
Elastic search 趣簡史 安裝 基礎知識 核心概念 ...
本文作為Elastic search系列的開篇之作,簡要介紹其簡要歷史、安裝及基本概念和核心模塊。
- 簡史
Elastic search基於Lucene(信息檢索引擎,ES里一個index—索引,一個索引指向一個或者多個分片—shards,一個分片就是一個Lucene實例。Lucene的作者——Doug Cutting同是也是hadoop的作者)。
ES的誕生於04年,Shay Banon——據傳剛失業又新婚,禍不單行(港蓉蒸蛋糕,蒸的嗎),在Lucene的基礎上為他去倫敦學廚師的老婆做的食譜搜索。一不小心,搞出了ES,然而老婆大人的食譜搜索卻遙遙無期,估計Shay在家鍵盤跪爛。
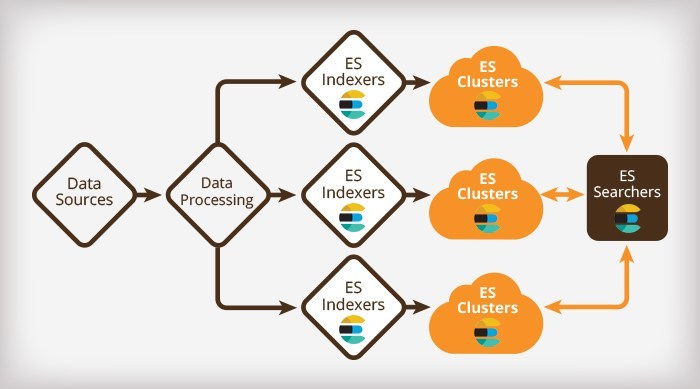
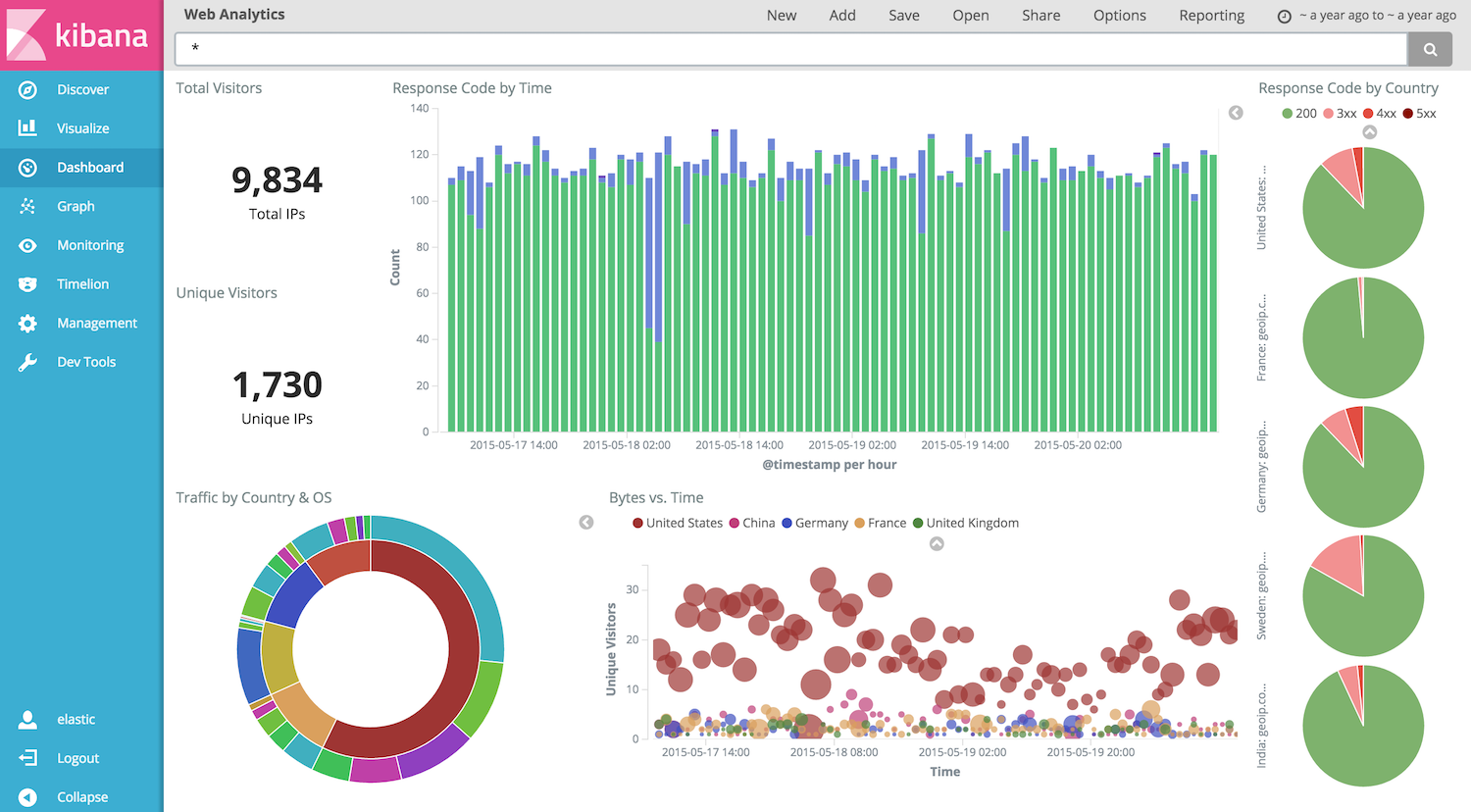
然後呢,官網出了個Kibana (ELK—Elasticsearch, logstash, kibana三劍客之一,另外Elastic認證瞭解一下——截止目前國內考過的不足500人),一個web應用程式,用圖表啊、地圖啊等面板來可視化數據(圖像天然具有親和力,詳見 Guide, 初步的安裝及說明詳見附錄5),如下圖:
- 安裝
windows上安裝Elastic search 請參考附註2 鏈接(需要安裝IK分詞器,以更好的支持漢語分詞;安裝elasticsearch-head ,簡單的可視化的web客戶端,可支持基本的查詢操作或者通過DSL檢索結果——為支持它,需要裝Node.js; node.js 又需要集成 npm 和 grunt)
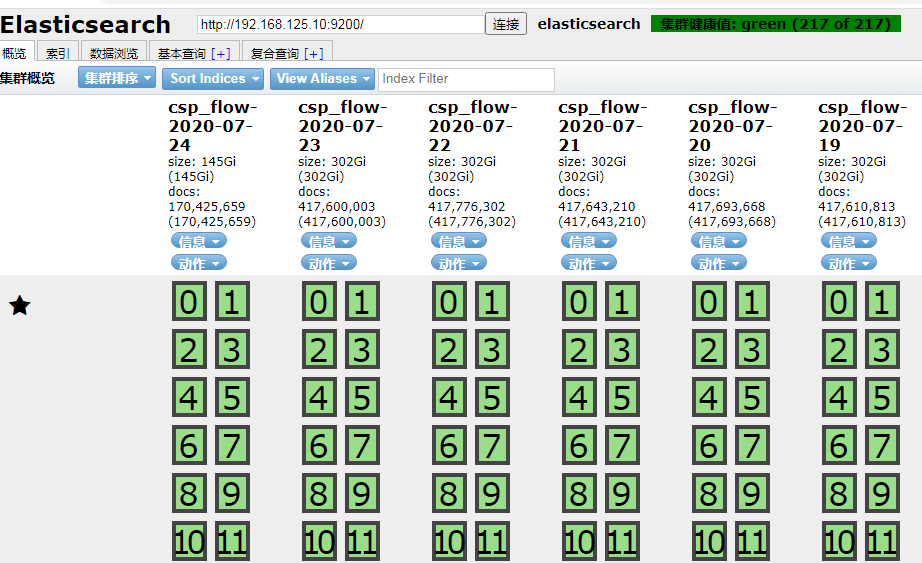
elasticsearch-head 效果如下圖:
- 核心概念
Elastic Search是一個實時分散式搜索和分析引擎,處理大數據相當的擅長。Stackoverflow、Github、Wiki以及英國衛報等在全文檢索、代碼搜索(Github超過1300億行)、地理位置查詢、社交網路實時數據等領域均廣泛深入的使用了ES,國內的位元組跳動、騰訊、阿裡、百度均有相關應用。目前認為其核心概念包括:
- Score
就是根據一套規則和演算法,滿足搜索條件的文檔,其中相關信息的匹配度(或稱之為相關度),打分越高,則匹配度越高,搜索結果按打分高低(匹配度)倒敘展示。如下圖的一個搜索結果:
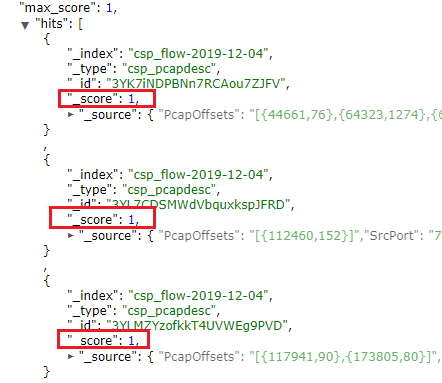
具體的Score,涉及到Norm(歸一化)和Boost(可以設置field和document的Boot—相當於權重的概念)
- 集群(Cluster)、節點(Node)和分片(shards)
集群即多台物理機構成,每個物理機包含多個節點(其中只有一個Master Node),每個節點包含多個分片,每個分片可以有0個或多個複製分片做必要的數據冗餘。其分散式特性,通過底層的如下操作自動完成:
(1)將你的文檔分區到不同的容器或者分片(shards)中,它們可以存在於一個或多個節點中。
(2)將分片均勻的分配到各個節點,對索引和搜索做負載均衡。 冗餘每一個分片,防止硬體故障造成的數據丟失。
(3)將集群中任意一個節點上的請求路由到相應數據所在的節點。
(4)無論是增加節點,還是移除節點,分片都可以做到無縫的擴展和遷移。
- 索引(Index)
Elastic Search使用倒排索引(Inverted Index)來做快速的全文搜索(不同於一般資料庫的索引,用B-Tree來實現)。具體倒排索引原理,可能需要單獨的一篇博客來說明
- 分詞(analysis)
分析(analysis)是這樣一個過程:
(1)首先,表徵化一個文本塊為適用於倒排索引單獨的詞(term)
(2)然後標準化這些詞為標準形式,提高它們的“可搜索性”或“查全率”
這個工作是分析器(analyzer)完成的。一個分析器(analyzer)包含如下三個功能:
(1)字元過濾器
首先字元串經過字元過濾器(character filter),它們的工作是在表徵化(譯者註:這個詞叫做斷詞更合適)前處理字元串。 字元過濾器能夠去除HTML標記,或者轉換 "&" 為 "and" 。
(2)分詞器
下一步,分詞器(tokenizer)被表徵化(斷詞)為獨立的詞。一個簡單的分詞器(tokenizer)可以根據空格或逗號將單詞分開 (譯者註:這個在中文中不適用)。
(3)表徵過濾
最後,每個詞都通過所有表徵過濾(token filters),它可以修改詞(例如將 "Quick" 轉為小寫),去掉詞(例如停用詞 像 "a" 、 "and"``"the" 等等),或者增加詞(例如同義詞像 "jump" 和 "leap" )
- 欄位共用
ES本質上和關係型資料庫還是有差別,並不能和DB的各個概念完全對應。預設同名的Fields在整個Indices共用,因此你不能在Type里定義同名的多個Filelds,導致刪除數據只能整個索引一起刪除,而不能單單刪除一個Type
- 基礎知識
- 文檔
Elastic search是面向文檔的,文檔歸屬於一種類型(type),而這些type存在(索引)index里。傳統關係資料庫和ES的簡單對比如下圖(6.0版本後預設支持single type,涉及欄位共用的優化):
| Relational DB | Databases | Tables | Rows | Columns |
| ElasticSearch | Indices | Types | Documents | Fields |
2.檢索文檔
支持HTTP的GET、PUT、HEAD、DELETE(由於欄位共用等原因,ES目前不支持刪除表,只能整個索引一起刪除)、POST操作,如下圖(故可直接用postman、SoapUI、Chrome插件ElasticSearch Head 等工具發http請求來查詢文檔):

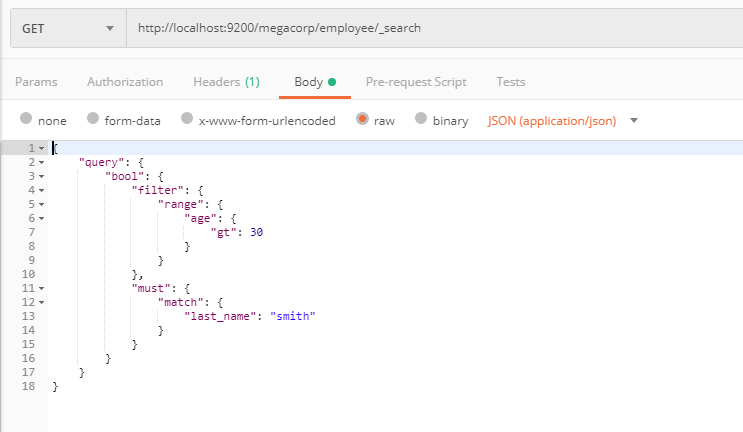
ES提供豐富靈活的查詢語句(另外Elasticsearch-sql插件可以自動將sql語句翻譯為DSL)——Query DSL(基本的語法有filter,bool—包括should【類似於Or】、must【類似於and】, term—精確匹配, match,range,exists,missing等),有了它構建複雜、強大的查詢都不事兒,如下圖(用postman,查詢 age > 30 且 last_name = "smith"):
3. 欄位數據類型
官方文檔:Mapping types (Mapping——映射,相當於關係資料庫的表結構定義)
- 核心數據類型 (只列工作中常用的):
| Data Types | Values |
| String | text, keyword |
| 數值類型(Numberic dataTypes) | long, integer, short, byte, double, float |
| 日期類型 | date |
| 布爾類型 | boolean |
| 範圍類型 | integer_range, float_range, long_range, double_range, date_range |
| 二進位類型 | binary |
- 複雜數據類型
| Data Types | Values |
| 數組類型 | 不需要特殊的數據類型支持 |
| Object type | object — 代表單個json |
| 嵌套類型 | nested — 代表一組json |
- 地理相關的數據類型
| Data Types | Values |
| 坐標點類型 | geo_point用來表徵經緯度 |
| 地理圖形類型 | geo_shape用來表徵複雜的形狀,如多邊形 |
- 專門的數據類型
| Data Types | Values |
| IP類型 | ip — 用於IPv4和IPv6(項目中高頻使用) |
| token數量類型 | token_count — 統計字元串中token的數量 |
- 尾聲
(1)ES不支持Join,但支持aggregations,類似於SQL的group by
(2)通過Merge segments可以提高查詢速度,最後Merge成的Segments個數越小,查詢時間提高的越快。Merge segments過程比較耗費磁碟和CPU,所以建議凌晨執行該操作
(3)ES支持將各種資料庫的數據導入,主要通過logstash;ES之間的數據拷貝,可以用elasticdump
致敬 Doug Cutting (Lucene、Nutch 、Hadoop之父)

談到成功,Cutting認為他的成功主要歸功於兩點:
- 對自己工作的熱情(Cutting在大學時就開始做Infrastracture類的程式,還用 Lisp為Emacs貢獻過代碼,他非常喜歡自己的程式被千萬人使用的感覺)
- 目標不要定得過大,要踏踏實實,一步一個腳印
附:
1) 官網guide 及對應中文版 — Elasticsearch: 權威指南(pdf下載)
2) Elasticsearch6.4.0-windows環境部署安裝
4) Hadoop 十歲生日時 Doug Cutting的講話
*******************************************************************************
精力有限,想法太多,專註做好一件事就行
- 我只是一個程式猿。5年內把代碼寫好,技術博客字字推敲,堅持零拷貝和原創
- 寫博客的意義在於打磨文筆,訓練邏輯條理性,加深對知識的系統性理解;如果恰好又對別人有點幫助,那真是一件令人開心的事
*******************************************************************************


