
開頭 看電影還在花錢?啥年代了?居然還有看電影花錢的,今天就給你上一課,讓你看看看電影是不需要花錢的。說乾就乾,衝衝 沖,代碼與實現思路就放在下麵了。 實現目的與思路 目的: 實現對騰訊視頻目標url的解析與下載,由於第三方vip解析,只提供線上觀看,隱藏想實現對目標視頻的下載 思路: 首先拿到想要 ...
開頭
看電影還在花錢?啥年代了?居然還有看電影花錢的,今天就給你上一課,讓你看看看電影是不需要花錢的。說乾就乾,衝衝
沖,代碼與實現思路就放在下麵了。

實現目的與思路
目的:
實現對騰訊視頻目標url的解析與下載,由於第三方vip解析,只提供線上觀看,隱藏想實現對目標視頻的下載
思路:
首先拿到想要看的騰訊電影url,通過第三方vip視頻解析網站進行解析,通過抓包,模擬瀏覽器發送正常請求,通過拿到緩存ts文
件,下載視頻ts文件,最後通過轉換為mp4文件,即可實現正常播放

完整代碼
Python ###Python學習交流Q群:906715085### import re import os,shutil import requests,threading from urllib.request import urlretrieve from pyquery import PyQuery as pq from multiprocessing import Pool ''' ''' class video_down(): def __init__(self,url): self.api='https://jx.618g.com' self.get_url = 'https://jx.618g.com/?url=' + url self.head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} self.thread_num=32 self.i = 0 html = self.get_page(self.get_url) if html: self.parse_page(html) def get_page(self,get_url): try: print('正在請求目標網頁....',get_url) response=requests.get(get_url,headers=self.head) if response.status_code==200: #print(response.text) print('請求目標網頁完成....\n 準備解析....') self.head['referer'] = get_url return response.text except Exception: print('請求目標網頁失敗,請檢查錯誤重試') return None def parse_page(self,html): print('目標信息正在解析........') doc=pq(html) self.title=doc('head title').text() print(self.title) url = doc('#player').attr('src')[14:] html=self.get_m3u8_1(url).strip() #self.url = url + '800k/hls/index.m3u8' self.url = url[:-10] +html print(self.url) print('解析完成,獲取緩存ts文件.........') self.get_m3u8_2(self.url) def get_m3u8_1(self,url): try: response=requests.get(url,headers=self.head) html=response.text print('獲取ts文件成功,準備提取信息') return html[-20:] except Exception: print('緩存文件請求錯誤1,請檢查錯誤') def get_m3u8_2(self,url): try: response=requests.get(url,headers=self.head) html=response.text print('獲取ts文件成功,準備提取信息') self.parse_ts_2(html) except Exception: print('緩存文件請求錯誤2,請檢查錯誤') def parse_ts_2(self,html): pattern=re.compile('.*?(.*?).ts') self.ts_lists=re.findall(pattern,html) print('信息提取完成......\n準備下載...') self.pool() def pool(self): print('經計算需要下載%d個文件' % len(self.ts_lists)) self.ts_url = self.url[:-10] if self.title not in os.listdir(): os.makedirs(self.title) print('正在下載...所需時間較長,請耐心等待..') #開啟多進程下載 p ool=Pool(16) pool.map(self.save_ts,[ts_list for ts_list in self.ts_lists]) pool.close() pool.join() print('下載完成') self.ts_to_mp4() def ts_to_mp4(self): p rint('ts文件正在進行轉錄mp4......') str='copy /b '+self.title+'\*.ts '+self.title+'.mp4' os.system(str) filename=self.title+'.mp4' if os.path.isfile(filename): print('轉換完成,祝你觀影愉快') shutil.rmtree(self.title) def save_ts(self,ts_list): try: ts_urls = self.ts_url + '{}.ts'.format(ts_list) self.i += 1 print('當前進度%d/%d'%(self.i,len(self.ts_lists))) urlretrieve(url=ts_urls, filename=self.title + '/{}.ts'.format(ts_list)) except Exception: print('保存文件出現錯誤') if __name__ == '__main__': #電影目標url:狄仁傑之四大天王 url='https://v.qq.com/x/cover/r6ri9qkcu66dna8.html' #電影碟中諜5:神秘國度 url1='https://v.qq.com/x/cover/5c58griiqftvq00.html' #電視劇鬥破蒼穹 url2='https://v.qq.com/x/cover/lcpwn26degwm7t3/z0027injhcq.html' url3='https://v.qq.com/x/cover/33bfp8mmgakf0gi.html' video_down(url2)
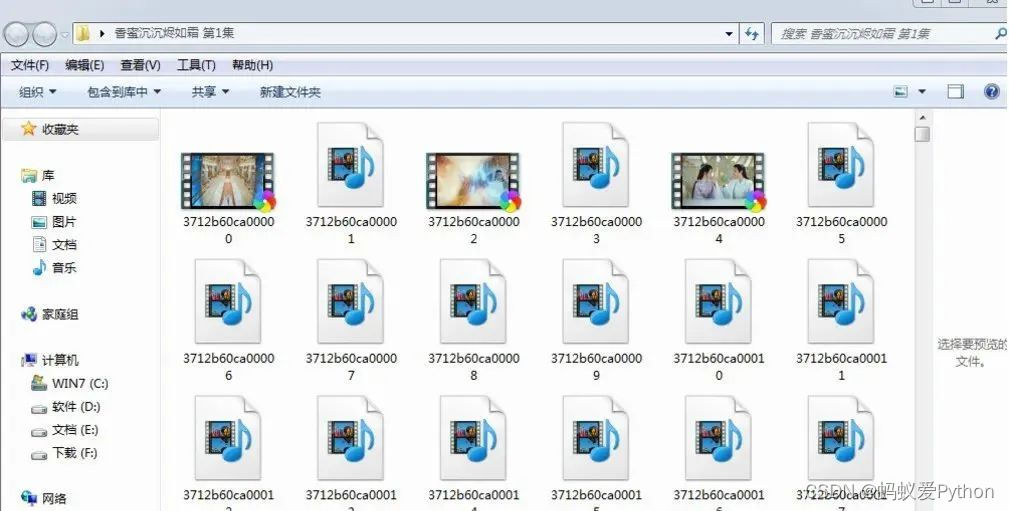
視頻緩存ts文件
這裡都是一些緩存視頻文件,每個只有幾秒鐘播放,最後需要合併成一個mp4格式的視頻,就可以正常播放,預設高清下載 。
註意這裡的進度因為使用多進程下載,進度僅供參考,沒有確切顯示進度,可以進文件夾查看正常進度,可以理解為顯示一次進
度,下載一個ts文件
實現效果

結尾
每日分享的小技能都學會了嗎?今天給大家分享的這個小技能還是特別有用的,畢竟看電影不花錢誰不心動,心動就要行動,馬
上就動手爬起來。喜歡的小伙伴記得點贊收藏,畢竟點贊的都是人美心善的。不懂的小伙伴記得評論留言,看到就給你回覆。當
然,你也可以私信我啦!!!



