
Apache Kafka 架構和相關概念 Apache Kafka 是一款開源的分散式消息引擎系統 消息引擎的同類 ActiveMQ RabbitMQ WebSphere MQ Rocket MQ JMS僅僅是一組 API 協議 消息引擎的作用 削峰填谷 緩衝上下游瞬時突發流量,使其更平滑.特別是對 ...
Apache Kafka 架構和相關概念
Apache Kafka 是一款開源的分散式消息引擎系統
消息引擎的同類
- ActiveMQ
- RabbitMQ
- WebSphere MQ
- Rocket MQ
- JMS僅僅是一組 API 協議
消息引擎的作用
削峰填谷
緩衝上下游瞬時突發流量,使其更平滑.特別是對於那種發送能力很強的上游系統,如果沒有消息引擎的保護,“脆弱”的下游系統可能會直接被壓垮導致全鏈路服務“雪崩”。
但是,一旦有了消息引擎,它能夠有效地對抗上游的流量衝擊,真正做到將上游的“峰”填滿到“谷”中,避免了流量的震蕩
解耦
使發送方與接收方松耦合,僅以協議的方式進行通訊,簡化了開發.
消息引擎使用方式
點對點
也叫消息隊列,每個消息只能被一個下游的消費者消費.
把消息發給多個處理者,方便擴展處理量,同時也意味著,當一個消費者消費了這條消息,這條消息就不存在了.別人無法消費
發佈/訂閱
把消息廣播給每個處理者.
由於每條消息都會傳遞給每個訂閱者,因此無法擴展處理。kafka的consumerGroup同時支持上述這兩種方式.
Kafka模型的優勢在於,每個主題都具有這兩個屬性-可以擴展處理範圍,並且是多用戶的-無需選擇其中一個。
KAFKA 拓撲結構圖
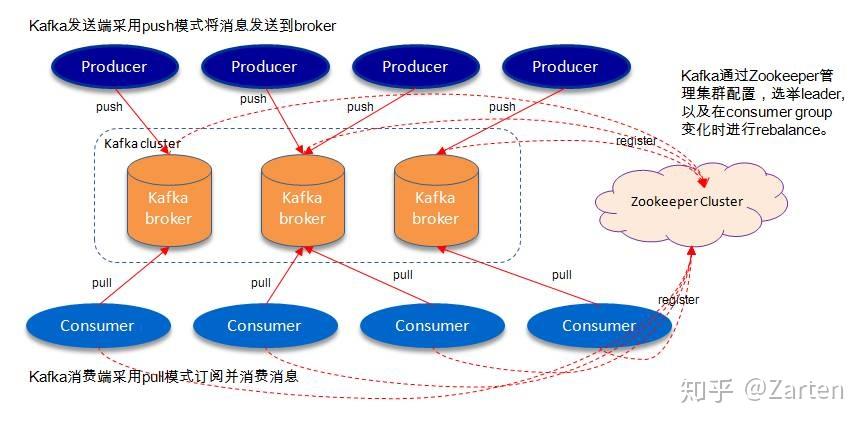
KAFKA 結構圖
KAFKA 概念
Broker
Broker 負責接收和處理客戶端發送過來的請求,以及對消息進行持久化, 一個 Kafka集群由多個
Broker 組成. 也可以理解為 KAFKA 伺服器
Client
分為生產者和消費者
- producer
向主題發佈消息的客戶端應用程式稱為生產者(Producer),生產者程式通常持續不斷地向一個或多個主題發送消息.
生產者負責選擇將記錄分配給主題中相應的分區。可以簡單地以輪循方式完成此操作,也可以根據某些語義分區功能(例如基於記錄中的某些鍵)完成此操作。
2. Consumer 訂閱這些主題消息的客戶端應用程式就被稱為消費者(Consumer)
消費者存在於消費者組中,主題的每條記錄都會傳遞到訂閱消費者組中的一個消費者實例。使用者實例可以位於單獨的進程中,也可以位於單獨的機器上。
Topic
發佈訂閱的對象是主題(Topic),可以是某個業務,某個應用甚至某類數據的邏輯分類.
Partitioning
每個分區都是有序的,不變的記錄序列,這些記錄連續地追加到結構化的提交日誌中.分區中的每個記錄均分配有一個稱為偏移的順序ID號,該ID
唯一地標識分區中的記錄。
Kafka中的分區機制指的是將每個主題劃分成多個分區(Partition),每個分區是一組有序的消息日誌。生產者生產的每條消息只會被髮送到一個分區中,也就是說如果向一個雙分區的主題發送一條消息,這條消息要麼在分區
0 中,要麼在分區 1 中。
每個主題下可以有多個分區.
分區的作用:
- 提供擴展性, TOPIC 下可以增加分區
- 提供並行性. 方便多個消費都並行處理
Replication
備份的思想很簡單,就是把相同的數據拷貝到多台機器上,而這些相同的數據拷貝在 Kafka 中被稱為副本(Replica)。
副本的數量是可以配置的,這些副本保存著相同的數據,但卻有不同的角色和作用。Kafka 定義了兩類副本:領導者副本(Leader Replica)和追隨者副本(Follower Replica)。前者對外提供服務,這裡的對外指的是與客戶端程式進行交互;而後者只是被動地追隨領導者副本而已,不能與外界進行交互。
副本的作用:
保證了 KAFKA 容錯能力
Producer
生產者:
向主題發佈新消息的應用程式。
生產者負責選擇將記錄分配給主題中的分區。可以簡單的以輪循的方式完成,也可以根據某些語義分區(例如基於記錄中的某些鍵)完成此操作。
客戶端程式只能與分區的領導者副本進行交互
Consumer
消費者
從主題訂閱新消息的應用程式。 消費都必須要在消費組中, Topic
對應的分區平均分配到消費組的中消費實例上.
Consumer Group
消費組
每個consumer屬於一個特定的consumer group,可為每個consumer指定group
name,若不指定,則屬於預設的group,一條消息可以發送到不同的consumer
group,但一個consumer group中只能有一個consumer能消費這條消息.
消費者與消費組的關係
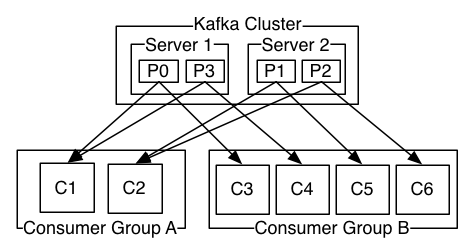
由兩台伺服器組成的Kafka群集,其中包含四個帶有兩個使用者組的分區(P0-P3)。消費者組A有兩個消費者實例,而組B有四個。
consumer group A中的C1 消費 P0和 P3分區的記錄
consumer group A中的C2 消費P1和P2分區的記錄
consumer group B有4個消費者,分別對應一個分區
Consumer Rebalance
消費者組裡面的所有消費者實例不僅“瓜分”訂閱主題的數據,而且更酷的是它們還能彼此協助。假設組內某個實例掛掉了,Kafka 能夠自動檢測到,然後把這個 Failed 實例之前負責的分區轉移給其他活著的消費者。
Offset
在 KAFKA 中,offSet有兩種含義
- 分區位移
消息的是分區內的消息位置,這個不變的.即一旦消息被成功寫入到一個分區上,它的位移值就是固定的了
- 消費者位移
是隨時變化的,是消費者消費進度的指示器。另外每個消費者有著自己的消費者位移.
Kafka與傳統消息引擎的對比:
點對點
傳統的消息隊列模型的特點在於消息一旦被消費,就會從隊列中被刪除,而且只能被下游的一個
Consumer 消費
發佈/訂閱
允許消息被多個 Consumer 消費,每個訂閱者都必須要訂閱主題的所有分區。
Kafka 僅僅使用 Consumer Group 這一種機制,卻同時實現了傳統消息引擎系統的兩大模型:如果所有實例都屬於同一個 Group,那麼它實現的就是消息隊列模型;如果所有實例分別屬於不同的 Group,那麼它實現的就是發佈 / 訂閱模型。
理想情況下,Consumer 實例的數量應該等於該 Group 訂閱主題的分區總數。
參考
極客時間
極客時間
apache kafka
Kafka架構圖


