
學習電腦組成原理有什麼用? 從StackOverFlow上一個很經典的問題說起 運行下麵的程式,然後比較加上Arrays.sort(data)這行之後,程式速度的變化 import java.util.Arrays; import java.util.Random; public class Te ...
學習電腦組成原理有什麼用?
從StackOverFlow上一個很經典的問題說起
運行下麵的程式,然後比較加上Arrays.sort(data)這行之後,程式速度的變化
import java.util.Arrays;
import java.util.Random;
public class Test
{
public static void main(String[] args)
{
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// !!! With this, the next loop runs faster
//Arrays.sort(data);
// Test
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < 100000; ++i)
{
// Primary loop
for (int c = 0; c < arraySize; ++c)
{
if(data[c]>128)
sum+=data[c];
}
}
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
}
在我的電腦上,對數組排序後程式運行速度是原來的四倍,這就奇了怪了,怎麼排個序就快了這麼多?你可能模模糊糊知道應該往計組的方面想,要從底層找原因,畢竟這篇博文就是試圖向你說明瞭解計組有什麼用。
現在將排序註釋掉,並把primary loop裡面的代碼換成
int t = (data[c] - 128) >> 31;
sum += ~t & data[c];
再次運行程式,你會發現程式運行的時間跟排序後的運行時間差不多,甚至還快一點。有意思吧,通過前面的兩次改動,我們已經把問題鎖定在了Primary loop這裡,現在看來是if語句搞的鬼。沒想到這個平日里看起來濃眉大眼,人畜無害的東西也會給我玩花樣,想不到想不到。
為了快點寫完作業,我選擇瞎蒙
現代電腦的設計,在提高運行速度這塊想出了很多辦法,cache絕對算的上是最精彩的那一個。不過跟本問題相關的是流水線的設計,我們還是先來認識這熟悉又陌生的詞語吧。
流水線是一種實現多條指令重疊執行的技術,你可以類比於生產流水線。
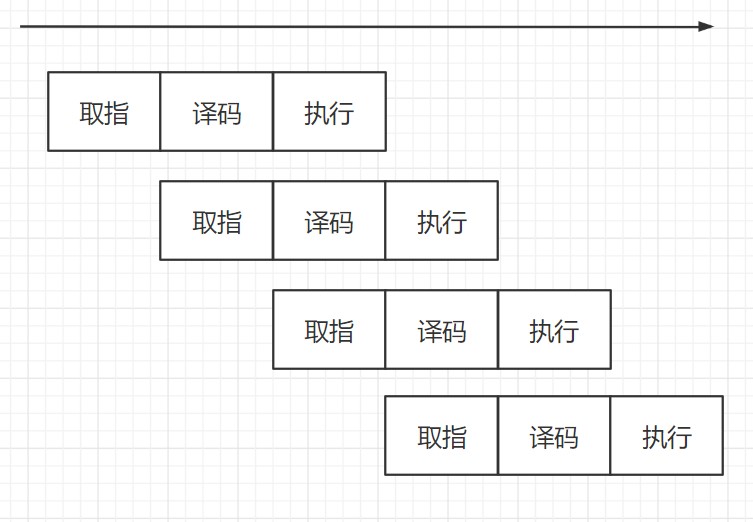
類似於這樣,大家印象中的流水線都是高速運轉的,沒有人希望它停頓。如果流水線存在分支的話,按照常理來講,我們只能是停下來等結果。等比較的結果出來了,再決定走哪條分支 。流水線說,我是一個永不止步的男人,怎麼能因為這點事就停頓呢?忍不了,咋整呢?
有一種辦法是分支冒險(branch hazard),雖然名字聽起來很高大上,其實就是賭一把,蒙一個。我假設這個分支發生,賭對了自然什麼都不用做,賭錯了就得丟棄假設不發生之後執行的指令。這有點像趕作業的時候,碰到判斷題如果你不想做的話,就一路打×,因為這種題目大概率打叉的情況多。當然,電腦沒有你那麼聰明不知道這條規律,但它可以使用動態分支預測的方法來提高預測的準確性。
這裡介紹兩位預測位機制,猜錯兩次就變換猜測方向。
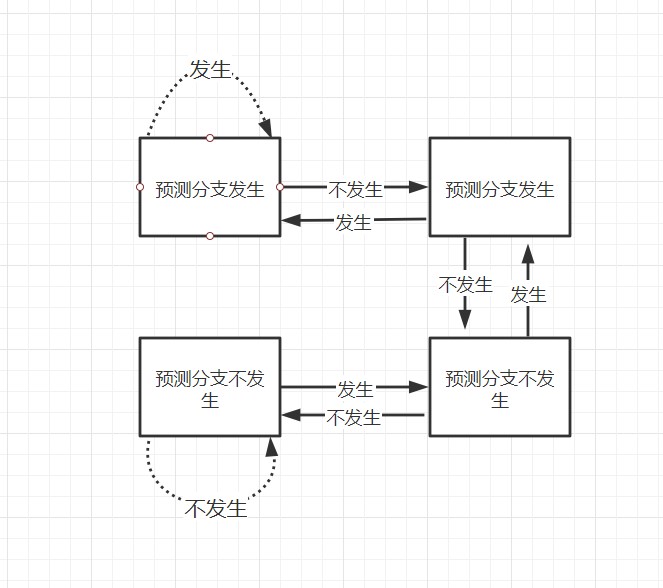
讓我們再來回憶一下之前的實常式序的流程,在0-256的範圍隨機生成了一個數組,並且將大於128的值加到sum變數中。現在,讓我們用剛剛學到的知識分析那條萬惡的if語句
if(data[c]>128)
sum+=data[c];
累計兩次預測失敗我們就會變換預測方向,如果不對數組進行排序的話,數組中的數字是隨機分佈的,我們預測的準確性將會非常低。這意味著我們將會耗費大量的時間在:將流水線中投機執行的中間結果全部拋棄,重新獲取正確分支路線上的指令執行。如果是已經排好序的數組,最壞的情況下我們也只有四次預測失敗,這為我們節省了大把的時間。這也是為什麼我們換成位運算,程式會更快的原因。因為不會存在預測失敗重新執行的情況。
好像和我程式里寫的不一樣
public class Thread01 implements Runnable {
private int cnt=10;
@Override
public void run() {
while (cnt>0){
System.out.println(Thread.currentThread().getName()+" cnt= "+cnt--);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
Thread01 thread01=new Thread01();
Thread a=new Thread(thread01,"a");
Thread b=new Thread(thread01,"b");
Thread c=new Thread(thread01,"c");
Thread d=new Thread(thread01,"d");
Thread e=new Thread(thread01,"e");
a.start();
b.start();
c.start();
d.start();
e.start();
}
}
運行這段程式,你會發現有兩個線程輸出了同樣的數字,按道理這是絕對不可能發生的事情。還是電腦惹的鍋,因為CPU訪問緩存區比訪問記憶體要快得多,所以為了高效,現代電腦往往會在高速緩存區中緩存共用變數。
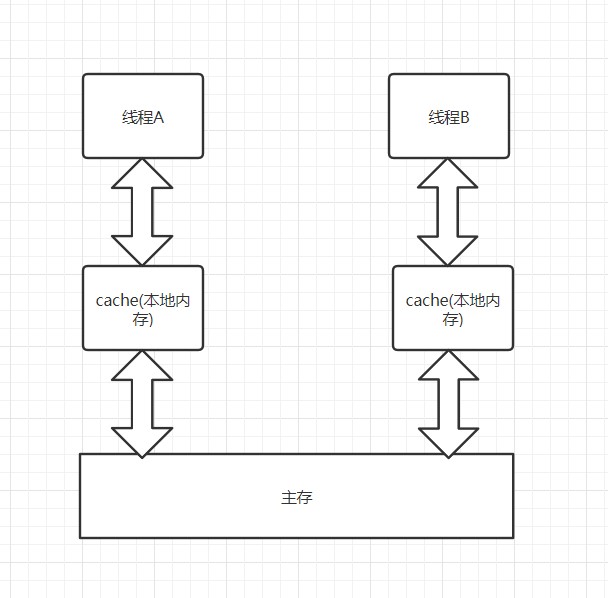
也就是說,大家各搞各的,這與cache的寫回操作有關(保險的辦法當然是寫直達,但咱不是為了快嘛,所以就出問題了)。有可能你修改的時候,來不及通知我這個值已經不能用了,要重新獲取,最後的結果就是輸出了兩個一模一樣的值。
多線程的東西很多:重排序,記憶體屏障,CAS....感興趣的同學可以查閱相關資料,這篇博文只是拋磚引玉而已。


