
##數據分析 ###數據清洗:缺失值處理、1刪除記錄 2數據插補 3不處理 ###數據在https://book.tipdm.org/jc/219 中的資源包中數據和代碼chapter4\demo\data\catering_sale.xls ###常見插補方法 ####插值法-拉格朗日插值法 根據 ...
數據分析
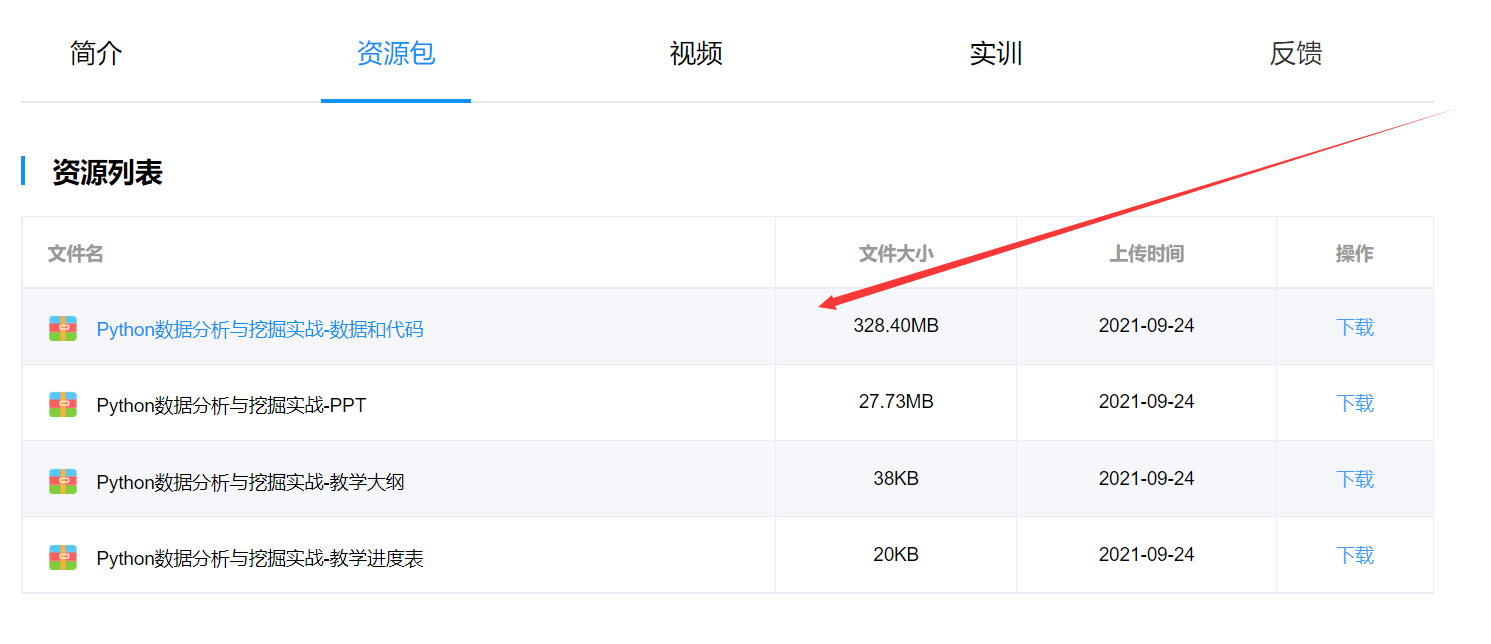
數據清洗:缺失值處理、1刪除記錄 2數據插補 3不處理
數據在https://book.tipdm.org/jc/219 中的資源包中數據和代碼chapter4\demo\data\catering_sale.xls
常見插補方法

插值法-拉格朗日插值法
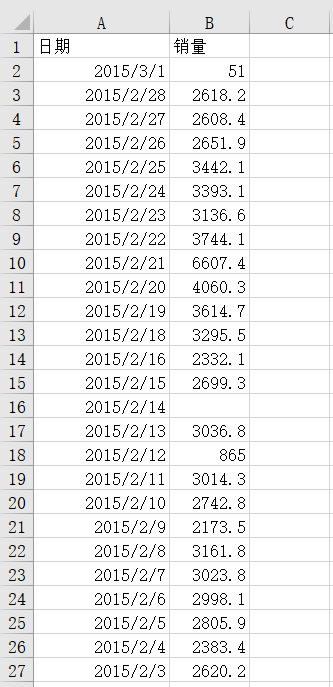
根據數學知識可知,對於平面上已知的n個點(無兩點在一條直線上可以找到n-1次多項式

,使次多項式曲線過這n個點。
1)求已知過n個點的n-1次多項式:
將n個點的坐標帶入多項式:得到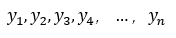
解出拉格朗日插值多項式: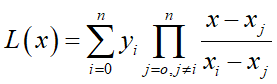
將缺失的函數值對應的點x帶入多項式得到趨勢值得近似值L(x)
#拉格朗日插值代碼
import pandas as pd #導入數據分析庫Pandas
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import lagrange #導入拉格朗日插值函數
inputfile = '../data/catering_sale.xls' #銷量數據路徑
outputfile = '../tmp/sales.xls' #輸出數據路徑
data = pd.read_excel(inputfile) #讀入數據
temp = data[u'銷量'][(data[u'銷量'] < 400) | (data[u'銷量'] > 5000)] #找到不符合要求得值 data[列][行]
for i in range(temp.shape[0]):
data.loc[temp.index[i],u'銷量'] = np.nan #把不符合要求得值變為空值
#自定義列向量插值函數
#s為列向量,n為被插值的位置,k為取前後的數據個數,預設為5
def ployinterp_column(s, n, k=5):
y = s.iloc[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取數 就是傳入得data
y = y[y.notnull()] #剔除空值
f = lagrange(y.index, list(y))
return f(n) #插值並返回插值結果
#逐個元素判斷是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果為空即插值。
data.loc[j,i] = ployinterp_column(data[i], j)
data.to_excel(outputfile) #輸出結果,寫入文件
print("success")
運行結果:

這個代碼是可以運行的
問題
沒有報SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame

我也不知道時怎麼把這個警告消除的,反正就是找啊找,在我不註意的時候能運行了!好像是不能一下多個賦值,要分開賦值。
最後
但是我們細看可以發現插入的值有問題:把插入的值輸出可以看到有一個異常值
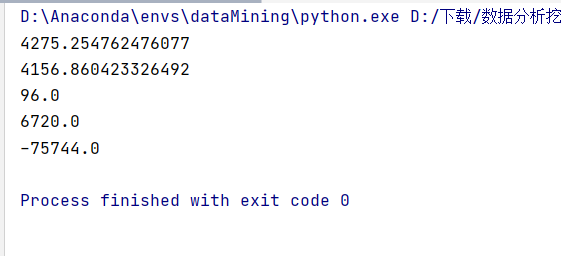
我們在處理數據時把小於400,大於5000的值都變成空值,然後通過拉格朗日插值法插入值,想要把數據沒有那麼大的差值,但是給我們插入一個負數,並且很離譜。我檢查了一下並沒有發現哪裡有錯誤;然後我把用到的數據和擬合出來的拉格朗日函數輸出得到:
f=-0.008874 x + 11.53 x - 6657 x + 2.242e+06 x - 4.854e+08 x + 7.005e+10 x - 6.74e+12 x + 4.168e+14 x - 1.504e+16 x + 2.411e+17
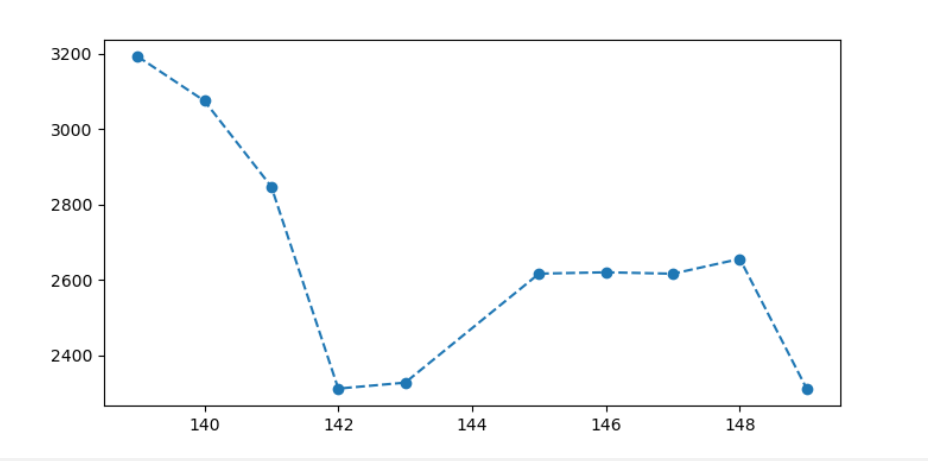
並沒有發現問題,讓後我就想著是不是擬合出來的函數步夠精確,我把取點增加,但是都沒有好的結果,反而更離譜,這種情況就是過擬合了,就是這個模型可以把你訓練的模型擬合的很好,但是測試模型並不好。
舉個例子:下麵一組數據可以看到用x4函數擬合的並沒有太多的點在模型上,x4函數擬合的相對較多一點,但是如果進行測試,14次方的模型可能會預測的很離譜:
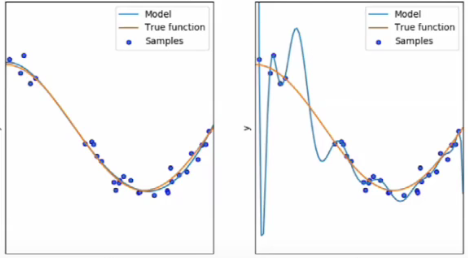
最後我把取值點減小發現上下取點4個時都會有一個好的結果,上下去點為3,2,1(直線,不建議取)時也都還能接受。所以我麽擬合出來的五個上下點時也並沒有錯,只是它擬合出來的函數就是在那個點上數值離譜。


