
MySQL 回表 五花馬,千金裘,呼兒將出換美酒,與爾同銷萬古愁。 一、簡述 回表,顧名思義就是回到表中,也就是先通過普通索引掃描出數據所在的行,再通過行主鍵ID 取出索引中未包含的數據。所以回表的產生也是需要一定條件的,如果一次索引查詢就能獲得所有的select 記錄就不需要回表,如果select ...
MySQL 回表
五花馬,千金裘,呼兒將出換美酒,與爾同銷萬古愁。
一、簡述
回表,顧名思義就是回到表中,也就是先通過普通索引掃描出數據所在的行,再通過行主鍵ID 取出索引中未包含的數據。所以回表的產生也是需要一定條件的,如果一次索引查詢就能獲得所有的select 記錄就不需要回表,如果select 所需獲得列中有其他的非索引列,就會發生回表動作。即基於非主鍵索引的查詢需要多掃描一棵索引樹。
二、InnoDB 引擎有兩大類索引
要弄明白回表,首先得瞭解 InnoDB 兩大索引,即聚集索引 (clustered index)和普通索引(secondary index)。
聚集索引 (clustered index)
InnoDB聚集索引的葉子節點存儲行記錄,因此, InnoDB必須要有且只有一個聚集索引。
- 如果表定義了主鍵,則Primary Key 就是聚集索引;
- 如果表沒有定義主鍵,則第一個非空唯一索引(Not NULL Unique)列是聚集索引;
- 否則,InnoDB會創建一個隱藏的row-id作為聚集索引;
普通索引(secondary index)
普通索引也叫二級索引,除聚簇索引外的索引都是普通索引,即非聚簇索引。
InnoDB的普通索引葉子節點存儲的是主鍵(聚簇索引)的值,而MyISAM的普通索引存儲的是記錄指針。
三、回表示例
數據準備
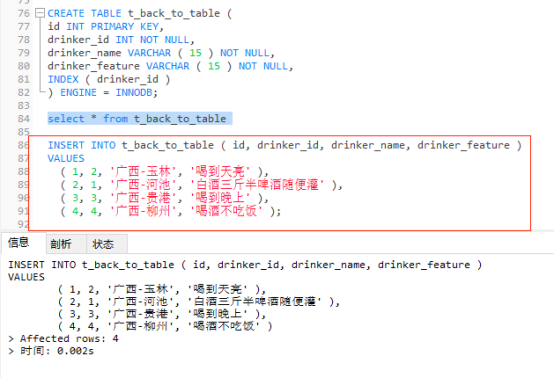
先創建一張表 t_back_to_table ,表中id 為主鍵索引即聚簇索引,drinker_id為普通索引。
CREATE TABLE t_back_to_table ( id INT PRIMARY KEY, drinker_id INT NOT NULL, drinker_name VARCHAR ( 15 ) NOT NULL, drinker_feature VARCHAR ( 15 ) NOT NULL, INDEX ( drinker_id ) ) ENGINE = INNODB;
再執行下麵的 SQL 語句,插入四條測試數據。
INSERT INTO t_back_to_table ( id, drinker_id, drinker_name, drinker_feature ) VALUES ( 1, 2, '廣西-玉林', '喝到天亮' ), ( 2, 1, '廣西-河池', '白酒三斤半啤酒隨便灌' ), ( 3, 3, '廣西-貴港', '喝到晚上' ), ( 4, 4, '廣西-柳州', '喝酒不吃飯' );
NO回表case
使用主鍵索引id,查詢出id 為 3 的數據。
EXPLAIN SELECT * FROM t_back_to_table WHERE id = 3;
執行 EXPLAIN SELECT * FROM t_back_to_table WHERE id = 3,這條 SQL 語句就不需要回表。
因為是根據主鍵的查詢方式,則只需要搜索 ID 這棵 B+ 樹,樹上的葉子節點存儲了行記錄,根據這個唯一的索引,MySQL 就能確定搜索的記錄。
回表case
使用 drinker_id 這個索引來查詢 drinker_id = 3 的記錄時就會涉及到回表。
SELECT * FROM t_back_to_table WHERE drinker_id = 3;
因為通過 drinker_id 這個普通索引查詢方式,則需要先搜索 drinker_id 索引樹(該索引樹上記錄著主鍵ID的值),然後得到主鍵 ID 的值為 3,再到 ID 索引樹搜索一次。這個過程雖然用了索引,但實際上底層進行了兩次索引查詢,這個過程就稱為回表。
回表小結
- 對比發現,基於非主鍵索引的查詢需要多掃描一棵索引樹,先定位主鍵值,再定位行記錄,它的性能較掃一遍索引樹更低。
- 在應用中應該儘量使用主鍵查詢,這裡表中就四條數據,如果數據量大的話,就可以明顯的看出使用主鍵查詢效率更高。
- 使用聚集索引(主鍵或第一個唯一索引)就不會回表,普通索引就會回表。
四、索引存儲結構
InnoDB 引擎的聚集索引和普通索引都是B+Tree 存儲結構,只有葉子節點存儲數據。
- 新的B+樹結構沒有在所有的節點里存儲記錄數據,而是只在最下層的葉子節點存儲,上層的所有非葉子節點只存放索引信息,這樣的結構可以讓單個節點存放更多索引值,增大Degree 的值,提高命中目標記錄的幾率。
- 這種結構會在上層非葉子節點存儲一部分冗餘數據,但是這樣的缺點都是可以容忍的,因為冗餘的都是索引數據,不會對記憶體造成大的負擔。
聚簇索引
id 是主鍵,所以是聚簇索引,其葉子節點存儲的是對應行記錄的數據。
聚簇索引存儲結構

如果查詢條件為主鍵(聚簇索引),則只需掃描一次B+樹即可通過聚簇索引定位到要查找的行記錄數據。
如:
SELECT * FROM t_back_to_table WHERE id = 1;
查找過程:
聚簇索引查找過程
普通索引
drinker_id 是普通索引(二級索引),非聚簇索引的葉子節點存儲的是聚簇索引的值,即主鍵ID的值。
普通索引存儲結構
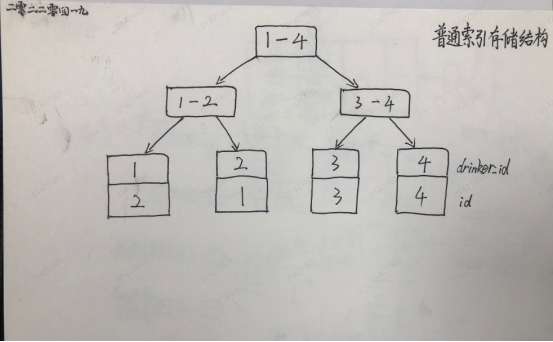
如果查詢條件為普通索引(非聚簇索引),需要掃描兩次B+樹。
- 第一次掃描先通過普通索引定位到聚簇索引的值。
- 第二次掃描通過第一次掃描獲得的聚簇索引的值定位到要查找的行記錄數據。
如:
SELECT * FROM t_back_to_table WHERE drinker_id = 1;
(1)第一步,先通過普通索引定位到主鍵值id=1;
(2)第二步,回表查詢,再通過定位到的主鍵值即聚集索引定位到行記錄數據。
普通索引查找過程

五、如何防止回表
既然我們知道了有回表這麼回事,肯定就要儘可能去防微杜漸。最常見的防止回表手段就是索引覆蓋,通過索引打敗索引。
索引覆蓋
為什麼可以使用索引打敗索引防止回表呢?因為其只需要在一棵索引樹上就能獲取SQL所需的所有列數據,無需回表查詢。
例如:SELECT * FROM t_back_to_table WHERE drinker_id = 1;
如何實現覆蓋索引?
常見的方法是將被查詢的欄位,建立到聯合索引中。
解釋性SQL的explain的輸出結果Extra欄位為Using index時表示觸發了索引覆蓋。
No覆蓋索引case1
繼續使用之前創建的 t_back_to_table 表,通過普通索引drinker_id 查詢id 和 drinker_id 列。
EXPLAIN SELECT id, drinker_id FROM t_back_to_table WHERE drinker_id = 1;
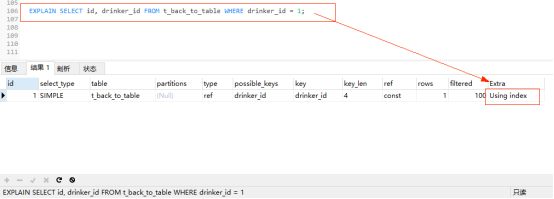
explain分析:為什麼沒有創建覆蓋索引Extra欄位仍為Using index,因為drinker_id是普通索引,使用到了drinker_id索引,在上面有提到普通索引的葉子節點保存了聚簇索引的值,所以通過一次掃描B+樹即可查詢到相應的結果,這樣就實現了隱形的覆蓋索引,即沒有人為的建立聯合索引。(drinker_id索引上包含了主鍵索引的值)
No覆蓋索引case2
繼續使用之前創建的 t_back_to_table 表,通過普通索引drinker_id查詢 id、drinker_id和drinker_feature三列數據。
EXPLAIN SELECT id, drinker_id, drinker_feature FROM t_back_to_table WHERE drinker_id = 1;
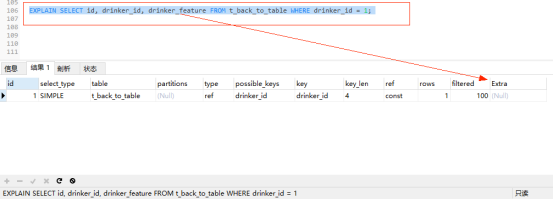
explain分析:drinker_id是普通索引其葉子節點上僅包含主鍵索引的值,而 drinker_feature 列並不在索引樹上,所以通過drinker_id 索引在查詢到id和drinker_id的值後,需要根據主鍵id 進行回表查詢,得到 drinker_feature 的值。此時的Extra列的NULL表示進行了回表查詢。
覆蓋索引case
為了實現索引覆蓋,需要建組合索引 idx_drinker_id_drinker_feature(drinker_id,drinker_feature)
#刪除索引 drinker_id DROP INDEX drinker_id ON t_back_to_table; #建立組合索引 CREATE INDEX idx_drinker_id_drinker_feature on t_back_to_table(`drinker_id`,`drinker_feature`);
繼續使用之前創建的 t_back_to_table 表,通過覆蓋索引 idx_drinker_id_drinker_feature 查詢 id、drinker_id和drinker_feature三列數據。
EXPLAIN SELECT id, drinker_id, drinker_feature FROM t_back_to_table WHERE drinker_id = 1;
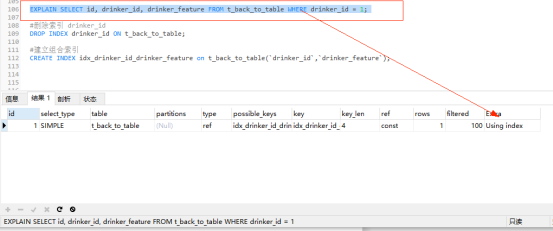
explain分析:此時欄位drinker_id和drinker_feature是組合索引idx_drinker_id_drinker_feature,查詢的欄位id、drinker_id和drinker_feature的值剛剛都在索引樹上,只需掃描一次組合索引B+樹即可,這就是實現了索引覆蓋,此時的Extra欄位為Using index表示使用了索引覆蓋。
六、索引覆蓋優化SQL場景
適合使用索引覆蓋來優化SQL的場景如全表count查詢、列查詢回表和分頁查詢等。
全表count查詢優化
#首先刪除 t_back_to_table 表中的組合索引 DROP INDEX idx_drinker_id_drinker_feature ON t_back_to_table; EXPLAIN SELECT COUNT(drinker_id) FROM t_back_to_table
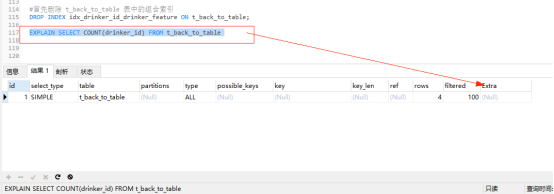
explain分析:此時的Extra欄位為Null 表示沒有使用索引覆蓋。
使用索引覆蓋優化,創建drinker_id欄位索引。
#創建 drinker_id 欄位索引 CREATE INDEX idx_drinker_id on t_back_to_table(drinker_id); EXPLAIN SELECT COUNT(drinker_id) FROM t_back_to_table

explain分析:此時的Extra欄位為Using index表示使用了索引覆蓋。
列查詢回表優化
前文在描述索引覆蓋使用的例子就是列查詢回表優化。
例如:
SELECT id, drinker_id, drinker_feature FROM t_back_to_table WHERE drinker_id = 1;
使用索引覆蓋:建組合索引 idx_drinker_id_drinker_feature on t_back_to_table(`drinker_id`,`drinker_feature`)即可。
分頁查詢優化
#首先刪除 t_back_to_table 表中的索引 idx_drinker_id DROP INDEX idx_drinker_id ON t_back_to_table; EXPLAIN SELECT id, drinker_id, drinker_name, drinker_feature FROM t_back_to_table ORDER BY drinker_id limit 200, 10;
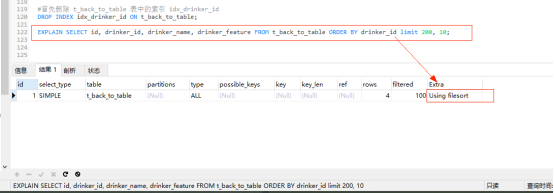
explain分析:因為 drinker_id 欄位不是索引,所以在分頁查詢需要進行回表查詢,此時Extra為U sing filesort 文件排序,查詢性能低下。
使用索引覆蓋:建組合索引 idx_drinker_id_drinker_name_drinker_feature
#建立組合索引 idx_drinker_id_drinker_name_drinker_feature (`drinker_id`,`drinker_name`,`drinker_feature`) CREATE INDEX idx_drinker_id_drinker_name_drinker_feature on t_back_to_table(`drinker_id`,`drinker_name`,`drinker_feature`);
再次根據 drinker_id 分頁查詢:
EXPLAIN SELECT id, drinker_id, drinker_name, drinker_feature FROM t_back_to_table ORDER BY drinker_id limit 200, 10;
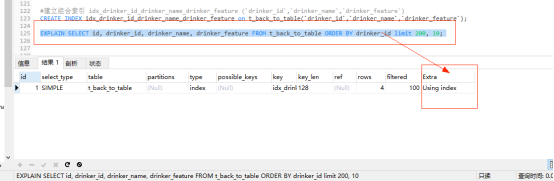
explain分析:此時的Extra欄位為Using index表示使用了索引覆蓋。
五花馬 千金裘 呼兒將出換美酒 與爾同銷萬古愁


