關的統計信息等。
本文將從以下幾個方面介紹:首先講一下TiDB的整體架構,接下來就是優化器的兩個比較重要的模塊,一個是SQL優化,做執行計劃生成;另一個模塊就是統計信息模塊,其作用是輔助執行計劃生成,為每一個執行計劃計算cost提供幫助。最後介紹下優化器還有哪些後續工作需要完成。

--
01 TiDB的整體架構
TiDB架構主要分為四個模塊:TiDB、TiKV、TiSpark和PD,TiKV是用來做數據存儲,是一個帶事務的、分散式的key-value存儲,PD集群是對原始數據里用來存儲key-value里每一個範圍的的k-v存儲在每一個具體的k-v元數據信息,也會負責做一些熱點調度;如熱點 region調度。在Tikv中做數據複製和分散式調度都是rastgroup做的,每一個讀寫請求都下放到Tikv的leader上去,可能會存在某些Tikv的server或者機器的region leader特別多,這個時候PD集群就會發揮熱點調度功能,將一些熱點leader調度到其他機器上去。TiDB是所有場景中對接用戶客戶端的一層,也負責做SQL的優化,也支持所有SQL運算元實現。Spark集群是用來做重型IP的SQL或者作業查詢,做一些分散式計算。
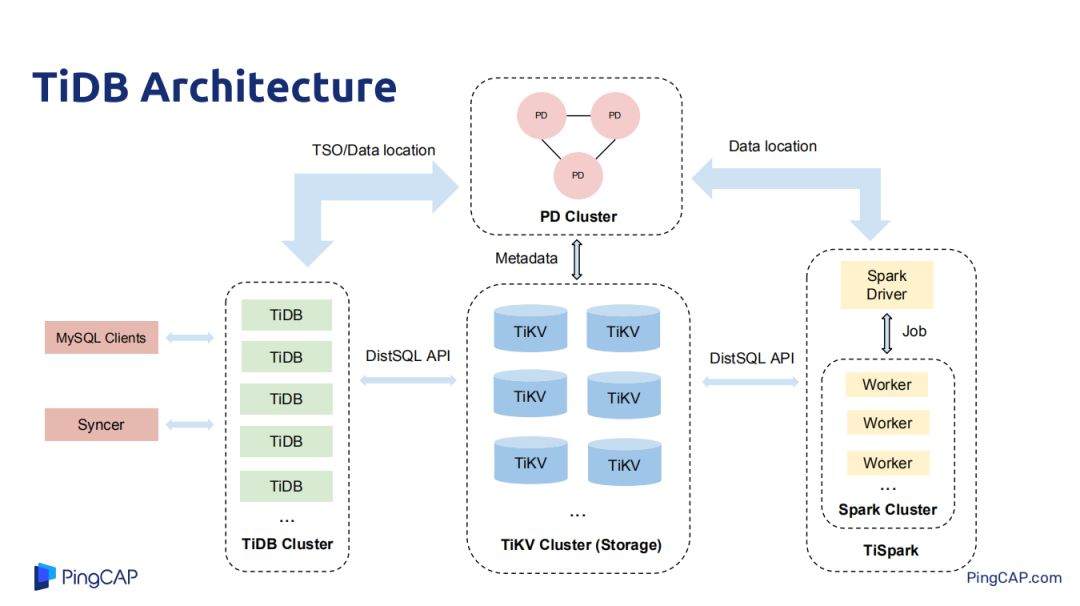
刨除Spark,TiDB集群主要有三個核心部分。最上層TiDB對接用戶的各種My SQL/Maria DB clients,ORMs,JDBC/ODBC,TiDB的節點與節點之間本身是不做任何數據交互,是無狀態的,其節點就是解析用戶的query,query的執行計劃生成。把一些執行計划下推到一些Tikv節點,將一些數據從Tikv節點拿上來,然後在PD中做計算,這就是整個TiDB的概覽。
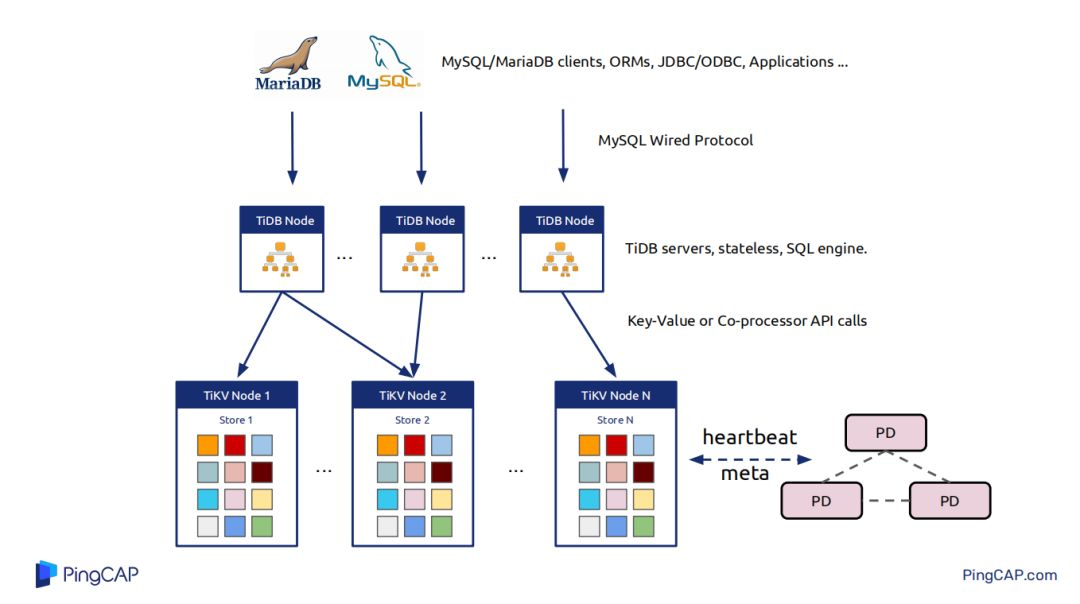
講優化器之前需要講一下TiDB中結構化的數據是如何映射到K-V數據的。在TiDB中只有兩種數據,一種是表數據,一種是為表數據創建的index數據。表數據就是tableID加RowID的形式將其映射為Key-Value中的key,表數據中具體每一行的數據一個col的映射為其value,以Key-Value的形式存儲到Tikv中。索引數據分為兩種一種是唯一索引和非唯一索引,唯一索引就是tableID+IndexID+索引的值構成Key-Value中的key,唯一索引對應的那一行的RowID,非唯一索引就是將rowID encode到Key中。

下麵是TiDB SQL層的應用組件,左邊是協議層,主要負責用戶的connect連接,和JDBC/ODBC做一些數據協議,解析用戶的SQL,將處理好的結果數據以MySQL的形式encode成符合MySQL規範的格式化數據返回給客戶端。中間的Session Context主要負責一個session裡面需要處理的一些用戶設置的各種變數,最右邊就是各種許可權管理的manager、源信息管理、DDL Worker,還有GC Worker也是在TiDB層。
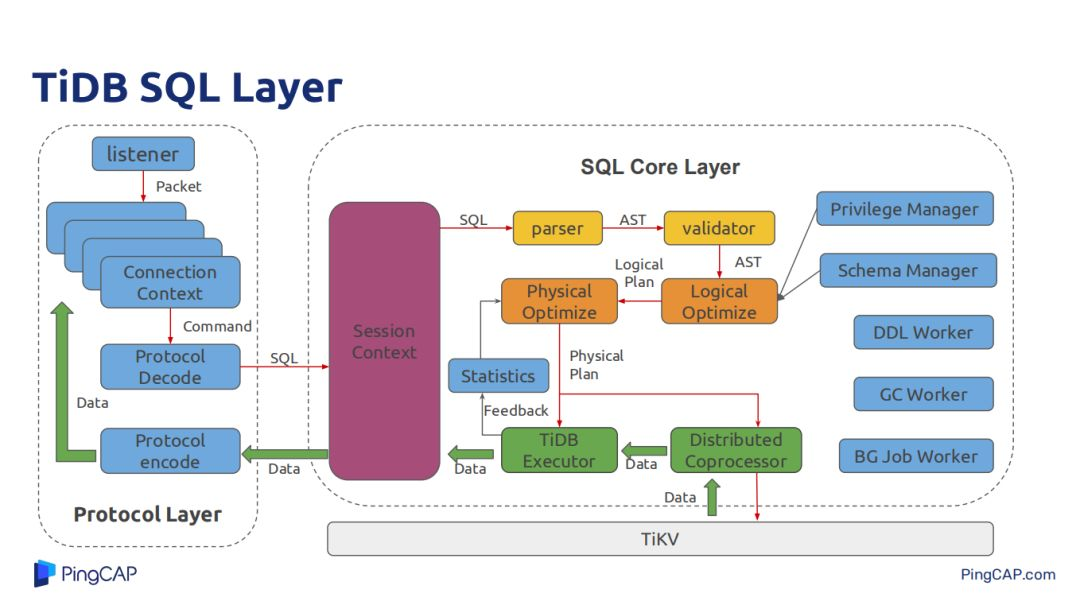
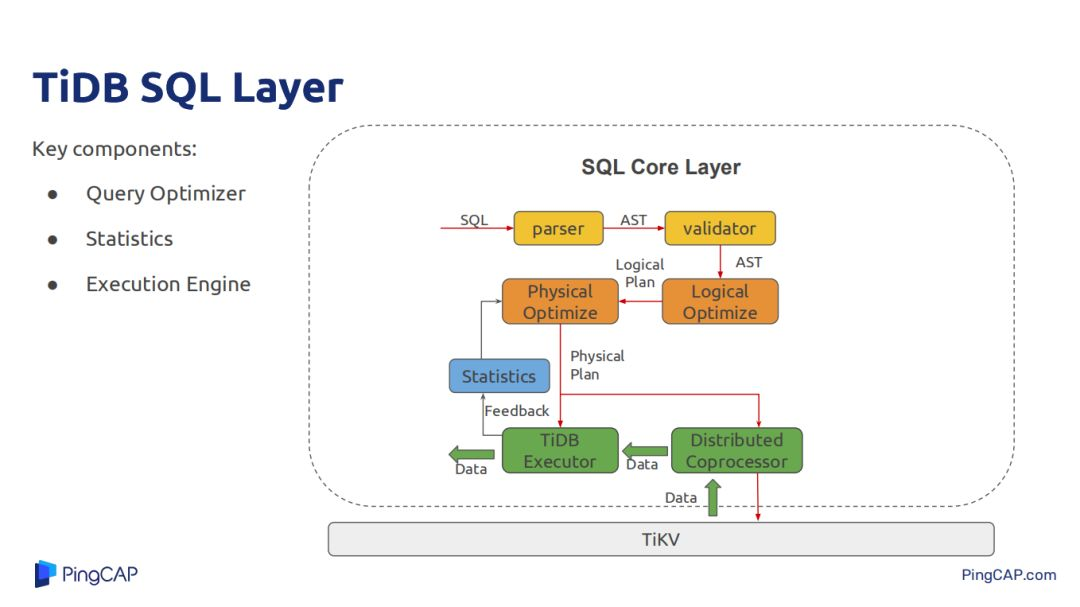
今天主要介紹SQL經過parser 再經過AST,然後Optimize,經過TiDB的SQL執行引擎,還有經過Tikv提供的Coprocessor,Coprocessor支持簡單的表達式計算、data scan、聚合等。Tikv能讓TiDB將一些大量操作都下推到Tikv上,減少Tikv與TiDB的數據交互帶來的網路開銷,也能讓一部分計算在Tikv上分散式並行執行。
--
02 Query Optimizer
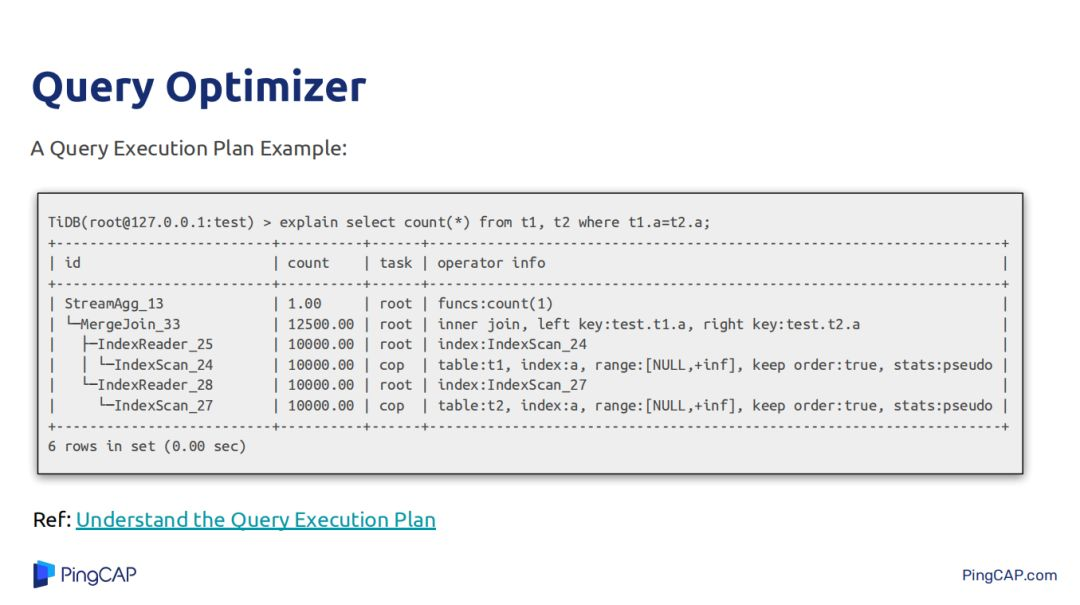
上圖中的執行計劃比較簡單,就是兩個表做join,然後對join的結果做count(*),join方式是merge join。
查詢優化器解決的工作很複雜,比如需要考慮運算元的下推,比如filter的下推,儘量下推到數據源,這樣能減少所有執行數據的計算量;還有索引的選擇,join Order和join演算法的選擇,join Order指的是當有多個表做join時以什麼樣的順序去執行這些join,不同的join Order意味著有不同大小的中間結果,而且join Oder也會去影響某一些join節點演算法的選擇;還有子查詢的優化,如硬子查詢是將其優化成inner join還是嵌套的方式去執行硬子查詢而不去join,這些在各種場景中因為數據源的分佈不同,每一種策略都會在一種場景中有它自身的優勢,需要考慮的方面很多,實現起來也比較困難。

優化器進行優化邏輯複雜,進行優化需要進行一些比較重的計算,為了降低一些不必要的計算。比如對一些簡單的場景點查,根據一些組件查一條數據,這種就不需要經過特別複雜的計算,這種需要提前標記出來,直接將索引的唯一值ID解析出來,變成一次k-v scan,這種就不需要做複雜的優化,不用去做執行樹的迭代。目前TiDB中的update、delete 、scan都支持k-v scan,還有PointGet Plan也支持這種優化。
TiDB的SQL優化器分為物理優化階段和邏輯優化階段,邏輯優化階段的輸入是一個邏輯優化執行計劃,有了初始邏輯優化執行計劃後,TiDB的邏輯優化過程需要把這個邏輯執行計划去應用一些rule,每一個rule必須具備的特點是輸出的邏輯執行計劃與輸出的邏輯執行計劃在邏輯上是等價的。邏輯優化與物理優化的區別是邏輯優化區別數據的形態是什麼,是先join再聚合還是先聚合再join,它並不會去聚合運算元是stream聚合還好hash聚合,也不會去關註join運算元是哪一種物理運算元。同時也要求rule將產生的每一個新的邏輯執行計劃一定要比原來輸入的邏輯執行計劃要更優,如將一些運算元下推到數據源比不下推下去要更優,下推後上層處理的數據量變少,整體計算量就比原來少。

接下來就講一下TiDB中已經實現的一些邏輯優化規則,如Column Pruning就是裁減掉一些不需要的列,Partition Pruning針對的是分區表,可以依據一些謂詞掃描去掉,Group By Elimination指的是聚合時Group By 的列是表的唯一索引時可以不用聚合。Project Emination是消除一些中間的沒用的一些投影操作,產生的原因是在一些優化規則以自己實現簡單會加一些Project ,還有就是從AST構造到最初邏輯執行計劃時也會為了實現上的簡單會去添加一些中間節點的投影操作,Outer Join Simplification主要針對null objective,如A>10,而A有又是null而且又是inner表中的列時,Outer Join就可以轉化為inner join。


Max/Min Eliminatation在有索引的時候非常有用,如Max A是一個索引列,直接在A上做一個逆序掃第一行數據就可以對外返回結果,頂層還有一個Max A,這個是為了處理join異常情況,如Max和count對空輸入結果值行為結果是不一樣的,需要有一個頂層的聚合函數來處理異常情況,這樣就不需要對所有數據做max,這樣做的好處就是不用做全表掃描。
Outer Join Elimination可以將其轉化為只掃描Outer 表,比如當用戶只需要使用Outer Join 的Outer表,如例子中只需要t1表中的數據,如何inner表上的key剛好是inner表上的索引,那麼這個inner表就可以扔掉,因為對於outer表中的每一條數據如果能join上,只會和inner表的一行數據join上,因為inner表上的key是唯一值,如果對應不上就是null,而返回的數據只需要outer表,inner表上的數據不需要。還有一種情況是父節點只需要outer表的唯一值,再做outer join如果對應上會膨脹很多值,而上層只需要不同值這樣就不需要膨脹,這樣就可以消除在outer表做一個select的distinct操作。

Subquery Decorrelation是一個多年研究的問題,上圖例子是先從t1表中掃一行數據,去構造t2表的filter,然後去掃描t2表中滿足這樣的數據,對t2表的A做一個聚合,最終是t1表的A類數據小於求的和,才把t1表的這行數據輸出。如果執行計劃按照上述邏輯執行,那麼每一行t1的值都會對t2進行全表掃描,這樣就會對集群產生非常大的負擔,也會做很多無用的計算。因此可以將優化成先聚合再join,就是先把t2表先按過濾的條件的列做一個group by,每一個group求t2表A的和,將其求得的和再去和t1表做join。上層的arcconditon,這樣就不會對inner表頻繁的做inner操作,從整體上看不用做全表掃描,每一行outer都會對t2表做掃描。

聚合下推不一定要優,但在某些場景很有用。兩個表做join,以上面一個表為例,join的結果以t1的a做一個group by。如果t1表的t1.a列重覆的值很多,先去做join就會導致重覆的值和t2表能夠匹配的值重覆很厲害,再去做聚合計算量也非常大,有一種策略是將聚合下推到t1表上。將t1表上a做一個聚合,很多重覆的t1.a再join之間就壓縮成一條,join操作的計算量非常輕,在更上層的聚合相應減輕不少負擔。但是不一定每種情況都有用,如果t1.a中的數據重覆值不多,那麼下推下去的聚合將數據過濾一遍又沒有起到聚合的效果。Top N Limit Push Down只需要將其outer join push到outer端,這是因為outer表的數據要輸出,只需要拿三條數據和inner表做join,如果有膨脹,再放一個top/limit將數據只限制在三條。相反如果將topN不push下去,那麼從table3讀取的數據會很大。

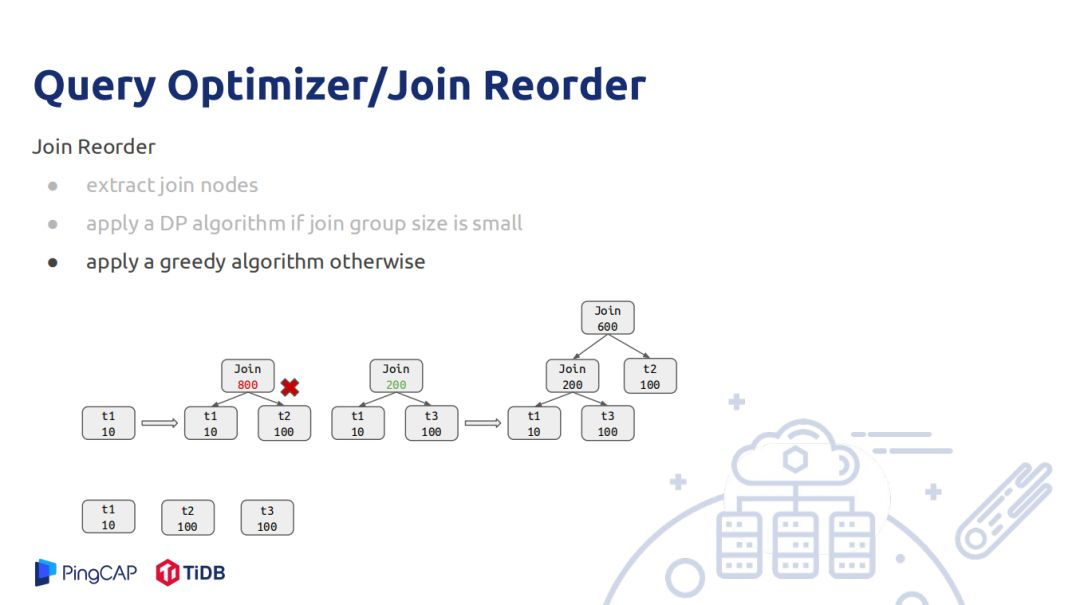
還有一個難題是Join Reorder,目前Join Reorder的演算法有很多。統計信息精準度一定的情況下,選出一個最好的Join Reorder演算法最好的方式是用DP演算法。如果兩者信息精確,利用動態規劃得出的演算法一定是最優的,但是現實中統計信息不一定優,如兩張表信息是優但是join後的結果不一定符合數據真實分佈,可能有推導誤差。A、B統計節點是推導出來的,再去推導節點的統計信息,誤差就被放大,因此DP的join order在使用真實的統計信息做join order再去推導統計節點的統計信息所做出來的order也不一定是好的。
在TiDB中使用的join order是一個子樹,使用狀態壓縮的方式做的,就是6的整數用二進位的形式表示110, 0表示節點不存在,1表示節點存在,第1、2節點存在,第0號節點不存在。就決定了最優的join順序是什麼,這樣DP演算法推導就比較簡單,不斷的枚舉其子集合,6可以分為110和10,分別join兩個子集合,選擇所有情況中最小的一個;這種方式時間複雜度很高,如果節點過多,做join reorder的時間會很長。還有DP演算法是用整數代替join節點,如果10個節點就是210,20個節點就是1M記憶體。因此當節點比較大的時候採用貪心策略做join reorder,實現原理是先將所有的join recount估算,從小打到大排序,一次選擇按邊相連的節點去做join,如圖一開始初始是t1和t2做join結果估算有800,由於t3的count也是100,也需要考慮t1和t3做join,join出來是200,則t1和t3優先做join,然後再遍歷節點數後最小的節點與當前join數做join,當為join節點集合為空時整個join樹就生成了。但是局部最優不一定全局最優,並不能把所有情況都考慮最好的join順序。

接下來是物理優化階段,邏輯優化並不決定以什麼演算法去執行,只介紹了join順序,並沒有說要用那種join方式。物理優化需要考慮不同的節點,不同的演算法對輸入輸出有不同的要求,如hash和merge join實現的時間複雜度本身不一樣。要理解物理優化的過程要理解什麼是物理屬性。物理屬性是一個物理演算法所具備的屬性,在TiDB就有task type屬性,就是這個演算法是應該在TiDB中執行還是在Tikv中執行;data order說的是演算法所產生的數據應該以什麼樣的順序屬性,如merge join是按outer join的key有序的。Stream聚合也是按照group by的column有序。但是有些演算法無法提供join順序,如hash join,還會破壞數據的順序,hash join無法對外提供任何順序上的保證。在分散式場景中做執行計劃時需要考慮分佈的屬性,如hash join在一個分式的節點上執行,考慮的是選表多下搜的方式,如果想正確出結果最好的方式是將小表和大表的數據都按照join的key下放到不同的機器上,那麼分散式的hash join特點就是join的key分佈在同一臺機器上。在TiDB沒有考慮數據分佈的特性,動態規劃的狀態就是輸入的邏輯狀態是什麼,實現的邏輯執行計劃的物理執行計劃需要滿足什麼樣的物理屬性,最後推導出一個最佳的物理執行計劃。這樣同一個邏輯節點可能會多次被父節點以不同路勁訪問它,因此需要緩存中間節點,下次父節點以同樣的動態規劃狀態訪問直接將之前最佳的結果返回就行。
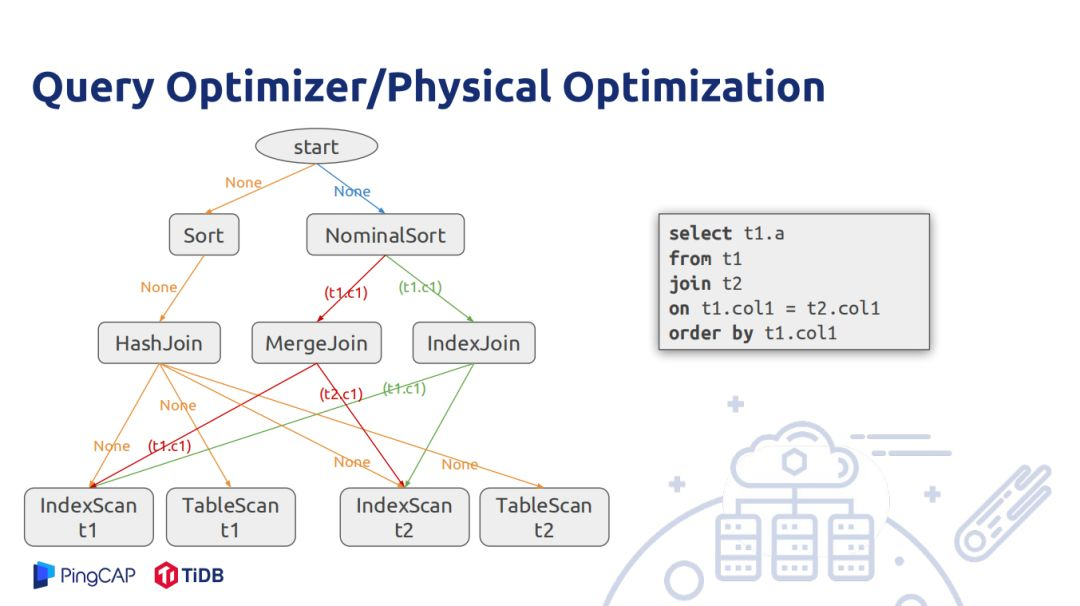
上圖的實例是對兩個表做join,join後數據按照join key排序,假設t1和t2表都在各自的join key上有索引,對於t1和t2表掃描有兩種方式,一種是index scan能夠滿足返回的數據以index有序,或者table scan不能滿足index scan有序,nominalsort是TiDB內部優化運算元,既不會出現在邏輯執行計劃裡面也不會出現物理執行計劃裡面,只是在做物理執行計劃輔助作用,從一開始調用動態規划過程,輸入邏輯計劃要求滿足的物理屬性是空,接下來可以用物理sort運算元和nominalsort運算元,其本身不 排數據,而是將排數據的功能傳遞給子節點。

在物理優化中比較重要的一點是如何選擇索引,沒有索引一個慢查詢會導致所有集群都慢。最後引入Skyline index Pruning,當要選擇那個選項最優時有多個維度可以考量,訪問一個表的方式有多種方式選擇,其要求就是父節點要求子節點返回的數據是否有序,還有就是索引能夠覆蓋多少列,這是因為用戶建索引並不是一定按照最優解來建。
從優化過程來說,演算法並不是最優的,應用完一個rule不會再次去應用,但是實際是會多次使用的。解決有Memo優化,就是將所有表達式存儲,將等價表達式存儲於一個group裡面,將所有rule用最小化、原子化做group expression。
--
03 Statistics
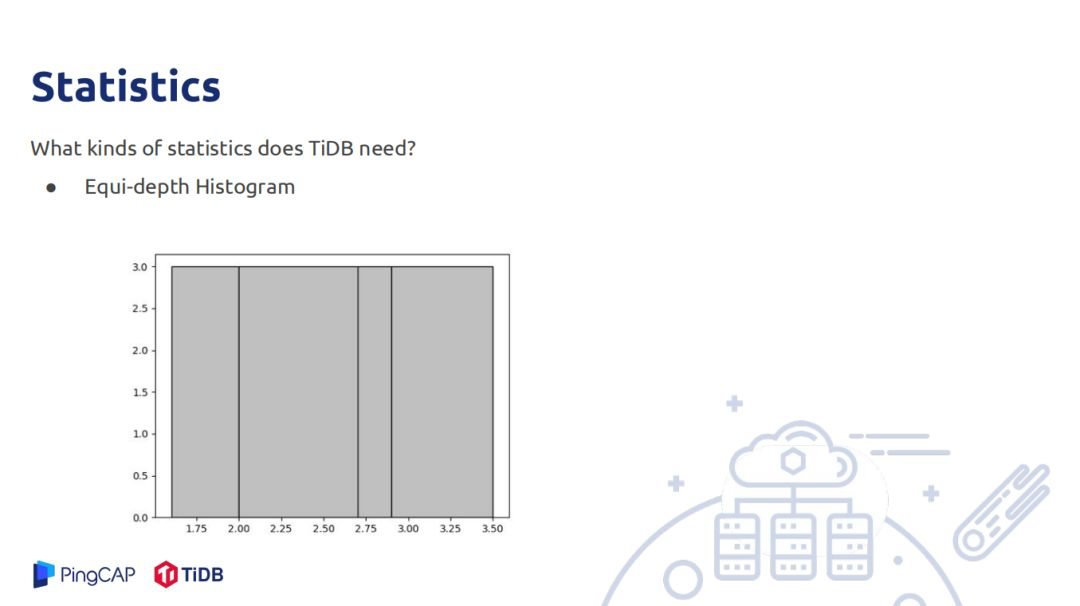
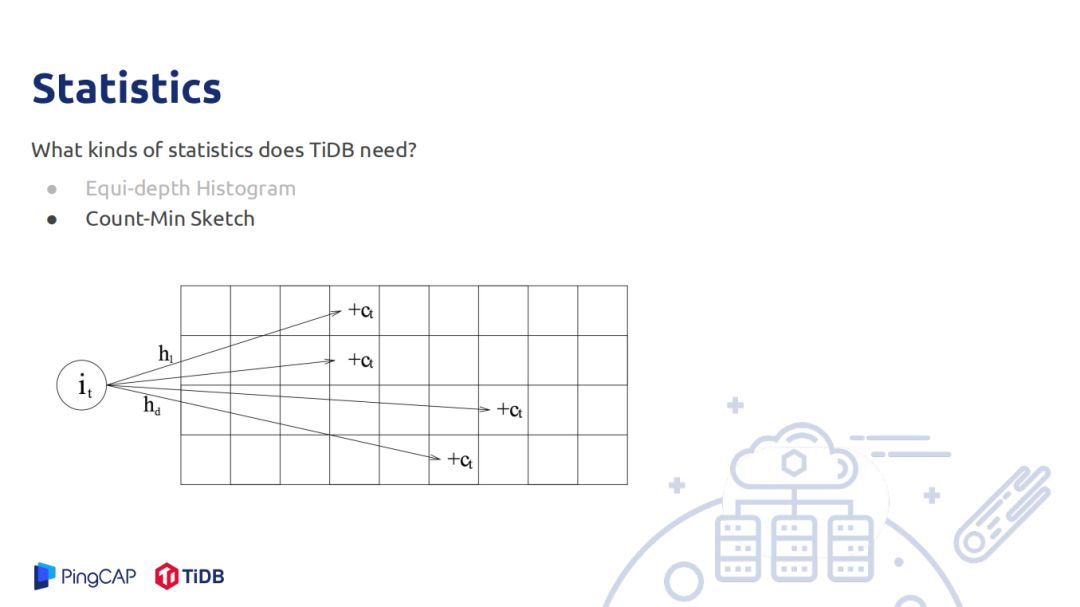
統計信息是用來估算row count,需要估算的row count有filter、join、聚合。TIDB中存儲的統計信息有直方圖,主要用於估算範圍查詢的統計信息,被覆蓋的其count直接加上去,部分覆蓋的桶使用連續均勻分佈的假設,被覆蓋的部分乘以桶的rowcount加上去;另一個是估算點查詢的rowcount,可以理解Min-Sketch,只是估算的值不再是0和1,數據代表是這個位置被hash到了多少次,如一個數據有D個hash函數,將其hash到D的某個位置,對具體位置加上1,查詢也做同樣的操作,最後取這D位置最小的值作為count估計,這個估計在實際中精度較高。
TiDB收集統計信息的方式有很多,首先手動執行analyze語句做統計信息的搜集;也可以配置自動analyze,就是表的更新超過某些行數會自動做analyze;還有Query Feedback,就是在查詢請求,如果查的數據分佈和以前統計的數據分佈信息不太匹配回去糾正已有的統計信息。
--
04 Future Work

接下來一些工作就是查詢計劃的穩定性,重要的是索引的準確,還有就是有些演算法的選擇也會影響查詢計劃的穩定性;The Cascades Planner就是要解決搜索空間的搜索演算法的效率問題,搜索空間導致執行計劃不夠優的問題。還有快孫analyze,目前表以億起步,如果現場採樣,會比較慢因此會採取一些手段加速analyze過程。Multi-Column Statistics主要生死用來解決多列之間的相關性,以前做row count估算都是基於column與column間的不相關假設做row count,這樣估計的值比實際值偏大,有多列相關估算準確度會提高很多。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號“DatafFunTalk”
歡迎轉載分享,轉載請留言或評論。


