
一. 歸併排序演算法簡介 歸併排序演算法是一種採用了分治策略的排序演算法。它通過遞歸地先使每個子序列有序,再將兩個有序的序列進行合併成一個有序的序列(也可以採用非遞歸的方式實現,效率更高一些)。歸併演算法是穩定和高效的排序演算法(適用於複雜對象(結構體)數列的穩定排序) 二. 演算法複雜度 最理想情況:O(nl ...
一. 歸併排序演算法簡介
歸併排序演算法是一種採用了分治策略的排序演算法。它通過遞歸地先使每個子序列有序,再將兩個有序的序列進行合併成一個有序的序列(也可以採用非遞歸的方式實現,效率更高一些)。歸併演算法是穩定和高效的排序演算法(適用於複雜對象(結構體)數列的穩定排序)
二. 演算法複雜度
最理想情況:O(nlogn)
最壞情況: O(nlogn)
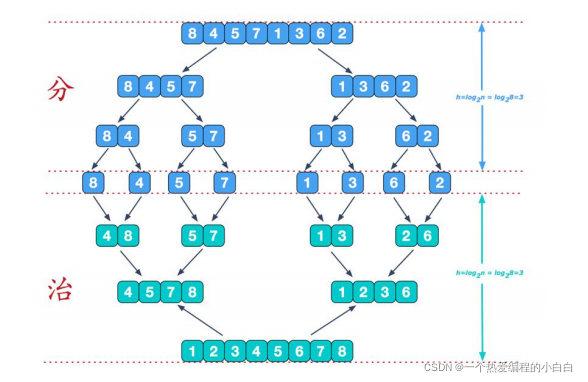
三. 演算法分治思路
- 將數組切片為相同長度的兩部分,長度為LEN的數組,分解為:兩個子數組,一個是 nums[0...LEN/2] 另一個是 nums[LEN/2+1...LEN]
- 遞歸的對兩個部分進行相同的切片操作,直到數組長度為1
- 對已經排好序的兩個切片進行合併操作
五. 演算法實現
5.1 遞歸實現
package main import ( "fmt" )func mergeSort1(array []int) []int { arrLen := len(array); if arrLen < 2 { return array; } i := arrLen >>1; leftSub := mergeSort1(array[0:i]); rightSub := mergeSort1(array[i:]); result := merge1(leftSub, rightSub); return result; }
func merge1(left []int, right []int) []int { m := len(left); n := len(right); result := make([]int, m+n, m+n); i, j, k := 0, 0, 0; for i < m && j < n { if left[i] <= right[j] { result[k] = left[i]; k++; i++; } else { result[k] = right[j]; k++; j++; } } if i == m { for j < n { result[k] = right[j]; k++; j++; } } if j == n { for i < m { result[k] = left[i]; k++; i++; } } return result; } 5.2 非遞歸實現 //merge sort using no recursion /**** // i: the begin index of old sub-array, j: the begin index of even sub-array
|<- k ->| |<- k ->| //case: k = 4 array [0,1,2,3] [4,5,6,7][8,9] ^ ^ ^ i j arrLen ****/
//merge sort using no recursion func mergeSort2(array []int){ arrLen := len(array); if arrLen <= 0 { return; }
list := make([]int, arrLen, arrLen); source := &array; target := &list; flag := 0;
// k is the arrLength of sub-array,k=1,2,4,... for k:= 1; k < arrLen; k <<=1 { if flag == 1{ source = &list; target = &array; } else { source = &array; target = &list; } flag = 1 - flag; //i, j is the begin index of sub-array i, j := 0, k; for n:= 0 ; n < arrLen; { p, q:= i, j; pEnd := i + k; if pEnd > arrLen { pEnd = arrLen; } qEnd := j + k; if qEnd > arrLen { qEnd = arrLen; } for (p < pEnd) && (q < qEnd) { if (*source)[p] <= (*source)[q] { (*target)[n] = (*source)[p]; n++; p++; } else { (*target)[n] = (*source)[q]; n++; q++; } } //copy the left data of sub_array indexed by q if p >= pEnd { for q < qEnd { (*target)[n] = (*source)[q]; n++; q++; } } //copy the left data of sub_array indexed by p if q >= qEnd { for p < pEnd { (*target)[n] = (*source)[p]; n++; p++; } }
i += k << 1; j += k << 1; } } if flag == 1 { for r:=0; r < arrLen; r++ { array[r] = list[r]; } } }
func main() { arr := []int{9,4, 6, 8, 6, 30, 28, 2, 3, 50}; fmt.Println(arr);
sortArr := mergeSort1(arr); fmt.Println(sortArr);
mergeSort2(arr); fmt.Println(arr); } 說明,遞歸演算法容易理解,因為涉及到嵌套遞歸和臨時空間開銷,效率不高,在項目實踐中不建議使用;非遞歸演算法,採用自下向上從最小長度為1的子數組(子數組長度分別為:1,2,4,8,...直到大於原數組長度)開始歸併,直到歸併排序完成,效率很高,另外只申請了和原數組等長的臨時空間用於存儲中間歸併結果,空間開銷小。


