
存儲過程與函數 類似與Java的方法和C語言的函數 存儲過程概述 含義 一組經過預先編譯的SQL語句的封裝 執行過程:存儲過程預先存儲在MySQL伺服器上,客戶端發出命令後,伺服器可以把預先存儲好的SQL語句全部執行 好處 簡化操作,提高了SQL語句的通用性,減少開發程式員的壓力 減少操作中的失誤, ...
存储过程与函数
类似与Java的方法和C语言的函数
存储过程概述
含义
一组经过预先编译的SQL语句的封装
执行过程:存储过程预先存储在MySQL服务器上,客户端发出命令后,服务器可以把预先存储好的SQL语句全部执行
好处
- 简化操作,提高了SQL语句的通用性,减少开发程序员的压力
- 减少操作中的失误,提高效率
- 减少网络传输量
- 减少SQL语句暴露在网上的风险,提高了安全性
与视图、函数的对比

分类
- 没有参数(无参无返回)
- 仅仅有带IN类型(有参无返回)
- 仅仅有带OUT类型(无参有返回)
- 既带IN又带OUT类型(有参有返回)
- 带INOUT类型(有参有返回)
IN、OUT、INOUT都可以在一个存储过程中带多个
创建存储过程
语法分析

DELIMITER $ #以$作为结束符(相当于;的作用,存储过程体中有;会影响)
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型)
[characteristics...]
BEGIN
存储过程体;
END $
DELIMITER ; #还原以;为结束符


代码举例
无参与返回值
提起创建好数据库和表
#创建
DELIMITER $
CREATE procedure select_all_data()
begin
select *
from employees;
end $
DELIMITER ;
创建成功
#调用
CALL select_all_data();

无参有返回值(OUT)
#创建
DELIMITER $ #返回工资最低的员工
create procedure show_min_salary(OUT ms double)
begin
select min(salary) into ms #将min的工资给了ms
from employees;
end $
DELIMITER ;
#调用
CALL show_min_salary(@ms);
#查看变量值
SELECT @ms;
有参无返回值(IN)
DELIMITER $ #查看表中某个员工的工资,用IN输入员工名字
create procedure show_someone_salary(IN empname varchar(15))
begin
select salary
from employees
where last_name = empname;#传入的名字等于表中的名字
end $
DELIMITER ;
#调用
1.
CALL show_someone_salary('Abel');
2.
SET @empname := 'Abel';
CALL show_someone_salary(@empname);
有参有返回值(IN和OUT)
DELIMITER $ #查看表中某个员工的工资,用IN输入员工名字,用OUT输出
create procedure show_someone_salary2(IN empname varchar(15),OUT empsalary double)
begin
select salary into empsalary
from employees
where last_name = empname;
end $
DELIMITER ;
#调用
SET @empname := 'Abel'
CALL show_someone_salary(@empname,@empsalary);
#查看
select @empsalary;
有参有返回值(INOUT)
DELIMITER $ #查询某个员工领导的姓名,并用INOUT“empname”输入员工的名字,输出领导的名字
create procedure show_mgr_name(INout empname varchar(20))
begin
select t1.last_name into empname
FROM employees t1
where t1.employe_id = (select t2.manger_id
from employees t2
WHERE t2.last_name = empname;
);
end $
DELIMITER ;
#调用
SET @empname :='Abel';
CALL show_mgr_name(@empname);#体现IN
#查看
select @empname;#体现OUT
如何调试
逐步推进(一句一句的看)
存储函数的使用
系自定义的函数
语法分析
DELIMITER $
CREATE FUNCTION 函数名(参数名 参数类型)
RETURNS 返回值类型
[characteristics...]
BEGIN
函数体; #一定有return语句
END $
DELIMITER ;
- 只有IN类型(多进一出)
- return的类型要和返回值的类型一样
代码举例
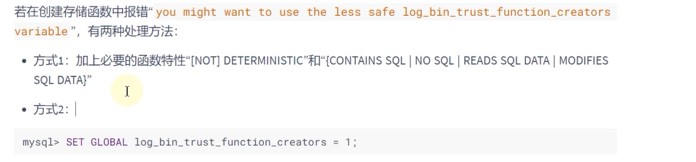
无参
mysql>SET GLOBAL log_bin_trust_function_creators = 1;#防止报错
#声明
DELIMITER $#查Abel的邮箱
CREATE FUNCTION email_by_name()
RETURNS carchar(20)
BEGIN
return(select email
from employees
where name = 'Abel'
);
END $
DELIMITER ;
#调用
EXISTS email_by_name();
有参
#参数传入emp_id,查询emp_id的email
#声明
DELIMITER $
CREATE FUNCTION email_by_id(emp_id int)
RETURNS carchar(20)
BEGIN
return(select email
from employees
where employe_id = emp_id
);
END $
DELIMITER ;
#调用
1.
EXISTS email_by_id('101');
2.
set @emp_id := '101';
EXISTS email_by_id(@emp_id);
#参数传入dept_id,查询该id部门的员工人数
#声明
DELIMITER $
CREATE FUNCTION count_by_id(dept_id int)
RETURNS int
BEGIN
return(select count(*)
from employees
where department_id = dept_id
);
END $
DELIMITER ;
#调用
set @dept_id = 30;
EXISTS count_by_id(@dept_id);
对比存储函数和存储过程
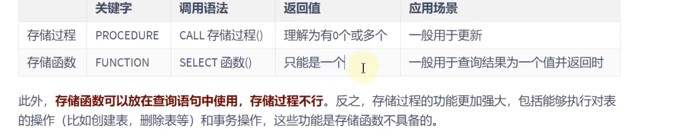
存储函数可以放在查询语句中使用,存储过程不可以
存储过程功能更强大,包括可以执行对表的操作和事务操作,这些是函数不具备的
存储过程和函数的查看、修改、删除
查看
创建完成之后,怎么知道我们创建的存储过程、存储函数是否成功呢
- 使用 SHOW CREATE 语句
SHOW CREATE PROCEDURE 存储过程\G
SHOW CREATE FUNCTION 函数名字\G
#\G在命令行中可以运行,若是MySQLbu不支持不支持,就用;
- 使用SHOW STATUS 语句
SHOW PROCEDURE STATUS LIKE '存储过程名'\G
SHOW FUNCTION STATUS LIKE '函数名字'\G
#\G在命令行中可以运行,若是MySQLbu不支持不支持,就用;
- 从information_schema.Routines表中查看
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME = '存储过程名' (AND ROUTINE_TYPE ='PROCEDURE')\G
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME = '函数名字' (AND ROUTINE_TYPE ='FUNCTION')\G
#\G在命令行中可以运行,若是MySQLbu不支持不支持,就用;
#若存储过程含函数重名,则写AND ROUTINE_TYPE ='类型'
查询效果
修改
修改存储过程或函数,不影响存储过程或函数的功能(不改存储过程\函数体),只是修改相关特性,使用 ALTER 语句实现
ALTER {PROCEDURE | FUNCTION} 存储过程\函数名 [characteristic...];

删除
使用 DROP 语句
DROP {PROCEDURE | FUNCTION} [IF EXISTS] 存储过程\函数名;
关于存储过程和函数的争议
有效公司对于大型项目需要使用存储过程\函数,而有的公司禁止使用
优点
- 存储过程\函数可以一次编译多次使用
- 减少开发的工作量(代码封装成块,可以重复使用)
- 提供良好的封装性
- 提供很好的安全性(可以设置权限)
- 减少网络传输
缺点
- 可移植性差
- 调试困难(有第三方进行调试,但要收费)
- 存储过程\函数版本管理困难
- 不适合高并发的场景


