
目前CSDN,博客園,簡書同步發表中,更多精彩歡迎訪問我的gitee pages MapReduce精通(一) MapReduce入門 MapReduce定義 MapReduce優缺點 優點 缺點 MapReduce核心思想 總結:分析WordCount數據流走向深入理解MapReduce核心思想。 ...
目前CSDN,博客園,簡書同步發表中,更多精彩歡迎訪問我的gitee pages
目錄
MapReduce精通(一)
MapReduce入門
MapReduce定義

MapReduce優缺點
優點


缺點

MapReduce核心思想
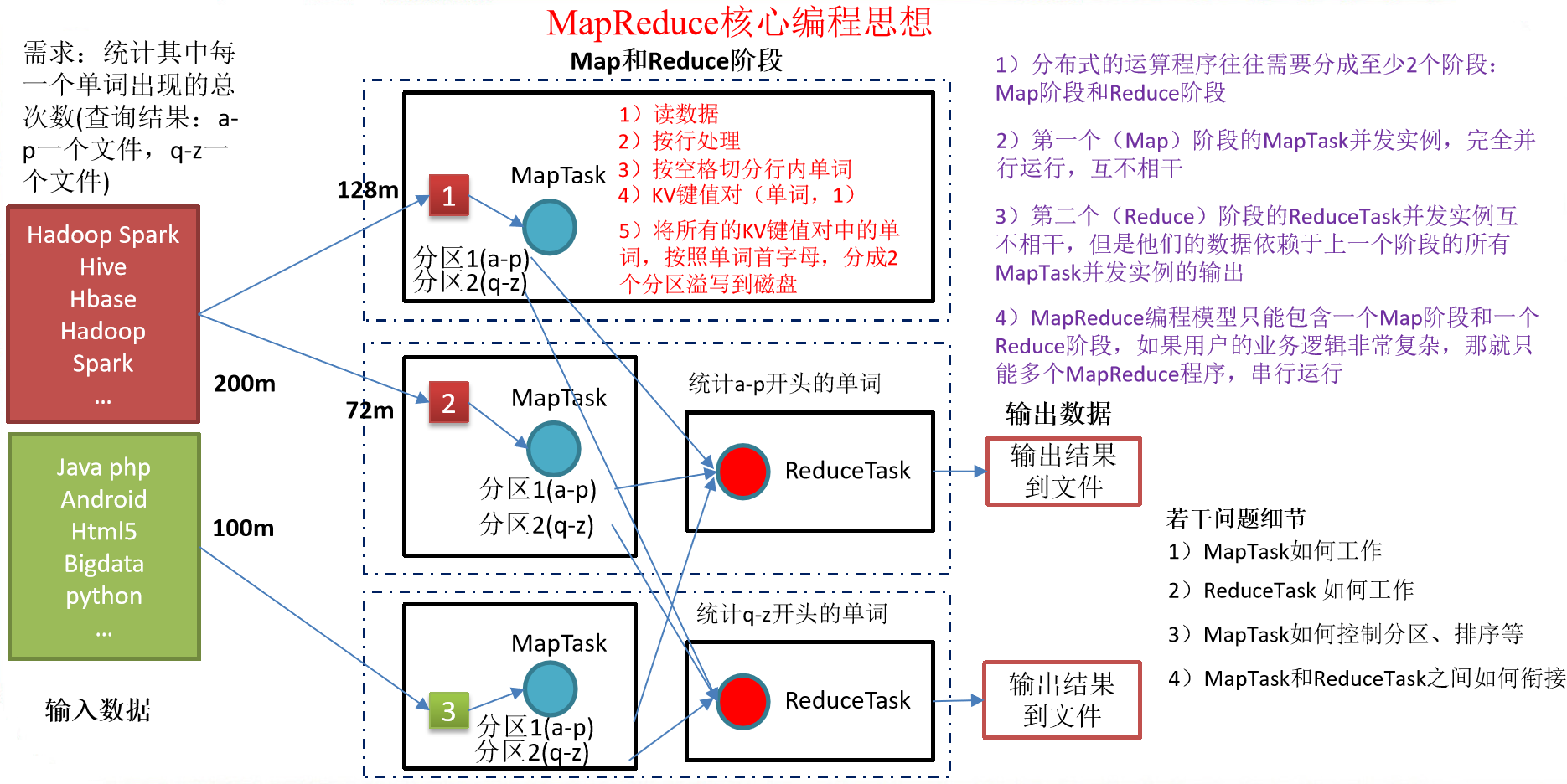
總結:分析WordCount數據流走向深入理解MapReduce核心思想。
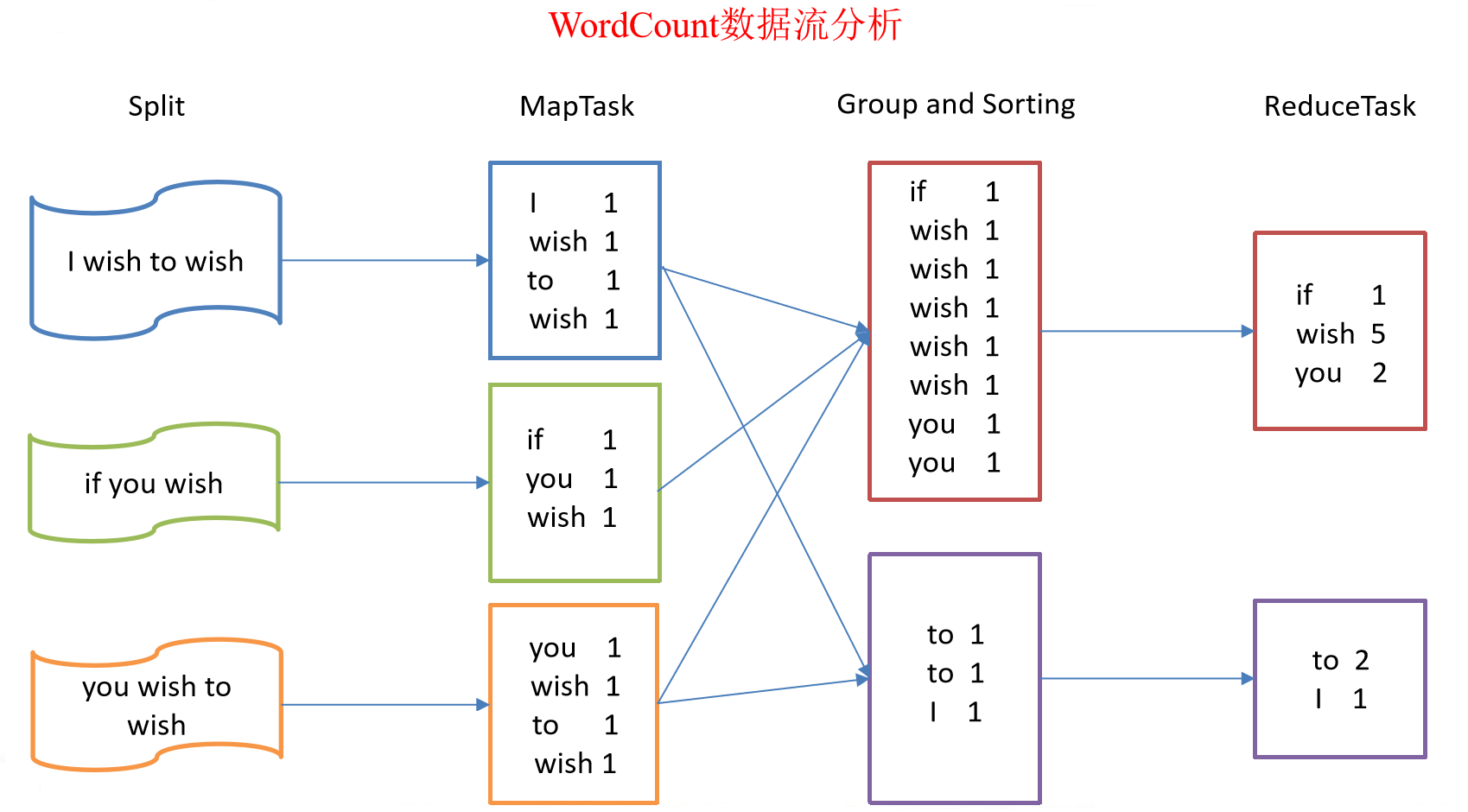
MapReduce進程

MapReduce編程規範
用戶編寫的程式分成三個部分:Mapper、Reducer和Driver。


WordCount案例實操
-
需求
在給定的文本文件中統計輸出每一個單詞出現的總次數
-
輸入數據
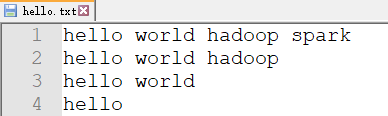
-
期望輸出數據
hadoop 2
hello 4
spark 1
world 3
-
-
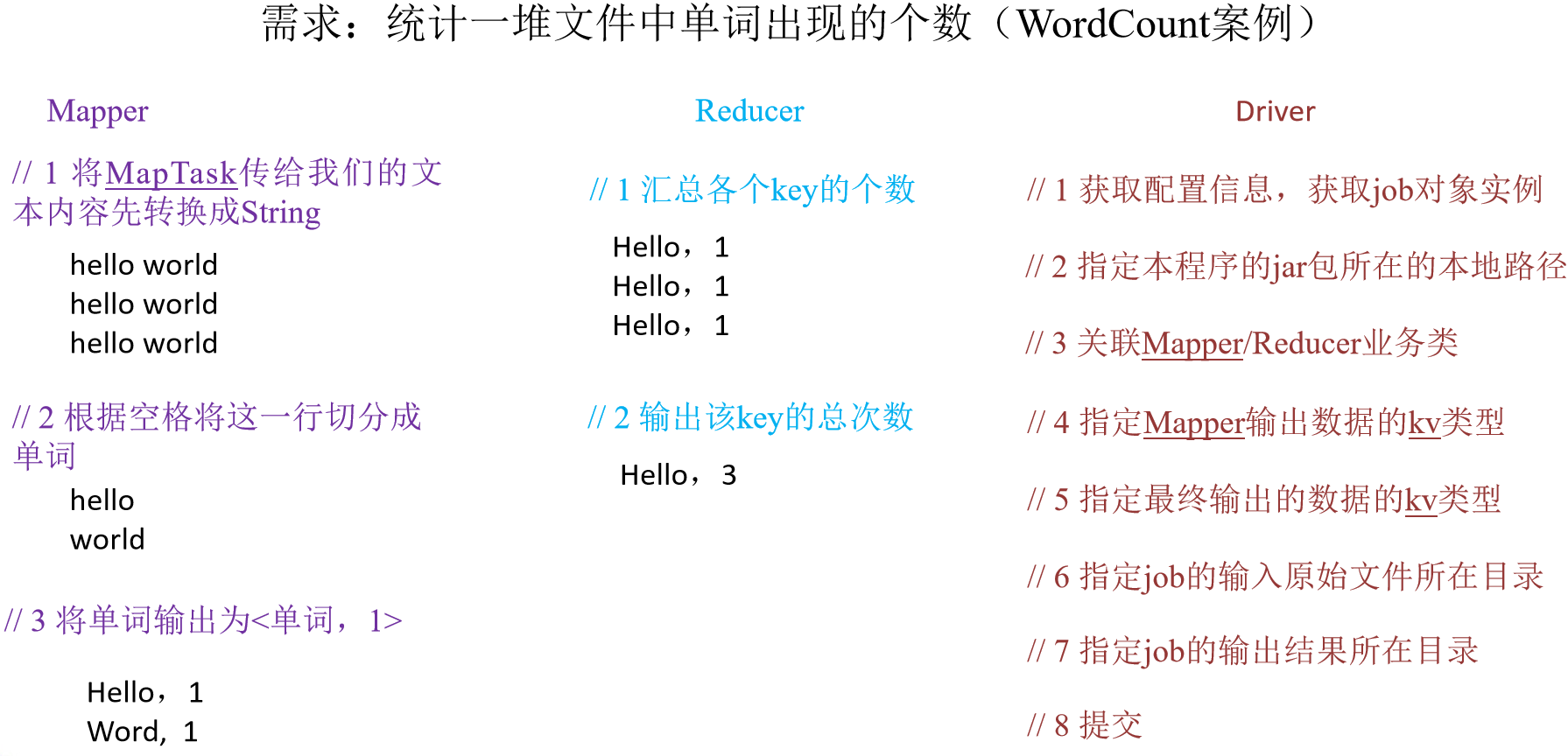
需求分析
按照MapReduce編程規範,分別編寫Mapper,Reducer,Driver,如圖所示。
-
環境準備
-
創建maven工程
-
在pom.xml文件中添加如下依賴
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> </dependencies> -
在項目的src/main/resources目錄下,新建一個文件,命名為“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
-
-
編寫程式
-
編寫Mapper類
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable{ Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取一行 String line = value.toString(); // 2 切割 String[] words = line.split(" "); // 3 輸出 for (String word : words) { k.set(word); context.write(k, v); } } }說明:
註意:導包時,導入 org.apache.hadoop.mapreduce包下的類(2.0的新api)
-
自定義的類必須符合MR的Mapper的規範
-
在MR中,只能處理key-value格式的數據
KEYIN, VALUEIN: mapper輸入的k-v類型。 由當前Job的InputFormat的RecordReader決定!封裝輸入的key-value由RR自動進行。
KEYOUT, VALUEOUT: mapper輸出的k-v類型: 自定義
-
InputFormat的作用:
-
驗證輸入目錄中文件格式,是否符合當前Job的要求
-
生成切片,每個切片都會交給一個MapTask處理
-
提供RecordReader,由RR從切片中讀取記錄,交給Mapper進行處理
方法: List
getSplits: 切片 RecordReader<K,V> createRecordReader: 創建RR
預設hadoop使用的是TextInputFormat
**TextInputFormat使用LineRecordReader** **LineRecordReader Treats keys as offset in file and value as line.**(即偏移量offset當做key,每一行當做value)
-
-
在Hadoop中,如果有Reduce階段。通常key-value都需要實現序列化協議!
MapTask處理後的key-value,只是一個階段性的結果!
這些key-value需要傳輸到ReduceTask所在的機器!
將一個對象通過序列化技術,序列化到一個文件中,經過網路傳輸到另外一臺機器,再使用反序列化技術,從文件中讀取數據,還原為對象是最快捷的方式!
hadoop開發了一款輕量級的序列化協議: Wriable機制!
-
-
編寫Reducer類
/* * 1. Reducer需要複合Hadoop的Reducer規範 * * 2. KEYIN, VALUEIN: Mapper輸出的keyout-valueout * KEYOUT, VALUEOUT: 自定義 */ public class WordcountReducer extends Reducer<Text, IntWritable, Text,IntWritable>{ int sum; IntWritable v = new IntWritable(); // reduce一次處理一組數據,key相同的視為一組 @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException,InterruptedException { // 1 累加求和 sum = 0; for (IntWritable count : values) { sum += count.get(); } // 2 輸出 v.set(sum); //將累加的值寫出 context.write(key,v); } } -
編寫Driver驅動類
public class WordcountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[] { "F:/BaiduNetdiskDownload/mrinput/wordcount", "F:/BaiduNetdiskDownload/wordcount"}; //Linux上的地址 //args = new String[] { "/wcinput1", "/wcoutput1"}; // 1 獲取配置信息以及封裝任務 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 設置jar載入路徑 job.setJarByClass(WordcountDriver.class); // 3 設置map和reduce類 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); // 4 設置map輸出 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5 設置Reduce輸出 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6 設置輸入和輸出路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
-
-
本地測試
直接運行WordcountDriver的main方法.查看結果

-
集群上測試
-
將程式打成jar包,然後拷貝到Hadoop集群中,修改jar包名稱為wc.jar
-
啟動Hadoop集群
-
執行WordCount程式
[atguigu@hadoop102 ~]$ hadoop fs -mkdir /wcinput1 [atguigu@hadoop102 ~]$ hadoop fs -put hello.txt /wcinput1 [atguigu@hadoop102 ~]$ hadoop jar wc.jar com.atguigu.mr.wordcount.WordcountDriver /wcinput1 /wcoutput1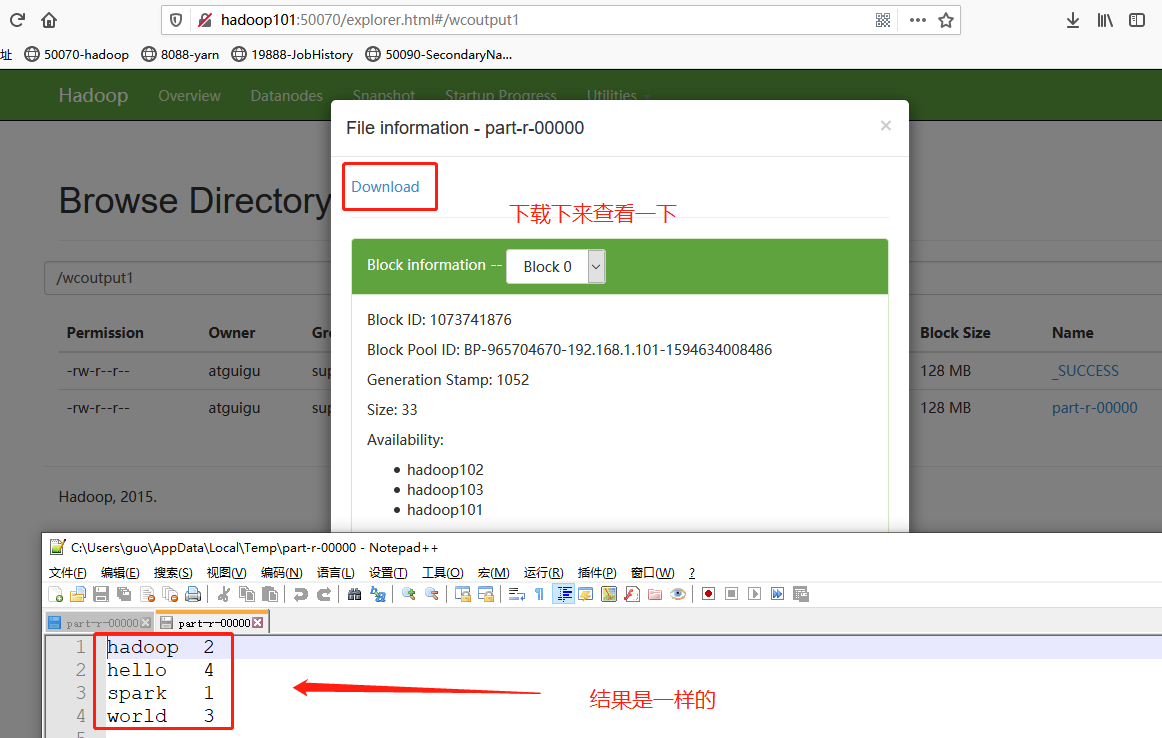
-
Hadoop序列化
序列化概述


常用數據序列化類型
| Java類型 | Hadoop Writable類型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
自定義bean對象實現序列化介面(Writable)
自定義bean對象要想序列化傳輸,必須實現序列化介面。具體操作步驟如下
-
必須實現Writable介面
-
反序列化時,需要反射調用空參構造函數,所以必須有空參構造
public FlowBean() { super(); } -
重寫序列化方法
@Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } -
重寫反序列化方法
@Override public void readFields(DataInput in) throws IOException { upFlow = in.readLong(); downFlow = in.readLong(); sumFlow = in.readLong(); } -
註意反序列化的順序和序列化的順序完全一致
-
要想把結果顯示在文件中,需要重寫toString(),可用”\t”分開,方便後續用。
@Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } -
如果需要將自定義的bean放在key中傳輸,則還需要實現Comparable介面,因為MapReduce框中的Shuffle過程要求對key必須能排序。
@Override public int compareTo(FlowBean o) { // 倒序排列,從大到小 return this.sumFlow > o.getSumFlow() ? -1 : 1; }
序列化案例實操
-
需求
統計每一個手機號耗費的總上行流量、下行流量、總流量
-
輸入數據格式
id 手機號碼 網路ip 上行流量 下行流量 網路狀態碼 7 13560436666 120.196.100.99 1116 954 200 -
輸入數據
1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.atguigu.com 1527 2106 200
6 84188413 192.168.100.3 www.atguigu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.atguigu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200
-
-
需求分析

-
編寫MapReduce程式
-
編寫流量統計的Bean對象
package com.atguigu.mapreduce.flowsum; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; // 1 實現writable介面 public class FlowBean implements Writable{ private long upFlow ; private long downFlow; private long sumFlow; //2 反序列化時,需要反射調用空參構造函數,所以必須有 public FlowBean() { super(); } public FlowBean(long upFlow, long downFlow) { super(); this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } //3 寫序列化方法 @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } //4 反序列化方法 //5 反序列化方法讀順序必須和寫序列化方法的寫順序必須一致 @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); } // 6 編寫toString方法,方便後續列印到文本 @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } } -
編寫Mapper類
package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ FlowBean v = new FlowBean(); Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取一行 String line = value.toString(); // 2 切割欄位 String[] fields = line.split("\t"); // 3 封裝對象 // 取出手機號碼 String phoneNum = fields[1]; // 取出上行流量和下行流量 long upFlow = Long.parseLong(fields[fields.length - 3]); long downFlow = Long.parseLong(fields[fields.length - 2]); k.set(phoneNum); v.set(downFlow, upFlow); // 4 寫出 context.write(k, v); } } -
編寫Reducer類
package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean>{ private FlowBean out_value=new FlowBean(); @Override protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException { long sumUpFlow=0; long sumDownFlow=0; // 1 遍歷所用bean,將其中的上行流量,下行流量分別累加 for (FlowBean flowBean : values) { sumUpFlow+=flowBean.getUpFlow(); sumDownFlow+=flowBean.getDownFlow(); } // 2 封裝對象 out_value.setUpFlow(sumUpFlow); out_value.setDownFlow(sumDownFlow); out_value.setSumFlow(sumDownFlow+sumUpFlow); // 3 寫出 context.write(key, out_value); } } -
編寫Driver驅動類
package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowsumDriver { public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[] {"F:/BaiduNetdiskDownload/mrinput/flowbean", "F:/BaiduNetdiskDownload/flowbean"}; //保證輸出目錄不存在 FileSystem fs=FileSystem.get(conf); if (fs.exists(outputPath)) { fs.delete(outputPath, true); } // 1 獲取配置信息,或者job對象實例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 6 指定本程式的jar包所在的本地路徑 job.setJarByClass(FlowsumDriver.class); // 2 指定本業務job要使用的mapper/Reducer業務類 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 3 指定mapper輸出數據的kv類型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 4 指定最終輸出的數據的kv類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 5 指定job的輸入原始文件所在目錄 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 將job中配置的相關參數,以及job所用的java類所在的jar包, 提交給yarn去運行 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
-
由於篇幅過長,[MapReduce框架原理]等以後的內容,請看下回分解!


