
對於sql優化,除了索引之外,執行計劃和統計信息是無法繞開的一個話題,如果sql優化(所有的RDBMS)脫離了統計信息的話就少了一個為什麼的過程,味道就感覺少了一大半。剛接觸Postgresql,粗淺地學習總結一下Postgresql相關的統計信息。 postgresql 進程模型 開始之前,有必要 ...
對於sql優化,除了索引之外,執行計劃和統計信息是無法繞開的一個話題,如果sql優化(所有的RDBMS)脫離了統計信息的話就少了一個為什麼的過程,味道就感覺少了一大半。
剛接觸Postgresql,粗淺地學習總結一下Postgresql相關的統計信息。
postgresql 進程模型
開始之前,有必要瞭解一下postgresql的進程結構。postgresql 進程模型,與MySQL或者SQLServer的單進程多線程機制不同,Postgresql為多進程模型,每個進負責特定的任務,同時每個進程自身有各自的運行或者喚醒機制。 相比單進程多線程的MySQL,各個子線程寄宿與主進程中的方式相比,postgresql這一點可以直觀地來描述每個進程以及其作用。 如下是一個Postgresql實例的所有進程信息,這裡僅關註autovacuum lancher和stat collector,後文會提交到這兩個進程。
 另:MySQL的單進程多線程服務模型,註:mysql_safe進程僅僅起到mysqld進程carsh後進程喚醒的作用,其他後臺功能以線程的形式寄宿在mysqld主進程。
另:MySQL的單進程多線程服務模型,註:mysql_safe進程僅僅起到mysqld進程carsh後進程喚醒的作用,其他後臺功能以線程的形式寄宿在mysqld主進程。 SQLServer的進程就太熟悉了,預設進程名稱就是實例名,預設MSSQL
SQLServer的進程就太熟悉了,預設進程名稱就是實例名,預設MSSQL
postgresql中的兩種“統計信息”
在MySQL或者SQLServer中,統計信息這個術語是描述數據分佈狀態的一種信息,由後臺線程或者人為命令觸發更新。 與SQLServer或者MySQL中的一些術語不同,postgresql中的stats分為兩類如下兩類 1,第一類是類似於SQLServer或者MySQL中的性能計數器和系統表,這些數據用來描述資料庫的負載,或者資料庫對象使用情況,SQLServer的性能計數器和各種系統表和DMV,或者MySQL中的performance_schema中的的信息 2,第二類是類似於SQLServer或者MySQL中的統計信息直方圖,用來描述數據的分佈,為優化器生成執行計劃提供依據。
這一類統計信息基本上等價於SQLServer或者MySQL中用來指導執行計劃的統計信息 “統計信息”在Postgresql中的含義,與SQLServer或者MySQL相比,第一類信息的稱呼上存在一些不同。
參考這裡:https://blog.pgaddict.com/posts/the-two-kinds-of-stats-in-postgresql
-
postgresql中的負載指標“統計信息”(Monitoring stats)
負載指標由上文提到的stats collector進程來實時收集更新。PostgreSQL的統計數據收集器是一個支持收集和報告伺服器活動信息的子系統。
目前,收集器可以計算對磁碟塊和單行項中的表和索引的訪問次數。
它還跟蹤每個表中的總行數,以及關於vacuum的信息,並分析每個表的操作。
同時還可以記錄基於sql語句執行的代價信息。這部分與該主題關係不大,就不展開詳述。
-
postgresql中的數據分佈狀態描述“統計信息”(Data distribution stats)
比如update statistics *** (***) with sample 30 percent,或者MySQL中的analyze table table_name 此外,基於postgresql的MVCC機制生成的“非活動數據”,更新可見性映射,凍結事務處理(保護老舊數據不會由於事務ID回捲或多事務ID回捲而丟失),也是由autovacuum 進程來清理,同時,還負責XID的清理工作。
有兩種VACUUM的變體:標準VACUUM和VACUUM FULL。
1,標準形式的VACUUM可以和生產資料庫操作並行運行(SELECT、INSERT、UPDATE和DELETE等命令將繼續正常工作,但在清理期間你無法使用ALTER TABLE等命令來更新表的定義)。
2,VACUUM FULL可以收回更多磁碟空間但是運行起來更慢,且vacuum full不會有後臺進程主從觸發(只能手動執行)。
另外,VACUUM FULL類似於表的重建或者說碎片整理,同時需要一個大小相當於原始表的額外空間。
要求在其工作的表上得到一個排他鎖,因此無法和對此表的其他使用並行。因此,通常管理員應該努力使用標準VACUUM並且避免VACUUM FULL。
大概列舉一下相關的系統表以及相關參數,簡述相關的含義。 如下為測試demo表以及測試數據的生成
create table myschema.table_test ( c1 serial primary key, c2 int, c3 varchar(100), c4 varchar(100), c5 timestamp ) create or replace function random_string(integer) returns text as $body$ select upper(array_to_string(array(select substring('0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' FROM (ceil(random()*62))::int FOR 1) FROM generate_series(1, $1)), '')); $body$ language sql volatile;
insert into myschema.table_test (c2,c3,c4,c5) select cast(random()*500000 as int),random_string(10),random_string(10), cast( now()-'1 min'::interval * random()*500000 as timestamp ) from generate_series(1,1000000)
postgresql中關於資料庫負載的統計信息
-
庫級別信息摘要
在庫級別,pg_stat_databases用來描述描述"庫"級別的摘要信息,包括庫名,當前庫事務提交次數,回滾次數,讀寫次數,死鎖等等信息。
這些信息可以觀察到到一個庫的負載情況和健康狀況。
-
表級別的信息摘要
在表級別,由pg_stat_user_tables來描述某個具體的表中的信息,包括增刪查改的次數,數據行等摘要信息。
這些信息可以衡量一個表的冷熱程度,活躍性,以及體量以及一些analyze時間相關的信息。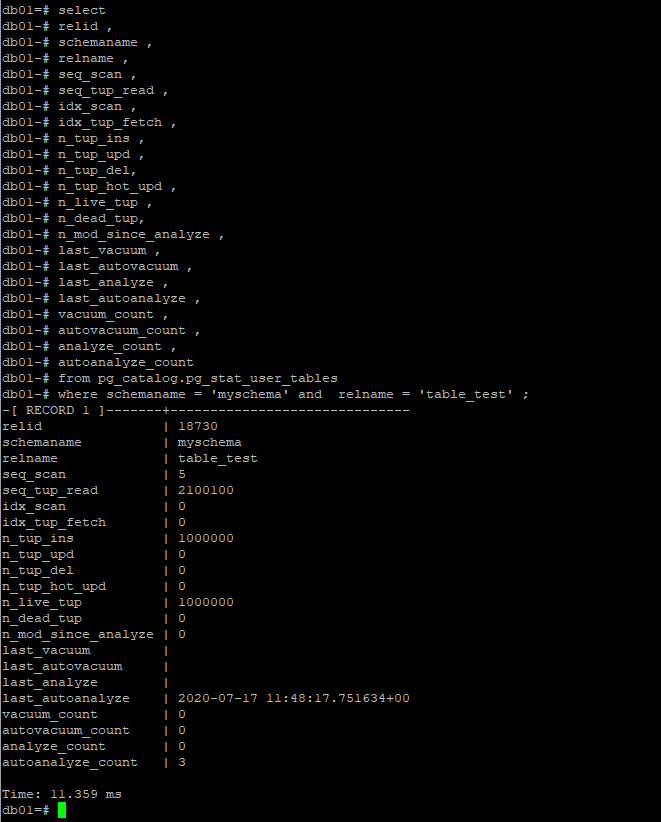
pg_class 來描述表的物理存儲信息,包括數據行數,數據頁的個數。
關於postgresql中的描述數據分佈統計信息
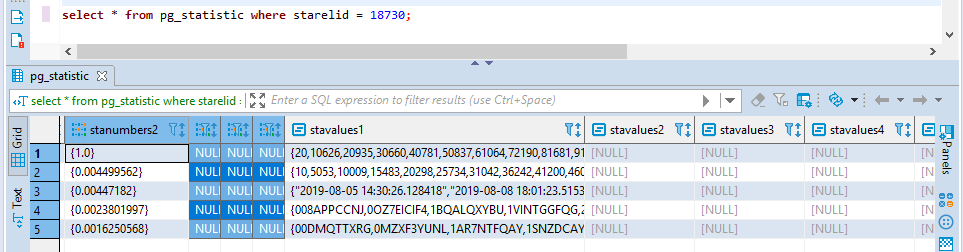
pg_stats用來描述一個表中所有的欄位的數據分佈信息,為執行計劃決策提供依據,與SQLServer的直方圖類似,熟悉的配方熟悉的味道,只有管理員賬號能夠訪問
類似於SQLServer的統計信息+直方圖,也即執行dbcc show_statistics(***,***)的效果,或者MySQL中的information_schema.column_statistics表中的信息(簡直一模一樣)。
這一點,SQLServer的直方圖用一種相對比較直觀的方式展示了出來。
select * from pg_stats WHERE tablename = 'table_test'; schemaname | myschema tablename | table_test attname | c1 inherited | f null_frac | 0 avg_width | 4 n_distinct | -1 most_common_vals | most_common_freqs | histogram_bounds | {15,9799,20037,30372,40276,……………………,990687,999949} correlation | 1 most_common_elems | most_common_elem_freqs | elem_count_histogram | schemaname | myschema tablename | table_test attname | c2 inherited | f null_frac | 0 avg_width | 4 n_distinct | -0.330106 most_common_vals | most_common_freqs | histogram_bounds | {23,4712,9677,14189,19403,………………490576,495541,499975} correlation | -0.00480835 most_common_elems | most_common_elem_freqs | elem_count_histogram | schemaname | myschema tablename | table_test attname | c5 inherited | f null_frac | 0 avg_width | 8 n_distinct | -0.993476 most_common_vals | most_common_freqs | histogram_bounds | {"2019-08-05 14:29:35.515329","2019-08-08 19:17:14.628418",……"2020-07-14 18:25:47.515329","2020-07-17 19:40:48.015329"} correlation | -0.00216757 most_common_elems | most_common_elem_freqs | elem_count_histogram | schemaname | myschema tablename | table_test attname | c4 inherited | f null_frac | 0 avg_width | 11 n_distinct | -1 most_common_vals | most_common_freqs | histogram_bounds | {0035UXPI6A,0N8JC5OIER,1BZZAU76H5,…………ZQSMJJRFWE,ZZZYYV9TKJ} correlation | -0.00186405 most_common_elems | most_common_elem_freqs | elem_count_histogram |
schemaname | myschema tablename | table_test attname | c3 inherited | f null_frac | 0 avg_width | 11 n_distinct | -1 most_common_vals | most_common_freqs | histogram_bounds | {000XXEZ4HN,0N3GEAC1QS,…………,Z5ANIIBHDO,ZH6ZYR94CJ,ZQW7M2HZ4I,ZZZENAC3OQ} correlation | 0.00391295 most_common_elems | most_common_elem_freqs | elem_count_histogram | Time: 1.259 ms
關於pg_stat系統表的詳細描述如下
| 名字 | 類型 | 引用 | 描述 |
| schemaname | name | pg_namespace.nspname | 包含此表的模式名字 |
| tablename | name | pg_class.relname | 表的名字 |
| attname | name | pg_attribute.attname | 這一行描述的欄位的名字 |
| inherited | bool | 如果為真,那麼這行包含繼承的子欄位,不只是指定表的值。 | |
| null_frac | real | 記錄中欄位為空的百分比 | |
| avg_width | integer | 欄位記錄以位元組記的平均寬度 | |
| n_distinct | real | 如果大於零,就是在欄位中獨立數值的估計數目。如果小於零, 就是獨立數值的數目被行數除的負數。 用負數形式是因為ANALYZE 認為獨立數值的數目是隨著表增長而增長; 正數的形式用於在欄位看上去好像有固定的可能值數目的情況下。比如, -1 表示一個唯一欄位,獨立數值的個數和行數相同。 |
|
| most_common_vals | anyarray | 一個欄位里最常用數值的列表。如果看上去沒有啥數值比其它更常見,則為 null | |
| most_common_freqs | real[] | 一個最常用數值的頻率的列表,也就是說,每個出現的次數除以行數。 如果most_common_vals是 null ,則為 null。 | |
| histogram_bounds | anyarray | 一個數值的列表,它把欄位的數值分成幾組大致相同熱門的組。 如果在most_common_vals里有數值,則在這個餅圖的計算中省略。
如果欄位數據類型沒有<操作符或者most_common_vals 列表代表了整個分佈性,則這個欄位為 null。 |
|
| correlation | real | 統計與欄位值的物理行序和邏輯行序有關。它的範圍從 -1 到 +1 。 在數值接近 -1 或者 +1
的時候,在欄位上的索引掃描將被認為比它接近零的時候開銷更少, 因為減少了對磁碟的隨機訪問。 如果欄位數據類型沒有<操作符,那麼這個欄位為null。 |
|
| most_common_elems | anyarray | 經常在欄位值中出現的非空元素值的列表。(標量類型為空。) | |
| most_common_elem_freqs | real[] | 最常見元素值的頻率列表,也就是,至少包含一個給定值的實例的行的分數。 每個元素頻率跟著兩到三個附加的值;它們是在每個元素頻率之前的最小和最大值,
還有可選擇的null元素的頻率。 當most_common_elems 為null時,為null) |
|
| elem_count_histogram | real[] | 該欄位中值的不同非空元素值的統計直方圖,跟著不同非空元素的平均值。(標量類型為空。) |
統計信息的更新
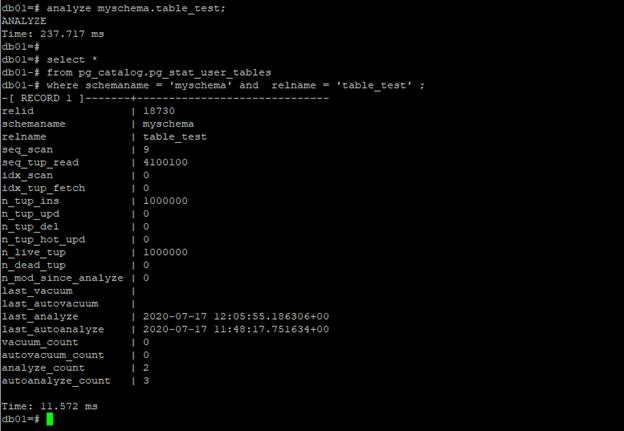
1,統計信息的手動更新:analyze table_name
2,統計信息的自動更新
開始之前,對比SQLServer和MySQL中統計信息的自動更新的出發情況,統計信息更新是一個非常有意思的話題。
SQLServer是表中的輸入寫入(增刪改)超過閾值500 + (20 %×表數據總量)之後會自動觸發更新,以為預設情況下可以認為這是一個寫死的參數。
因為SQLServer統計信息的更新會有非常多的問題,雖然SQLServer有一個trace flag 2371
可以改變改規則,但也屬於半遮半掩的一個非開放功能對於MySQL或者postgresql,類似所有的參數都是可配置化的,因此非常透明
MySQL是innodb_stats_auto_recalc打開的情況下,增刪改的次數大於表中已有數據的10%之後主動觸發更新。
2.1 自動更新的開關
首先autovacuum開關需要打開,也即上文中提到的autovacuum lancher進程實現,在表中的數據滿足一定條件之後的定時更新
這裡的autovacuum是這個自動化更新的開關。預設打開。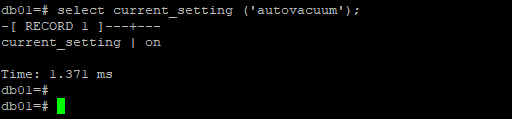
2.2關於自動更新的觸發機制
也類似於MySQL,子線程會根據上下文,存在一個工作頻率,postgresql在打開autovacuum基礎上,
autovacuum進程執行統計信息更新的喚醒頻率,以及工作線程數,依次對各個表執行併發清理,
autovacuum_naptime喚醒頻率預設為1min,autovacuum_max_workers工作線程預設為3個,被喚醒的工作線程會併發對庫中的滿足更新條件的表進行統計信息更新。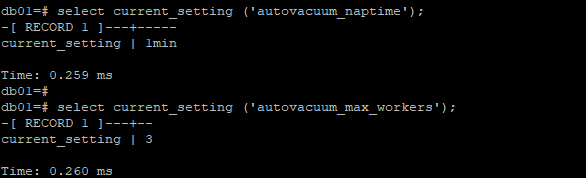
2.3關於自動更新統計信息的閾值
這裡會涉及兩個參數autovacuum_vacuum_threshold和autovacuum_vacuum_scale_factor
anl_base_thresh預設值時50,anl_scale_factor預設值時0.2,這都是可配置的,而且是每個表可以獨立配置的,這裡難免會想到SqlServer的這個閾值也是類似變化數量超過500 + (20 %×表數據總量)
autovacuum進程進行 vacuum 觸發條件表上增刪改的行數 >= autovacuum_vacuum_scale_factor* reltuples(表上記錄數) + autovacuum_vacuum_threshold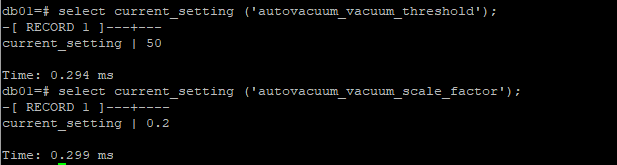
2.4關於自動更新的採樣範圍
參考這裡,提了一個非常好的問題:https://dba.stackexchange.com/questions/200136/postgresql-what-the-default-statistics-target-value-really-means
採樣容量:採用300×default_statistics_target=30000作為採樣的樣本預設容量,default_statistics_target是一個可配置化的參數,預設值變為100
這一點類似於MySQL中的STATS_SAMPLE_PAGES,也就是更新統計信息時候採樣的比例,只不過這裡是page頁面的個數,也是可以基於表來配置的。
難免又想到Server的類似配置項,SqlServer沒有該配置項,不過一切都不是問題,可以換種方式間接使實現。
多扯一句,很多人在講什麼SQL優化,執行計劃,索引之類的,如果拋開統計信息不談,基本上還是那種初級的手段,或者根本就沒遇到過複雜的場景。
上面說了,對於採樣容量,300×default_statistics_target=30000作為採樣的樣本預設容量,default_statistics_target可配置化,這一切看起來都沒有問題,其實可以仔細考慮一下。
對於某些大表或者數據分佈不均勻的請,300×default_statistics_target是不一定夠的,對於10W行的表,採用30000的採樣容量,跟1000W行的表採用同樣的容量,統計信息得到的數據準確性差別是非常大的。 因此,如何根據具體的表,具體的索引結構,具體的應用場景,調整default_statistics_target這個變數就是非常有必要的了。
上面說了,MySQL和SQLServer可以在表級別定義一個STATS_SAMPLE_PAGES或者default_statistics_target的取樣範圍。
sqlserver有一個類似於與此的統計採樣百分比,update statistics *** (***) with sample 30 percent,就是這裡的30,這個值可以從0~100%,隨意指定。
可見,很多東西是殊途同歸的,只是外面的一層馬甲不一樣而已。(為什麼往往要從一定範圍內採樣而不是100%採樣?其實腳後跟就能想明白)
 statistics採樣比例是一個可以在列級別指定的參數,範圍是0~1000,語法是:Alter table <table_name> alter column <column_name> set statistics < value from 1 to 1000 > ;
statistics採樣比例是一個可以在列級別指定的參數,範圍是0~1000,語法是:Alter table <table_name> alter column <column_name> set statistics < value from 1 to 1000 > ;

這個欄位級統計信息的屬性記錄在pg_attribute這個系統表中。
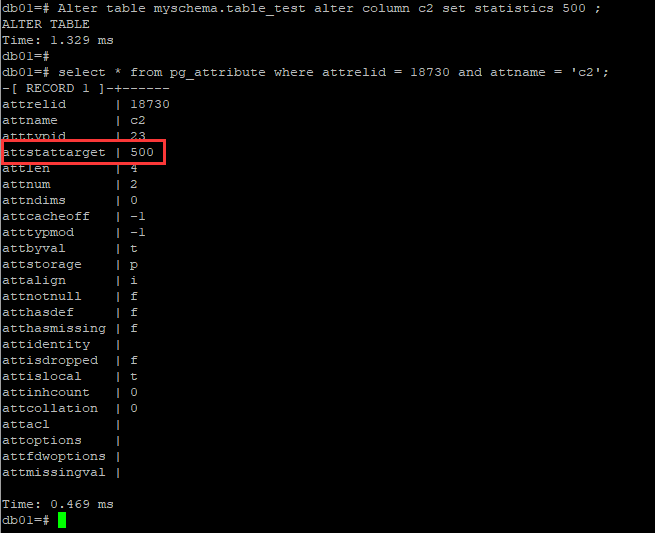
2.5 統計信息最後一次更新之後的變化
統計信息更新日誌,pg_stat_all_tables表存儲了所有表的最後一次更新曆史信息(last_analyza),以及最後一次更新之後數據發生的變化情況(n_mod_since_analyze),這是一個非常因吹斯汀的數據。
上面把統計信息各種閾值,各種觸發條件七七八八地列舉的差不多了,有沒有表再回頭關註最後一次統計信息更新之後表的基數的變化?
肯定是有必要的,上面說了,即便是default_statistics_target是一個可以調整的參數,但不一定知道具體哪個值是合理的或者說是可行的。
那麼,就可以觀察,在執行計劃使用統計信息做預估,出現偏差的臨界點,就需要重新收集更新統計信息了,
那麼此時就可以結合pg_stat_all_tables此時舉上次收集完統計信息變化的情況,來反推autovacuum_vacuum_scale_factor這個值,從而更加科學地去設置autovacuum_vacuum_scale_factor這個因數。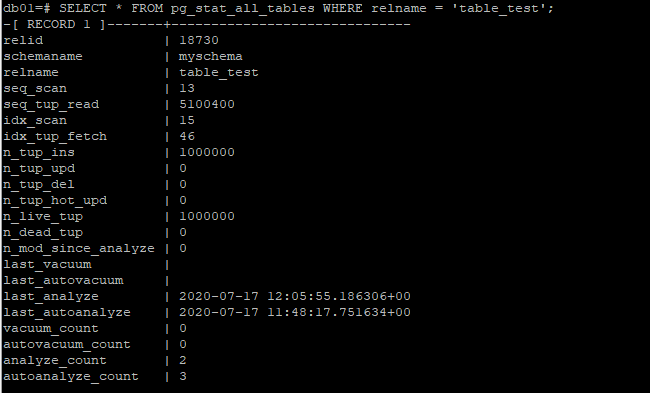
3 手工創建統計信息以及多列統計信息
開始之前現提出一個問題:為什麼需要手動創建統計信息?
通常情況下,統計信息在滿足一定條件,且取樣達到一定程度之後,可以得到一個相對準確的統計信息,一切看起來都是水到渠成。
但是不排除一些個特殊情況,需要手動創建統計信息來實現預估的準確性,比如數據傾斜嚴重的情況下,又難以100%取樣(即便100%取樣,統計信息還有一個“步長”的限制),
此時手動創建統計信息,從而更好指導執行計劃的生成。
這一點SQLServer和Postgresql都是支持的,MySQL這一點是不支持的。
這個就稍微扯遠一點,SQLServer中對於select * from table where c1 = m and c2 = n這種語句,返回行數是如何預估的?
如之前提到過的,假如c1的選擇性為p1,c2的選擇性為p2,表中的總行數為table_rowcount,暫忽略索引自身以及統計信息準確性帶來的影響,以此為前提。
在SQLServer 2012中是預估返回函數是p1*p2*table_rowcount,
在SQLServer 2014或者更高版本中,這個演算法發生了變化,是P1*P21/2*table_rowcount
簡單demo一下,假設在c2和c3欄位上某些條件值分佈的特別不均勻(嚴重傾斜)的情況下,創建這麼一個統計信息之後,可以指導執行計劃在遇到類似的查詢條件之後,做出更加準確的預估。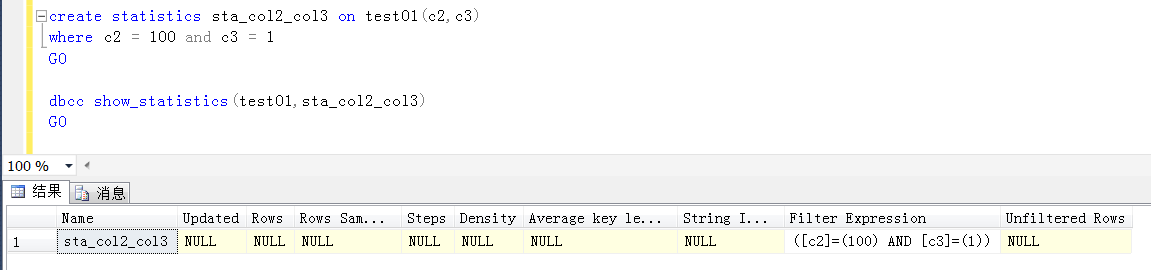
詳細信息參考筆者的上一篇譯文:https://www.cnblogs.com/wy123/p/13306673.html
需要註意的是,在創建完統計信息之後,且執行analyze table,且指定的列數與統計信息中的一致的時候,才會生成該統計信息。
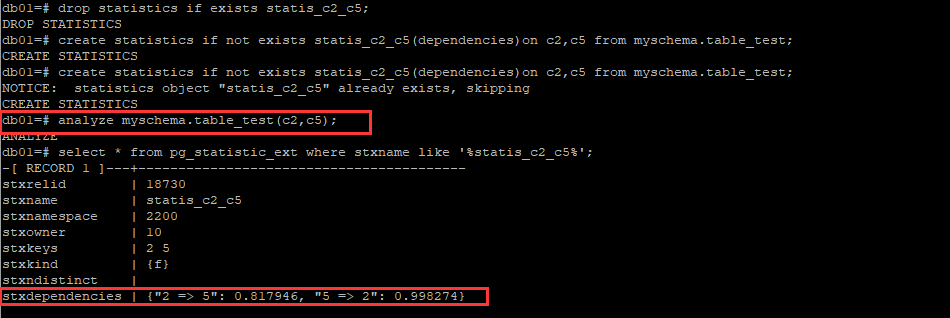
db01=# drop statistics if exists statis_c2_c5; DROP STATISTICS db01=# create statistics if not exists statis_c2_c5(dependencies)on c2,c5 from myschema.table_test; CREATE STATISTICS db01=# create statistics if not exists statis_c2_c5(dependencies)on c2,c5 from myschema.table_test; NOTICE: statistics object "statis_c2_c5" already exists, skipping CREATE STATISTICS db01=# analyze myschema.table_test(c2,c5); ANALYZE db01=# select * from pg_statistic_ext where stxname like '%statis_c2_c5%'; -[ RECORD 1 ]---+----------------------------------------- stxrelid | 18730 stxname | statis_c2_c5 stxnamespace | 2200 stxowner | 10 stxkeys | 2 5 stxkind | {f} stxndistinct | stxdependencies | {"2 => 5": 0.817946, "5 => 2": 0.998274}當然這個多列統計信息之間的依賴性,涉及的東西太多,如果準確地計算相關列之間的依賴(stdkind的f演算法)是一個難題,
這其中的演算法到底是如何實現的,原理是什麼,計算出來結果的準確性如何等等一系列問題,筆者目前也尚不清楚,需要進一步的挖掘(備註:20200722已放棄,如下)。
20200722更新:
因為統計信息作為關係資料庫系統中最複雜的組件之一,看到相關係度的計算原理和公式之後,就開始想念我的高數老師……,神似貝葉斯定理???
已經開始放棄原理的探索了……,開始無條件相信源碼中這部分功能實現的人。
感慨,在非關係資料庫中,相比關係數據是是沒有也不需要如此複雜的組件的,因此在某些場景下,簡單就是美。
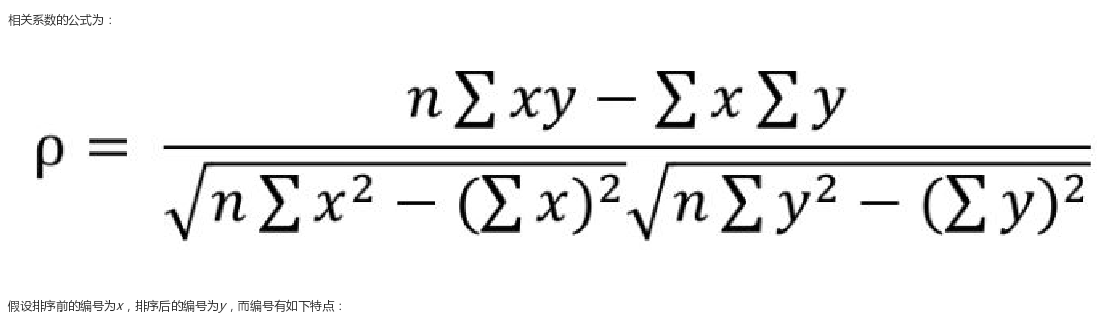
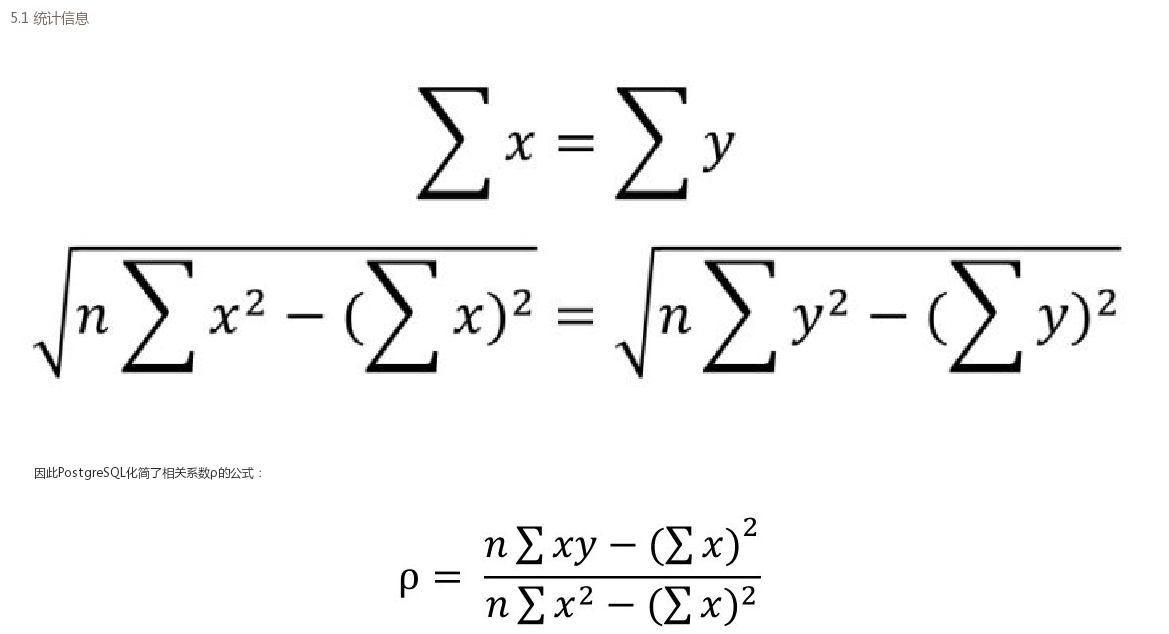

Vacuum和Analyze
統計信息的更新由vacuum進程實現,也可以有手動analyze實現,那麼,Vacuum和Analyze的區別是什麼? autovcuum lancher進程中會定期的執行autovcuum ,Analyze是autovcuum其中的一步,會主動被觸發。 Vacuum是Analyze的超集,Vacuum包含一系列的清理、表的重建、以及表的統計信息更新,換句話說就是,vacuum包含但不限於analyze table來更新統計信息。 參考這裡:Using ANALYZE to optimize PostgreSQL queries Vacuuming isn't the only periodic maintenance your database needs. You also need to analyze the database so that the query planner has table statistics it can use when deciding how to execute a query. Simply put: Make sure you're running ANALYZE frequently enough, preferably via autovacuum. And increase the default_statistics_target (in postgresql.conf) to 100.參考鏈接: http://www.postgres.cn/docs/9.4/monitoring-stats.html
https://blog.pgaddict.com/posts/the-two-kinds-of-stats-in-postgresql
http://www.postgres.cn/docs/10/routine-vacuuming.html
https://www.postgresql.org/docs/12/planner-stats.html
https://www.postgresql.org/docs/11/runtime-config-query.html
https://pganalyze.com/blog/postgresql-log-monitoring-101-deadlocks-checkpoints-blocked-queries
https://www.cybertec-postgresql.com/en/setting-postgresql-configuration-parameters/
https://coderbook.com/@marcus/postgres-autovacuum-vacuum-and-analyze-explained/
https://wiki.postgresql.org/wiki/Introduction_to_VACUUM,_ANALYZE,_EXPLAIN,_and_COUNT


